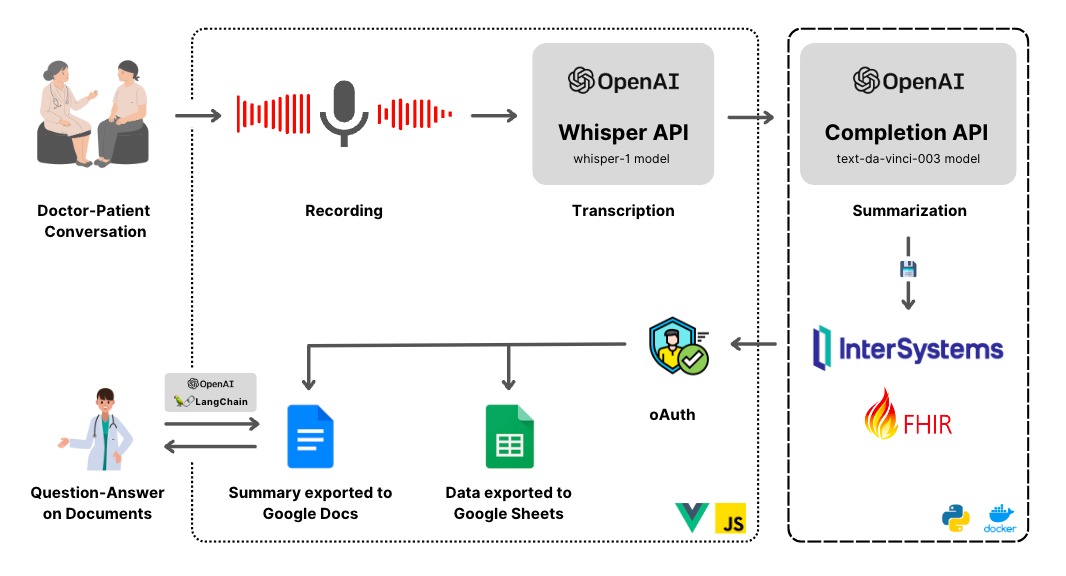
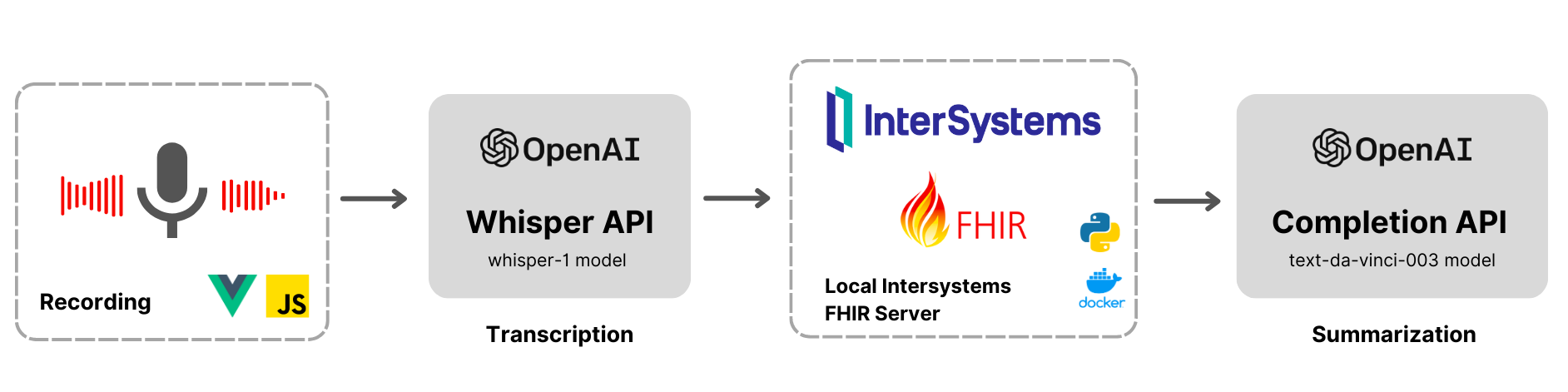
好きなもので
好きなもので糖尿病は、医学会でよく知られるいくつかのパラメーターから発見することが可能です。 この測定により、医学界とコンピューター化されたシステム(特に AI)を支援すべく、(米)国立糖尿病・消化器・腎疾病研究所(NIDDK)は、糖尿病の検出/予測における ML アルゴリズムをトレーニングするための非常に便利なデータセットを公開しました。 このデータセットは、ML の最大級のデータリポジトリとして最もよく知られている Kaggle に公開されています: https://www.kaggle.com/datasets/mathchi/diabetes-data-set。
糖尿病データセットには、以下のメタデータ情報が含まれています(出典: https://www.kaggle.com/datasets/mathchi/diabetes-data-set):
 Open Exchange app
Open Exchange app