Prometheus で InterSystems Caché を監視する
Prometheus は時系列データの収集に適した監視システムです。
このシステムのインストールと初期構成は比較的簡単です。 このシステムにはデータ視覚化用の PromDash と呼ばれる画像サブシステムが組み込まれていますが、開発者は Grafana と呼ばれる無料のサードパーティ製品を使用することを推奨しています。 Prometheus は多くの要素(ハードウェア、コンテナ、さまざまな DBMS の構成要素)を監視できますが、この記事では Caché インスタンス(正確に言えば Ensemble インスタンスですが、メトリックは Caché からのものになります)の監視に注目したいと思います。 ご興味があれば、このまま読み進めてください。
非常に単純なケースでは、Prometheus と Caché は単一のマシン(Fedora Workstation 24 x86_64)上に存在します。 Caché のバージョンは以下のとおりです。
%SYS>write $zv
Cache for UNIX (Red Hat Enterprise Linux for x86-64) 2016.1 (Build 656U) Fri Mar 11 2016 17:58:47 EST
インストールと構成
公式サイトから適切な Prometheus の配布パッケージをダウンロードし、/opt/prometheus フォルダーに保存してください。
アーカイブを解凍し、必要に応じてテンプレート構成ファイルを変更してから Prometheus を起動します。 Prometheus はデフォルトでコンソールにログを表示するため、ここではアクティビティレコードをログファイルに保存することにします。
Prometheus の起動
pwd
/opt/prometheus
# ls
prometheus-1.4.1.linux-amd64.tar.gz
# tar -xzf prometheus-1.4.1.linux-amd64.tar.gz
# ls
prometheus-1.4.1.linux-amd64 prometheus-1.4.1.linux-amd64.tar.gz
# cd prometheus-1.4.1.linux-amd64/
# ls
console_libraries consoles LICENSE NOTICE prometheus prometheus.yml promtool
# cat prometheus.yml
global:
scrape_interval: 15s # スクレイプ間隔を 15 秒に設定します。 デフォルトは 1 分ごとです。
scrape_configs:
- job_name: 'isc_cache'
metrics_path: '/metrics/cache'
static_configs:
- targets: ['localhost:57772']
# ./prometheus > /var/log/prometheus.log 2>&1 &
[1] 7117
# head /var/log/prometheus.log
time=«2017-01-01T09:01:11+02:00» level=info msg=«Starting prometheus (version=1.4.1, branch=master, revision=2a89e8733f240d3cd57a6520b52c36ac4744ce12)» source=«main.go:77»
time=«2017-01-01T09:01:11+02:00» level=info msg=«Build context (go=go1.7.3, user=root@e685d23d8809, date=20161128-09:59:22)» source=«main.go:78»
time=«2017-01-01T09:01:11+02:00» level=info msg=«Loading configuration file prometheus.yml» source=«main.go:250»
time=«2017-01-01T09:01:11+02:00» level=info msg=«Loading series map and head chunks...» source=«storage.go:354»
time=«2017-01-01T09:01:11+02:00» level=info msg=«23 series loaded.» source=«storage.go:359»
time=«2017-01-01T09:01:11+02:00» level=info msg="Listening on :9090" source=«web.go:248»
prometheus.yml 構成ファイルは YAML 言語で記述されているため、タブ文字の使用は好ましくありません。したがって、スペースのみを使用する必要があります。 また、すでにお伝えしたとおり、メトリックは
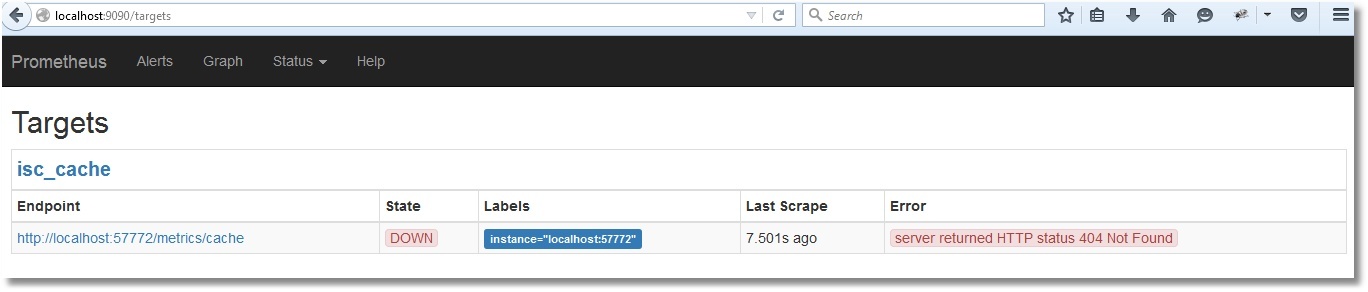
Web インターフェイスが開きます。これは、Prometheus が機能していることを意味します。 ただし、Caché のメトリックはまだ表示されていません([Status] → [Targets] をクリックして確認しましょう)。
メトリックの準備
目標は、Prometheus が
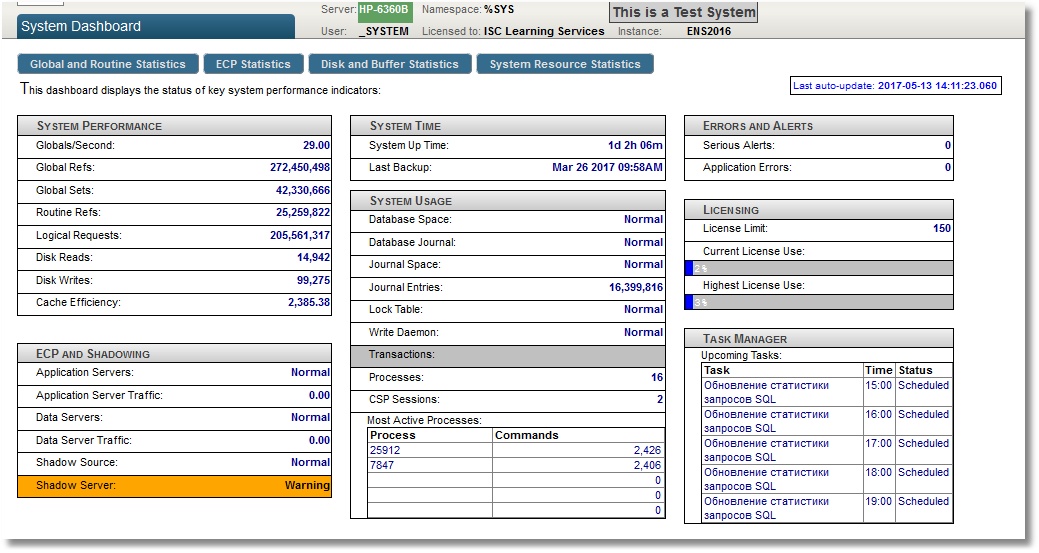
同じ内容をターミナルで表示した例:
%SYS>set dashboard = ##class(SYS.Stats.Dashboard).Sample()
%SYS>zwrite dashboard
dashboard=
<OBJECT REFERENCE>
[2@SYS.Stats.Dashboard]
+----------------- general information ---------------
| oref value: 2
| class name: SYS.Stats.Dashboard
| reference count: 2
+----------------- attribute values ------------------
| ApplicationErrors = 0
| CSPSessions = 2
| CacheEfficiency = 2385.33
| DatabaseSpace = "Normal"
| DiskReads = 14942
| DiskWrites = 99278
| ECPAppServer = "OK"
| ECPAppSrvRate = 0
| ECPDataServer = "OK"
| ECPDataSrvRate = 0
| GloRefs = 272452605
| GloRefsPerSec = "70.00"
| GloSets = 42330792
| JournalEntries = 16399816
| JournalSpace = "Normal"
| JournalStatus = "Normal"
| LastBackup = "Mar 26 2017 09:58AM"
| LicenseCurrent = 3
| LicenseCurrentPct = 2
. . .
ここでは USER スペースがサンドボックスになります。 まず、REST アプリケーションの /metrics を作成しましょう。 非常に基本的な安全対策を行うため、ログインをパスワードで保護し、Web アプリケーションをリソースに関連付けます。このようなリソースを PromResource と呼びましょう。 リソースへの公開アクセスを無効にするため、次の内容を実行してください。
%SYS>write ##class(Security.Resources).Create("PromResource", "Resource for Metrics web page", "")
1
Web アプリの設定:
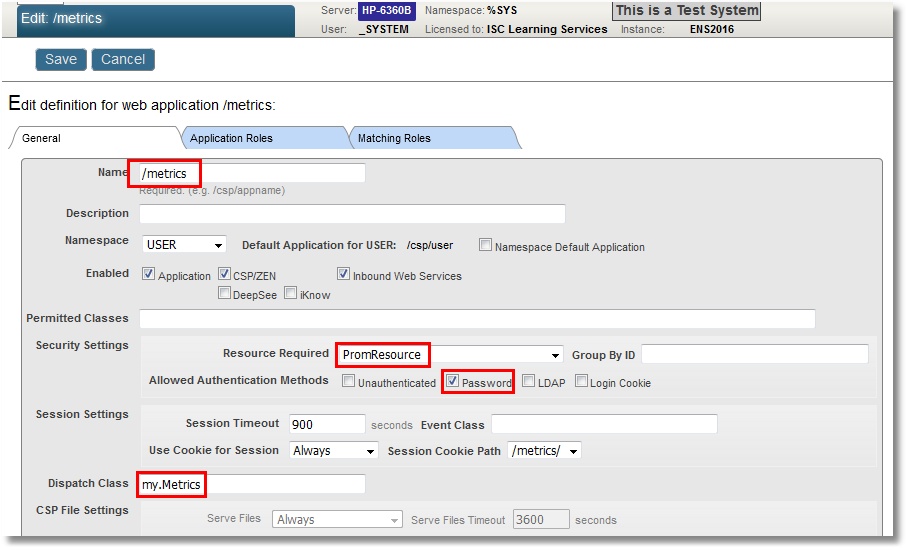
このリソースにアクセスできるユーザーも必要です。 このユーザーもデータベース(この場合は USER)から読み取り、そこへデータを保存できる必要があります。 また、別件ですがコードの後半部では %SYS スペースに切り替えるため、このユーザーには CACHESYS システムデータベースの読み取り権限が必要になります。 ここでは標準のスキームに従います。すなわち、これらの権限を持つ PromRole ロールを作成した後にこのロールに割り当てられた PromUser ユーザーを作成します。 パスワードには「Secret」を使いましょう。
%SYS>write ##class(Security.Roles).Create("PromRole","Role for PromResource","PromResource:U,%DB_USER:RW,%DB_CACHESYS:R"
1
%SYS>write ##class(Security.Users).Create("PromUser","PromRole","Secret")
1
Prometheus の構成では、この PromUser ユーザーを認証に使用します。 完了後はサーバープロセスに SIGNUP シグナルを送信し、構成を再読み込みします。
より安全な構成
cat /opt/prometheus/prometheus-1.4.1.linux-amd64/prometheus.yml
global:
scrape_interval: 15s # スクレイプ間隔を 15 秒に設定します。 デフォルトは 1 分ごとです。
scrape_configs:
- job_name: 'isc_cache'
metrics_path: '/metrics/cache'
static_configs:
- targets: ['localhost:57772']
basic_auth:
username: 'PromUser'
password: 'Secret'
#
# kill -SIGHUP $(pgrep prometheus) # または kill -1 $(pgrep prometheus)
以上で Prometheus がメトリックを含む Web アプリケーションを使用するための認証をパスできるようになりました。
メトリックは、my.Metrics リクエスト処理クラスによって提供されます。以下にその実装を示します。
Class my.Metrics Extends %CSP.REST
{
Parameter ISCPREFIX = "isc_cache";
Parameter DASHPREFIX = {..#ISCPREFIX_"_dashboard"};
XData UrlMap [ XMLNamespace = "http://www.intersystems.com/urlmap" ]
{
<Routes>
<Route Url="/cache" Method="GET" Call="getMetrics"/>
</Routes>
}
/// 出力は Prometheus の出力フォーマットに従う必要があります。 ドキュメントは以下で確認できます。
/// https://prometheus.io/docs/instrumenting/exposition_formats/
///
/// このプロトコルは行指向です。 改行文字(\n)は行を区切ります。
/// 最後の行は改行文字で終了する必要があります。 空の行は無視されます。
ClassMethod getMetrics() As %Status
{
set nl = $c(10)
do ..getDashboardSample(.dashboard)
do ..getClassProperties(dashboard.%ClassName(1), .propList, .descrList)
for i=1:1:$ll(propList) {
set descr = $lg(descrList,i)
set propertyName = $lg(propList,i)
set propertyValue = $property(dashboard, propertyName)
// Prometheusは時系列データベースをサポートします。
// そのため、空(バックアップメトリックなど)や非デジタルメトリックを
// 取得した場合はそれらを単に省略します。
if ((propertyValue '= "") && ('$match(propertyValue, ".*[-A-Za-z ]+.*"))) {
set metricsName = ..#DASHPREFIX_..camelCase2Underscore(propertyName)
set metricsValue = propertyValue
// 各メトリックの説明(ヘルプ)を記述します。
// フォーマットはPrometheusが要求するものです。
// 複数行の説明は1つの文字列に結合する必要があります。
write "# HELP "_metricsName_" "_$replace(descr,nl," ")_nl
write metricsName_" "_metricsValue_nl
}
}
write nl
quit $$$OK
}
ClassMethod getDashboardSample(Output dashboard)
{
new $namespace
set $namespace = "%SYS"
set dashboard = ##class(SYS.Stats.Dashboard).Sample()
}
ClassMethod getClassProperties(className As %String, Output propList As %List, Output descrList As %List)
{
new $namespace
set $namespace = "%SYS"
set propList = "", descrList = ""
set properties = ##class(%Dictionary.ClassDefinition).%OpenId(className).Properties
for i=1:1:properties.Count() {
set property = properties.GetAt(i)
set propList = propList_$lb(property.Name)
set descrList = descrList_$lb(property.Description)
}
}
/// キャメルケースのメトリック名を小文字のアンダースコア名に変換します
/// 例: 入力 = WriteDaemon、出力 = write_daemon
ClassMethod camelCase2Underscore(metrics As %String) As %String
{
set result = metrics
set regexp = "([A-Z])"
set matcher = ##class(%Regex.Matcher).%New(regexp, metrics)
while (matcher.Locate()) {
set result = matcher.ReplaceAll(""_"$1")
}
// 小文字にします
set result = $zcvt(result, "l")
// _e_c_p (_c_s_p) を _ecp (_csp) にします
set result = $replace(result, "_e_c_p", "_ecp")
set result = $replace(result, "_c_s_p", "_csp")
quit result
}
}
コンソールを使用して、私たちの作業が無駄ではなかったことを確認しましょう(curl がプログレスバーの表示を邪魔しないように --silent キーを追加しました)。
# curl --user PromUser:Secret --silent -XGET 'http://localhost:57772/metrics/cache' | head -20
# HELP isc_cache_dashboard_application_errors Number of application errors that have been logged.
isc_cache_dashboard_application_errors 0
# HELP isc_cache_dashboard_csp_sessions Most recent number of CSP sessions.
isc_cache_dashboard_csp_sessions 2
# HELP isc_cache_dashboard_cache_efficiency Most recently measured cache efficiency (Global references / (physical reads + writes))
isc_cache_dashboard_cache_efficiency 2378.11
# HELP isc_cache_dashboard_disk_reads Number of physical block read operations since system startup.
isc_cache_dashboard_disk_reads 15101
# HELP isc_cache_dashboard_disk_writes Number of physical block write operations since system startup
isc_cache_dashboard_disk_writes 106233
# HELP isc_cache_dashboard_ecp_app_srv_rate Most recently measured ECP application server traffic in bytes/second.
isc_cache_dashboard_ecp_app_srv_rate 0
# HELP isc_cache_dashboard_ecp_data_srv_rate Most recently measured ECP data server traffic in bytes/second.
isc_cache_dashboard_ecp_data_srv_rate 0
# HELP isc_cache_dashboard_glo_refs Number of Global references since system startup.
isc_cache_dashboard_glo_refs 288545263
# HELP isc_cache_dashboard_glo_refs_per_sec Most recently measured number of Global references per second.
isc_cache_dashboard_glo_refs_per_sec 273.00
# HELP isc_cache_dashboard_glo_sets Number of Global Sets and Kills since system startup.
isc_cache_dashboard_glo_sets 44584646
これで、Prometheus のインターフェースで同じ内容を確認できるようになりました。
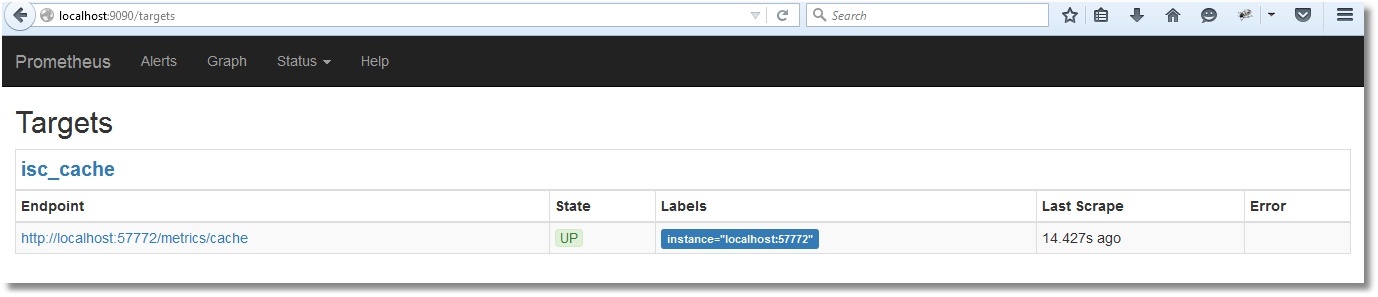
以下は上記メトリックのリストです。
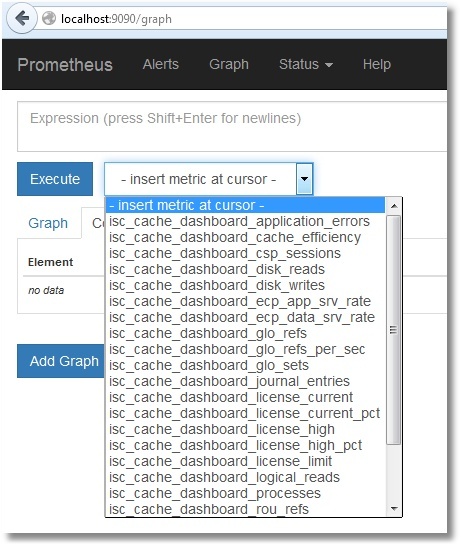
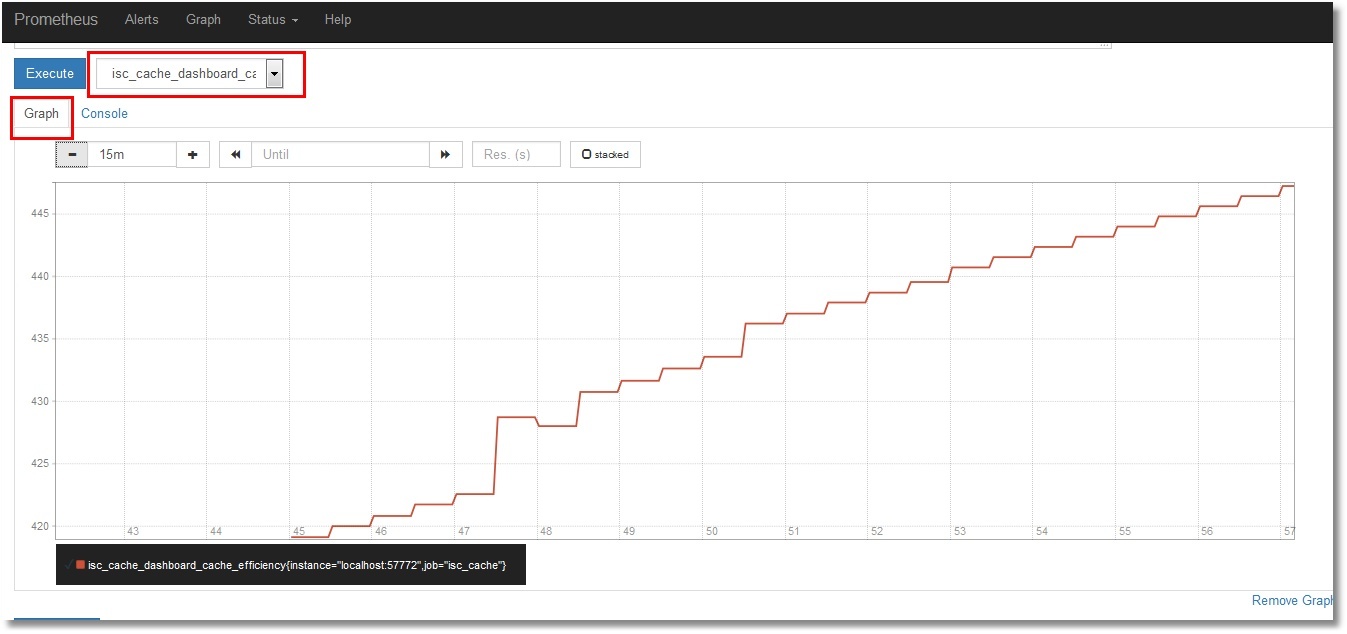
これらのメトリックの Prometheus での表示内容については詳述しません。 必要なメトリックを選択して「Execute」ボタンをクリックしてください。 「Graph」タブを選択すると、グラフが表示されます(キャッシュの効率が表示されます)。
メトリックの視覚化
メトリックを視覚化するため、Grafana をインストールしましょう。 この記事では、tarball からインストールすることにしました。 ただし、パッケージからコンテナまで、他のインストール方法もあります。 次の手順を実行してみましょう(/opt/grafana フォルダーを作成し、そこに切り替えた後)。
とりあえず設定は変更せずにそのままにしておきましょう。 最後のステップでは、Grafana をバックグラウンドモードで起動します。 Prometheus の場合と同じように、Grafana のログをファイルに保存します。
# ./bin/grafana-server > /var/log/grafana.log 2>&1 &
デフォルトでは、3000 番ポートで Grafana の Web インターフェースにアクセスできます。 ログイン/パスワードは、admin/admin です。

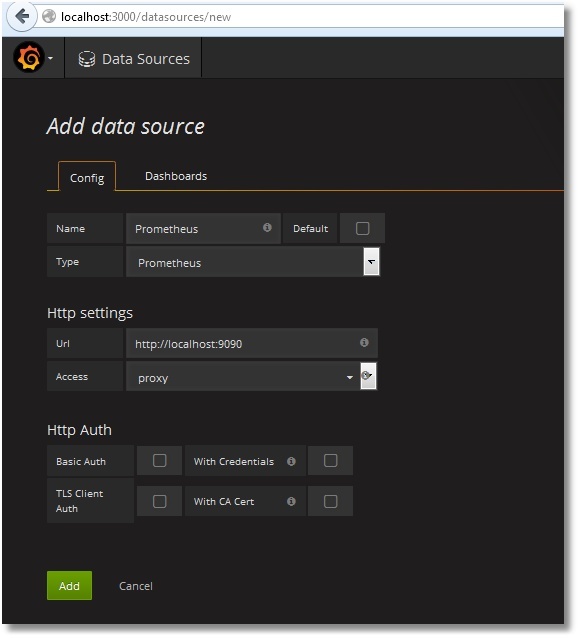
詳細な Prometheus と Grafana の連携手順については、こちらを参照してください。 簡単に言えば、Prometheus タイプの新しいデータソースを追加する必要があります。 また、次のように direct/proxy アクセスのオプションを選択してください。
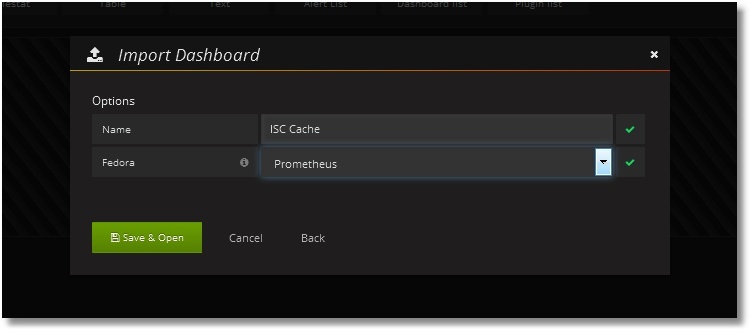
完了後、必要なパネルを含むダッシュボードを追加する必要があります。 ダッシュボードのテストサンプルは、メトリック収集クラスのコードと共に公開されています。 ダッシュボードは Grafana に簡単にインポートできます([Dashboards] → [Import])。
インポート後、次のようになります。
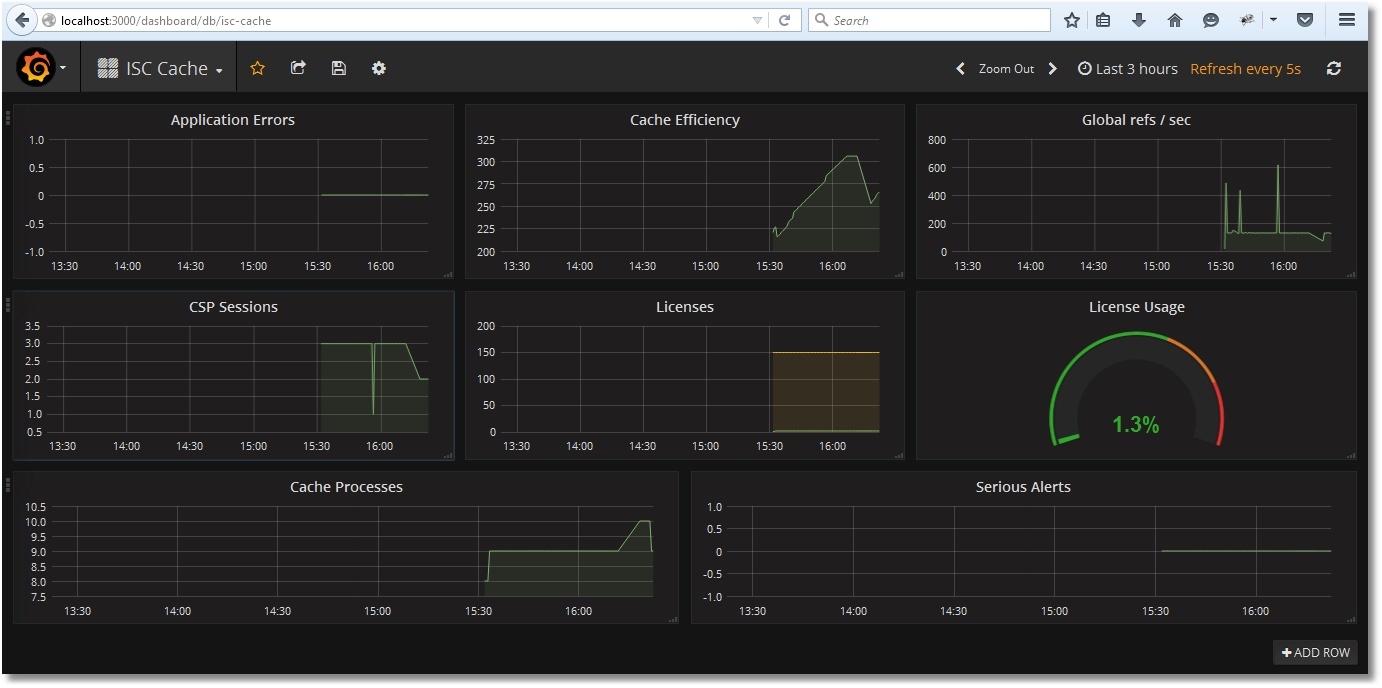
ダッシュボードを保存します。
時間範囲と更新間隔は右上で選択できます。
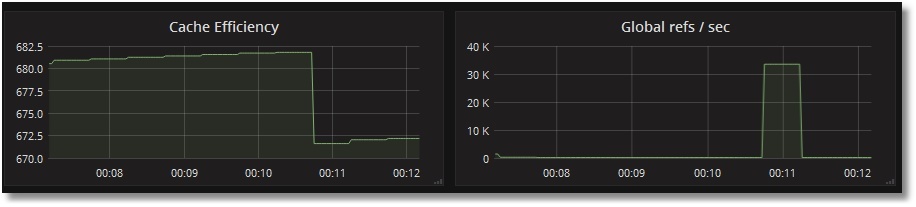
監視種類の例
グローバルへの呼び出しの監視をテストしてみましょう。
USER>for i=1:1:1000000 {set ^prometheus(i) = i}
USER>kill ^prometheus
以下のグラフでは、1秒あたりのグローバルへの参照数が増加してキャッシュ効率が低下していることが分かります(^Prometheus グローバルがまだキャッシュされていない)。
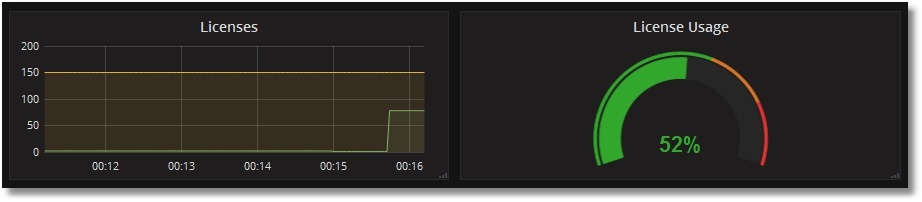
ライセンスの使用状況を確認しましょう。 そのためには、次のように PromTest.csp というプリミティブな CSP ページを USER ネームスペースに作成しましょう。
監視は正常に機能しています!
そして、何度もアクセスしてください(/csp/user アプリケーションがパスワード保護されていないことを想定しています)。
# ab -n77 http://localhost:57772/csp/user/PromTest.csp
ライセンスの使用状況について、次の図が表示されます。
まとめ
ご覧のとおり、監視機能の実装はまったく難しくありません。 いくつかの初期手順を実行しただけでも、ライセンスの使用状況、グローバルキャッシュの効率、アプリケーションエラーなど、システムの動作に関する重要な情報を取得できます。 このチュートリアルでは SYS.Stats.Dashboard を使用しましたが、SYS / %SYSTEM / %SYS パッケージの他のクラスも注目に値します。 また、特定タイプのドキュメントの数など、独自アプリケーションのカスタムメトリックを提供する独自のクラスを作成することもできます。 いくつかの有用なメトリックは、最終的に Grafana 用の個別テンプレートにコンパイルされます。
今後の予定
本件についてより詳細な情報が必要な場合は、このテーマを詳しく説明するつもりです。 以下に私の予定を記しておきます。
-
ログデーモンのメトリックを含む Grafana テンプレートの準備について。 ^mgstat と同等の、少なくともそのメトリックに対応した何らかのグラフィカルツールを作成するのが望ましいと考えています。
-
Web アプリケーションのパスワード保護は優れていますが、証明書を使用できる可能性を確認するのが望ましいと考えています。
-
Prometheus、Grafana、および Prometheus を Docker コンテナとしてエクスポートするツールの使用について。
-
新しい Caché インスタンスを Prometheus の監視リストに自動追加するための検出サービスの使用について。 また、Grafana とそのテンプレートの利便性を(実際に)説明したいと考えています。 これは、選択した特定のサーバーのメトリックがすべて同じダッシュボードに表示される動的なパネルのようなものです。
-
Prometheus Alertmanager について。
-
データの保存期間に関連する Prometheus の構成設定、および多数のメトリックと短い統計収集間隔を持つシステムに考えられる最適化について。
-
途中で発生するさまざまで微妙な差異について。
リンク
この記事を準備中にいくつかの有益なサイトにアクセスし、次のようなたくさんの動画を視聴しました。
最後までお読みいただき、ありがとうございました!
Comments
監視ツールのことで申し訳ございませんが、興味があり質問があるのでお教えいただけないでしょうか。
・このツールは無料なのでしょうか? もしくは有料でしょうか?
・Cache'やEnsembleを監視できるということですが、CPU、メモリ、DISK、その他サービスの監視などもできるのでしょうか?
(例えばEnsembleのメッセージログでDISKいっぱいになる前に知りたい)
・閾値を設定しそれを超えた場合は、管理者にメール送信することなども可能でしょうか?
・Cache'やEnsembleが動作しているサーバーとは別のサーバーから監視するのか、もしくは同じOSにインストールして監視するのでしょうか?
・Cache'やEnsembleの監視の動作実績はありますでしょうか? またIRISを監視対象にすることもできるのでしょうか?
よろしくお願いします。
ありがとうございます。
Prometheousはフリーソフトでシステムの監視を行うソフトウェアで、RESTインターフェースを使ってJson形式で監視データをやり取りしています。アーキテクチャは(https://prometheus.io/docs/introduction/overview/#architecture)を参照ください。
基本的に監視サーバから監視対象サーバのExporterにアクセスし、監視データを取得する仕組みになっており、閾値を超えるとAlert Managerに通知され、メールやSlackなど様々な通知が行えるようになっています。
また、grafanaという視覚化(グラフ表示等)ツールを使って推移を確認することもできます。
監視データの取得については仕様に基づいて様々なハードウェア、OS、ミドルウェアの監視データを提供するExporterが公開されています。(https://prometheus.io/docs/instrumenting/exporters/)
この記事ではCacheやEnsembleのRESTインターフェースでExporterを作成していますが、IRISは標準でPrometheousの監視データを提供する機能が備わっています。
InterSystemsではPrometheousやGrafanaの機能を使用したInterSystems SAMを公開しており、簡単な設定でIRISを監視できるようにしています。
以下の記事もご確認頂ければと思います。
InterSystems System Alerting and Monitoring (SAM)を使ってみました!
よろしくお願いします。
早速のご回答、ありがとうございました。
やりたいことは出来ると思いました。