2024年第3四半期のプラットフォーム最新情報をお届けします。今回は、いつもの OS 更新情報に加えて、AIX のセキュリティ向上に関連するニュースをお伝えします。
インターシステムズは、非常にまれな状況下で、マルチボリュームデータベースでデータベース破損または <DISKHARD> エラーが発生する可能性がある不具合を修正しました。危険性があるのは、未使用領域削除(Truncate)を行ったマルチボリュームデータベースのみです。
この問題は、以下の製品およびそれらベースとしたその他のインターシステムズ製品に存在します:
InterSystems IRIS 2024.1, 2024.1.1, 2024.2
InterSystems IRIS for Health 2024.1, 2024.1.1, 2024.2
HealthShare Health Connect 2024.1, 2024.1.1, 2024.2
上記以外の HealthShare 製品はこの問題の影響を受けません。
インターシステムズは、この不具合に関するお客様からの報告を受けていませんが、この問題を回避するために、以下の一時的な緩和策を推奨します:
- マルチボリュームデータベースで未使用領域削除をしない。
- 最後にデータベースをマウントした以降に未使用領域削除をしたシングルボリュームまたはマルチボリュームデータベースに対して、新しいボリュームを作成しない。
Visual Studio Code(VSCode)は、市場で最も一般的なコードエディターです。 Microsoft によって制作され、無料 IDE として配布されています。 VSCode は ObjectScript などの多数のプログラミング言語をサポートしており、2018 年までは Atelier(Eclipse ベース)もサポートしていました。 InterSystems 製品開発の主なオプションの 1 つとして考えられていましたが、 2018 年、InterSystems 開発者コミュニティが VSCode のサポートを発表した際に、関連する InterSystems のプロユーザーらが実際にこのエディターを使用し始め、以来、特に新しいテクノロジー(Docker、Kubernetes、NodeJS、Angular、React、DevOps、GitLab など)を使用する開発者の間でその使用が続いています。 VSCode の一番の機能の中にはデバッグ機能が挙げられます。 そこで、この記事では、クラスコードや %CSP.REST コードなどの ObjectScript コードをデバッグする方法を詳しく紹介します。
デバッグとは?
デバッグとは、ObjectScript コードに含まれる「バグ」と呼ばれるエラーを検出して解決するプロセスを指します。
コミュニティの皆さん
こんにちは!
ご存知かもしれませんが、Developer Community AIがリリースされて1ヶ月以上が経ちました🎉 興味を持たれた方は、ぜひ試してみてください😁 まだの方は、ぜひお試しください!いずれにせよ、まだベータ版であるため、私たちは皆さんがこのAIについてどのように考えているかを知りたいと思っています。

皆さんの時間と労力を大切にしているので、感想をシェアしてくれたメンバーに、抽選でキュートな賞品をプレゼントします。この懸賞に参加するには、以下のガイドラインに従ってください。
InterSystems IRIS 2024.3 と InterSystems IRIS for Health 2024.3 の最初の開発者プレビューが WRC プレビューダウンロードページ に公開されました。コンテナ版は InterSystems コンテナレジストリ から入手いただけます。コンテナは latest-preview とタグ付けされています。
%UnitTest framework を使用してユニットテストを構築したことがある場合、またはこれから構築しようとお考えの場合は、InterSystems Testing Manager をご覧ください。
VS Code を離れることなく、ユニットテストの閲覧、実行またはデバッグ、過去の実行結果の表示が可能になりました。
InterSystems Testing Manager は、ObjectScript 拡張機能がサポートするソースコード場所のパラダイムに対応しています。 ユニットテストクラスは、VS Code のローカルファイルシステム('client-side editing' パラダイム)またはサーバーネームスペース('server-side editing')のいずれかでマスターできます。 いずれの場合でも、実際のテストの実行は、サーバーネームスペースで発生します。
フィードバックをぜひお送りください。
IRISでPythonを扱う時に、既存の%DynamicObject型の値をそのまま利用したいと思うのですが、Embedded Pythonは自動で%DynamicObjectをdict型にはしてくれません。親和性はとてもあるのですが。。。
そこで、既存プログラムで生成した%DynamicObject型の値をPython側、特に外部のPythonファイル側でdict型を期待している関数に利用するにはどうすれば良いか。
少しスマートではありませんが、%DynamicObjectを一旦JSON文字列に置き換え、Embedded Python 内でJSON文字列からdict型に変換する方法しかないようです。
以下が、その手順です。
Set data = {}
Set data.name = "hanako"
Set data.age = 20
Do ..testPython(data)
ClassMethod testPython(arg As %DynamicObject) [ Language = python ]
{
import json
import pythonfile
data = json.loads(arg._ToJSON())
pythonfile.test(data)
}
InterSystems API Manager (IAM) のバージョン 2.8.4.11 & 3.4.3.11 が公開されました。 これらは、長期的にサポートされている IAM の 2 つのバージョンの最新版です。これらのリリースには重要な修正が含まれており、すべてのお客様にアップグレードをお勧めします。
IAM 3.0または3.2をお使いのお客様は、これらのバージョンのサポートがまもなく終了するため、3.4.3.11にアップグレードすることをお勧めします。
IAM は、InterSystems IRIS サーバとアプリケーション間の API ゲートウェイであり、HTTP ベースのトラフィックを効果的に監視、制御、管理するためのツールを提供します。IAM は、InterSystems IRIS ライセンスの無償アドオンとして利用できます。
IAMは、WRCソフトウェア配布サイトのComponentsエリアからダウンロードできます。
IAM のダウンロード、インストール、使用開始方法については、 インストール・ガイド を参照してください 。InterSystems IRIS での使用に関する詳細な情報については IAM Version 3.4 Guide を参照してください。パートナーであるKong社では、Kong Gateway (Enterprise) 3.4 ドキュメント
(2).jpg)
前回の記事でSMART On FHIRプロジェクトのアーキテクチャを紹介したので、いよいよ本題に入り、必要となる全ての要素の設定を始めましょう。
まずはAuth0から始めます。
Auth0の設定
登録が完了したら、左側のメニューから最初のアプリケーションを作成します

この例では、Angular 16で開発されたアプリケーションなので、Single Page Web Applicationタイプとなります。このオプションを選択し、Createをクリックします。
次の画面では以下のフィールドを定義する必要があります。
- 許可されるコールバックURL:https://localhost
- 許可されるログアウトURL:https://localhost
- 許可されるWebオリジン:https://localhost
- クロスオリジン認証を許可する:チェック済
- 許可されたオリジン(CORS):https://localhost
注意: URLはすべてHTTPSでなければなりません。これはOAuth2接続要件の1つです。
これはOAuth2接続の要件の1つです。これでAuth0が認証と認可プロセスの後にユーザーをリダイレクトするために必要なURLを設定しました。
これは、InterSystems FAQサイトの記事です。
管理ポータルのグローバル変数表示ページでは、サブスクリプトレベルの範囲を指定して表示することが可能です。
各サブスクリプトレベルで、 <開始値>:<終了値> のように指定します。
開始値を省略すると先頭から終了値まで、終了値を省略すると指定値から最後までのグローバル変数を表示します。
《例》
(グローバル全体)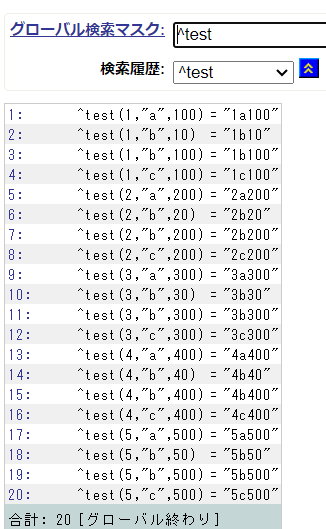
(第2サブスクリプトが"b"のデータだけを表示)
(第3サブスクリプトが300以上のデータを表示)
(第3サブスクリプトが50以下のデータを表示)
下記ドキュメントページも併せてご確認ください。
【ドキュメント】グローバル・データの表示
これは、InterSystems FAQサイトの記事です。
区切り識別子は、区切り文字で囲まれた一意の識別子です。
InterSystems SQL は、その区切り文字として二重引用符 「"」 をサポートしています。
一方、リテラル値を区切る場合は、一重引用符「'」を使用します。
例えば、下記のSQLにおいて、
①は、Nameの値が「AAA」という文字列である、という検索条件と解釈されますが、
②は、Name列 = AAA列、という結合条件と解釈されます。※実際にAAA列が無ければエラーとなります。
①
selectfromwhere
②
リテラル値(文字列、数値)を示す区切り文字として二重引用符「"」を使用したい場合は、
下記を実行し、この区切り識別子サポートするためのオプションを無効にします。
これにより、「'AAA'」と「"AAA"」はどちらも同様に「AAA」という文字列を示すことになり、
上記①・②のSQLは、どちらも、同義に解釈されます。
これは、InterSystems FAQサイトの記事です。
既定では、InterSystems製品で表すことのできる日時の最小値は、1840年12月31日 0時0分0秒 です。
USER>write$ZDATETIME ですが、アプリ内での用途や、他DBからの登録などで、それよりも前の日付時刻を登録する必要がある場合があります。
その場合には、日付日時のプロパティに、MINVAL(最小値)を設定することでサポートできます。
下記は、%DateTime型、%TeimaStamp型のプロパティに、最小値:西暦1年1月1日0時0分0秒と設定したものです。
※2023.3および2024.1以降のバージョンでは、%DateTime型のMINVALの設定は必要なく、1840年12月31日 0時0分0秒より前の日時でも問題なく登録できます。%TimeStamp型の場合は、引き続き設定が必要です。
これは InterSystems FAQ サイトの記事です。
新しいインデックスを定義した後、インデックスの再構築が完了する前にクエリを実行するとデータが存在しているにもかかわらず「検索結果0件」や検索結果数が徐々に増えるような状況が発生します。
インデックスを永続クラス定義(またはテーブル定義)に追加しコンパイルすることで今まで使用していたクエリ実行経路が削除され、再度同じクエリを実行するタイミングで新しいインデックス定義を含めた実行経路が作成されるためです。(この時にインデックス再構築が完了していないとインデックスデータが存在しない、または不完全であるため0件や徐々に検索結果数が増えるような状況を起こします。)
これを起こさなために、新しいインデックスの再構築が終了するまでクエリオプティマイザにインデックスを使用させないように指定する方法が用意されています。
※ 2024/8/2: 2024.1以降から利用できる方法を追加しました。
2024.1以降
CREATE INDEXのDEFERオプションを使用します(オプションを付けないCREATE INDEX文では、作成時にインデックスの再構築も同時に行われます)。
インターシステムズは InterSystems IRIS Data Platform, InterSystems IRIS for Health, HealthShare Health Connect バージョン 2024.2 をリリースしました。
リリースハイライト
2024.2 は Continuous Delivery(CD)リリースです。
2024.2 には多くのアップデートや拡張機能が追加されています。
開発者向け機能の強化
- スタジオの削除 - 本リリース以降、Windows キットにはスタジオが含まれなくなります。つまり、このキットを使用した新規インストールではスタジオがインストールされません。既存のインスタンスをバージョン 2024.2以降にアップグレードした場合は、インスタンスの bin ディレクトリから スタジオが削除されます。スタジオをこれからも利用されたい方は、WRC 配布ページから 2024.1 スタジオの独立したコンポーネントをダウンロードできます。
- 外部テーブル の正式サポート - 2024.2 リリースでは、早期アクセスユーザからのフィードバックに対応しており、メタデータ管理の改善、述語プッシュダウンの改善、外部データをIRIS SQLテーブルに投影するのではなく取り込む LOAD DATA コマンドとのさらなる調整などが行われています。
こんにちは。
VSCodeでObjectScriptにコメントを挿入する拡張機能を作成してみましたので、共有させて頂きたいと思います。
使い方はとても簡単で、コンテキストメニューから「コメントの追加」を選択するだけです。
カーソル位置に合ったコメントが挿入されます。
挿入するコメントの定型文は設定で自由に指定できます。
クラスの説明文を挿入する
パラメーターやプロパティの説明文を挿入する
メソッドの説明文を挿入する
インターシステムズは、InterSystems IRIS、InterSystems IRIS for Health、HealthShare Health Connect のメンテナンスバージョン 2024.1.1 をリリースしました。2024.1.1 は 2024.1.0 に対するバグフィックスを提供しています。詳細な情報は、以下のページをご参照ください(すべて英語版です)
InterSystems IRIS
InterSystems IRIS for Health
HealthShare Health Connect
【キットのご案内】
本製品は、従来からのインストーラパッケージ形式と、コンテナイメージ形式をご用意しています。その一覧は、サポートプラットフォームページをご覧ください。
インストーラパッケージは WRC Direct から入手できます。InterSystems IRIS、IRIS for Health は IRIS ダウンロードページから、HealthShare Health Connect は HealthShare ダウンロードページから、それぞれ入手してください。
コンテナイメージは InterSystems Container Registry から入手できます。コンテナイメージには 2024.1 のタグが付けられています。

ご好評をいただいておりますインターシステムズ開発者向けオンラインセミナー、9月は以下のテーマで開催いたします。
テーマ「InterSystems IRIS® サーバーとデータの守り方入門」
日時:9月6日(金)13:30~14:00 (参加費無料・事前登録制)
[概要]
はじめはユートピアになると考えられていたサイバー空間にも多様な脅威が出現し、日々変化し続けています。
多くの分野で活用されている IRIS と IRIS for Health、より厳しいセキュリティ要件は避けられない未来とも言えるでしょう。
本セッションではIRISインスタンスと管理するデータを保護する方法について概要をご説明します。
[こんな方にお勧め]
IRISの管理機能に興味ある方
IRISを使用したソリューションを設計される方
ご多用中とは存じますが、皆様のご参加をお待ち申し上げております!
(3).jpg)
これは InterSystems FAQ サイトの記事です。
通常SQLCODE -114(一致する行が既に別のユーザにロックされています)のエラーはロックが競合した場合に発生します。
こちらはレコードロック競合があったり、ロック閾値を超える更新を行いテーブルロックに昇格した際に、そのテーブルレコードに対して別のプロセスよりSelectを行い共有ロックを取ろうとして失敗した(ロック待ちがタイムアウトとなった)場合に発生します。
Selectで共有ロックを取る場合というのは、IRIS の ISOLATION LEVEL がREAD COMMITTED(デフォルトはREAD UNCOMMITTED)で、Selectを行った場合です。
例:Sample.Personテーブルにテーブルロックがかかった状態で以下を実行する場合
USER>:sql
SQL Command Line Shell
----------------------------------------------------
The command prefix is currently setq
こちらは、
- 他のプロセスが該当テーブルの該当IDをロックしている
- ロック閾値によるテーブルロックを行っている
これは InterSystems FAQ サイトの記事です。
JDBC および ODBC 経由でInterSystemsIRISから外部データベースにアクセスしたい場合、SQLゲートウェイを使用しリンクテーブルを作成して接続できます。
2023.1以降のバージョンでは、リンクテーブルに加えて、外部テーブル/FOREIGN TABLE を使用することが可能となりました(外部テーブルの定義)。
外部テーブルというのは、物理的に別の場所に保存されているデータを IRIS SQL に投影する非常に便利な機能です。
外部テーブルを使用する場合は、Java(2023.1の場合は1.8~)を事前にインストールし、JAVA_HOME環境変数を設定するだけで、簡単に接続することが可能です。
※JAVA_HOME環境変数設定例: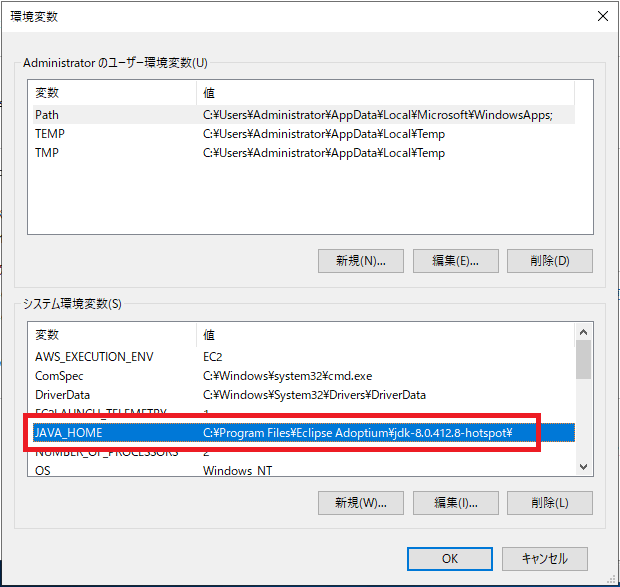
外部テーブルの使用方法については、以下の記事で紹介しております。
レシピデータセットを外部テーブルで読み込み、組み込みPythonでLLMを使って分析する (Langchain + OpenAI)
こちらの記事では、外部テーブルで作成できる2種類のテーブル(「CSVファイル直接接続」と「外部DBへのJDBCゲートウェイ経由での接続」)の簡単なサンプル作成例と、外部テーブルの特徴を紹介しています。
1-1. 簡単なサンプル作成例(CSVファイル編:ファイルから外部テーブル作成)
a.
埋め込みPythonは、同じプロセス空間で、IRIS言語とPython言語を組み合わせて使える面白い環境を提供しますが、組み合わせて使う場合、オブジェクトタイプとそのアクセス方法の違いをはっきり意識して使わないと混乱するように思います。その使い分けの勉強の為、両言語のオブジェクト参照から、その構造を解析ダンプするツールを作ってみました。とくに、実行中のPython情報が、ZWRITE Oref コマンドでの表示しかないようなので、有用かも知れません。ツールは、まだ、間違い、改良等があると思います(教えて下さい)が、ポストします。
ツール本体: Py.Dump.cls
ClassExtends%RegisteredObject"||"簡易・テストエントリー:Py.Dump.mac
ROUTINE Py.Dump
#テストサンプル:Py.Sample.cls
実行例 入力 oref は Py.Sample.cls の メソッド s1 と s10 の返り値
42InterSystems API Manager (IAM) のバージョン 2.8.4.10 と 3.4.3.10 が公開されました。 これらは、長期的にサポートされている IAM の 2 つのバージョンの最新版です。これらのリリースには重要な修正が含まれており、すべてのお客様にアップグレードをお勧めします。
IAM 3.0または3.2をお使いのお客様は、これらのバージョンのサポートがまもなく終了するため、3.4.3.10にアップグレードすることをお勧めします。
IAM は、InterSystems IRIS サーバとアプリケーション間の API ゲートウェイであり、HTTP ベースのトラフィックを効果的に監視、制御、管理するためのツールを大規模に提供します。IAM は、InterSystems IRIS ライセンスの無償アドオンとして利用できます。
IAMは、WRCソフトウェア配布サイトのComponentsエリアからダウンロードできます。
ダウンロード、インストール、IAMの使用方法につきましては、インストール・ガイドをご参照ください。InterSystems IRIS での使用に関する詳細な情報についてはドキュメントをご参照ください。パートナーであるKong社では、IAMの使用に関する詳細なドキュメントとしてKong Gateway (Enterprise) 3.4ドキュメント
これは InterSystems FAQ サイトの記事です。
管理ポータル > [システム管理] > [セキュリティ] 以下の設定は、%SYSネームスペースにあるSecurityパッケージ以下クラスが提供するメソッドを利用することでプログラムから作成することができます。
以下シナリオに合わせたセキュリティ設定例をご紹介します。
シナリオ:RESTアプリケーション用設定を作成する
事前準備
シナリオの中で使用するソースを2種類インポートします。
アプリケーション用RESTディスパッチクラスをインポートします。
ClassExtends%CSP.REST"application/json"続いて、Test.Humanテーブル用定義もインポートします。
Asそれでは設定してみましょう。
1) RESTアプリケーション(/testApp)があり、USERネームスペースで動作するRESTアプリケーションに対して不特定多数のユーザが利用できるようにします=(認証なしアクセスを許可します)。
これは InterSystems FAQ サイトの記事です。
SQLゲートウェイの接続設定は管理ポータルで作成できますが、プログラムでも作成が可能です。
管理ポータル:
[システム管理] > [構成] > [接続性] > [SQLゲートウェイ接続]
こちらのトピックでは、ODBC/JDBCそれぞれの設定をプログラムで行う方法をご紹介します。
--- SQL Gateway for ODBC ----
set##class
--- SQL Gateway for JDBC ----
接続テストは以下のように行います。
--- SQL Gateway Connection Test for ODBC ----
USER>
--- SQL Gateway Connection Test for JDBC ----
USER> 【ご参考】
【ご参考】
SQL ゲートウェイを使用した外部データベースへのアクセス方法について
(管理ポータルで行う)リンクテーブルをプログラムで行う方法
Pandas は単に人気のあるソフトウェアライブラリだけではありません。 これは、Python データ分析環境の基礎でもあります。 その単純さとパワーで知られており、データの準備と分析の複雑さをより扱いやすい形態に変換する上で不可欠な多様なデータ構造と関数が備わっています。 これは、主要なデータ管理および分析ソリューションである InterSystems IRIS プラットフォームのフレームワーク内で、主要評価指標(KPI)やレポート作成用の ObjectScript などの特殊な環境に特に関連しています。
データの処理と分析の分野において、Pandas はいくつかの理由により際立っています。 この記事では、それらの側面を詳細に探ります。
- データ分析における Pandas の主なメリット:
ここでは、Pandas を使用する様々なメリットについて深く掘り下げます。 直感的な構文、大規模なデータセットの効率的な処理、および異なるデータ形式のシームレスな操作などが含まれます。 Pandas を既存のデータ分析ワークフローに統合する容易さも、生産性と効率を強化する大きな要因です。
- Pandas による一般的なデータ分析タスクのソリューション:
Pandas には、単純なデータ集計から複雑な変換まで、日常的なデータ分析タスクを処理できる十分な汎用性が備わっています。
2024年10月15日をもって、MacOS での Caché および Ensemble のサポートが非推奨となります。
Caché および Ensemble 2018.1.9 のサポートは続きますが、MacOS 向けのメンテナンスバージョンは今後リリースされません。つまり、MacOS 向け製品としては、Caché および Ensemble 2018.1.9 が最後のバージョンとなる予定です。
あらためてのお知らせですが、その他のプラットフォームにおいても、Caché および Ensemble のメンテナンスバージョンは 2027年3月31日をもってリリース終了となる予定です。詳細は昨年発表の記事をご参照ください。
これは InterSystems FAQ サイトの記事です。
管理ポータル > [システム管理] > [セキュリティ] 以下の設定は、%SYSネームスペースにあるSecurityパッケージ以下クラスが提供するメソッドを利用することでプログラムから作成することができます。
ユーザ設定については、Security.UsersクラスのCreate()メソッドを使えば作成できますが、ユーザを作成するだけでは適切な権限が付与されずに目的のデータにアクセスできない状況もあります。
例)testAユーザ作成
%SYSset##class上記メソッドで作成した結果は以下の通りです。(ロール付与無し、テーブルに対する権限の割り当てもなしの状態)

以降の解説では、以下のシナリオをもとにした設定を行っていきます。
シナリオ:アプリケーション開発者用ロールとユーザを作成する
1) アプリケーション開発者のtestAは、USERネームスペースにログインするアプリケーション開発者です(=%DevelopmentリソースのUse許可を与えます)。
2) このユーザはUSERネームスペース内で自由にテーブルの作成・参照・更新が行えるよう適切な特権を持つように定義します。
InterSystems Reports 24.1 がリリースされ、WRC の Components エリアから入手いただけるようになりました。本製品は InterSystems Reports Designer と InterSystems Reports Server と表記されており、Mac OSX、Windows、Linux 版を入手いただけます。
この新バージョンには、弊社パートナーの insightsoftware 社によるすばらしい拡張機能が含まれています。InterSystems Reports 24.1 は Logi Report 24.1 SP2 をベースにしており、以下の機能が含まれます。
これは InterSystems FAQ サイトの記事です。
こちらの記事では、「IRISでシャドウイングの代わりにミラーリングを構成する方法」を紹介しました。
今回は、「プログラムでシャドウイングの代わりにミラーリングを構成する方法(Windows版)」を紹介します。
【今回のサンプル・ミラー構成について】
| 正サーバ(ミラー・プライマリ) | 副サーバ(ミラー・非同期) | |
| ミラー名 | MIRRORSET | MIRRORSET |
| ミラーメンバ名 | MACHINEA | MACHINEC |
| IPアドレス | 35.77.84.159 | 54.248.39.237 |
では、ミラーの構成手順をご紹介します。手順は以下になります。
<ミラーリングのプライマリ設定> // MACHINEA(正サーバ)
1. ISCAgentの自動起動設定および起動 ※Windowsコマンドプロンプトで実行
C:\Users\Administrator>sc config ISCAgent start=auto
C:\Users\Administrator>sc start ISCAgent2.

