 返信数
返信数クラス、テーブル、グローバルとその仕組み
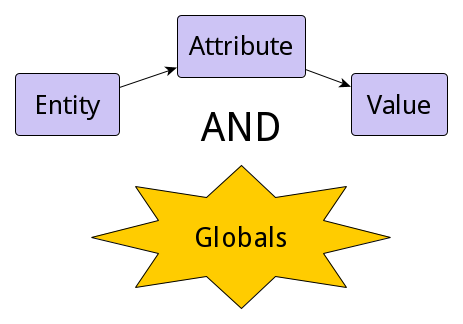
InterSystems IRIS を技術的知識を持つ人々に説明する際、私はいつもコアとしてマルチモデル DBMSであることから始めます。
個人的には、それが(DBMSとして)メインの長所であると考えています。 また、データが格納されるのは一度だけです。 ユーザーは単に使用するアクセス API を選択するだけです。
- データのサマリをソートしたいですか?SQL を使用してください!
- 1 つのレコードを手広く操作したいですか?オブジェクトを使用してください!
- あなたが知っているキーに対して、1 つの値にアクセスしたりセットしたいですか? グローバルを使用してください!
これは短く簡潔なメッセージで、一見すると素晴らしく聞こえます。しかし、実際には intersystems IRIS を使い始めるたユーザーには クラス、テーブル、グローバルはそれぞれどのように関連しているのだろうか? 互いにどのような存在なのだろうか? データは実際にどのように格納されているのだろうか?といった疑問が生じます。
この記事では、これらの疑問に答えながら実際の動きを説明するつもりです。
.png)
 Open Exchange app
Open Exchange app.png)
 「クエリ印刷」画面で「ファイルにエクスポート」をチェックすると「ファイル形式」の欄が表示されます。
「クエリ印刷」画面で「ファイルにエクスポート」をチェックすると「ファイル形式」の欄が表示されます。