開発者の皆さん、こんにちは。
InterSystems ベクトル検索、GenAI、 ML コンテスト(USコミュニティ)の投票が始まりました!今回は新メンバーからの6作品を含め、16のアプリケーションが投稿されました。
🔥 ベストアプリケーションはこれだ! 🔥と思う作品にぜひ投票をお願いします!
%20(3)(3).jpg)
投票方法は以下の通りです。
開発者の皆さん、こんにちは。
InterSystems ベクトル検索、GenAI、 ML コンテスト(USコミュニティ)の投票が始まりました!今回は新メンバーからの6作品を含め、16のアプリケーションが投稿されました。
🔥 ベストアプリケーションはこれだ! 🔥と思う作品にぜひ投票をお願いします!
投票方法は以下の通りです。
「30 秒も経ってるのにサービスを受けられないなんて、 あり得ない! もう結構!」
「大変申し訳ございません。 次回からはご予約なさってはいかがでしょうか。」
お気に入りのレストランでこんなコメントを聞いたら、そんな発言はばかばかしいと思うのではないでしょうか。 でも、API のコンテキストでは、まったく合理的な意見です。 お気に入りのレストランと同じように、API にも常連客がいます。よく訪問するユーザーのことです。 同じように繰り返し予約が可能であればよいと思いませんか?
これには、IRIS の基本機能がいくつか関わってきます。 まず、%SYSTEM.License インターフェースを理解する必要があります。 これは、IRIS インスタンスのライセンス使用状況に関する情報を取得するために提供されているインターフェースです。 次に、%CSP.SessionEvents クラスについて学ぶ必要があります。 このクラスを使うと、CSP セッションのライフサイクル全体で呼び出される様々なメソッドをオーバーライドできます。
まずは、%SYSTEM.License インターフェースから見ていきましょう。 このクラスには、$SYSTEM.License を使って呼び出せるメソッドもあれば、##class(%SYSTEM.License) で呼び出す必要のあるメソッドもあります。
IRIS BIチュートリアル試してみたシリーズの9回目です。
今回は、チュートリアル全6ページのうちの5ページ目、「サブジェクト領域の作成」について試していきます。
「サブジェクト領域」という新しい概念が出てきますが、どんなものかを触りながら理解していきます。
では、早速はじめていきましょう。
最初に、サブジェクト領域とは何かを理解するところから始めましょう。チュートリアルでは以下のような説明があります。
”サブジェクト領域は、オプションによる項目名のオーバーライドを持つサブキューブです。サブジェクト領域を定義すると、セキュリティ上の理由およびその他の理由により、より小さなデータ・セットに焦点を当てることができます。”
うーん、分かったような、分からないような。。実例を基に説明してみます。
6回目の記事で郵便番号と市区町村の階層を作成しました。郵便番号→市区町村という階層構造になっていましたよね。以下の図が、郵便番号と市区町村の関連を表したものです。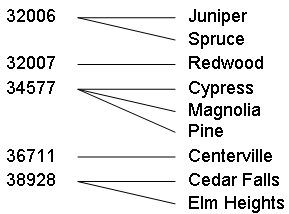
現状、チュートリアルで使用しているキューブには上記5つの郵便番号を持つデータが格納されています。
これを、特定の郵便番号のデータだけを扱えるサブセットに分割したい要件があったとします。例えば配達員の担当地域ごとに分割するとか。
開発者の皆さん、こんにちは。
2023年5月にご案内した記事「2023.2 からスタジオが非推奨となります」でもご案内しましたが、インターシステムズは、IRIS 2023.2のリリースからスタジオの廃止を発表しました。
詳細な非推奨計画は2023年11月にお知らせした記事「InterSystems Studio の非推奨に関するお知らせ」でご案内していましたが、バージョン2024.2のプレビューリリースが始まり現在その計画の最初のマイルストーンに到達しました。
バージョン2024.2 プレビューキット以降、Windows キットにはスタジオが含まれなくなります。つまり、このキットを使用した新規インストールでは スタジオがインストールされません。既存のインスタンスをバージョン 2024.2以降にアップグレードした場合は、インスタンスの bin ディレクトリから スタジオが削除されます。
VS Code でファイルを編集しているときに、グローバル値のチェックやいくつかの ObjectScript コマンドの実行が必要だったことはありませんか? これが可能になりました。しかもセットアップは不要です! vscode-objectscript 拡張機能バージョン 2.10.0 以上を持っており、InterSystems IRIS 2023.3 以降に接続している場合は、サーバーの場所に関係なくサーバーへのターミナル接続を開けるようになりました。
この新しいターミナルを開く方法には 3 つあります。
コマンドパレットの「Launch WebSocket Terminal」(WebSocket ターミナルを起動)コマンド(Windows では Ctrl-Shift-P、Mac では Cmd-Shift-P):
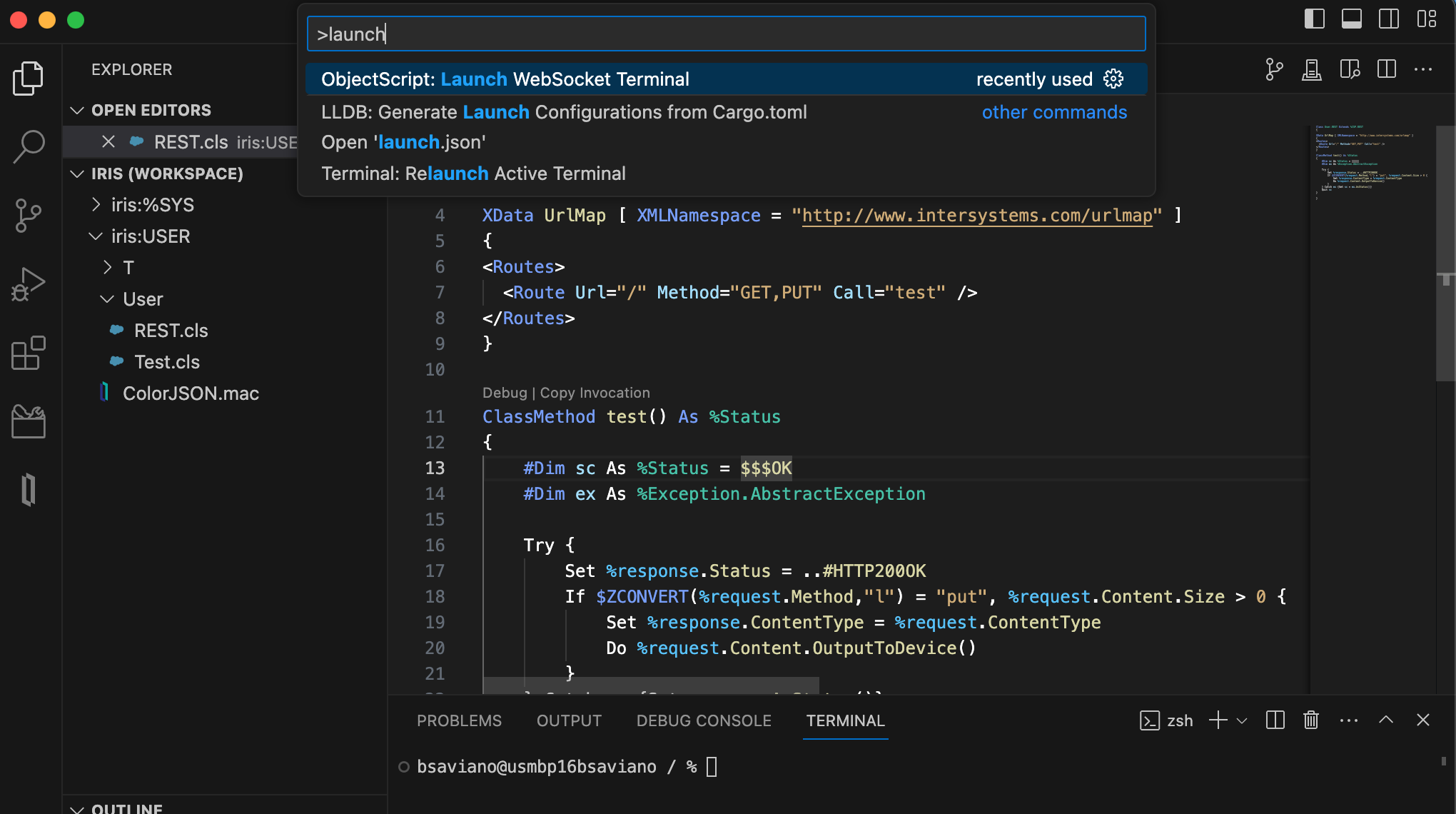
VS Code が統合されたターミナルの Profiles(プロファイル)メニュー:
Server Manager 拡張機能のサーバーツリー:
WebSocket ターミナルは、読み取り、ネームスペースの切り替え、中断、カスタムターミナルプロンプトなど、標準 ObjectScript シェルの多数の機能をサポートしていますが、 この記事では、これに特有の 3 つの機能に焦点を当てたいと思います。
InterSystems IRIS 2024.2 と InterSystems IRIS for Health 2024.2 の最新の開発者プレビューが WRC プレビューダウンロードページ に公開されました。今回のリリースには以下のような注目の変更点が含まれています。
VS Code に焦点を当てた 2 つの現地ウェビナー(ヘブライ語による「Intro」および「Beyond Basics」)に続き、フォローアップとして参加者向けに送信した関連リソースのリンクを用意しました。 コミュニティのために、ここでもそれを共有しています。
便利なリソースをぜひさらに追加してください。
前回、LinuxでODBC接続を行う方法 をご紹介しました。
今回は、LinuxでJDBC接続を行う方法 をご紹介します。作業は、root ユーザ で行います。
はじめに、Linuxのバージョンを確認します。
$ cat /etc/os-release$ su - yum update今回は、Adoptium OpenJDK の Version 8 - LTS を使用してテストします。
※ *.tar.gz は、/usr/java 以下にダウンロードします。
cd lsLinuxのバージョンにあったインストーラを使用してください。
cd ./irisinstall_client※JDBC ドライバのみダウンロードしたい場合は、こちら から行えます(JDBC のリンクをクリック)。
JAVA_HOME --- JDKがインストールされているディレクトリ PATH --- $JAVA_HOME/bin + <IRISクライアントインストールディレクトリ>/bin LD_LIBRARY_PATH --- $JAVA_HOME/lib
IRIS BIチュートリアル試してみたシリーズの8回目です。このシリーズもだいぶ長くなってきました。
今回も、前回に引き続きチュートリアルの「キューブ定義の拡張」ページの内容です。
最後に残った2つのトピックについて進めていきます。では、はじめていきましょう。
タイトルには「置換」とありますが、ディメンジョンのレベルを集約した新しいレベルを作成する方法、と理解していただくのがよいかもしれません。
2回目の記事でちょっとだけ触れた Age Group と Age Bucket レベルを作成していきます。
まず Age Group レベルを作成します。こちらは以下のような3つのグルーピングになります。
アーキテクト画面を開き、Tutorial キューブを開きます。
新しいレベルを作成しますので、AgeD ディメンジョンの Age レベルをクリックし、その後に [要素を追加] リンクをクリックします。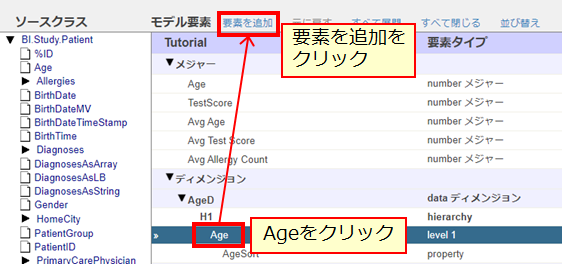
要素名に Age Group、要素選択に レベル を指定します。
Age Groupレベルが追加されました。
詳細ペインで Age Group レベルの設定を変更します。[プロパティ] に Age と入力し、[範囲表現] の虫眼鏡アイコンをクリックします。
こちらの記事では、LinuxでODBC接続の設定を行う方法をご紹介します。
はじめに、Linuxのバージョンを確認します。
$ cat /etc/os-release$ sudo yum update sudo yum install unixODBC確認します
which which※Linuxのバージョンにあったインストーラを使用してください。
sudo ./irisinstall_client※SYSTEM DATA SOURCES: /etc/odbc.ini に以下を追加します
[ODBC Data Sources] InterSystemsODBC6435 = InterSystemsODBC6435 [InterSystemsODBC6435] Description=InterSystems ODBC Driver = /intersystems/iris/bin/libirisodbcur6435.so Setup = /intersystems/iris/bin/libirisodbcur6435.so Unicode SQLTypes = 1 Host=***.***.***.*** Namespace=USER UID=_SYSTEM Password=SYS Port=1972
警告:"NOT %INLIST" を使用した SQL クエリが結果を返さない
インターシステムズは、一部の SQL クエリが不正な結果を返す原因となる 3 つ
の不具合を修正しました。 影響を受けるクエリの詳細については、以下を参照し
てください。
この問題は、以下の製品のリストにあるバージョンに存在します:
同様に上記製品をベースとしたその他のインターシステムズ製品
影響を受けるバージョン:
以下の条件を満たすクエリで、誤った結果を返す可能性があります:
WHERE 節に NOT %INLIST が含まれている
そのリストに NULL 値がある
この不具合の修正は DP-430793 で解決します。この修正は、2022.1.5、2023.1.4、2024.1.1
以降のすべてのバージョンに含まれる予定です。修正はアドホックによる配布でも可能です。
インターシステムズは、InterSystems IRIS、InterSystems IRIS for Health、HealthShare Health Connect のメンテナンスバージョン 2022.1.5 および 2023.1.4 をリリースしました。
2022.1.x に対するバグフィックスを提供しています。詳細な情報は、以下のページをご参照ください(すべて英語版です)
InterSystems IRIS
InterSystems IRIS for Health
HealthShare Health Connect
2023.1.x に対するバグフィックスを提供しています。詳細な情報は、以下のページをご参照ください(すべて英語版です)
InterSystems IRIS
InterSystems IRIS for Health
HealthShare Health Connect
本製品は、従来からのインストーラパッケージ形式と、コンテナイメージ形式をご用意しています。その一覧は、サポートプラットフォームページ(英語)をご覧ください。
インストーラパッケージは、WRC Direct から入手できます。
IRIS BIチュートリアル試してみたシリーズの7回目です。
今回も、「キューブ定義の拡張」ページのトピックになります。では、早速はじめていきましょう。
コレクションを使用してディメンジョンのレベルを作成します。
コレクションって何?という方は、こちらのオンラインドキュメントを参考にしてください。リストや配列など、同じタイプの要素が複数含まれるオブジェクト・クラスのことを指します。
今回のキューブのベースとなる BI_Study.Patient テーブルにある2つのフィールド、Allergies と DiagnosesAsLB を使用します。各々のデータタイプを確認してみましょう。システムエクスプローラ → SQL から BI_Study.Patient テーブルのフィールド情報を確認します。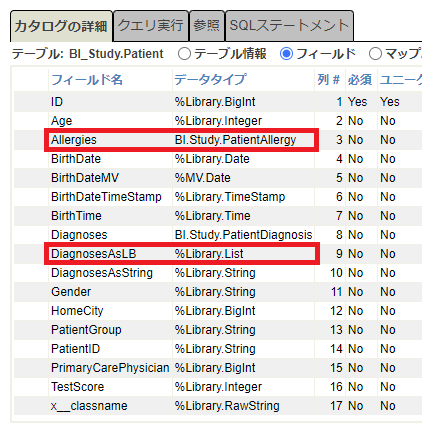
Allergies フィールドは PatientAllergy クラスを参照し、DiagnosesAsLB フィールドはリスト型で定義されています。
では、まず DiagnosesAsLB に対応するレベルを作成します。アーキテクト画面から Tutorial キューブを開きます。
画面上部の [要素を追加] リンクから DiagD という名前のディメンジョンを作成します。要素選択は データ・ディメンジョン を選択します。
大きなサイズのデータを持つフィールドに対してインデックスを作成すると、<SUBSCRIPT>エラーとなることがあります。
これは、グローバルの添え字(サブスクリプト)のサイズには制限があり、制限を超えるとエラーとなるためです。
例えば、以下のようなインデックスの場合、
^Sample.PersonI("NameIdx"," xxx...xxx",1) = ""グローバル名+サブスクリプト部(=の左側)が、エンコード文字数で最長 511 文字を超えるとエラーとなります(日本語の場合はもっと小さな文字数です)。
※ご参考:グローバル参照の最大長
大きいデータを持つカラムに対してインデックスを設定したい場合の回避策としては、こちらの ドキュメント にありますように
「該当のプロパティのインデックス照合文字列を任意の文字数(例:128文字)に制限した照合を定義」
する方法があります。
具体的には、以下の2つの方法になります。
※クラス定義の変更/保存/コンパイル+インデックスの再構築が必要です。
IRIS BIチュートリアル試してみたシリーズの6回目です。
今回からは、全6ページのうちの4ページ目「キューブ定義の拡張」に入っていきます。
前回まではメジャーやディメンジョンなど、基本的なキューブの構成要素を作成しましたが、さらにキューブを使いやすくするための機能について学んでいきます。
では、早速はじめましょう。
前回までの作業で作成した HomeD ディメンジョンに階層となるレベルを追加します。3回目の記事で BirthD ディメンジョンで体験したドリルダウン・ドリルアップの機能を使えるようにするものです。
キューブを変更しますので、アーキテクト画面に行き、Tutorial キューブを開きます。開いたら、画面左側のクラス・ビューワで HomeCity を展開します。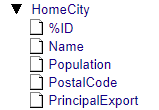
HomeCity の配下にある PostalCode を追加します。HomeD ディメンジョンの H1 階層の上にドラッグ&ドロップします。
そうしますと、PostalCode がレベルとして追加されます。「level 2」となっていますね。
レベル名を ZIP Code に変更します。詳細ペインのところで書き換えてください。
書き換えたら、キューブをコンパイルします。画面上部の [コンパイル] ボタンから実行します。
コンパイルが完了したら、続いてビルドを行います。
インターシステムズでは、すべてにおいて最高の品質を提供するよう努めています。グローバル・マスターズ・プログラムの実現もその一つです。
このプラットフォームのベンダーが他社に買収され、残念ながら、グローバル・マスターズ・プログラムをこのプラットフォームでサービスし続けることができなくなりました。現在、グローバル・マスターズ・アドボケート・ハブの移行を行うべく、新しいプラットフォーム・プロバイダーを評価中です。

連続3回のシリーズでお届けする新機能についてのウェビナー、第二弾はベクトル検索です。
セッション概要:IRIS 2024.1の実験的機能として、ベクトル検索が実装されました。この機能により、ベクトル型が新たにサポートされ、ドキュメントの類似検索などが可能になります。また、大規模言語モデル(LLM)や生成AIと組み合わせて、最先端のアプリケーション開発を強力に支援します。本ウェビナーでは、ベクトル検索の概要について解説します。
ウェビナーの前に少し内容を確認されたい方は、開発者コミュニティの記事「Vector Search (ベクトル検索) をご紹介します」をぜひご参照ください。
こんな方にお勧め:
・ 文書検索に興味のある方
・ 大規模言語モデルや生成AIの活用を検討されている方
ご多用中とは存じますが、皆様のご参加をお待ち申し上げております。
VS Code を使ってコードを編集する場合、設定モデルでは、ワークスペースルートフォルダの .vscode サブフォルダにある settings.json ファイルを使用して、一部の設定にフォルダ固有の値を指定できます。 ワークスペースのルートフォルダ内で作業している場合、ここで設定した値は個人設定の値よりも優先されます。
isfs-type ワークスペースを使用してサーバー上のネームスペースで直接操作している場合は、現在および将来のネームスペースごとに特別な .vscode フォルダをサポートするようにそのサーバーを構成しておく必要があります。 このフォルダはフォルダ固有のコードスニペットとデバッグ起動構成も提供できます。
この機能をセットアップしておくと、設定(またはスニペット、またはデバッグ構成)をサーバーに配置することで、そのサーバーで作業するすべての VS Code ユーザーがすぐにそれを使用できるようになるというメリットがあります。
たとえば、Deltanji ソース管理は、機能拡張を使って VS Code に統合されます。 サーバー側の設定ストレージを使用すれば、結果が設定に依存する場合に、特定のネームスペースに接続するすべての開発者が Deltanji 拡張機能から同じ結果を得ることができるようになります。
サーバーがネームスペースごとに .
我々には、Redditユーザーが書いた、おいしいレシピデータセット がありますが, 情報のほとんどは投稿されたタイトルや説明といったフリーテキストです。埋め込みPythonやLangchainフレームワークにあるOpenAIの大規模言語モデルの機能を使い、このデータセットを簡単にロードし、特徴を抽出、分析する方法を紹介しましょう。
まず最初に、データセットをロードするかデータセットに接続する必要があります。
これを実現するにはさまざまな方法があります。たとえばCSVレコードマッパーを相互運用性プロダクションで使用したり csvgenのようなすばらしい OpenExchange アプリケーションを使用することもできます。
今回、外部テーブルを使用します。これは物理的に別の場所に保存されているデータをIRIS SQLで統合する非常に便利な機能です。
まずは外部サーバ(Foreign Server)を作成します。
CREATE FOREIGN SERVER dataset FOREIGN DATA WRAPPER CSV HOST '/app/data/'
その上でCSVファイルに接続する外部テーブルを作成します。
CREATE FOREIGN TABLE dataset.Recipes (
CREATEDDATE DATE,
NUMCOMMENTS INTEGER,
TITLE VARCHAR,
USERNAME VARCHAR,
COMMENT VARCHAR,
NUMCHAR INTEGER
) SERVER dataset FILE 'Recipes.csv' USING
{
"from": {
"file": {
"skip": 1
}
}
}
IRIS BIチュートリアル試してみたシリーズの5回目です。
今回も、前回同様チュートリアルの「キューブの作成」ページになります。
前回はキューブを作成し、そのキューブを使用していくつかのピボットテーブルを作成しました。
その中で気になった点を今回は修正していきます。では、はじめていきましょう。
前回の作業の中で、ピボットテーブル作成時に気になった点は以下のものがありました。
では、これらを解消していきましょう。アーキテクト画面で Tutorial キューブを開きます。
キューブが開いたら、 Age レベルをクリックし、続いて [要素を追加] をクリックします。
要素名に AgeSort と入力し、要素選択は プロパティ を指定します。
AgeSort プロパティができました。
では、AgeSort プロパティの詳細設定を変えます。詳細ペインの [表現] に以下の式を設定します。
$CASE$LENGTH%source.AgeAgeが1ケタの場合は、頭にゼロを付けるという式ですね。
InterSystems IRIS 2024.2 と InterSystems IRIS for Health 2024.2 の最初の開発者プレビューが WRC プレビューダウンロードページ に公開されました。このプレビューではコンテナ版は準備できていませんが、次回にはコンテナ版も公開する予定です。
今回のリリースは、これまで公開してきた開発者プレビュー版の中で一番早いリリースサイクルになります。それもあり、「本リリースの注目点」と呼べる機能はまだありません。今後のプレビューリリースで機能一覧の準備が整い次第、すぐにお伝えいたします。
ドキュメントは以下のリンクからご覧いただけます。
本リリースでは、すべてのサポート対象プラットフォーム向けに、従来のインストーラ形式を提供します。サポート対象プラットフォーム一覧は、こちらのドキュメント をご覧ください。
インストーラとプレビュー用ライセンスキーは、WRC プレビューダウンロードページ もしくは 評価サービスページ ("Show Preview Software" フラグをチェックしてください) から入手いただけます。
IRIS BIチュートリアル試してみたシリーズの4回目です。
今回からはチュートリアルの3ページ目、「キューブの作成」に沿って進めていきます。
では、早速はじめていきたいと思います。
キューブの作成はアーキテクト画面から行います。
管理ポータル画面のメニューで、 Analytics → アーキテクト を選択します。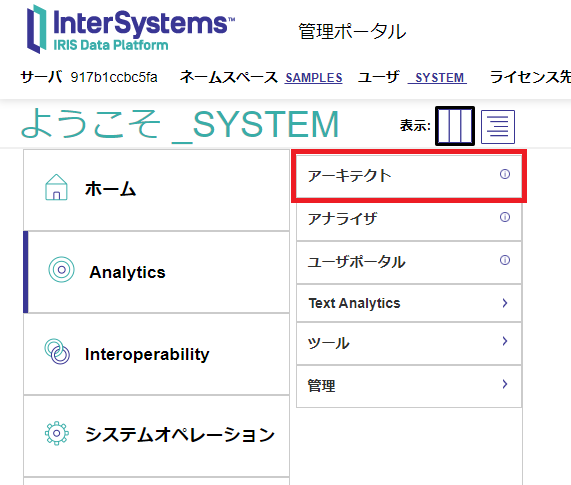
アーキテクト画面が開きました。1回目の記事の作業のときに Patientsキューブを開いたので、私の環境では再びPatientsキューブが表示されました。
新しいキューブを作成しますので、[新規] ボタンをクリックします。
ダイアログが開いたら、以下のように指定していきます。
ソースクラスの指定は、[参照] ボタンを押してダイアログから行うこともできます。
最後に [OK] をクリックしますと、まっさらな画面が表示されます。
もし、以下のようなダイアログが表示されたら、[Leave] を選択してください。
アーキテクト画面ですが、3つのエリアで構成されています。左側から順に、クラス・ビューワ、モデル・ビューワ、詳細ペインです。
開発者の皆さん、こんにちは!
(2024.4.17更新:コンテストタイトルに「ベクトル検索」を追加しました)
次の InterSystems オンラインプログラミングコンテストのテーマが決定しました!👉生成 AI、ベクトル検索、機械学習 です!
🏆 InterSystems ベクトル検索、GenAI、ML コンテスト(USコミュニティ) 🏆
期間: 2024年4月22日~5月19日
賞金総額: $14,000
.jpg)
開発者の皆さん、こんにちは。
こちらの記事👉「Apache Webサーバ(プライベートWebサーバ: PWS)インストレーションの廃止」でご案内していましたが、コミュニティエディションを除くInterSystems製品のバージョン2023.2以降では、プライベートWebサーバ(*)を使用した管理ポータル/Webアクセスを非推奨に変更しました。
(*)プライベートWebサーバとは、バージョン2023.1以前のInterSystems製品をインストールすると自動でインストールされる簡易的なApacheで、52773番ポートで管理ポータルやWebアクセスのテストにご利用いただけるWebサーバです。(本番運用環境には適さない簡易的なWebサーバです)
新規インストール/アップグレードインストールによるプライベートWebサーバの利用可否やインストール時の選択項目の違いについての概要は以下表をご参照ください。

人工知能は、命令によってテキストから画像を生成したり、単純な指示によって物語を差作成したりすることだけに限られていません。
多様な写真を作成したり、既存の写真に特殊な背景を含めたりすることもできます。
また、話者の言語や速度に関係なく、音声のトランスクリプションを取得することも可能です。
では、ファイル管理の仕組みを調べてみましょう。
みなさんこんにちは! 今回は、IRIS 2024.1で実験的機能として実装されたVector Search (ベクトル検索)について紹介します。ベクトル検索は、先日リリースされたIRIS 2024.1の早期アクセスプログラム(EAP)で使用できます。IRIS 2024.1については、こちらの記事をご覧ください。
ChatGPTをきっかけに、大規模言語モデル(LLM)や生成AIに興味を持たれている方が増えていると思います。開発者の方々の中には、中はどうなっているのか気になっている方も多いのではないでしょうか。実は、LLMや生成AIの仕組みを理解したいと思えば、ベクトルの理解は不可欠な要素となります。
ベクトルは、高校の数学で習う「あの」ベクトルのことです。が、今回は、複数の数値をまとめて扱うデータ型であるという理解で十分です。例えば、
( 1.2, -4.5 )
という感じです。この例は、1.2と-4.5という2つの数値をまとめており、数値の個数(ここでは2)のことを次元数と言います。我々の生きている場所を3次元空間と呼ぶことがありますが、これは、3つの数値で場所が特定できることを表しています(例えば、緯度、経度、標高の3つで地球上の位置を完全に特定できます)。
IRIS BIチュートリアル試してみたシリーズの3回目です。
チュートリアルの「キューブ要素の概要」ページの続きを行います。
前回同様、アナライザを操作しながらキューブの要素について説明していきます。
では、早速はじめていきましょう。
Allメンバとは、ディメンジョンの中の特殊なメンバ、とでも言えばよいでしょうか。
チュートリアルでは
「All メンバは、ベース・クラスの全レコードを参照します。」
と表現しています。分かったような、分からないような。。
実際に使ってみて、どのようなものか理解を深めましょう。
Patientsキューブでは、AgeD ディメンジョンの中に All Patients という名前で作成されています。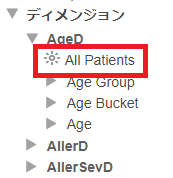
画面左上の [新規] ボタンをクリックして、新しいピボットテーブルを作成します。
AgeD ディメンジョンの Age Group レベルを [行] に指定し、メジャーの Patient Count、Avg Age、Avg Test Score を [メジャー]に指定します。
※注意:サンプルデータはランダムに作成されるため、こちらの画面表示とみなさまの実行結果は一致しないことがあります。
では、この状態でピボット・オプション・ボタンをクリックします。画面上側にある、スパナのイラストのアイコンです。
![]()
皆さんもご存知のように、人工知能の世界はもう生活の中に存在しており、誰もが利用従っています。
多数のプラットフォームが、無料、サブスクリプション、または非公開の形式で、人工知能サービスを提供していますが、 コンピューティングの世界で「話題」となったことから、特に注目されているサービスは OpenAI です。最も有名な ChatGPT および DALL-E が主な原因と言えます。
ここで、明白に進化をみることができます! GPT-3(2020 年)は、達成したいことを示した十分な入力を使ってトレーニングする必要がありましたが、現行の GPT-4 バージョンでは自然言語を使用することができるため、入力をより簡単に提供することができます。 これで、命令の意図を理解するだけでなく、それ自体が話している内容を理解している「ように見えます」。
現在は、Gary Marcus が 2020 年に GPT-2 用に作成した同じ例を使用した場合、期待どおりの結果を得られます。
OpenAI は現在、驚くほどの速さで大幅に進化した一連のツールを提供しており、適切に組み合わせれば、以前よりも効率的な結果をはるかに簡単に得ることができます。
これは InterSystems FAQ サイトの記事です。
Caché 2016.2以降(IRISはすべてのバージョン)で、クエリプランの凍結機能 が実装されました。
この機能により、メジャーバージョンのアップグレードを行った場合、既存のクエリプランは自動的に凍結(※)されます。
※2023.1以降のバージョンより、アダプティブモードが無効の場合のみ、クエリプランが自動的に凍結されます。有効の場合は、既存のクエリプランは無効になり、新しいシステムでクエリの最初の実行時に新しい最適化されたクエリプランを生成します。既定は有効です。
こちらのトピックでは、
「新しいバージョンにしたのに、一部のクエリで思うようなパフォーマンスが出ない」
「凍結プランが使用されている場合、新しいプランでパフォーマンスがどのくらいでるのかを知りたい」
という場合の確認手順について、ご説明します。
Frozen Plan (古いバージョンと同じプラン)を使用していて思ったようなパフォーマンスが出ない場合、凍結を解除して新しいプランを試すことが可能です。
新しいプランを試したい場合は、%NOFPLANキーワードをつけてクエリを実行します。
%NOFPLANを付けた方がパフォーマンスが良ければ、プラン凍結を解除して新しいプランで実行するようにします。
インターシステムズがこの機能を導入したのは何年も前のことであり、公開鍵インフラストラクチャの利用がまだ広まっていなかった時代でした。
現在では、公開鍵インフラストラクチャを使用するための資料を作成することが広く利用できるようになり、インターシステムズ PKI の使用が減少しています。さらにインターシステムズ PKIを安全に使用するためには投資が必要となります。
IRIS PKI のドキュメントには以前より以下を記載しております。
InterSystems PKI はテスト目的のみで本番環境では使用しないで下さい。
2024 年 3 月 26 日をもって、InterSystems PKI は非推奨としました。
製品ドキュメントは更新され、以下のように記載されます。
InterSystems PKI の実装は非推奨です。将来のバージョンの InterSystems 製品から
この機能は削除される可能性があります。
このドキュメントは、 既存のユーザのための参考資料としてのみ提供されます。
インターシステムズは、ユーザが PKI 機能の使用を中止することを推奨します。



