クリアフィルター
記事
Toshihiko Minamoto · 2021年2月8日
これで 3 記事目になります ([パート 1](https://jp.community.intersystems.com/node/485976) と [パート 2](https://jp.community.intersystems.com/node/486191) をご覧ください) が、引き続き Caché データベースの内部構造をご紹介いたします。 今回は、興味深い内容をいくつかご紹介し、私の [Caché Blocks Explorer](https://github.com/daimor/CacheBlocksExplorer/) プロジェクトを使って作業の生産性をアップさせる方法について説明します。
[](https://habrastorage.org/files/fad/ba3/2c3/fadba32c335a4ebeb26354cf1fc19838.png)
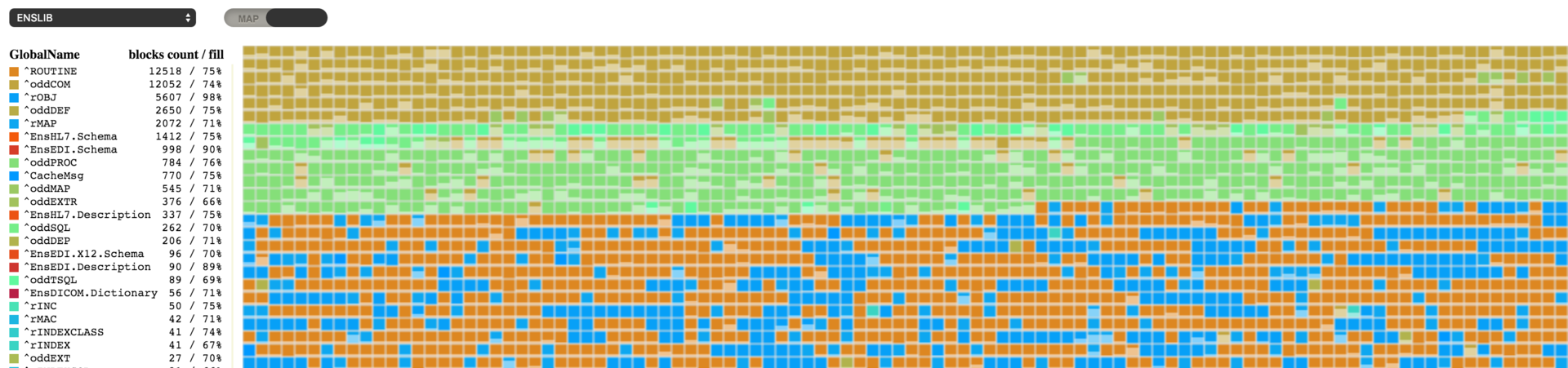
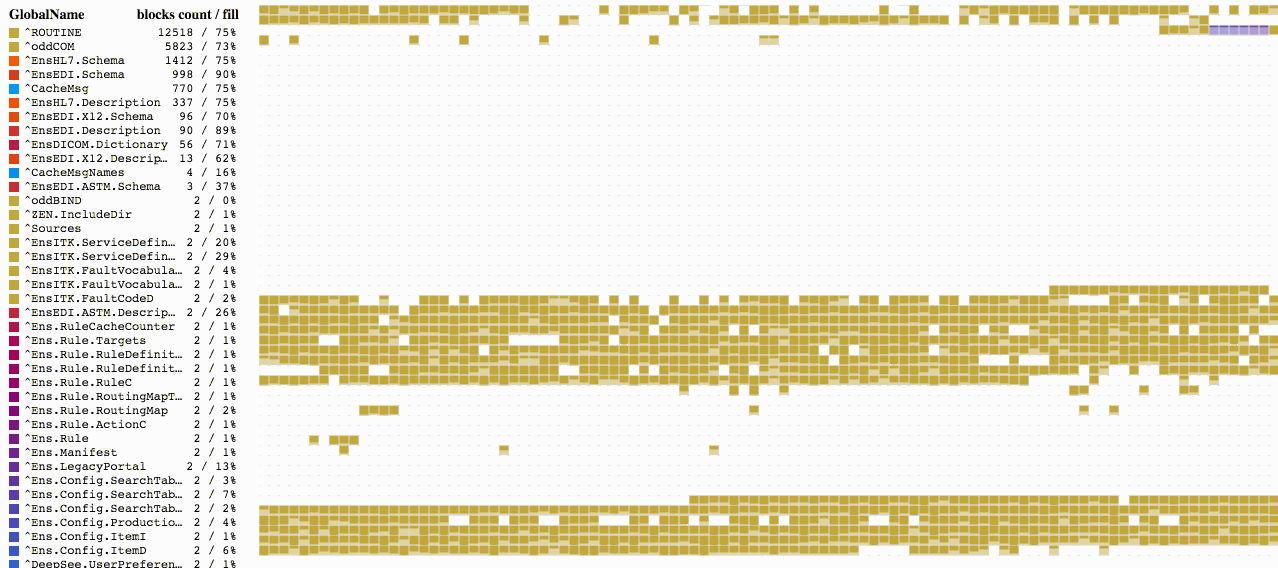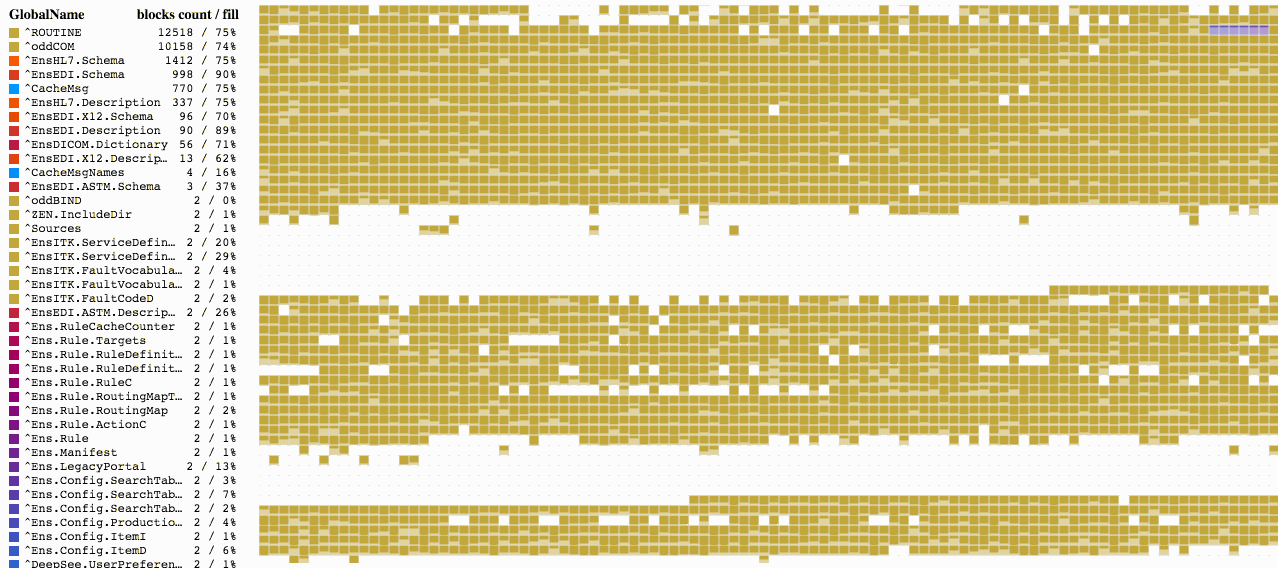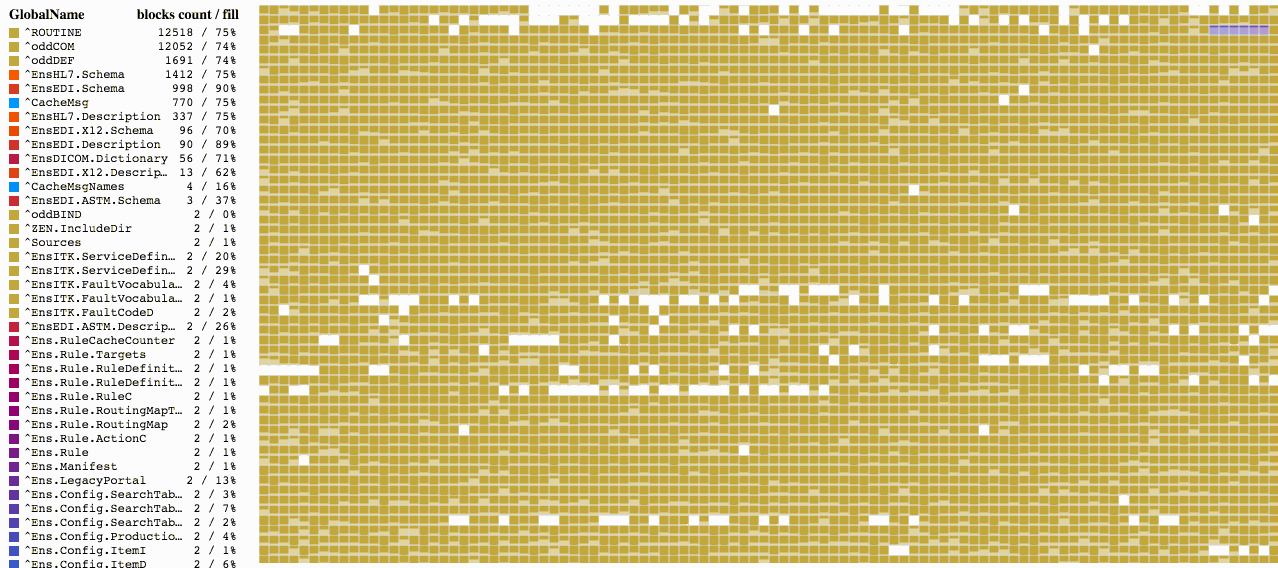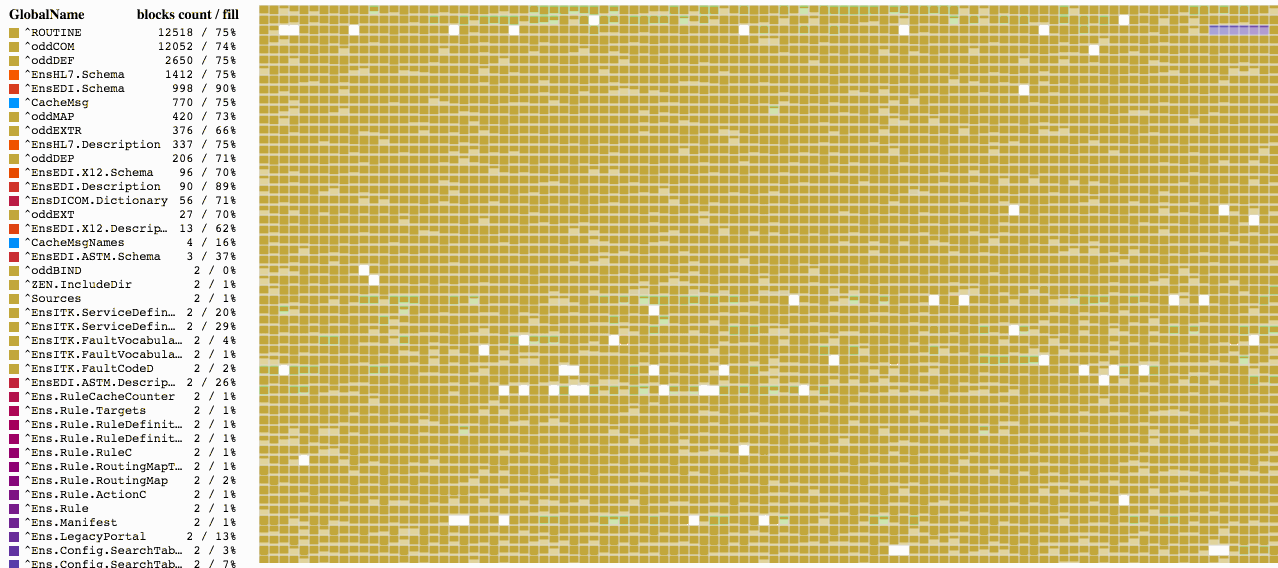
この画像に表示されているものに見覚えがあるという方はたくさんおられると思います (クリック可能)。 グローバルの断片化した状態を視覚化する必要があったとき、様々なディスクデフラグツールが私の頭をよぎりました。 なんとか、そういったツールと同等の効果を発揮する製品を開発できたと願っています。
このユーティリティには複数のブロックで構成されたマップが表示されています。 四角はそれぞれブロックを表し、その色はレジェンドセクションに表示されている特定のグローバルに対応しています。 また、ブロックそのものは格納されているデータの量を示しているため、マップにさっと目を通すだけで、データベース全体の使用量を素早く推定できます。 グローバルレベルのブロックとマップレベルのブロックは未だ実装されていませんので、空のブロック同様に白のブロックとして表示されます。
データベースを選択すれば、すぐにブロックのマップが読み込みを開始します。 情報はそれぞれ順番にではなく、ブロックツリーに並ぶブロックの順番に従って読み込まれるため、そのプロセスは以下の画像のようになる可能性があります。
[](https://habrastorage.org/files/53c/5de/696/53c5de696d3448398b62b19c600e7a47.gif)
データベースは、前回の[記事](https://jp.community.intersystems.com/node/486191)で使用したものを引き続き使用しましょう。 グローバルは必要ありませんので、すべて削除しています。 また、SAMPLES データベースの Sample クラスパッケージを基に新しいデータを生成しました。 そのために、HABR と名付けた私のネームスペースへのパッケージマッピングを設定しています。
[](https://habrastorage.org/files/c31/6a0/a7a/c316a0a7ac2444058536616554541da5.png)
以下のようにデータ生成コマンドを実行しました。
do ##class(Sample.Utils).Generate(20000)
マップには以下の結果が表示されました。
[](https://habrastorage.org/files/003/26f/cdd/00326fcdd5094c85af50f58c8ceccc63.png)
ブロックが埋まり始める場所はファイルの先頭でないことにお気づきでしょうか。 ブロック 16 からトップレベルのポインタブロックが、そしてブロック 50 からデータブロックが始まります。 デフォルト値は 16 と 50 ですが、必要に応じて変更できます。 ポインタブロックの先頭は [SYS.Database](http://docs.intersystems.com/latestj/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=%25SYS&CLASSNAME=SYS.Database) クラスの_NewGlobalPointerBlock_ プロパティで定義されます。これにより、新しいグローバルのデフォルト値が設定されます。 既存のグローバルの場合は、_PointerBlock_ プロパティを使って[%Library.GlobalEdit](http://docs.intersystems.com/latestj/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=%25SYS&CLASSNAME=%Library.GlobalEdit) クラスの中で変更できます。 一連のデータブロックを開始するブロックは、[SYS.Database](docs.intersystems.com/latestj/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=%25SYS&CLASSNAME=SYS.Database) クラスの_NewGlobalGrowthBlock_ プロパティに指定されます。 個別のグローバルの場合は、[%Library.GlobalEdit](http://docs.intersystems.com/latestj/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=%25SYS&CLASSNAME=%Library.GlobalEdit) クラスの _GrowthBlock_ プロパティを使っても同じことができます。 こういったプロパティの変更は、トップポインタブロックやデータブロックの現在の位置には一切影響しないため、まだデータを格納していないグローバルに対してだけ行うことが理に適っていると言えます。
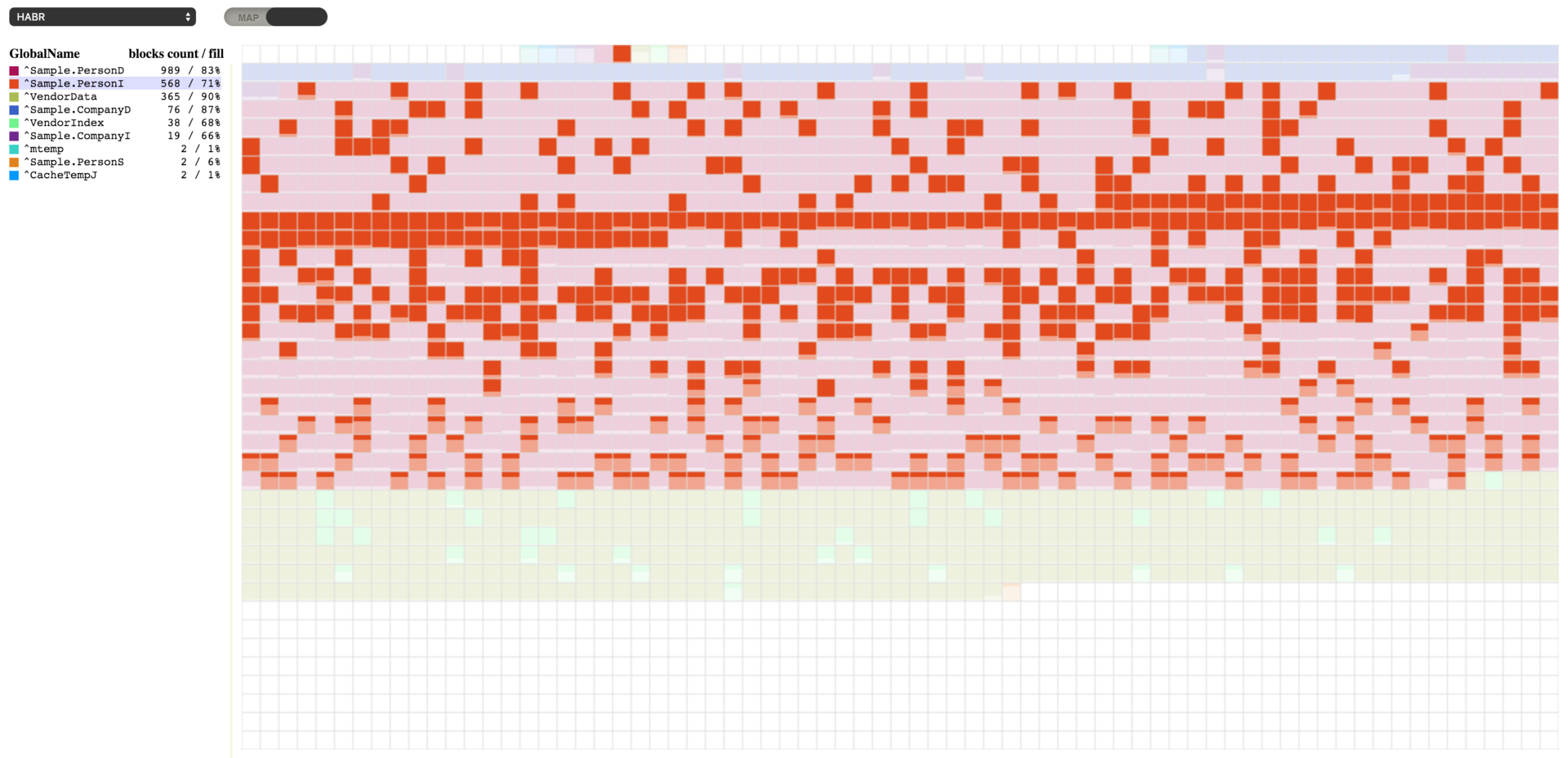
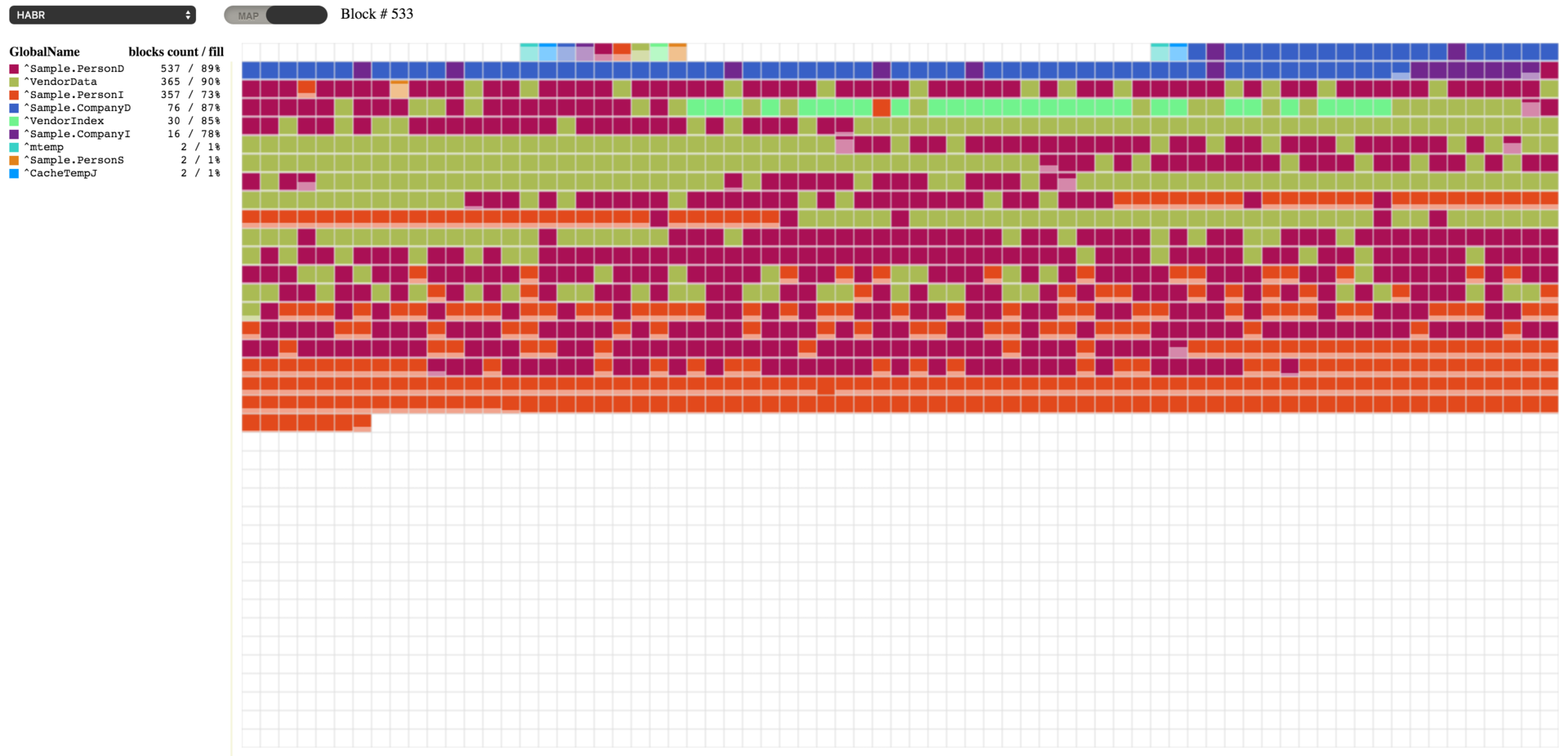
ここで、989 個のブロックを持つ **^Sample.PersonD** グローバルは 83% 埋まっており、それに次いで 573 個のブロックを持つ **^Sample.PersonI** グローバルは 70% 埋まっていることが分かります。 どのグローバルを選択しても、それに割り当てられたブロックを確認できます。 ^Sample.PersonI グローバルを選択すると、ほぼ空になっているブロックがいくつかあるのが分かります。 また、これら 2 つのグローバルに属するブロックが混合していることも分かります。 実はこれには理由があります。 新しいオブジェクトが作成されると、これら 2 つのグローバルは、片方はデータで、もう片方は Sample.Person テーブルのインデックスで埋まってしまうのです。
[](https://habrastorage.org/files/f46/414/e0b/f46414e0b42c4be8a39be1c23e1dda65.png)
テストデータがいくつか手に入ったところで、Caché が提供するデータベース管理機能を活用して結果を確認することができます。 まずは、データを少し取り除いて、いかにもデータを追加したり、削除したりするアクティビティが実行されているかのように見せます。 ランダムなデータをいくつか削除するコードを実行します。
set id=""
set first=$order(^Sample.PersonD(""),1)
set last=$order(^Sample.PersonD(""),-1)
for id=first:$random(5)+1:last {
do ##class(Sample.Person).%DeleteId(id)
}
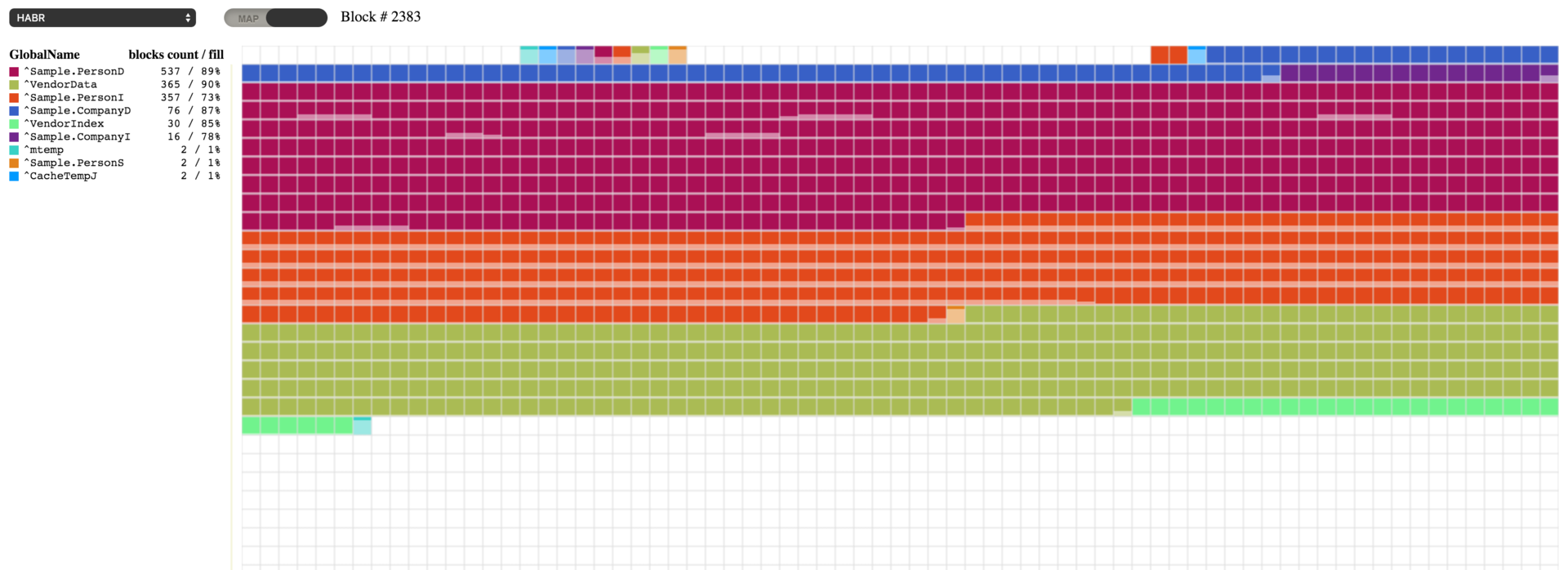
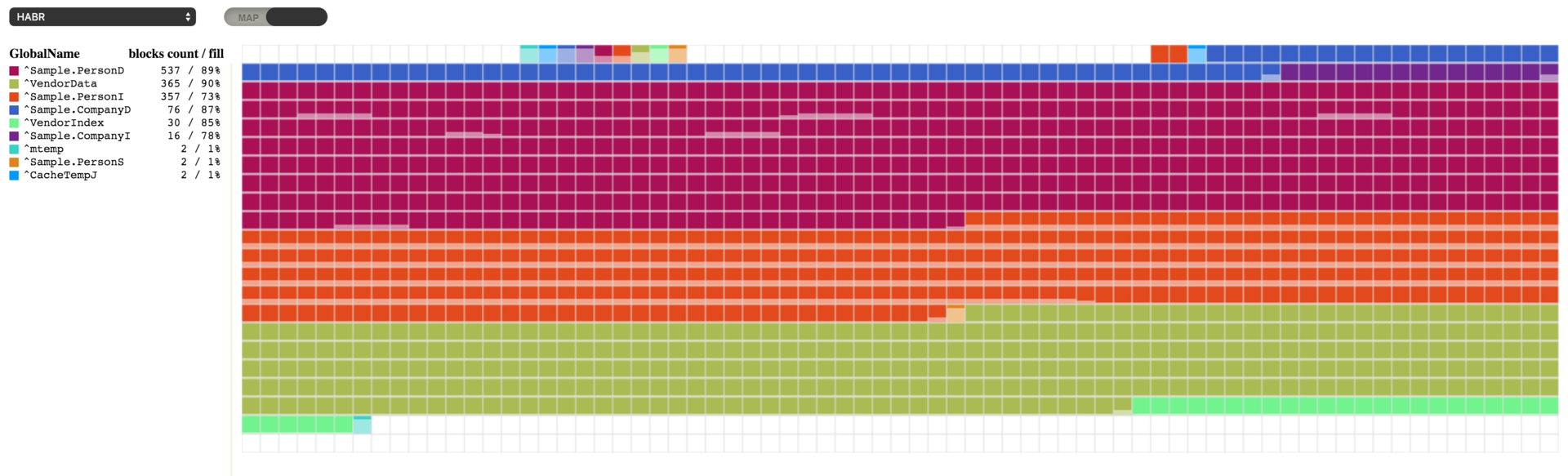
このコードを実行すると、以下の結果が表示されます。 空のブロックがいくつかある一方で、64~67% 埋まっているブロックもあります。
[](https://habrastorage.org/files/cbb/bbf/db3/cbbbbfdb32454d2b955a4573ac4d34d2.png)
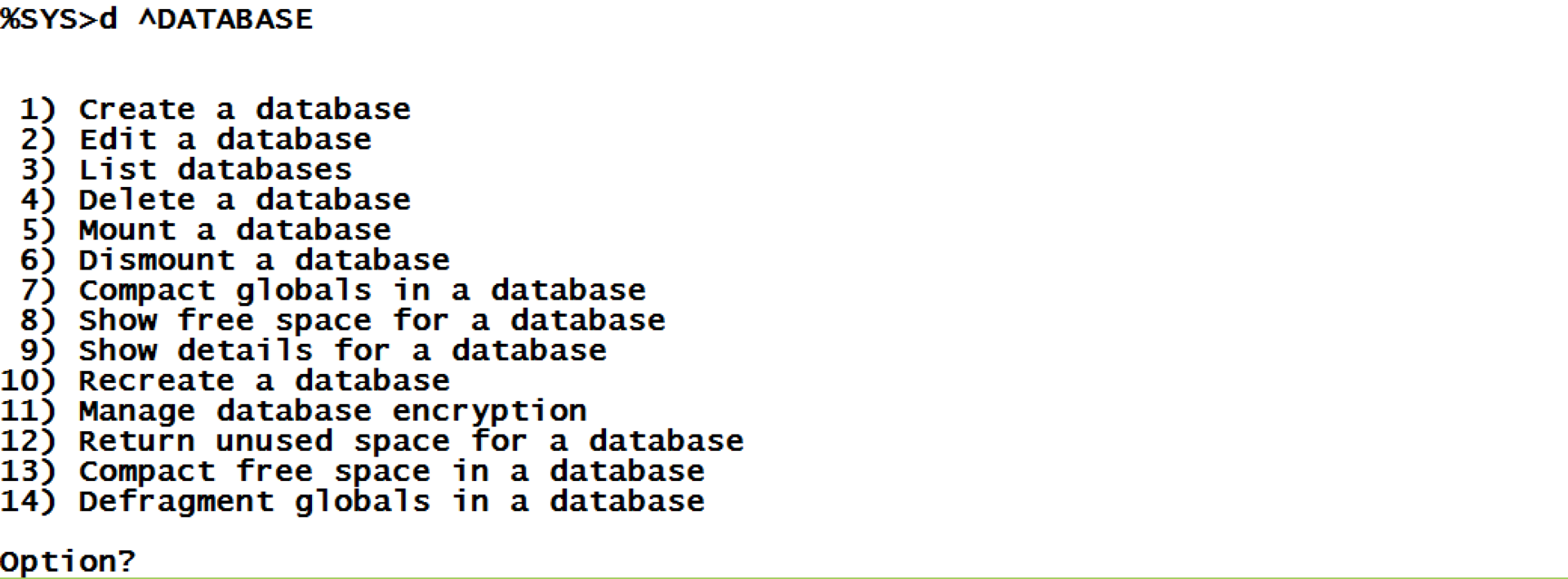
このデータベースは、%SYS ネームスペースから ^[DATABASE](http://docs.intersystems.com/latestj/csp/docbook/DocBook.UI.Page.cls?KEY=GCAS_chui-mgmt#GCAS_chui-mgmt_database) ツールを使って操作することができます。 では、その機能をいくつか使ってみましょう。
[](https://habrastorage.org/files/79f/4d4/9ba/79f4d49ba79a4a41a7c1d470d98f94fa.png)
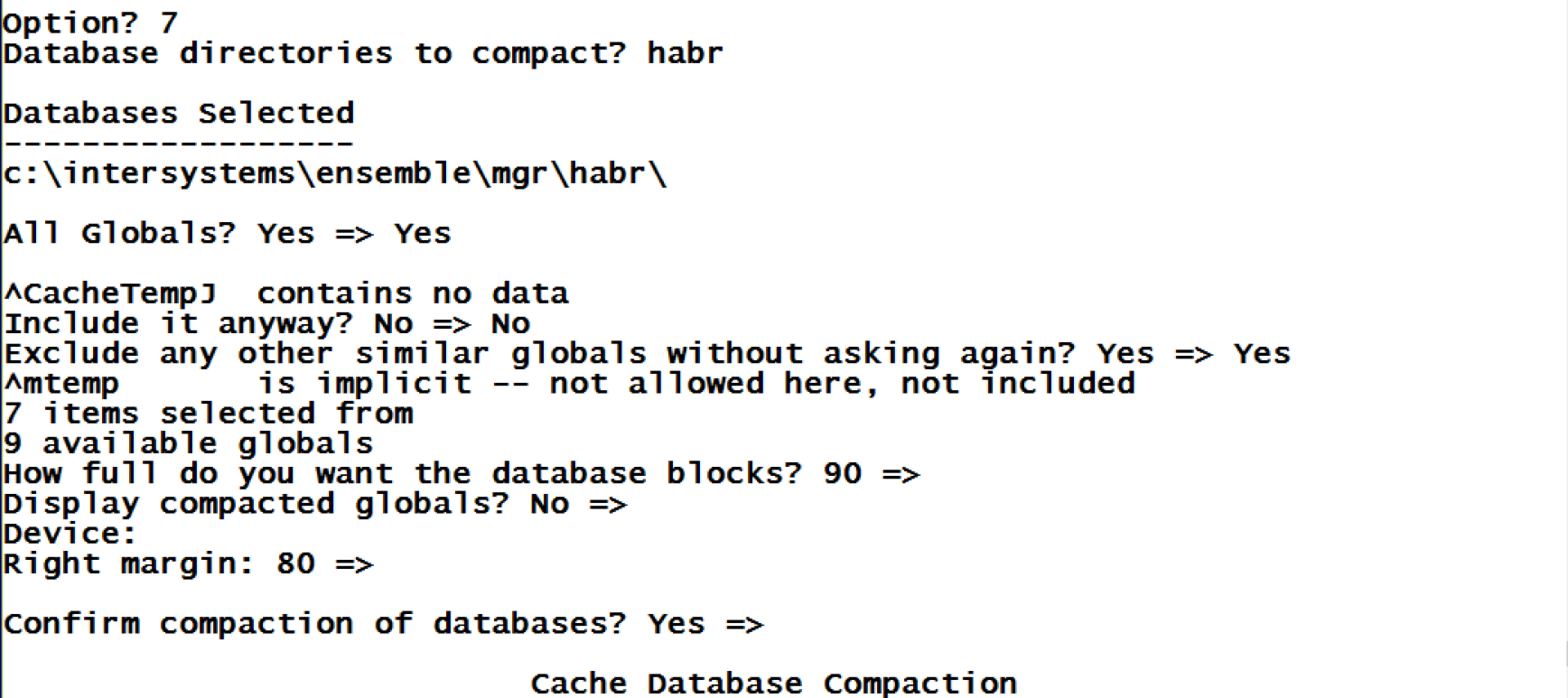
まずは、ブロックがほとんど埋まっていないので、データベース内のすべてのグローバルを圧縮したらどうなるか試してみましょう。
[](https://habrastorage.org/files/987/afe/6d0/987afe6d0a494b5b9f338d0126e94999.png)
[](https://habrastorage.org/files/e6e/35f/f22/e6e35ff2286142a39b1fb0e71b06c90c.png)
ご覧のとおり、圧縮したことで、占有率を必要な 90% の値に限りなく近づけることができました。 この結果、空であったブロックは他のブロックから移動されてきたデータでいっぱいになりました。 データベースのグローバルは、^[DATABASE](http://docs.intersystems.com/latestj/csp/docbook/DocBook.UI.Page.cls?KEY=GCAS_chui-mgmt#GCAS_chui-mgmt_database) ツール (アイテム 7) を使うか、以下のコマンドにデータベースへのパスを 1 つ目のパラメーターとして渡して実行すれば圧縮できます。
do ##class(SYS.Database).CompactDatabase("c:\intersystems\ensemble\mgr\habr\")
また、すべての空のブロックをデータベースの最後に移動することもできます。 これは、例えば、膨大なデータを削除したからデータベースを圧縮したいというときに必要となるかもしれません。 このデモとして、私たちのテスト用データベースからデータを削除する作業をもう一度実行してみましょう。
set gn=$name(^Sample.PersonD)
set first=$order(@gn@(""),1)
set last=$order(@gn@(""),-1)
for i=1:1:10 {
set id=$random(last)+first
write !,id
set count=0
for {
set id=$order(@gn@(id))
quit:id=""
do ##class(Sample.Person).%DeleteId(id)
quit:$increment(count)>1000
}
}
以下はデータを削除した結果です。
[](https://habrastorage.org/files/610/a8e/0b7/610a8e0b7f514b75b002a63c5f2703f0.png)
空のブロックがいくつかあるのが分かります。 Caché では、こういった空のブロックをデータベースファイルの末尾に移動して圧縮することができます。 空のブロックを移動するには、システムネームスペースにある [SYS.Database](http://docs.intersystems.com/latestj/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=%25SYS&CLASSNAME=SYS.Database) クラスの FileCompact メソッドを使うか、^[DATABASE](http://docs.intersystems.com/latestj/csp/docbook/DocBook.UI.Page.cls?KEY=GCAS_chui-mgmt#GCAS_chui-mgmt_database) ツール (アイテム 13) を利用しましょう。 このメソッドには、データベースへのパス、ファイルの末尾の理想的な空きスケース (デフォルトは 0)、戻り値パラメーター (最終的な空きスペース) の 3 つのパラメーターを渡すことができます。
do ##class(SYS.Database).FileCompact("c:\intersystems\ensemble\mgr\habr\",999)
結果、空のブロックがなくなりました。 先頭のブロックは、設定通りに (上位のトップレベルポインタとデータブロックを開始する位置として) 置かれているだけなので、考慮しません。
[](https://habrastorage.org/files/a01/284/6f9/a012846f9cfa4c019df2524a768450cc.png)
### デフラグ (最適化)
これでグローバルを最適化する作業に取りかかれます。 このプロセスを実行すると、各グローバルのブロックの順番が並び替えられます。 デフラグを実行するには、データベースファイルの最後に、ある程度の空きスペースが必要になる場合があり、それが必要な状況ではスペースが追加される可能性があります。 このプロセスは、^[DATABASE](http://docs.intersystems.com/latestj/csp/docbook/DocBook.UI.Page.cls?KEY=GCAS_chui-mgmt#GCAS_chui-mgmt_database) ツールのアイテム 14 から始めるか、以下のコマンドを実行して始めることができます。
d ##class(SYS.Database).Defragment("c:\intersystems\ensemble\mgr\habr\")
[](https://habrastorage.org/files/a38/65d/87b/a3865d87b0cd47d6ab9d06ff5d150630.png)
### 空きスペースを増やす
グローバルがきちんと並べられているのはいいのですが、 どうやら、デフラグによってデータベースファイルのスペースが余分に使われてしまったようです。 このスペースを開放するには、^[DATABASE](http://docs.intersystems.com/latestj/csp/docbook/DocBook.UI.Page.cls?KEY=GCAS_chui-mgmt#GCAS_chui-mgmt_database) ツールのアイテム 12 を使用するか、以下のコマンドを実行します。
d ##class(SYS.Database).ReturnUnusedSpace("c:\intersystems\ensemble\mgr\habr\")
[](https://habrastorage.org/files/4f7/4b4/efe/4f74b4efed0142759fb5f0b7820a777e.png)
データベースの占有スペースは大幅に減りましたが、データベースファイルには空きスケースが 1 MB しか残っていません。 ブロックを移動し、空きスペースを作ることによってデータベース内のグローバルをデフラグし、空きスペースを管理するという可能性が発表されたのはつい最近の話です。 それまでは、データベースをデフラグしてデータベースファイルのサイズを縮小する必要があったときは、^[GBLOCKCOPY](http://docs.intersystems.com/latestj/csp/docbook/DocBook.UI.Page.cls?KEY=GSTU_remote#GSTU_remote_gblockcopy) ツールを使う必要がありました。 このツールは、ソースデータベースの各ブロックを新しく作成されたデータベースに 1 つずつコピーするもので、ユーザーはコピーするグローバルを選択できました。 このツールは現在も使用可能です。
記事
Toshihiko Minamoto · 2021年6月21日
この記事では、syslogテーブルについて説明したいと思います。 syslogとは何か、どのように確認するのか、実際のエントリはどのようなものか、そしてなぜそれが重要であるのかについて説明します。 syslogテーブルには、重要な診断情報が含まれることがあります。 システムに何らかの問題が生じている場合に、このテーブルの確認方法とどのような情報が含まれているのかを理解しておくことが重要です。
syslogテーブルとは?
Cachéは、共有メモリのごく一部を使って、関心のある項目をログに記録しています。 このテーブルは、次のようなさまざまな名前で呼ばれています。
* Cachéシステムエラーログ
* errlog
* SYSLOG
* syslogテーブル
この記事では、単に「syslogテーブル」と呼ぶことにします。
syslogテーブルのサイズは構成可能です。 デフォルトは500エントリで、 10~10,000エントリの範囲で構成できます。 syslogテーブルのサイズを変更するには、システム管理ポータル -> システム管理 -> 構成 -> 追加設定 -> 詳細メモリに移動し、「errlog」行の「編集」を選択します。 そこにsyslogテーブルに必要なエントリの数を入力してください。
**syslogテーブルのサイズを変更する理由は?**
syslogテーブルが500エントリに構成されていると、501番目のエントリによって最初のエントリが上書きされ、そのエントリの情報は失われてしまいます。 これはメモリ内にあるテーブルであるため、出力を明示的に保存しない限りどこにも永続されません。 また、Cachéを停止した場合には、以下に説明する方法でエントリをconsole.logファイルに保存するように構成していない限り、すべてのエントリは失われてしまいます。
Cachéが多くのエントリをsyslogテーブルに書き込んでおり、問題の診断目的でそのエントリを確認する場合、テーブルのサイズが十分に大きくなければ、エントリは失われてしまいます。 syslogテーブルの**Date/Time**列を見ると、テーブルが書き込まれた期間を判別できます。 その上で、どれくらいのエントリ数を設定するのかを決めることができます。 個人的には、エントリを失わない数で判断を誤る方が良いと思います。 このことについては、以下でより詳しく説明します。
**syslogテーブルの確認方法**
syslogテーブルの確認方法にはいくつかあります。
1. Cachéターミナルプロンプトから、%SYSネームスペースで「Do ^SYSLOG」を実行する。
2. Cachéターミナルプロンプトから、%SYSネームスペースで「do ^Buttons」を実行する。
3. 管理ポータル -> システム操作 -> 診断レポートに移動する。
4. -e1オプションでcstatを実行する。
5. Cachehungを実行する。
6. シャットダウン中にsyslogテーブルをconsole.logファイルに書き込むようにCaché を設定し、console.logファイルを確認する。 設定するには、システム管理ポータル -> 構成 -> 追加設定 -> 互換性に移動し、「ShutDownLogErros」行で「編集」を選択します。 Cachéのシャッドダウン中にsyslogのコンテンツをconsole.logに保存する場合は「true」、保存しない場合は「false」を選択します。
**syslogのエントリとは?**
syslogテーブルの例を以下に示します。 この例は、Cachéターミナルプロンプトで「^SYSLOG」を実行して得られたものです。
%SYS>d ^SYSLOG
Device:
Right margin: 80 =>
Show detail? No => No
Cache System Error Log printed on Nov 02 2016 at 4:29 PM
--------------------------------------------------------
Printing the last 8 entries out of 8 total occurrences.
Err Process Date/Time Mod Line Routine Namespace
9 41681038 11/02/2016 04:44:51PM 93 5690 systest+3^systest %SYS
9 41681038 11/02/2016 04:43:34PM 93 5690 systest+3^systest %SYS
9 41681038 11/02/2016 04:42:06PM 93 5690 systest+3^systest %SYS
9 41681038 11/02/2016 04:41:21PM 93 5690 systest+3^systest %SYS
9 41681038 11/02/2016 04:39:29PM 93 5690 systest+3^systest %SYS
9 41681036 11/02/2016 04:38:26PM 93 5690 systest+3^systest %SYS
9 41681036 11/02/2016 04:36:57PM 93 5690 systest+3^systest %SYS
9 41681036 11/02/2016 04:29:45PM 93 5690 systest+3^systest %SYS
列の見出しを見ればエントリの各項目が何であるかは明確のようですが、それらについて説明します。
**Printing the last 8 entries out of 8 total occurrences**
これは、syslogテーブルエントリの一部ではありませんが、確認することは重要なので、ここで説明します。 この行から、いくつのエントリがsyslogテーブルに書き込まれたかがわかります。 この例では、Cachéが起動してから8つのエントリしか書き込まれていません。 エントリ数が少ないのは、これが私のテストシステムであるためです。 「Printing the last 500 entries out of 11,531 total occurrences(発生総数11,531件中最新の500件のエントリを出力)」と書かれていれば、多数のエントリが見逃されていることがわかります。 見逃されたエントリを確認する場合は、テーブルサイズは最大10,000に増やすか、より頻繁にSYSLOGを実行してください。
**Err**
これは、関心のあるイベントについてログに記録される情報です。 エラーは必ずOSレベルで/usr/include/errno.h(Unix)から発生しているものと思われがちですが、実際には「必ず」ではなく、ほとんどの場合です。 ログに記録できるものであれば、何でも記録されます。 たとえば、診断アドホックのデバッグ情報、C変数の値、エラーコードの定義(10000を超えるもの)などを記録することができます。 どのように区別すればよいのでしょうか。 実際に、エントリの**Mod**と**Line**に示される、Cコードの行を確認する必要があります。 つまり、InterSystemsに連絡を取らなければ、それが実際に何であるかを区別することはできません。 では、わざわざ確認する必要はあるのでしょうか。 **err**の意味を正確に知らずとも、ほかの情報を見ることで把握できることがたくさんあるからです。 エントリがたくさんある場合や、普段から目にするエントリとは異なるエントリがある場合には、InterSystemsに問い合わせることもできます。 syslogテーブルのエントリは、必ずしもエラー状態を示すものではないことに注意してください。
**Process**
これは、syslogテーブルにエントリを書き込んだプロセスのプロセスIDです。 たとえば、スタックしたプロセス、スピンし続けるプロセス、またはデッドプロセスがある場合、syslogテーブルに何か記録されていないかを確認できます。 記録されていれば、プロセスで障害が起きた理由の重要な手がかりになるかもしれません。
**Date/Time**
これは、エントリが書き込まれた日時です。 問題になった原因の手がかりを得るために、エントリの日時とシステムイベントの日時を相関することは非常に重要です。
**ModとLine**
Modは特定のCファイルに対応しており、Lineは、そのエントリをsyslogテーブルに書き込んだファイルの行番号です。 カーネルコードにアクセスできるInterSystemsの従業員のみが、これを検索できます。 このコードを調べるだけで、エントリに何が記録されたのかを正確に知ることができます。
**Routine**
syslogテーブルにエントリが書き込まれたときにプロセスが実行していたタグ、オフセット、およびルーチンです。 何が起こっているのかを理解する上で非常に役立ちます。
##### **Namespace**
これは、プロセスが実行していたネームスペースです。
**では、err 9がsyslogテーブルに書き込まれた理由をどのようにして知ることができますか?**
まず、示されているルーチンを確認します。 私の^systestルーチンは次のようになっています。
systest ;test for syslog post
s file="/home/testfile"
o file:10
u file w "hello world"
c file
q
syslogエントリでは、エントリが書き込まれた時に実行していたものはsystest+3だったと示されています。 この行は次のようになっています。
u file w "hello world"
プロセスがファイルに書き込もうとしていたため、これは実際にOSレベルのエラーである可能性があります。そこで、/usr/include/errno.hで9を探すと、次のようになっています。
#define EBADF 9 /* Bad file descriptor */
9はファイル関連であり、示されたコードの行はファイルに書き込もうとしていたため、これは実際にOSエラーコードであると推測するのが合理的です。
**何がエラーになっているのかわかりますか?**
これを解決するために、まず、/homeディレクトリとtestfileファイルの権限を確認しました。 両方とも777となっていたため、ファイルを開いて書き込むのは可能なはずです。 そこでコードをよく見ると、エラーに気づきました。 10秒のタイムアウトの前にコロンを2つ付けていなかったこと、そしてOpenコマンドにはパラメーターを使用していなかったことに気づいたのです。 以下は更新したルーチンです。実際にエラーなしで終了し、ファイルに書き込みます。
systest ;test for syslog post
s file="/scratch1/yrockstr/systest/testfile"
o file:"WNSE":10
u file w "hello world"
c file
q
**最後に**
syslogテーブルは、正しく使用すればデバッグに役立つ貴重なツールです。 使用するときは、次の点に注意してください。
1. **err**は必ずしもオペレーティングシステムのエラーとは限りません。ログに記録できるものは何でも記録されます。 記録された内容については、InterSystemsにお問い合わせください。
2. ログに記録されているその他の情報を使用して、何が起きているのかを判断します。 エラーと組み合わされたCOSコードの行から、それがOSのエラーであるかどうかについて、合理的に推測することができます。
3. 解決できない問題がある場合は、syslogテーブルを確認しましょう。手がかりが見つかるかもしれません。
4. **Date/Time**、エントリ数、および合計発生数を使って、syslogテーブルのサイズを増やす必要があるかどうかを判断します。
5. システムがsyslogテーブルに何を記録しているのかを把握しておきましょう。エントリに何らかの変更があったり、新しいエントリや異なるエントリが記録されたことに気づくことができます。
6. syslogテーブルのエントリは、必ずしも問題を示すものではありません。
記事
Toshihiko Minamoto · 2020年9月28日
InterSystems ハッカソンの時、Artem Viznyuk と私のチームは Arduino ボード(1 台)とその各種パーツ(大量)を所有していました。 そのため、私たちは活動方針を決めました。どの Arduino 初心者もそうであるように、気象観測所を作ることにしたのです。 ただし、Caché のデータ永続ストレージと DeepSee による視覚化を利用しました!
デバイスの操作
InterSystems の Caché は、次のようなさまざまな物理デバイスと論理デバイスを直接操作することができます。
ターミナル
TCP
スプーラー
プリンター
磁気テープ
COM ポート
その他多数
Arduino は通信に COM ポートを使用しているため、私たちの準備は万端でした。一般的に、デバイスの操作は次の5つのステップに分けることができます。
OPEN コマンドでデバイスを現在のプロセスに登録し、デバイスにアクセスする。
USE コマンドでデバイスをプライマリにする。
実際の操作を行う。 READ でデバイスからデータを受信し、WRITE でデータを送信する。
もう一度 USE でプライマリデバイスを切り替える。
CLOSE コマンドでデバイスを解放する。
理論上はこうなりますが、実際はどうなのでしょうか?
Caché からの点滅操作
まず、私たちはCOM ポートから数値を読み取り、指定したミリ秒の間だけ LED に電力を供給する Arduino デバイスを作りました。
回路:
C のコード(Arduino 用)
/* Led.ino
* COM ポートでデータを受信
* led を ledPin に接続
*
// led を接続するピン
#define ledpin 8
// 受信したデータバッファ
String inString = "";
// 開始時に 1 回だけ実行
void setup() {
Serial.begin(9600);
pinMode(ledpin, OUTPUT);
digitalWrite(ledpin, LOW);
}
// 無期限に実行
void loop() {
// com からデータを取得
while (Serial.available() > ) {
int inChar = Serial.read();
if (isDigit(inChar)) {
// 同時に 1 文字
// さらにデータバッファに追加
inString += (char)inChar;
}
// 改行を検出
if (inChar == '\n') {
// led の電源をオン
digitalWrite(ledpin, HIGH);
int time = inString.toInt();
delay(time);
digitalWrite(ledpin, LOW);
// バッファをフラッシュ
inString = "";
}
}
}
最後に、COM ポートに 1000\n を送信する Caché のメソッドを掲載します。
/// 1000\n を com ポートに送信
ClassMethod SendSerial()
{
set port = "COM1"
open port:(:::" 0801n0":/BAUD=9600) // デバイスを開く
set old = $IO // 現在のプライマリデバイスを記録
use port // com ポートに切り替え
write $Char(10) // テストデータを送信
hang 1
write 1000 _ $Char(10) // 1000\n を送信
use old // 古いターミナルに戻る
close port // デバイスを解放
}
«0801n0» は Com ポートにアクセスするためのパラメーターを含む文字列であり、ドキュメントに記載されています。 また、/BAUD=9600 は言うまでもなく接続速度です。
このメソッドをターミナルで実行する場合、次のようになります。
do ##class(Arduino.Habr).SendSerial()
上記を実行しても何も出力されませんが、LED が 1 秒間点滅します。
データ受信
次はキーパッドを Cache に接続し、入力データを受信します。 これは、 認証委任と ZAUTHENTICATE.mac ルーチンを使用するカスタムユーザー認証として使用できます。
回路:
C のコード
/* Keypadtest.ino *
* Keypad ライブラリを使用します。
* Keypad を rowPins[] と colPins[] で指定されているように
* Arduino のピンに接続します。
*
*/
// リポジトリ:
// https://github.com/Chris--A/Keypad
#include
const byte ROWS = 4; // 4 行
const byte COLS = 4; // 3 列
// 記号をキーにマッピングします
char keys[ROWS][COLS] = {
{'1','2','3','A'},
{'4','5','6','B'},
{'7','8','9','C'},
{'*','0','#','D'}
};
// キーパッドのピン 1-8(上下)を Arduino のピン 11-4 に接続します: 1->11, 2->10, ... , 8->4
// キーパッド ROW0, ROW1, ROW2, ROW3 をこの Arduino ピンに接続します
byte rowPins[ROWS] = { 7, 6, 5, 4 };
// キーパッド COL0, COL1, COL2 をこの Arduino ピンに接続します
byte colPins[COLS] = { 8, 9, 10, 11 };
// Keypad の初期化
Keypad kpd = Keypad( makeKeymap(keys), rowPins, colPins, ROWS, COLS );
void setup() {
Serial.begin(9600);
}
void loop() {
char key = kpd.getKey(); // 押されたキーを取得
if(key)
{
switch (key)
{
case '#':
Serial.println();
default:
Serial.print(key);
}
}
}
また、以下は同時に 1 行ずつ COM ポートからデータを取得するために使用される Caché メソッドです。
/// 行末文字を検出するまで COM1 から 1 行を受信します
ClassMethod ReceiveOneLine() As %String
{
port = "COM1"
set str=""
try {
open port:(:::" 0801n0":/BAUD=9600)
set old = $io
use port
read str // 行末文字を検出するまで読み込みます
use old
close port
} catch ex {
close port
}
return str
}
ターミナルで以下を実行します。
write ##class(Arduino.Habr).ReceiveOneLine()
また、(行末文字として送信される)# が押されるまで入力待ち状態になります。その後、入力されたデータがターミナルに表示されます。
以上が Arduino-Caché I/O の基本です。これで、自前の気象観測所を作る準備が整いました。
気象観測所
これで気象観測所に着手できる状態になりました。 私たちはフォトレジスタと DHT11 温湿度センサを使用し、データを収集しました。
回路:
C のコード
/* Meteo.ino *
* 湿度、気温、光の強度を記録して
* それらを COM ポートに送信します
* 出力例: H=1.0;T=1.0;LL=1;
*/
// フォトレジスタのピン(アナログ)
int lightPin = ;
// DHT-11 のピン(デジタル)
int DHpin = 8;
// DHT-11 の一次データを保存する配列
byte dat[5];
void setup() {
Serial.begin(9600);
pinMode(DHpin,OUTPUT);
}
void loop() {
delay(1000); // 1 秒ごとにすべてを測定
int lightLevel = analogRead(lightPin); //輝度レベルを取得
temp_hum(); // 気温と湿度を dat 変数に格納
// And output the result
Serial.print("H=");
Serial.print(dat[], DEC);
Serial.print('.');
Serial.print(dat[1],DEC);
Serial.print(";T=");
Serial.print(dat[2], DEC);
Serial.print('.');
Serial.print(dat[3],DEC);
Serial.print(";LL=");
Serial.print(lightLevel);
Serial.println(";");
}
// DHT-11 のデータを dat に格納
void temp_hum() {
digitalWrite(DHpin,LOW);
delay(30);
digitalWrite(DHpin,HIGH);
delayMicroseconds(40);
pinMode(DHpin,INPUT);
while(digitalRead(DHpin) == HIGH);
delayMicroseconds(80);
if(digitalRead(DHpin) == LOW);
delayMicroseconds(80);
for(int i=;i
記事
Megumi Kakechi · 2025年6月1日
これは InterSystems FAQ サイトの記事です。ロックテーブルを参照する方法として、主に以下の3つの方法が挙げられます。
1. 管理ポータルで参照する方法 ⇒ 管理ポータル:システムオペレーション > ロック > ロックを表示(または管理)
2. ^LOCKTAB ユーティリティ を使用する方法 ⇒ %SYS> do ^LOCKTAB
3. プログラムで参照する方法 ⇒ プログラム内でロック情報を取得する方法
こちらの記事では、ロックテーブルで参照できる情報について、以下の3つのケースに分けて、かかるロックとその意味をご説明します。
1.トランザクションで更新クエリ実行時、他のプロセスで更新・参照した状態
2.デッドロックとなった状態
3.テーブルロックがかかった状態
目視で一番わかり易いのは、1の 管理ポータルで参照する方法 になるので、こちらで説明したいと思います。
最初に、1.トランザクションで更新クエリ実行時、他のプロセスで更新・参照をすると、どのようなロックがかかるのか見ていきます。
a. プロセスA(PID=10044)にてトランザクションで、Sample.Personテーブルの ID=1 を更新します。 ⇒ Exclusive_e->Delock ロック
[SQL]TL1:USER>>update Sample.Person(Name) values('bbb') where ID=1
b. プロセスB(PID=46952)にて、Sample.Personテーブルの ID=1 を更新します。 ⇒ WaitExclusiveExact ロック → ロックタイムアウト後(既定10秒)、[SQLCODE: <-110>:<ファイル中にロック競合が発生しました>] エラーが返ります。
[SQL]USER>>update Sample.Person(Name) values('ccc') where ID=1
c. プロセスC(PID=45680)にて、read commit モード で、Sample.Personテーブルの ID=1 を参照します。 ⇒ WaitSharedExact ロック → ロックタイムアウト後(既定10秒)、[SQLCODE: <-114>:<ひとつまたはそれ以上のマッチする行が別のユーザによりロックされています>] エラーが返ります。
[SQL]USER>>set transaction isolation level read committed
[SQL]USER>>select * from Sample.Person where ID=1
管理ポータルでロックテーブル情報を見てみます。青四角がそれそれでの持しているロックになります。※複数の増分ロックがかかっているときは、「Exclusive/5」のように、ロック数も表示されます。1つのロックの時は表示されません。
次に、2.デッドロックが発生しているとき、どのようなロックの状態になるのか見てみます。
1. プロセス A(PID:43468) で次のコマンドを発行します : lock +^MyGlobal(15)
2. プロセス B(PID:2198) で次のコマンドを発行します : lock +^MyOtherGlobal(15)
3. プロセス A で次のコマンドを発行します : lock +^MyOtherGlobal(15)
⇒ この LOCK コマンドは返りません。このプロセスは、プロセス B がロックを解放するまでブロックされます。
4. プロセス B で次のコマンドを発行します : lock +^MyGlobal(15)
⇒ この LOCK コマンドも返りません。このプロセスは、プロセス A がロックを解放するまでブロックされます。
プロセスA、プロセスB、ともにロックの解放待ちで、応答が返らない状態(デッドロック)になりました。
管理ポータルでロックテーブル情報を見てみます。
プロセスA(PID:43468) ・^MyGlobal(15) に対する Exclusive(排他ロック)を保持 ・^MyOtherGlobal(15) に対し、WaitExclusiveExactで同一ロックに対する排他ロックの待機(ロック解放待ち)
プロセスB(PID:2198) ・^MyOtherGlobal(15) に対する Exclusive(排他ロック)を保持 ・^MyGlobal(15) に対し、WaitExclusiveExactで同一ロックに対する排他ロックの待機(ロック解放待ち)
お互いに、それぞれが保持しているロックの解放待ちで、デッドロック状態となっていることが分かります。
デッドロックを防止するには以下のような方法があります。
常に timeout 引数を使用する。
増分 LOCK コマンドを発行する際にその順序に関して厳格なプロトコルに従う。すべてのプロセスが、ロック名に関して同じ順序に従っている限り、デッドロックが発生することはありません。単純なプロトコルは、照合順序でロックを追加するものです。
増分ロックではなく単純ロックを使用する (つまり、+ 演算子を使用しない)。前述のとおり、単純ロックでは、LOCK コマンドは最初に、プロセスによって以前から保持されていたすべてのロックを解放します (ただし、実際には単純ロックはあまり使用されません)。
最後に、3.テーブルロックがかかった状態では、どのようなロックがかかるのか見ていきます。
今回は、Create Table で作成した、SQLUser.tab1 テーブルで実験してみます。現在、ロック閾値 が 1000(デフォルト) なので、トランザクションでそれ以上の更新をしてみます。
1回目の Insert で、「Exclusive_e->Delock」のロックが1つかかっているのが分かります。
2回目の Insert で、「Exclusive_e->Delock」のロックが2つになったのが分かります。
1001回目の Insert では、テーブルロック閾値(1000)を超えたために、「Exclusive/1001E->Delock」というテーブルロックにまとめられたことが分かります。
今回は、管理ポータルで参照する方法をご紹介しましたが、^LOCKTABユーティリティ や、プログラムで取得する方法 でも、同様の情報を見ることが可能です。
なお、正常に終了したプロセスは取得していたロックを全て解放します。
【ご参考】InterSystems製品のロックの基本
記事
Toshihiko Minamoto · 2022年2月14日
**キーワード**: IRIS、IntegratedML、Flask、FastAPI、Tensorflow Serving、HAProxy、Docker、Covid-19
## 目的:
過去数か月に渡り、潜在的なICU入室を予測するための単純なCovid-19 X線画像分類器やCovid-19ラボ結果分類器など、ディープラーニングと機械学習の簡単なデモをいくつか見てきました。 また、ICU分類器のIntegratedMLデモ実装についても見てきました。 「データサイエンス」の旅路はまだ続いていますが、「データエンジニアリング」の観点から、AIサービスデプロイメントを試す時期が来たかもしれません。これまでに見てきたことすべてを、一式のサービスAPIにまとめることはできるでしょうか。 このようなサービススタックを最も単純なアプローチで達成するには、どういった一般的なツール、コンポーネント、およびインフラストラクチャを活用できるでしょうか。
## 対象範囲
### **対象:**
ジャンプスタートとして、docker-composeを使用して、次のDocker化されたコンポーネントをAWS Ubuntuサーバーにデプロイできます。
* **HAProxy ** - ロードバランサー
* **Gunicorn** と **Univorn ** - Webゲートウェイ****サーバー
* **Flask** と **FastAPI** - WebアプリケーションUI、サービスAPI定義、およびヒートマップ生成などのアプリケーションサーバー
* **Tensorflow Model Serving** と **Tensorflow-GPU Model Serving** - 画像や分類などのアプリケーションバックエンドサーバー
* IRIS **IntegratedML** - SQL インターフェースを備えたアプリとデータベースを統合した AutoML
* **ベンチマーキング**用クライアントをエミュレートする、**Jupyterノートブック**のPython3
* Dockerと**docker-compose**
* Testla T4 GPU搭載の**AWS Ubuntu** 16.04
注意: GPUを使用したTensorflow Servingはデモのみを目的としています。GPU関連の画像(dockerfile)と構成(docker-compose.yml)は、単純にオフにできます。
### **対象外**またはウィッシュリスト:
* **Nginx **または**Apache**などのWebサーバーは、今のところこのデモでは省略されています。
* **RabbitMQ**とRedis - IRISまたはEnsembleと置き換えられる、信頼性の高いメッセージングキューブローカー。
* **IAM**([Intersystems API Manger](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=AIAM))または**Kong**はウィッシュリストに含まれます。
* **SAM **(InterSystemsの[システムアラートと監視](https://docs.intersystems.com/sam/csp/docbook/DocBook.UI.Page.cls?KEY=ASAM))
* **Kubernetes** Operator付きの**ICM**([InterSystems Cloud Manager](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=PAGE_DEPLOYMENT_ICM))- 誕生したときからずっとお気に入りの1つです。
* **FHIR**(IntesyStems IRISベースのFHIR R4サーバーとFHIRアプリのSMART用FHIRサンドボックス)
* **CI/CD**開発ツールまたは**Github Actions**
「機械学習エンジニア」は、サービスのライフサイクルに沿って本番環境をプロビジョニングする際に、必然的にこれらのすべてのコンポーネントを操作しなければならないでしょう。 今後徐々に、焦点を当てていきたいと思います。
## GitHubリポジトリ
全ソースコードの場所:
また、新しいリポジトリとともに、[integratedML-demo-templateリポジトリ](https://github.com/intersystems-community/integratedml-demo-template)も再利用します。
## デプロイメントのパターン
以下に、この「DockerでのAIデモ」テストフレームワークの論理的なデプロイパターンを示します。
デモの目的により、意図的にディープラーニング分類とWebレンダリング用に個別のスタックを2つ作成し、HAProxyをソフトロードバランサーとして使用して、受信するAPIリクエストをこれらの2つのスタックでステートレスに分散できるようにしました。
* Guniorn + Flask + Tensorflow Serving
* Univcorn + FaskAPI + Tensorflow Serving GPU
前の記事のICU入室予測と同様に、機械学習デモのサンプルには、IntegratedMLを使用したIRISを使用します。
現在のデモでは、本番サービスでは必要または検討される共通コンポーネントをいくつか省略しました。
* Webサーバー: NginxまたはApacheなど。 HAProxyとGunicorn/Uvicornの間で、適切なHTTPセッション処理を行うために必要となります(DoS攻撃を防止するなど)。
* キューマネージャーとDB: RabbitMQやRedisなど。Flask/FastAPIとバックエンドサービングの間で、信頼性のある非同期サービングとデータ/構成の永続性などに使用されます。
* APIゲートウェイ: IAMまたはKongクラスター。単一障害点を作らないように、HAProxyロードバランサーとAPI管理用Webサーバーの間に使用されます。
* 監視とアラート: SAMが適切でしょう。
* CI/CD開発のプロビジョニング: クラウドニューラルデプロイメントと管理、およびその他の一般的な開発ツールによるCI/CDにはK8を使用したICMが必要です。
実際のところ、IRIS自体は、信頼性の高いメッセージングのためのエンタープライズ級のキューマネージャーとしても、高性能データベースとしても確実に使用することができます。 パターン分析では、IRISがRabbitMQ/Redis/MongoDBなどのキューブローカーとデータベースの代わりになることは明らかであるため、レイテンシが大幅に低く、より優れたスループットパフォーマンスとさらに統合する方が良いでしょう。 さらに、IRIS Webゲートウェイ(旧CSPゲートウェイ)は、GunicornやUvicornなどの代わりに配置できますよね?
## 環境トポロジー
上記の論理パターンを全Dockerコンポーネントに実装するには、いくつかの一般的なオプションがあります。 頭に思い浮かぶものとしては以下のものがあります。
* docker-compose
* docker swarmなど
* Kubernetesなど
* K8演算を使用したICM
このデモは、機能的なPoCといくつかのベンチマーキングを行うために、「docker-compose」から始めます。 もちろん、いつかはK8やICMを使いたいとも考えています。
[docker-compose.yml](https://github.com/zhongli1990/covid-ai-demo-deployment/blob/master/docker-compose.yml)ファイルに説明されているように、AWS Ubuntuサーバーでの環境トポロジーの物理的な実装は、以下のようになります。
上図は、全Dockerインスタンスの**サービスポート**が、デモの目的でどのようにマッピングされており、Ubuntuサーバーで直接公開されているかを示したものです。 本番環境では、すべてセキュリティ強化される必要があります。 また、純粋なデモの目的により、すべてのコンテナは同じDockerネットワークに接続されています。本番環境では、外部ルーティング可能と内部ルーティング不可能として分離されます。
## Docker化コンポーネント
以下は、[docker-compose.yml](https://github.com/zhongli1990/covid-ai-demo-deployment/blob/master/docker-compose.yml)ファイルに示されるとおり、ホストマシン内でこれらの**ストレージボリューム**が各コンテナインスタンスにどのようにマウントされているかを示します。
ubuntu@ip-172-31-35-104:/zhong/flask-xray$ tree ./ -L 2
./
├── covid19 (Flask+GunicornコンテナとTensorflow Servingコンテナがここにマウントされます)
│ ├── app.py (Flaskメインアプリ: WebアプリケーションとAPIサービスインターフェースの両方がここに定義されて実装されます)
│ ├── covid19_models (CPU使用の画像分類Tensorflow Servingコンテナ用のTensorflowモデルはここに公開されてバージョン管理されます)
│ ├── Dockerfile (Flask サーバーとGunicorn: CMD ["gunicorn", "app:app", "--bind", "0.0.0.0:5000", "--workers", "4", "--threads", "2"])
│ ├── models (.h5形式のFlaskアプリ用モデルとX線画像へのGrad-CAMによるヒートマップ生成のAPIデモ)
│ ├── __pycache__
│ ├── README.md
│ ├── requirements.txt (全Flask+Gunicornアプリに必要なPythonパッケージ)
│ ├── scripts
│ ├── static (Web静的ファイル)
│ ├── templates (Webレンダリングテンプレート)
│ ├── tensorflow_serving (TensorFlow Servingサービスの構成ファイル)
│ └── test_images
├── covid-fastapi (FastAPI+UvicornコンテナとGPU使用のTensorflow Servingコンテナはここにマウントされます)
│ ├── covid19_models (画像分類用のTensorflow Serving GPUモデルは、ここに公開されてバージョン管理されます)
│ ├── Dockerfile (Uvicorn+FastAPIサーバーはここから起動されます: CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000", "--workers", "4" ])
│ ├── main.py (FastAPIアプリ: WebアプリケーションとAPIサービスインターフェースの両方がここに定義されて実装されます)
│ ├── models (.h5形式のFastAPIアプリ用モデルとX線画像へのGrad-CAMによるヒートマップ生成のAPIデモ)
│ ├── __pycache__
│ ├── README.md
│ ├── requirements.txt
│ ├── scripts
│ ├── static
│ ├── templates
│ ├── tensorflow_serving
│ └── test_images
├── docker-compose.yml (フルスタックDocker定義ファイル。 Docker GPU「nvidia runtime」用にバージョン2.3を使用。そうでない場合はバージョン3.xを使用可)
├── haproxy (HAProxy dockerサービスはここに定義されます。 注意: バックエンドLBにはスティッキーセッションを定義できます。 )
│ ├── Dockerfile
│ └── haproxy.cfg
└── notebooks (TensorFlow 2.2とTensorBoardなどを含むJupyterノートブックコンテナサービス)
├── Dockerfile
├── notebooks (機能テスト用に外部APIクライアントアプリをエミュレートするサンプルノートブックファイルとロードバランサーに対してPythonによるAPIベンチマークテストを行うサンプルノートブックファイル)
└── requirements.txt
注意: 上記の[docker-compose.yml](https://github.com/zhongli1990/covid-ai-demo-deployment/blob/master/docker-compose.yml)はCovid-19 X線画像のディープラーニングデモ用です。 別の[integratedML-demo-template](https://github.com/intersystems-community/integratedml-demo-template)の[docker-compose.yml](https://github.com/intersystems-community/integratedml-demo-template/blob/master/docker-compose.yml)とともに、環境トポロジーに表示されるフルサービススタックを形成するために使用されています。
## サービスの起動
すべてのコンテナサービスを起動するには、単純な**docker-compose up -d**を使用します。
ubuntu@ip-172-31-35-104:~$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES31b682b6961d iris-aa-server:2020.3AA "/iris-main" 7 weeks ago Up 2 days (healthy) 2188/tcp, 53773/tcp, 54773/tcp, 0.0.0.0:8091->51773/tcp, 0.0.0.0:8092->52773/tcp iml-template-master_irisimlsvr_16a0f22ad3ffc haproxy:0.0.1 "/docker-entrypoint.…" 8 weeks ago Up 2 days 0.0.0.0:8088->8088/tcp flask-xray_lb_171b5163d8960 ai-service-fastapi:0.2.0 "uvicorn main:app --…" 8 weeks ago Up 2 days 0.0.0.0:8056->8000/tcp flask-xray_fastapi_1400e1d6c0f69 tensorflow/serving:latest-gpu "/usr/bin/tf_serving…" 8 weeks ago Up 2 days 0.0.0.0:8520->8500/tcp, 0.0.0.0:8521->8501/tcp flask-xray_tf2svg2_1eaac88e9b1a7 ai-service-flask:0.1.0 "gunicorn app:app --…" 8 weeks ago Up 2 days 0.0.0.0:8051->5000/tcp flask-xray_flask_1e07ccd30a32b tensorflow/serving "/usr/bin/tf_serving…" 8 weeks ago Up 2 days 0.0.0.0:8510->8500/tcp, 0.0.0.0:8511->8501/tcp flask-xray_tf2svg1_1390dc13023f2 tf2-jupyter:0.1.0 "/bin/sh -c '/bin/ba…" 8 weeks ago Up 2 days 0.0.0.0:8506->6006/tcp, 0.0.0.0:8586->8888/tcp flask-xray_tf2jpt_188e8709404ac tf2-jupyter-jdbc:1.0.0-iml-template "/bin/sh -c '/bin/ba…" 2 months ago Up 2 days 0.0.0.0:6026->6006/tcp, 0.0.0.0:8896->8888/tcp iml-template-master_tf2jupyter_1
**docker-compose up --scale fastapi=2 --scale flask=2 -d** for example will horizontally scale up to 2x Gunicorn+Flask containers and 2x Univcorn+FastAPI containers:
ubuntu@ip-172-31-35-104:/zhong/flask-xray$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMESdbee3c20ea95 ai-service-fastapi:0.2.0 "uvicorn main:app --…" 4 minutes ago Up 4 minutes 0.0.0.0:8057->8000/tcp flask-xray_fastapi_295bcd8535aa6 ai-service-flask:0.1.0 "gunicorn app:app --…" 4 minutes ago Up 4 minutes 0.0.0.0:8052->5000/tcp flask-xray_flask_2
... ...
「integrtedML-demo-template」の作業ディレクトリで別の「docker-compose up -d」を実行することで、上記リストのirisimlsvrとtf2jupyterコンテナが起動されています。
## テスト
### **1. 単純なUIを備えたAIデモWebアプリ**
上記のdockerサービスを起動したら、一時アドレスのAWS EC2インスタンスにホストされている[Covid-19に感染した胸部X線画像の検出](https://community.intersystems.com/post/run-some-covid-19-lung-x-ray-classification-and-ct-detection-demos)用デモWebアプリにアクセスできます。
以下は、私の携帯でキャプチャした画面です。 デモUIは非常に単純です。基本的に「Choose File」をクリックして「Submit」ボタンを押せば、[X線画像](https://github.com/zhongli1990/Covid19-X-Rays/tree/master/all/test)がアップロードされて分類レポートが表示されます。 Covid-19感染のX線画像として分類されたら、DLによって「検出された」病変領域をエミュレートする[ヒートマップが表示](https://community.intersystems.com/post/explainability-and-visibility-covid-19-x-ray-classifiers-deep-learning)されます。そうでない場合は、分類レポートにはアップロードされたX線画像のみが表示されます。
このWebアプリはPythonサーバーページです。このロジックは主に[FastAPI's main.py](https://github.com/zhongli1990/covid-ai-demo-deployment/blob/master/covid-fastapi/main.py)ファイルと[Flask's app.py](https://github.com/zhongli1990/covid-ai-demo-deployment/blob/master/covid19/app.py)ファイルにコーディングされています。
もう少し時間に余裕がある際には、FlaskとFastAPIのコーディングと規則の違いを詳しく説明かもしれません。 実は、AIデモホスティングについて、FlaskとFastAPIとIRISの比較を行いたいと思っています。
### **2. テストデモAPI**
FastAPI(ポート8056で公開)には、以下に示すSwagger APIドキュメントが組み込まれています。 これは非常に便利です。 以下のようにURLに「/docs」を指定するだけで、利用することができます。
.png)
いくつかのプレースホルダー(/helloや/itemsなど)と実際のデモAPIインターフェース(/healthcheck、/predict、predict/heatmapなど)を組み込みました。
**これらのAPIに簡単なテストを実行してみましょう**。[私がこのAIデモサービス用に作成したJupyterノートブックサンプル](https://github.com/zhongli1990/covid-ai-demo-deployment/tree/master/notebooks/notebooks)の1つで、Python行を(APIクライアントアプリエミュレーターとして)いくつか実行します。
以下では、例としてこちらのファイルを実行しています。
まず、バックエンドのTF-Serving(ポート8511)とTF-Serving-GPU(ポート8521)が稼働していることをテストします。
!curl http://172.17.0.1:8511/v1/models/covid19 # tensorflow serving
!curl http://172.17.0.1:8521/v1/models/covid19 # tensorflow-gpu serving
{
"model_version_status": [
{
"version": "2",
"state": "AVAILABLE",
"status": {
"error_code": "OK",
"error_message": ""
}
}
]
}
{
"model_version_status": [
{
"version": "2",
"state": "AVAILABLE",
"status": {
"error_code": "OK",
"error_message": ""
}
}
]
}
次に、以下のサービスAPIが稼働していることをテストします。
Gunicorn+Flask+TF-Serving
Unicorn+FastAPI+TF-Serving-GPU
上記の両サービスの手間にあるHAProxyロードバランサー
r = requests.get('http://172.17.0.1:8051/covid19/api/v1/healthcheck') # tf srving docker with cpu
print(r.status_code, r.text)
r = requests.get('http://172.17.0.1:8056/covid19/api/v1/healthcheck') # tf-serving docker with gpu
print(r.status_code, r.text)
r = requests.get('http://172.17.0.1:8088/covid19/api/v1/healthcheck') # tf-serving docker with HAproxy
print(r.status_code, r.text)
そして、以下のような結果が期待されます。
200 Covid19 detector API is live!
200 "Covid19 detector API is live!\n\n"
200 "Covid19 detector API is live!\n\n"
入力X線画像の分類とヒートマップ結果を返す、**/predict/heatmap**などの機能的なAPIインターフェースをテストします。 受信する画像は、API定義に従ってHTTP POST経由で送信される前にbased64にエンコードされています。
%%time
# リクエストライブラリをインポート
import argparse
import base64
import requests
# api-endpointを定義
API_ENDPOINT = "http://172.17.0.1:8051/covid19/api/v1/predict/heatmap"
image_path = './Covid_M/all/test/covid/nejmoa2001191_f3-PA.jpeg'
#image_path = './Covid_M/all/test/normal/NORMAL2-IM-1400-0001.jpeg'
#image_path = './Covid_M/all/test/pneumonia_bac/person1940_bacteria_4859.jpeg'
b64_image = ""
# JPGやPNGなどの画像をbase64形式にエンコード
with open(image_path, "rb") as imageFile:
b64_image = base64.b64encode(imageFile.read())
# APIに送信されるデータ
data = {'b64': b64_image}
# POSTリクエストを送信しレスポンスをレスポンスオブジェクトとして保存
r = requests.post(url=API_ENDPOINT, data=data)
print(r.status_code, r.text)
# レスポンスを抽出
print("{}".format(r.text))
このようなすべての[テスト画像もGitHubにアップロード済み](https://github.com/zhongli1990/Covid19-X-Rays/tree/master/all/test)です。 上記のコードの結果は以下のようになります。
200 {"Input_Image":"http://localhost:8051/static/source/0198f0ae-85a0-470b-bc31-dc1918c15b9620200906-170443.png","Output_Heatmap":"http://localhost:8051/static/result/Covid19_98_0198f0ae-85a0-470b-bc31-dc1918c15b9620200906-170443.png.png","X-Ray_Classfication_Raw_Result":[[0.805902302,0.15601939,0.038078323]],"X-Ray_Classification_Covid19_Probability":0.98,"X-Ray_Classification_Result":"Covid-19 POSITIVE","model_name":"Customised Incpetion V3"}
{"Input_Image":"http://localhost:8051/static/source/0198f0ae-85a0-470b-bc31-dc1918c15b9620200906-170443.png","Output_Heatmap":"http://localhost:8051/static/result/Covid19_98_0198f0ae-85a0-470b-bc31-dc1918c15b9620200906-170443.png.png","X-Ray_Classfication_Raw_Result":[[0.805902302,0.15601939,0.038078323]],"X-Ray_Classification_Covid19_Probability":0.98,"X-Ray_Classification_Result":"Covid-19 POSITIVE","model_name":"Customised Incpetion V3"}
CPU times: user 16 ms, sys: 0 ns, total: 16 ms
Wall time: 946 ms
### **3. デモサービスAPIをベンチマークテストする**
HAProxyロードバランサーインスタンスをセットアップします。 また、Flaskサービスを4個のワーカーで開始し、FastAPIサービスも4個のワーカーで開始しました。
ノートブックファイルで直接8個のPythonプロセスを作成し、8個の同時APIクライアントがデモサービスAPIにリクエストを送信する様子をエミュレートしてみてはどうでしょうか。
#from concurrent.futures import ThreadPoolExecutor as PoolExecutor
from concurrent.futures import ProcessPoolExecutor as PoolExecutor
import http.client
import socket
import time
start = time.time()
#laodbalancer:
API_ENDPOINT_LB = "http://172.17.0.1:8088/covid19/api/v1/predict/heatmap"
API_ENDPOINT_FLASK = "http://172.17.0.1:8052/covid19/api/v1/predict/heatmap"
API_ENDPOINT_FastAPI = "http://172.17.0.1:8057/covid19/api/v1/predict/heatmap"
def get_it(url):
try:
# 画像をループ
for imagePathTest in imagePathsTest:
b64_image = ""
with open(imagePathTest, "rb") as imageFile:
b64_image = base64.b64encode(imageFile.read())
data = {'b64': b64_image}
r = requests.post(url, data=data)
#print(imagePathTest, r.status_code, r.text)
return r
except socket.timeout:
# 実際のケースではおそらく
# ソケットがタイムアウトする場合に何かを行うでしょう
pass
urls = [API_ENDPOINT_LB, API_ENDPOINT_LB,
API_ENDPOINT_LB, API_ENDPOINT_LB,
API_ENDPOINT_LB, API_ENDPOINT_LB,
API_ENDPOINT_LB, API_ENDPOINT_LB]
with PoolExecutor(max_workers=16) as executor:
for _ in executor.map(get_it, urls):
pass
print("--- %s seconds ---" % (time.time() - start))
したがって、8x27 = 216個のテスト画像を処理するのに74秒かかっています。 これは負荷分散されたデモスタックが、(分類とヒートマップの結果をクライアントに返すことで)1秒間に3個の画像を処理できています。
--- 74.37691688537598 seconds ---
PuttyセッションのTopコマンドから、上記のベンチマークスクリプトが実行開始されるとすぐに8個のサーバープロセス(4個のGunicornと4個のUvicorn/Python)がランプアップし始めたことがわかります。
## 今後の内容
この記事は、テストフレームワークとして「全DockerによるAIデモ」のデプロイメントスタックをまとめるための出発点に過ぎません。 次は、Covid-19 ICU入室予測インターフェースなどさらに多くのAPIデモインターフェースを理想としてはFHIR R4などによって追加し、サポートDICOM入力形式を追加したいと思います。 これは、IRISがホストするML機能とのより緊密な統合を検討するためのテストベンチになる可能性もあります。 医用画像、公衆衛生、またはパーソナル化された予測やNLPなど、さまざまなAIフロントを見ていく過程で、徐々に、より多くのMLまたはDL特殊モデルを傍受するためのテストフレームワーク(非常に単純なテストフレーム)として使用していけるでしょう。 ウィッシュリストは、[前の投稿(「今後の内容」セクション)](https://jp.community.intersystems.com/node/507006)の最後にも掲載しています。
記事
Tomoko Furuzono · 2023年4月11日
これは、InterSystems FAQサイトの記事です。データの登録/更新/削除を実行中でも、インデックスを再構築することは可能です。ただし、再構築中は更新途中の状態で参照されますので、専用ユーティリティを使用することをお勧めします。手順は以下の通りです。
追加予定のインデックス名をクエリオプティマイザから隠します。
インデックス定義を追加し、再構築を実施します。
再構築が完了したら、追加したインデックスをオプティマイザに公開します。
実行例は以下の通りです。Sample.Person の Home_State(連絡先住所の州情報)カラムに対して標準インデックス HomeStateIdx を定義する目的での例で記載します。
1、追加予定のインデックス名を Caché のクエリオプティマイザから隠します。
>write $system.SQL.SetMapSelectability("Sample.Person","HomeStateIdx",0)1
2、インデックス定義を追加した後、再構築を実施します。 定義例)Index HomeStateIdx On Home.State;
>do ##class(Sample.Person).%BuildIndices($LB("HomeStateIdx"))
3、再構築が完了したら、追加したインデックスをオプティマイザに公開します
>write $system.SQL.SetMapSelectability("Sample.Person","HomeStateIdx",1)1
インデックスが使用されたか/されないか、の確認はクエリプランを参照します。以下の例では、ターミナルを $system.SQL.Shell() でSQL実行環境に切り替えた状態でのプラン確認結果を表示しています(管理ポータルで参照する場合は、クエリ実行画面でSQL実行後「プラン表示」ボタンを押下します)。
SAMPLES>do $system.SQL.Shell()SQL Command Line Shell----------------------------------------------------The command prefix is currently set to: <>.Enter q to quit, ? for help.SAMPLES>>select ID,Name from Sample.Person where Home_State='NY'1. select ID,Name from Sample.Person where Home_State='NY'ID Name61 Alton,Debby O.138 Isaksen,Charlotte L.175 Walker,Emily O.3 Rows(s) Affectedstatement prepare time(s)/globals/lines/disk: 0.0026s/35/974/0ms execute time(s)/globals/lines/disk: 0.0017s/216/2447/0ms cached query class: %sqlcq.SAMPLES.cls1---------------------------------------------------------------------------SAMPLES>>show plan // ★ インデックス未使用時のプラン表示 DECLARE QRS CURSOR FOR SELECT ID , Name FROM Sample . Person WHERE Home_State = ?Read master map Sample.Person.IDKEY, looping on ID.For each row: Output the row.SAMPLES>>show plan // ★ インデックス使用時のプラン表示 DECLARE QRS CURSOR FOR SELECT ID , Name FROM Sample . Person WHERE Home_State = ?Read index map Sample.Person.HomeStateIdx, using the given %SQLUPPER(Home_State), and looping on ID.For each row: Read master map Sample.Person.IDKEY, using the given idkey value. Output the row.SAMPLES>>
詳細は、以下ドキュメントをご参照ください。READ および WRITE アクティブシステム上でのインデックスの構築について【IRIS】READ および WRITE アクティブシステム上でのインデックスの構築についてまた、下記の関連トピックもご確認ください。アプリケーション使用中にインデックス再構築を複数プロセスで実行する方法クエリをチューニングする方法
記事
Megumi Kakechi · 2022年3月23日
これは、InterSystems FAQサイトの記事です。ジャーナル・ファイルの処理でジャーナルファイルに記録されるタイプが、それぞれどのような状況下で記録されるのかについて説明します。
処理
(管理ポータルの)タイプ
説明
具体的にどのような処理で記録?
JRNSET
SET
ローカルノードを設定
Set コマンドによりグローバルを更新した場合
JRNMIRSET
MirrorSET
ミラーノードを設定
ミラー環境にてSet コマンドによりグローバルを更新した場合
JRNBITSET
BitSET
ノード内の指定されたビット位置を設定
$Bit関数によりグローバルを更新した場合
JRNKILL
KILL
ローカルノードを削除
Kill コマンドによりグローバルを更新した場合
JRNKILLDES
KILLdes
下位ノードを削除(※1)
トランザクション中に従属ノードが存在するグローバルノードを削除した場合
JRNMIRKILL
MirrorKILL
ミラーノードを削除
ミラー環境にてKill コマンドによりグローバルを更新した場合
JRNZKILL
ZKILL
従属ノードを削除せずにローカルノードを削除
ZKill コマンドによりグローバルを更新した場合
JRNNSET
現在使用されていません
JRNNKILL
現在使用されていません
JRNNZKILL
現在使用されていません
JRNMIRSET
内部ミラー処理
ミラーリングのシステムグローバルに対する内部的な更新
JRNMIRKILL
内部ミラー処理
ミラーリングのシステムグローバルに対する内部的な更新
※1:JRNKILLDESの例
USER>zw ^test^test(1)=1^test(1,1)=1 USER>ts TL1:USER>k ^test(1)
ジャーナルレコード:
以下のタイプはデータベースへの更新は行いません。
処理
(管理ポータルの)タイプ
説明
JRNBEGTRANS
BeginTrans
トランザクションを開始
JRNTBEGINLEVEL
BeginTrans with level
トランザクション・レベルを開始
JRNCOMMIT
CommitTrans
トランザクションをコミット
JRNTCOMMITLEVEL
CommitTrans with level
分離されたトランザクション・レベルをコミット
JRNTCOMMITPENDLEVEL
CommitTrans Pending with level
保留中のトランザクション・レベルをコミット
JRNMARK
Marker
ジャーナル・マーカ
JRNBIGNETECP
netsyn
ECPネットワーキング
JRNTROLEVEL
Rollback
トランザクションをロールバック
あわせて、以下の関連記事も是非ご覧ください。
ジャーナルファイルを削除する方法
ジャーナルファイルが長時間消されずに残ってしまう原因
コマンドでジャーナルファイルにある特定のグローバル変数を検索する方法
誤って削除したグローバルを復旧させる方法
ジャーナルファイルの内容を管理ポータル以外で参照する方法
ジャーナルファイルの使用量をチェックする方法
記事
Megumi Kakechi · 2023年3月28日
これは InterSystems FAQ サイトの記事です。
テーブル名/カラム名/インデックス名を変更したい場合、以下のケース別に変更方法をご案内します。
A. テーブル名・カラム名の変更B. インデックス名の変更
-------------------------------------------------------------------------A. テーブル名・カラム名の変更する方法-------------------------------------------------------------------------
テーブル(クラス)名とカラム(プロパティ)名は基本的には変えないようにしてください。
もし「SQLアクセス時の名前だけ変更したい」場合は、以下のように新しい名前を SqlTableName(テーブル名)、SqlFieldName(カラム名) として指定することができます。
Class User.test Extends %Persistent [ SqlTableName = test2 ] {
Property p1 As %Integer [ SqlFieldName = xx ];
....
以後 "SELECT xx from test2" としてアクセス可能になります。こちらの方法の場合は、スタジオで定義を記述し、再コンパイルすると即座に反映されます。
どうしてもクラス名を変更したい場合は以下の(1)、プロパティ名を変更したい場合は以下の(2)が必要となります。
(1) クラス名変更はできないため、新規クラス作成し、定義を丸ごとコピーする必要があります。 コピーには、スタジオの「ツール > クラスをコピー」を使用できます。 ストレージ定義やクラス名のインスタンスもすべてコピーする場合は、以下のようにチェックを入れます。
※元のクラスは、新規クラスをコンパイルする前にコマンドで削除してください。 以下の実行例を参考にしてください。
実行例:
USER>do $SYSTEM.OBJ.Delete("User.Test")
クラスを削除中 User.Test
USER>write ##class(%ExtentMgr.Util).DeleteExtentDefinition("User.Test","cls")
1
(2) プロパティ名変更は、スタジオで定義を変更するだけです。 ただしグローバルのストレージ場所が変わらないように、手動でストレージ情報を編集する必要があります。
【注意】クラス名やプロパティ名を変える場合、手順を間違えると 【ご参考】にある関連トピックのような問題が発生します。十分に注意した上で行うようにしてください。
-----------------------------------------------------B. インデックス名の変更-----------------------------------------------------
インデックス名の変更については、以下の手順になります。旧インデックスを削除 → スタジオでインデックス名を変更 → 新インデックス再構築
【例】Index a1 を Index b1 に変更する場合
(1) インデックスa1データ削除
do ##class(User.test).%PurgeIndices($LB("a1"))
(2) スタジオでインデックス名を変更し、コンパイル
(3) インデックス b1データ再構築
do ##class(User.test).%BuildIndices($LB("b1"))
【ご参考】クラス定義でプロパティ名を変更するとそれまで参照できていたデータが参照できなくなる/参照時にエラーが発生する場合の対処方法
記事
Megumi Kakechi · 2023年4月3日
これは InterSystems FAQ サイトの記事です。
データ取込み処理の性能・エラー(Lock Table Full)対策として、一般メモリヒープ(gmheap)や ロックテーブルサイズ(locksiz)のパラメータチューニングを行う場合があると思います。
実際に、現在どのくらいの一般メモリヒープが確保できているのかは、ターミナルと管理ポータルで確認することができます。
★ターミナルの場合
// 一般メモリヒープサマリ
USER>w $system.Config.SharedMemoryHeap.GetUsageSummary()
4992226,6029312,59441152
一般メモリヒープサマリは、使用量,アロケート量,構成量(bytes) で戻り値が表示されます。
使用量は、アロケートされたロックテーブルやプロセステーブルなどで実際に使用されている量になります。アロケート量は、gmheapの領域でロックテーブルやプロセステーブルなどでアロケートされている量になります。構成量は、gmheap(KB) +IRISシステム追加領域 で、これが現在の最大利用可能な量(実際の一般メモリヒープの領域の値)になります。
上で述べたように、構成量は構成パラメータの gmheap の単体の値と一致していません。これは、IRISが自動で 構成パラメータ gmheap に内部で使用するメモリ領域分を付加して、一般メモリヒープの領域を構成しているためになります。詳細は以下のドキュメントをご覧ください。
gmheapについて
以下のコマンドでは、ロックテーブル使用量を取得できます。使用可能量, ユーザ使用可能量, 使用量(bytes) で戻り値が表示されます。詳細はこちらの記事をご覧ください。
%SYS>w ##class(SYS.Lock).GetLockSpaceInfo()
16772624,16764624,4592
★管理ポータルの場合
システムオペレーション > システム使用 > 共有メモリヒープ使用状況 より確認できます。
一般メモリヒープ全体については、 "Total SMH Pages Used"の項目の"割り当てられたSMH/ST"が、アロケート量(bytes) を示します。
ロックテーブルについては "Lock Table"の項目の"SMH/ST使用中"が、ロックテーブルの使用量(byte) を示します。 ユーザ使用可能量は、locksiz 値からこの値の差分により求める必要があります。
gmheap を変更する場合、IRISインスタンスの再起動を伴います。現在の gmheap 内で設定可能な、locksiz の最大値を求めるには以下のように行います。locksiz のみであれば、再起動なしに変更が可能です。
%SYS>write ##class(SYS.Lock).GetMaxLockTableSize()
16777216
GetMaxLockTableSize() で取得できる値よりも大きな locksiz を指定したい場合は、差分を gmheap に追加して設定する必要があります。
その場合は、IRISインスタンスの再起動後に新しい設定値が反映されます。
記事
Mihoko Iijima · 2024年12月24日
これは InterSystems FAQ サイトの記事です。
イベントログの削除には、Ens.Util.LogクラスのPurge()メソッドを使用します。実行時以下の引数を指定します。
第1引数:削除数(参照渡し)
第2引数:保持日数(デフォルト7)
メッセージの削除には、2種類の方法があります。
1) 2022.1.2以降の導入されたマルチプロセスで削除する方法
Ens.Ens.Util.MessagePurgeクラスのPurge()メソッドを使用します。実行時以下の引数を指定します。
第1引数:削除数(参照渡し)
第2引数:保持日数(デフォルト7)
第3引数:1を指定(Completeではないメッセージの削除を防止するための指定)
第4引数:メッセージボディも一緒に削除する場合は1を指定
第5引数:デフォルトは500(秒)が設定されていますが、大量のメッセージをパージするとクリアされたビットマップの最適化に時間を要して最適化が完了しない場合があるため、大量削除の場合は 10000000000など大きな値を指定します。
2) Ens.MessageHeaderクラスのPurge()メソッドを使用する方法。
実行時以下の引数を指定します。
第1引数:削除数(参照渡し)
第2引数:保持日数(デフォルト7)
第3引数:1を指定(Completeではないメッセージの削除を防止するための指定)
第4引数:メッセージボディも一緒に削除する場合は1を指定
上記パージ用メソッド実行時、ログ削除の内容もジャーナルに記録されますので、Purge()メソッド実行中プロセスのジャーナルファイルへの書き込みを無効にする設定を使用します。
※ジャーナルファイルへの書き込みが無効化されるのは、以下ユーティリティを実行しているプロセスのみのため、システム全体に影響はありません。
※注意※ ミラーリングを使用している環境でミラーデータベースへの更新ではこのジャーナル無効化の影響を受けず、ジャーナルが記録されますのでご注意ください。
以下実行例です。
//使用中プロセスのジャーナルファイルへの書き込み無効化
do DISABLE^%NOJRN
//イベントログを直近7日分を保持して削除
set st=##class(Ens.Util.Log).Purge(.cnt,7,1)
//削除数確認
write cnt,!
//マルチスレッド対応のメッセージヘッダとボディを直近7日分を保持して削除する
set st=##class(Ens.Util.MessagePurge).Purge(.cnt2,7,1,1,10000000000)
//削除数確認
write cnt2,!
//メッセージヘッダとボディを直近7日間分を保持して削除
set st=##class(Ens.MessageHeader).Purge(.cnt3,7,1,1)
//削除数確認
write cnt3,!
//使用中プロセスのジャーナルファイルへの書き込み有効化
do ENABLE^%NOJRN
記事
Toshihiko Minamoto · 2021年10月28日
InterSystems開発者コミュニティにおいて、CachéアプリケーションへのTWAINインターフェースの作成の可能性に関する質問が上がりました。 Webクライアントの撮像装置からサーバーにデータを取得し、そのデータをデータベースに保管する方法について、素晴らしい提案がいくつかなされました。
しかし、こういった提案を実装するには、Webクライアントからデータベースサーバーにデータを転送し、受信データをクラスプロパティ(または質問のケースで言えばテーブルのセル)に格納できなければなりません。 この方法は、TWAINデバイスから受信した撮像データを転送するためだけでなく、ファイルアーカイブや画像共有などの整理といったほかのタスクにも役立つ可能性があります。
そこで、この記事では主に、HTTP POSTコマンドの本体から、raw状態またはJSON構造にラップしてデータを取得するRESTfulサービスを記述する方法を説明することにします。
RESTの基本
具体的な話に入る前に、まずREST全般と、IRISでRESTfulサービスがどのように作成されるかについて簡単に説明しましょう。
Representational state transfer(REST)は、分散ハイパーメディアシステムのためのアーキテクチャスタイルです。 RESTにおける情報の重要な抽象化は、適切な識別子を持ち、JSON、XML、またはサーバーとクライアントの両方が認識するほかの形式で表されるリソースです。
通常、クライアントとサーバー間でのデータの転送にはHTTPが使用されます。 CRUD(作成、読み取り、更新、削除)操作ごとに独自のHTTPメソッド(POST、GET、PUT、DELETE)があり、リソースまたは一連のリソースには独自のURIがあります。
この記事では、POSTメソッドのみを使用して新しい値をデータベースに挿入するため、その制約を知る必要があります。
「[IETF RFC7231 4.3.3 POST](https://tools.ietf.org/html/rfc7231#section-4.3.3) 」の仕様によると、POSTには本文に格納されるデータサイズに関する制限はありません。 しかし、Webサーバーやブラウザでは独自の制限が適用され、通常は1 MBから2 GBとなっています。 たとえば、[Apache](https://httpd.apache.org/docs/2.4/mod/core.html#limitrequestbody)の制限は最大2 GBとなっています。 いずれにせよ、2 GBのファイルを送信する必要がある場合は、アプローチを考え直すことをお勧めします。
IRISにおけるRESTfulサービスの要件
IRISでRESTfulサービスを実装するには、次を行う必要があります。
抽象クラス%CSP.RESTを拡張するクラスブローカーを作成します。 これは逆に、%CSP.Pageを拡張するため、さまざまな便利なメソッド、パラメーター、オブジェクト、特に%requestへのアクセスが可能になります。
ルートを定義するUrlMapを指定します。
オプションとしてUseSessionパラメーターを設定し、各REST呼び出しが独自のWebセッションで実行されるのか、ほかのREST呼び出しで1つのセッションを共有するのかを設定します。
ルートで定義された演算を実行するクラスメソッドを提供します。
CSP Webアプリケーションを定義し、そのセキュリティをWebアプリケーションページ(システム管理 > セキュリティ > アプリケーション > Webアプリケーション)に指定します。Dispatchクラスには、ユーザークラスの名前とNameが格納されています。これはREST呼び出しのURLの最初の部分です。
一般に、大きなデータ(ファイル)のチャンクとメタデータをクライアントからサーバーに送信するには、次のようにいくつかの方法があります。
ファイルとメタデータをBase64-encodeで暗号化し、サーバーとクライアントの両方に暗号化/復号化を行うための処理オーバーヘッドを追加します。
最初にファイルを送信し、クライアントにIDを返します。すると、そのIDを持つメタデータが送信されます。 サーバーはファイルとメタデータをもう一度関連付けます。
最初にメタデータを送信し、クライアントにIDを返します。すると、そのIDのファイルが送信されます。サーバーはファイルとメタデータをもう一度関連付けます。
この第1回目の記事では、基本的に2つ目のアプローチを使用しますが、クライアントへのIDの送信とメタデータ(別のプロパティとして格納するためのファイル名)の追加については、このタスクでは特に意味を持たないため、行いません。 第2回目の記事では、最初のアプローチを使用しますが、私のファイルとメタデータをサーバーに送信する前にJSON構造にパッケージ化します。
RESTfulサービスの実装
では、具体的な内容に入りましょう。 まず、設定しようとしているクラスとプロパティを定義しましょう。
Class RestTransfer.FileDesc Extends %Persistent
{
Property File As %Stream.GlobalBinary;
Property Name As %String;
}
もちろん、通常はファイルに使用するメタデータがほかにもありますが、私たちの目的にはこれで十分です。
次に、クラスブローカーを作成する必要があります。これは、ルートとメソッドを使用して後で拡張します。
Class RestTransfer.Broker Extends %CSP.REST
{
XData UrlMap
{
<Routes>
</Routes>
}
}
そして最後に、前段階のセットアップとして、このアプリケーションをWebアプリケーションのリストに指定する必要があります。
前段階のセットアップが完了したので、RESTクライアント([Advanced REST Client](https://install.advancedrestclient.com/install)を使用します)から受信するファイルをクラスRestTransfer.FileDescのインスタンスのFileプロパティとしてデータベースに格納するメソッドを記述できるようになりました。
では、POSTメソッドの本体にRawデータとして格納されている情報から始めましょう。 まず、新しいルートをUrlMapに追加しましょう。
<Route Url="/file" Method="POST" Call="InsertFileContents"/>
このルートは、サービスがURL/RestTransfer/fileでPOSTコマンドを受信すると、InsertFileContentsクラスメソッドを呼び出すことを指定します。 より簡単に行うために、このメソッドの中にクラスRestTransfer.FileDescの新しいインスタンスを作成して、そのFileプロパティを受信データに設定します。 これにより、ステータスと、成功またはエラーのいずれかを示すJSON形式のメッセージが返されます。 以下はそのクラスメソッドです。
ClassMethod InsertFileContents() As %Status
{
Set result={}
Set st=0
set f = ##class(RestTransfer.FileDesc).%New()
if (f = $$$NULLOREF) {
do result.%Set("Message","Couldn't create an instance of the class")
} else {
set st = f.File.CopyFrom(%request.Content)
If $$$ISOK(st) {
set st = f.%Save()
If $$$ISOK(st) {
do result.%Set("Status","OK")
} else {
do result.%Set("Message",$system.Status.GetOneErrorText(st))
}
} else {
do result.%Set("Message",$system.Status.GetOneErrorText(st))
}
}
write result.%ToJSON()
Quit st
}
まず、クラスRestTransfer.FileDescの新しいインスタンスを作成し、正常に作成されたこととOREFがあることをチェックします。 オブジェクトを作成できなかった場合は、JSON構造を作成します。
{"Message", "Couldn't create an instance of class"}
オブジェクトが作成された場合は、リクエストのコンテンツがプロパティFileにコピーされます。 コピーに成功しなかった場合は、エラーの説明を含むJSON構造を作成します。
{"Message",$system.Status.GetOneErrorText(st)}
コンテンツがコピーされた場合は、オブジェクトを保存し、保存に成功した場合は、JSON {"Status","OK"}を作成します。 そうでない場合、JSONはエラーの説明を返します。
最後に、このJSONをレスポンスに書き込んで、ステータスstを返します。
画像を転送する例を次に示します。
データベースへの保存方法:
このストリームをファイルに保存して、変更されずに転送されたことを確認できます。
set f = ##class(RestTransfer.FileDesc).%OpenId(4)
set s = ##class(%Stream.FileBinary).%New()
set s.Filename = "D:\Downloads\test1.jpg"
do s.CopyFromAndSave(f.File)
テキストファイルでも同じことができます。
これはグローバルでも表示可能です。
また、実行可能ファイルやその他の種類のデータを保存できます。
グローバルでサイズを確認できます。正しいサイズを確認できます。
この部分は正常に動作するようになったので、2番目のアプローチを確認することにしましょう。ファイルのコンテンツとJSON形式で格納されているメタデータ(ファイル名)を取得し、POSTメソッドの本体で転送するアプローチです。
RESTサービスの作成についての詳細は、InterSystemsの[ドキュメント](https://docs.intersystems.com/iris20191j/csp/docbook/Doc.View.cls?KEY=GREST)をご覧ください。
両方のアプローチのサンプルコードは[GitHub](https://github.com/Gra-ach/RESTFileTransfer)と[InterSystems Open Exchange](https://openexchange.intersystems.com/package/RESTFileTransfer)にあります。 いずれかに関連する質問や提案があれば、お気軽にコメント欄に書き込んでください。
記事
Hiroshi Sato · 2020年10月19日
これはInterSystems FAQ サイトの記事です。
2つのステップにて作業します。
クラス定義の移行
クラス定義を別システムへ移行するため、XML形式またはUDL形式(拡張子.cls)のファイルにエクスポートします。
スタジオでのエクスポート手順は以下の通りです。
[ツール] > [エクスポート]
> [追加]ボタンで移行したいクラスを複数選択
> [ローカルファイルにエクスポート]にチェック
> ファイルの種類がXMLであることを確認し、ファイル名を入力し、[OK]
この後、別システム上のスタジオで、エクスポートしたXML、UDLファイルをインポートします。
この手順で、クラス定義は移行できます。
スタジオでのインポート手順は以下の通りです。
[ツール] > [ローカルからインポート]
> 上記手順で出力したXML、UDLファイルを指定します。
データの移行
次に実際のデータを移行します。オブジェクトデータは既定では、以下の命名規則のグローバル変数内に格納されています。データ :^クラス名Dインデックス:^クラス名Iストリーム :^クラス名S例)User.testクラスのデータは以下の3つのグローバルに格納されます。^User.testD, ^User.testI, ^User.testS
これらのうち存在するグローバル変数をすべて、システム管理ポータル(Caché5.0以前では、エクスプローラ)から、エクスポートします。
エクスポート手順は以下の通りです。 【バージョン2011.1~】
管理ポータルを利用する場合、以下メニュからエクスポートを行います。
[システムエクスプローラ] > [グローバル] ([グローバル]をダブルクリックか、移動ボタンを押下)
> 左ペインからネームスペースを選択する> [エクスポート]をクリック> エクスポートしたいグローバルをチェックし、出力ファイル名を指定 【バージョン2010.2以前】
システム管理ポータルを利用する場合、以下メニュからエクスポートを行います。
データ管理→グローバル
→ 左ペインからネームスペースを選択する→ 「エクスポート」をクリック→ エクスポートしたいグローバルをチェックし、出力ファイル名を指定
次に上記ファイルを、別システムにインポートします。
インポート手順は以下の通りです。 【バージョン2011.1~】
管理ポータルを利用する場合、以下メニュからインポートします。
システムエクスプローラ→グローバル (「グローバル」をダブルクリックか、移動ボタンを押下)
→ 左ペインからネームスペースを選択する→ インポートをクリック→ エクスポートしたファイルを指定→ インポートを実行 【バージョン2010.2以前】
システム管理ポータルを利用する場合、以下メニュからインポートします。
[データ管理] > [グローバル]> 左ペインからネームスペースを選択する> インポートをクリック> エクスポートしたファイルを指定> インポートを実行
以上で、データの移行が完了します。
記事
Mihoko Iijima · 2023年3月13日
これは InterSystems FAQ サイトの記事です。
永続クラス定義では、データを格納するグローバル変数名を初回クラスコンパイル時に決定しています。グローバル変数名は、コンパイル後に表示されるストレージ定義(Storage)で確認できます。
例)
Class Training.Person Extends %Persistent{Property Name As %String; Property Email As %String; Storage Default{<Data name="PersonDefaultData"><Value name="1"><Value>%%CLASSNAME</Value></Value><Value name="2"><Value>Name</Value></Value><Value name="3"><Value>Email</Value></Value></Data><DataLocation>^Training.PersonD</DataLocation><DefaultData>PersonDefaultData</DefaultData><ExtentSize>0</ExtentSize><IdLocation>^Training.PersonD</IdLocation><IndexLocation>^Training.PersonI</IndexLocation><StreamLocation>^Training.PersonS</StreamLocation><Type>%Storage.Persistent</Type>}
}
DataLocation:^パッケージ名.クラス名D永続クラスのデータが登録されるグローバル変数です。
IndexLocation:^パッケージ名.クラス名Iインデックスが格納されるグローバル変数です。
StreamLocation:^パッケージ名.クラス名Sストリームプロパティのデータが格納される変数です。
例外として、31文字以上のクラス名を指定した場合、グローバル変数名の文字数制限を超えてしまうため、ネームスペースで一意となる適当なグローバル変数名を使用します。
Class TestPackage.VeryLongLongLongLongName Extends %Persistent{Property Name As %String; Storage Default{<Data name="VeryLongLongLongLongNameDefaultData"><Value name="1"><Value>%%CLASSNAME</Value></Value><Value name="2"><Value>Name</Value></Value></Data><DataLocation>^TestPackage.VeryLongLon92A3D</DataLocation><DefaultData>VeryLongLongLongLongNameDefaultData</DefaultData><IdLocation>^TestPackage.VeryLongLon92A3D</IdLocation><IndexLocation>^TestPackage.VeryLongLon92A3I</IndexLocation><StreamLocation>^TestPackage.VeryLongLon92A3S</StreamLocation><Type>%Storage.Persistent</Type>}}
ストレージ定義未作成の場合、DEFAULTGLOBALパラメータを利用してグローバル変数名を指定することができます。(指定したグローバル変数名の末尾にD、I、Sを付与した名称をストレージに定義します。)
Class TestPackage.VeryLongLongLongLongName Extends %Persistent{Property Name As %String;Parameter DEFAULTGLOBAL = "^Test.LongName";Storage Default{<Data name="VeryLongLongLongLongNameDefaultData"><Value name="1"><Value>%%CLASSNAME</Value></Value><Value name="2"><Value>Name</Value></Value></Data><DataLocation>^Test.LongNameD</DataLocation><DefaultData>VeryLongLongLongLongNameDefaultData</DefaultData><IdLocation>^Test.LongNameD</IdLocation><IndexLocation>^Test.LongNameI</IndexLocation><StreamLocation>^Test.LongNameS</StreamLocation><Type>%Storage.Persistent</Type>}}
詳細は以下ドキュメントもご参照ください。
標準のグローバル名
ユーザ定義のグローバル名
この他、2017.2以降からストレージに定義されるグローバル変数名をハッシュ化したグローバル変数名に変更できるパラメータ:USEREXTENTSETが、パフォーマンス向上のために追加されました。
ストレージ未作成時(クラス定義の初回コンパイル前)に設定することで、 ^EPgS.D8T6.1 のようなハッシュ化したグローバル変数名が設定されます。
Parameter USEEXTENTSET = 1;
USEEXTENTSETパラメータを使用する場合のストレージ定義について詳細は、関連トピックをご参照ください。
関連記事もご参照ください
テーブル定義のデータが格納されるグローバル変数名について
記事
Tomoko Furuzono · 2023年4月10日
これは、InterSystems FAQサイトの記事です。管理ポータル:システムエクスプローラの使用には、%DevelopmentリソースのUse特権が必要です。システムエクスプローラでの参照のみ利用可能とする権限をユーザに付与したい場合は、%DevelopmentリソースのUse特権(※1)と、該当のデータベースリソース(※2)への参照特権(R)を付与したロールを作成し、これをユーザに与えます。※1.「%Development:U」を付与している場合はターミナルやスタジオも参照のみで使用可能となります。※2.参照したいデータベースに割り当てられているリソースが%DB_DEFAULTリソースになっており、このデータベースのみに参照権限を設定したい場合は、事前に、このデータベース用の独自リソース(%DB_<データベース名>)を作成し、該当データベースに割り当てるようにします。
<図:独自リソースの作成>[管理ポータル]>[システム管理]>[構成]>[システム構成]>[ローカルデータベース]>(該当データベースを選択)
【例】:testAユーザに、TESTデータベースへの参照のみを許可する。1.新規ロール作成
2.ロール編集(リソースへの権限の追加)
3.上記で作成したロールをユーザに付与。以上の設定で、testAユーザは、システムエクスプローラでの該当データベースへの参照のみが可能となります。※実際に対象ユーザ(上記testA)が使用する場合は、管理ポータルアクセス後、参照するデータベースに接続できるネームスペースに切り替えた後、システムエクスプローラでの参照を行ってください。
ロールの追加が完了したら、管理ポータルのユーザ定義一覧から該当ユーザのプロファイルを確認し、希望の条件を満たしているか、確認してください。[管理ポータル]>[システム管理]>[セキュリティ]>[ロール]>ユーザ一覧>[プロファイル](一覧の該当ユーザの右端のリンク)
なお、インストール時の初期セキュリティが「最小」の場合、デフォルトでは管理ポータルへはユーザログイン無しでアクセスできます。ユーザログイン出来るようにするためには、管理ポータル用のWebアプリケーションパスの設定として[許可された認証方法]で「パスワード」のみをチェックして、パスワード認証を有効にする必要があります。詳細は、関連トピック「管理ポータル/スタジオ/ターミナルにパスワード認証を設定するにはどうしたらいいですか?」をご参照ください。さらに、SQLでの参照を行いたい場合には、参照したいテーブルへのSQL権限を付与する必要があります。これについての詳細は、関連トピック「SELECTのみを実行できるユーザ作成方法について」をご確認ください。
記事
Megumi Kakechi · 2023年5月30日
これは InterSystems FAQ サイトの記事です。
Apache環境でRESTを動かすための設定方法は以下のとおりです。
1. Webゲートウェイをインストールします
添付(Webゲートウェイインストール手順.pdf)の手順に従い、Webゲートウェイをインストールします。※Webゲートウェイをインストールする前に、Apacheを停止してください。
2. Apache 構成ファイルの設定を行います
/etc/httpd/conf/httpd.conf の末尾に以下を追加します。追加後、Apacheを再起動してください。
<Location /> CSP On SetHandler csp-handler-sa</Location>
※こちらの設定では、Apacheに対するすべてのリクエストをWebゲートウェイに渡す設定になります。 <Location />ではなく、<Location /rest> にすると、/rest のみWebゲートウェイに渡すようになります。 (既に他の目的でApacheを使用している場合、<Location /> の設定にするとそちらが動かなくなりますのでご注意ください)
Apacheの再起動:
# systemctl stop httpd.service // Apache の停止(開始している場合)
# systemctl start httpd.service // Apache の開始
# systemctl status httpd.service // ステータスの確認
3. Webゲートウェイ管理ページに接続できることを確認します
Web Gateway 管理ページ http://localhost/csp/bin/Systems/Module.cxw
4. Webゲートウェイ管理ページで以下の設定を行います
4-1. 接続先IRISサーバの設定
WebGateway の Server Access より、サーバの設定を確認します。※以下はローカルにIRISをインストールしている場合
4-2. アプリケーションアクセスの設定
Web Gateway の Application Access から /rest を追加します。→既存アプリケーションをクリックしてコピーし、アプリケーションパスを /rest に設定 & 4-1.で設定したIRISサーバを指定します。
この構成により、Webゲートウェイは /rest アプリケーションをIRISサーバに転送します。
5. IRISサーバの構成でウェブアプリケーションの設定を行います
IRISサーバの管理ポータル(http://localhost/csp/sys/UtilHome.csp)を開き、
システム構成 > セキュリティ > アプリケーション > ウェブ・アプリケーション
より /rest アプリケーションを追加します。RESTのクラスをディスパッチクラスに指定します(この記事の後方にサンプルコードを載せています)。
この構成により、IRIS は /rest アプリケーションを対象ネームスペースに転送し、対象ディスパッチクラスを呼び出します。
6. Postman や Webブラウザより、GETリクエストを試してみます
以下はローカルにIRISをインストールしている場合です。必要に応じてサーバのIPアドレスに変更してください。 http://localhost/rest/req2 パスワード認証を有効にしている場合、ブラウザからは以下のように実行します。 http://localhost/rest/req2?IRISUserName=<UserName>&IRISPassword=<Password>以下のように、日時が表示されます。
※サンプルコード:
Class User.REST Extends %CSP.REST
{
XData UrlMap
{
<Routes>
<Route Url="/req2" Method="GET" Call="req2"/>
</Routes>
}
ClassMethod req2() As %Status
{
write $ZDT($H)
quit $$$OK
}
}
【ご参考】IISでRESTを動かす場合の設定方法