現在、Django(python)でWebアプリケーションを作成するための調査をしています。
DjangoからIRISのデータベースにODBCでアクセスできるのか、についてご教授頂けないでしょうか。
宜しくお願い致します。
Pythonは、汎用プログラミング用のインタープリター型の高水準のプログラム言語です。 Guido van Rossumによって作成され、1991年に最初にリリースされたPythonは、特に重要な空白を使用してコードの可読性を強調する設計哲学を持っています。 公式サイト。
現在、Django(python)でWebアプリケーションを作成するための調査をしています。
DjangoからIRISのデータベースにODBCでアクセスできるのか、についてご教授頂けないでしょうか。
宜しくお願い致します。
これまでの記事では、メールサーバーのメールボックスからのメッセージを処理する IMAP プロトコルの基本的な使用方法を学習しました。 とても興味深いものではありましたが、他の人が作成してすぐに利用できるようにライブラリに提供されている実装を利用することも可能です。
IRIS データプラットフォームの改善の 1 つに、同じ IRIS プロセスで ObjectScript に並行して Python コードを記述できる機能があります。 この新機能は、組み込み Python と呼ばれます。 組み込み Python を使用すると、ObjectScript コードに巨大な Python エコシステムのライブラリの力を取り込むことができます。
この記事では、imaplib というライブラリを使用して IMAP クライアントを実装し、それを IRIS Email フレームワーク に統合することにします。 また、Python エコシステムの力を借りて、組み込み Python を使用して、IRIS プラットフォームでの実際の課題を解決する方法を示す実用的な例も確認します。
ここで実装されているすべてのコードは、こちらの GitHub リポジトリの python ディレクトリにあります。
Python コードは最近の IRIS バージョンでのみ機能することに注意してください。
開発者のみなさん、こんにちは!
InterSystems Python コンテスト の投票結果が発表されました!この記事ではコンテスト受賞者を発表します📢

受賞された開発者の皆さん、👏おめでとうございます!🎊
開発者のみなさん、こんにちは。
今回は、スーパーやコンビニでもらうレシートを写真で撮り、OCR を使ってレシートの画像から文字列を切り出して IRIS に登録する流れを試してみました。
サンプルでは、Google の Vision API を利用してレシートの JPG 画像から購入物品をテキストで抽出しています。
サンプルコード一式 👉 https://github.com/Intersystems-jp/iris-embeddedpython-OCR
最初、オンラインラーニングで使っている 「tesseract-OCR」を使ってみようと思ったのですが、レシートには半角カナが混在していたりで、半カナがなかなかうまく切り出せず、あきらめました・・(半角カナがなかったら日本語もばっちり読めていたのですが・・)
もし、tesseract-OCR で半カナを切り出す良い方法をご存知の方いらっしゃいましたら、ぜひ教えてください!
今回試すにあたり、Vision API の使い方を詳しく書いているページがありましたのでコードなど参考させていただきました。ありがとうございました。
開発者の皆さん、こんにちは!
InterSystems Python コンテストの投票が始まりました!これはベストアプリケーションだ🔥と思う作品に投票をお願いします!
🔥 投票はこちらから! 🔥

投票方法は以下ご参照ください。
開発者の皆さん、こんにちは!
次の InterSystems プログラミングコンテストのお題が発表されました!次は、Python です!
🏆 InterSystems Python Contest 🏆
応募期間: 2022年2月7日~20日
💰 賞金総額: $10K💰 + さらに賞品を用意予定です!

開発者の皆さん、こんにちは!
InterSystems Python コンテスト 2022 のテクノロジーボーナスについてご案内します。
以下のテクノロジを使いコンテストにご応募いただくと、ボーナス点を獲得できます!
詳細は以下の通りです。
開発者の皆さん、Python好きの皆さん、こんにちは!
ドキュメントをみながら IRIS 2021.2 に追加された Embedded Python を試してみました!
IRIS にログインしてるのに Pythonシェルに切り替えできて Python のコードが書けたり、Python で import iris するだけで SQL を実行できたりグローバルを操作できるので、おぉ!✨という感じです。
ぜひ、みなさんも体感してみてください!
では早速。
まず、IRISにログインします。Windows ならターミナルを開きます。Windows 以外は以下実行します。
IRIS のインストール方法を確認されたい方は、【はじめての InterSystems IRIS】セルフラーニングビデオ:基本その1:InterSystems IRIS Community Edition をインストールしてみよう!をチェックしてみてください!
iris session irisiris session の引数はインストール時指定のインスタンス名(構成名)です。インスタンス名が不明な場合は iris list を打つと確認できます。以下の例の場合は IRIS がインスタンス名です。
キーワード: Pandasデータフレーム、IRIS、Python、JDBS
PandasデータフレームはEDA(探索的データ分析)に一般的に使用されるツールです。 MLタスクは通常、データをもう少し理解することから始まります。 先週、私はKaggleにあるこちらのCovid19データセットを試していました。 基本的に、このデータは1925件の遭遇の行と231列で構成されており、タスクは、患者(1つ以上の遭遇レコードにリンク)がICUに入室するかどうかを予測するものです。 つまりこれは、いつものようにpandas.DataFrameを使用して、まず簡単にデータを確認する、通常の分類タスクです。
現在では、IRIS IntegratedMLが提供されています。これには強力な「AutoML」のオプションに関する洗練されたSQLラッパーがあるため、従来型のMLアルゴリズムに対抗して、多様なデータフレームのステージをIRISデータベーステーブルに保存してから、IntegratedMLを実行する方法を頻繁に採用しています。 ただし、dataframe.to_sql()はまだIRISで機能しないため、実際には、ほとんどの時間を他のデータ保存手段をいじることに充てていました。
開発者の皆さん、こんにちは!
最近リリースされた InterSystems IRIS 2021.2 の目玉機能のひとつが Embedded Pythonです。Embedded Pythonは、PythonのランタイムをIRISに組み込むことによって、IRISのメソッドをPythonで記述したり、PythonのコードからIRISのクラスにアクセスしたりなどなど、IRISのObjectScriptとPythonとで相互に呼び出しを行なえる機能です。
しかも、Pythonのランタイムを埋め込んでいるため、ネットワークのオーバーヘッドがなく、パフォーマンスへの影響は最小限です。
IRISのプログラマの方には、Pythonの豊富なライブラリをストレスなく利用して頂けます。
Pythonのプログラマの方には、ObjectScriptを学ぶことなく、IRISの高速なデータベースやインターオペラビリティ機能などをストレスなく活用して頂けます。
今回の記事では、Embedded Pythonの機能をほんの一部だけ紹介します。
次のコードは、日付を表す文字列を2つ渡して、2つの日付の間の日数を返すメソッドです。
バージョン2019.2より、InterSystems IRISは、高性能データアクセス手法としてPython用のネイティブAPIを提供してきました。 ネイティブAPIを使用すると、ネイティブのIRISデータ構造と直接対話することができます。
この短い記事では、マシンにPythonをセットアップしなくて済むように、dockerコンテナでYapeを実行する方法について説明します。
このシリーズの前回の記事からしばらく時間が経っているため、簡単に振り返ってみましょう。
まず、matplotlibで基本的なグラフを作成する方法について話しました。 そして、bokehを使った動的グラフについて紹介しました。 最後にパート3では、monlblデータを使ったヒートマップの生成について説明しました。
フィードバックをさまざまなチャンネルを通じて受け取りましたが、これらを実行するための環境をセットアップするのが困難であるという、共通したテーマが見られました。 そこで、それを少しでも簡単に行えるよう、Murrayと協力して、Murrayの優れたYapeツール用のDockerfileを作成してみることにしました。 GitHubページ
もちろん、これを行うには、マシンにdockerがインストールされている必要があります。
公式のPythonイメージに基づく、どちらかと言えば単純なdocker定義:
FROM python:3
WORKDIR .
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
キーワード: Python、JDBC、SQL、IRIS、Jupyterノートブック、Pandas、Numpy、および機械学習
これは、デモの目的で、Jupyterノートブック内でPython 3によってIRIS JDBCドライバーを呼び出し、SQL構文でIRISデータベースインスタンスにデータを読み書きする、5分程度の簡単なメモです。
昨年、私はCacheデータベースへのPythonバインディング(セクション4.7)について簡単に触れました。 そこで、Pythonを使ってIRISデータベースに接続し、そのデータをPandasデータフレームとNumPy配列に読み込んで通常の分析を行ってから、事前処理済みまたは正規化されたデータをML/DLパイプラインに通すためにIRISに書き込む作業においてのオプションと議論について要約しましょう。
すぐに思い浮かぶ簡単なオプションがいくつかあります。
先週のディスカッションでは、1つのファイルのデータ入力に基づく単純なグラフを作成しました。 ご存知のように、解析して相関付けるデータファイルが複数あることがあります。 そこで今週は、perfmonデータを追加して読み込み、それを同じグラフにプロットする方法について学習しましょう。 生成したグラフをレポートやWebページで使用する可能性があるため、生成したグラフのエクスポート方法についても説明します。
標準のpButtonsレポートから抽出されたperfmonデータは、少し独特なデータ形式です。 一見すると、かなり単純なCSVファイルで、 最初の行には列のヘッダーがあり、それ以降の行にはデータポイントが含まれています。 ただし、ここでの目的のために、値エントリーを囲む引用符をどうにかする必要があります。 標準的なアプローチを使用してファイルをPythonに解析すると、文字列オブジェクトの列ができてしまい、うまくグラフ化できません。
perfmonfile="../vis-part2/perfmon.txt"
perfmon=pd.read_csv(perfmonfile,
header=0,
index_col=0,
converters={0: parse_datetime
})
キーワード: Jupyterノートブック、TensorFlow GPU、Keras、ディープラーニング、MLP、HealthShare
前回の「パート1」では、ディープラーニングデモ環境をセットアップしました。今回「パート2」では、それを使ってできることをテストします。
私と同年代の人の中には、古典的なMLP(多層パーセプトロン)モデルから始めた人がたくさんいます。 直感的であるため、概念的に取り組みやすいからです。
それでは、AI/NNコミュニティの誰もが使用してきた標準的なデモデータを使って、Kerasの「ディープラーニングMLP」を試してみましょう。 いわゆる「教師あり学習」の一種です。 これを実行するのがどんなに簡単かをKerasレベルで見ることにします。
後で、その歴史と、なぜ「ディープラーニング」と呼ばれているのかについて触れることができます。流行語ともいえるこの分野は、実際に最近20年間で進化してきたものです。
HealthShareにも関連しているため、最終的には、少々実現的なユースケースを想像または予測できるようになることを願っています。
次のことを行います。
Python 3をHealthShareにバインディングした深層学習デモキット(パート1) キーワード: Anaconda、Jupyterノートブック、TensorFlow GPU、ディープラーニング、Python 3、HealthShare
この「パート1」では、Python 3をHealthShare 2017.2.1インスタンスにバインドして、「単純」かつ一般的なディープラーニングデモ環境をセットアップする方法を段階的に簡単に説明します。 私は手元にあるWin10ノートパソコンを使用しましたが、このアプローチはMacOSとLinuxでも同じように実装できます。
先週、PYPL Indexにおいて、Pythonが最も人気のある言語としてJavaを超えたことが示されました。 TensorFlowも研究や学術の分野において非常に人気のある強力な計算エンジンです。 HealthShareは、ケア提供者に患者の統一介護記録を提供するデータプラットフォームです。
これらを1つのキットにまとめることはできるでしょうか。また、これを実現する上での最も単純なアプローチは何でしょうか。 ここでは、このトピックの最初のステップを一緒に試してから、次に試すことのできるデモについて検討しましょう。
インターネットを使うようになってから (1990年代後半)、PythonとIRIS グローバルを使ってブログを書いていますが、常にCMS (コンテンツ管理システム) でブログ、ソーシャルメディア、さらには企業ページに情報を簡単に投稿できるようにしていました。
数年後、自分がマークダウンファイルに収めて使ってきたすべてのコードをgithubに入れました。
ネイティブAPIでデータをIntersystems IRISに入れて永続化するのはとても簡単だったので、このアプリケーションを作成して少しSQLを忘れ、キー・バリュー・データベースモデルを受け入れることにしました!
これはWEB LOGの略名で、基本的にはユーザーが書いてページに投稿、公開できるプラットフォームです。
マークダウンとは、フォーマットしたテキストを作成するマークアップ言語であり、HTMLより簡単で、多くのCMSプラットフォームで人気があります。
例:
# Header 1
## Header 2
### Header 3
結果:
IRIS Globalsを使用して各投稿のデータを永続化しながら、各データコンサルタントはキー・バリュー・データベースとして動作するIRISのスピードというメリットを得ます。
この記事は、視覚化ツールと時系列データの分析を説明する連載の最初の記事です。 当然ながら、Caché製品ファミリーから収集できるパフォーマンス関連のデータを見ることに焦点を当てますが、 説明の途中で、他の内容についても解説していきます。 まずは、Pythonとそのエコシステムで提供されているライブラリ/ツールを探りましょう。
この連載は、Murrayが投稿したCachéのパフォーマンスと監視に関する優れた連載(こちらから参照)、より具体的にはこちらの記事と密接に関係しています。
免責事項1: 確認しているデータの解釈について話すつもりですが、それを詳しく話すと実際の目標から外れてしまう可能性があります。 そのため、Murrayの連載を先に読んで、主題の基本的な理解を得ておくことを強くお勧めします。
免責事項2: 収集したデータを視覚化するために使用できるツールは山ほどあります。 その多くは、mgstatなどから得たデータを直接処理するが、必要最低限の調整だけで処理することができます。 この記事は「このソリューションがベストですよ」という投稿ではまったくなく、 あくまでも、「データを操作する上で便利で効果的な方法を見つけたよ」という記事です。
免責事項3: データの視覚化と分析は、詳しく見るほど非常にやみつきになる、刺激的で楽しい分野です。
.png)
開発者のみなさん、こんにちは!
インターシステムズ開発者コミュニティでは、4回に渡り、InterSystems IRIS 2021.1の新機能や、開発を行う上で役に立つ機能をご紹介するウェビナーを開催します。10月の火曜と木曜のお昼に、弊社の技術者が30分でインターシステムズの最新テクノロジーについて解説します。
ぜひお気軽にご視聴ください!
※ (2022/4/1更新)YouTubeにアーカイブを公開しました。こちらよりご覧いただけます。
開催予定
第1回:10/12(火)InterSystems IRIS Adaptive Analytics のご紹介
第2回:10/14(木)Python Gateway のご紹介
第3回:10/19(火)SQL から始める機械学習 – IntegratedML のご紹介
第4回:10/21(木)FHIR 新機能
時間:12:30~13:00予定(約30分)
配信形式:ON24を使用したオンライン配信
参加費:無料
プレビュー:IRIS & InterSystems IRIS for Health 2021.1 新機能のご紹介
このビデオでは、昨年リリースされたバージョン2020.1から、新バージョン2021.1の間で追加/改善/強化された機能についてご紹介しています。合わせてご覧ください。

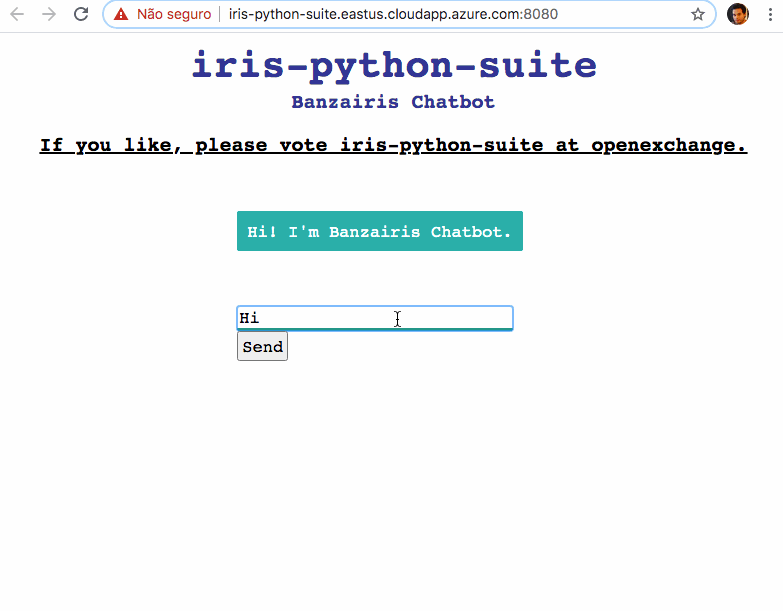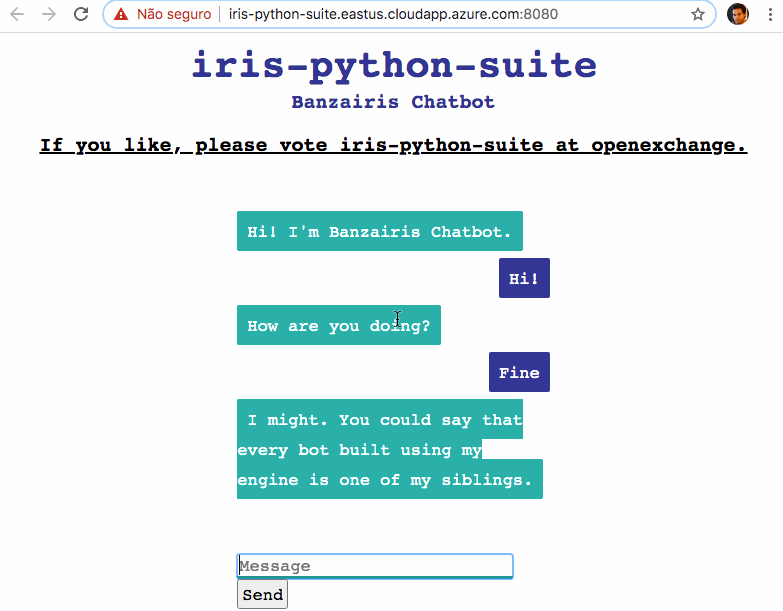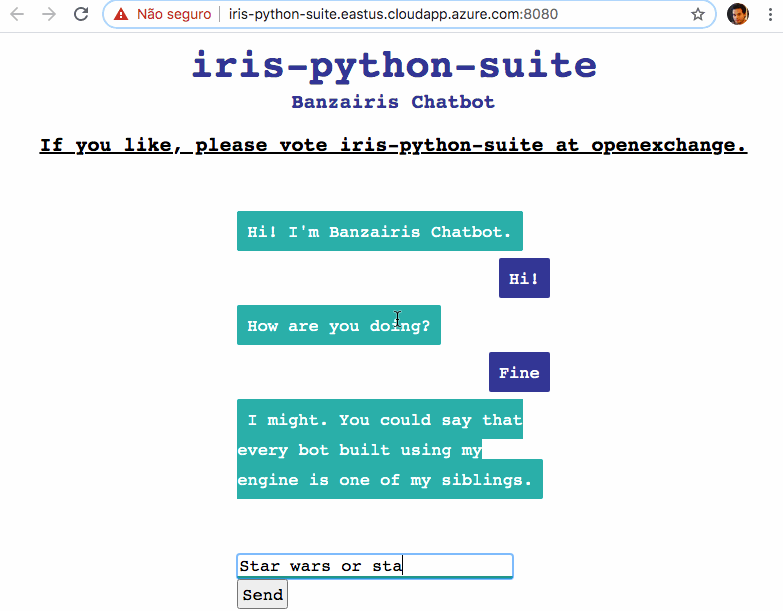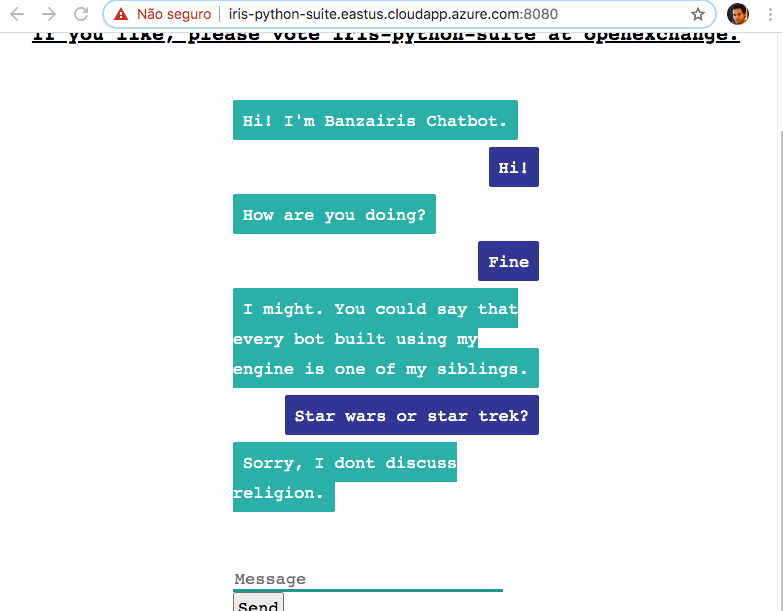
皆さんこんにちは! よろしければ、ボットが対話できるようになるようお手伝いいただけませんか?
チャットボットはこちらからアクセスしてください: Help my chatbots to talk!
なんだ、そのチャットボットはスマートではないのですか?
このシナリオでは「スマート」は適切な言葉ではありません。 チャットボットはトレーニング済みではありますが、少量のデータでしかトレーニングされていません! ほとんどのチャットボットソリューションでは、機械学習を使用して人間と対話する方法が作成されており、機械学習がうまく機能するには、重要なものが 1 つ必要となります。それはデータです。
どのように動作しますか?
簡単に説明しましょう。脳があっても人生経験のない人がいるとします。生まれたばかりの赤ん坊です。 この状況では、その人(赤ん坊)は、話している人を見たり、授業を受けたり、映画を見たりなどして、話し方を学習しなければなりません。 この人間の学習プロセスを、機械学習モデルにも当てはめることができます。 機械学習モデルが学習できる状況を与える必要があり、その状況がデータということになります。
** つまり、チャットボットは単なる辞書かオウムということになるのでしょうか…**
全くもってそうではありません。
この記事では、InterSystems IRIS データベースを Python と統合して自然言語処理(NLP)の機械学習モデルを提供する方法を説明します。
世界的に広く採用され使用されている Python には素晴らしいコミュニティがあり、様々なアプリケーションをデプロイするためのアクセラレータ/ライブラリが豊富に提供されています。 関心のある方は https://www.python.org/about/apps/ をご覧ください。
^globals について学び始めると、型にはまらないデータモデルに素早くデータを取り込む手法として使用することに慣れてきました。 そのため、最初は ^globals を使用してトレーニングデータと会話を保存し、チャットボットの動作をログに記録することにします。
自然言語処理(NLP)は、人間の言語から意味を読み取って理解する能力を機械に与える AI のテーマです。 ご想像のとおりあまり単純ではありませんが、この広大で魅力的な分野で最初の一歩を踏み出す方法を説明します。
チャットボットアプリケーションをデモとしてデプロイしています: http://iris-python-suite.eastus.cloudapp.azure.com:8080
*この動画は、2021年2月に開催された「InterSystems Japan Virtual Summit 2021」のアーカイブです。
IRIS の ObjectScript を使えば、ビジネスロジックの記述からキーバリュー形式のデータ操作まで様々な処理が記述できます。
ですが、残念ながら Python のように豊富なライブラリを利用し、機械学習をはじめとする Python が得意とすることまでは単独では行えません。
「ObjectScript から Python を呼べたら?」を実現するための計画中機能も含め、IRIS がサポートする Python の利用方法をご紹介します。
この動画の講演資料(PDF)もご用意しました。
動画の中でご紹介している技術資料へのURLは、こちらの資料をご活用ください。
開発者の皆さん、こんにちは🌂 今年は早い梅雨入りでした ☔
さて、新しい✨ 実行/開発環境テンプレートを作成しました。 Docker 🐳、docker-compose 、git がインストールされていれば、すぐにお試しいただけます。ぜひご利用ください!
今回は、ご存知の方が多いと思われる(?)某アニメの登場人物を使った人物相関図をテーマに【キーバリュー形式で IRIS に登録してグラフ構造で表示してみた】を体験できるテンプレートです(テンプレートは、Python/Node.js/Java からお試しいただける環境をご用意しています)。
人物相関図のイメージ 
以下、今回のテーマについて、ビデオと文字でご紹介しています。最後までお付き合いいただければ幸いです!(ビデオは全体で 7 分 20 秒)
人物相関図と言えば、グラフデータベースをイメージされると思います。
IRIS はグラフデータベースではないのですが、IRIS ネイティブのデータの「グローバル」を利用することで、グラフデータベースと似たような構造を表現することができます。
IRIS の高パフォーマンスを支える 「グローバル」 は 40 年以上前(= InterSystems 創業)から InterSystems のコア技術であるデータベースとして提供されてきました。
皆さん、こんにちは。 今日は、Jupyter Notebook をインストールして、Apache Spark と InterSystems IRIS に接続したいと思います。
注記: 以下にお見せする作業は Ubuntu 18.04 で Python 3.6.5 を使って実行しました。
Apache Zeppelin の代わりに認知度が高く、よく普及していて、主に Python ユーザーの間で人気というノートブックをお探しの方は、 Jupyter notebookをおすすめします。 Jupyter notebook は、とてもパワフルで優れたデータサイエンスツールです。 大きなコミュニティが存在し、使用できるソフトウェアや連携がたくさんあります。 Jupyter Notebook では、ライブコード、数式、視覚化インターフェース、ナレーションテキストを含む文書を作成、共有できます。 機能としてデータクリーニングや変換、数値シミュレーション、統計モデリング、データの視覚化、機械学習などが含まれています。 最も重要なこととして、問題に直面したときにその解決を手伝ってくれる大きなコミュニティが存在します。
何かうまく行かないことがあれば、一番下の「考えられる問題と解決策」をご覧ください。
2019年 10月 17日
Anton Umnikov
InterSystems シニアクラウドソリューションアーキテクト
AWS CSAA、GCP CACE
AWS Glue は、完全に管理された ETL (抽出、変換、読み込み) サービスです。データの分類、クリーンアップ、強化、そして様々なデータストア間でデータを確実に移動させるという作業を簡単にかつコスト効率の良いかたちで行えるようにするものです。
InterSystems IRIS の場合、AWS Glue を使用すれば、大規模なデータをクラウドとオンプレミスのデータソースの両方から IRIS に移動させることができます。 ここで考えられるデータソースは、オンプレミスのデータベース、CSV、JSON、S3 バケットに保管されている Parquet ファイルならびに Avro ファイル、AWS Redshift や Aurora といったクラウドネイティブのデータベースを含みますが、これらに限定されません。
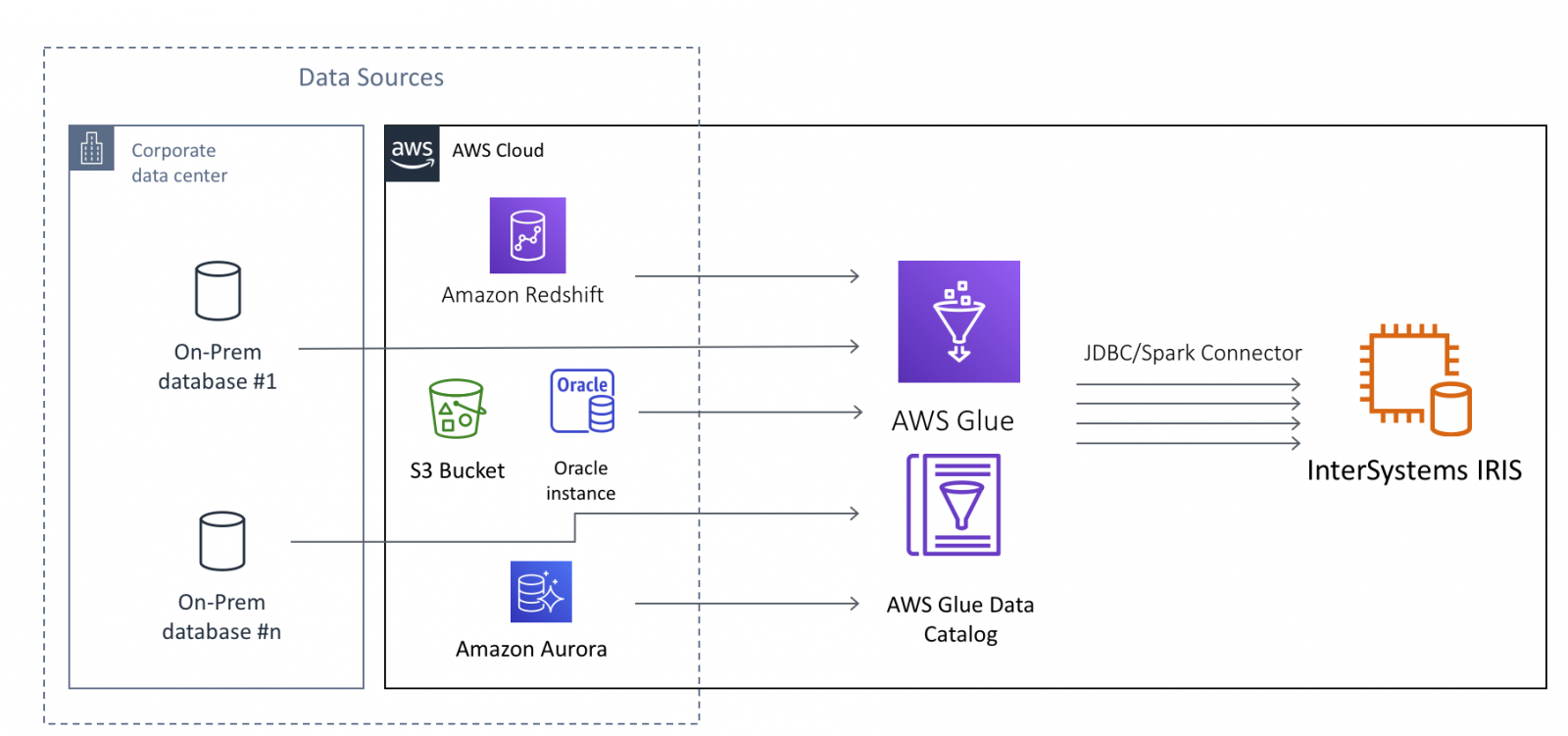
本記事では、読者の皆さんが、AWS Glue について少なくとも AWS Glue の入門チュートリアル を完了している程度の基本的な知識をお持ちであるという前提で話を進めていきます。
みなさん、こんにちは。 今回は ML モデルを IRIS Manager にアップロードしてテストしようと思います。
注意: Ubuntu 18.04、Apache Zeppelin 0.8.0、Python 3.6.5 で以下を実行しました。
最近では実にさまざまなデータマイニングツールを使用して予測モデルを開発し、これまでにないほど簡単にデータを分析できるようになっています。 InterSystems IRIS Data Platform はビッグデータおよび高速データアプリケーション向けに安定した基盤を提供し、最新のデータマイニングツールとの相互運用性を実現します。
この連載記事では、InterSystems IRIS で利用できるデータマイニング機能について説明します。最初の記事ではインフラストラクチャを構成し、作業を開始する準備をしました。2 番目の記事では、Apache Spark と Apache Zeppelin を使用して花の種を予測する最初の予測モデルを構築しました。 この記事では KMeans PMML モデルを構築し、InterSystems IRIS でテストします。
Intersystems IRIS は PMML の実行機能を提供しています。 そのため、モデルをアップロードし、SQLクエリを使用して任意のデータに対してそのモデルをテストできます。
NoSQLデータベースという言葉を聞かれたことがあると思います。色々な定義がありますが、簡単に言えば、文字通りSQLを使わない、つまりリレーショナルデータベース(RDB)以外のデータベースのことを指すのが一般的です。
InterSystems IRIS Data Platformでは、テーブルを定義してSQLでデータにアクセスできます。ですから、InterSystems IRIS Data Platformは厳密にNoSQLデータベースというわけではありません。しかし、InterSystems IRISの高パフォーマンスを支える「グローバル」は、40年も前からInterSystemsのコア技術として、現代で言うNoSQLデータベースを提供してきました。本稿では、InterSystems IRISの「グローバル」でグラフ構造を作り、それをPythonでアクセスする方法を紹介します。
本稿で説明する内容は動画でも公開しています。ぜひご覧ください。
NoSQLに分類されるデータベースには様々なデータモデルを扱うものがあります。以下に代表的なものを挙げます。
この連載記事では、InterSystemsデータプラットフォーム用のPython Gatewayについて説明します。 また、InterSystems IRISからPythonコードなどを実行します。 このプロジェクトは、InterSystems IRIS環境にPythonの力を与えます。
現時点での連載計画です(変更される可能性があります)。
Jupyter Notebookは実コード、数式、図、説明文を含むドキュメントを作成および共有できるオープンソースのWebアプリケーションです。
この拡張機能を使用すると、InterSystems IRIS BPLのプロセスをJupyterノートブックとして参照および編集できます。
この連載記事では、InterSystemsデータプラットフォーム用のPython Gatewayについて説明します。 また、InterSystems IRISからPythonコードなどを実行します。 このプロジェクトは、InterSystems IRIS環境にPythonの力を与えます。
現時点での連載計画です(変更される可能性があります)。
この記事と次の記事では、一般に(.Net/Java)ゲートウェイとして理解されているものに関する機能を説明します。 今回は、実行関数(Pythonコードを構造化されたプログラムで実行する機能)について説明します。
皆さんこんにちは。
第4回 InterSystems IRIS プログラミングコンテスト(AI/MLコンテスト) への応募は終了しました。コンテストへのご参加、またご興味をお持ちいただきありがとうございました。
この記事では、見事受賞されたアプリケーションと開発者の方々を発表します!

🏆 審査員賞 -特別に選ばれた審査員から最も多くの票を獲得したアプリケーションに贈られます。
🥇 1位 - $2,000 は iris-integratedml-monitor-example を開発された José Roberto Pereir さんに贈られました!
🥈 2位 - $1,000 は iris-ml-suite を開発された Renato Banza さんに贈られました!
🥉 3位 - $500 は ESKLP を開発された Aleksandr Kalinin さんに贈られました!
🏆 開発者コミュニティ賞 - 最も多くの票を獲得したアプリケーションに贈られます。
🥇 1位 - $1,000 は iris-ml-suite を開発された Renato Banza さんに贈られました!
🥈 2位 - $250 は iris-integratedml-monitor-example を開発された José Roberto Pereir さんに贈られました!