日付
日付 Open Exchange app
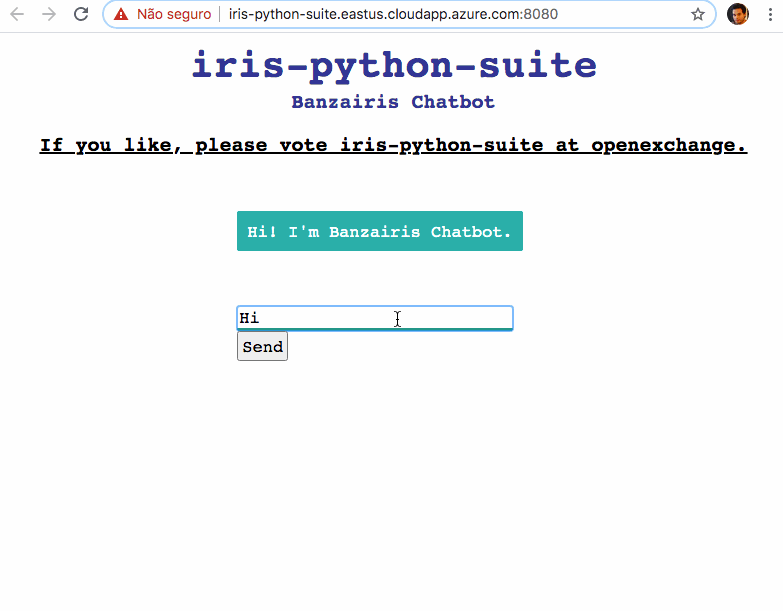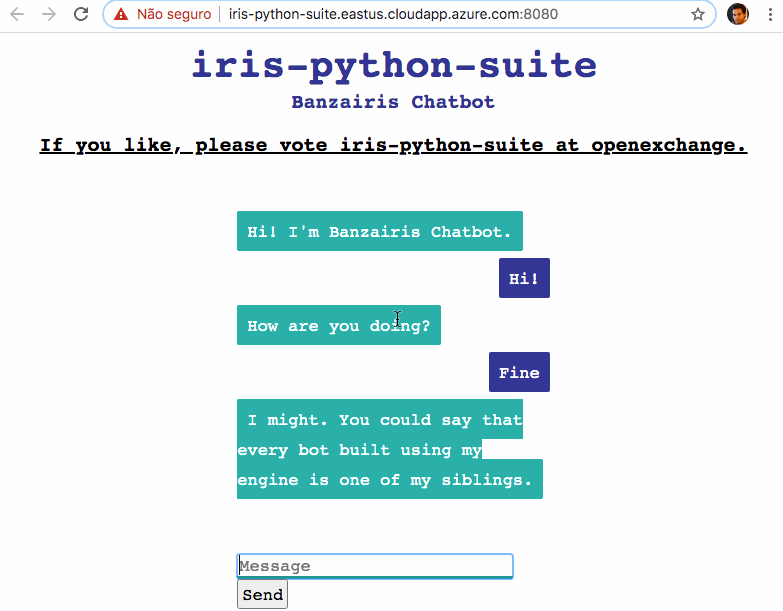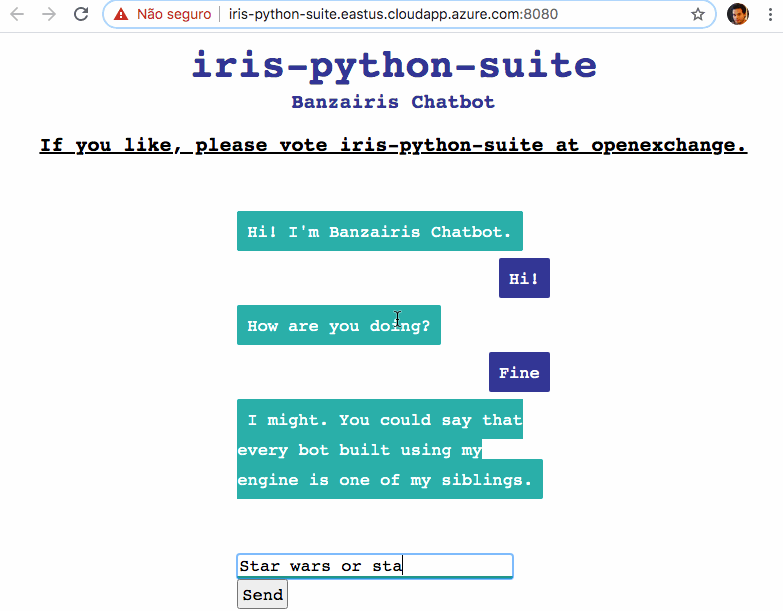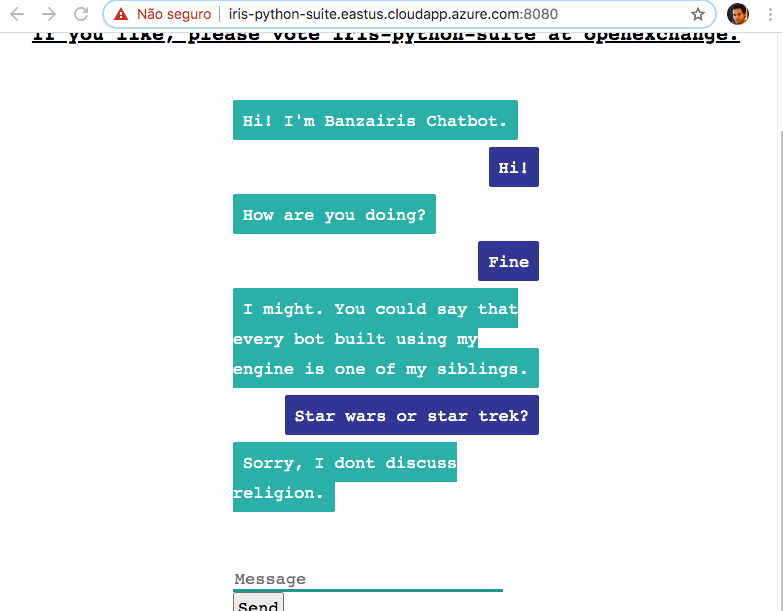
Open Exchange app前回の記事では、ICD-10 による診断のコーディングをサポートできるように開発された d[IA]gnosis アプリケーションを紹介しました。 この記事では、InterSystems IRIS for Health が、事前トレーニングされた言語モデル、そのストレージ、およびその後の生成されたすべてのベクトルの類似性の検索を通じて ICD-10 コードのリストからベクトルを生成するために必要なツールをどのように提供するかを見ていきます。

はじめに
AI モデルの開発に伴って登場した主な機能の 1 つは、RAG(検索拡張生成)という、コンテキストをモデルに組み込むことで LLM モデルの結果を向上させることができる機能です。 この例では、コンテキストは ICD-10 診断のセットによって提供されており、これらを使用するには、まずこれらをベクトル化する必要があります。
診断リストをベクトル化するにはどうすればよいでしょうか?