Caché データベースブロックの内部構造、パート 2
この記事は Caché データベースの内部構造を説明したこちらの記事の続編です。 そちらの記事では、様々なブロックタイプ、それぞれのつながりやグローバルとの関係について説明しました。 純粋に理論を述べた記事でした。 ブロックツリーを視覚化するのに役立つプロジェクトを作成しましたので、この記事ではその仕組みを詳しく説明します。

デモを行うために、新しいデータベースを作成しましたが、Caché のデフォルト機能としてすべての新しいデータベースで初期化されるグローバルは消去しています。 それでは、シンプルなグローバルを作成しましょう。
set ^colors(1)="red" set ^colors(2)="blue" set ^colors(3)="green" set ^colors(4)="yellow"

作成されたグローバルのブロックを表す画像をご覧ください。 これはシンプルなものなので、その説明は Type 9 のブロック (グローバルカタログのブロック) に記載されています。 次にくるのが、「上位ポインタと下位ポインタ」のブロック (Type 70) です (グローバルツリーはまだ浅いため)。ここでは、まだ 8KB の単一のブロックに収まるデータブロックへのポインタを使用できます。
それでは、単一のブロックには収まりきらないほどの数の値を別のグローバルに書き込んでみます。そして、最初のブロックに収まらなかった新しいデータブロックにポイントするポインタブロックの中に新しいノードが表示されます。
それでは、それぞれ 1000 文字を持つ値を 50 個書き込んでみましょう。 このデータベースのブロックサイズは 8192 バイトであることを覚えておいてください。
set str=""
for i=1:1:1000 {
set str=str_"1"
}
for i=1:1:50 {
set ^test(i)=str
}
quit下の画像をご覧ください。

ポインタブロックレベルでデータブロックにポイントするノードがいくつかあります。 各データブロックには、次のブロックをポイントするポインタがあります (「適切なリンク」)。 Offset は、このデータブロック内で占有されているバイト数をポイントしています。
それでは、ブロックの分割をシミュレートしてみましょう。 ブロックの合計サイズが 8KB をオーバーしてしまうほどの数の値をブロックに追加しましょう。それにより、ブロックは半分に分割されます。
サンプルコード
set str=""
for i=1:1:1000 {
set str=str_"1"
}
set ^test(3,1)=str
set ^test(3,2)=str
set ^test(3,3)=str結果は以下の通りです。
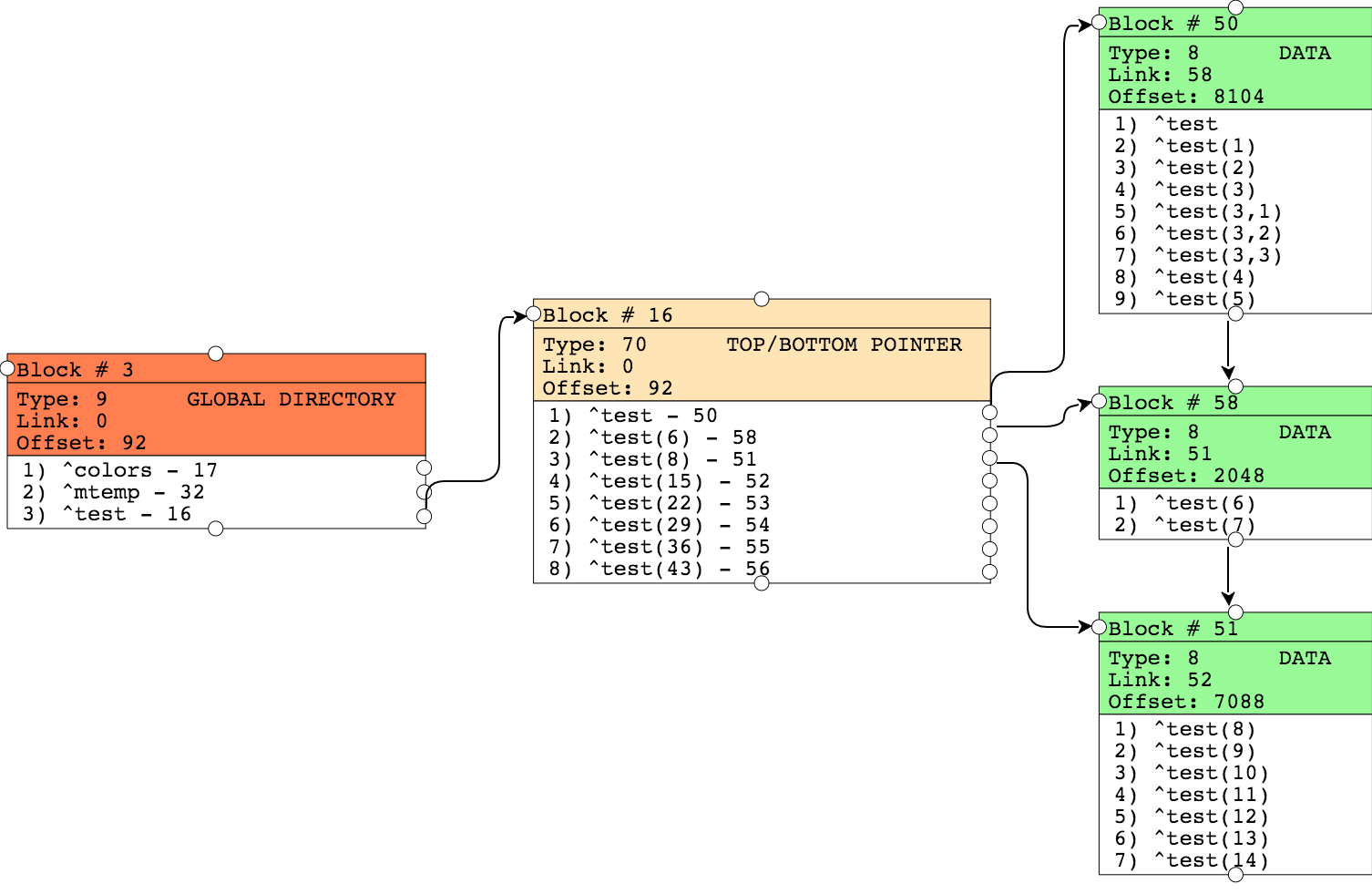
ブロック #50 が分割され、新しいデータが入っているのが分かります。 ブロック #50 から取り出された値はブロック #58 に置かれ、このブロックにポイントするポインタがポインタブロックに表示されているのが分かります。 他のブロックに変化はありません。
長い文字列を使った例
8KB (データブロックのサイズ) よりも長い文字列を使うと、「長いデータ」で構成されるブロックができます。 そのような状況は、例えば、文字列を 10000 バイトとして書き込んでシミュレートします。
サンプルコード
set str=""
for i=1:1:10000 {
set str=str_"1"
}
for i=1:1:50 {
set ^test(i)=str
}結果を見てみましょう。

結果としては、新しいグローバルノードは加えずに、値を変更しただけなので、画像に表示されているブロック構造に変更はありません。 しかし、すべてのブロックで、Offset の値 (占有されているバイト数) に変化がありました。 例えば、ブロック #51 の Offset の値は、7088 から 172 に変わっています。 新しい値がブロックに収まらない場合は、データの最後のバイトへのポインタが変更されるということが分かりました。しかし、データはどこに行ったのでしょう? 現時点では、「大きなブロック」に関する情報を示す技術的な可能性はありません。 それでは、^REPAIR ツールを使って、ブロック #51 の新しいデータに関する情報を取得してみましょう。

このツールの仕組みを詳しく説明いたします。 右側のブロック #52 へのポインタがあり、同じ番号が次のノードの親ポインタブロックで指定されているのが分かります。 グローバルの照合順序は Type 5 に設定されています。 長い文字列を持つノードの数は 7 個です。 場合によっては、1 つのブロックの中に、いくつかのノードのデータ値と別のノードの長い文字列の両方が含まれる場合があります。 また、次のブロックの先頭で予測できる次のポインタ参照も表示されています。
長い文字列のブロックについて: キーワード「BIG」がグローバルの値をとして指定されているのが分かります。 それは、データが実際には「大きなブロック」に保管されていることを意味します。 同じ行には、含まれている文字列の長さの合計とこの値を保管するブロックの一覧が表示されています。 それでは、ブロック #73 (長い文字列のブロック) を見てみましょう。
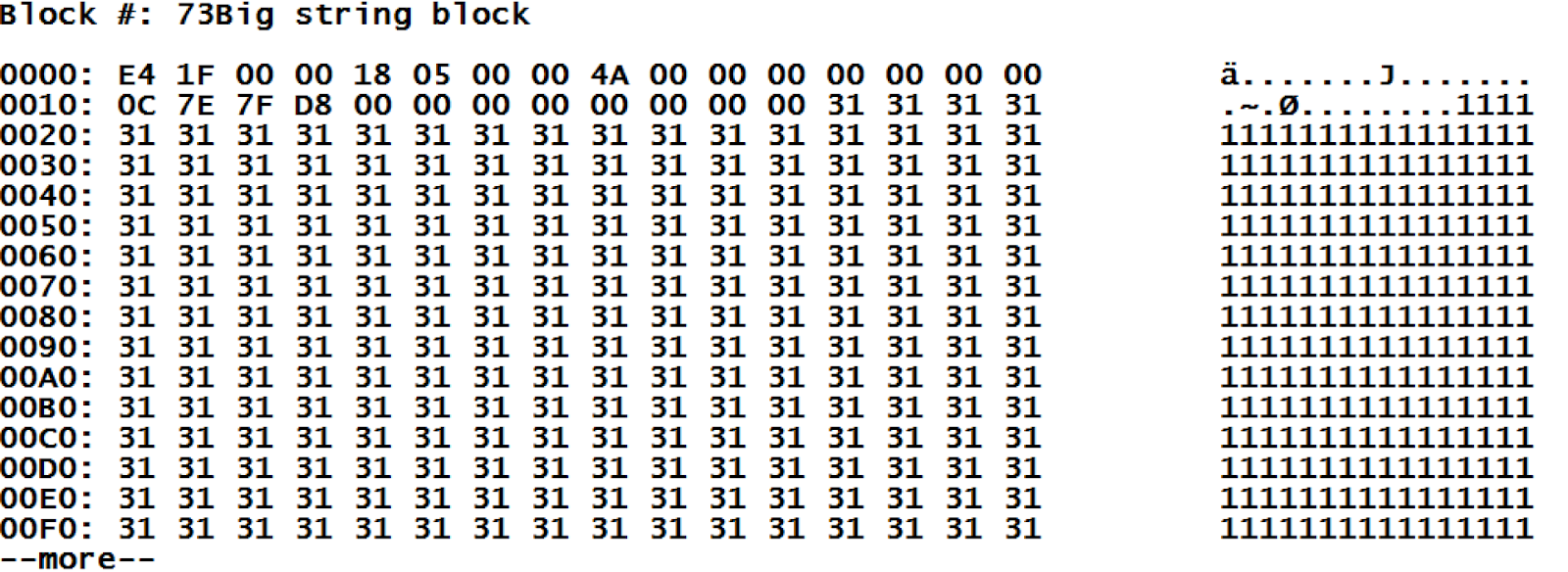
残念ながら、このブロックはエンコードされた状態で表示されています。 しかし、ブロックヘッダーのサービス情報 (長さは常に 28 バイト) に続いて、私たちのデータが表示されているのが分かります。 データ型が分かっていると、ヘッダーの内容をとても簡単にデコードできます。
| 位置 | 値 | 説明 | コメント |
| 0-3 | E4 1F 00 00 | データの最後をポイントする Offset | 8164 バイトとヘッダーの 28 バイトを合わせて合計 8192 バイトあり、ブロックは満タンです。 |
| 4 | 18 | ブロックタイプ | 記憶にあるかと思いますが、24 は長い文字列の型指定子です。 |
| 5 | 05 | 照合順序 | 照合順序 5 は「標準の Caché」を意味します |
| 8-11 | 4A 00 00 00 | 適切なリンク | ここは 74 になっています。記憶にあるかと思いますが、値はブロック #73 と #74 に保管されます。 |
ブロック #51 のデータはわずか 172 バイトしか占有していないことを覚えていますか? 大きな値を保存したにも関わらずです。 つまり、有効なデータがわずか 172 バイトとなり、ブロックはほぼ空になったように思えますが、それでも 8KB を占有しているのです! そのような場合、空きスペースには新しい値が入力されることが分かりましたが、Caché ではそのようなグローバルを圧縮することもできます。 %Library.GlobalEdit クラスに CompactGlobal メソッドがあるのはそのためです。 このメソッドの効率を確認するために、サンプルコードを使って大規模のデータを作成してみましょう。例えば、ノードを 500 個作成します。
こちらのコードを実行します。
kill ^test
for l=1000,10000 {
set str=""
for i=1:1:l {
set str=str_"1"
}
for i=1:1:500 {
set ^test(i)=str
}
}
quitすべてのブロックを表示するのは控えますが、要点は理解していただけると思います。 データブロックはたくさんありますが、ノードの数は少なくなっています。

以下のように CompactGlobal メソッドを実行します
write ##class(%GlobalEdit).CompactGlobal("test","c:\intersystems\ensemble\mgr\test")結果を見てみましょう。 ポインタブロックにはノードが 2 個しかありません。つまり、最初はポインタブロックにノードが 72 個もあったのに対し、実際はすべての値が 2 個のノードに移動されているのです。 従い、70 個ものノードを取り除いたことになり、ブロックの読み取り操作を行う回数が減ったため、グローバルをイテレーションしてデータにアクセスする時間が短縮されました。
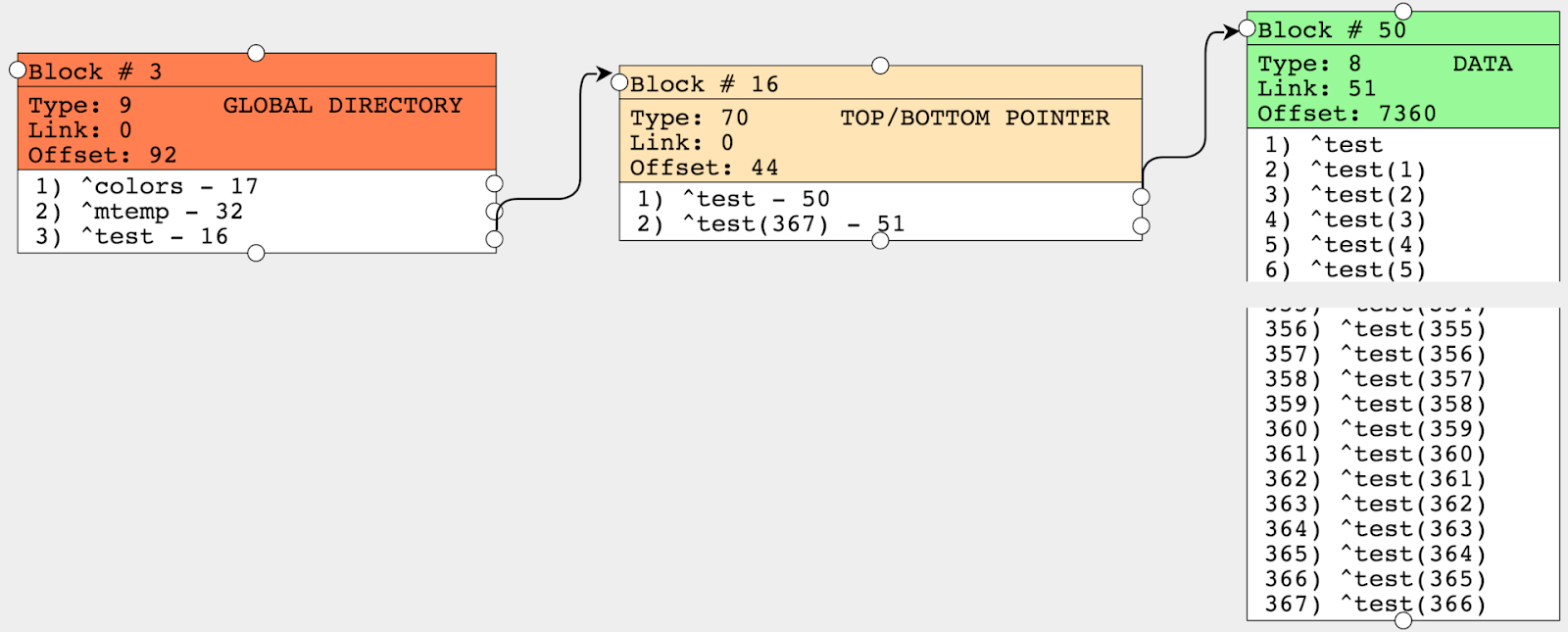
CompactGlobal には、グローバルの名前やデータベース、ターゲットとするフィル値 (デフォルトは 90%) など、様々なパラメーターを渡すことができます。 そして、Offset (占有されているバイト数) の値は 7360 となり、デフォルトのフィル値 90% に近くなったことが分かります。 関数には、処理されたメガバイト数や圧縮後のメガバイト数など、複数の出力パラメーターがあります。 以前、グローバルは、今や廃止ツールとされる ^GCOMPACT を使って圧縮されていました。
ちなみに、ブロックが部分的に満たされた状態で変化しないというのはいたって普通のことです。 また、グローバルを圧縮するのは好ましくないと考えられる場合もあります。 ですが、例えば、ほぼ読み取るだけで、変更することが滅多にないというグローバルは、圧縮すると良いかもしれません。 但し、グローバルがしょっちゅう変更される場合なら、データブロックの密度が低いと頻繁にブロックを分割する手間が省けるほか、新しいデータもより素早く保存できます。
本記事のまたさらに次の続編では、InterSystems School 2015 で初の開催となった InterSystems ハッカソン (hackathon) の最中に導入された、私自作のプロジェクトのまた別の機能「データベースブロックの分布状況を表すマップ」とその実用的な活用方法について解説いたします。