レシピデータセットを外部テーブルで読み込み、組み込みPythonでLLMを使って分析する (Langchain + OpenAI)
我々には、Redditユーザーが書いた、おいしいレシピデータセット がありますが, 情報のほとんどは投稿されたタイトルや説明といったフリーテキストです。埋め込みPythonやLangchainフレームワークにあるOpenAIの大規模言語モデルの機能を使い、このデータセットを簡単にロードし、特徴を抽出、分析する方法を紹介しましょう。
データセットのロード
まず最初に、データセットをロードするかデータセットに接続する必要があります。
これを実現するにはさまざまな方法があります。たとえばCSVレコードマッパーを相互運用性プロダクションで使用したり csvgenのようなすばらしい OpenExchange アプリケーションを使用することもできます。
今回、外部テーブルを使用します。これは物理的に別の場所に保存されているデータをIRIS SQLで統合する非常に便利な機能です。
まずは外部サーバ(Foreign Server)を作成します。
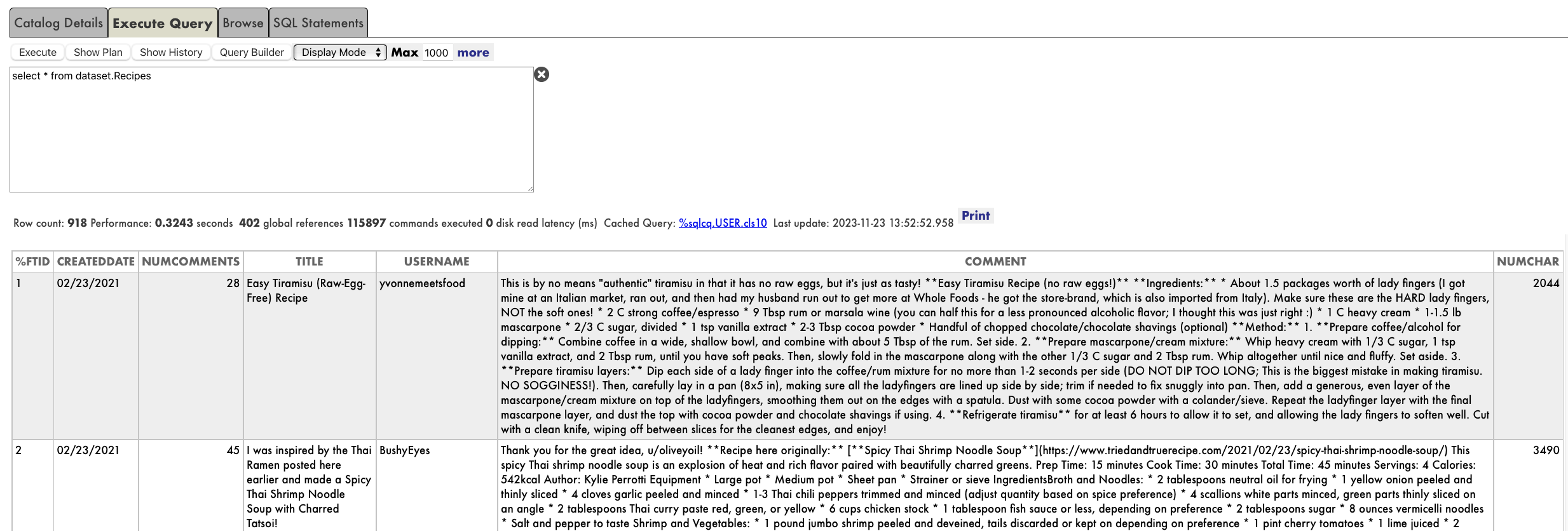
CREATE FOREIGN SERVER dataset FOREIGN DATA WRAPPER CSV HOST '/app/data/'
その上でCSVファイルに接続する外部テーブルを作成します。
CREATE FOREIGN TABLE dataset.Recipes (
CREATEDDATE DATE,
NUMCOMMENTS INTEGER,
TITLE VARCHAR,
USERNAME VARCHAR,
COMMENT VARCHAR,
NUMCHAR INTEGER
) SERVER dataset FILE 'Recipes.csv' USING
{
"from": {
"file": {
"skip": 1
}
}
}
以上です。すぐに「dataset.Recipes」にSQLクエリを実行できます。
## どんなデータが必要?
データセットは興味深く、直ぐに処理したいと思うのですが、調理のレシピを決めたいのであれば、分析に使える情報がもう少し必要です。 2つの永続化クラス(テーブル)を使用します。
- yummy.data.Recipe 抽出、分析したいレシピのタイトルと説明、他のプロパティが入ったクラス (例: スコア、難易度、材料、調理タイプ、準備時間)
- yummy.data.RecipeHistory レシピのログを取るためのシンプルなクラス
これで 「yummy.data*」 テーブルにデータセットの内容をロードすることができます。
do ##class(yummy.Utils).LoadDataset()
一見良さそうに見えますが、スコア、難易度、材料、準備時間、調理時間フィールドのデータをどのように生成するのかを見つける必要があります。
## レシピの分析 各レシピのタイトルと説明を処理します
- 難易度, 材料, 調理タイプなどの抽出
- 何を作りたいか決められるよう、基準に基づいて独自のスコアを構築
以下を使用します
- より多くの分析を構築したい場合に再利用できる一般的な分析構造
- yummy.analysis.SimpleOpenAI - 埋め込み Python + Langchain フレームワーク + OpenAI LLM モデルを使った分析。
LLM(大規模言語モデル)は自然言語を処理するための本当に素晴らしいツールです。
LangChainはPythonで動くようになっているので、Embedded Pythonを使ってInterSystems IRISで直接使うことができます。 LangChain is ready to work in Python, so we can use it directly in InterSystems IRIS using Embedded Python.
完全な SimpleOpenAI クラスは以下のようになります。
/// レシピ向けのシンプルな OpenAI 分析
Class yummy.analysis.SimpleOpenAI Extends Analysis
{
Property CuisineType As %String;
Property PreparationTime As %Integer;
Property Difficulty As %String;
Property Ingredients As %String;
/// 実行
/// ターミナルから実行できます。
/// set a = ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(8))
/// do a.Run()
/// zwrite a
Method Run()
{
try {
do ..RunPythonAnalysis()
set reasons = ""
// 好きな調理タイプ
if "spanish,french,portuguese,italian,korean,japanese"[..CuisineType {
set ..Score = ..Score + 2
set reasons = reasons_$lb("It seems to be a "_..CuisineType_" recipe!")
}
// 丸一日調理に費やしたくない :)
if (+..PreparationTime < 120) {
set ..Score = ..Score + 1
set reasons = reasons_$lb("You don't need too much time to prepare it")
}
// 好きな材料ボーナス
set favIngredients = $listbuild("kimchi", "truffle", "squid")
for i=1:1:$listlength(favIngredients) {
set favIngred = $listget(favIngredients, i)
if ..Ingredients[favIngred {
set ..Score = ..Score + 1
set reasons = reasons_$lb("Favourite ingredient found: "_favIngred)
}
}
set ..Reason = $listtostring(reasons, ". ")
} catch ex {
throw ex
}
}
/// 分析結果でレシピを更新する
Method UpdateRecipe()
{
try {
// 親クラスの処理を先に呼び出す
do ##super()
// 個別のOpenAI 解析結果を追加
set ..Recipe.Ingredients = ..Ingredients
set ..Recipe.PreparationTime = ..PreparationTime
set ..Recipe.Difficulty = ..Difficulty
set ..Recipe.CuisineType = ..CuisineType
} catch ex {
throw ex
}
}
/// 埋め込み Python + Langchain で分析を実行
/// do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(8)).RunPythonAnalysis(1)
Method RunPythonAnalysis(debug As %Boolean = 0) [ Language = python ]
{
# load OpenAI APIKEY from env
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv('/app/.env')
# account for deprecation of LLM model
import datetime
current_date = datetime.datetime.now().date()
# date after which the model should be set to "gpt-3.5-turbo"
target_date = datetime.date(2024, 6, 12)
# set the model depending on the current date
if current_date > target_date:
llm_model = "gpt-3.5-turbo"
else:
llm_model = "gpt-3.5-turbo-0301"
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
# init llm model
llm = ChatOpenAI(temperature=0.0, model=llm_model)
# prepare the responses we need
cuisine_type_schema = ResponseSchema(
name="cuisine_type",
description="What is the cuisine type for the recipe? \
Answer in 1 word max in lowercase"
)
preparation_time_schema = ResponseSchema(
name="preparation_time",
description="How much time in minutes do I need to prepare the recipe?\
Anwer with an integer number, or null if unknown",
type="integer",
)
difficulty_schema = ResponseSchema(
name="difficulty",
description="How difficult is this recipe?\
Answer with one of these values: easy, normal, hard, very-hard"
)
ingredients_schema = ResponseSchema(
name="ingredients",
description="Give me a comma separated list of ingredients in lowercase or empty if unknown"
)
response_schemas = [cuisine_type_schema, preparation_time_schema, difficulty_schema, ingredients_schema]
# get format instructions from responses
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
analysis_template = """\
Interprete and evaluate a recipe which title is: {title}
and the description is: {description}
{format_instructions}
"""
prompt = ChatPromptTemplate.from_template(template=analysis_template)
messages = prompt.format_messages(title=self.Recipe.Title, description=self.Recipe.Description, format_instructions=format_instructions)
response = llm(messages)
if debug:
print("======ACTUAL PROMPT")
print(messages[0].content)
print("======RESPONSE")
print(response.content)
# populate analysis with results
output_dict = output_parser.parse(response.content)
self.CuisineType = output_dict['cuisine_type']
self.Difficulty = output_dict['difficulty']
self.Ingredients = output_dict['ingredients']
if type(output_dict['preparation_time']) == int:
self.PreparationTime = output_dict['preparation_time']
return 1
}
}
「RunPythonAnalysis」メソッドがOpenAIが詰め込むところです :) ターミナルから直接実行してレシピを受け取れます。
do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12)).RunPythonAnalysis(1)
以下のような出力を受け取れます。
USER>do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12)).RunPythonAnalysis(1)
======実際の課題
レシピタイトルを解釈、評価: 巻きずし - アラスカロール
説明: 寿司がたべたいのに巻きすがない? 代わりに簡単なバージョンを試してみてください。超簡単なのに、同じようにおいしい!
[Video Recipe](https://www.youtube.com/watch?v=1LJPS1lOHSM)
# 材料
提供量: \~サンドイッチ5枚分
* 米1カップ
* 水 3/4 カップ + 大さじ 2 1/2
* 昆布 小口切り 1枚
* 米酢 大さじ2
* さとう 大さじ1
* 塩 小さじ1
* アボカド 2個
* カニカマ 6個
* 和風マヨ 大さじ2
* サーモン 1/2 ポンド
# レシピ
* 酢飯1合をボウルに入れ、2回以上、または水が透明になるまで米を洗う。炊飯器に米を移し、昆布の小口切り1枚と水3/4カップ+大さじ2と1/2杯を加える。炊飯器の指示に従って炊く。
* 米酢大さじ2、砂糖大さじ1、塩小さじ1を中くらいのボウルに入れる。全体がよく混ざるまで混ぜる。
* 炊き上がったら昆布を取り除き、すぐに酢を入れた中ボウルに米をすべてすくい入れ、飯ベラを使ってよく混ぜる。米をつぶさないように、切るように混ぜること。炊きあがったら、キッチンタオルをかけて室温まで冷ます。
* アボカド1個の上部を切り、アボカドの中央に切り込みを入れ、ナイフに沿って回転させる。次にアボカドを半分ずつ取り、ひねる。その後、ピットのある側を取り、慎重にピットに切り込みを入れ、ひねって取り除く。その後、手で皮をむく。この手順をもう片方のアボカドでも繰り返す。作業スペースを確保するため、作業台を片付けるのを忘れずに。次に、アボカドを下向きに置き、薄くスライスする。スライスしたら、ゆっくりと広げていく。それが終わったら、脇に置いておく。
* カニカマから包みをはずす。カニカマを縦にむいていく。すべてのカニカマを剥いたら、横に回転させながら細かく刻み、和風マヨ(大さじ2)とともにボウルに入れ、全体がよく混ざるまで混ぜる。
* 鋭利なナイフを斜めに入れ、木目に逆らって薄くスライスする。切り口の厚さは好みによる。ただ、すべてのピースが同じような厚さになるようにする。
* 海苔巻きラップを手に取る。キッチンバサミを使い、海苔巻きラップの半分の位置から切り始め、ラップの中心を少し過ぎるまで切る。ラップを垂直に回転させ、作り始める。すし飯を握るために、手に水をつけておく。酢飯を手に取り、海苔巻きの左上の四辺に広げる。次に、右上にサーモンを2切れ並べる。右下にアボカドを2切れのせる。最後に左下にカニサラダを小さじ2杯ほどのせる。次に、右上の四つ角を右下の四つ角に折り込み、さらに左下の四つ角に折り込む。最後に、左上の四つ角をサンドイッチの残りの部分に折り込む。その後、ラップを上に置き、半分に切って、生姜とわさびを2、3枚添えれば出来上がり。
出力は、先頭と末尾の"``json "と"``"を含む、以下のスキーマでフォーマットされたマークダウンのコードスニペットでなければなりません:
json
{
"cuisine_type": string // レシピの調理タイプは? 小文字の1単語で回答
"preparation_time": integer // レシピの準備に必要な時間(分)は? 整数で回答(不明な場合はnull)
"difficulty": string // レシピの難易度は? 「容易」「標準」「難しい」「とても難しい」のうちから1つを回答
"ingredients": string // 小文字のカンマ区切りの材料リスト、不明な場合は空
}
======応答
json
{
"cuisine_type": "japanese",
"preparation_time": 30,
"difficulty": "easy",
"ingredients": "sushi rice, water, konbu, rice vinegar, sugar, salt, avocado, imitation crab sticks, japanese mayo, salmon"
}
良さそうです。OpenAIのプロンプトは有用な情報を返してくれるようです。ターミナルから分析クラス全体を実行してみましょう:
set a = ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12))
do a.Run()
zwrite a
USER>zwrite a
a=37@yummy.analysis.SimpleOpenAI ; <OREF>
+----------------- general information ---------------
| oref value: 37
| class name: yummy.analysis.SimpleOpenAI
| reference count: 2
+----------------- attribute values ------------------
| CuisineType = "japanese"
| Difficulty = "easy"
| Ingredients = "sushi rice, water, konbu, rice vinegar, sugar, salt, avocado, imitation crab sticks, japanese mayo, salmon"
| PreparationTime = 30
| Reason = "It seems to be a japanese recipe!. You don't need too much time to prepare it"
| Score = 3
+----------------- swizzled references ---------------
| i%Recipe = ""
| r%Recipe = "30@yummy.data.Recipe"
+-----------------------------------------------------
## 全レシピを解析する!
当然、読み込んだすべてのレシピで分析を実行したいでしょう。 この方法でレシピ ID の範囲を分析することができます
USER>do ##class(yummy.Utils).AnalyzeRange(1,10)
> Recipe 1 (1.755185s)
> Recipe 2 (2.559526s)
> Recipe 3 (1.556895s)
> Recipe 4 (1.720246s)
> Recipe 5 (1.689123s)
> Recipe 6 (2.404745s)
> Recipe 7 (1.538208s)
> Recipe 8 (1.33001s)
> Recipe 9 (1.49972s)
> Recipe 10 (1.425612s)
その後、レシピテーブルを再度表示させ、結果をチェックします。
select * from yummy_data.Recipe
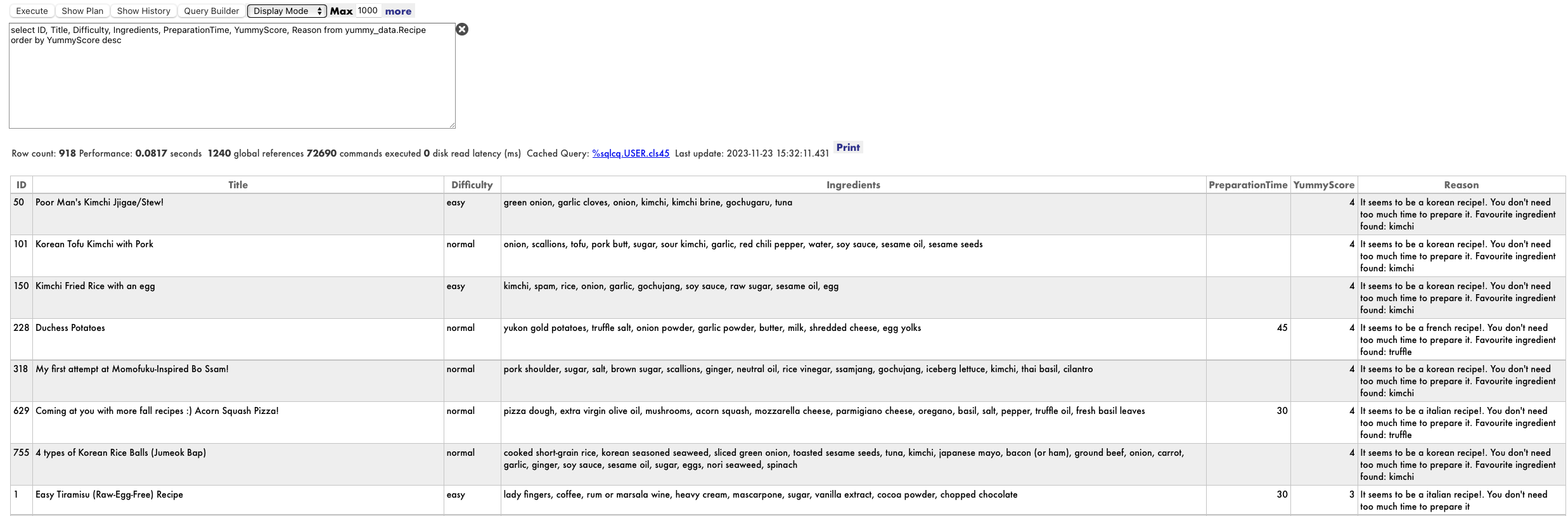
どんぐりカボチャのピザか、豚肉入り韓国風豆腐キムチを試してみます:) いずれにせよ、家で再確認する必要がありますね :)
最後に
サンプルソースは全て https://github.com/isc-afuentes/recipe-inspector にあります。
この簡単な例で、InterSystems IRIS で LLM テクニックを使用して機能を追加したり、データの一部を分析する方法を学びました。
これを起点に以下のことが考えられます
- InterSystems BIを使い、キューブやダッシュボードでデータの検索やナビゲートをおこなう。
- Webアプリを作成し、UIを提供する(例:Angular)RESTForms2のようなパッケージを活用することで、永続クラスへのREST APIを自動的に生成することができます。 *レシピが好きか嫌いかを保存し、新しいレシピが好きかどうかを判断するのはいかがでしょうか。IntegratedMLアプローチ、あるいはLLMアプローチでいくつかの例データを提供し、RAG(Retrieval Augmented Generation)ユースケースを構築してみるのも良いでしょう。
他にどんなことが試せそうでしょうか?ご意見をお聞かせください!