RDBにおけるEntity-Attribute-Value(EAV)モデル。 グローバル変数はテーブルでエミュレートする必要がありますか? パート1.
はじめに
この連載の最初の記事では、リレーショナルデータベースのEAV(Entity–Attribute–Value)モデルを見て、それがどのように使用されて、何に役立つのかを確認しましょう。 その上で、EAVモデルの概念とグローバル変数と比較します。
原則として検索する必要のある、フィールド数、または階層的にネストされたフィールドの数が不明なオブジェクトがある場合があります。
たとえば、多様な商品群を扱うオンラインストアを考えてみましょう。 商品群ごとに固有の一意のプロパティセットがあり、共通のプロパティもあります。 たとえば、SSDとHDDドライブには共通の「capacity」プロパティがありますが、SSDには「Endurance, TBW」、HDDには「average head positioning time」という一意のプロパティもあります。
場合によっては、同じ商品でも別のメーカーが製造した場合には、それぞれに一意のプロパティが存在します。
では、50種の商品群を販売するオンラインストアがあるとしましょう。 各商品群には、数値またはテキストの固有のプロパティが5つあります。
実際に使用するのは5個だけであっても、各商品に250個のプロパティがあるテーブルを作成するのであれば、ディスク容量の要件が大幅に増える(50倍!)だけでなく、有用性のない空のプロパティによってキャッシュが詰まってしまうため、データベースの速度特性が大幅に減少してしまいます。
さらに、それだけではありません。 固有のプロパティを持つ新しい商品群を追加するたびに、ALTER TABLEコマンドを使用してテーブルの構造を変更する必要があります。 大規模なテーブルであれば、この操作には数時間、さらには数日間かかる可能性もあり、ビジネスでは許容しかねます。
これを注意深く読んでいる方は「商品群ごとに異なるテーブルを用意しては?」と言うでしょう。 もちろんその通りではありますが、このアプローチを使用すると、大型ストアの場合には、数万個ものテーブルでデータベースを作成することになり、管理が困難になります。 さらに、サポートする必要のあるコードがますます複雑化してしまいます。
一方、新しい商品群を追加するときに、データベースの構造を変更する必要はありません。 新しい商品群向けの新しいテーブルを追加すればよいだけだからです。
いずれにせよユーザーは、ストア内の商品を簡単に検索できること、現在のプロパティを示す便利な表形式で商品を表示できること、そして商品を比較できることが必要です。
ご想像のとおり、商品群の5個のプロパティのみが必要であるにもかかわらず、商品テーブルにはさまざまなプロパティを示す250個のフィールドがあれば不便であるのと同様に、250個のフィールドを使った検索フォームは、ユーザーにとって非常に不便です。 これは商品の比較にも当てはまります。
マーケティングデータベースも別の有用な例と言えるでしょう。 それに格納されている人ごとに、絶えず追加、変更、または削除される可能性のある多数のプロパティが必要です(多くの場合はネストされています)。 過去にある商品を特定の数量で購入した、特定の商品群を購入した、何かに参加した、どこかで勤務した、親戚がいる、この都市に住む、特定の社会階級に属する、などのプロパティがあります。 フィールド数は数千個にもなり、変化も絶えないでしょう。 マーケターは常に、さまざまな顧客グループを区別して魅力的な特別オファーを提供する方法を考えています。
これらの問題を解決すると同時に、明確で確定的なデータベース構造を得るために、Entity-Attribute-Valueアプローチが編み出されました。
EAVアプローチ
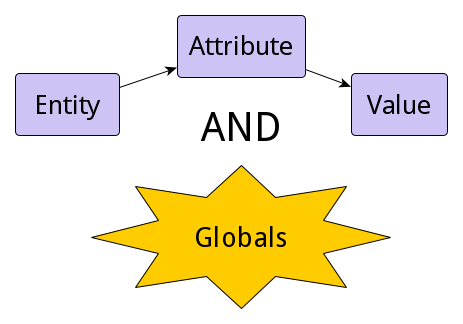
EAVアプローチの本質は、エンティティ、属性、および属性値を個別に保存することにあります。 一般的に、EAVアプローチを説明するために、Entity、Attribute、およびValueという3つのテーブルのみが使用されます。

保存するデモデータの構造。

テーブルを使用したEAVアプローチの実装
5つ(最後の2つのテーブルを1つに統合することにした場合は4つ)のテーブルを使用したより複雑な例を考察してみましょう。

最初のテーブルはСatalogです。
CREATE TABLE Catalog (
id INT,
name VARCHAR (128),
parent INT
);
このテーブルは実際、EAVアプローチのエンティティに対応しています。 階層的な商品カタログのセクションを保存します。
2つ目のテーブルは ****Fieldです。
CREATE TABLE Field (
id INT,
name VARCHAR (128),
typeOf INT,
searchable INT,
catalog_id INT,
table_view INT,
sort INT
);
このテーブルでは、属性の名前、型、および属性が検索可能であるかどうかを指定します。 また、プロパティが属する商品を保持しているカタログのセクションも指定します。 catalog_id以下のカタログセクションにあるすべての商品には、このテーブルに保存されているさまざまなプロパティがある場合があります。
3つ目のテーブルはGoodです。 商品を、商品の価格、商品の合計数量、商品の予約数量、および商品名とともに保存するように設計されています。 厳密にはこのテーブルは必要ではありませんが、個人的には、商品用に別のテーブルを用意しておくと便利だと思います。
CREATE TABLE Good (
id INT,
name VARCHAR (128),
price FLOAT,
item_count INT,
reserved_count,
catalog_id INT
);
4つ目のテーブル(TextValues)と5つ目のテーブル(NumberValues)は、商品のテキストの値と数値属性を保存するように設計されており、構造も似ています。
CREATE TABLE TextValues (
good_id INT,
field_id INT,
fValue TEXT
);
CREATE TABLE NumberValues (
good_id INT,
field_id INT,
fValue INT
);
テキスト値と数値に個別のテーブルを使用する代わりに、次の構造で単一のCustomeValuesテーブルを使用することもできます。
CREATE TABLE CustomValues (
good_id INT,
field_id INT,
text_value TEXT,
number_value INT
);
データ型ごとに個別に保存しておけば、速度が向上し、容量を節約できるため、私は別々に保存する方を好んでいます。
EAVアプローチを使用したデータへのアクセス
SQLを使用して、カタログ構造マッピングを表示してみましょう。
SELECT * FROM Catalog ORDER BY id;
これらの値からツリーを作成するには、個別のコードが必要となります。 PHPでは、次のようになります。
$stmt = $ pdo-> query ('SELECT * FROM Catalog ORDER BY id');
$aTree = [];
$idRoot = NULL;
while ($row = $ stmt->fetch())
{
$aTree [$row ['id']] = ['name' => $ row ['name']];
if (! $row['parent'])
$idRoot = $row ['id'];
else
$aTree [$row['parent']] ['sub'] [] = $row['id'];
}
将来的には、ルートノードの $aTree[$ idRoot] から始めると、ツリーを簡単に描画できるようになります。
では、特定の商品のプロパティを取得しましょう。
まず、この商品に固有のプロパティのリストを取得し、その後で、それらのプロパティとデータベースにあるプロパティを接続します。 実際には、示されるすべてのプロパティが入力されているわけではないため、LEFT JOINを使用する必要があります。
SELECT * FROM
(
SELECT g. *, F.name, f.type_of, val.fValue, f.sort FROM Good as g
INNER JOIN Field as f ON f.catalog_id = g.catalog_id
LEFT JOIN TextValues as val ON tv.good = g.id AND f.id = val.field_id
WHERE g.id = $ nGood AND f.type_of = 'text'
UNION
SELECT g. *, F.name, f.type_of, val.fValue, f.sort FROM Good as g
INNER JOIN Field as f ON f.catalog_id = g.catalog_id
LEFT JOIN NumberValues as val ON val.good = g.id AND f.id = val.field_id
WHERE g.id = $nGood AND f.type_of = 'number'
) t
ORDER BY t.sort;
数値とテキスト値の両方を保存するために1つのテーブルのみを使用すると、クエリを大幅に簡略化できます。
SELECT g. *, F.name, f.type_of, val.text_value, val.number_value, f.sort FROM Good as g
INNER JOIN Field as f ON f.catalog = g.catalog
LEFT JOIN CustomValues as val ON tv.good = g.id AND f.id = val.field_id
WHERE g.id = $nGood
ORDER BY f.sort;
では、$nCatalogカタログセクションに含まれる商品を表形式で取得します。 まず、カタログのこのセクションのテーブルビューに反映する必要があるプロパティのリストを取得します。
SELECT f.id, f.name, f.type_of FROM Catalog as c
INNER JOIN Field as f ON f.catalog_id = c.id
WHERE c.id = $nCatalog AND f.table_view = 1
ORDER BY f.sort;
次に、テーブルを作成するクエリを構築します。 表形式ビューには、3つの追加プロパティ(Goodテーブルのプロパティのほかに)が必要だとします。 クエリを単純化するために、次を前提としています。
SELECT g.if, g.name, g.price,
f1.fValue as f1_val,
f2.fValue as f2_val,
f3.fValue as f3_val,
FROM Good
LEFT JOIN TextValue as f1 ON f1.good_id = g.id
LEFT JOIN NumberValue as f2 ON f2.good_id = g.id
LEFT JOIN NumberValue as f3 ON f3.good_id = g.id
WHERE g.catalog_id = $nCatalog;
EAVアプローチの長所と短所
EAVアプローチは明らかに柔軟性のメリットがあります。 テーブルなどの固定されたデータ構造を使用すると、オブジェクトの広範なプロパティセットを保存することが可能になります。 また、データベースのスキーマを変更せずに、別のデータ構造を保存することができます。
また、非常に多くの開発者に馴染みのあるSQLも使用することができます。
最も明白なデメリットは、データの論理構造と物理ストレージの不一致であり、これによって様々な問題が引き起こされます。
さらに、プログラミングには、非常に複雑なSQLクエリが伴うこともよくあります。 EAVデータの表示には標準的に使用されていないツールの作成が必要となるため、デバッグが困難になることがあります。 また、LEFT JOINクエリを使用する必要がある場合があるため、データベースの速度が低下してしまいます。
グローバル変数: EAVの代替
私はSQLの世界とグローバル変数の世界の両方に精通しているため、EAVアプローチが解決するタスクにグローバルを使用する方がはるかに魅力的になるのではないかと考えました。
グローバル変数はまばらで階層的な情報を保存できるデータ構造です。 グローバル変数は階層情報を保存するために慎重に最適化されているというのが非常に重要なポイントです。 グローバル変数自体はテーブルよりも低レベルの構造であるため、テーブルよりもはるかに素早く動作します。
同時に、グローバル構造自体をデータ構造に従って選択できるため、コードを非常に単純で明確にすることができます。
デモデータを保存するためのグローバル構造
グローバル変数はデータを保存する上で非常に柔軟でエレガントな構造であるため、1つのグローバル変数を管理するだけでカタログセクション、プロパティ、および商品などのデータを保存することができます。

グローバル構造がデータ構造にどれほど似ているのかに注目してください。 このコンプライアンスによって、コーディングとデバッグが大幅に簡略化されます。
実際には、全ての情報を1つのグローバルに保存したい気持ちが非常に強くても、複数のグローバルを使用することをお勧めします。 インデックス用に別のグローバルを作成することが合理的です。 また、ディレクトリのパーティション構造のストレージを商品から分離することもできます。
この続きは?
この連載の2つ目の記事では、EAVモデルに従う代わりに、InterSystems Irisのグローバルにデータを保存する方法の詳細とメリットについて説明します。