![]()
InterSystems CachéはマルチモデルのDBMSおよびアプリケーションサーバーです
作成者:Daniel Kutac(InterSystems セールスエンジニア)
パート 3. 付録
この連載の前のパートでは、InterSystems IRIS を OAUTH クライアントおよび認可/認証サーバー(OpenID Connect を使用)として機能するように構成する方法について学びました。 この連載の最後のパートでは、InterSystems IRIS OAuth 2.0 フレームワークを実装するクラスについて説明します。 また、一部の API クラスのメソッドの使用例についても説明します。
OAuth 2.0 を実装する API クラスは、目的に応じて 3 種類のグループに分けることができます。 すべてのクラスは %SYS ネームスペースで実装されています。 これらの一部は(% package 経由で)公開されていますが、一部は非公開になっており、開発者が直接呼び出すことはできません。
作成者:Daniel Kutac(InterSystems セールスエンジニア) 注意: 使用されている URL に戸惑っている方のために。*元の連載記事では、dk-gs2016 と呼ばれるマシンの画面を使用していました。 新しいスクリーンショットは別のマシンから取得されています。 *WIN-U9J96QBJSAG という URL は dk-gs2016 であると見なしても構いません。
この短い連載の前のパートでは、OAUTH[1] クライアントとして機能する単純な使用事例について学びました。 今回は私たちの経験をまったく新しいレベルに引き上げましょう。 InterSystems IRIS がすべての OAUTH の役割を果たす、より複雑な環境を構築します。 クライアントの作成方法はすでに分かっていますので、認可サーバーだけでなく、OpenID Connect[2] プロバイダーにも注意を向けましょう。 前のパートと同様に、環境を準備する必要があります。 今回はより多くの変動要素があるため、より注意を要します。
具体例を見る前に、OpenID Connect について少し説明する必要があります。
この記事では、スナップショットを使用したソリューションとの統合の例を使って、_外部バックアップ_による Caché のバックアップ方法を紹介します。 このところ私が目にするソリューションの大半は、Linux の VMware にデプロイされているため、この記事の大半では、例として、ソリューションが VMware スナップショットテクノロジーをどのように統合しているかを説明しています。
Caché をインストールすると、Caché データベースを中断せずにバックアップできる Caché オンラインバックアップが含まれています。 しかし、システムがスケールアップするにつれ、より効率的なバックアップソリューションを検討する必要があります。 Caché データベースを含み、システムをバックアップするには、スナップショットテクノロジーに統合された_外部バックアップ_をお勧めします。
詳しい内容は外部バックアップのオンラインドキュメンテーションに説明されていますが、 主な考慮事項は次のとおりです。
「スナップショットの整合性を確保するために、スナップショットが作成される間、Caché はデータベースへの書き込みをfreezeする方法を提供しています。
最初の記事では、RESTForms(永続クラス用のREST API)について説明をしました。 基本的な機能についてはすでに説明しましたが、ここではクエリ機能を中心とする高度な機能について説明します。
クエリを使用すると、任意の条件に基づいてデータの一部を取得できます。 RESTFormsには、2種類のクエリがあります。
一度定義すると、すべてのクラスか一部のクラスですぐに使用できます。 基本クエリはシステムによって定義されているものもありますが、開発者が追加することもできます。これらのクエリはすべて、SELECTのフィールドリストのみを定義します。 その他すべて(絞り込み、ページネーションなど)はRESTFormsによって行われます。 form/objects/:class/:query を呼び出すと、単純なクエリを実行できます。 2番目の :query パラメーターはクエリ名(クエリの SELECT と FROM の間の内容)を定義します。 デフォルトのクエリタイプは次のとおりです。
この記事では、RESTFormsプロジェクト(モダンなWebアプリケーション用の汎用REST APIバックエンド)を紹介します。
プロジェクトの背後にあるアイデアは単純です。私はいくつかのREST APIを書いた後、REST APIが一般的に次の2つの部分で構成されていることに気付きました。
また、独自のカスタムビジネスロジックを書く必要はありますが、RESTFormsには永続クラスの操作に関連するすべての機能を提供しています。
使用例
IRIS で REST サーバを作成する際に準備する REST ディスパッチクラスを API ファーストの手順で作成する方法を解説します。
(OpenAPI 2.0に基づいて作成したアプリケーション定義を使用してディスパッチクラスを作成する手順を解説します)
このビデオには、以下の関連ビデオがあります。
もくじ
最初~ 復習ビデオ/関連ビデオについて など
2:36~ 作成するディスパッチクラスの内容
4:15~ RESTディスパッチクラス:APIファーストで作成する方法(手順説明)
5:55~ アプリケーションの仕様を定義する (例)
6:19~ IRISにアプリケーション仕様を登録する(説明)など
7:40~ POST要求の実行 (例)
8:24~ 実演
↓実演で使用したURL↓
http://localhost:52773/api/mgmnt/v2/user/crud2
10:32~ (POST要求の)実行結果
11:50~ ベースURLの設定(管理ポータルでの設定)+ 実演
13:23~ curd2.
IRIS で作成する REST サーバの仕組みを解説します。
このビデオには、以下の関連ビデオがあります。
もくじ
0:55~ 今回の説明内容解説と関連ビデオについて
3:00~ RESTとは?
3:52~ 動作の仕組み
6:23~ RESTディスパッチクラスとは
8:04~ RESTディスパッチクラスの実装方法
8:34~ RESTディスパッチクラス:全て手動で作成する方法 概要
9:30~ RESTディスパッチクラス:APIファーストで作成する方法 概要
11:12~ 共通:ベースURLの設定(管理ポータルでの設定)
11:37~最後まで 確認できたこと
※YouTubeでご覧いただくと、もくじの秒数にジャンプできます。
この記事ではVMware ESXi 5.5以降の環境にCaché 2015以降を導入する場合の構成、システムのサイジング、およびキャパシティ計画のガイドラインを示します。
ここでは、皆さんがVMware vSphere仮想化プラットフォームについてすでに理解していることを前提としています。 このガイドの推奨事項は特定のハードウェアやサイト固有の実装に特化したものではなく、vSphereの導入を計画して構成するための完全なガイドとして意図されたものでもありません。これは、皆さんが選択可能なベストプラクティス構成をチェックリストにしたものです。 これらの推奨事項は、皆さんの熟練したVMware実装チームが特定のサイトのために評価することを想定しています。
InterSystems データプラットフォームとパフォーマンスに関する他の連載記事のリストはこちらにあります。
注意: 本番データベースインスタンス用のVMメモリを予約し、Cachéに確実にメモリを使用させてデータベースのパフォーマンスに悪影響を与えるスワップやバルーニングの発生を防ぐ必要があることを強調するため、この記事を2017年1月3日に更新しています。 詳細については、以下のメモリセクションを参照してください。
** 2018年2月12日改訂
この記事はInterSystems IRISに関するものですが、Caché、Ensemble、およびHealthShareのディストリビューションにも適用されます。
メモリはページ単位で管理されます。 Linuxシステムでは、デフォルトのページサイズは4KBです。 Red Hat Enterprise Linux 6、SUSE Linux Enterprise Server 11、およびOracle Linux 6では、HugePageと呼ばれるシステム構成に応じて、ページサイズを2MBまたは1GBに増やす方法が導入されました。
第一に、HugePagesは起動時に割り当てる必要があり、適切に管理や計算が行われていない場合はリソースが浪費される可能性があります。 結果的に、さまざまなLinuxディストリビューションでTransparent HugePagesがデフォルトで有効になっているカーネル2.6.38が導入されました。 これは、HugePagesの作成、管理、使用を自動化することを意図したものでした。 旧バージョンのカーネルもこの機能を備えている可能性がありますが、[always] に指定されておらず、 [madvise] に設定されている可能性があります。
この記事では、InterSystems Technologiesに基づく、堅牢なパフォーマンスと可用性の高いアプリケーションを提供するリファレンスアーキテクチャをサンプルとして提供します。Caché、Ensemble、HealthShare、TrakCare、およびDeepSee、iKnow、Zen、Zen Mojoといった関連する組み込みテクノロジーに適用可能です。
Azureには、リソースを作成して操作するための、Azure ClassicとAzure Resource Managerという2つのデプロイメントモデルがあります。 この記事で説明する情報は、Azure Resource Managerモデル(ARM)に基づきます。
Microsoft Azureクラウドプラットフォームは、InterSystems製品すべてを完全にサポートできるクラウドサービスとして、IaaS(サービスとしてのインフラストラクチャ)向けの機能の豊富な環境を提供しています。 あらゆるプラットフォームやデプロイメントモデルと同様に、パフォーマンス、可用性、運用、管理手順などの環境に関わるすべての側面が正しく機能するように注意を払う必要があります。 この記事では、こういった各分野の詳細について説明しています。
InterSystemsのテクノロジースタックを使用して独自のアプリを開発し、顧客側で複数のデプロイを実行したいとします。 開発プロセスでは、クラスをインポートするだけでなく、必要に応じて環境を微調整する必要があるため、アプリケーションの詳細なインストールガイドを作成しました。この特定のタスクに対処するために、インターシステムズは、%Installer(Caché/Ensemble)という特別なツールを作成しました 。 続きを読んでその使用方法を学んでください。
%Installer
このツールを使用すると、インストール手順ではなく、目的のCaché構成を記述するインストールマニフェストを定義できます。作成したい Caché 構成を記述します。必要な内容を記述するだけで、環境を変更するために必要なコードが自動的に生成されます。
したがって、マニフェストのみを配布する必要がありますが、インストール・コードはすべてコンパイル時に特定の Caché サーバ用に生成されます。
マニフェストを定義するには、ターゲット構成の詳細な説明を含む新しいXDataブロックを作成してから、このXDataブロックのCaché ObjectScriptコードを生成するメソッドを実装します(このコードは常に同じです)。
この記事と後続の2つの連載記事は、InterSystems製品ベースのアプリケーションでOAuth 2.0フレームワーク(簡略化のためにOAUTHとも呼ばれます)を使用する必要のある開発者またはシステム管理者向けのユーザーガイドを対象としています。
作成者:Daniel Kutac(InterSystemsシニアセールスエンジニア)
パート1.
ここ数年の間、ハイパーコンバージドインフラストラクチャ(HCI)ソリューションが勢いを増しており、導入件数が急速に増加しています。 IT部門の意思決定者は、VMware上ですでに仮想化されているアプリケーションなどに対し、新規導入やハードウェアの更新を検討する際にHCIを考慮に入れています。 HCIを選択する理由は、単一ベンダーと取引できること、すべてのハードウェアおよびソフトウェアコンポーネント間の相互運用性が検証済みであること、IO面を中心とした高いパフォーマンス、単純にホストを追加するだけで拡張できること、導入や管理の手順が単純であることが挙げられます。
この記事はHCIソリューションの一般的な機能を取り上げ、HCIを初めて使用する読者に紹介するために執筆しました。 その後はデータベースアプリケーションの具体的な例を使用し、InterSystems データプラットフォーム上に構築されたアプリケーションを配置する際の、キャパシティプランニングとパフォーマンスに関する構成の選択肢と推奨事項を確認します。 HCIソリューションはパフォーマンスを向上させるためにフラッシュストレージを利用しているため、選択されたフラッシュストレージオプションの特性と使用例に関するセクションも含めています。
VMware vSphereで実行する大規模な本番データベースのCPUキャパシティプランニングについて、お客様やベンダー、または社内のチームから説明するように頼まれることが良くあります。
要約すると、大規模な本番データベースのCPUのサイジングには、いくつかの単純なベストプラクティスがあります。
このことから、通常いくつかの一般的な疑問が生まれます。
こういった疑問につては、下の例を使って答えることにします。 ただし、ベストプラクティスは決定事項ではありません。 ときには妥協することも必要です。 たとえば、大規模なデータベースVMはNUMAノードに収まらない可能性が高く、それはそれでも良いのです。
前回の記事では、pButtonsを使って履歴パフォーマンスメトリックを収集する方法を説明しました。 すべてのデータプラットフォームインスタンス(Ensemble、Cachéなど)にはpButtonsがインストールされていることがわかっているため、私はpButtonsを使用する傾向にありますが、 Cachéパフォーマンスメトリックをリアルタイムで収集、処理、表示する方法はほかにもあり、単純な監視や、それよりもさらに重要な、より高度な運用分析とキャパシティプランニングに使用することができます。 データ収集の最も一般的な方法の1つは、SNMP(簡易ネットワーク管理プロトコル)を使用することです。
SNMPは、Cachéが管理・監視情報をさまざまな管理ツールに提供するための標準的な方法です。 Cachéのオンラインドキュメンテーションには、CachéとSNMP間のインターフェースに関する詳細が説明されています。 SNMPはCachéと「単純に連携」するはずですが、構成にはいくつかの技と罠があります。 私自身、はじめに何度も過ちを繰り返し、InterSystemsの同僚から助けを得ながらCachéをオペレーティングシステムのSNMPマスターエージェントにやっと接続できた経験から、皆さんが同じような困難を避けられるようにこの記事を書くことにしました。
この記事では、InterSystemsデータプラットフォームで実行するデータベースアプリケーションにおけるグローバルバッファ、ルーチンバッファ、gmheap、locksizeなどの共有メモリ要件のサイジングアプローチを説明し、サーバー構成時およびCachéアプリケーションの仮想化時に検討すべきパフォーマンスのヒントをいくつか紹介します。 これまでと同じように、Cachéについて話すときは、すべてのデータプラットフォーム(Ensemble、HealthShare、iKnow、Caché)を指しています。
最初にCachéを使い始めたころ、ほとんどの顧客オペレーティングシステムは32ビットで、Cachéアプリケーションのメモリは少なく、高価なものでした。 一般的に展開されていたIntelサーバーにはコアが数個しかなく、スケールアップするには、大型のサーバーを使用するか、ECPを使って水平方向にスケールアウトするしかありませんでした。 今では、基本製品グレードのサーバーでさえも、マルチプロセッサ、数10個のコア、TBにまで増設できる可能性も備わった128GBまたは256GBの最低メモリが搭載されています。
今週は、ハードウェアの主な”食品群” (^_^) の1つであるCPUに注目します。お客様から、次のようなシナリオについてのアドバイスを求められました。お客様の本番サーバーはサポート終了に近づいており、ハードウェアを交換する時期が来ています。 また、仮想化によってサーバーを一元的に管理できるようにし、ベアメタルか仮想化によりキャパシティを適正化したいとも考えています。 今日はCPUに焦点を当てますが、後日の記事では、メモリやIOといったほかの主要食品群を適正化するアプローチについて説明したいと思います。
では、質問を整理しましょう。
2017年6月追記:
VMware CPUに関する考慮事項と計画の詳細、および一般的な質問と問題の詳細については、「大規模データベースの仮想化 - VMware CPUのキャパシティ計画」の記事も参照してください。
前回の投稿では、pButtonsを使用してパフォーマンスメトリックを24時間収集する処理をスケジュールしました。 この投稿では、収集対象の主なメトリックのいくつかと、それらの土台となるシステムハードウェアがどのように関連しているかを見ていきます。 また、Caché(または任意のInterSystemsデータプラットフォーム)メトリックとシステムメトリックの関係についても調べます。 さらに、これらのメトリックを使用してシステムの毎日の健全性を把握し、パフォーマンスの問題を診断する方法もご紹介します。
2016年10月に編集...
pButtonsデータを .csv ファイルに抽出するスクリプトの例はこちらで確認できます。
2018年3月に編集...
画像が消えていましたが、元に戻しました。
この連載を読み進めていくと、パフォーマンスに影響を与えるサーバーコンポーネントを次のように分類できることが分かってきます。
- CPU
- メモリ
- ストレージIO
- ネットワークIO
アプリケーションがデプロイされ、すべてが問題なく動作しています。 素晴らしいですね! しかし、その後突然電話が鳴り止まなくなりました。アプリケーションが時々「遅くなる」というユーザーからの苦情の電話です。 これは一体どういうことなのでしょうか? なぜ時々遅くなるのでしょうか? このような速度低下を検出し、解決するにはどのようなツールと統計情報に注目すべきなのでしょうか? お使いのシステムのインフラはユーザーの負荷に対応できていますか? 本番環境を調べる前に、どのようなインフラ設計上の問題を問うべきなのでしょうか? 新しいハードウェアのキャパシティプランニングを、必要以上の設備投資を行うことなく自信を持って行うにはどうすればよいのでしょうか? どうすれば電話がかかってこなくなるのでしょうか? そもそも電話がかかってこないようにするには、どうすればよかったのでしょうか?
これは、システムパフォーマンスの監視、確認、トラブルシューティングに使用できるツールとメトリック、およびパフォーマンスに影響を与えるシステムとアーキテクチャの設計上の考慮事項について説明する連載の最初の投稿です。
「データプラットフォームのキャパシティプランニングとパフォーマンス」シリーズの全記事をリストしました。 その下には私の一般的なその他の記事も記載しています。 このシリーズに新しい記事が追加されるたびに、このリストを更新する予定です。
通常、各記事はその前の記事の続きとして書かれていますが、ほかの記事を飛び越して気になるものを読むこともできます。
コミュニティに掲載中のアーキテクチャ全般の記事を集めたリストです。
 前のパート(1、2)では、ツリーとしてのグローバルを話題に取り上げました。 この記事では、それらを疎な配列と見なします。
前のパート(1、2)では、ツリーとしてのグローバルを話題に取り上げました。 この記事では、それらを疎な配列と見なします。
疎な配列は、ほとんどの値が同一であると想定される配列の種類です。
疎な配列は実際には非常に大きいため、同一の要素でメモリを占有することには意味がありません。 したがって、疎な配列を整理し、重複した値の格納にメモリが浪費されないようにすることには意味があります。
疎な配列は、J、MATLABなど一部のプログラミング言語では言語の一部になっています。 他の言語では、疎な配列を使用できるようにする特別なライブラリが存在します。 C++の場合は、Eigenなどがあります。
次の理由により、グローバルは疎な配列を実装するのに適した候補であると言えます。
Set ^a(1, 2, 3)=5
Write ^a(1, 2, 3)  最初の記事については、パート1を参照してください。
最初の記事については、パート1を参照してください。
順序付きツリーなどの構造には、さまざまな特殊ケースがあります。 グローバルを使用する上で実用的な価値があるものを見てみましょう。
 グローバルは配列のようにも、通常の変数のようにも使用できます。 例えば、カウンターを作成する場合を考えてみましょう。
グローバルは配列のようにも、通常の変数のようにも使用できます。 例えば、カウンターを作成する場合を考えてみましょう。
Set ^counter = 0 ; カウンターの設定
Set id=$Increment(^counter) ; アトミックなインクリメント操作
また、グローバルには値に加えて枝を持たせることができます。 一方が他方を除外することはありません。
実際、これは典型的なキー・バリューベースのデータ構造です。 また、値の代わりに値のタプルを保存すると、主キーを持つ通常のテーブルが得られます。
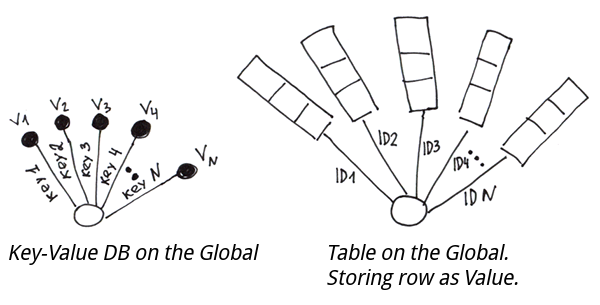
グローバルに基づくテーブルを実装するには、カラムの値から文字列を作成し、主キー別にそれをグローバルに保存する必要があります。 読み取りの時に文字列をカラムに分割できるようにするため、以下のいずれかを使用することができます。
Cachéの優れた可用性とスケーリング機能の1つは、エンタープライズキャッシュプロトコル(ECP)です。 アプリケーション開発中に考慮することにより、ECPを使用した分散処理は、Cachéアプリケーションのスケールアウトアーキテクチャを可能にします。 アプリケーション処理は、アプリケーションを変更することなく、単一のアプリケーションサーバーから最大255台といった非常に高いレートにまで、アプリケーションサーバー処理能力を拡張できます。
ECPは、私が関与していたTrakCareのデプロイメントで長年広く使用されていました。 10年前は、主要ベンダーの1つが提供する「大きな」x86サーバーは、合計で8つのコアしか備えていなかったかもしれません。 大規模なデプロイメントの場合、ECPは、高価な大型コンピュータを使う単一のエンタープライズサーバーではなく、コモディティサーバーでの処理をスケールアウトする方法でした。 コア数の多いエンタープライズサーバーでさえ制限があったため、ECPはそれらのサーバーへのデプロイメントのスケーリングにも使用されました。
現在、ほとんどの新しいTrakCareのデプロイメントや主流ハードウェアへのアップグレードは、ECPでのスケーリングを必要としません。 現行の2ソケットx86プロダクションサーバーは、数十のコアと巨大なメモリを持つことができます。
私や他のテクノロジアーキテクトは、Caché IOの要件と、Cachéアプリケーションがストレージシステムを使用する方法を顧客とベンダーに説明しなければならないことがよくあります。以下の表は、一般的なCaché IOプロファイルと、トランザクションデータベースアプリケーションの要件を顧客やベンダーに説明するときに役立ちます。 オリジナルの表は、マーク・ボリンスキーが作成しました。
今後の投稿ではストレージIOについて詳しく説明する予定なので、今後の記事の参考資料として、今回これらの表も公開します。
予測可能なディスクIOパフォーマンスを提供し、高可用性機能をサポートし、アプリケーションにストレージの冗長性、スケーラビリティ、および信頼性を提供するには、ストレージアレイなど、ストレージを適切に設定することが不可欠です。
選択したストレージアレイテクノロジーによっては、物理層のディスクストレージがプールまたはディスクグループに分離される場合があります。 可能であれば、可用性とパフォーマンスのために、予想されるIOプロファイルに基づいてストレージをパーティション化する必要があります。 たとえば、データとジャーナル(トランザクションログ)は別々の物理ディスクグループに存在する必要があります。
 データを格納するための魔法の剣であるグローバルは、かなり前から存在しています。しかしながら、これを効率的に使いこなせる人や、この素晴らしい道具の全貌を知る人はそう多くありません。 グローバルを本当に効果を発揮できるタスクに使用すると、パフォーマンスの向上やソリューション全体の劇的な単純化といった素晴らしい結果を得ることができます(1、2)。
データを格納するための魔法の剣であるグローバルは、かなり前から存在しています。しかしながら、これを効率的に使いこなせる人や、この素晴らしい道具の全貌を知る人はそう多くありません。 グローバルを本当に効果を発揮できるタスクに使用すると、パフォーマンスの向上やソリューション全体の劇的な単純化といった素晴らしい結果を得ることができます(1、2)。
グローバルは、SQLテーブルとはまったく異なる特別なデータの格納・処理方法を提供します。 グローバルは1966年にM(UMPS)プログラミング言語で初めて導入され、医療データベースで使用されていました。 また、現在も同じように使用されていますが、金融取引など信頼性と高いパフォーマンスが最優先事項である他のいくつかの業界でも採用されています。
M(UMPS)は後にCaché ObjectScript(COS)に進化しました。 COSはInterSystemsによってMの上位互換として開発されました。 元の言語は現在も開発者コミュニティに受け入れられており、いくつかの実装で生き残っています。 ウェブ上では、MUMPS Googleグループ、Mumpsユーザーグループ、ISO規格といった複数の活動が見られます。
最新のグローバルベースのDBMSは、トランザクション、ジャーナリング、レプリケーション、パーティショニングをサポートしています。
CachéまたはEnsembleへの接続にStudio、ODBC、またはターミナルを使用している場合、その接続をどのように保護すれば良いのか疑問に思うかもしれません。 選択肢の一つに、TLS(別名SSL)を接続に追加することが挙げられます。 Cachéクライアントアプリケーション(TELNET、ODBC、Studio)にはすべて、TLSを接続に追加する機能があります。 あとは単純にその構成を行うだけです。
2015.1以降はこれらのクライアントを簡単に設定できるようになりました。 ここでは、その新しい方法について説明します。 既に古い方法を使用している場合も引き続き機能しますが、新しい方法への切り替えを検討することをお勧めします。
これらのクライアントアプリケーションは、サーバーがインストールされていないマシンにインストールできます。 ただし、CACHESYSデータベースやcpfファイルなど、設定を保存する通常の場所へのアクセスに依存することはできません。 その代わり、受け付ける証明書やプロトコルの設定はテキストファイルに保存されます。 このファイルの設定の多くは、管理ポータルのSSL/TLS構成の設定に似ています。
独自のファイルを作成する必要があります。 クライアントインストーラーは設定ファイルを作成しません。
Cachéミラーリングは、CachéおよびEnsembleベースのアプリケーションに適した信頼性が高く、安価で実装しやすい高可用性および災害復旧ソリューションです。 ミラーリングは幅広い計画停止シナリオや計画外停止シナリオで自動フェイルオーバーを提供するもので、通常はアプリケーションの回復時間を数秒に抑制します。 論理的にデータが複製されるため、単一障害点およびデータ破損の原因となるストレージが排除されます。 ほとんど、またはダウンタイムなしでアップグレードを実行できます。
ただし、Cachéミラーの展開にはかなり大がかりな計画が必要であり、さまざまな手順が要求されます。 また、他の重要なインフラストラクチャコンポーネントと同様に、運用中のミラーには継続的な監視とメンテナンスが必要とされます。
この記事はよくある質問のリスト、あるいはミラーリングの理解と評価、ミラーの計画、ミラーの設定、ミラーの管理という簡単な一連のガイドとして利用することができます。 それぞれの回答には、各トピックの詳細なディスカッションへのリンクと各タスクの段階的手順へのリンクが含まれています。
ミラーを導入する計画を始める準備ができたら、まずはCaché高可用性ガイドの「ミラーリング」の章のミラーリングのアーキテクチャと計画セクションから必ず読み始めるようにしてください。