Python から InterSystems IRIS へ接続する方法の1つである「Native API」(※)の使用方法ご説明します。
※ Python からのアクセスは、Native API の他に、PyODBC を利用した接続方法もあります。PyODBC の利用については別の記事でご説明します。
Python から InterSystems IRIS へ接続する方法の1つである「Native API」(※)の使用方法ご説明します。
※ Python からのアクセスは、Native API の他に、PyODBC を利用した接続方法もあります。PyODBC の利用については別の記事でご説明します。
アイリスデータセットのK平均クラスタリング
みなさん、こんにちは。 今回はアイリスデータセットでk平均アルゴリズムを使用します。
注意:Ubuntu 18.04、Apache Zeppelin 0.8.0、python 3.6.5で以下を実行しました。
K平均法は、クラスタリングの問題を解決する最も単純な教師なし学習アルゴリズムの1つです。 このアルゴリズムは、同じグループ内のオブジェクト(グループはクラスターです)が他のグループ内のオブジェクトよりも(意味的に)互いに類似するようにすべてのオブジェクトをグループ化します。 例えば、緑の芝生に赤いボールのある画像があるとします。 K平均法はすべてのピクセルを2つのクラスターに分割します。 1番目のクラスターにはボールのピクセルが含まれ、2番目のクラスターには芝生のピクセルが含まれます。
アイリスデータセットは、3種のアイリスの花の特徴をいくつか含むテーブルです。 種には「Iris-setosa」、「Iris-versicolor」、「Iris-virginica」があります。 それぞれの花には5つの特徴(花びらの長さ、花びらの幅、がく片の長さ、がく片の幅、種 )があります。
まず、すべての要件を確認しましょう。 次のように、ターミナルに「which python3」貼り付けてください。

優勝特典
1、審査員から多く票を集めたアプリケーションには、以下の賞金が贈られます。
🥇 1位 - $2,000
🥈 2位 - $1,000
🥉 3位 - $500
2、Developer Community で多く票を集めたソリューションには、以下の賞金が贈られます。
🥇 1位 - $1,000
🥈 2位 - $500
複数の参加者が同数の票を獲得した場合、全参加者が勝者となり賞金は勝者間で分配されます。
参加資格
どなたでもご参加いただけます。
コンテストのスケジュール
6月29日~7月12日 応募期間
7月13日~7月19日 投票
7月20日 優秀者発表
コンテストの課題
AI / ML
InterSystems IRIS を使った AI/ML ソリューションの開発。
InterSystems IRIS を使用して開発された AI/ML ソリューションの中から、優秀アプリケーションに賞が贈られます。
アプリケーションは、ライブラリ、パッケージ、ツール、または InterSystems IRIS を使用した AI/ML ソリューション等です。
VMware vSphereで実行する大規模な本番データベースのCPUキャパシティプランニングについて、お客様やベンダー、または社内のチームから説明するように頼まれることが良くあります。
要約すると、大規模な本番データベースのCPUのサイジングには、いくつかの単純なベストプラクティスがあります。
このことから、通常いくつかの一般的な疑問が生まれます。
こういった疑問につては、下の例を使って答えることにします。 ただし、ベストプラクティスは決定事項ではありません。 ときには妥協することも必要です。 たとえば、大規模なデータベースVMはNUMAノードに収まらない可能性が高く、それはそれでも良いのです。
前回の記事では、pButtonsを使って履歴パフォーマンスメトリックを収集する方法を説明しました。 すべてのデータプラットフォームインスタンス(Ensemble、Cachéなど)にはpButtonsがインストールされていることがわかっているため、私はpButtonsを使用する傾向にありますが、 Cachéパフォーマンスメトリックをリアルタイムで収集、処理、表示する方法はほかにもあり、単純な監視や、それよりもさらに重要な、より高度な運用分析とキャパシティプランニングに使用することができます。 データ収集の最も一般的な方法の1つは、SNMP(簡易ネットワーク管理プロトコル)を使用することです。
SNMPは、Cachéが管理・監視情報をさまざまな管理ツールに提供するための標準的な方法です。 Cachéのオンラインドキュメンテーションには、CachéとSNMP間のインターフェースに関する詳細が説明されています。 SNMPはCachéと「単純に連携」するはずですが、構成にはいくつかの技と罠があります。 私自身、はじめに何度も過ちを繰り返し、InterSystemsの同僚から助けを得ながらCachéをオペレーティングシステムのSNMPマスターエージェントにやっと接続できた経験から、皆さんが同じような困難を避けられるようにこの記事を書くことにしました。
この記事では、InterSystemsデータプラットフォームで実行するデータベースアプリケーションにおけるグローバルバッファ、ルーチンバッファ、gmheap、locksizeなどの共有メモリ要件のサイジングアプローチを説明し、サーバー構成時およびCachéアプリケーションの仮想化時に検討すべきパフォーマンスのヒントをいくつか紹介します。 これまでと同じように、Cachéについて話すときは、すべてのデータプラットフォーム(Ensemble、HealthShare、iKnow、Caché)を指しています。
最初にCachéを使い始めたころ、ほとんどの顧客オペレーティングシステムは32ビットで、Cachéアプリケーションのメモリは少なく、高価なものでした。 一般的に展開されていたIntelサーバーにはコアが数個しかなく、スケールアップするには、大型のサーバーを使用するか、ECPを使って水平方向にスケールアウトするしかありませんでした。 今では、基本製品グレードのサーバーでさえも、マルチプロセッサ、数10個のコア、TBにまで増設できる可能性も備わった128GBまたは256GBの最低メモリが搭載されています。
今週は、ハードウェアの主な”食品群” (^_^) の1つであるCPUに注目します。お客様から、次のようなシナリオについてのアドバイスを求められました。お客様の本番サーバーはサポート終了に近づいており、ハードウェアを交換する時期が来ています。 また、仮想化によってサーバーを一元的に管理できるようにし、ベアメタルか仮想化によりキャパシティを適正化したいとも考えています。 今日はCPUに焦点を当てますが、後日の記事では、メモリやIOといったほかの主要食品群を適正化するアプローチについて説明したいと思います。
では、質問を整理しましょう。
2017年6月追記:
VMware CPUに関する考慮事項と計画の詳細、および一般的な質問と問題の詳細については、「大規模データベースの仮想化 - VMware CPUのキャパシティ計画」の記事も参照してください。
前回の投稿では、pButtonsを使用してパフォーマンスメトリックを24時間収集する処理をスケジュールしました。 この投稿では、収集対象の主なメトリックのいくつかと、それらの土台となるシステムハードウェアがどのように関連しているかを見ていきます。 また、Caché(または任意のInterSystemsデータプラットフォーム)メトリックとシステムメトリックの関係についても調べます。 さらに、これらのメトリックを使用してシステムの毎日の健全性を把握し、パフォーマンスの問題を診断する方法もご紹介します。
2016年10月に編集...
pButtonsデータを .csv ファイルに抽出するスクリプトの例はこちらで確認できます。
2018年3月に編集...
画像が消えていましたが、元に戻しました。
この連載を読み進めていくと、パフォーマンスに影響を与えるサーバーコンポーネントを次のように分類できることが分かってきます。
- CPU
- メモリ
- ストレージIO
- ネットワークIO
アプリケーションがデプロイされ、すべてが問題なく動作しています。 素晴らしいですね! しかし、その後突然電話が鳴り止まなくなりました。アプリケーションが時々「遅くなる」というユーザーからの苦情の電話です。 これは一体どういうことなのでしょうか? なぜ時々遅くなるのでしょうか? このような速度低下を検出し、解決するにはどのようなツールと統計情報に注目すべきなのでしょうか? お使いのシステムのインフラはユーザーの負荷に対応できていますか? 本番環境を調べる前に、どのようなインフラ設計上の問題を問うべきなのでしょうか? 新しいハードウェアのキャパシティプランニングを、必要以上の設備投資を行うことなく自信を持って行うにはどうすればよいのでしょうか? どうすれば電話がかかってこなくなるのでしょうか? そもそも電話がかかってこないようにするには、どうすればよかったのでしょうか?
これは、システムパフォーマンスの監視、確認、トラブルシューティングに使用できるツールとメトリック、およびパフォーマンスに影響を与えるシステムとアーキテクチャの設計上の考慮事項について説明する連載の最初の投稿です。
「データプラットフォームのキャパシティプランニングとパフォーマンス」シリーズの全記事をリストしました。 その下には私の一般的なその他の記事も記載しています。 このシリーズに新しい記事が追加されるたびに、このリストを更新する予定です。
通常、各記事はその前の記事の続きとして書かれていますが、ほかの記事を飛び越して気になるものを読むこともできます。
コミュニティに掲載中のアーキテクチャ全般の記事を集めたリストです。
 前のパート(1、2)では、ツリーとしてのグローバルを話題に取り上げました。 この記事では、それらを疎な配列と見なします。
前のパート(1、2)では、ツリーとしてのグローバルを話題に取り上げました。 この記事では、それらを疎な配列と見なします。
疎な配列は、ほとんどの値が同一であると想定される配列の種類です。
疎な配列は実際には非常に大きいため、同一の要素でメモリを占有することには意味がありません。 したがって、疎な配列を整理し、重複した値の格納にメモリが浪費されないようにすることには意味があります。
疎な配列は、J、MATLABなど一部のプログラミング言語では言語の一部になっています。 他の言語では、疎な配列を使用できるようにする特別なライブラリが存在します。 C++の場合は、Eigenなどがあります。
次の理由により、グローバルは疎な配列を実装するのに適した候補であると言えます。
Set ^a(1, 2, 3)=5
Write ^a(1, 2, 3) 先週、私たちはInterSystems IRIS Data Platformを発表しました。これは、トランザクション、分析、またはその両方に関係なく、あらゆるデータの取り組みに対応する新しい包括的なプラットフォームです。 CachéとEnsembleでお客様が慣れ親しんでいる多くの機能が取り込まれていますが、この記事では、プラットフォームの新機能の1つであるSQLシャーディングについてもう少し詳しく説明します。これはスケーラビリティに関する強力な新機能です。
ちょうど4分41秒の時間がある方は、スケーラビリティに関するこちらの詳しい動画をご覧ください。 ヘッドホンがない方や聞き心地の良いナレーションが同僚の方の迷惑になると思う方は、どうぞ読み進めてください!
1日に何百万件という株取引を処理する場合でも、1日に数万人の患者を治療する場合でも、このような業務を支えているデータプラットフォームは、こういった大きなスケールに透過的に対処できなければなりません。 「透過的に」というのは、プラットフォームがスケーリングの面を請け負い、開発者やビジネスユーザーは処理量を気にすることなく、それぞれが専門とする業務とアプリケーションに専念することができるという意味です。
長年にわたり、Cachéは垂直スケーラビリティをサポートしてきました。
 最初の記事については、パート1を参照してください。
最初の記事については、パート1を参照してください。
順序付きツリーなどの構造には、さまざまな特殊ケースがあります。 グローバルを使用する上で実用的な価値があるものを見てみましょう。
 グローバルは配列のようにも、通常の変数のようにも使用できます。 例えば、カウンターを作成する場合を考えてみましょう。
グローバルは配列のようにも、通常の変数のようにも使用できます。 例えば、カウンターを作成する場合を考えてみましょう。
Set ^counter = 0 ; カウンターの設定
Set id=$Increment(^counter) ; アトミックなインクリメント操作
また、グローバルには値に加えて枝を持たせることができます。 一方が他方を除外することはありません。
実際、これは典型的なキー・バリューベースのデータ構造です。 また、値の代わりに値のタプルを保存すると、主キーを持つ通常のテーブルが得られます。
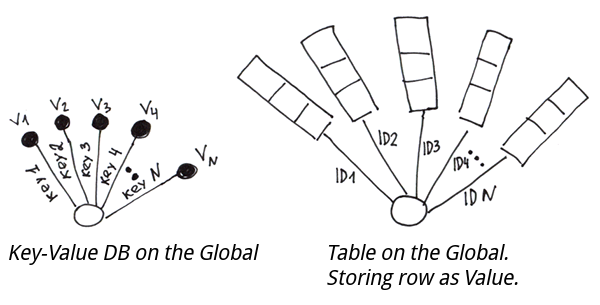
グローバルに基づくテーブルを実装するには、カラムの値から文字列を作成し、主キー別にそれをグローバルに保存する必要があります。 読み取りの時に文字列をカラムに分割できるようにするため、以下のいずれかを使用することができます。
次の手順で、/api/monitor サービスから利用可能なメトリックのサンプル一覧を表示することができます。
前回の投稿では、IRISのメトリックをPrometheus形式で公開するサービスの概要を説明しました。 この投稿では、コンテナにIRISプレビューリリース2019.4 をセットアップして実行し、メトリックを一覧表示する方法をお伝えします。
この投稿は、Dockerがインストールされた環境があることを前提としています。 そうでない場合は、今すぐお使いのプラットフォームにインストールしてください :)
「プレビューの配布」のダウンロード手順に従い、プレビューライセンスキーとIRISのDockerイメージをダウンロードします。 この例では、InterSystems IRIS for Health 2019.4を選択しています。
「機能紹介:Dockerコンテナ内のInterSystems製品について」の指示に従ってください。 すでにコンテナに精通している場合は、「InterSystems IRISのDockerイメージをダウンロードする」というタイトルのセクションに進んでください。
次のターミナル出力は、私がDockerイメージの読み込みに使用している手順を示しています。
Cachéの優れた可用性とスケーリング機能の1つは、エンタープライズキャッシュプロトコル(ECP)です。 アプリケーション開発中に考慮することにより、ECPを使用した分散処理は、Cachéアプリケーションのスケールアウトアーキテクチャを可能にします。 アプリケーション処理は、アプリケーションを変更することなく、単一のアプリケーションサーバーから最大255台といった非常に高いレートにまで、アプリケーションサーバー処理能力を拡張できます。
ECPは、私が関与していたTrakCareのデプロイメントで長年広く使用されていました。 10年前は、主要ベンダーの1つが提供する「大きな」x86サーバーは、合計で8つのコアしか備えていなかったかもしれません。 大規模なデプロイメントの場合、ECPは、高価な大型コンピュータを使う単一のエンタープライズサーバーではなく、コモディティサーバーでの処理をスケールアウトする方法でした。 コア数の多いエンタープライズサーバーでさえ制限があったため、ECPはそれらのサーバーへのデプロイメントのスケーリングにも使用されました。
現在、ほとんどの新しいTrakCareのデプロイメントや主流ハードウェアへのアップグレードは、ECPでのスケーリングを必要としません。 現行の2ソケットx86プロダクションサーバーは、数十のコアと巨大なメモリを持つことができます。
私や他のテクノロジアーキテクトは、Caché IOの要件と、Cachéアプリケーションがストレージシステムを使用する方法を顧客とベンダーに説明しなければならないことがよくあります。以下の表は、一般的なCaché IOプロファイルと、トランザクションデータベースアプリケーションの要件を顧客やベンダーに説明するときに役立ちます。 オリジナルの表は、マーク・ボリンスキーが作成しました。
今後の投稿ではストレージIOについて詳しく説明する予定なので、今後の記事の参考資料として、今回これらの表も公開します。
予測可能なディスクIOパフォーマンスを提供し、高可用性機能をサポートし、アプリケーションにストレージの冗長性、スケーラビリティ、および信頼性を提供するには、ストレージアレイなど、ストレージを適切に設定することが不可欠です。
選択したストレージアレイテクノロジーによっては、物理層のディスクストレージがプールまたはディスクグループに分離される場合があります。 可能であれば、可用性とパフォーマンスのために、予想されるIOプロファイルに基づいてストレージをパーティション化する必要があります。 たとえば、データとジャーナル(トランザクションログ)は別々の物理ディスクグループに存在する必要があります。
この記事では、REST API開発への仕様ファーストアプローチについて説明します。
従来のコードファーストREST API開発は次のようになります。
仕様ファーストのアプローチでは同じ手順を行いますが、順序が逆になります。 ドキュメントを兼ねた仕様書を作成し、そこからRESTアプリの定型文を生成して、最後にビジネスロジックを書きます。
これは、次の理由でメリットがあります。
 データを格納するための魔法の剣であるグローバルは、かなり前から存在しています。しかしながら、これを効率的に使いこなせる人や、この素晴らしい道具の全貌を知る人はそう多くありません。 グローバルを本当に効果を発揮できるタスクに使用すると、パフォーマンスの向上やソリューション全体の劇的な単純化といった素晴らしい結果を得ることができます(1、2)。
データを格納するための魔法の剣であるグローバルは、かなり前から存在しています。しかしながら、これを効率的に使いこなせる人や、この素晴らしい道具の全貌を知る人はそう多くありません。 グローバルを本当に効果を発揮できるタスクに使用すると、パフォーマンスの向上やソリューション全体の劇的な単純化といった素晴らしい結果を得ることができます(1、2)。
グローバルは、SQLテーブルとはまったく異なる特別なデータの格納・処理方法を提供します。 グローバルは1966年にM(UMPS)プログラミング言語で初めて導入され、医療データベースで使用されていました。 また、現在も同じように使用されていますが、金融取引など信頼性と高いパフォーマンスが最優先事項である他のいくつかの業界でも採用されています。
M(UMPS)は後にCaché ObjectScript(COS)に進化しました。 COSはInterSystemsによってMの上位互換として開発されました。 元の言語は現在も開発者コミュニティに受け入れられており、いくつかの実装で生き残っています。 ウェブ上では、MUMPS Googleグループ、Mumpsユーザーグループ、ISO規格といった複数の活動が見られます。
最新のグローバルベースのDBMSは、トランザクション、ジャーナリング、レプリケーション、パーティショニングをサポートしています。
この連載記事では、InterSystemsの技術とGitLabを使用したソフトウェア開発に向けて実現可能な複数の手法を紹介し、議論したいと思います。 次のようなトピックについて説明します。
CachéまたはEnsembleへの接続にStudio、ODBC、またはターミナルを使用している場合、その接続をどのように保護すれば良いのか疑問に思うかもしれません。 選択肢の一つに、TLS(別名SSL)を接続に追加することが挙げられます。 Cachéクライアントアプリケーション(TELNET、ODBC、Studio)にはすべて、TLSを接続に追加する機能があります。 あとは単純にその構成を行うだけです。
2015.1以降はこれらのクライアントを簡単に設定できるようになりました。 ここでは、その新しい方法について説明します。 既に古い方法を使用している場合も引き続き機能しますが、新しい方法への切り替えを検討することをお勧めします。
これらのクライアントアプリケーションは、サーバーがインストールされていないマシンにインストールできます。 ただし、CACHESYSデータベースやcpfファイルなど、設定を保存する通常の場所へのアクセスに依存することはできません。 その代わり、受け付ける証明書やプロトコルの設定はテキストファイルに保存されます。 このファイルの設定の多くは、管理ポータルのSSL/TLS構成の設定に似ています。
独自のファイルを作成する必要があります。 クライアントインストーラーは設定ファイルを作成しません。
誰もがテスト環境を持っています。
本番環境とは完全に独立した実行環境を持てるほど幸運な人もいます。
-- 作者不明
この連載記事では、InterSystemsの技術とGitLabを使用したソフトウェア開発に向けて実現可能な複数の手法を紹介し、議論したいと思います。 次のようなトピックについて説明します。
この最初のパートでは、最新のソフトウェア開発の基礎であるGitバージョン管理システムとさまざまなGitフローを扱います。
これから説明する主なトピックでは、後の概念をより良く理解できるようにするため、ソフトウェア開発全般とGitlabがその取り込みにどのように役立っているのか、Git、あるいはもっと厳密に言えば重要なGit設計の基礎となる複数の高度な概念を取り上げます。
そして、Gitは以下のようなアイデア(他にもたくさんありますが、これらが最も重要なアイデアです)に基づいたバージョン管理システムです。
この連載記事では、InterSystemsの技術とGitLabを使用したソフトウェア開発に向けて実現可能な複数の手法を紹介し、議論したいと思います。 次のようなトピックについて説明します。
第1回の記事では、Gitの基本、Gitの概念を高度に理解することが現代のソフトウェア開発にとって重要である理由、Gitを使用してソフトウェアを開発する方法について説明しています。
第2回の記事では、アイデアからユーザーフィードバックまでの完全なソフトウェアライフサイクルプロセスであるGitLabワークフローについて説明しています。
第3回の記事では、GitLabのインストールと構成ならびに利用環境のGitLabへの接続について説明しています。
第4回の記事では、CDの構成を作成しています。
第5回の記事では、コンテナとその使用方法(および使用する理由)について説明しています。
この連載記事では、InterSystemsの技術とGitLabを使用したソフトウェア開発に向けて実現可能な複数の手法を紹介し、議論したいと思います。 次のようなトピックについて説明します。
第1回の記事では、Gitの基本、Gitの概念を高度に理解することが現代のソフトウェア開発にとって重要である理由、Gitを使用してソフトウェアを開発する方法について説明しました。
第2回の記事では、アイデアからユーザーフィードバックまでの完全なソフトウェアライフサイクルプロセスであるGitLabワークフローについて説明しました。
第3回の記事では、GitLabのインストールと構成ならびに利用環境のGitLabへの接続について説明しました。
この記事では、最終的にCDの構成を作成します。
まず、いくつかの環境とそれに対応するブランチが必要です。
この連載記事では、InterSystemsの技術とGitLabを使用したソフトウェア開発に向けて実現可能な複数の手法を紹介し、議論したいと思います。 次のようなトピックについて説明します。
第1回の記事では、Gitの基本、Gitの概念を高度に理解することが現代のソフトウェア開発にとって重要である理由、Gitを使用してソフトウェアを開発する方法について説明しています。
第2回の記事では、アイデアからユーザーフィードバックまでの完全なソフトウェアライフサイクルプロセスであるGitLabワークフローについて説明しています。
この記事では以下について説明します。
GitLabをオンプレミス環境にインストールします。 GitLabのインストール方法は多彩で、ソースやパッケージからインストールしたり、コンテナーにインストールしたりできます。 ここではすべての手順を実際に説明するつもりはありませんが、そのためのガイドを紹介します。 ただし、それでもいくつか注意すべき点があります。
この連載記事では、InterSystemsの技術とGitLabを使用したソフトウェア開発に向けて実現可能な複数の手法を紹介し、議論したいと思います。 次のようなトピックについて説明します。
第1回の記事では、Gitの基本、Gitの概念を高度に理解することが現代のソフトウェア開発にとって重要である理由、Gitを使用してソフトウェアを開発する方法について説明していますました。
第2回の記事では、アイデアからユーザーフィードバックまでの完全なソフトウェアライフサイクルプロセスであるGitLabワークフローについて説明しています。
第3回の記事では、GitLabのインストールと構成ならびに利用環境のGitLabへの接続について説明しています。
第4回の記事では、CDの構成を作成しています。
この記事では、コンテナとその使用方法(および使用する理由)について説明します。
この記事は、Dockerとコンテナの概念を熟知していることを前提としています。
この連載記事では、InterSystemsの技術とGitLabを使用したソフトウェア開発に向けて実現可能な複数の手法を紹介し、議論したいと思います。 次のようなトピックについて説明します。
前の記事では、Gitの基本、Gitの概念を高度に理解することが現代のソフトウェア開発にとって重要である理由、Gitを使用してソフトウェアを開発する方法について説明しました。 なお、前の記事ではソフトウェア開発の実装部分を中心に取り扱っていましたが、このパートでは以下を取り扱います。
Cachéミラーリングは、CachéおよびEnsembleベースのアプリケーションに適した信頼性が高く、安価で実装しやすい高可用性および災害復旧ソリューションです。 ミラーリングは幅広い計画停止シナリオや計画外停止シナリオで自動フェイルオーバーを提供するもので、通常はアプリケーションの回復時間を数秒に抑制します。 論理的にデータが複製されるため、単一障害点およびデータ破損の原因となるストレージが排除されます。 ほとんど、またはダウンタイムなしでアップグレードを実行できます。
ただし、Cachéミラーの展開にはかなり大がかりな計画が必要であり、さまざまな手順が要求されます。 また、他の重要なインフラストラクチャコンポーネントと同様に、運用中のミラーには継続的な監視とメンテナンスが必要とされます。
この記事はよくある質問のリスト、あるいはミラーリングの理解と評価、ミラーの計画、ミラーの設定、ミラーの管理という簡単な一連のガイドとして利用することができます。 それぞれの回答には、各トピックの詳細なディスカッションへのリンクと各タスクの段階的手順へのリンクが含まれています。
ミラーを導入する計画を始める準備ができたら、まずはCaché高可用性ガイドの「ミラーリング」の章のミラーリングのアーキテクチャと計画セクションから必ず読み始めるようにしてください。
ここは、Intersystems IRIS,Caché,Ensemble,HealthShare,Intersystems Business Inteligence, NLPといったインターシステムズ製品や技術について情報を読んだり、議論することができるサイトです。
本サイトには主にアナウンス、記事、質問とその回答、ビデオがあります。
インターシステムズの製品や技術を使った経験やベストプラクティスを記事にしており、インターシステムズ社員とコミュニティメンバーの両方が記事を投稿できるようになっています。また、リリースノートや新機能の説明、体験談、技術的な事例も掲載されています。
もちろん、全世界のインターシステムズ製品の経験豊富なエンジニアに質問し、その回答を得られる場所でもあります。
本サイトにメンバー登録することで、インターシステムズ製品のソリューションを構築、デプロイ、保守するのに役立つソリューションやツール、技術、アプローチに関する記事を投稿、コメントしたり、質問、回答することができます。アカウント作成方法はこちらです。ただし弊社サポートセンター(WRC)のアカウントをお持ちの方はそのログイン名、パスワードでログインできますのでアカウント作成は不要です。

