OMOP Odyssey - Vanna AI(冥界編)
.png)
Vanna.AI - パーソナライズされた AI InterSystems OMOP エージェント
.png)
OHDSI のウェブブックからアキレスに続くこの OMOP の旅シリーズに沿って、適切に記述された R と SQL の組み合わせによって、組織間で共有可能な大規模な分析の結果が導き出されるのを見れば、OMOP 共通データモデルの威力を理解し始めることができます。 とは言え、私には第 3 正規形の知識がないので、約 1 か月前の旅において、Databricks Genie を使って、InterSystems OMOP と Python 相互運用性を活用して SQL を生成しました。 非常にうまくいきましたが、RAG「モデル」がどのように構築され、それを実現するための LLM の使用については、Databricks の内部に魔法が残されています。
OMOP の旅のこの時点で、同じ道で Vanna.ai と出会いました...
Vanna は、LLM を使用してデータベースの正確な SQL クエリを生成するのに役立つ、検索拡張を使った Python パッケージです。Vanna は、データに対して RAG「モデル」をトレーニングしてから質問をするという 2 つの簡単なステップで機能し、それによりデータベースで自動的に実行するようにセットアップできる SQL クエリが返されます。
Vanna は、OMOP 共通データモデルに対して、より高度な制御と独自のスタックを使用して、ユーザー自身が実行するためのすべての要素を公開します。
Vanna キャンプのアプローチは特に素晴らしく、概念的には魔法が実際に起きていると言う人もいるくらいのトリックが演じられているように感じました。
Vanna のトリックには、SQL データベース、ベクトルデータベース、LLM の 3 の要素が必要です。 カードゲームのディーラーが 3 つの山札を差し出して、それぞれから選択を促している状況を想像してください。

明確にするために、SQL データベースは共通データモデルを実装する InterSystems OMOP、使用する LLM は Gemini、手っ取り早く評価するために、ベクトルに Chroma DB を使用して Python ですぐに要点に到達できるようにしています。
Gemini
キーを申し込んで少し背伸びすることにしました。実際に支払っています。1 日 50 プロンプト、1 分 1 プロンプトのレート制限のある無料バージョンを試しましたが、不安でした… 多分、破産した方が幸せになれるような気がするので、今後どうなるのか見守ります。
InterSystems OMOP
別の記事で使用した、期限切れが近づいているものを使用しています。 CDM には、米国の地域ごとに約 100 人の患者数が登録されており、医療従事者と組織も含まれています。
Vanna
ノートブックスタイルで文字を開いてホイールを回転させて Vanna を動かしましょう。pip3 install 'vanna[chromadb,gemini,sqlalchemy-iris]'
Python を整理しましょう。
from vanna.chromadb import ChromaDB_VectorStore
from vanna.google import GoogleGeminiChat
from sqlalchemy import create_engine
import pandas as pd
import ssl
from sqlalchemy import create_engine
import time
このショーのスターを初期化して、モデルに紹介しましょう。 ちょっとおかしいですね。Vanna(White)さんはモデルです。
class MyVanna(ChromaDB_VectorStore, GoogleGeminiChat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
GoogleGeminiChat.__init__(self, config={'api_key': "shaazButt", 'model': "gemini-2.0-flash"})
vn = MyVanna()
@caretdev の sqlalchemy-iris を使って InterSystems OMOP Cloud デプロイメントに接続しましょう。 このダイアレクトで行う作業は、データ業界において急速に iris 製品のモダンなデータ相互運用性の重要な要素となっています。
engine = create_engine("iris://SQLAdmin:LordFauntleroy!!!@k8s-0a6bc2ca-adb040ad-c7bf2ee7c6-e6b05ee242f76bf2.elb.us-east-1.amazonaws.com:443/USER", connect_args={"sslcontext": context})
context = ssl.SSLContext(ssl.PROTOCOL_TLS_CLIENT)
context.verify_mode=ssl.CERT_OPTIONAL
context.check_hostname = False
context.load_verify_locations("vanna-omop.pem")
conn = engine.connect()
SQL クエリを文字列として取り、pandas DataFrame を返す関数を定義します。 こうすることで、Vannna に、SQL を OMOP 共通データモデルで実行するために使用できる関数が提供されます。
def run_sql(sql: str) -> pd.DataFrame:
df = pd.read_sql_query(sql, conn)
return df
vn.run_sql = run_sql
vn.run_sql_is_set = True
モデルにメニューを与える
情報スキーマクエリには、データベースに応じて何らかの調整が必要となる場合があります。 これは優れた出発点です。 情報スキーマを小さなチャンクに分化して LLM が参照できるようにします。 この方法が気に入ったら、このコメントを解除して、Vanna のトレーニングで実行してください。
df_information_schema = vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")
plan = vn.get_training_plan_generic(df_information_schema)
plan
vn.train(plan=plan)
トレーニング
次は、trining データを追加する方法です。 このサンプルをデータベースに一致するように変更してください。 DDL ステートメントは、テーブル名、列名、型、潜在的なリレーションを指定するので強力です。 これらの DDL は、こちらの記事で説明されるとおり、現在ではサポートされた DataBaseConnector を使って生成されます。vn.train(ddl="""
--iris CDM DDL Specification for OMOP Common Data Model 5.4
--HINT DISTRIBUTE ON KEY (person_id)
CREATE TABLE omopcdm54.person (
person_id integer NOT NULL,
gender_concept_id integer NOT NULL,
year_of_birth integer NOT NULL,
month_of_birth integer NULL,
day_of_birth integer NULL,
birth_datetime datetime NULL,
race_source_concept_id integer NULL,
ethnicity_source_value varchar(50) NULL,
ethnicity_source_concept_id integer NULL );
--HINT DISTRIBUTE ON KEY (person_id)
CREATE TABLE omopcdm54.observation_period (
observation_period_id integer NOT NULL,
person_id integer NOT NULL,
observation_period_start_date date NOT NULL,
observation_period_end_date date NOT NULL,
period_type_concept_id integer NOT NULL );
--HINT DISTRIBUTE ON KEY (person_id)
CREATE TABLE omopcdm54.visit_occurrence (
visit_occurrence_id integer NOT NULL,
discharged_to_source_value varchar(50) NULL,
preceding_visit_occurrence_id integer NULL );
--HINT DISTRIBUTE ON KEY (person_id)
CREATE TABLE omopcdm54.visit_detail (
visit_detail_id integer NOT NULL,
person_id integer NOT NULL,
visit_detail_concept_id integer NOT NULL,
provider_id integer NULL,
care_site_id integer NULL,
visit_detail_source_value varchar(50) NULL,
visit_detail_source_concept_id Integer NULL,
--HINT DISTRIBUTE ON KEY (person_id)
CREATE TABLE omopcdm54.condition_occurrence (
condition_occurrence_id integer NOT NULL,
person_id integer NOT NULL,
visit_detail_id integer NULL,
condition_source_value varchar(50) NULL,
condition_source_concept_id integer NULL,
condition_status_source_value varchar(50) NULL );
--HINT DISTRIBUTE ON KEY (person_id)
CREATE TABLE omopcdm54.drug_exposure (
drug_exposure_id integer NOT NULL,
person_id integer NOT NULL,
dose_unit_source_value varchar(50) NULL );
--HINT DISTRIBUTE ON KEY (person_id)
CREATE TABLE omopcdm54.procedure_occurrence (
procedure_occurrence_id integer NOT NULL,
person_id integer NOT NULL,
procedure_concept_id integer NOT NULL,
procedure_date date NOT NULL,
procedure_source_concept_id integer NULL,
modifier_source_value varchar(50) NULL );
--HINT DISTRIBUTE ON KEY (person_id)
CREATE TABLE omopcdm54.device_exposure (
device_exposure_id integer NOT NULL,
person_id integer NOT NULL,
device_concept_id integer NOT NULL,
unit_source_value varchar(50) NULL,
unit_source_concept_id integer NULL );
--HINT DISTRIBUTE ON KEY (person_id)
CREATE TABLE omopcdm54.observation (
observation_id integer NOT NULL,
person_id integer NOT NULL,
observation_concept_id integer NOT NULL,
observation_date date NOT NULL,
observation_datetime datetime NULL,
<SNIP>
""")
ビジネスの用語や定義に関するドキュメントを追加することもあるかもしれません。ここでは、OMOP に変換された FHIR のリソース名を追加したいと思います。
vn.train(documentation="Our business is to provide tools for generating evicence in the OHDSI community from the CDM")
vn.train(documentation="Another word for care_site is organization.")
vn.train(documentation="Another word for provider is practitioner.")
次に、InterSystems OMOP 共通データモデルのすべてのデータを追加しましょう。おそらく、これを行うにはもっと良い方法ですが、バイト単位で支払いを受け取っています。
cdmtables = ["care_site", "cdm_source", "cohort", "cohort_definition", "concept", "concept_ancestor", "concept_class", "concept_relationship", "concept_synonym", "condition_era", "condition_occurrence", "cost", "death", "device_exposure", "domain", "dose_era", "drug_era", "drug_exposure", "drug_strength", "episode", "episode_event", "fact_relationship", "location", "measurement", "metadata", "note", "note_nlp", "observation", "observation_period", "payer_plan_period", "person", "procedure_occurrence", "provider", "relationship", "source_to_concept_map", "specimen", "visit_detail", "visit_occurrence", "vocabulary"]
for table in cdmtables:
vn.train(sql="SELECT * FROM WHERE OMOPCDM54." + table)
time.sleep(60)
ここで、Gemini がデータを参照できる機能を追加しました。道中でこれを実行するのか、または巧妙なやり方で Google に OMOP データを提供するのかを確認してください。
さぁ、最高のパット・セイジャックを演じて、輝かしい Vanna アプリを起動しましょう。
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn,allow_llm_to_see_data=True, debug=False)
app.run()
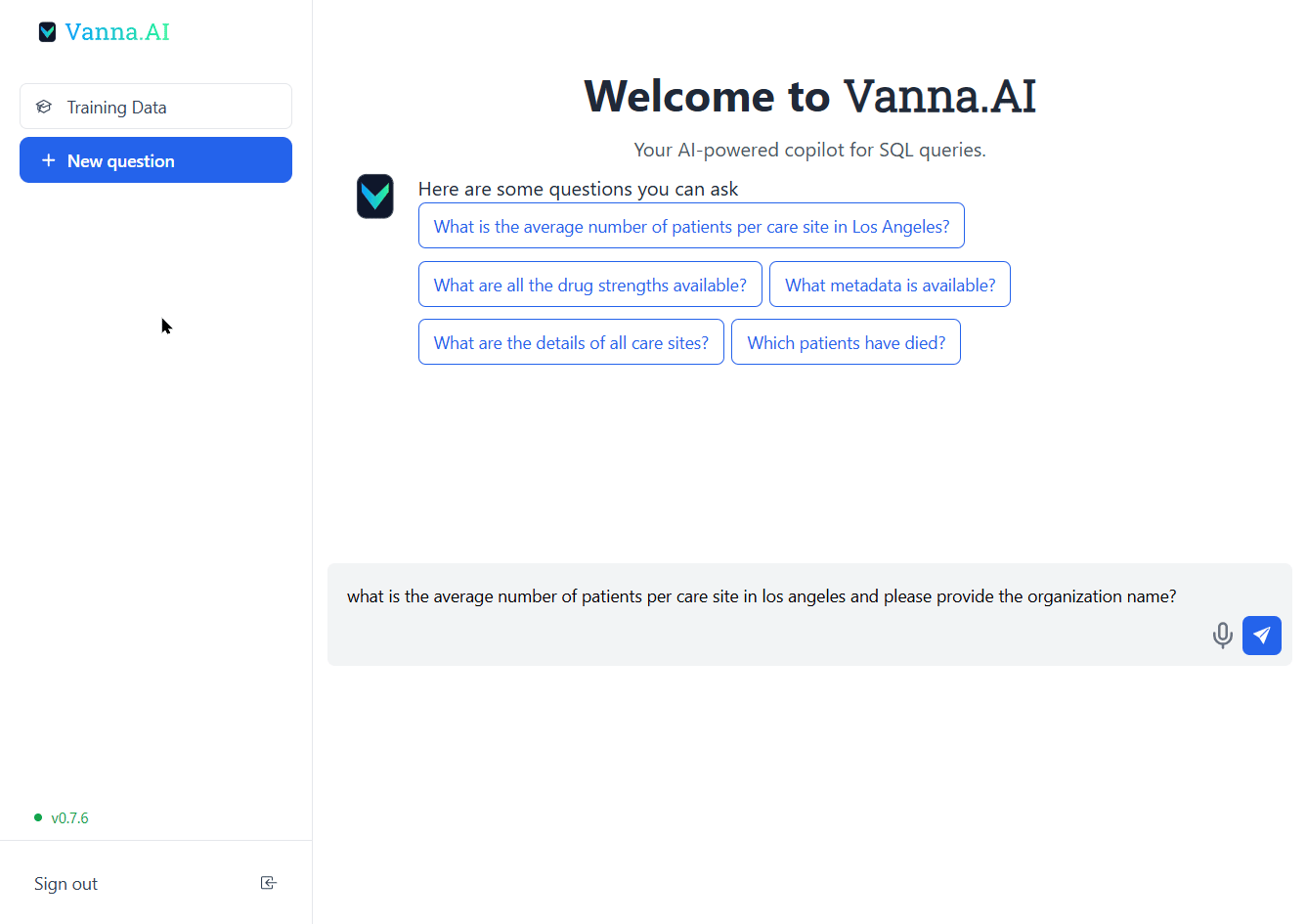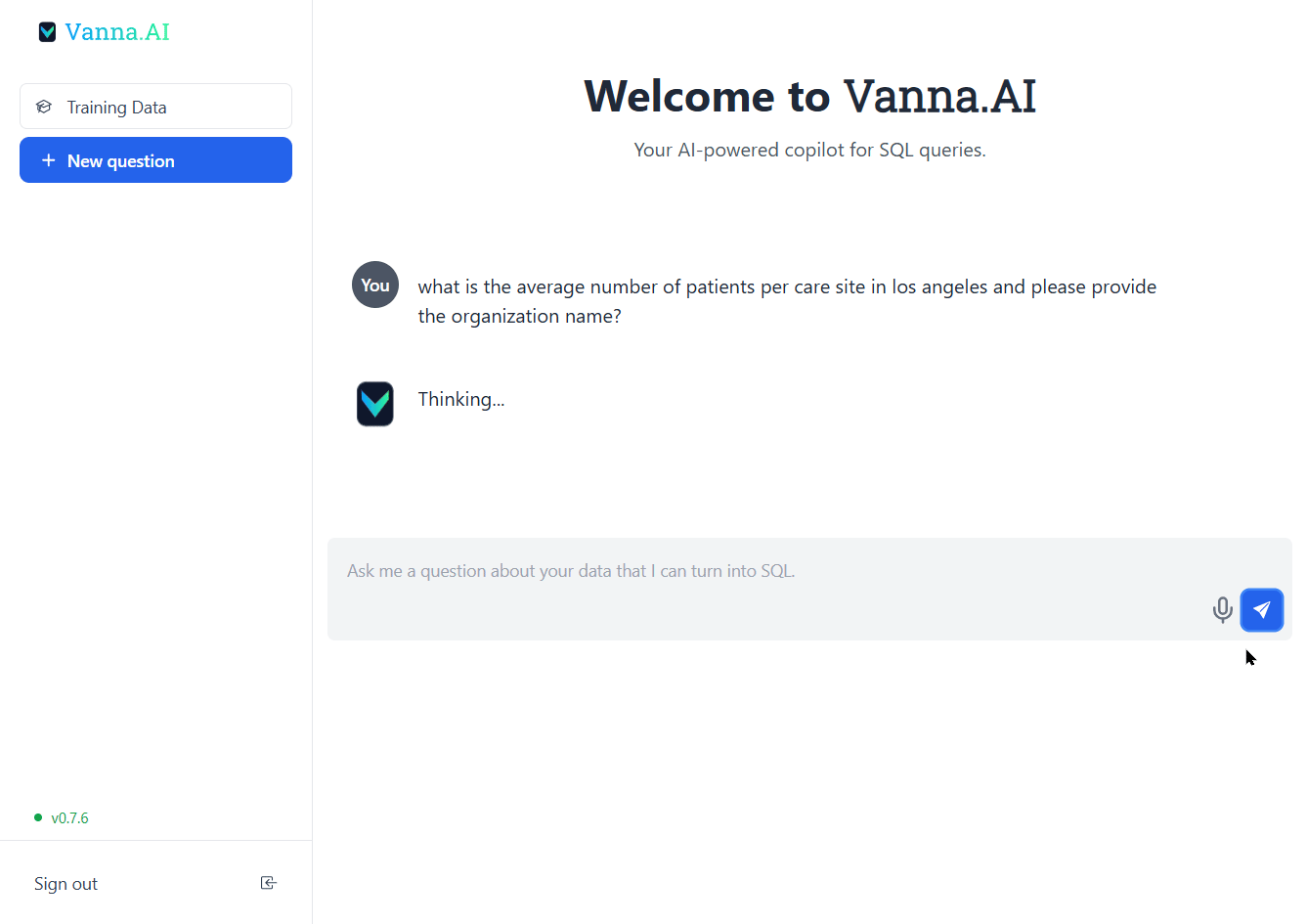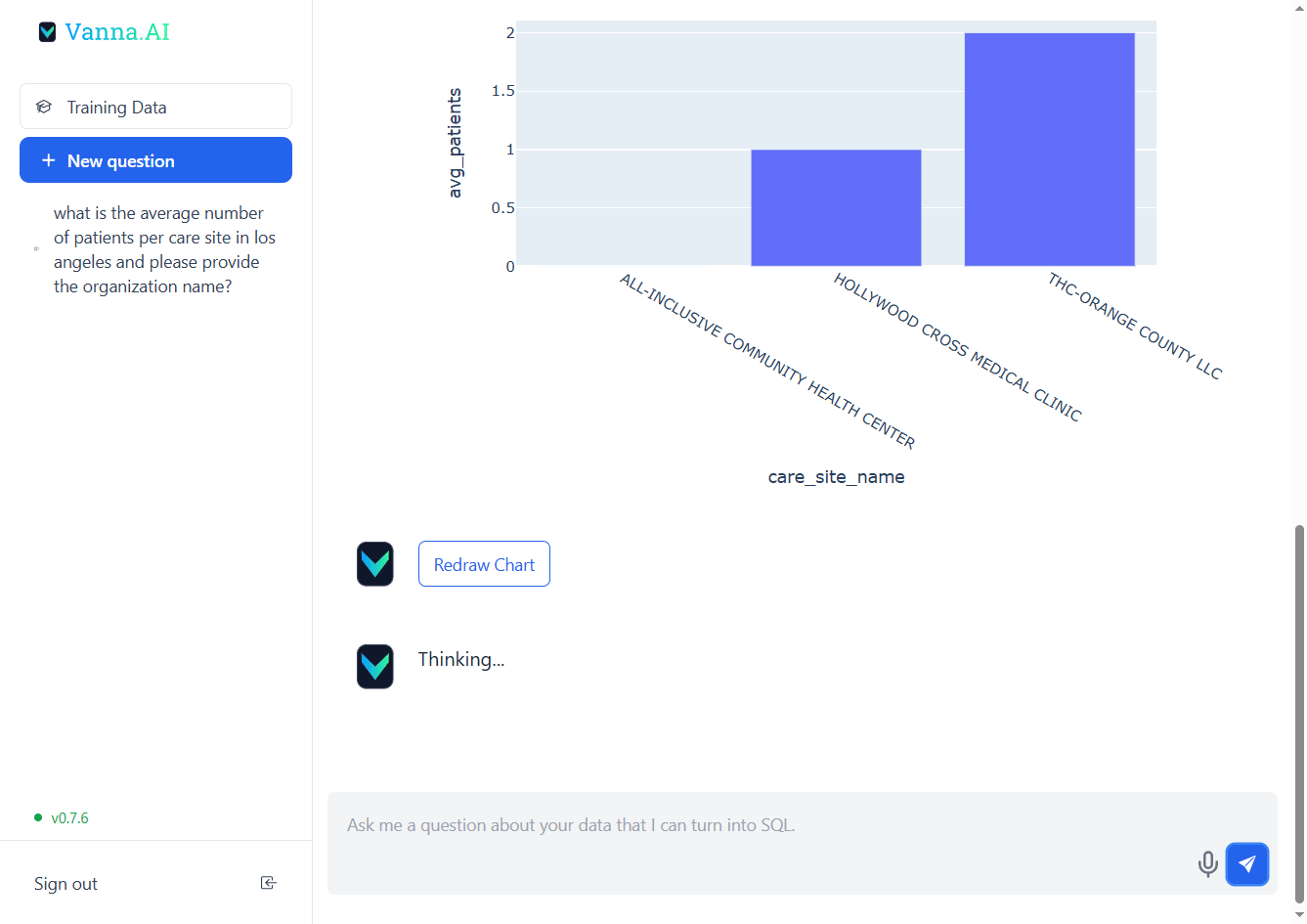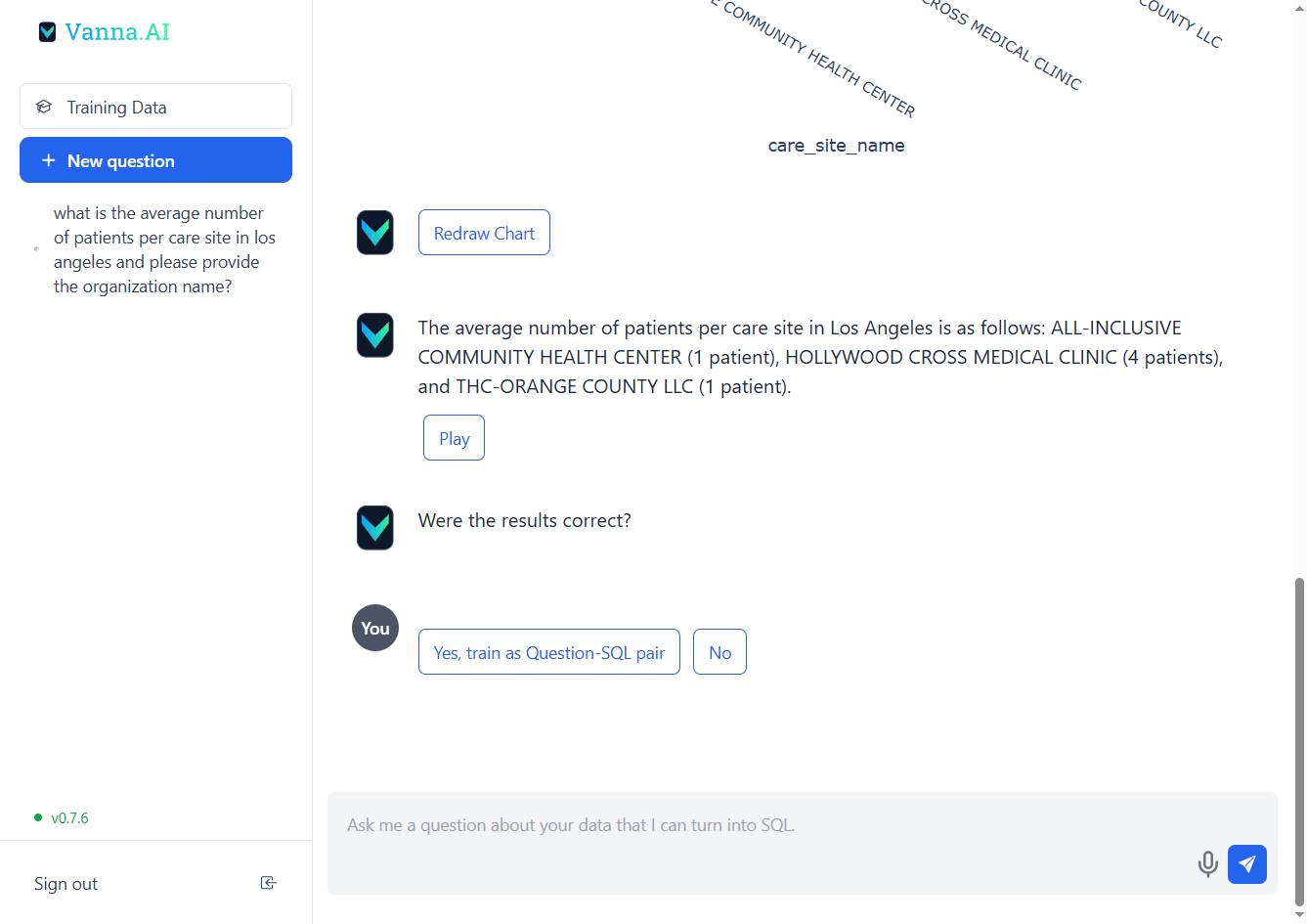
Skynet!
これはちょっとハックっぽいですが、AIを将来アプリと統合して実現したいのは、自然言語で質問し、SQL クエリを返してから、sqlalchemy-iris を使用して InterSystems OMOP デプロイメントに対してそのクエリをすぐに使用するということです。
while True:
import io
import sys
old_stdout = sys.stdout
sys.stdout = io.StringIO() # Redirect stdout to a dummy stream
question = 'How Many Care Sites are there in Los Angeles?'
sys.stdout = old_stdout
sql_query = vn.ask(question)
print("Ask Vanna to generate a query from a question of the OMOP database...")
#print(type(sql_query))
raw_sql_to_send_to_sqlalchemy_iris = sql_query[0]
print("Vanna returns the query to use against the database.")
gar = raw_sql_to_send_to_sqlalchemy_iris.replace("FROM care_site","FROM OMOPCDM54.care_site")
print(gar)
print("Now use sqlalchemy-iris with the generated query back to the OMOP database...")
result = conn.exec_driver_sql(gar)
#print(result)
for row in result:
print(row[0])
time.sleep(3)
ユーティリティ
いつでも、Vanna パッケージが参照できる OMOP データを検査できます。 また、古い情報や不正確な情報がある場合は、training データを削除することも可能です(UI からも行えます)。training_data = vn.get_training_data()
training_data
vn.remove_training_data(id='omop-ddl')
IRIS Vectors の使用について
幸運を祈ってください。押しつぶすべきものをすべて押しつぶして、昇る太陽に抵抗することができれば、次のリポジトリを使用して Vanna に IRIS Vectors を実装します。