医師と患者の会話: AI を使用した文字起こしおよび要約
前の記事 - AI による臨床文書の保管、取得、検索の単純化
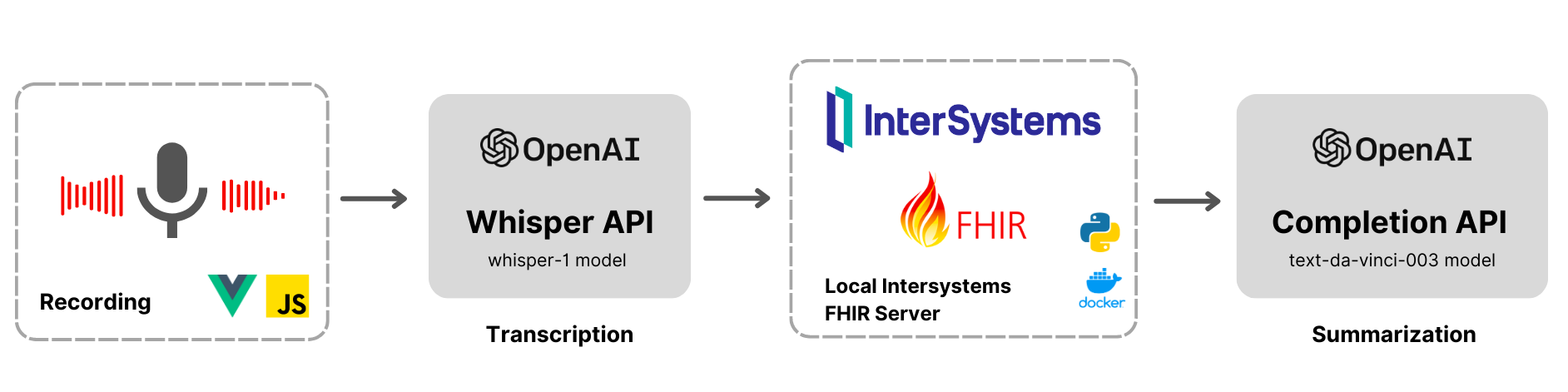
この記事では、AI を使用した文字起こしと要約によってヘルスケアに変革を起こす OpenAI の高度な言語モデルの可能性を探ります。 OpenAPI の最先端 API を活用して、録音データを文字起こしし、自然言語処理アルゴリズムを使って簡潔な要約を生成するための重要なインサイトを抽出するプロセスを掘り下げていきます。
似たような機能は Amazon Medical Transcibe や Medvoice などの既存のソリューションでも提供されていますが、この記事では、OpenAI テクノロジーを使用してこれらの強力な機能を InterSystems FHIR に実装することに焦点を当てています。
Vue.js の録音データ
Vue.js アプリのボイスレコーダーは、完全にネイティブであり、Mediarecorder インターフェースを使って JavaScript で記述されています。 これは、アプリケーションを軽量に維持しながら、録音オプションを完全に制御できるようにすることを目的としています。 以下は、録音入力の開始と停止を行うスニペットです。
// オーディオストリームをチャンクとして保存する録音開始メソッド
async startRecording() {
try {
const stream = await navigator.mediaDevices.getUserMedia({
audio: true,
});
this.mediaRecorder = new MediaRecorder(stream);
this.mediaRecorder.start();
this.mediaRecorder.ondataavailable = (event) => {
this.chunks.push(event.data);
};
this.isRecording = true;
} catch (error) {
console.error("Error starting recording:", error);
}
}
// 停止後にブロブを作成する(そして転写メソッドを呼び出す)録画停止メソッド
stopRecording() {
if (this.mediaRecorder) {
this.isLoading = true;
this.mediaRecorder.stop();
this.mediaRecorder.onstop = async () => {
const blob = new Blob(this.chunks, {
type: "audio/webm;codecs=opus",
});
await this.sendAudioToWhisper(
new File([blob], file${Date.now()}.m4a)
);
this.getSummary(this.transcription);
};
}
}
文字起こしコンポーネント
OpenAI の Whisper モデルを使った音声データの文字起こしには、いくつかの基本コンポーネントが使用されます。 以下のコードスニペットは、文字起こしプロセスに関わるステップを示します。
const apiKey = process.env.OPENAI_API_KEY;
const formData = new FormData();
formData.append("file", blob);
formData.append("model", "whisper-1");
formData.append("response_format", "json");
formData.append("temperature", "0");
formData.append("language", "en");
try {
const response = await fetch(
"https://api.openai.com/v1/audio/transcriptions",
{
method: "POST",
headers: {
Accept: "application/json",
Authorization: Bearer ${apiKey},
},
body: formData,
redirect: "follow",
}
);
const data = await response.json();
if (data.text) {
this.transcription = data.text;
}
} catch (error) {
console.error("Error sending audio to Whisper API:", error);
}
return this.transcription;
- API キー -
OPENAI_API_KEYは、OpenAI API にアクセスするために必要な認証トークンです。 - フォームデータ - 文字起こしされる音声ファイルは、
FormDataオブジェクトに追加されます。 選択されたモデル(whisper-1)、レスポンス形式(json)、体温(``)、および言語(en)などの追加パラメーターも含まれています。 - API リクエスト - OpenAI API エンドポイント
https://api.openai.com/v1/audio/transcriptionsへの POST リクエストには、ヘッダーとフォームデータを含むボディを指定して、fetchメソッドで送信されています。 - レスポンス処理 - API からのレスポンスがキャプチャされ、文字起こしされたテキストが
dataオブジェクトから抽出されます。 文字起こしを変数this.transcriptionに割り当てて、さらに処理するか使用することができます。
要約コンポーネント
以下のコードスニペットは、OpenAI の text-davinci-003 モデルを使用したテキスト要約プロセスに関わる基本コンポーネントを示しています。
response = openai.Completion.create(
model="text-davinci-003",
prompt="Summarize the following text and give title and summary in json format.
Sample output - {"title": "some-title", "summary": "some-summary"}.
Input - "
+ text,
temperature=1,
max_tokens=300,
top_p=1,
frequency_penalty=0,
presence_penalty=1
)
return response["choices"][0]["text"].replace('\n', '')
- モデルの選択 -
modelパラメーターはtext-davinci-003に設定されており、OpenAI のテキスト補完モデルが要約に使用されていることを示します。 - プロンプト - モデルに提供されるプロンプトは、望ましい結果を指定しています。これは入力テキストを要約して JSON 形式でタイトルと要約を返します。 入力テキストは、プロンプトに連結して処理されます。 OpenAI を通じてレスポンス変換を処理できるところに興味深いポイントがあります。 受信側での検証のみで十分であり、将来的にはコンバーターがほとんど必要なくなる可能性があります。
- 生成パラメーター - 生成された要約の動作と品質を制御するために、
temperature、max_tokens、top_p、frequency_penalty、presence_penaltyなどのパラメーターが設定されます。 - API リクエストとレスポンスの処理 - API リクエストを行うために、
openai.Completion.create()メソッドが呼び出されます。 レスポンスがキャプチャされ、生成された要約テキストがレスポンスオブジェクトから抽出されます。 要約テキストに含まれる改行文字(\n)は、最終結果を返す前に取り除かれます。
FHIR のドキュメント参照
OpenAI テクノロジーを使用して医師と患者の会話の文字起こしと要約を実装する文脈においては、FHIR 規格内での診療記録の保管を考慮することが重要です。 FHIR は、診療記録などの医療情報を様々な医療システムやアプリケーション間で交換するための構造化された標準アプローチです。 FHIR の DocumentReference リソースは、診療記録や関連文書を保管するための専用のセクションとして機能します。
文字起こしと要約機能を医師と患者の会話ワークフローに統合する場合、生成される文字起こしと要約は、FHIR Documents リソース内の診療記録として保管できます。 これにより、生成されたインサイトへのアクセス、取得、およびヘルスケアプロバイダーやその他の承認機関の間での共有を簡単に行えます。
{
"resourceType": "Bundle",
"id": "1a3a6eac-182e-11ee-9901-0242ac170002",
"type": "searchset",
"timestamp": "2023-07-01T16:34:36Z",
"total": 1,
"link": [
{
"relation": "self",
"url": "http://localhost:52773/fhir/r4/Patient/1/DocumentReference"
}
],
"entry": [
{
"fullUrl": "http://localhost:52773/fhir/r4/DocumentReference/1921",
"resource": {
"resourceType": "DocumentReference",
"author": [
{
"reference": "Practitioner/3"
}
],
"subject": {
"reference": "Patient/1"
},
"status": "current",
"content": [
{
"attachment": {
"contentType": "application/json",
"data": ""
}
}
],
"id": "1921",
"meta": {
"lastUpdated": "2023-07-01T16:34:33Z",
"versionId": "1"
}
},
"search": {
"mode": "match"
}
}
]
}試してみましょう
- プロジェクトをクローン - 次の GitHub リンクからプロジェクトリポジトリをクローンします:
- ローカルでセットアップ - 提供された指示に従って、プロジェクトをローカルマシン上にセットアップします。 セットアップ中に問題が発生した場合は、お知らせください。
- 患者を選択 - プロジェクト内の提供されたサンプルリストから患者を選択します。 この患者は、文字起こしと要約に使用される医師と患者の会話と関連付けられます。
- 対話ページ - 患者が選択されたら、プロジェクト内の対話ページに移動します。 このページで、「Take Notes」オプションを見つけてクリックし、医師と患者の会話の文字起こしプロセスを開始します。
- 文字起こしの表示と編集 - 文字起こしプロセスが完了したら、生成された文字起こしを表示するオプションが表示されます。 さらに整理してわかりやすくするために、文字起こしに関連付けられたタイトルと要約を編集することもできます。
- FHIR DocumentReference に保存 - タイトルと要約の処理が完了し、変更を保存すると、FHIR DocumentReference 内に自動的に保管されます。 これにより、関連する診療記録がキャプチャされ、それぞれの患者の記録に確実に関連付けられます。 現時点では、このプロジェクトは文字起こしテキスト全体を保存しませんが、 完全な文字起こしの補完を含めるように変更することもできます。
デモ
アプリケーション全体のデモはこちらでご覧ください:
今後の方向性
AI を活用した文字起こしと要約の応用を遠隔医療通信に拡大することには、計り知れない可能性が秘められています。 これらの機能を Zoom、Teams、Google Meet などの一般的な会議プラットフォームに統合することで、医師と患者のリモート対話を合理化できる可能性があります。 遠隔医療セッションの自動文字起こしと要約機能には、正確な文書作成や分析の強化といったメリットがあります。 ただし、データプライバシーが重大な課題として残されます。 これに対応するためには、外部サーバーにデータを送信する前に、個人を特定できる情報(PII)をフィルターまたは匿名化する対策を実装する必要があります。
今後の方向性としては、ローカルで処理するためのオンデバイス AI モデルの調査、多言語コミュニケーションのサポートの改善、プライバシー維持した手法の進歩が挙げられます。
有用な実装だと思われた方は、Grand Prix 2023 でこのアプリに投票してください。