Apache Zeppelin は以下を行えるようにする多目的ノートブックです。
- データの取り込み
- _ データ検出_
- データ分析
- データの可視化とコラボレーション
Apache Zeppelin インタープリターの概念に基づき、あらゆる言語/データ処理バックエンドを Zeppelin にプラグインすることができます。 現在、Apache Zeppelin は、Apache Spark、Apache Flink、Python、R、JDBC、Markcown、およびシェルなど、多くのインタープリターに対応しています。
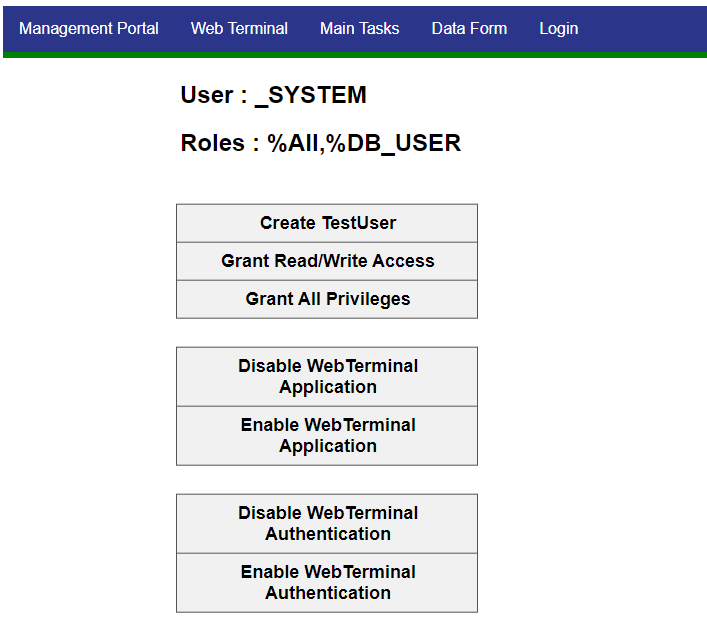
データの洞察を得るための安全な環境を得られます。 Zeppelin のハイライト機能は、JDBC と Spark IRIS のネイティブコネクタを使用して利用することができます。
これは、あなたを軌道に乗せるためのクイックスタートガイドです。
1.- 公式 Web サイト(こちら)から Zeppelin をダウンロードして保存します。
2.- ディストリビューションを任意のインストールフォルダに解凍します。
3.- JDK をインストールする必要があります(まだインストールされていない場合)。
4.- JDK のインストールが完了すると、#bash> sudo ./<zeppelin_path>/bin/zeppelin-daemon.
.png)
.png)
 。
。
 269
269