今回は、InterSystems IRIS に特有のことではなく、職場で Windows 10 Pro または Enterprise を搭載した PC またはノートパソコンがサーバーとして使用されている環境で Docker を使用する場合に重要と思われる点について触れたいと思います。
ご存知かと思いますが、コンテナテクノロジーは基本的に Linux の世界で生まれ、最近では Linux のホストで使用されており、その最大のポテンシャルを伺わせています。 Windows を普段から使用するユーザーの間では、Microsoft と Docker 両社によるここ数年の重大な試みにより、Windows のシステムで Linux イメージを基にコンテナを実行することがとても簡単になったと理解されています。しかし、生産システムでの使用がサポートされておらず、それが大きな問題となっています。特に、Windows と Linux のファイルシステムに大きな違いがあるため、安心してホストシステム内でコンテナの外に持続データを保管するということができないのです。 ついには、コンテナを実行するために、Docker for Windows 自体で Linux の小さな仮想マシン (MobiLinux) が使用されるようになり、Windows ユーザーに対しては透過的に実行されます。また、先ほど述べたように、データベースの存続がコンテナよりも短くて構わないのであれば、パーフェクトに動作します。
では、何が言いたいかというと、問題を回避して処理を単純化するには、完全な Linux システムが必要になるが、Windows ベースのサーバーを使用していると、仮想マシンを使用する以外に方法がない場合が多い、ということです。 少なくとも、Windows の WSL2 がリリースされるまでの話ですが、それはまた別の機会に触れたいと思います。もちろん、十分堅牢に動作するまでは時間がかかるでしょう。
 アップデートで
アップデートで

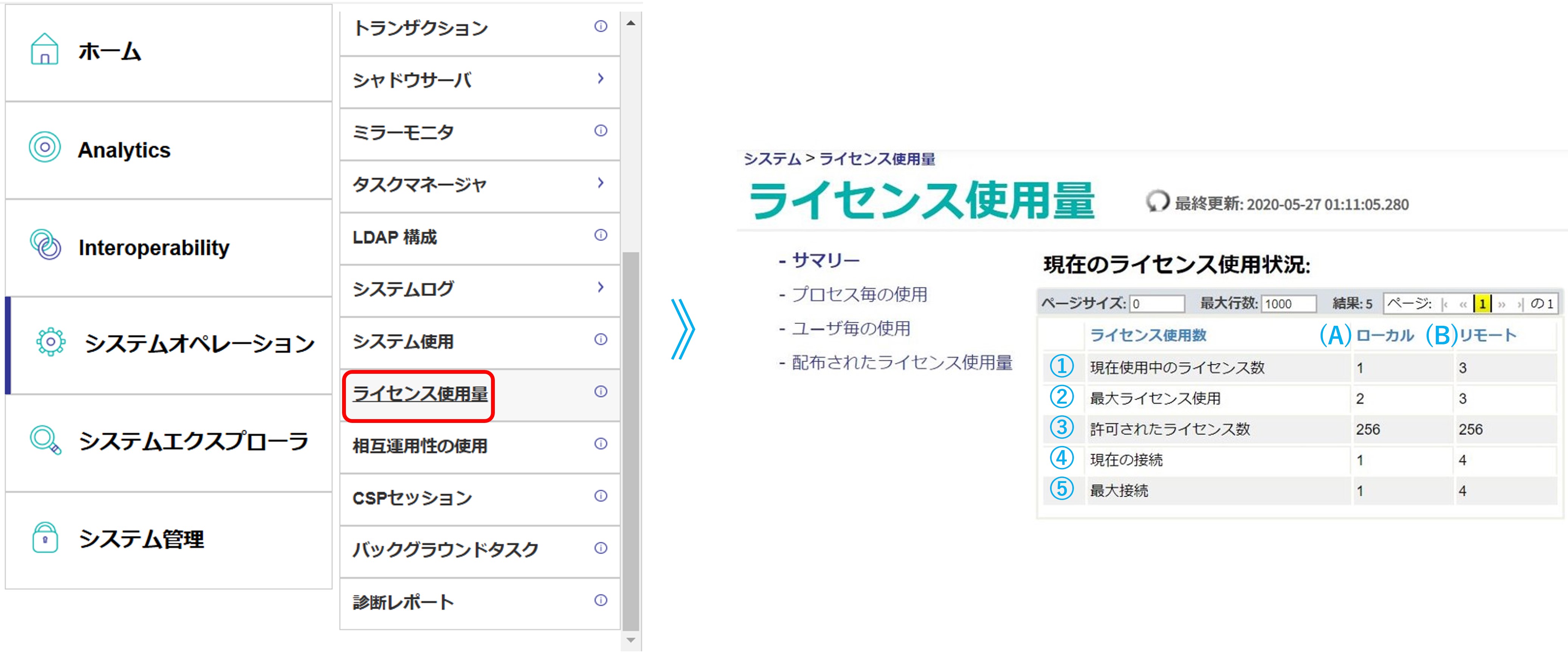 ① 現在使用中のライセンス数:現時点のライセンスユニット使用数です。
① 現在使用中のライセンス数:現時点のライセンスユニット使用数です。