インターシステムズでは、すべてにおいて最高の品質を提供するよう努めています。グローバル・マスターズ・プログラムの実現もその一つです。
このプラットフォームのベンダーが他社に買収され、残念ながら、グローバル・マスターズ・プログラムをこのプラットフォームでサービスし続けることができなくなりました。現在、グローバル・マスターズ・アドボケート・ハブの移行を行うべく、新しいプラットフォーム・プロバイダーを評価中です。
インターシステムズでは、すべてにおいて最高の品質を提供するよう努めています。グローバル・マスターズ・プログラムの実現もその一つです。
このプラットフォームのベンダーが他社に買収され、残念ながら、グローバル・マスターズ・プログラムをこのプラットフォームでサービスし続けることができなくなりました。現在、グローバル・マスターズ・アドボケート・ハブの移行を行うべく、新しいプラットフォーム・プロバイダーを評価中です。

連続3回のシリーズでお届けする新機能についてのウェビナー、第二弾はベクトル検索です。
セッション概要:IRIS 2024.1の実験的機能として、ベクトル検索が実装されました。この機能により、ベクトル型が新たにサポートされ、ドキュメントの類似検索などが可能になります。また、大規模言語モデル(LLM)や生成AIと組み合わせて、最先端のアプリケーション開発を強力に支援します。本ウェビナーでは、ベクトル検索の概要について解説します。
ウェビナーの前に少し内容を確認されたい方は、開発者コミュニティの記事「Vector Search (ベクトル検索) をご紹介します」をぜひご参照ください。
こんな方にお勧め:
・ 文書検索に興味のある方
・ 大規模言語モデルや生成AIの活用を検討されている方
ご多用中とは存じますが、皆様のご参加をお待ち申し上げております。
VS Code を使ってコードを編集する場合、設定モデルでは、ワークスペースルートフォルダの .vscode サブフォルダにある settings.json ファイルを使用して、一部の設定にフォルダ固有の値を指定できます。 ワークスペースのルートフォルダ内で作業している場合、ここで設定した値は個人設定の値よりも優先されます。
isfs-type ワークスペースを使用してサーバー上のネームスペースで直接操作している場合は、現在および将来のネームスペースごとに特別な .vscode フォルダをサポートするようにそのサーバーを構成しておく必要があります。 このフォルダはフォルダ固有のコードスニペットとデバッグ起動構成も提供できます。
この機能をセットアップしておくと、設定(またはスニペット、またはデバッグ構成)をサーバーに配置することで、そのサーバーで作業するすべての VS Code ユーザーがすぐにそれを使用できるようになるというメリットがあります。
たとえば、Deltanji ソース管理は、機能拡張を使って VS Code に統合されます。 サーバー側の設定ストレージを使用すれば、結果が設定に依存する場合に、特定のネームスペースに接続するすべての開発者が Deltanji 拡張機能から同じ結果を得ることができるようになります。
サーバーがネームスペースごとに .
我々には、Redditユーザーが書いた、おいしいレシピデータセット がありますが, 情報のほとんどは投稿されたタイトルや説明といったフリーテキストです。埋め込みPythonやLangchainフレームワークにあるOpenAIの大規模言語モデルの機能を使い、このデータセットを簡単にロードし、特徴を抽出、分析する方法を紹介しましょう。
まず最初に、データセットをロードするかデータセットに接続する必要があります。
これを実現するにはさまざまな方法があります。たとえばCSVレコードマッパーを相互運用性プロダクションで使用したり csvgenのようなすばらしい OpenExchange アプリケーションを使用することもできます。
今回、外部テーブルを使用します。これは物理的に別の場所に保存されているデータをIRIS SQLで統合する非常に便利な機能です。
まずは外部サーバ(Foreign Server)を作成します。
CREATE FOREIGN SERVER dataset FOREIGN DATA WRAPPER CSV HOST '/app/data/'
その上でCSVファイルに接続する外部テーブルを作成します。
CREATE FOREIGN TABLE dataset.IRIS BIチュートリアル試してみたシリーズの5回目です。
今回も、前回同様チュートリアルの「キューブの作成」ページになります。
前回はキューブを作成し、そのキューブを使用していくつかのピボットテーブルを作成しました。
その中で気になった点を今回は修正していきます。では、はじめていきましょう。
前回の作業の中で、ピボットテーブル作成時に気になった点は以下のものがありました。
では、これらを解消していきましょう。アーキテクト画面で Tutorial キューブを開きます。
キューブが開いたら、 Age レベルをクリックし、続いて [要素を追加] をクリックします。
要素名に AgeSort と入力し、要素選択は プロパティ を指定します。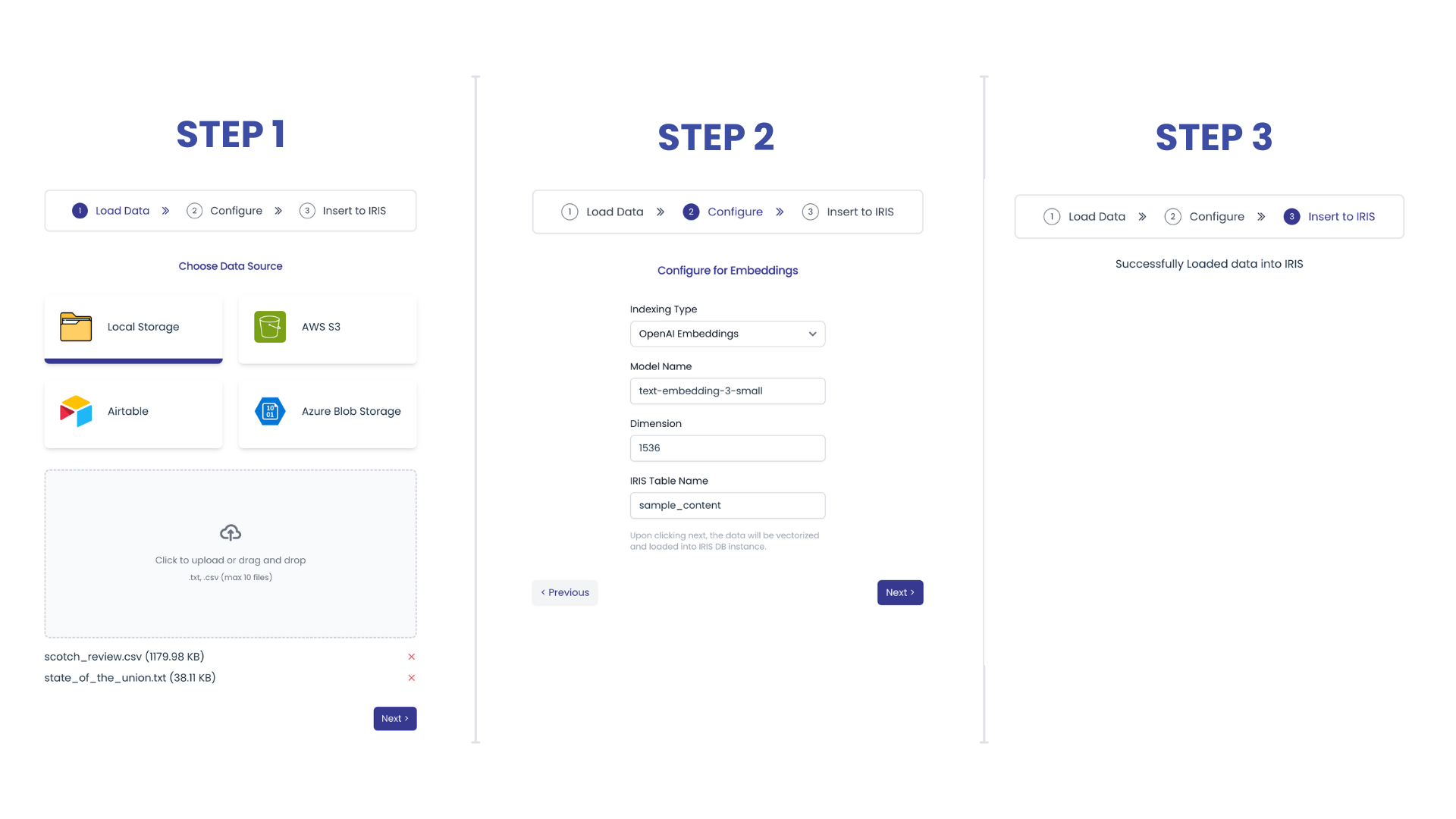
AgeSort プロパティができました。
では、AgeSort プロパティの詳細設定を変えます。詳細ペインの [表現] に以下の式を設定します。
$CASE($LENGTH(%source.Age),2:%source.Age,:"0"_%source.Age)Ageが1ケタの場合は、頭にゼロを付けるという式ですね。
InterSystems IRIS 2024.2 と InterSystems IRIS for Health 2024.2 の最初の開発者プレビューが WRC プレビューダウンロードページ に公開されました。このプレビューではコンテナ版は準備できていませんが、次回にはコンテナ版も公開する予定です。
今回のリリースは、これまで公開してきた開発者プレビュー版の中で一番早いリリースサイクルになります。それもあり、「本リリースの注目点」と呼べる機能はまだありません。今後のプレビューリリースで機能一覧の準備が整い次第、すぐにお伝えいたします。
ドキュメントは以下のリンクからご覧いただけます。
本リリースでは、すべてのサポート対象プラットフォーム向けに、従来のインストーラ形式を提供します。サポート対象プラットフォーム一覧は、こちらのドキュメント をご覧ください。
インストーラとプレビュー用ライセンスキーは、WRC プレビューダウンロードページ もしくは 評価サービスページ ("Show Preview Software" フラグをチェックしてください) から入手いただけます。
IRIS BIチュートリアル試してみたシリーズの4回目です。
今回からはチュートリアルの3ページ目、「キューブの作成」に沿って進めていきます。
では、早速はじめていきたいと思います。
キューブの作成はアーキテクト画面から行います。
管理ポータル画面のメニューで、 Analytics → アーキテクト を選択します。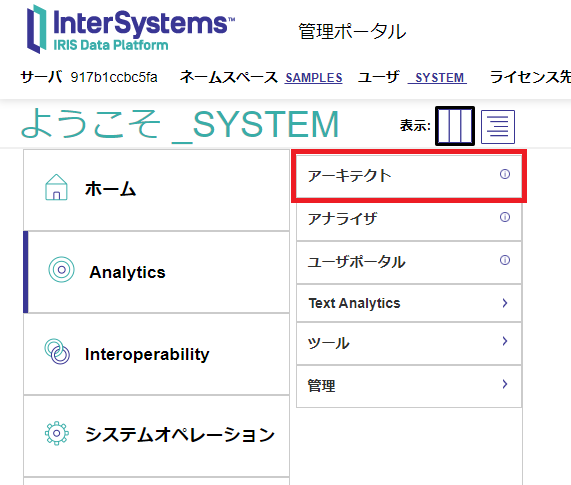
アーキテクト画面が開きました。1回目の記事の作業のときに Patientsキューブを開いたので、私の環境では再びPatientsキューブが表示されました。
新しいキューブを作成しますので、[新規] ボタンをクリックします。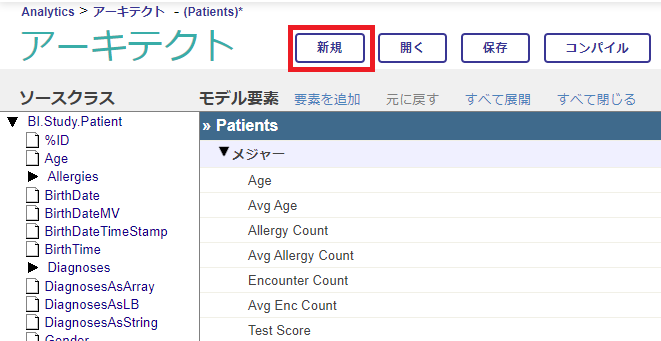
ダイアログが開いたら、以下のように指定していきます。
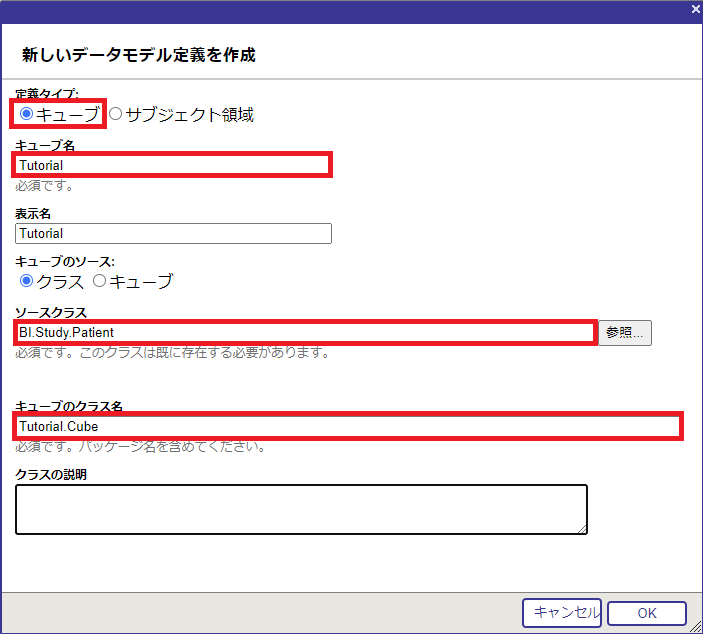
ソースクラスの指定は、[参照] ボタンを押してダイアログから行うこともできます。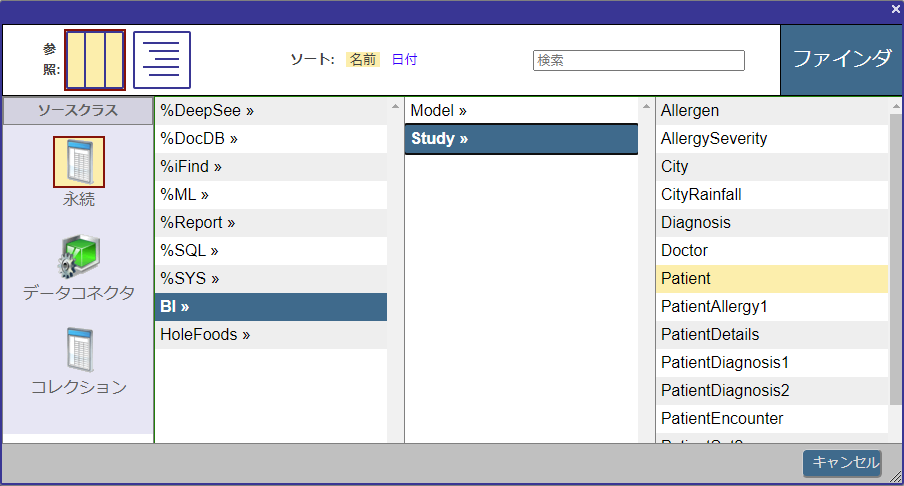
最後に [OK] をクリックしますと、まっさらな画面が表示されます。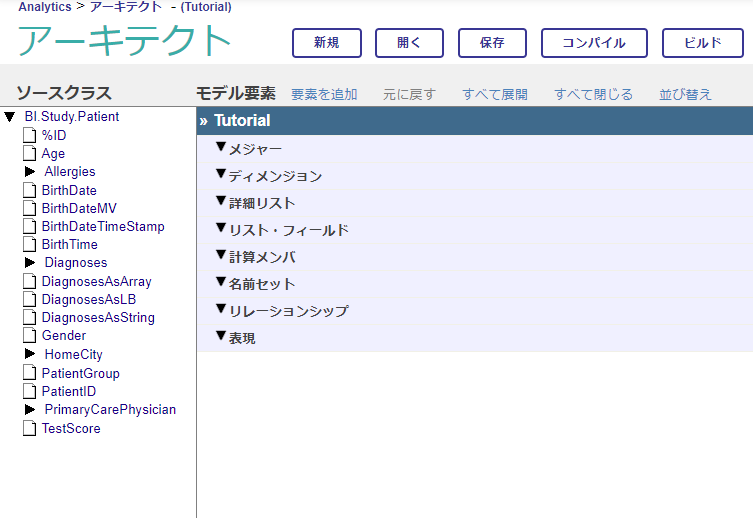
もし、以下のようなダイアログが表示されたら、[Leave] を選択してください。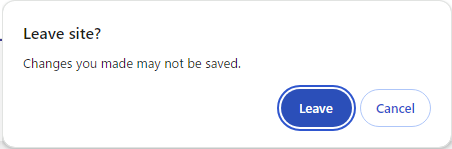
アーキテクト画面ですが、3つのエリアで構成されています。左側から順に、クラス・ビューワ、モデル・ビューワ、詳細ペインです。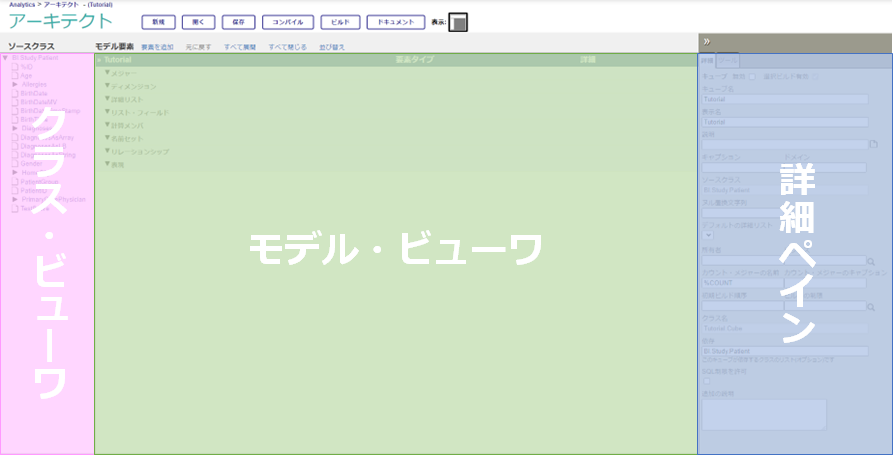
開発者の皆さん、こんにちは!
(2024.4.17更新:コンテストタイトルに「ベクトル検索」を追加しました)
次の InterSystems オンラインプログラミングコンテストのテーマが決定しました!👉生成 AI、ベクトル検索、機械学習 です!
🏆 InterSystems ベクトル検索、GenAI、ML コンテスト(USコミュニティ) 🏆
期間: 2024年4月22日~5月19日
賞金総額: $14,000
.jpg)
開発者の皆さん、こんにちは。
こちらの記事👉「Apache Webサーバ(プライベートWebサーバ: PWS)インストレーションの廃止」でご案内していましたが、コミュニティエディションを除くInterSystems製品のバージョン2023.2以降では、プライベートWebサーバ(*)を使用した管理ポータル/Webアクセスを非推奨に変更しました。
(*)プライベートWebサーバとは、バージョン2023.1以前のInterSystems製品をインストールすると自動でインストールされる簡易的なApacheで、52773番ポートで管理ポータルやWebアクセスのテストにご利用いただけるWebサーバです。(本番運用環境には適さない簡易的なWebサーバです)
新規インストール/アップグレードインストールによるプライベートWebサーバの利用可否やインストール時の選択項目の違いについての概要は以下表をご参照ください。


人工知能は、命令によってテキストから画像を生成したり、単純な指示によって物語を差作成したりすることだけに限られていません。
多様な写真を作成したり、既存の写真に特殊な背景を含めたりすることもできます。
また、話者の言語や速度に関係なく、音声のトランスクリプションを取得することも可能です。
では、ファイル管理の仕組みを調べてみましょう。
みなさんこんにちは! 今回は、IRIS 2024.1で実験的機能として実装されたVector Search (ベクトル検索)について紹介します。ベクトル検索は、先日リリースされたIRIS 2024.1の早期アクセスプログラム(EAP)で使用できます。IRIS 2024.1については、こちらの記事をご覧ください。
ChatGPTをきっかけに、大規模言語モデル(LLM)や生成AIに興味を持たれている方が増えていると思います。開発者の方々の中には、中はどうなっているのか気になっている方も多いのではないでしょうか。実は、LLMや生成AIの仕組みを理解したいと思えば、ベクトルの理解は不可欠な要素となります。
ベクトルは、高校の数学で習う「あの」ベクトルのことです。が、今回は、複数の数値をまとめて扱うデータ型であるという理解で十分です。例えば、
( 1.2, -4.5 )
という感じです。この例は、1.2と-4.5という2つの数値をまとめており、数値の個数(ここでは2)のことを次元数と言います。我々の生きている場所を3次元空間と呼ぶことがありますが、これは、3つの数値で場所が特定できることを表しています(例えば、緯度、経度、標高の3つで地球上の位置を完全に特定できます)。
IRIS BIチュートリアル試してみたシリーズの3回目です。
チュートリアルの「キューブ要素の概要」ページの続きを行います。
前回同様、アナライザを操作しながらキューブの要素について説明していきます。
では、早速はじめていきましょう。
Allメンバとは、ディメンジョンの中の特殊なメンバ、とでも言えばよいでしょうか。
チュートリアルでは
「All メンバは、ベース・クラスの全レコードを参照します。」
と表現しています。分かったような、分からないような。。
実際に使ってみて、どのようなものか理解を深めましょう。
Patientsキューブでは、AgeD ディメンジョンの中に All Patients という名前で作成されています。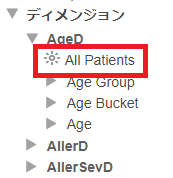
画面左上の [新規] ボタンをクリックして、新しいピボットテーブルを作成します。
AgeD ディメンジョンの Age Group レベルを [行] に指定し、メジャーの Patient Count、Avg Age、Avg Test Score を [メジャー]に指定します。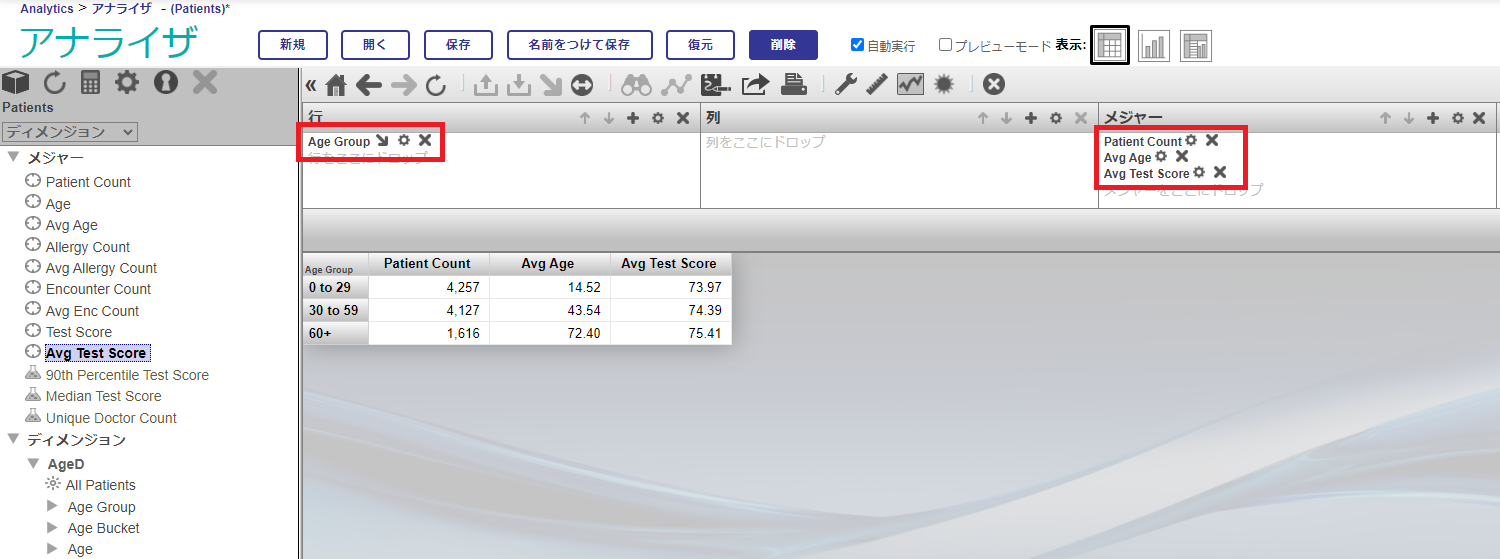 ※注意:サンプルデータはランダムに作成されるため、こちらの画面表示とみなさまの実行結果は一致しないことがあります。
※注意:サンプルデータはランダムに作成されるため、こちらの画面表示とみなさまの実行結果は一致しないことがあります。
では、この状態でピボット・オプション・ボタンをクリックします。画面上側にある、スパナのイラストのアイコンです。
![]()
皆さんもご存知のように、人工知能の世界はもう生活の中に存在しており、誰もが利用従っています。
多数のプラットフォームが、無料、サブスクリプション、または非公開の形式で、人工知能サービスを提供していますが、 コンピューティングの世界で「話題」となったことから、特に注目されているサービスは OpenAI です。最も有名な ChatGPT および DALL-E が主な原因と言えます。
ここで、明白に進化をみることができます! GPT-3(2020 年)は、達成したいことを示した十分な入力を使ってトレーニングする必要がありましたが、現行の GPT-4 バージョンでは自然言語を使用することができるため、入力をより簡単に提供することができます。 これで、命令の意図を理解するだけでなく、それ自体が話している内容を理解している「ように見えます」。
現在は、Gary Marcus が 2020 年に GPT-2 用に作成した同じ例を使用した場合、期待どおりの結果を得られます。
OpenAI は現在、驚くほどの速さで大幅に進化した一連のツールを提供しており、適切に組み合わせれば、以前よりも効率的な結果をはるかに簡単に得ることができます。
これは InterSystems FAQ サイトの記事です。
Caché 2016.2以降(IRISはすべてのバージョン)で、クエリプランの凍結機能 が実装されました。
この機能により、メジャーバージョンのアップグレードを行った場合、既存のクエリプランは自動的に凍結(※)されます。
※2023.1以降のバージョンより、アダプティブモードが無効の場合のみ、クエリプランが自動的に凍結されます。有効の場合は、既存のクエリプランは無効になり、新しいシステムでクエリの最初の実行時に新しい最適化されたクエリプランを生成します。既定は有効です。
こちらのトピックでは、
「新しいバージョンにしたのに、一部のクエリで思うようなパフォーマンスが出ない」
「凍結プランが使用されている場合、新しいプランでパフォーマンスがどのくらいでるのかを知りたい」
という場合の確認手順について、ご説明します。
Frozen Plan (古いバージョンと同じプラン)を使用していて思ったようなパフォーマンスが出ない場合、凍結を解除して新しいプランを試すことが可能です。
新しいプランを試したい場合は、%NOFPLANキーワードをつけてクエリを実行します。
%NOFPLANを付けた方がパフォーマンスが良ければ、プラン凍結を解除して新しいプランで実行するようにします。
インターシステムズがこの機能を導入したのは何年も前のことであり、公開鍵インフラストラクチャの利用がまだ広まっていなかった時代でした。
現在では、公開鍵インフラストラクチャを使用するための資料を作成することが広く利用できるようになり、インターシステムズ PKI の使用が減少しています。さらにインターシステムズ PKIを安全に使用するためには投資が必要となります。
IRIS PKI のドキュメントには以前より以下を記載しております。
InterSystems PKI はテスト目的のみで本番環境では使用しないで下さい。
2024 年 3 月 26 日をもって、InterSystems PKI は非推奨としました。
製品ドキュメントは更新され、以下のように記載されます。
InterSystems PKI の実装は非推奨です。将来のバージョンの InterSystems 製品から
この機能は削除される可能性があります。
このドキュメントは、 既存のユーザのための参考資料としてのみ提供されます。
インターシステムズは、ユーザが PKI 機能の使用を中止することを推奨します。
大規模言語モデル(OpenAI の GPT-4 など)の発明と一般化によって、最近までは手動での処理が非現実的または不可能ですらあった大量の非構造化データを使用できる革新的なソリューションの波が押し寄せています。 データ検索(検索拡張生成に関する優れた紹介については、Don Woodlock の ML301 コースをご覧ください)、センチメント分析、完全自律型の AI エージェントなど、様々なアプリケーションが存在します。
この記事では、IRIS テーブルに挿入するレコードに自動的にキーワードを割り当てる単純なデータタグ付けアプリケーションの構築を通じて、IRIS の Embedded Python 機能を使って、Python OpenAI ライブラリに直接インターフェース接続する方法をご紹介します。 これらのキーワードをデータの検索と分類だけでなく、データ分析の目的に使用できるる単純なデータタグ付けアプリケーションを構築します。ユースケースの例として、製品の顧客レビューを使用します。

Review クラス顧客レビューのデータモデルを定義する ObjectScript クラスの作成から始めましょう。
開発者の皆さん、こんにちは!
USコミュニティ開催の ✍️ 技術文書ライティングコンテスト: InterSystems IRIS チュートリアル ✍️ の勝者が発表されました!📣
今回は、19人のメンバーから🌟 21 の素晴らしい記事 🌟が投稿されました。
全ての記事が素晴らしい内容であったため、審査員からは3記事を選択するのが非常に難しかったとのコメントがありました。
.jpg)
それでは、受賞者の皆さんを紹介します!
IRIS BIチュートリアル試してみたシリーズの2回目です。
今回は、前回の作業でセットアップしたサンプルキューブやデータを用いてアナライザを操作します。
アナライザは、IRIS BIのキューブ等を基にピボットテーブルを作成する機能です。Excelのピボットテーブルをご存知でしたらイメージがつきやすいかもしれません。
では、早速はじめていきたいと思います。
まずはアナライザ画面を開きます。管理ポータル画面のメニューから、 Analytics → アナライザ を選択します。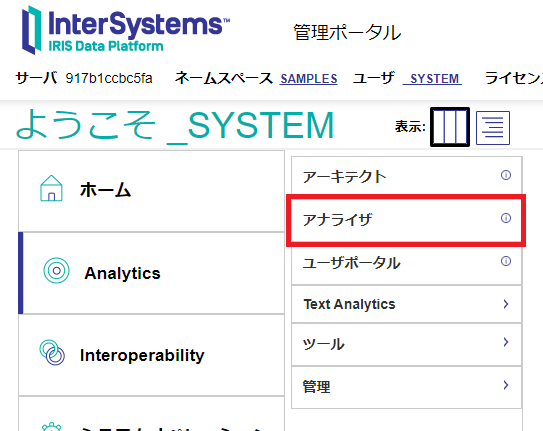
以下のような画面が表示されます。アナライザ画面は大きく3つの領域から成り立っています。
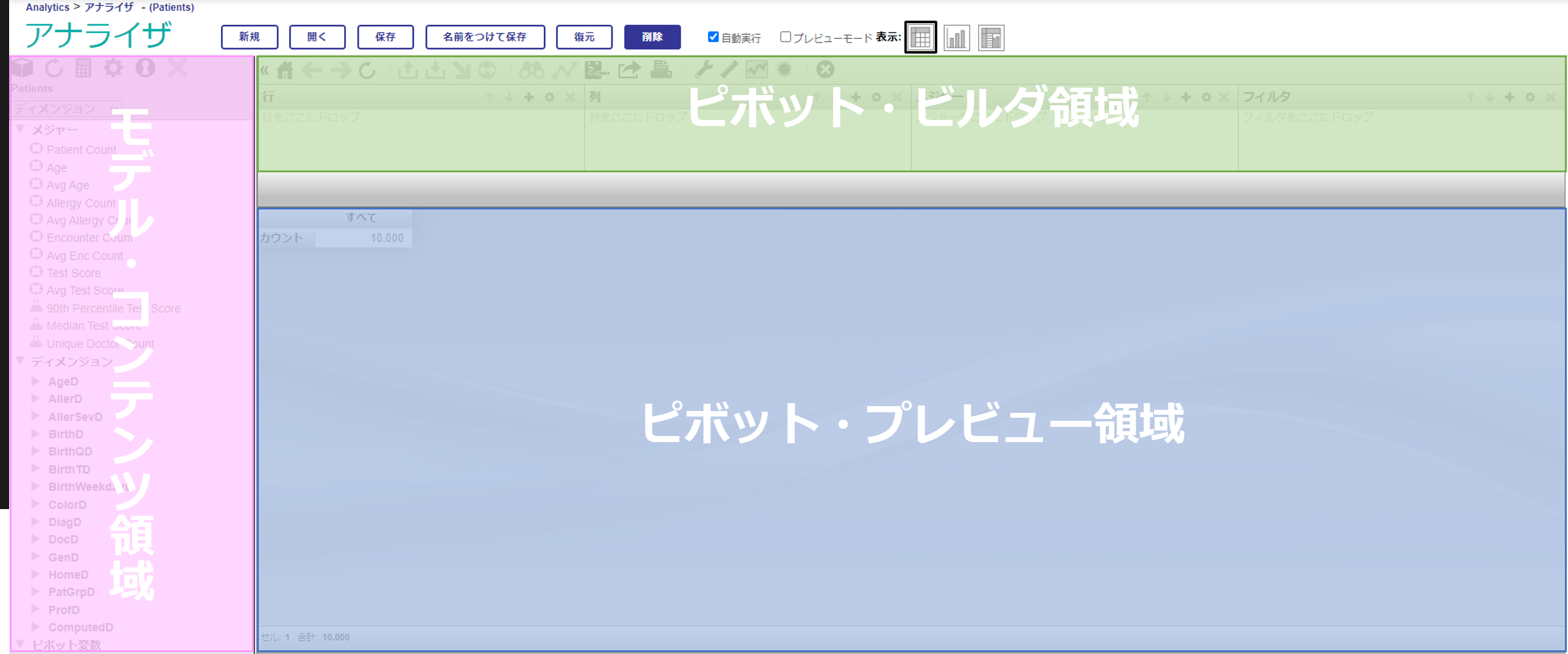
まずは、Patientsキューブを使ってモデル・コンテンツ領域を詳しく見ていきます。
モデル・コンテンツ領域にPatientsキューブが開かれていない場合には、領域左上のキューブ型のアイコンをクリックするとキューブ選択のダイアログが開きますので、そこからPatientsキューブを選択します。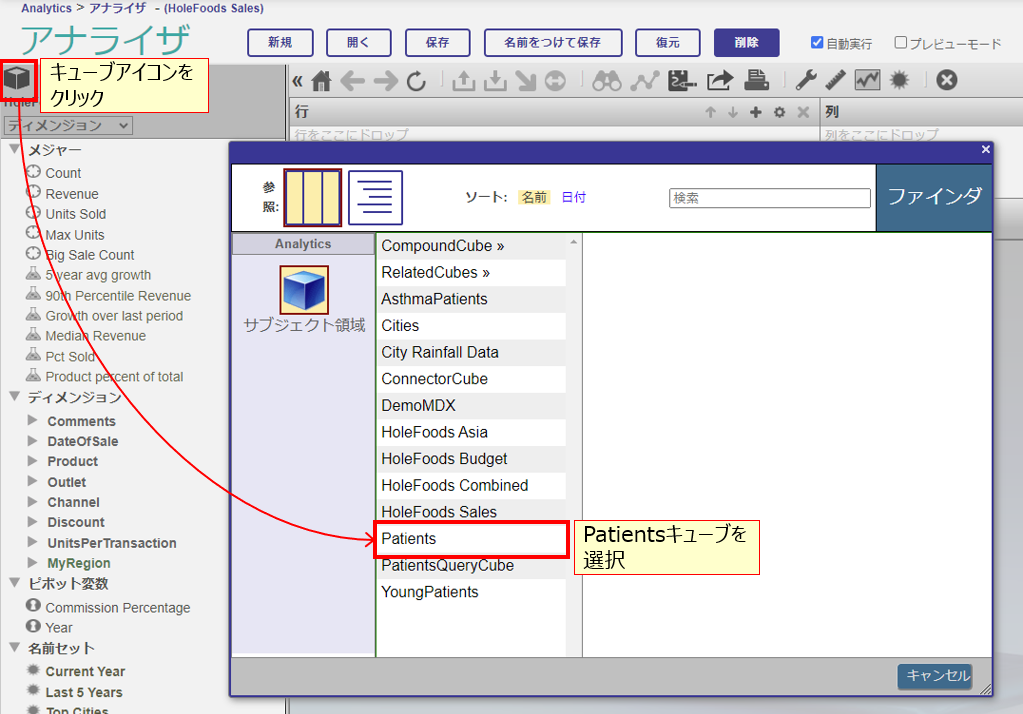
こんな状況を思い浮かべてください。「ウィジェットダイレクト」というウィジェットとウィジェットアクセサリーを販売する一流のネットショップで楽しく勤務しています。先日、上司から一部の顧客がウィジェット商品にあまり満足していないという残念な話を聞き、苦情を追跡するヘルプデスクアプリケーションが必要となりました。さらに面白いことに、上司はコードのフットプリントを最小限に抑えることを希望しており、InterSystems IRIS を使って 150 行未満のコードでアプリケーションを提供するという課題をあなたに与えました。これは実際に可能なのでしょうか?
免責事項: この記事は、非常に基本的なアプリケーションの構築を記すものであり、簡潔さを維持するために、セキュリティやエラー処理などの重要な部分は省略されています。このアプリケーションは参考としてのみ使用し、本番アプリケーションには使用しないようにしてください。この記事ではデータプラットフォームとして IRIS 2023.1 を使用していますが、それ以前のバージョンでは記載されているすべての機能が提供されているとは限りません。
クリーンなネームスペースを新規に定義することから始めましょう。CODE と DATA データベースを使用します。
バージョン 2023.3(InterSystems IRIS for Health)の新機能は、FHIR プロファイル基準の検証を実行する機能です。
 ()
()
この記事では、この機能の基本的な概要を説明します。
FHIR が重要な場合は、この新機能を絶対にお試しになることをお勧めします。このままお読みください。
開発者コミュニティのみなさん、こんにちは。
IRISには組み込みのビジネスインテリジェンス機能であるIRIS BIが備わっております。
ただし、使い方がよく分からないということから利用に至ってない方もいらっしゃるのではないでしょうか。
幸いなことに、オンラインドキュメントの中にはIRIS BIの開発者向けチュートリアルのページがあり、それに沿って作業するとIRIS BIの簡単な概要を理解することができます。
ですので、これから数回に分けてチュートリアルを実行した結果を紹介し、IRIS BIの機能や使い方について知っていただければと思います。
初回は、チュートリアル用のネームスペースにサンプルのデータやキューブなどを作成する準備作業について説明します。
なお、使用した環境ですが、Windows PC(OS: Windows 10)にIRIS 2024.1のコミュニティエディション(コンテナ版)で行っております。
チュートリアルの最初のページは「準備」です。チュートリアルを進めるためのネームスペース作成やサンプルデータの投入を行います。
必要なファイルはgithubに公開されている Samples-BI から取得します。このページのREADMEに手順(Step-by-step Installation)が記されてますので、それに沿いながら進めます。
開発者の皆さん、こんにちは!
InterSystems全製品のサーバ側コードで利用できる「ObjectScript」の基本の使い方から、困ったときのヒント集、エラーの読み方など、日本語ドキュメントの逆引きになるようなページを目指して、「ObjectScriptクックブック」を作成しました!
Hello Worldの出力から始めたい方に最適です。
2024/3/25更新:8. デバッグ方法 を追加しました。ぜひご参照ください。
ObjectScriptの記述に困ったときに読んでいただけるヒント集です。コミュニティに寄せられたご質問をどんどん掲載していきます。
ObjectScriptのプログラムでエラーが発生したときのエラーメッセージの読み方から、エラー情報の取得方法などを解説しています。
これは InterSystems FAQ サイトの記事です。
クエリパフォーマンスを左右するクエリプランは、テーブルチューニングを行った結果の統計情報を元に生成されます。
ある環境で期待したプランになったけれど、他の環境では意図したプランにならない場合、(期待したプランとなる)既存環境からテーブル統計情報をエクスポートして別の環境にインポートし、同じ統計情報をもとにしたクエリプランで実行することができます。
新規環境にてテーブルチューニングをしても思うようなパフォーマンスが出ない場合に、パフォーマンスの出ていたテスト環境と、もう一つの別の環境で同じクエリプランでの実行を試してみたい場合があるかと思います。
そんな時は、テーブル統計情報である選択性(Selectivity)とデータ数(ExtentSize)情報等をエクスポートして、対象環境にインポートする方法が使用できます。
もちろん、データの偏りによってクエリオプティマイザが適切だと判断して作成したプランが最適だと考えられますが、どうしても思うようなパフォーマンスが出ない場合に、原因調査も含めてこちらの方法をお試しください。
以下のように統計情報をエクスポート/インポートすることで、同じテーブル統計情報=同じクエリプラン で実行することが可能となります。
インターシステムズは、InterSystems IRIS for Health および HealthShare Health Connect の2024.1 リリースを一般提供開始(GA) したことを発表しました。
リリースハイライト
今回のリリースには、以下のような数々の興味深いアップデートが含まれます:
1. Smart on FHIR 2.0.0のサポート
2. FHIR R4オブジェクトモデルの生成
3. FHIR クエリのパフォーマンス向上
4. プライベート・ウェブ・サーバー(PWS)の削除
5. その他
ドキュメント
注目機能の詳細は、以下のリンクからご覧いただけます。(英語)
また、このリリースに関連するアップグレード情報については、こちらのリンクをご覧ください。
本バージョンではプライベートWebサーバを使用した管理ポータル/Webアクセスが非推奨となりました。詳細についてはこちらをご参照ください。
早期アクセス・プログラム(EAP)
現在、多くのEAPが用意されています。
InterSystems は先日、Visual Studio Code(VSC)IDE 用の拡張機能は InterSystems Studio に比べてより優れたエクスペリエンスを提供するという考えから、VSC IDE 用の拡張機能を独占的に開発するためにバージョン 2023.2 より InterSystems Studio のサポートを終了すると発表しました。それ以来、VSC に切り替えた開発者や、VSC を使用し始めた開発者が大勢います。 VSC には Studio のような出力パネルがなく、InterSystems が開発したプラグインをダウンロードする以外に IRIS ターミナルを開く統合機能もないため、多くの人は演算を実行する際にターミナルの開き方に迷ったことでしょう。
この記事では、FHIR を理解し、FHIR アーティファクトを使用するアプリケーションを開発できるようにするために clinFHIR アプリケーションを使用する方法を説明しています。 FHIR の紹介を意図したものではなく、学習 / 開発の過程で clinFHIR がどのように役立てられるかを説明しています。 相応に概要レベルでの説明となっています。その他の情報は、特に私の個人ブログで提供しています。
FHIR を使用している方は、FHIR チャットに参加することをお勧めしています。ほとんどのエキスパートが参加しているため、FHIR コミュニティに質問するのに最適な手段です。 また、アプリ固有の質問には clinfhir ストリームもあります。
まずは、背景から少し説明します。
10 年前に初めて FHIR を開発していた頃、FHIR が一体何であるかを可視化できる必要性があることが明確になりました。 リソースとは何か、どのように使用して特定のユースケースを表現できるのか、用語はどのように機能するのかといったことです。 これは特に、臨床分野のオーディエンスにおいて必要であったため、「clinical FHIR」を短縮して「clinFHIR」という名前になりました。
それ以来、clinFHIR は FHIR の数々のバージョンを重ね、モジュールの追加や削除を繰り返し進化してきました。
%Installerという特別なツールを使用すると、目的のIRIS構成を記述するインストールマニフェストを定義できることはご存じでしょうか?
インストールマニフェストに作成したい IRIS 構成を記述すると、インストール中、またはターミナルやコードからマニフェストを実行した際に、構成設定が適用されます。
インストールマニフェストについては、以下の記事でご紹介しておりますので是非ご覧ください(Cachéの記事になりますがIRISでも同様です)。
%InstallerでInterSystems Cachéにアプリケーションをデプロイする
こちらの記事では、実際にマニフェストで追加できる主な項目について、サンプルコードとあわせてご紹介します。
今回は、以下の機能の設定例をご紹介します。
1. ライセンスファイルのコピーと適用
2. ネームスペース・データベースの作成
3. 構成情報(ポートやデータベースキャッシュ・メモリ設定など)の適用
4. セキュリティ情報(ユーザ・サービスなど)のインポート ※同一バージョンのみ
5. セキュリティ情報(ユーザ・ロールなど)の作成
6. SQL情報の作成
7. ジャーナル情報の作成
8. ユーザ作成クラスやグローバルのインポート、メソッドの実行
9.
これは InterSystems FAQ サイトの記事です。
インスタンスの開始が失敗し、コンソールログに"There exists a MISMATCH.WIJ file"が記録されている場合、何らかのシステム障害の影響でデータベースの整合性に関して問題が生じていることを示しています。
このような状況が発生した際にインスタンスの開始ができるようにするためには、以下の手順を実施します。
(1) a. インスタンスをNOSTUモードで起動 注1:
(2) b. データベースの整合性チェック
◆(2)の整合性チェックでエラーを検出しなかった場合、
(3) d. MISMATCH.WIJ ファイルのリネーム
(4) e. インスタンスの再起動
を実施します。
◆(2)の整合性チェックでエラーが検出された場合は、
(3) c. MISMATCH.WIJファイルの適用
(4) b. データベースの整合性チェック
(5) d. MISMATCH.WIJファイルのリネーム
(6) e. インスタンスの再起動
を実施します。
以下に各手順の詳細を説明します。
a. インスタンスをNOSTUモードで起動します。
以下に記載の手順の内、1)および2)の手順まで実行します。
3)以降は実施する必要はありません。
これは InterSystems FAQ サイトの記事です。
まず以下のようなREST APIを定義したクラスを作成します。
Class User.REST Extends %CSP.REST
{
Parameter HandleCorsRequest = 1;
XData UrlMap [ XMLNamespace = "http://www.intersystems.これは InterSystems FAQ サイトの記事です。
UTF-8(BOM付)のテキストファイルは以下のようにして作成可能です。
set f=##class(%Stream.FileCharacter).%New()
set f.TranslateTable="UTF8"
set f.BOM=($char($zhex("EF"))_$char($zhex("BB"))_$char($zhex("BF")))
set f.Filename="D:\TEST\test.txt"
set cr = $char(13)
do f.Write("1行目"_cr)
do f.Write("2行目"_cr)
set ret=f.%Save()


