開発者の皆さん、こんにちは!
InterSystems IRIS でアナリティクスソリューションを構築するにはどのような方法があるでしょうか。

最初に、アナリティクスソリューションは何かについて確認しようと思いますが、とても幅広いテーマになってしまうので、Analytics コンテストで発表できるソリューションに限定してご紹介します。
以下、モニタリング、インタラクティブアナリティクス、レポーティングの3種類のアナリティクスソリューションについてご紹介します。
モニタリング
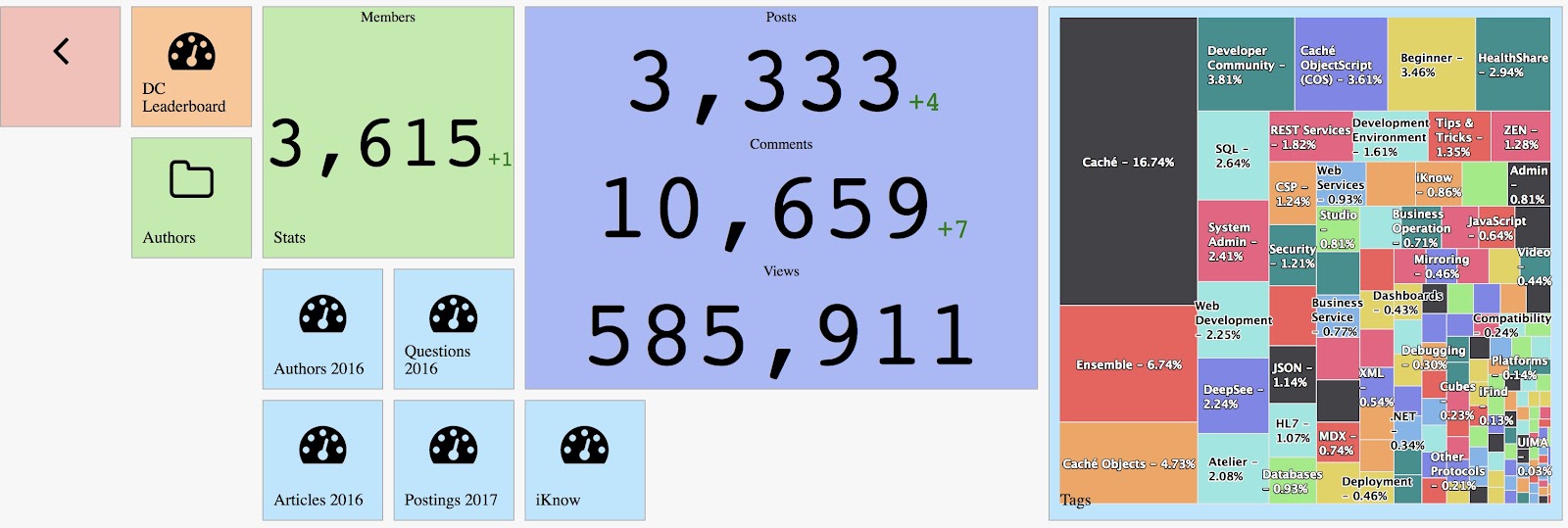
一般的なモニタリングソリューションは、アクティブに更新される KPI を備えたオンラインダッシュボードで構成されています。
モニタリングの主な使用例としては、新しいデータの KPI を常に視覚的に観察し、緊急時に対応することです。
インタラクティブアナリティクス
このソリューションはフィルタやドリルダウンが行えるインタラクティブなダッシュボードのセットを想定しています。
主なユースケースは、グラフや表のデータを視覚化した上で、フィルタやドリルダウンを使用してデータを探しだし、ビジネス上の意思決定を行うことです。
レポーティング
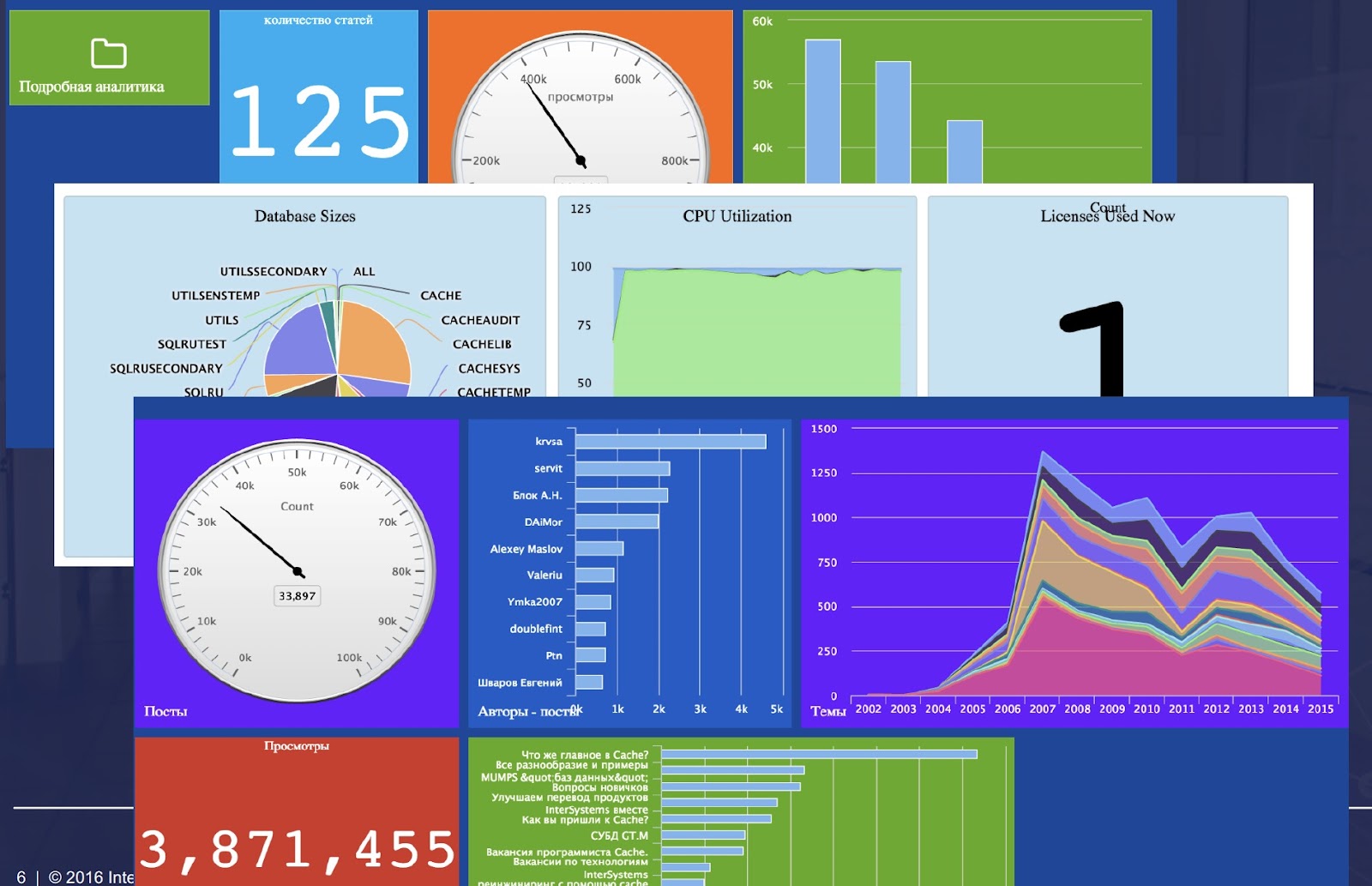
レポーティングソリューションは、グラフやテキスト形式のデータを事前にデザインされたフォームで提供する HTML や PDF ドキュメントの形式で、静的(通常)レポートを提供し、メールで送付することもできます。
レポーティングシステムの主なユースケースは、ビジネスにとって重要な製品やプロセス、サービス、セールスなどの状況を説明するレポートを一定期間に取得することです。
このようなソリューションを構築するために、InterSystems 製品をどのように利用できるでしょうか。
以下の項目で議論してみましょう。
 閲覧回数
閲覧回数
 Open Exchange app
Open Exchange app