IRIS と Python でチャットボットを作成する
IRIS と Python でチャットボットを作成する
この記事では、InterSystems IRIS データベースを Python と統合して自然言語処理(NLP)の機械学習モデルを提供する方法を説明します。
Python を使用する理由
世界的に広く採用され使用されている Python には素晴らしいコミュニティがあり、様々なアプリケーションをデプロイするためのアクセラレータ/ライブラリが豊富に提供されています。 関心のある方は https://www.python.org/about/apps/ をご覧ください。
IRIS のグローバル
^globals について学び始めると、型にはまらないデータモデルに素早くデータを取り込む手法として使用することに慣れてきました。 そのため、最初は ^globals を使用してトレーニングデータと会話を保存し、チャットボットの動作をログに記録することにします。
自然言語処理
自然言語処理(NLP)は、人間の言語から意味を読み取って理解する能力を機械に与える AI のテーマです。 ご想像のとおりあまり単純ではありませんが、この広大で魅力的な分野で最初の一歩を踏み出す方法を説明します。
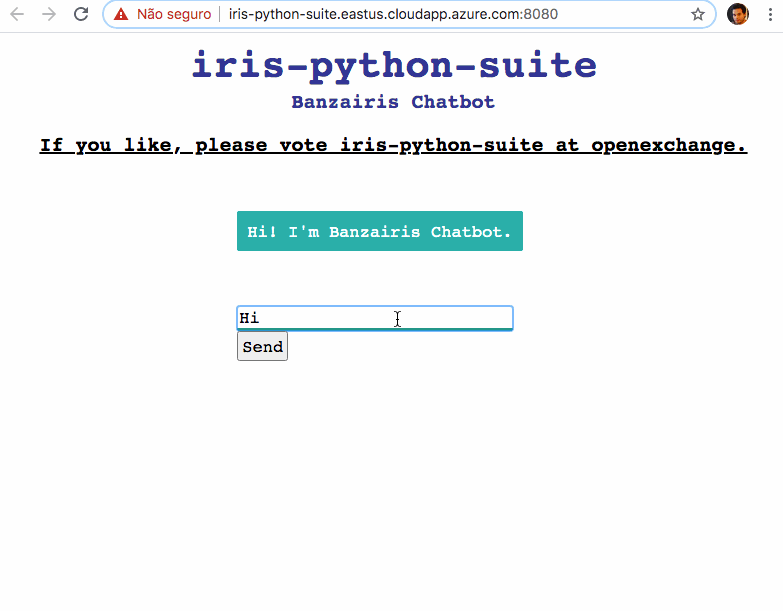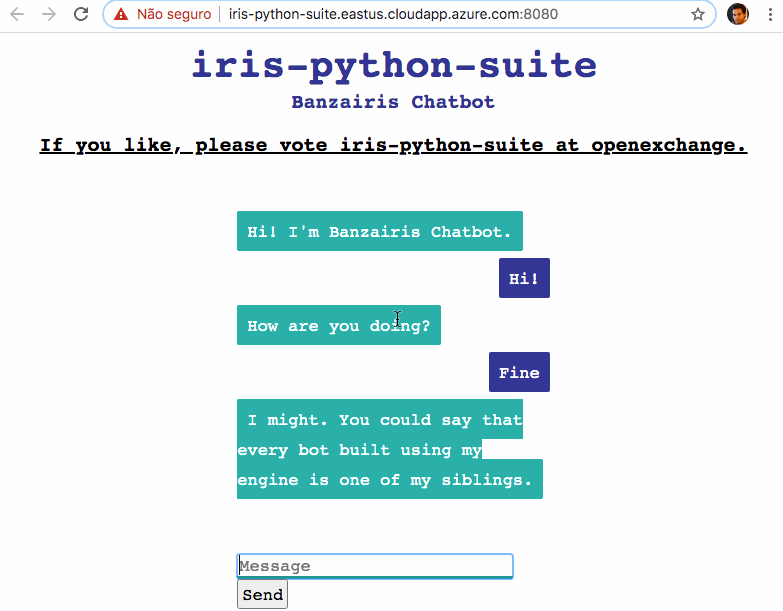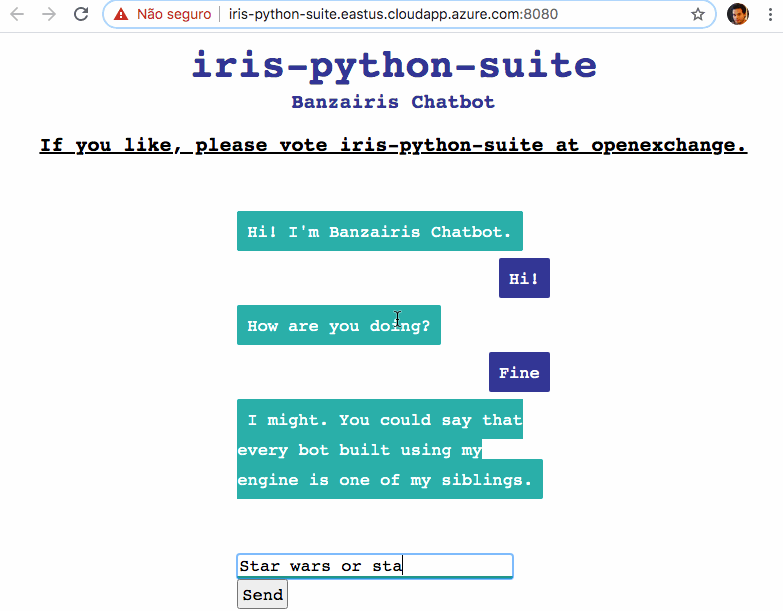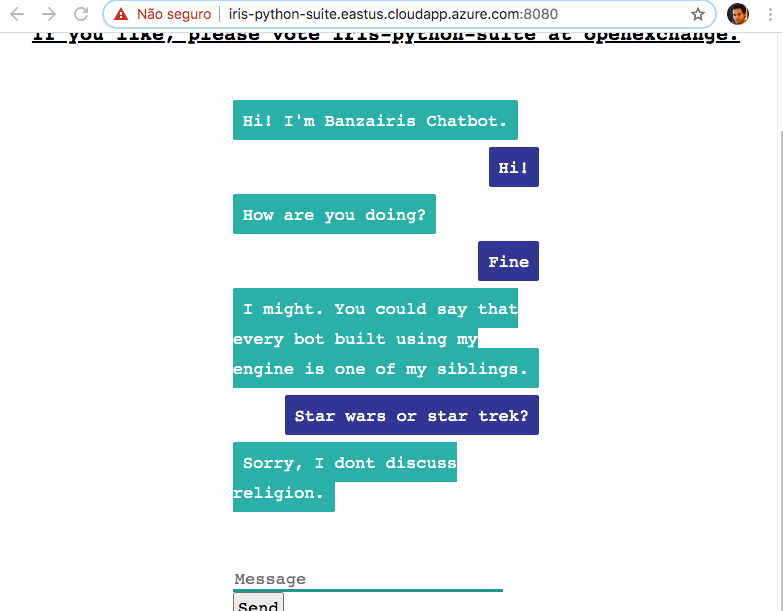
デモ - 試してみましょう
チャットボットアプリケーションをデモとしてデプロイしています: http://iris-python-suite.eastus.cloudapp.azure.com:8080
どのように動作しますか?
機械学習
まず、機械学習には、一般的なソフトウェア開発とは異なるパラダイムがあることを知っておきましょう。 分かりにくい要点は、機械学習モデルの開発サイクルです。
完全な説明ではありません
標準的なアプリケーション開発サイクルは次のようになっています。
コードの開発 -> テスト(開発データを使用)-> デプロイ(実際のデータを使用)
そして、機械学習では、コード自体に同じ価値がありません。 責任はデータと共有されています! つまり、データがなければ、実際のデータもないということです。 これは、実行される最終的なコードは、開発コンセプトと使用されるデータのマージによって生成されるためです。 したがって、機械学習アプリケーションのサイクルは次のようになっています。
モデルの開発(トレーニング)と実データ -> 検証 -> この結果(モデル)をデプロイ
モデルをトレーニングするには
モデルをトレーニングするにはたくさんの手法があり、それぞれのケースと目的には大きな学習曲線が伴います。 ここでは、いくつかの手法をカプセル化して、トレーニング方法と事前処理済みのトレーニングデータを提供する ChatterBot ライブラリを使用し、結果に焦点を当てやすくしています。
事前学習のモデル言語とカスタムモデル
基本的な会話型チャットボットを作成するにはこれを使用することができます。 チャットボットをトレーニングするためのすべてのデータがニーズを完全に満たすように作成することもできますが、短時間で作成するのは困難です。 このプロジェクトでは、会話のベースとして en_core_web_sm を使用し、フォームを使って作成できるカスタムトレーニングデータとマージします。
基本アーキテクチャ
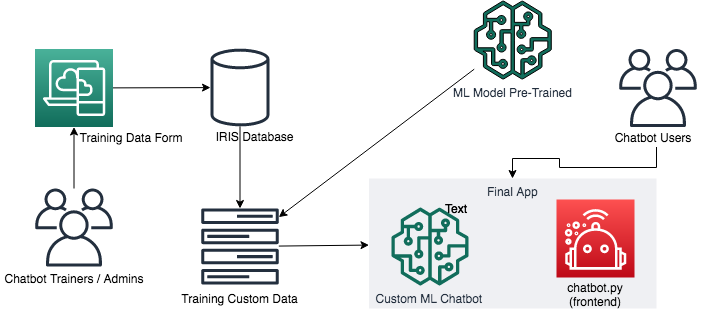
Python で使用したもの
このアプリケーション環境では、Python 3.7 と以下のモジュールを使用します。
- PyYAML<=5.0.0 - dash==1.12.0 - dash-bootstrap-components==0.10.1 - dash-core-components==1.10.0 - dash-html-components==1.0.3 - dash-renderer==1.4.1 - dash-table==4.7.0 - plotly==4.7.1 - numpy==1.18.4 - networkx==2.4 - Flask>=1.0.0
- chatterbot>=1.0.0
- chatterbot-corpus>=1.2.0
- SQLAlchemy>=1.2
- ./nativeAPI_wheel/irisnative-1.0.0-cp34-abi3-linux_x86_64.whl
プロジェクト構造
このプロジェクトは理解しやすい単純な構造になっています。 メインのフォルダには、最も重要な 3 つのサブフォルダがあります。
- ./app: すべてのアプリケーションコードとインストール構成が含まれます。
- ./iris: アプリケーションをサービングする InterSystems IRIS dockerfile が含まれます。
- ./data: ボリュームによってホストをコンテナー環境にリンクします。
アプリケーション構造
./app ディレクトリには、以下のファイルが含まれます。
- chatbot.py: Web アプリケーションの実装が含まれます。
- iris_python_suite.py: IRIS Native API によって IRIS データベースや Python と使用する、アクセラレータを持つクラスです。
データベース構造
このアプリケーションでは、InterSystems IRIS をリポジトリとして使用します。使用されるグローバルは以下のとおりです。
- ^chatbot.training.data: 質疑応答の形式で、すべてのカスタムトレーニングデータを保存します。
- ^chatbot.conversation: すべての会話ペイロードを保存します。
- ^chatbot.training.isupdated: トレーニングパイプラインを制御します。
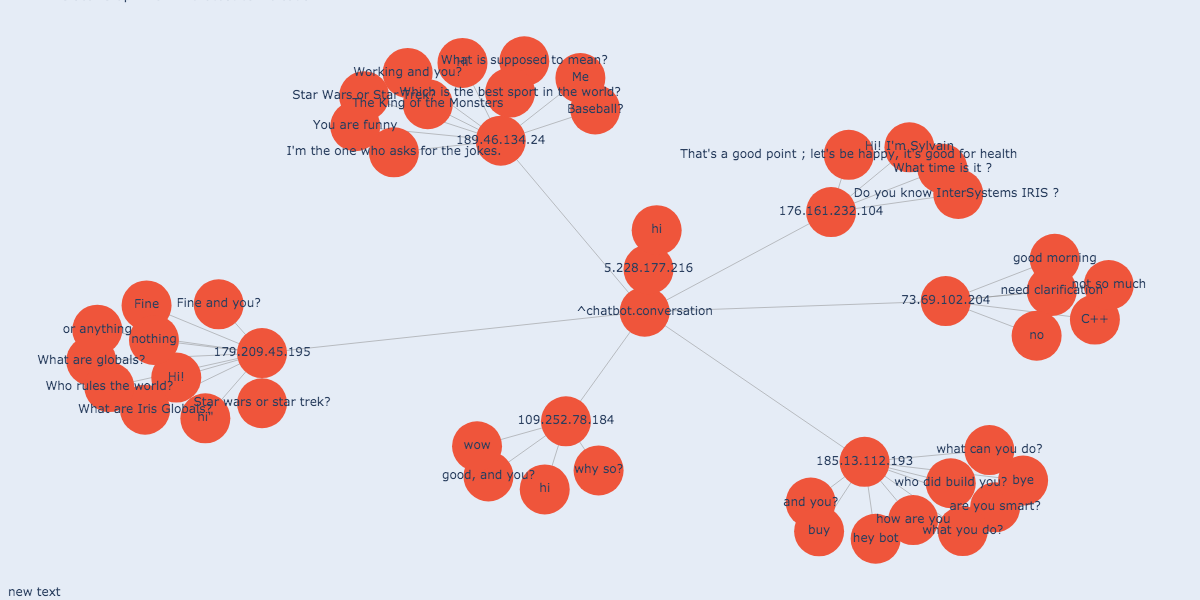
ほかのソリューションの製品
全会話のレポートは作成しませんでしたが、私のグローバルグラフビューアを使用すれば、問題なく会話を追跡することができます。
自分でアプリケーションを実行する
前提条件
- git
- docker と docker-compose(docker のメモリ設定を 4 GB 以上に増加してください)
- 環境のターミナルへのアクセス
手順
docker-compose を使って、すべてのピースと構成を備えた 1 つの環境を簡単に起動できます。iris-python-covid19 フォルダに移動し、次のように入力します。
$ docker compose build
$ docker compose up
コンテナの推定起動時間
初回実行時は、画像や依存関係をダウンロードするためのインターネット接続に依存します。 15 分以上かかる場合は、おそらく何らかの問題が発生しているので、こちらにご連絡ください。 2 回目以降はパフォーマンスが向上し、2 分もかかりません。
すべてが万全である場合
しばらくしたら、ブラウザを開いて次のアドレスに移動します。
トレーニングデータのフォーム
http://localhost:8050/chatbot-training-data
チャットボット
http://localhost:8080
IRIS 管理ポータルの確認
この時点では、USER ネームスペースを使用しています。
http://localhost:9092
user: _SYSTEM
pass: theansweris42
この記事が役に立った場合、またはコンテンツを気に入った場合は、投票してください。
このアプリケーションは、Open Exchange コンテストに現在参加中です。こちら(https://openexchange.intersystems.com/contest/current)から私のアプリケーション「iris-python-suite」に投票してください。