前の記事では、smolagentsとInterSystems IRISを使用して、SQL、ベクトル検索を使用したRAG、interoperabilityを組み合わせたカスタマーサービスAIエージェントをビルドしました。
その際、LLMと埋め込み表現のためにクラウドモデル(OpenAI)を使用しました。
今回はさらに一歩進めます。Ollamaを利用して、同じエージェントをローカルモデルで実行します。
人工知能(AI)は、機械、特にコンピューターシステムによる人間の知能プロセスのシミュレーションです。 これらのプロセスには、学習(情報の取得と情報を使用するためのルール)、推論(概算または明確な結論に到達するためのルールを使用)、および自己修正が含まれます。 詳細はこちら。
前の記事では、smolagentsとInterSystems IRISを使用して、SQL、ベクトル検索を使用したRAG、interoperabilityを組み合わせたカスタマーサービスAIエージェントをビルドしました。
その際、LLMと埋め込み表現のためにクラウドモデル(OpenAI)を使用しました。
今回はさらに一歩進めます。Ollamaを利用して、同じエージェントをローカルモデルで実行します。
カスタマーサポートの質問は、構造化データ(オーダー、製品 🗃️)、非構造化知識(ドキュメント/よくある質問 📚)、およびライブストリーム(出荷更新 🚚)と多岐にわたります。 この投稿では、以下を使用して、3つすべてに対応するコンパクトなAIエージェントを作成します。
.png)
.png)
OHDSI のウェブブックからアキレスに続くこの OMOP の旅シリーズに沿って、適切に記述された R と SQL の組み合わせによって、組織間で共有可能な大規模な分析の結果が導き出されるのを見れば、OMOP 共通データモデルの威力を理解し始めることができます。 とは言え、私には第 3 正規形の知識がないので、約 1 か月前の旅において、Databricks Genie を使って、InterSystems OMOP と Python 相互運用性を活用して SQL を生成しました。 非常にうまくいきましたが、RAG「モデル」がどのように構築され、それを実現するための LLM の使用については、Databricks の内部に魔法が残されています。
OMOP の旅のこの時点で、同じ道で Vanna.ai と出会いました...
Vanna は、LLM を使用してデータベースの正確な SQL クエリを生成するのに役立つ、検索拡張を使った Python パッケージです。
コミュニティの皆さん、こんにちは。
従来のキーワードベースの検索では、ニュアンスのあるドメイン固有のクエリには対応できません。 ベクトル検索であれば、セマンティック認識を利用して、キーワードだけでなくコンテキストにも基づいたレスポンスを AI エージェントで検索して生成することができます。
この記事では、エージェンティック AI RAG(検索拡張生成)アプリケーションを作成手順を紹介します。
この連載記事を終えていなかったことに気付きました!

今日の記事では、フロントエンドから最適なオプションを選択できるように、テキストに最も類似する ICD-10 診断を抽出するプロダクションプロセスについて説明します。
アプリケーション内で、HL7 で受け取った診断リクエストを示す画面から、医療従事者が入力したテキストに最も近い ICD-10 診断を検索できます。
.png)
検索プロセスを高速化するために、HL7 メッセージを取得する際に受信した診断をベクトル化したテキストをデータベースに保存しました。 これを行うために、メッセージから診断コードを抽出し、ベクトルを生成するメソッドにそれを送信する単純な BPL を実装しました。
.png)
受信した診断をベクトル化するコードは以下のようになります。
ClassMethod GetEncoding(sentence As %String) As %String [ Language = python ]
{
import sentence_transformers
# create the model and form the embeddings
model = sentence_transformers.SentenceTransformer('/iris-shared/model/')
embeddings = model.開発者の皆さん、こんにちは!
今年最初のプログラミング・コンテスト(USコミュニティ)の開催が決定しました!
🏆 InterSystems AI プログラミングコンテスト:ベクトル検索、生成AI、AIエージェント 🏆
期間:2025年3月17日~4月6日
賞品総額:$12,000 + Global Summit 2025 へご招待!
.jpg)
コミュニティメンバーから、Python 2024 コンテストでの出品に対する非常に素晴らしいフィードバックが届きました。 ここで紹介させていただきます。
純粋な IRIS の 5 倍以上のサイズでコンテナーをビルドしているため、時間がかかっています
コンテナーの始動も時間はかかりますが、完了します
バックエンドは説明通りにアクセス可能です
プロダクションは稼動しています
フロントエンドは反応します
何を説明したいのかがよくわかりません
私以外のエキスパート向けに書かれた説明のようです
出品はこちら: https://openexchange.intersystems.com/package/IRIS-RAG-App
このようなフィードバックをいただけて、本当に感謝しています。プロジェクトに関する記事を書く素晴らしいきっかけとなりました。 このプロジェクトにはかなり包括的なドキュメントが含まれてはいますが、ベクトル埋め込み、RAG パイプライン、LLM テキスト生成のほか、Python や LLamaIndex などの人気の Python ライブラリに精通していることが前提です。
この記事は、IRIS での RAG ワークフローを実証するに当たって、上記の前提事項や、それらが IRIS で RAG ワークフローをこのプロジェクトにどのように適合するかについてを説明する試みです。
前回の記事では、ICD-10 による診断のコーディングをサポートできるように開発された d[IA]gnosis アプリケーションを紹介しました。 この記事では、InterSystems IRIS for Health が、事前トレーニングされた言語モデル、そのストレージ、およびその後の生成されたすべてのベクトルの類似性の検索を通じて ICD-10 コードのリストからベクトルを生成するために必要なツールをどのように提供するかを見ていきます。

AI モデルの開発に伴って登場した主な機能の 1 つは、RAG(検索拡張生成)という、コンテキストをモデルに組み込むことで LLM モデルの結果を向上させることができる機能です。 この例では、コンテキストは ICD-10 診断のセットによって提供されており、これらを使用するには、まずこれらをベクトル化する必要があります。
診断リストをベクトル化するにはどうすればよいでしょうか?
ベクトルを生成するために、トレーニング済みのモデルからの自由テキストのベクトル化を大幅に容易にする SentenceTransformers という Python ライブラリを使用しました。 そのウェブサイトでは以下のように説明されています。
ベクトルデータ型と Vector Search 機能が IRIS に導入されたことにより、アプリケーションの開発に多数の可能性が開かれました。こういったアプリケーションの例として、バレンシア保健省が AI モデルを使用した ICD-10 コーディング支援ツールを要求した公募で出品されたアプリケーションが最近私の目に留まりました。
要求されたツールのようなアプリケーションをどのように実装できるでしょうか? 必要なものを確認しましょう。
これらのニーズに対応するために、IRIS は何を提供できるでしょうか?
コミュニティの皆さん、こんにちは!
開発者コミュニティ AI 懸賞企画 お楽しみいただけましたか? まだまだ改良の必要がありそうですが、DC AIを利用して何か新しい回答が得られていることを願っています。
この投稿では、優勝者を発表します!🎊(抽選の様子を動画でご紹介しています。ぜひご覧ください!)
コミュニティの皆さん
こんにちは!
ご存知かもしれませんが、Developer Community AIがリリースされて1ヶ月以上が経ちました🎉 興味を持たれた方は、ぜひ試してみてください😁 まだの方は、ぜひお試しください!いずれにせよ、まだベータ版であるため、私たちは皆さんがこのAIについてどのように考えているかを知りたいと思っています。

皆さんの時間と労力を大切にしているので、感想をシェアしてくれたメンバーに、抽選でキュートな賞品をプレゼントします。この懸賞に参加するには、以下のガイドラインに従ってください。
我々には、Redditユーザーが書いた、おいしいレシピデータセット がありますが, 情報のほとんどは投稿されたタイトルや説明といったフリーテキストです。埋め込みPythonやLangchainフレームワークにあるOpenAIの大規模言語モデルの機能を使い、このデータセットを簡単にロードし、特徴を抽出、分析する方法を紹介しましょう。
まず最初に、データセットをロードするかデータセットに接続する必要があります。
これを実現するにはさまざまな方法があります。たとえばCSVレコードマッパーを相互運用性プロダクションで使用したり csvgenのようなすばらしい OpenExchange アプリケーションを使用することもできます。
今回、外部テーブルを使用します。これは物理的に別の場所に保存されているデータをIRIS SQLで統合する非常に便利な機能です。
まずは外部サーバ(Foreign Server)を作成します。
CREATE FOREIGN SERVER dataset FOREIGN DATA WRAPPER CSV HOST '/app/data/'
その上でCSVファイルに接続する外部テーブルを作成します。
CREATE FOREIGN TABLE dataset.開発者の皆さん、こんにちは!
(2024.4.17更新:コンテストタイトルに「ベクトル検索」を追加しました)
次の InterSystems オンラインプログラミングコンテストのテーマが決定しました!👉生成 AI、ベクトル検索、機械学習 です!
🏆 InterSystems ベクトル検索、GenAI、ML コンテスト(USコミュニティ) 🏆
期間: 2024年4月22日~5月19日
賞金総額: $14,000
.jpg)

人工知能は、命令によってテキストから画像を生成したり、単純な指示によって物語を差作成したりすることだけに限られていません。
多様な写真を作成したり、既存の写真に特殊な背景を含めたりすることもできます。
また、話者の言語や速度に関係なく、音声のトランスクリプションを取得することも可能です。
では、ファイル管理の仕組みを調べてみましょう。
みなさんこんにちは! 今回は、IRIS 2024.1で実験的機能として実装されたVector Search (ベクトル検索)について紹介します。ベクトル検索は、先日リリースされたIRIS 2024.1の早期アクセスプログラム(EAP)で使用できます。IRIS 2024.1については、こちらの記事をご覧ください。
ChatGPTをきっかけに、大規模言語モデル(LLM)や生成AIに興味を持たれている方が増えていると思います。開発者の方々の中には、中はどうなっているのか気になっている方も多いのではないでしょうか。実は、LLMや生成AIの仕組みを理解したいと思えば、ベクトルの理解は不可欠な要素となります。
ベクトルは、高校の数学で習う「あの」ベクトルのことです。が、今回は、複数の数値をまとめて扱うデータ型であるという理解で十分です。例えば、
( 1.2, -4.5 )
という感じです。この例は、1.2と-4.5という2つの数値をまとめており、数値の個数(ここでは2)のことを次元数と言います。我々の生きている場所を3次元空間と呼ぶことがありますが、これは、3つの数値で場所が特定できることを表しています(例えば、緯度、経度、標高の3つで地球上の位置を完全に特定できます)。
![]()
皆さんもご存知のように、人工知能の世界はもう生活の中に存在しており、誰もが利用従っています。
多数のプラットフォームが、無料、サブスクリプション、または非公開の形式で、人工知能サービスを提供していますが、 コンピューティングの世界で「話題」となったことから、特に注目されているサービスは OpenAI です。最も有名な ChatGPT および DALL-E が主な原因と言えます。
ここで、明白に進化をみることができます! GPT-3(2020 年)は、達成したいことを示した十分な入力を使ってトレーニングする必要がありましたが、現行の GPT-4 バージョンでは自然言語を使用することができるため、入力をより簡単に提供することができます。 これで、命令の意図を理解するだけでなく、それ自体が話している内容を理解している「ように見えます」。
現在は、Gary Marcus が 2020 年に GPT-2 用に作成した同じ例を使用した場合、期待どおりの結果を得られます。
OpenAI は現在、驚くほどの速さで大幅に進化した一連のツールを提供しており、適切に組み合わせれば、以前よりも効率的な結果をはるかに簡単に得ることができます。
大規模言語モデル(OpenAI の GPT-4 など)の発明と一般化によって、最近までは手動での処理が非現実的または不可能ですらあった大量の非構造化データを使用できる革新的なソリューションの波が押し寄せています。 データ検索(検索拡張生成に関する優れた紹介については、Don Woodlock の ML301 コースをご覧ください)、センチメント分析、完全自律型の AI エージェントなど、様々なアプリケーションが存在します。
この記事では、IRIS テーブルに挿入するレコードに自動的にキーワードを割り当てる単純なデータタグ付けアプリケーションの構築を通じて、IRIS の Embedded Python 機能を使って、Python OpenAI ライブラリに直接インターフェース接続する方法をご紹介します。 これらのキーワードをデータの検索と分類だけでなく、データ分析の目的に使用できるる単純なデータタグ付けアプリケーションを構築します。ユースケースの例として、製品の顧客レビューを使用します。

Review クラス顧客レビューのデータモデルを定義する ObjectScript クラスの作成から始めましょう。
前の記事 - AI による臨床文書の保管、取得、検索の単純化
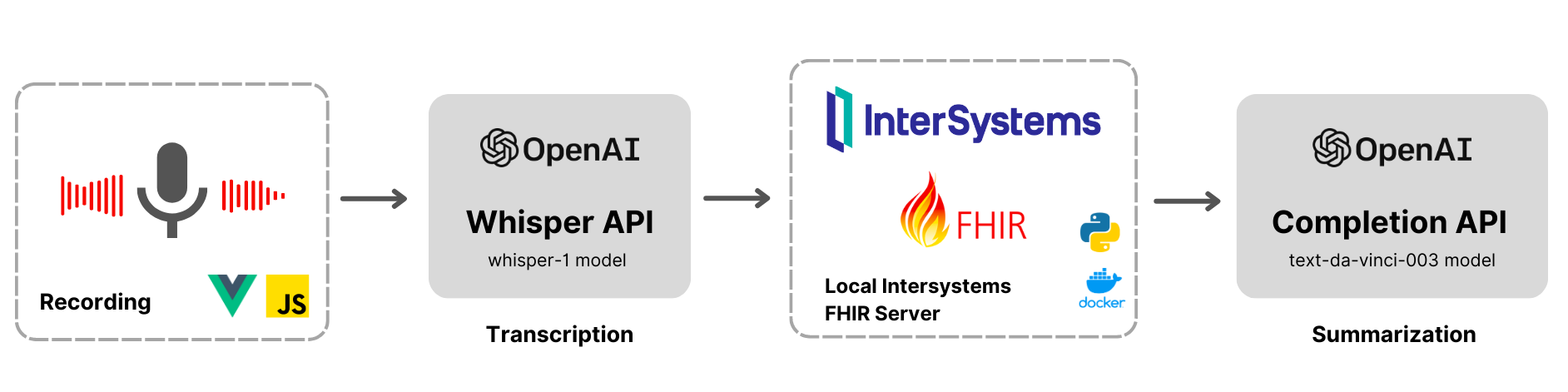
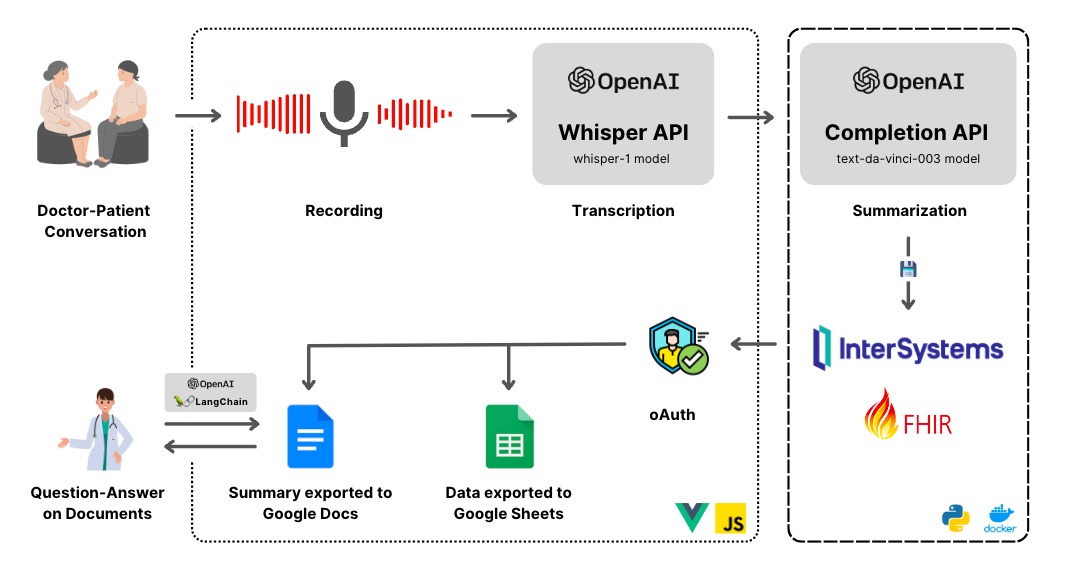
この記事では、AI を使用した文字起こしと要約によってヘルスケアに変革を起こす OpenAI の高度な言語モデルの可能性を探ります。 OpenAPI の最先端 API を活用して、録音データを文字起こしし、自然言語処理アルゴリズムを使って簡潔な要約を生成するための重要なインサイトを抽出するプロセスを掘り下げていきます。
似たような機能は Amazon Medical Transcibe や Medvoice などの既存のソリューションでも提供されていますが、この記事では、OpenAI テクノロジーを使用してこれらの強力な機能を InterSystems FHIR に実装することに焦点を当てています。
Vue.js アプリのボイスレコーダーは、完全にネイティブであり、Mediarecorder インターフェースを使って JavaScript で記述されています。 これは、アプリケーションを軽量に維持しながら、録音オプションを完全に制御できるようにすることを目的としています。 以下は、録音入力の開始と停止を行うスニペットです。
あわただしい臨床環境では迅速な意思決定が重要であるため、文書保管とシステムへのアクセスが合理化されていなければいくつもの障害を生み出します。 文書の保管ソリューションは存在しますが(FHIR など)、それらの文書内で特定の患者データに有意にアクセスして効果的に検索するのは、重大な課題となる可能性があります。
AI により、文書の検索が非常に強力になりました。 Chroma や Langchain のようなオープンソースツールを使用して、ベクトル埋め込みを保存して使用し、生成 AI API 全体でクエリを実行することで、ドキュメント上での質疑応答がかつてないほど簡単になっています。 より献身的に取り組む組織は、既存のドキュメントにインデックスを作成し、エンタープライズ用に微調整されたバージョンの GPT を構築しています。 GPT の現状に関する Andrej Karpathy の講演では、このトピックに関する素晴らしい概要が提供されています。
このプロジェクトは、医療関係者が文書を操作するあらゆるタッチポイントにおいて発生する摩擦を緩和する試みです。 医療関係者が情報を保管し、必要な情報を難なく検索できるように、入力と処理から保管と検索まで、IRIS FHIR と AI を活用しました。
医療関係者が音声メモを記録できるフルスタックのウェブアプリを構築しました。
開発者の皆さん、こんにちは!
InterSystems グランプリコンテスト2023 では、InterSystems IRIS data platform を使用する機能であればどんな内容でもご応募いただけます。
以下の機能を含めた場合、ボーナスポイントを獲得できます。
詳細は以下の通りです。
開発者の皆さん、こんにちは。
技術文書ライティングコンテストの受賞者が発表されたばかりですが、次のコンテスト:InterSystems IRIS Cloud SQL and IntegratedML コンテスト 2023 のテクノロジーボーナス詳細が決定しましたのでお知らせします📣
獲得ポイントについて詳細は、以下ご参照ください。
開発者の皆さん、こんにちは!
次のプログラミングコンテストの詳細が決定し「IRIS Cloud SQLのデータを利用してAI/MLソリューションを作成する」がテーマとなりました。
🏆 InterSystems IRIS Cloud SQL and IntegratedML コンテスト 🏆
期間: 2023年4月3日~23日
賞金総額: $13,500

腎臓病は、医学会でよく知られるいくつかのパラメーターから発見することが可能です。 この測定により、医学界とコンピューター化されたシステム(特に AI)を支援すべく、科学者である Akshay Singh は、腎臓病の検出/予測における ML アルゴリズムをトレーニングするための非常に便利なデータセットを公開しました。 このデータセットは、ML の最大級のデータリポジトリとして最もよく知られている Kaggle に公開されています。https://www.kaggle.com/datasets/akshayksingh/kidney-disease-dataset
腎臓病データセットには、以下のメタデータ情報が含まれています(出典: https://www.kaggle.com/datasets/akshayksingh/kidney-disease-dataset)
糖尿病は、医学会でよく知られるいくつかのパラメーターから発見することが可能です。 この測定により、医学界とコンピューター化されたシステム(特に AI)を支援すべく、(米)国立糖尿病・消化器・腎疾病研究所(NIDDK)は、糖尿病の検出/予測における ML アルゴリズムをトレーニングするための非常に便利なデータセットを公開しました。 このデータセットは、ML の最大級のデータリポジトリとして最もよく知られている Kaggle に公開されています: https://www.kaggle.com/datasets/mathchi/diabetes-data-set。
糖尿病データセットには、以下のメタデータ情報が含まれています(出典: https://www.kaggle.
母体リスクは、医学界でよく知られているいくつかのパラメーターから測定できます。 この測定により、医学界とコンピューター化されたシステム(特に AI)を支援すべく、科学者である Yasir Hussein Shakir は、母体リスクの検出/予測における ML アルゴリズムをトレーニングするための非常に便利なデータセットを公開しました。 このデータセットは、ML の最大級のデータリポジトリとして最もよく知られている Kaggle に公開されています。
https://www.kaggle.com/code/yasserhessein/classification-maternal-health-5-algorithms-ml
妊娠中と出産後の母体のヘルスケアに関する情報の不足により、妊娠中の女性の多くは、妊娠に関わる問題で死亡しています。 これは、農村地域や新興国の下位中流家庭の間でより一般的に起きている問題です。 妊娠中は、状態を絶えず観察することで、胎児の適切な成長と安全な出産を保証する必要があります(出典: https://www.kaggle.com/code/yasserhessein/classification-maternal-health-5-algorithms-ml)。
キーワード: IRIS、IntegratedML、Flask、FastAPI、Tensorflow Serving、HAProxy、Docker、Covid-19
過去数か月に渡り、潜在的なICU入室を予測するための単純なCovid-19 X線画像分類器やCovid-19ラボ結果分類器など、ディープラーニングと機械学習の簡単なデモをいくつか見てきました。 また、ICU分類器のIntegratedMLデモ実装についても見てきました。 「データサイエンス」の旅路はまだ続いていますが、「データエンジニアリング」の観点から、AIサービスデプロイメントを試す時期が来たかもしれません。これまでに見てきたことすべてを、一式のサービスAPIにまとめることはできるでしょうか。 このようなサービススタックを最も単純なアプローチで達成するには、どういった一般的なツール、コンポーネント、およびインフラストラクチャを活用できるでしょうか。
ジャンプスタートとして、docker-composeを使用して、次のDocker化されたコンポーネントをAWS Ubuntuサーバーにデプロイできます。
キーワード: PyODBC、unixODBC、IRIS、IntegratedML、Jupyterノートブック、Python 3
数か月前、私は「IRISデータベースへのPython JDBC接続」という簡易メモを書きました。以来、PCの奥深くに埋められたスクラッチパッドよりも、その記事を頻繁に参照しています。 そこで今回は、もう一つの簡易メモで「IRISデータベースへのPython ODBC接続」を作成する方法を説明します。
ODBCとPyODCBをWindowsクライアントでセットアップするのは非常に簡単なようですが、Linux/Unix系サーバーでunixODBCとPyODBCクライアントをセットアップする際には毎回、どこかで躓いてしまいます。
バニラLinuxクライアントで、IRISをインストールせずに、リモートIRISサーバーに対してPyODBC/unixODBCの配管をうまく行うための単純で一貫したアプローチがあるのでしょうか。
最近、Linux Docker環境のJupyterノートブック内でゼロからPyODBCデモを機能させるようにすることに少しばかり奮闘したことがありました。 そこで、少し冗長的ではありますが、後で簡単に参照できるように、これをメモに残しておくことにしました。
このメモでは、以下のコンポーネントに触れます。
キーワード: IRIS、IntegratedML、機械学習、Covid-19、Kaggle
最近、Covid-19患者がICU(集中治療室)に入室するかどうかを予測するKaggleデータセットがあることに気づきました。 231列のバイタルサインや観測で構成される1925件の遭遇記録が含まれる表計算シートで、最後の「ICU」列では「Yes」を示す1と「No」を示す0が使用されています。 既知のデータに基づいて、患者がICUに入室するかどうかを予測することがタスクです。
このデータセットは、「従来型ML」タスクと呼ばれるものの良い例のようです。 データ量は適切で、品質も比較的適切なようです。 IntegratedMLデモキットに直接適用できる可能性が高いようなのですが、通常のMLパイプラインと潜在的なIntegratedMLアプローチに基づいて簡易テストを行うには、どのようなアプローチが最も単純なのでしょうか。
次のような通常のMLステップを簡単に実行します。
上記との比較で、次を実行します。
Docker-composeなどを使用して、AWS Ubuntu 16.04サーバーで実行します。
キーワード: COVID-19、医用画像、ディープラーニング、PACSビューア、HealthShare。
私たちは皆、この前例のないCovid-19パンデミックに悩まされています。 現場のお客様をあらゆる手段でサポートする一方で、今日のAI技術を活用して、Covid-19に立ち向かうさまざまな前線も見てきました。
昨年、私はディープラーニングのデモ環境について少し触れたことがあります。 この長いイースターの週末中に、実際の画像を扱ってみてはどうでしょうか。Covid-19に感染した胸部X線画像データセットに対して簡単な分類を行うディープラーニングモデルをテスト実行し、迅速な「AIトリアージ」や「放射線科医の支援」の目的で、X線画像やCT用のツールがdockerなどを介してクラウドにどれほど素早くデプロイされるのかを確認してみましょう。
これは、10分程度の簡易メモです。学習過程において、最も単純なアプローチでハンズオン経験を得られることを願っています。
このデモ環境では、次のコンポーネントが使用されます。 これまで見てきた中で最も単純な形式です。
キーワード: Jupyterノートブック、TensorFlow GPU、Keras、ディープラーニング、MLP、HealthShare
前回の「パート1」では、ディープラーニングデモ環境をセットアップしました。今回「パート2」では、それを使ってできることをテストします。
私と同年代の人の中には、古典的なMLP(多層パーセプトロン)モデルから始めた人がたくさんいます。 直感的であるため、概念的に取り組みやすいからです。
それでは、AI/NNコミュニティの誰もが使用してきた標準的なデモデータを使って、Kerasの「ディープラーニングMLP」を試してみましょう。 いわゆる「教師あり学習」の一種です。 これを実行するのがどんなに簡単かをKerasレベルで見ることにします。
後で、その歴史と、なぜ「ディープラーニング」と呼ばれているのかについて触れることができます。流行語ともいえるこの分野は、実際に最近20年間で進化してきたものです。
HealthShareにも関連しているため、最終的には、少々実現的なユースケースを想像または予測できるようになることを願っています。
次のことを行います。