新着
INTRO
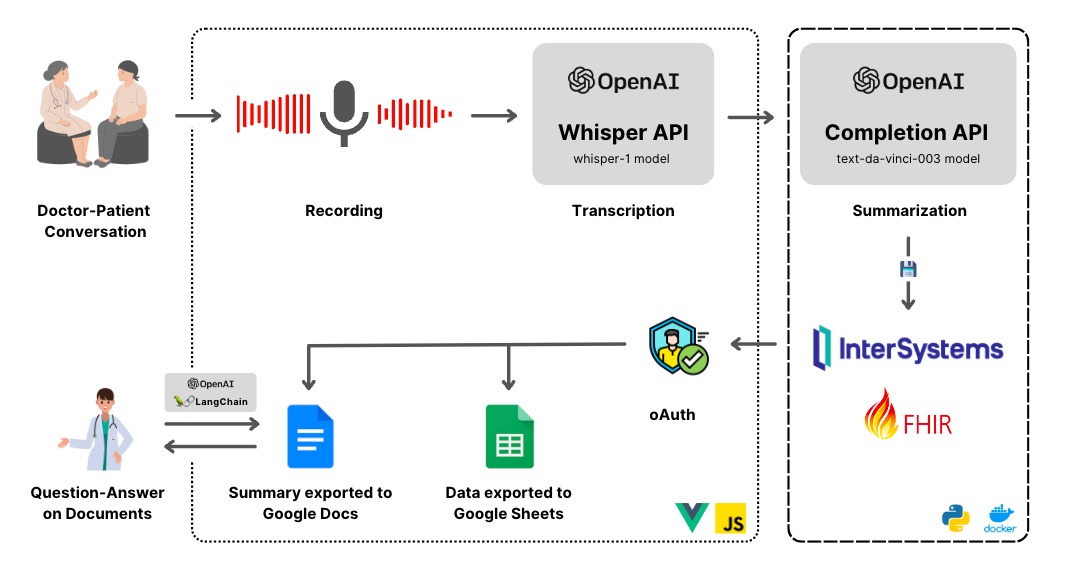
Barricadeは、InterSystems OMOP向けのFHIRからOMOPへの変換を効率化し、そのサポートをスケールアップするために、ICCA Opsが開発したツールです。当社のクライアントは、InterSystems OMOPを使用してFHIRデータをこのOMOP形式に変換することになります。マネージドサービスとして、当社の役割は変換プロセスに伴うあらゆる問題のトラブルシューティングを行うことです。Barricadeは、さまざまな理由から、このプロセスを支援する理想的なツールです。第一に、効果的なサポートには、FHIR標準、OHDSI OMOPモデル、そしてInterSystems特有の運用ワークフローにわたる専門知識が必要ですが、これらはすべて高度に専門化された分野です。Barricadeは、大規模言語モデルを活用してFHIRやOHDSIに関する専門知識を提供することで、知識のギャップを埋めるお手伝いをします。さらに、特定の変換問題を解決するために詳細な説明が行われたとしても、その知識はメールやチャットの中に埋もれてしまい、将来的に活用できなくなることがよくあります。Barricadeなら、その知識を収集・再利用し、類似のケースにスケールさせることも可能です。最後に、多くの場合、ソースデータにアクセスできません。



.png)

.jpg)


.jpg)