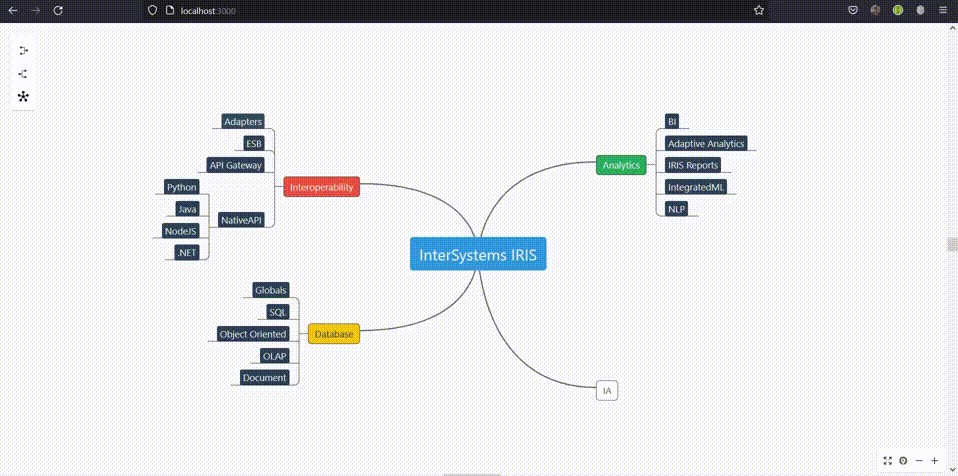
@Ming Zhou から素晴らしい質問をいただきました。その回答は、まさに私がObjectScriptを愛用している理由を表しています。
初めて誰かに ObjectScript や IRIS を説明する際、必ず、クラスを記述してコンパイルし、テーブルを取得して、オブジェクトまたはリレーショナルのいずれか最も自然な観点からデータを操作できると説明しています。 いずれにせよ、これは単に、グローバルと呼ばれる非常に高速な内部データ構造を囲む薄めのラッパーであり、速度をさらにバーストさせる必要がある場合にも使用できます。
オタクレベルの人と話すときには、ObjectScipt はあらゆる類の凝ったメタプログラミングが可能だと説明します。たった今書いたクラスが、オブジェクトやリレーショナルというアクセス方法から、さらなる高速なアクセスが必要な時に内部データ構造を使う方法まで操作ができるためです。
「継承されたプロパティも含め、クラス内のすべてのプロパティを取得するにはどうすればよいですか?」という質問に対する回答がわかるでしょう。
同じ回答を得られる 3 つの異なる方法を以下に示します。
Class DC.Demo.PropertyQuery Extends %Persistent
{
Property Foo As %String;
Property Bar As %Boolean;
/// 特定の目的を実現するためのすべての方法を紹介します
ClassMethod Run()
{
for method = "FromRelationship","WithQuery","AsQuicklyAsPossible" {
write !,method,":"
kill properties
do $classmethod($classname(),"GetProperties"_method,.properties)
do ..Print(.properties)
write !
}
}
ClassMethod Benchmark()
{
for method = "FromRelationship","WithQuery","AsQuicklyAsPossible" {
write !,method,":",!
set start = $zhorolog
set startGlobalRefs = $system.Process.GlobalReferences($job)
set startLines = $system.Process.LinesExecuted($job)
for i=1:1:1000 {
kill properties
do $classmethod($classname(),"GetProperties"_method,.properties)
}
set endLines = $system.Process.LinesExecuted($job)
set endGlobalRefs = $system.Process.GlobalReferences($job)
write "Elapsed time (1000x): ",($zhorolog-start)," seconds; ",(endGlobalRefs-startGlobalRefs)," global references; ",(endLines-startLines)," routine lines",!
}
}
/// %Dictionary.CompiledClass 内のプロパティ関係を使用してプロパティを取得します
ClassMethod GetPropertiesFromRelationship(Output properties)
{
// 些細な問題: %OpenId と Properties.GetNext() は、絶対的に必要なデータ以上のデータを読み込むため、低速です。
// グローバル参照が多いほど、処理に時間がかかります。
set class = ##class(%Dictionary.CompiledClass).IDKEYOpen($classname(),,.sc)
$$$ThrowOnError(sc)
set key = ""
for {
set property = class.Properties.GetNext(.key)
quit:key=""
set properties(property.Name) = $listbuild(property.Type,property.Origin)
// 余分なメモリの消費を回避します
do class.Properties.%UnSwizzleAt(key)
}
}
/// %Dictionary.CompiledProperty に対してクエリし、プロパティを取得します
ClassMethod GetPropertiesWithQuery(Output properties)
{
// SQL でプロパティを取得することで、不要な参照のオーバーヘッドを回避します
set result = ##class(%SQL.Statement).%ExecDirect(,
"select Name,Type,Origin from %Dictionary.CompiledProperty where parent = ?",
$classname())
if result.%SQLCODE < 0 {
throw ##class(%Exception.SQL).CreateFromSQLCODE(result.%SQLCODE,result.%Message)
}
while result.%Next(.sc) {
$$$ThrowOnError(sc)
set properties(result.Name) = $listbuild(result.Type,result.Origin)
}
$$$ThrowOnError(sc)
}
/// ダイレクトグローバル参照をラッピングするマクロを使用してプロパティを取得します
ClassMethod GetPropertiesAsQuicklyAsPossible(Output properties)
{
// マクロでラップされたダイレクトグローバル参照を介してプロパティを取得する方法は読み取りにくいですが、
// 一番速い方法です。
set key = ""
set class = $classname()
for {
set key = $$$comMemberNext(class,$$$cCLASSproperty,key)
quit:key=""
set type = $$$comMemberKeyGet(class,$$$cCLASSproperty,key,$$$cPROPtype)
set origin = $$$comMemberKeyGet(class,$$$cCLASSproperty,key,$$$cPROPorigin)
set properties(key) = $listbuild(type,origin)
}
}
ClassMethod Print(ByRef properties)
{
set key = ""
for {
set key = $order(properties(key),1,data)
quit:key=""
set $listbuild(type,origin) = data
write !,"property: ",key,"; type: ",type,"; origin: ",origin
}
}
Storage Default
{
.png)




 まずは、データの匿名化とは何でしょうか?
まずは、データの匿名化とは何でしょうか?



