AI による臨床文書の保管、取得、検索の単純化
問題
あわただしい臨床環境では迅速な意思決定が重要であるため、文書保管とシステムへのアクセスが合理化されていなければいくつもの障害を生み出します。 文書の保管ソリューションは存在しますが(FHIR など)、それらの文書内で特定の患者データに有意にアクセスして効果的に検索するのは、重大な課題となる可能性があります。
動機
AI により、文書の検索が非常に強力になりました。 Chroma や Langchain のようなオープンソースツールを使用して、ベクトル埋め込みを保存して使用し、生成 AI API 全体でクエリを実行することで、ドキュメント上での質疑応答がかつてないほど簡単になっています。 より献身的に取り組む組織は、既存のドキュメントにインデックスを作成し、エンタープライズ用に微調整されたバージョンの GPT を構築しています。 GPT の現状に関する Andrej Karpathy の講演では、このトピックに関する素晴らしい概要が提供されています。
このプロジェクトは、医療関係者が文書を操作するあらゆるタッチポイントにおいて発生する摩擦を緩和する試みです。 医療関係者が情報を保管し、必要な情報を難なく検索できるように、入力と処理から保管と検索まで、IRIS FHIR と AI を活用しました。
ソリューション
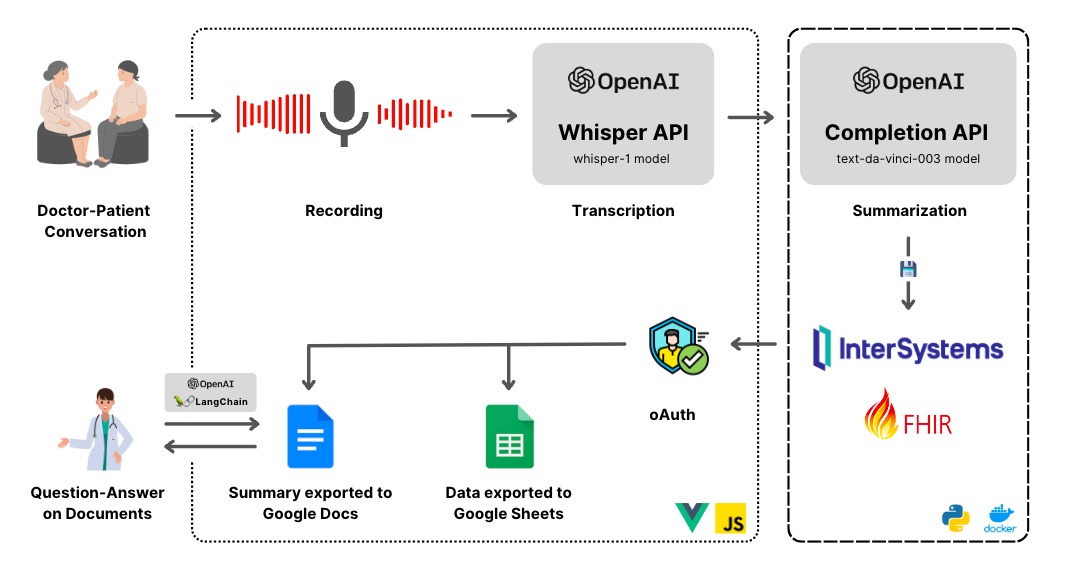
医療関係者が音声メモを記録できるフルスタックのウェブアプリを構築しました。 これらのメモは、Open AI を使って文字起こしされ、要約されてから FHIR サーバーに保管されます。 保管されたドキュメントは、インデックス作成されてから、セマンティック検索で使用できるようになります。
デモ動画
主な機能
- ウェブアプリ - 患者、観察、遭遇に関する診療情報を表示します。 これは Vue.js で構築されています。
- 音声データの文字起こし - Open AI Whisper API を使って、録音を正確なテキストに文字起こしします。
- テキストの要約 - 文字起こしされた内容を必要なフォーマットで要約してタイトルが付けられます。 症状、診断などの具体的なセクションなどです。 これは、text-da-vinci-003 を使った Open AI テキスト補完 API で行われます。
- ドキュメントの保管 - 要約されたドキュメントは、DocumentReference アーティファクトを使って FHIR に保管されます。
- セマンティックドキュメント検索 - 保管されたドキュメントはインデックス作成されて、チャンクとして Chroma に保管されます。 これは、Langchain を使用して検索スペースを制限してセマンティック検索に GPT トークンを控えめに使用するために使用されます。 現時点では、使用できるドキュメント数が少ないため、検索時にドキュメントを読み込んでいますが、 非同期的にバックグラウンドでインデックス作成するように変更することが可能です。
- ドキュメントのエクスポート - 最後に、ドキュメントを Google Docs に、その他のデータを Google Sheets にエクスポートするオプションがあります。 ユーザーは他の医療関係者や患者とのコラボレーションとやり取りを簡単に行えるように、OAuth を使って特定のアカウントにログインし、ドキュメントをエクスポートすることができます。
試してみましょう
次の GitHub リンクからプロジェクトリポジトリをクローンします:
ご意見とフィードバック
現在使用できる高度言語モデルと大量のデータを合わせることで、ヘルスケア分野の特に文書管理の領域に革命を起こす大きな可能性があります。 以下に、ご意見やフィードバックをお寄せください。 このプロジェクトの背後にある技術的な情報について、さらに多くの記事を投稿する予定です。
このプロジェクトに期待できると思われる場合は、Grand Prix コンテストでこのアプリに投票してください!