InterSystemsのテクノロジースタックを使用して独自のアプリを開発し、顧客側で複数のデプロイを実行したいとします。 開発プロセスでは、クラスをインポートするだけでなく、必要に応じて環境を微調整する必要があるため、アプリケーションの詳細なインストールガイドを作成しました。この特定のタスクに対処するために、インターシステムズは、%Installer(Caché/Ensemble)という特別なツールを作成しました 。 続きを読んでその使用方法を学んでください。
%Installer
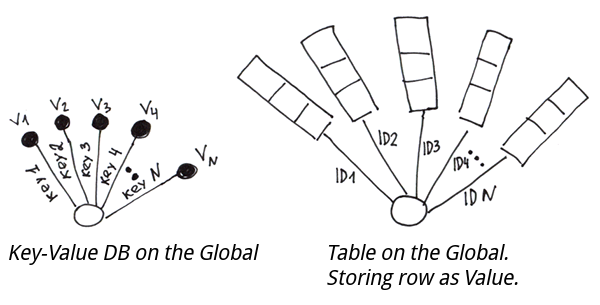
このツールを使用すると、インストール手順ではなく、目的のCaché構成を記述するインストールマニフェストを定義できます。作成したい Caché 構成を記述します。必要な内容を記述するだけで、環境を変更するために必要なコードが自動的に生成されます。
したがって、マニフェストのみを配布する必要がありますが、インストール・コードはすべてコンパイル時に特定の Caché サーバ用に生成されます。
マニフェストを定義するには、ターゲット構成の詳細な説明を含む新しいXDataブロックを作成してから、このXDataブロックのCaché ObjectScriptコードを生成するメソッドを実装します(このコードは常に同じです)。
.png)
.png)
.png)
.png)
.png)
.png)


 前のパート(
前のパート( 最初の記事については、
最初の記事については、 グローバルは配列のようにも、通常の変数のようにも使用できます。 例えば、カウンターを作成する場合を考えてみましょう。
グローバルは配列のようにも、通常の変数のようにも使用できます。 例えば、カウンターを作成する場合を考えてみましょう。