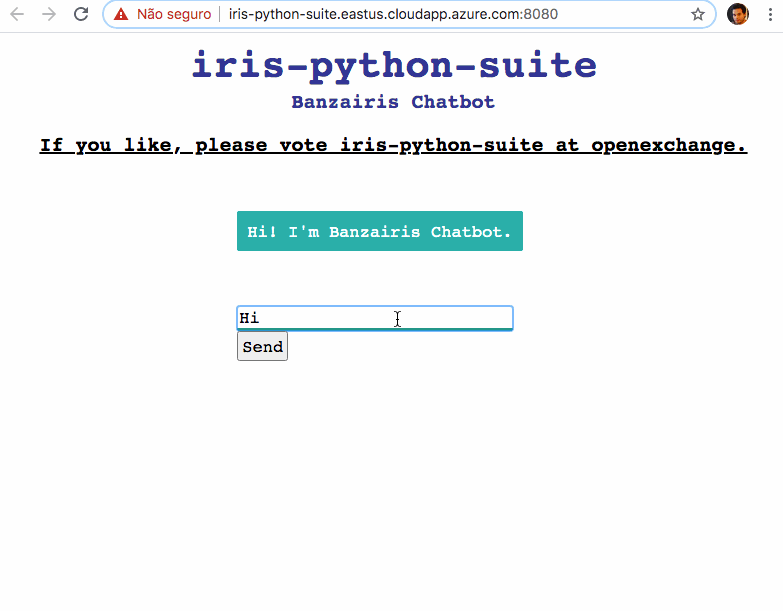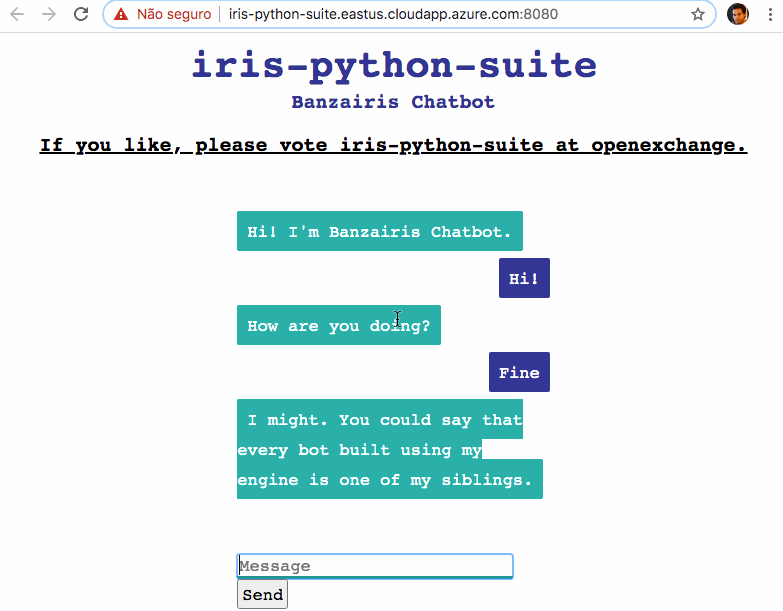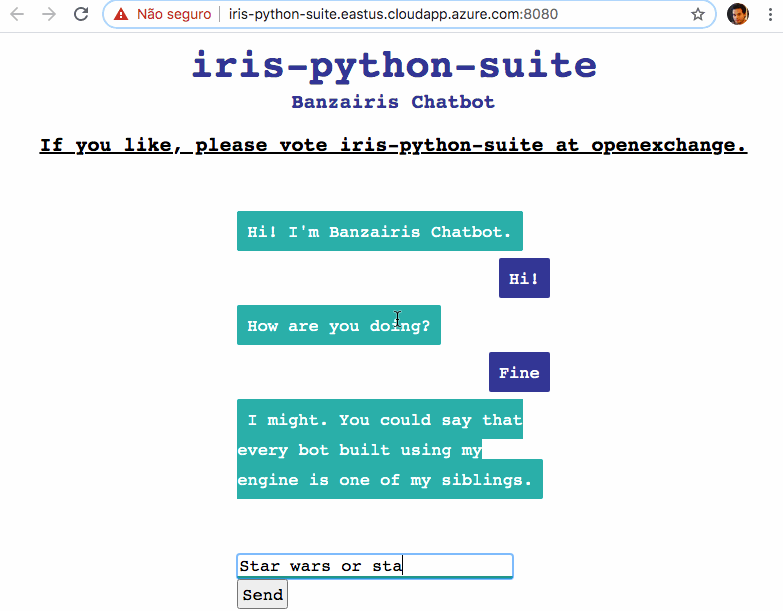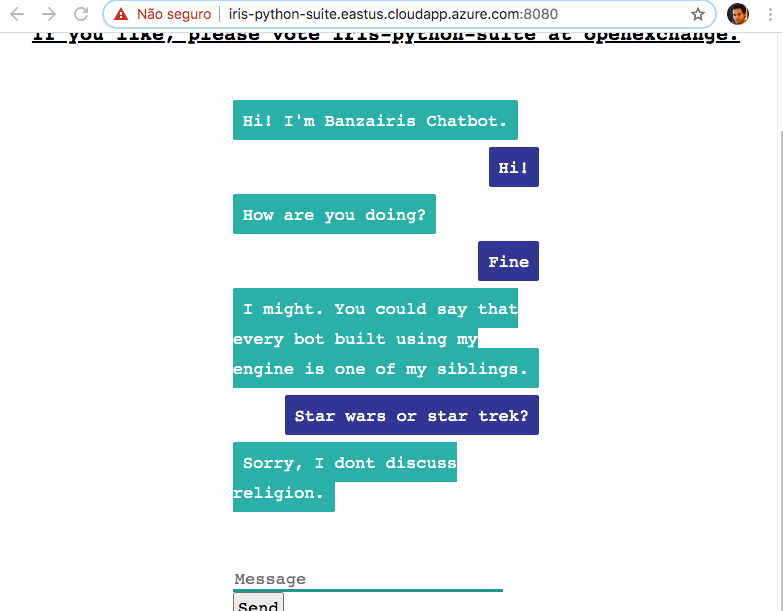
好きなもので
好きなものでキーワード: IRIS、IntegratedML、Flask、FastAPI、Tensorflow Serving、HAProxy、Docker、Covid-19
目的:
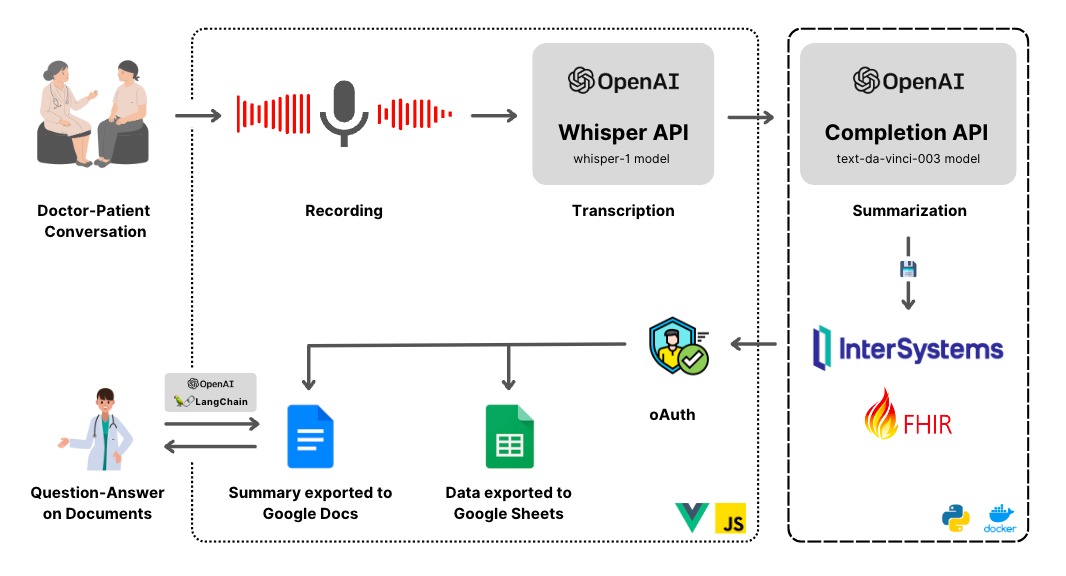
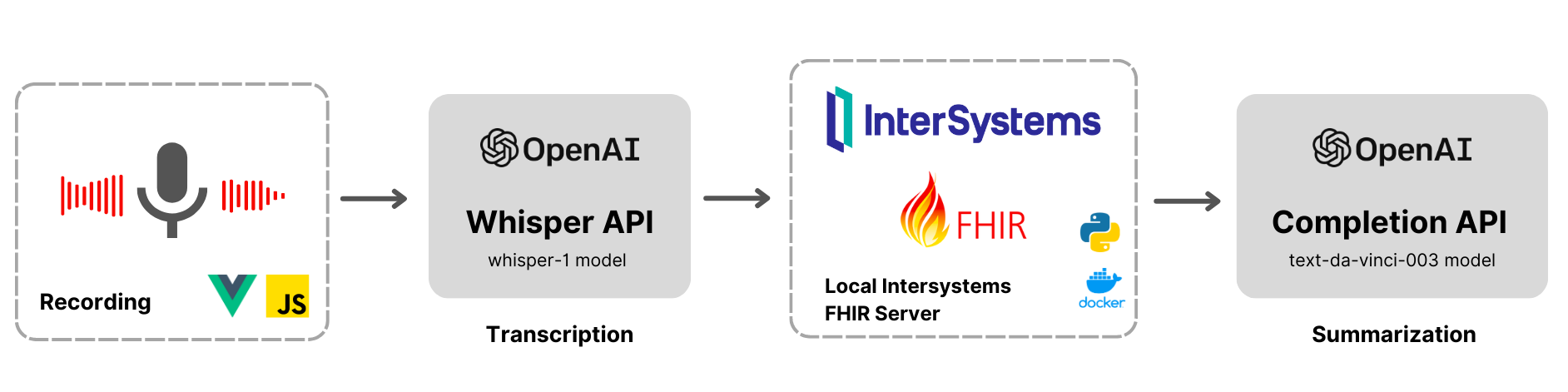
過去数か月に渡り、潜在的なICU入室を予測するための単純なCovid-19 X線画像分類器やCovid-19ラボ結果分類器など、ディープラーニングと機械学習の簡単なデモをいくつか見てきました。 また、ICU分類器のIntegratedMLデモ実装についても見てきました。 「データサイエンス」の旅路はまだ続いていますが、「データエンジニアリング」の観点から、AIサービスデプロイメントを試す時期が来たかもしれません。これまでに見てきたことすべてを、一式のサービスAPIにまとめることはできるでしょうか。 このようなサービススタックを最も単純なアプローチで達成するには、どういった一般的なツール、コンポーネント、およびインフラストラクチャを活用できるでしょうか。
対象範囲
対象:
ジャンプスタートとして、docker-composeを使用して、次のDocker化されたコンポーネントをAWS Ubuntuサーバーにデプロイできます。
 Open Exchange app
Open Exchange app