IRISインターオペラビリティのメッセージビューワで何かを変更できるとしたら、何を変更しますか?
この連載の最初の記事では、大きなチャンクのデータをHTTP POSTメソッドのRaw本体から読み取って、それをクラスのストリームクラスとしてデータベースに格納する方法を説明しました。 2つ目の記事では、ファイルとファイル名をJSON形式にラップして送信する方法を説明しました。
それでは、大きなファイルを分割してサーバーに送るという構想を詳しく見ていきましょう。 これを行うために使用できるアプローチにはいくつかあるのですが、 この記事では、Transfer-Encodingヘッダーを使用してチャンク転送を指示する方法を説明します。 Transfer-EncodingヘッダーはHTTP/1.1仕様で導入されたものです。RFC 7230第4.1項では説明されているものの、HTTP/2仕様からはその説明が無くなっています。
この連載の第1回目の記事では、「大規模な」チャンクのデータをHTTP POSTメソッドのRaw本体から読み取って、それをクラスのストリームプロパティとしてデータベースに格納する方法について説明しました。 では、そのようなデータとメタデータをJSON形式で格納する方法について見てみましょう。
残念ながら、Advanced REST Clientでは、バイナリーデータをキーの値としてJSONオブジェクトを作成することはできません(もしかすると、私がまだ知らないだけかもしれません)。そこで、サーバーにデータを送信する単純なクライアントをObjectScriptで記述することにしました。
新しいRestTransfer.Clientというクラスを作成し、私のWebサーバーを指定するServer = "localhost"パラメーターとPort = 52773パラメーターをそれに追加しました。 そしてGetLinkクラスメソッドを作成しました。この中で、クラス%Net.HttpRequestの新しいインスタンスを作成し、プロパティを前述のパラメーターに設定します。
実際にPOSTリクエストをサーバーに送信するために、クラスメソッドSendFileDirectを作成しました。
InterSystems開発者コミュニティにおいて、CachéアプリケーションへのTWAINインターフェースの作成の可能性に関する質問が上がりました。 Webクライアントの撮像装置からサーバーにデータを取得し、そのデータをデータベースに保管する方法について、素晴らしい提案がいくつかなされました。
しかし、こういった提案を実装するには、Webクライアントからデータベースサーバーにデータを転送し、受信データをクラスプロパティ(または質問のケースで言えばテーブルのセル)に格納できなければなりません。 この方法は、TWAINデバイスから受信した撮像データを転送するためだけでなく、ファイルアーカイブや画像共有などの整理といったほかのタスクにも役立つ可能性があります。
そこで、この記事では主に、HTTP POSTコマンドの本体から、raw状態またはJSON構造にラップしてデータを取得するRESTfulサービスを記述する方法を説明することにします。
RESTの基本
具体的な話に入る前に、まずREST全般と、IRISでRESTfulサービスがどのように作成されるかについて簡単に説明しましょう。
Representational state transfer(REST)は、分散ハイパーメディアシステムのためのアーキテクチャスタイルです。
InterSystems IRISを初めて使用し始める際には、最低限のセキュリティレベルでのみシステムをインストールするのが通例です。 パスワードを入力する回数が少なくて済むため、初めて作業を始めるときに、開発サービスやWebアプリケーションの操作がより簡単になるからです。 また、開発済みのプロジェクトまたはソリューションをデプロイする際には、最小限のセキュリティを適用している方が便利な場合があります。 それでも、プロジェクトを開発環境から非常に敵対的な可能性のあるインターネット環境に移行する時が来れば、本番環境にデプロイされる前に、最大限のセキュリティ設定(つまり、完全なロックダウン状態)でテストしなければなりません。 これがこの記事の論点です。
InterSystems Caché、Ensemble、およびIRISにおけるDBMSセキュリティ問題をさらに包括的に説明した記事については、私の別の記事、「Recommendations on installing the InterSystems Caché DBMS for a production environment」(本番環境向けにInterSystems Caché DBMS をインストールするための推奨事項)をご覧ください。 InterSystems IRISのセキュリティシステムは、さまざまなカテゴリ(ユーザー、サービス、リソース、特権、およびアプリケーション)に異なるセキュリティ設定を適用する概念に基づいています。 
インターネットを使うようになってから (1990年代後半)、PythonとIRIS グローバルを使ってブログを書いていますが、常にCMS (コンテンツ管理システム) でブログ、ソーシャルメディア、さらには企業ページに情報を簡単に投稿できるようにしていました。
数年後、自分がマークダウンファイルに収めて使ってきたすべてのコードをgithubに入れました。
ネイティブAPIでデータをIntersystems IRISに入れて永続化するのはとても簡単だったので、このアプリケーションを作成して少しSQLを忘れ、キー・バリュー・データベースモデルを受け入れることにしました!
ブログとは?
これはWEB LOGの略名で、基本的にはユーザーが書いてページに投稿、公開できるプラットフォームです。
マークダウンフォーマットとは?
マークダウンとは、フォーマットしたテキストを作成するマークアップ言語であり、HTMLより簡単で、多くのCMSプラットフォームで人気があります。
例:
# Header 1
## Header 2
### Header 3
結果:
Header 1
Header 2
Header 3
IRISで作成するメリットとは?
IRIS Globalsを使用して各投稿のデータを永続化しながら、各データコンサルタントはキー・バリュー・データベースとして動作するIRISのスピードというメリットを得ます。
はじめに
ObjectScriptで複雑な問題を解決している場合、おそらく%Status値を使用したコードがたくさんあることでしょう。 オブジェクトの観点(%Save、%OpenIdなど)から永続クラスを操作したことがある場合は、ほぼ確実にその状況に遭遇したことがあるでしょう。 %StatusはInterSystemsのプラットフォームでローカライズ可能なエラーメッセージのラッパーを提供します。 OKステータス($$$OK)は1に等しいだけであるのに対し、不良ステータス($$$ERROR(errorcode,arguments...))は0、スペース、エラーに関する構造化情報を含む$ListBuildリストとして表されます。 $System.Status(クラスリファレンスを参照)は、%Status値を操作するための便利なAPIをいくつか提供しています。クラスリファレンスを役立てられるので、ここでは繰り返しません。 このトピックに関する有用な記事/質問もほかにいくつかあります(最後のリンクをご覧ください)。 この記事では、コーディングのベストプラクティスではなく、いくつかのデバッグのコツや手法に焦点を当てています(ベストプラクティスについては、最後のリンクをご覧ください)。
@Evgeny.Shvarovの記事へのコメントとして書こうとしていましたが、 コメントが長すぎたため、別に投稿することにしました。

dockerがどのようにディスクスペースを使用し、クリーンアップするかについて、少し説明を加えたいと思います。 私はmacOSを使用しているため、以下に示すものは主にmacOSを対象としていますが、dockerコマンドはすべてのプラットフォームでも使用できます。

前の記事では、マクロの潜在的なユースケースををレビューしました。そこで、マクロの使用方法についてより包括的な例を見てみることにしましょう。 この記事では、ロギングシステムを設計して構築します。
ロギングシステム
ロギングシステムは、アプリケーションの作業を監視するための便利なツールで、デバッグや監視にかける時間を大幅に節約してくれます。 これから構築するシステムは2つの部分で構成されます。
- ストレージクラス(レコードをログ記録するためのクラス)
- 新しいレコードをログに自動的に追加する一連のマクロ
これは、オンラインドキュメントのさまざまな場所に表示される主題に関する概要であり、主に注釈として表示され、専用の章として表示されることはありません。
むかしむかし、ある所に... おっと、おとぎ話ではありません。
Cachéの初めの頃(それからその前にも)、自分のコードを実行するためのパーティションを用意していたことがあるでしょう。 そのパーティションの一部は、すべてのローカル変数が%、A~Z、a~zでうまくソートされていた領域でした。
また、ローカルに保存する値や情報が何であれ、すべてはそこに保存されており、パーティションでどんなコードを実行する場合でも、可視状態であり、利用することができました。 完全なドキュメントと優良な規律をもって共同作業できている開発者チームであれば、問題はありません。
[残念ながら、これをおとぎ話にしてはいけません]。
実際に、(独自または外部の)ソフトウェアパッケージを使って作業することは、当時は悪夢であり、コードそのものよりも競合しない変数の使用方法を見つけることに労力を要していました。 言うまでもなく、有意義な命名は例外になっていたのです。 その頃助けとなっていたのは、
スタックに変数をプッシュして後で復元するNEWコマンドです。
メッセージビューアはメッセージを再送信できますが、大量(>100件)のメッセージを再送信するには適していません。 それを行うには、以下のようなCache Object Scriptコードを使用する必要があります。
Class Sample.Resender Extends %RegisteredObject
{
ClassMethod Resend()
{
//2016-06-15から2016-06-20の間に'FromComponent'から'ToComponent'に送られたすべてのメッセージを再送信
&sql(DECLARE C1 CURSOR FOR
SELECT ID INTO :id FROM Ens.MessageHeader
WHERE SourceConfigName='FromComponent' AND TargetConfigName='ToComponent'
AND TimeCreated BETWEEN '2016-06-15' AND '2016-06-20')
&sql(OPEN C1)
&sql(FETCH C1)
set tSC = $$$OK
while (SQLCODE = 0) {
//idには1つのメッセージのidが含まれます。 それを再送信
set tSC = ##class(Ens.MessageHeader).
{
ClassMethod Resend()
{
//2016-06-15から2016-06-20の間に'FromComponent'から'ToComponent'に送られたすべてのメッセージを再送信
&sql(DECLARE C1 CURSOR FOR
SELECT ID INTO :id FROM Ens.MessageHeader
WHERE SourceConfigName='FromComponent' AND TargetConfigName='ToComponent'
AND TimeCreated BETWEEN '2016-06-15' AND '2016-06-20')
&sql(OPEN C1)
&sql(FETCH C1)
set tSC = $$$OK
while (SQLCODE = 0) {
//idには1つのメッセージのidが含まれます。 それを再送信
set tSC = ##class(Ens.MessageHeader).
Cachéでのデータ同期については、オブジェクトとテーブルを同期させるさまざまな方法があります。
データベースレベルでは、シャドーイングまたはミラーリングを使用できます。
これは非常によく機能し、データの一部分だけを同期する必要がある場合には、
グローバルマッピングを使用してより小さなピースにデータを分割することができます。
または、クラス/テーブルレベルで双方向の同期が必要な場合には、オブジェクト同期機能を使用することができます。
これらすべての優れた機能には次のような制限があります。
Caché/IRISからCaché/IRISにしか機能しません。
この記事は、視覚化ツールと時系列データの分析を説明する連載の最初の記事です。 当然ながら、Caché製品ファミリーから収集できるパフォーマンス関連のデータを見ることに焦点を当てますが、 説明の途中で、他の内容についても解説していきます。 まずは、Pythonとそのエコシステムで提供されているライブラリ/ツールを探りましょう。
この連載は、Murrayが投稿したCachéのパフォーマンスと監視に関する優れた連載(こちらから参照)、より具体的にはこちらの記事と密接に関係しています。
免責事項1: 確認しているデータの解釈について話すつもりですが、それを詳しく話すと実際の目標から外れてしまう可能性があります。 そのため、Murrayの連載を先に読んで、主題の基本的な理解を得ておくことを強くお勧めします。
免責事項2: 収集したデータを視覚化するために使用できるツールは山ほどあります。 その多くは、mgstatなどから得たデータを直接処理するが、必要最低限の調整だけで処理することができます。 この記事は「このソリューションがベストですよ」という投稿ではまったくなく、 あくまでも、「データを操作する上で便利で効果的な方法を見つけたよ」という記事です。
免責事項3: データの視覚化と分析は、詳しく見るほど非常にやみつきになる、刺激的で楽しい分野です。
開発者の皆さん、こんにちは!
CSVまたはURLからCSVデータをプログラムでInterSystems IRISにインポートしなければならない場合があります。 そして、適切なデータ型でクラスが作成され、そのデータがインポートされることを期待するでしょう。
それを実現するcsvgenモジュールをOpen Exchangeに公開しました。
IRISにCSVファイルをインポートするだけであれば、次のようにすることができます。
USER>do ##class(community.csvgen).Generate("/usr/data/titanic.csv",,"Data.Titanic")
Class name: Data.Titanic
Header: PassengerId INTEGER,Survived INTEGER,Pclass INTEGER,Name VARCHAR(250),Sex VARCHAR(250),Age INTEGER,SibSp INTEGER,Parch INTEGER,Ticket VARCHAR(250),Fare MONEY,Cabin VARCHAR(250),Embarked VARCHAR(250)
Records imported: 891
USER>
または、GitHubのCOVID-19 Dataのように、インターネット上にCSVがある場合は、次のようにしてデータを取得できます。
USER>d ##class(community.csvgen).GenerateFromURL("https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_daily_reports/05-29-2020.csv",",","Data.Covid19")
Class name: Data.Covid19
Header: FIPS INTEGER,Admin2 VARCHAR(250),Province_State VARCHAR(250),Country_Region VARCHAR(250),Last_Update DATE,Lat MONEY,Long_ DOUBLE,Confirmed INTEGER,Deaths INTEGER,Recovered INTEGER,Active INTEGER,Combined_Key VARCHAR(250),Incidence_Rate DOUBLE,Case-Fatality_Ratio DOUBLE
Records imported: 3522
USER>
はじめに
InterSystemsは最近、HL7バージョン2の相互運用性に焦点を当てた、IRIS for Health 2020.1のパフォーマンスとスケーラビリティのベンチマークを完了しました。 この記事では、さまざまなワークロードで観察されたスループットを説明し、IRIS for HealthをHL7v2メッセージングの相互運用性エンジンとして使用しているシステムの一般的な構成とサイジングのガイドラインを提供します。
より産業向けのグローバルストレージスキーム
この連載の第1回では、リレーショナルデータベースにおけるEAV(Entity-Attribute-Value)モデルを取り上げ、テーブルにエンティティ、属性、および値を保存することのメリットとデメリットについて確認しました。 このアプローチには柔軟性という点でメリットがあるにもかかわらず、特にデータの論理構造と物理ストレージの基本的な不一致などによりさまざまな問題が引き起こされるという深刻なデメリットがあります。
こういった問題を解決するために、階層情報の保存向けに最適化されたグローバル変数を、EAVアプローチが通常処理するタスクに使用できるかどうかを確認することにしました。
パート1では、オンラインストア向けのカタログをテーブルを使って作成し、その後で1つのグローバル変数のみで作成しました。 それでは、複数のグローバル変数で同じ構造を実装してみることにしましょう。
最初のグローバル変数^catalogには、ディレクトリ構造を保存します。 2つ目のグローバル変数^goodには、店の商品を保存します。 ^indexグローバルには、店のインデックスを保存します。 プロパティは階層的なカタログに関連付けられているため、プロパティ用の個別のグローバル変数は作成しません。
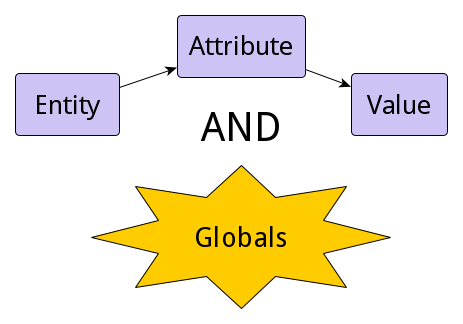
はじめに
この連載の最初の記事では、リレーショナルデータベースのEAV(Entity–Attribute–Value)モデルを見て、それがどのように使用されて、何に役立つのかを確認しましょう。 その上で、EAVモデルの概念とグローバル変数と比較します。
原則として検索する必要のある、フィールド数、または階層的にネストされたフィールドの数が不明なオブジェクトがある場合があります。
たとえば、多様な商品群を扱うオンラインストアを考えてみましょう。 商品群ごとに固有の一意のプロパティセットがあり、共通のプロパティもあります。 たとえば、SSDとHDDドライブには共通の「capacity」プロパティがありますが、SSDには「Endurance, TBW」、HDDには「average head positioning time」という一意のプロパティもあります。
場合によっては、同じ商品でも別のメーカーが製造した場合には、それぞれに一意のプロパティが存在します。
では、50種の商品群を販売するオンラインストアがあるとしましょう。 各商品群には、数値またはテキストの固有のプロパティが5つあります。
実際に使用するのは5個だけであっても、各商品に250個のプロパティがあるテーブルを作成するのであれば、ディスク容量の要件が大幅に増える(50倍!
まずはこの記事で手短にこの疑問に回答します。 この連載のパート2には、pButtonsから抽出されたパフォーマンスデータのグラフを含めました。 pButtonsの.htmlファイルからmgstatなどのメトリックを抽出してExcelで簡単にグラフ作成する方法として、カット&ペーストよりも素早く行える方法がないか、オフラインで尋ねられました。
pButtonsは、収集したデータをWRCに送信して確認しやすくするために、そのデータを1つのhtmlファイルにコンパイルするのですが、 特に24時間などの長い収集時間で実行されるpButtonsの場合は、mgstat、vmstatなどの時間ベースのデータをグラフィック表示にして確認できれば、トレンドやパターンが見やすくなります。
pButtons データをhtmlファイルにロールアップしてから解凍するのに時間を掛けるのはばかげているように聞こえるかもしれませんが、pButtonsはパフォーマンスの問題をトラブルシューティングするためにWRCが多数のシステムメトリックのビューを取得するためのツールであることを忘れてはいけません。
記事で使用されているすべてのソースコード: https://github.com/antonum/ha-iris-k8s

前の記事では、従来型のミラーリングではなく分散ストレージに基づいて、高可用性のあるk8sでIRISをセットアップする方法について説明しました。 その記事では例としてAzure AKSクラスタを使用しました。 この記事では引き続き、k8sで可用性の高い構成を詳しく見ていきますが、 今回は、Amazon EKS(AWSが管理するKubernetesサービス)に基づき、Kubernetes Snapshotに基づいてデータベースのバックアップと復元を行うためのオプションが含まれます。
インストール
早速作業に取り掛かりましょう。 まず、AWSアカウントが必要です。AWS CLI、kubectl、およびeksctlツールがインストールされている必要があります。 新しいクラスタを作成するために、次のコマンドを実行します。
eksctl create cluster
このコマンドは約15分掛けてEKSクラスタをデプロイし、それをkubectlツールのデフォルトのフォルダに設定します。 デプロイを確認するには、次のコードを実行します。
kubectl get nodes NAME STATUS ROLES AGE VERSION ip-192-168-19-7.ca-central-1.compute.internal Ready <none> 18d v1.18.9-eks-d1db3c ip-192-168-37-96.ca-central-1.compute.internal Ready <none> 18d v1.18.9-eks-d1db3c ip-192-168-76-18.ca-central-1.compute.internal Ready <none> 18d v1.18.9-eks-d1db3c
最初の記事では、Caché Webアプリケーションのテストとデバッグを外部ツールを用いて行うことについて説明しました。 2回目となるこの記事では、Cachéツールの使用について説明します。
以下について説明します。
- CSP GatewayとWebappの構成
- CSP Gatewayのロギング
- CSP Gatewayのトレース
- ISCLOG
- カスタムロギング
- セッションイベント
- デバイスへの出力
この記事では、Caché Webアプリケーション(主にREST)のテストとデバッグを外部ツールを用いて行うことについて説明します。 パート2では、Cachéツールの使用について説明します。
サーバー側のコードを作成したのでクライアントからテストしたい、またはすでにWebアプリケーションが存在するが機能していない― そういったときに使用できるのがデバッグです。 この記事では、最も使いやすいツール(ブラウザ)から最も包括的なツール(パケットアナライザー)までを説明しますが、まずは、最も一般的なエラーとその解決方法について少し説明します。
ソリューションを Amazon Web Services エコシステム、サーバーレスアプリケーション、または boto3 を使用した Python スクリプトにスムーズに統合する方法を探している場合は、IRIS Python Native API を使用するのが最適です。 IRIS で何かを取得したり設定したりしてアプリケーションに素晴らしい機能を備える必要があるまで、本番の実装を大々的に構築する必要はありません。したがって、誰かにとって重要なものまたはあなた以外にはまったく重要でないもの(これも同じくらい重要なことです)を構築できるようにこの記事が役に立てればと思います。

 PHP はその公開当初から、多くのライブラリや市場に出回っているほぼすべてのデータベースとの統合をサポートしていることでよく知られています(またそのことで批判を受けてもいます)。 にもかかわらず、何らかの不可解な理由により、グローバル変数については階層型データベースをサポートしませんでした。
PHP はその公開当初から、多くのライブラリや市場に出回っているほぼすべてのデータベースとの統合をサポートしていることでよく知られています(またそのことで批判を受けてもいます)。 にもかかわらず、何らかの不可解な理由により、グローバル変数については階層型データベースをサポートしませんでした。
グローバル変数は階層情報を格納するための構造です。 Key-Value型データベースにある程度似ていますが、キーを次のようにマルチレベルにできるという点で異なっています。
Office ドキュメント(docx ドキュメント、xlsx 表計算、pptx プレゼンテーション)を処理するタスクは非常に複雑です。 この記事では、XSLT と ZIP のみを使用してドキュメントを解析、作成、および編集する方法を紹介します。
このトピックを記事にしたのは、 docx が最も一般的に使用されているドキュメント形式であり、この形式を生成して解析する機能は必ず役に立つからです。 「既製ライブラリ」によるソリューションでは、次の理由により面倒になる可能性があります。
- ライブラリが存在しない
- プロジェクトに別のブラックボックスは必要ない
- ライブラリの制限: プラットフォーム、機能など
- ライセンス
- 処理速度
この記事では、基本ツールのみを使用して、docx ドキュメントを操作します。
不在時に、セキュリティとプライバシーを維持しながら、コンピューターを相互に信頼させるにはどうすればよいでしょうか?

「ドライマルティーニを」と彼は言った。 「1 杯。 深いシャンパングラスで。」
「承知いたしました。」
「気が変わった。 ゴードンを 3、ヴォッカを 1、キナリレを半量。 キンキンに冷えるまでよくシェイクしてから、大きめの薄いレモンピールを 1 つ加えてくれ。 わかったかい?」
「お承りいたしました。」 バーテンダーはその考えが気に入ったようだった。
イアン・フレミング著『カジノ・ロワイヤル』(1953 年)より
OAuth は、ユーザーログイン情報を伴うサービスを「運用中」のデータベースから、物理的にも地理的にも分離する上で役立ちます。 このように分離すると、ID データの保護が強化され、必要であれば、諸国のデータ保護法の要件に準拠しやすくしてくれます。
OAuth を使用すると、ユーザーは、最小限の個人データをさまざまなサービスやアプリケーションに「公開」しながら、一度に複数のデバイスから安全に作業することができるようになります。 また、サービスのユーザーに関する「過剰な」データを操作しなくてよくなります(データはパーソナル化されていない形態で処理することができます)。
開発者の皆さん、こんにちは。
今回、インターシステムズ・パートナーディレクトリをオープンさせていただくことになりました!
このサイトではインターシステムズ製品で構築された商用のサービスやソリューションを見つけることができます。
インターシステムズ・パートナーディレクトリとは?
1 年ほど前、私のチーム(多数の社内アプリケーションの構築と管理、および他の部署のアプリケーションで使用するツールやベストプラクティスの提供を担う InterSystems のアプリケーションサービス部門)は、Angular/REST ベースのユーザーインターフェースを元々 CSP や Zen を使って構築された既存のアプリケーションに作りこむ作業を開始しました。 この道のりには、皆さんも経験したことがあるかもしれない興味深いチャレンジがありました。既存のデータモデルとビジネスロジックに新しい REST API を構築するというチャレンジです。
このプロセスの一環として、REST API 用に新しいフレームワークを構築しました。あまりにも便利であるため、自分たちだけに取っておくわけにはいきません。 そこで、Open Exchange の
はじめに、設計の目標と意図についていくつか以下に示します。 すべての目標が実現したわけではありませんが、順調に進んでいます!

皆さんこんにちは! よろしければ、ボットが対話できるようになるようお手伝いいただけませんか?
チャットボットはこちらからアクセスしてください: Help my chatbots to talk!
なんだ、そのチャットボットはスマートではないのですか?
このシナリオでは「スマート」は適切な言葉ではありません。 チャットボットはトレーニング済みではありますが、少量のデータでしかトレーニングされていません! ほとんどのチャットボットソリューションでは、機械学習を使用して人間と対話する方法が作成されており、機械学習がうまく機能するには、重要なものが 1 つ必要となります。それはデータです。
どのように動作しますか?
簡単に説明しましょう。脳があっても人生経験のない人がいるとします。生まれたばかりの赤ん坊です。 この状況では、その人(赤ん坊)は、話している人を見たり、授業を受けたり、映画を見たりなどして、話し方を学習しなければなりません。 この人間の学習プロセスを、機械学習モデルにも当てはめることができます。 機械学習モデルが学習できる状況を与える必要があり、その状況がデータということになります。
** つまり、チャットボットは単なる辞書かオウムということになるのでしょうか…**
全くもってそうではありません。