クリアフィルター
記事
Henrique Dias · 2020年10月8日
npm-iris とは何ですか?
N.P.Mは "No Project Mess "の略です。
N.P.M.は、InterSystems IRISとBootstrap 4を使用したプロジェクト&タスク管理アプリです。
No Project Messは、シンプルで直感的なプロジェクトとタスクの管理ソフトウェアで、開発者や中小企業が日々の複雑な問題を軽減できるように作成されています。 スプレッドシート、カンバン、カレンダー、ガントチャートなど、タスクのためのさまざまなビューを提供しています。
なぜでしょうか?
異なるチームで仕事をしていると、あなたは異なるツールを好む人々の存在に気づくでしょう。
だから、多くの場合、あなたはプロジェクトのためのガントチャート、別のためのカンバン、他の紙の上のリストを使用しているでしょう...
N.P.M.を使うとこういった煩わしさから解放されます。 あなたやあなたのチームがどのような表示を好むかは関係ありません。 表示はクリックだけで変更することが出来ます。
特徴
初期設定
プロジェクト
利用者
タスク : タスクの作成と管理
スケジューラ : タスクのカレンダー表示
カンバン : カンバンスタイルでタスクを管理する
ガント : ガントチャートを使用して、締め切り、マイルストーン、進捗状況を確認できます。
新機能・改善のためのロードマップ
OAuth2認証
プロジェクト/チーム/ユーザー別のセキュリティ
タイムトラッキング
カスタムカレンダー(祝日)
添付ファイルのサポート
AppS.RESTフレームワークを活用
Vue.js版
ホームダッシュボードでtodoリストの進捗を確認することができます。
ここでソフトウェアを試すことができます!!!http://npm-iris.eastus.cloudapp.azure.com:52773/npm/home.csp
あなたがソフトウェアを気に入って、私があなたの投票に値すると思うなら、npm-irisに投票してください! https://openexchange.intersystems.com/contest/current
Henriqueさん、ありがとうございます。
シンプルで見やすいですね!また、ユーザがそれぞれ見やすい画面を選択できるというのも良いと思いました
Toshihikoさん、どうもありがとうございました。
お知らせ
Seisuke Nakahashi · 2025年6月17日
このたび InterSystems IRIS 2025.1 の日本語ドキュメントが完成しました。以下のURLでご参照いただけます。
IRIS 2025.1
https://docs.intersystems.com/iris20251/csp/docbookj/DocBook.UI.Page.cls
IRIS for Health 2025.1
https://docs.intersystems.com/irisforhealth20251/csp/docbookj/DocBook.UI.Page.cls
Health Connect 2025.1
https://docs.intersystems.com/healthconnect20251/csp/docbookj/DocBook.UI.Page.cls
Supply Chain Orchestrator 2025.1
https://docs.intersystems.com/supplychain20251/csp/docbookj/DocBook.UI.Page.cls
IRIS for Windows では、ランチャーの [ドキュメント] をクリックしたときに、好きな日本語ドキュメントを表示させることができます。
ランチャーのドキュメントリンク先は、デフォルトでは英語ドキュメントに飛ぶようになっています。ご希望の日本語ドキュメントを表示させるには、IRISサーバがIISを利用している場合は、IRISサーバ上で以下の(1)(2)を実行し、HTTPリダイレクト機能をインストール&リダイレクトを設定する必要があります。
(1) IIS HTTPリダイレクト機能追加 (まだの場合)
IRISサーバ上のIISに、リダイレクト機能を追加します。[Windows の機能の有効化または無効化]→[インターネット インフォメーション サービス]→[World Wide Web サービス]→[HTTP 共通機能]→[HTTP リダイレクト]→[OK]
(2) 日本語ドキュメントへのリダイレクト設定
IRISサーバ上でコマンドプロンプトを管理者モードで起動し、以下3行を実行してください。これにより、希望の日本語オンラインドキュメントへのリダイレクトが設定されます。
注意※2行目の /path は /<インスタンス名>/csp/docbook になります。以下の例では、インスタンス名=IRIS です。また、 /physicalPath は任意のフォルダで構いませんが、フォルダが存在している必要があります。※3行目の /destination は、表示したいドキュメントの docbookj までを指定します。以下の例では、IRIS for Health にリンクしています。
cd C:\windows\system32\inetsrv
appcmd add app /site.name:"Default Web Site" /path:/iris/csp/docbook /physicalPath:c:\inetpub\docbook
appcmd set config "Default Web Site/iris/csp/docbook" /section:httpRedirect /enabled:true /destination:https://docs.intersystems.com/irisforhealth20251/csp/docbookj
IRISサーバが Apache を利用している場合は、こちら の手順をご覧ください。
なお、過去バージョンを含めた、日本語ドキュメント一覧は こちら からご確認いただけます。ぜひ日本語ドキュメントをご活用いただき、IRIS 製品をより便利にお使いください。
記事
Shintaro Kaminaka · 2021年4月15日
開発者の皆さん、こんにちは。
以前の[記事](https://jp.community.intersystems.com/node/481321)でIRIS for Health上でFHIRリポジトリを構築し、OAuth2認証を構成する方法をご紹介しました。
この代行認証編では、IRIS for HealthのFHIRリポジトリに組み込まれた認証機能ではなく、IRISの代行認証機能+ZAUTHENTICATEルーチンを使用して認証を行う方法をご紹介します。
前回記事でご紹介したように、標準のFHIRリポジトリの認証機構では、アクセストークンの発行先を追加するためのAudienceの指定(aud=https://~) や、アクセストークンだけではなくベーシック認証の情報を送付するなどの対応が必要でした。
スクラッチでFHIRクライアントを開発するのではなく、既成の製品やアプリケーションからアクセスする場合、上記のような処理の実装ができないことがあるかもしれません。
そのような場合には、この代行認証+ZAUTHENTICATEルーチンを使用して、カスタマイズした認証の仕組みを構築することができます。
## この記事に含まれる情報のドキュメントについて
この記事で記載されている情報はIRIS for Healthのドキュメントにも含まれている内容をわかりやすく再構成したものです。
[RESTサービスの保護:RESTアプリケーションおよびOAuth2.0](https://docs.intersystems.com/irisforhealth20201/csp/docbookj/Doc.View.cls?KEY=GREST_securing#GREST_oauth2)
[OAuth 2.0 クライアントとしての InterSystems IRIS Web アプリケーションの使用法](https://docs.intersystems.com/irisforhealth20201/csp/docbookj/DocBook.UI.Page.cls?KEY=GOAUTH_client)
## 代行認証を有効にする
まず使用しているIRIS環境で「代行認証」機能を有効にし、アクセスするFHIRリポジトリの「Webアプリケーション設定」で「代行認証」機能を使える用に構成します。
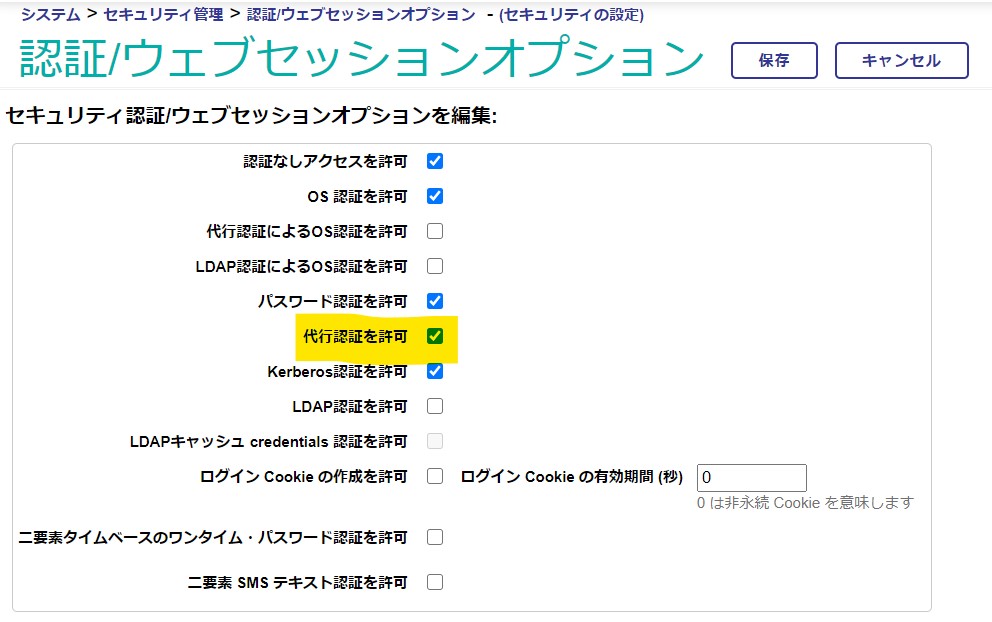
### 認証/ウェブセッションオプション画面
まずシステムとして「代行認証」が使用できるように構成します。
管理ポータルの システム管理→セキュリティ→システム・セキュリティ→認証/ウェブセッションオプション と進み、「代行認証を許可」をチェックします。
「代行認証によるOS認証を許可」ではありませんのでご注意ください。
### %Service_WebGatewayサービス 画面
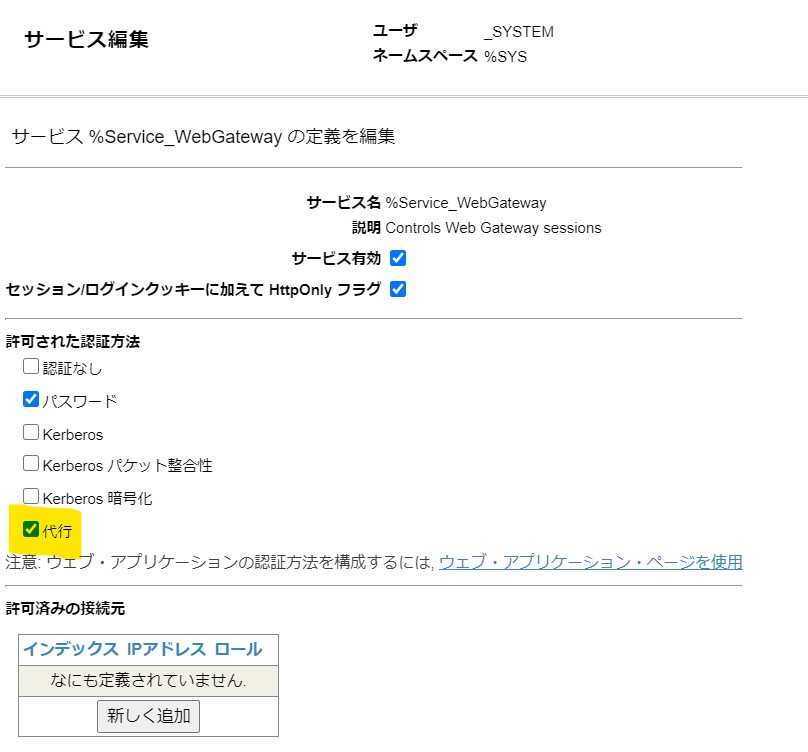
次に、CSPゲートウェイを経由したWebのアクセスに対して、「代行認証」が有効になるよう構成します。
管理ポータルの システム管理→セキュリティ→サービス と進み、「%Service_WebGateway」をクリックして、許可された認証方法の「代行」にチェックがついていることを確認します。もしチェックされていなければ、チェックして保存を実行してください。
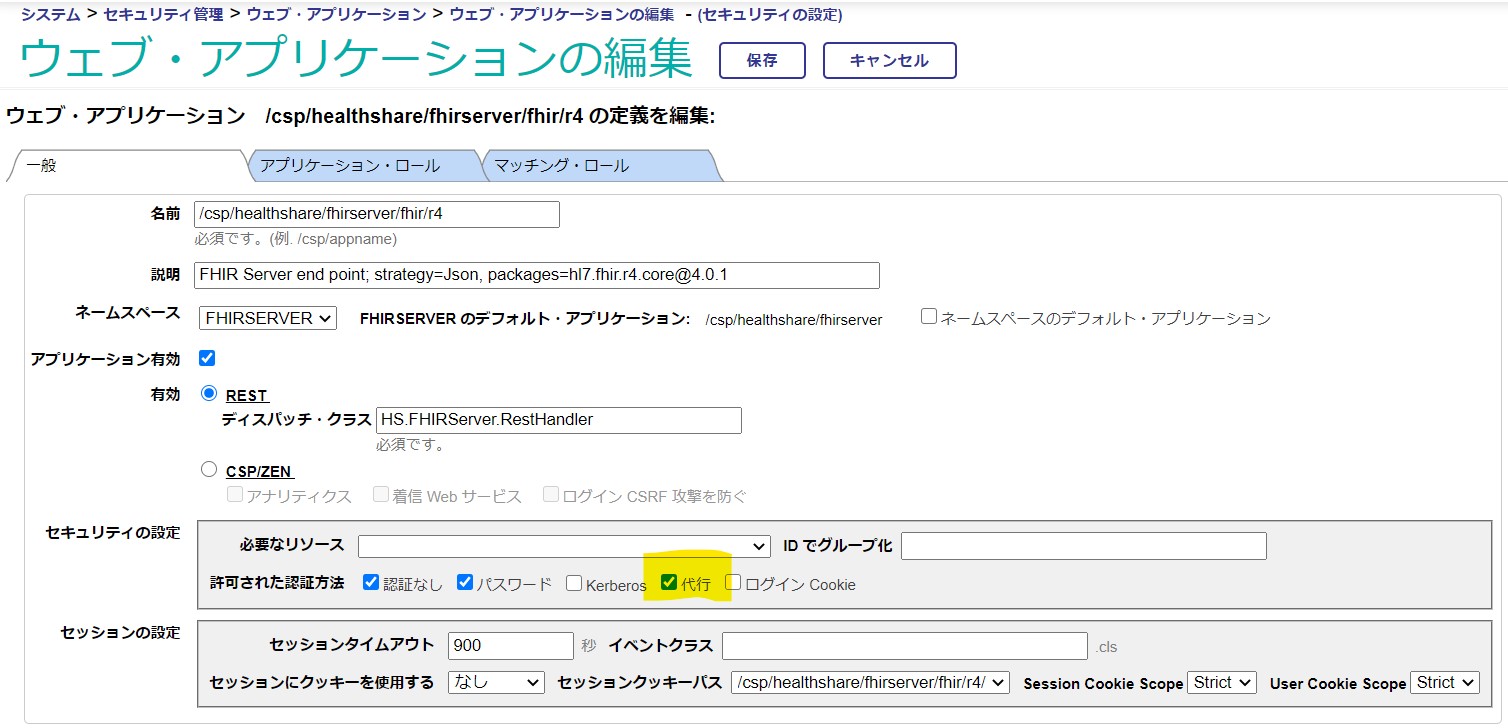
### FHIRリポジトリの ウェブアプリケーションの編集 画面
最後に、アクセスするFHIRリポジトリの ウェブ・アプリケーションの編集画面で「代行認証」を有効にします。
管理ポータルの システム管理→セキュリティ→アプリケーション→ウェブ・アプリケーション と進み、該当のFHIRリポジトリアプリケーションを選択します。
特に変更をしていなければ、/csp/healthshare/\/fhir/r4 となっています。
この画面で、セキュリティの設定:許可された認証方法の「代行」をチェックして保存します。
これで、「代行認証」を利用する準備はOKです。次は、実際に代行認証のためのロジックが記載されたZAUTHENTICATEルーチンを用意します。
## ZAUTHETICATEルーチンの入手とインポート
ZAUTHENTICATEルーチンのサンプルはInterSystemsのGitHubで公開されています。
[GitHub:Samples-Security](https://github.com/intersystems/Samples-Security/)
この記事ではここで紹介されているREST.ZAUTHENTICATE.macルーチンを利用します。
GitHubのREADMEに記載されているこのルーチンの説明をここにも転載します。
* `REST.ZAUTHENTICATE.mac` is another sample routine that demonstrates how to authenticate a REST application using OAuth 2.0. To use this sample:
1. Configure the resource server containing the REST application as an OAuth 2.0 resource server.
2. Copy this routine to the %SYS namespace as ZAUTHENTICATE.mac.
3. Modify value of applicationName in ZAUTHENTICATE.mac.
4. Allow delegated authentication for %Service.CSP.
5. Make sure that the web application for the REST application is using delegated authentication.
この記事では、先に手順の4.,5.を済ませているので、ルーチンのインポートを実施しましょう。
(上記READMEでは、%Service.CSPと記載されていますが、現在は%Service_WebGatewayになっています。)
GitHubからルーチンをダウンロードしてインポートするか、あるいは、この[リンク](https://github.com/intersystems/Samples-Security/blob/master/rtn/REST.ZAUTHENTICATE.mac)から直接ルーチンを表示し、中身をStudioやVS Codeのエディタを使ってコピーしてZAUTHENTICATEルーチンをつくることもできます。**%SYS**ネームスペースに作成します。
(**注意**:2021/4/16時点ではこのルーチンをスタジオからインポートするとエラーが発生してしまいます。お手数ですが、ファイルの中身をコピーしてZAUTHENTICATEルーチンを作成する方法で回避してください。)
ZAUTHENTICATEルーチンを作成したら、applicationNameを変更します。これは前回の記事で記載したOAuth2クライアントアプリケーションの **クライアント構成** 画面で作成した「アプリケーション名」を指定します。
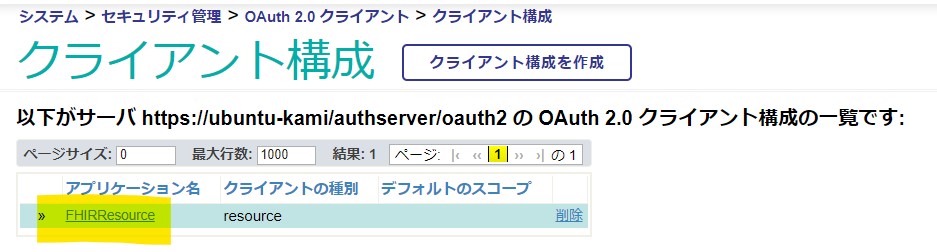
ここでは前回の記事にならい「FHIRResource」としています。コードの一部を紹介します。
```
// Usually you will need to modify at least the roles to be assigned.
set roles="%DB_DEFAULT,%Operator"
$$$SysLog(3,"OAuth2","[ZAUTHENTICATE]","ServiceName="_ServiceName_", Username="_Username_", roles="_roles)
// MUST BE MODIFIED FOR EACH INSTANCE WHICH USES OAuth 2.0 for REST.
// The application name used to define the authorization server to this resource server.
set applicationName="FHIRResource"
set loginSuccessful=0
set errorText=""
```
コードを変更したらコンパイルを実行します。
このZAUTHENTICATEルーチンで重要なのは以下のコード部分です。
GetAccessTokenFromRequestメソッドを使用してHTTPリクエストからアクセストークンを取り出し、ValidateJWTメソッドを使用してValidationを実施し正しいアクセストークンであることを確認しています。
```
// This ZAUTHENTICATE routine will support OAuth 2.0 based
// delegated authentication for subclasses of %CSP.REST.
set accessToken=##class(%SYS.OAuth2.AccessToken).GetAccessTokenFromRequest(.sc)
// Check if authorized.
// if the access token is not a JWT, we would need to validate the access token
// using another means such as the introspection or userinfo endpoint.
if $$$ISOK(sc) {
set valid=##class(%SYS.OAuth2.Validation).ValidateJWT(applicationName,accessToken,,,.jsonObject,,.sc)
}
```
## POSTMANからのテスト
それでは前回同様、RESTクライアントツールのPOSTMANからテストしてみましょう。
前回同様、まずはアクセストークンを取得します。
前回とは異なり、Auth URLにaudパラメータを追加する必要はありません。トークンを取得できたら、「Use Token」ボタンをクリックし、そのトークンを使用できるようにします。
次は、FHIRリポジトリへのアクセスです。今回は前回と異なり、ベーシック認証と組み合わせる必要はありませんので、そのままFHIRリポジトリにアクセスするRESTのURLのみを入力し、実行します。
FHIRリソースが取得できたら成功です。
### 2020.4以降の対応
IRIS for Health 2020.4ではこちらの[記事](https://jp.community.intersystems.com/node/493246)に掲載したように、FHIRリポジトリ上でアクセストークンのスコープ情報がチェックされるようになりました。
このため、セキュリティ用件にも依存しますが、ZAUTHENTICATEルーチンで必ずしもアクセストークンのValidationチェックを行う必要はありません。
これまでこのシリーズで紹介してきましたように、IRIS for HealthがOAuth2認可サーバの役割も兼ねている場合、2020.4上で動かす最も単純な方法は、ZAUTHENTICATEルーチンのGetCredentialsラベルで、アクセストークンを取得する際にも指定したIRISパスワードユーザを返すようにすることです。
例:アクセストークンを取得した際のユーザと
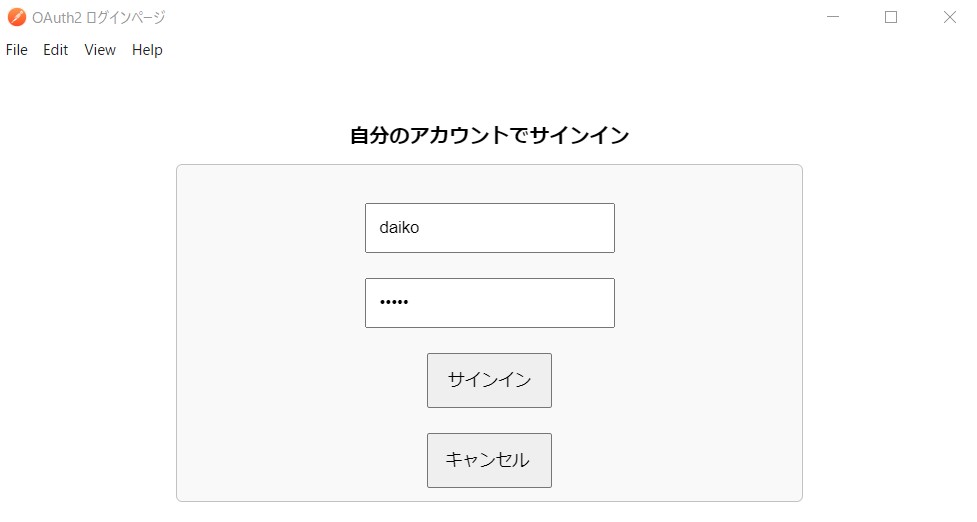
同じユーザを返すようにする。(このdaikoユーザには%All権限を与えています)
```
GetCredentials(ServiceName,Namespace,Username,Password,Credentials) Public {
if ServiceName="%Service_WebGateway" {
// Supply user name and password for authentication via a subclass of %CSP.REST
set Username="daiko"
set Password="xxxxx"
}
quit $$$OK
}
```
こちらの[代行認証に関するドキュメント](https://docs.intersystems.com/irisforhealth20201/csp/docbookj/Doc.View.cls?KEY=GCAS_delegated#GCAS_delegated_zauthgetcreds)に記載があるように、GetCredentialsラベルで実在するIRISパスワードユーザが返された場合はそのユーザに認証が行われるため、ZAUTHENTICATEルーチンで実行されていたアクセストークンのValidationチェックのロジックは実施されなくなります。
ただし、アクセストークンの検証はその後FHIRリポジトリ上で実施されるため不正なアクセストークンでアクセスしたりすることはできません。
なお、2020.4では、スコープのチェックやAudience情報のチェックも行われるため、このバージョンの代行認証では aud=https://~ の情報の追加や適切なスコープ指定も必要になります。
テストとしてはこの方法で動作を確認することができると思いますが、もちろん実際のアプリケーションで実装する場合は、より複雑な状況を考慮に入れる必要があるでしょう。例えば、アクセスするユーザごとに異なるIRISパスワードユーザをもつケースもあれば、そもそもアクセストークンの発行元であOAuth2認可サーバが、IRISではなく他のサービスである可能性もあります。後者のようなケースでは、このZAUTHENTICATEルーチン上で代行ユーザを作成する必要があり、さらにそのユーザ名はアクセストークン内のユーザ情報(sub)と一致する必要があります。
残念ながらこの記事でそれらの状況をすべてカバーすることはできませんが、この記事に記載されている情報がIRIS for HealthのFHIRリポジトリを活用したセキュアなアプリケーション構築の一助となれば幸いです。
記事
Mihoko Iijima · 2020年10月22日
皆さんこんにちは!Virtual Summit ご覧いただけていますでしょうか。
Virtual Summit で VSCode の ObjectScript 用エクステンションバージョン1.0 のリリースが👏正式発表👏されましたので、さっそく利用方法を投稿してみました。
来週の技術セッションではさらに詳しい説明があると思いますので、ご登録がまだの方は、ぜひご登録ください!(ご登録いただくとオンデマンド配信でいつでもセッションのビデオを視聴できます。機械翻訳ではありますがビデオには日本語字幕が付いています。)
この記事では、以下の操作方法をご紹介します。
ObjectScript用エクステンションのインストール方法
サーバへ接続する
クラス定義を作ってみる
ルーチンを作ってみる
デバッグを実行してみる
操作前の準備
VSCodeのインストール を行います。
インストール後、VSCode で作成するクラス定義(*.cls)やルーチン(*.mac や *.inc)用ファイルを配置するためのワークスペース(作業環境)用フォルダを作成します。作成が終わったら VSCode を開き、[File > Open Folder...] から作成したフォルダを選択します。
1、ObjectScript用エクステンションのインストール
エクステンションのアイコン をクリックし「InterSystems」で検索し と をインストールします。
インストールが完了すると のアイコンが左端に表示されます。
2、サーバへ接続する
メニューから File > Preferences > Settings (macOS では Code > Preferences > Settings) を選択して、VS Code Settings Editor を開きます。
検索欄に、objectscript を記入し(下図 赤〇)設定を絞り込み、検索欄すぐ下にある [Workspace] を選択します。
[Objectscript:conn] の下にある [Edit in settings.json] (上図 青〇)をクリックします。
開いたワークスペースのフォルダ以下に [.vscode] フォルダが用意され、settings.json が作成されます。
この settings.json は開いているワークスペースに対するサーバ接続情報の設定ファイルになります。”objectscript.conn”: {} の中に接続したいサーバ情報を記入すると、接続が行えます。設定するパラメータは入力候補が出ます。
図例のイメージで、接続したい IRIS のホスト名(host)、Webサーバポート番号(port)、ネームスペース(ns)、ユーザ名(username)、パスワード(password)を設定し、"active" : true を設定し保存します(Ctrl + s で保存できます)。
記述例は以下の通りです(コピーしてご利用ください)。
{
"objectscript.conn": {
"active": true,
"host":"localhost",
"port": 52773,
"ns":"USER",
"username": "_system",
"password": "SYS"
}
}
接続できると、VSCode左下にある接続状態が、Connected になります。
最新情報を確認する場合は、上図赤枠をクリックしすると、VSCode画面上部中央に以下メニューが表示されます。
メニューの [Refresh Connection] をクリックして最新情報をご確認ください。
この他にも、複数インスタンスへ接続切り替えが簡単に行える、InterSystems Server Manager の機能を利用した記述方法もあります。
前述の方法と異なる点は、settings.json にパスワードを記入しません。
また、”intersystems.servers" に接続するサーバ情報を定義し、"objectscript.conn" の "server" に”intersystems.servers" で定義したサーバ名を指定します。
初回接続時、パスワードを指定するように入力欄(下図赤枠)が表示されます。パスワードを入力すると接続できます。
複数のインスタンスに対して接続情報を登録する場合の settings.json の記述例は以下の通りです。
{
"objectscript.conn": {
"server": "test",
"active": true,
"ns": "USER"
},
"intersystems.servers": {
"test": {
"webServer": {
"scheme": "http",
"host": "localhost",
"port": 52773
},
"username": "_SYSTEM"
},
"hs":{
"webServer": {
"scheme": "http",
"host": "localhost",
"port":52776
},
"username": "_SYSTEM"
}
}
}
サーバ側でパスワードを変更した場合など、VSCode上に登録されたパスワードをクリアするためには、コマンドパレットを利用してクリアできます。
VSCodeのメニューバーから [View > Command Palette...] を選択し、[InterSystems Server Manager: Clear key chain] を選択します。どの接続情報のパスワードをクリアするか表示されるので、接続名を選択してクリアします。
接続完了後、 をクリックすると、サーバ内のクラス/ルーチン/インクルードファイルなどの情報を確認できます。
サーバ情報は読み取り専用の為、VSCode 上で編集したい場合は、ソースコードを右クリックし「Export」を選択します。
Export選択後、ワークスペース > src 以下にソースコードがコピーされます。
※システムコードは上書きしないようにご注意ください。
3、クラス定義を作ってみる
早速、クラス定義を作成し、HelloWorld! の文字列を出力するメソッドを作ります。
をクリックし、ワークスペースに戻ります。
開いたワークスペースに、パッケージ名と同名のフォルダを用意します。例では、Test としています。
定義例)
Class Test.Class1{
ClassMethod Hello(){ write "Hello world! こんにちは!"}
}
[Ctrl + スペース] を押すと以下のような入力候補が出ます。
コードの作成が完了したら、Ctrl + s で保存+コンパイルを行います。(Outputウィンドウを表示しておくとコンパイル結果が確認できます。)
ターミナルを起動し、クラスメソッドの実行を試します。
USER>do ##class(Test.Class1).Hello()Hello world! こんにちは!USER>
メモ:コンテナやLinux上のIRISに対しては、iris session インスタンス名 でIRISにログインできます。
例)
irisowner@0c6e3bc48ff6:~$ iris session IRIS
ノード: 0c6e3bc48ff6 インスタンス: IRIS
USER>
4、ルーチンを作ってみる
ルーチンの作成についての注意事項は、橋本さんに投稿いただいたこちらの記事がとても参考になります。ぜひご参照ください。
ワークスペース以下にルーチン用ファイルを作成します。拡張子は mac とします。
ルーチンでも [Ctrl + スペース] を押すと入力候補が表示されます。
ルーチン実行例は以下の通りです。
USER>do hello^First()こんにちは、ルーチンですUSER>
5、デバッグの実行
クラス定義の場合、以下のようにメソッドの前に [Debug this method] と表示されます。
ObjectScript のコードをデバッグするためには、launch.json ファイルを作成し、デバッグ内容を定義しておく必要があります。
クラス定義の場合、メソッド名の上に [Debug this method] と表示されるので、ここをクリックすると以下の指示が出てきます。
(ルーチン作成の場合は、ワークスペース内に launch.json を作成すれば大丈夫です)
デバッグ用エクステンションのアイコン をクリックしてワークスペースからデバッグ用ウィンドウに切り替えます。
[create a launch.json file.] をクリックすると、以下のように環境選択が表示されるので [ObjectScript Debug] を選択します(以下赤枠)。
launch.json の雛形ファイルが開きます。
name は デバッグ名で、下図の赤枠のように表示されます。
デバッグ対象のコードを program に設定します。
(ルーチンをデバッグする場合は、ワークスペースにある .vscode フォルダの下に launch.json を作成し、program に実行したいルーチンを指定します。)
設定内容例は以下の通りです(コピーしてご利用ください)。
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"type": "objectscript",
"request": "launch",
"name": "Debugテスト",
"program": "##class(Test.Class1).Hello()"
}
]
}
設定が完了したら launch.json を保存し、デバッグを開始します。
記事
Toshihiko Minamoto · 2022年4月21日
この記事では、ObjectScript Package Manager( を参照)を使用して、ユニットテストを実行するためのプロセスを説明します。テストカバレッジ測定( を使用)も含まれます。
## ObjectScript でのユニットテスト
ObjectScript でユニットテストを記述する方法については、素晴らしいドキュメントがすでに存在するため、ここでは繰り返しません。 ユニットテストのチュートリアルは、こちらをご覧ください:
ユニットテストは、「/tests」など、ソースツリーの別の場所に含めるのがベストプラクティスです。 InterSystems 内では、デファクトスタンダードとして、/internal/testing/unit_tests/ を使用しています。テストは社内用/非配布用であり、ユニットテスト以外の種類のテストもあるため、これが意に適うためではありますが、単純なオープンソースプロジェクトでは、多少複雑になるかもしれません。 InterSystems の一部の GitHub リポジトリでは、この構造が使用されています。
ワークフローの観点では、VSCode では非常に簡単に行えます。ディレクトリを作成して、そこにクラスを配置するだけです。 より旧式のサーバー中心型のソース管理アプローチ(Studio で使用されているアプローチ)の場合、このパッケージを適切にマッピングする必要があります。このアプローチは、ソース管理拡張機能ごとに異なります。
ユニットテストクラスの命名規則の観点では、個人的には以下を気に入っています(私の所属するグループにおいてはベストプラクティスです)。
UnitTest.<テストされるパッケージ/クラス>[.<テストされるメソッド/機能>]
たとえば、MyApplication.SomeClass クラスのメソッド Foo のユニットテストであれば、ユニットテストクラスは UnitTest.MyApplication.SomeClass.Foo と名付けられます。一方で、クラス全体のテストであれば、単に UnitTest.MyApplication.SomeClass となります。
## ObjectScript Package Manager でのユニットテスト
ObjectScript Package Manager でユニットテストを認識させるのは簡単です! 以下のように、module.xml に行を 1 つ追加するだけです( から抜粋。Open Exchange の @Peter.Steiwer による優れた数学パッケージのフォークです。これは単純なサンプルとして使用しています)。
``
` ...`
` `
``
上記は次のように解釈します。
* ユニットテストは、モジュールのルート配下にある「tests」ディレクトリにあります。
* ユニットテストは「UnitTest.Math」パッケージにあります。 テストされるクラスは「Math」パッケージに含まれるため、合理的です。
* ユニットテストは、パッケージライフサイクルの「test」フェーズで実行します。 (テストが実行できる「verify」フェーズもありますが、これについては後日お話しします。)
### ユニットテストの実行
上記で説明されたとおりにユニットテストを定義したら、Package Manager でそれを実行するための非常に便利なツールを使用することができます。 %UnitTest.Manager と同じように ^UnitTestRoot などを設定することも可能ですが、特に同じ環境で複数のプロジェクトの作業を行っている場合には、次のオプションを使用する方がはるかに簡単だと思います。
このすべては、上記にリストされている objectscript-math リポジトリのクローンを作成してから `zpm "load /path/to/cloned/repo/"` で読み込むか、「objectscript-math」を自分のパッケージ名(とテスト名)に入れ替えて独自のパッケージで実行することができます。
モジュールを再読み込みしてからすべてのユニットテストを実行する:
`zpm "objectscript-math test"`
ユニットテストのみを実行する(再読み込みなし):
`zpm "objectscript-math test -only"`
ユニットテストのみを実行し(再読み込みなし)、詳細出力を取得する:
`zpm "objectscript-math test -only -verbose"`
再読み込みを行わずに特定のテストスイート(テストのディレクトリ、この場合は UnitTest/Math/Utils のすべてのテスト)のみを実行し、詳細出力を取得する:
`zpm "objectscript-math test -only -verbose -DUnitTest.Suite=UnitTest.Math.Utils"`
再読み込みを行わずに特定のテストケース(この場合は UnitTest.Math.Utils.TestValidateRange)のみを実行し、詳細出力を取得する:
`zpm "objectscript-math test -only -verbose -DUnitTest.Case=UnitTest.Math.Utils.TestValidateRange"`
または、1 つのテストメソッドに存在する問題を解決するだけである場合は、以下のようにします。
`zpm "objectscript-math test -only -verbose -DUnitTest.Case=UnitTest.Math.Utils.TestValidateRange -DUnitTest.Method=TestpValueNull"`
ObjectScript Package Manager を使ったテストカバレッジ測定
ユニットテストがあっても、それがうまく機能するのかを知るにはどうすればよいのでしょうか。 テストカバレッジを測定するだけでは、この疑問に完全に答えることはできませんが、少なくとも役には立ちます。 このことについては、2018 年の Global Summit でお話ししました。https://youtu.be/nUSeGHwN5pc をご覧ください。
最初に行うべきことは、テストカバレッジパッケージをインストールすることです。
`zpm "install testcoverage"`
これには ObjectScript Package Manager によるインストール/実行は不要であることに注意してください。詳しくは、Open Exchange をご覧ください:
とは言っても、ObjectScript Package Manager も使用するのであれば、テストカバレッジツールを最大限に活用することができます。
テストを実行する前に、テストでカバーしたいクラス/ルーチンを指定する必要があります。 非常に大型のコードベース(HealthShare など)においては、プロジェクト内のすべてのファイルに使用するテストカバレッジを測定して収集してしまうと、システムに装備されている以上のメモリが必要となる場合があるため、このステップは重要です。 (具体的には、行単位モニターの gmheap です。)
ファイルのリストは、ユニットテストのルート内の coverage.list というファイルに出力されます。つまり、ユニットテストの別のサブディレクトリ(スイート)にそれぞれのリストが格納されるため、テストスイートが実行する間、追跡されるクラス/ルーチンがオーバーライドされます。
objectscript-math を使った単純な例については、 をご覧ください。[テストツールのユーザーガイド](https://github.com/intersystems/TestCoverage#user-guide)ではさらに詳しく説明されています。
テストカバレッジ測定を有効にしてユニットテストを実行する場合、コマンドにはもう 1 つ引数を追加します。テストを実行するために、%UnitTest.Manager の代わりに TestCoverage.Manager が使用することを指定するのです。
`zpm "objectscript-math test -only -DUnitTest.ManagerClass=TestCoverage.Manager"`
出力には、詳細モードでなくても、ユニットテストでカバーされたクラス/ルーチンの行と一部の集計された統計情報を確認できる URL が含まれます。
## 今後の内容
このすべてのプロセスを CI で自動化してはどうでしょうか。 ユニットテストの結果とカバレッジのスコア/差をレポートするにはどうすればよいでしょうか。 こういったことも、実現可能です! Docker、Travis CI、および codecov.io を使用した簡単な例について、 をご覧ください。将来、いくつかの異なるアプローチを説明する記事を書く予定です。
記事
Mihoko Iijima · 2023年4月4日
開発者の皆さん、こんにちは。
Python Native APIを利用すると、IRISにあるグローバル変数の参照/更新をPythonから行えたり、メソッドやルーチンをPythonから実行することができます。
この記事では「AWS Lambda の IRIS Python Native API IRIS」の記事を参考に、NativeAPIを利用してPythonからIRISに接続するAWS Lambda関数を作成する流れで必要となる、レイヤー作成と関数用コードの作成例をご紹介します。
※ 事前にAWSのEC2インスタンス(Ubuntu 20.04を選択)にIRISをインストールした環境を用意した状態からの例でご紹介します。
「AWS Lambda の IRIS Python Native API IRIS」の記事では、レイヤーとコードをまとめたZipを用意してLambda関数を作成していますがこの記事ではレイヤーとコード用Zipをそれぞれ用意して作成する流れでご紹介します。
NativeAPIについて詳しくは、「【はじめての InterSystems IRIS】セルフラーニングビデオ:アクセス編:Python の NativeAPI に挑戦」をご参照ください。
AWS Lambda関数のレイヤー作成、関数作成の流れは、別の記事:「PyODBC経由でIRISに接続するAWS Lambda関数を作成するまでの流れ」 と同様のため、この記事では詳細な作成手順について割愛しています。詳細な流れは記事をご参照ください。
以下の流れでご紹介します。
Native API レイヤー用Zipの作成
サンプルのクラス定義のインポート
関数の作成とテスト実行
CloudformationのYAML例
例で使用しているコード一式はこちらにあります👉https://github.com/Intersystems-jp/iris-native-lambda
1. Native API レイヤー用Zipの作成
Native API用モジュールのレイヤーを以下の手順で作成します。
レイヤー作成用の任意ディレクトリを用意し、その下に python ディレクトリを用意します。
mkdir python
cd python
wget https://github.com/intersystems/quickstarts-python/raw/master/Solutions/nativeAPI_wheel/irisnative-1.0.0-cp34-abi3-linux_x86_64.whl
unzip irisnative-1.0.0-cp34-abi3-linux_x86_64.whl
cd ..
zip -r9 ../iris_native_lambda.zip *
この流れで作成したZipの例:iris_native_lambda.zip
2.サンプルのクラス定義のインポート
Native APIでは、IRIS内のメソッドやルーチンをPythonから実行できるのでサンプルでは Test.Utils に用意したメソッドを実行しています。
Pythonのサンプルスクリプト:index.pyを試す場合は事前にインポートしてください。
インポートは管理ポータルから、またはVSCodeから、またはUtils.clsをIRISをインストールした環境に転送後、ユーティリティからインポートすることができます。
管理ポータルからインポートする場合
http://IPアドレス:52773/csp/sys/UtilHome.csp にアクセスし、システムエクスプローラ→クラス→ネームスペース:USER→インポートボタン をクリックします。
Utils.clsをファイルに指定してインポートを行ってください。
VSCodeを利用する場合
VSCodeにObjectScriptエクステンションをインストール後、IRISに接続しUtils.cls保存します(Ctrl+S)。
詳細は VSCode を使ってみよう!をご参照ください。
Utils.clsをIRISをインストールした環境に転送後、ユーティリティからインポートする場合
Utils.cls を /usr/irissys/mgr/user ディレクトリに配置した状態での実行例です。
IRISにログインします(USERネームスペースにログインしています)。
iris session IRIS
インポート用ユーティリティを利用してインポートを実施します。
do $system.OBJ.Load("/usr/irissys/mgr/user/Utils.cls","ck")
実行例は以下の通りです。
USER>do $system.OBJ.Load("/usr/irissys/mgr/user/Utils.cls","ck")
Load started on 03/27/2023 09:36:21
Loading file /usr/irissys/mgr/user/Utils.cls as udl
Compiling class Test.Utils
Compiling routine Test.Utils.1
Load finished successfully.
USER>
インポートしたクラス:Test.Utilsには以下のクラスメソッドが用意されています。(全メソッド、JSON文字列を戻り値で返すように作成しています)
メソッド名
内容
Hello()
IRISのバージョンと実行時の日付時刻を戻り値で返します。
CreateDummyTbl()
テスト実行に使用するTest.Personテーブルの作成とサンプルデータ(2レコード)を作成します。
GetPerson()
Test.PersonテーブルのSELECTの結果を返します。
CreateDummyGlo()
Pythonからグローバル変数の操作例に使用するサンプルグローバル ^KION を作成します。
3. 関数の作成とテスト実行
1.Native API レイヤー用Zipの作成 の手順で作成したレイヤー用Zip:iris_native_lambda.zipと、Pythonスクリプトのサンプルコード:index.py と 接続情報を記載するファイル:connection.config をZipにしたファイル:iris_native_code.zipを利用してAWS Lambda関数を作成します。
Lambda 関数作成とテスト実行の流れついては、開発者コミュニティの記事:PyODBC経由でIRISに接続するAWS Lambda関数を作成するまでの流れ:(6) レイヤーの作成以降をご参照ください。
確認:IRISへの接続情報について
サンプルのpythonスクリプト:index.py では、以下いずれかの方法でIRISに接続できるように記述しています。
環境変数を使用する場合
index.pyには、lambda関数作成時に設定する環境変数を利用するように記述しています(19~23行目) 。
なお、環境変数は、Lambda関数登録後、画面で追加/変更できます。
connection.config を使用する
index.py の10行目と12~16行目のコメントを外し19~23行目をコメント化して利用します。接続するIRISの情報に合わせて connection.config を変更してください。
メモ:Lambda関数に設定する環境変数例は以下の通りです。
テスト実行の引数例
※引数に指定するJSONのプロパティに指定が不要な場合は、"none" を設定してください。
TestlUtilsクラスのHello()メソッドを実行する場合の引数例
{
"method": "Hello",
"function":"none",
"args": "none"
}
以下のような戻り値が返ります。
"{\"message\":\"こんにちは!今の時間は:2023年3月27日 10:16:05です\",\"status\":1,\"payload\":\"IRIS for UNIX (Ubuntu Server 20.04 LTS for x86-64) 2022.1.2 (Build 574U) Fri Jan 13 2023 15:03:40 EST\"}"
Test.Personテーブルの作成とダミーデータの登録する場合の引数例
(TestlUtilsクラスのCreateDummyTbl()メソッドを実行する場合)
{
"method": "CreateDummyTbl",
"function":"none",
"args": "none"
}
以下の戻り値が返ります。
"{\"Message\":\"登録完了\"}"
Test.PersonテーブルのSELECTの結果を取得する場合の引数例
(Test.UtilsクラスのGetPetPerson()メソッド実行する場合)
{
"method": "GetPerson",
"function":"none",
"args": "none"
}
以下の戻り値が返ります。
"[{\"Name\":\"山田\",\"Email\":\"taro@mail.com\"},{\"Name\":\"斉藤\",\"Email\":\"saito@mail.com\"}]"
^KIONグローバル変数を設定する例
(Test.UtilsクラスのCreateDummyGlo()メソッドを実行する場合の引数例)
{
"method": "CreateDummyGlo",
"function":"none",
"args": "none"
}
以下の戻り値が返ります。
"{\"Message\":\"登録完了\"}"
index.pyのFunctionを動かす例
(^KION全データ取得する get_globaldata()関数を実行する例)
{
"method":"none",
"function":"getglobal",
"args":"none"
}
以下の戻り値が返ります。
"[[\"久留米\", 14, 19], [\"大阪\", 12, 18], [\"奈良\", 10, 18], [\"愛知\", 13, 15], [\"新潟\", 6, 12], [\"東京\", 14, 19], [\"沖縄\", 21, 26]]"
index.pyのFunctionを動かす例
(^KIONにデータを追加するset_kiondata()関数を実行する場合の引数例)
{
"method":"none",
"function": "setglobal",
"args": {"area":"長野","min":5,"max":10}
}
正しくデータ登録できたかどうかは、get_globaldata()関数を再度実行すると確認できます。
以下、get_globaldata()関数を再実行した場合の戻り値の例です。
"[[\"久留米\", 14, 19], [\"大阪\", 12, 18], [\"奈良\", 10, 18], [\"愛知\", 13, 15], [\"新潟\", 6, 12], [\"東京\", 14, 19], [\"沖縄\", 21, 26], [\"長野\", 5, 10]]"
4. CloudformationのYAML例
例:cloudformation.yml
実行の流れについては、「[PyODBC経由でIRISに接続するAWS Lambda関数を作成するまでの流れ]の」3. 1,2の流れをCloudformationで行う例と同様です。
記事
Hiroshi Sato · 2020年10月5日
ここで紹介するサンプルは、以下のGitHubから入手可能です。
IRIS .Netサンプル
jpegファイルを読んで、IRISデータベースに格納するサンプル
上記GitHub上のinsertbinary\insertbinary\binread.csというファイル名です。
処理内容は、ファイルシステム上のjpeg形式のファイルを読み込んで、BLOB形式でIRISデータベースに格納します。
Caché ではADO.NET Managed Providerを使用して実装していましたが、それをIRISのInterSystems Managed Provider for .NETを使用して書き換えました。(名前が変わっていますが、ADO.NETに関しては、機能はほとんど同じです)
従って、厳密に言うと.Net Native APIを使用していませんが、コネクションオブジェクトの使用方法は共通なので、この部分は、Native APIを使用していると言うこともできます。
Caché での実装は、以下の通りです。
// binread.csusing System;using System.IO;CacheCommand spCache;CacheConnection cnCache;CacheDataAdapter daCache;CacheTransaction txCache=null;DataSet dsCache;DataTable dtCache;DataRow drCache;class BinaryRead { static void Main(string[] args) { //存在するファイルを指定する FileStream fs = new FileStream( @"c:\temp\picture\xxx.jpeg", FileMode.Open, FileAccess.Read) int fileSize = (int)fs.Length; // ファイルのサイズ byte[] buf = new byte[fileSize]; // データ格納用配列 int readSize; // Readメソッドで読み込んだバイト数 int remain = fileSize; // 読み込むべき残りのバイト数 int bufPos = 0; // データ格納用配列内の追加位置 readSize = fs.Read(buf, 0, fs.Length) string cacheConnectString = "Server = localhost;Port=1972;Namespace=User;Password=SYS;User ID = _SYSTEM;"; cnCache = new CacheConnection(cacheConnectString); cnCache.Open(); spCache = new CacheCommand("Insert into MyApp.Person2(Name, Picture) Values(?, ?)", cnCache, txCache); CacheParameter pName = new CacheParameter(); pName.ParameterName = "Name"; pName.CacheDbType = CacheDbType.NVarChar; pName.Direction = ParameterDirection.Input; pName.Value = "Hoge Hoge; CacheParameter pPicture = new CacheParameter(); pDOB.ParameterName = "Picture"; pName.CacheDbType = CacheDbType.LONGVARBINARY; pDOB.Direction = ParameterDirection.Input; pDOB.Value = buf; spCache.ExecuteNonQuery(); fs.Dispose(); cnCache.close(); }}
IRISで書き換えたソースは以下の通りです。
// binread.csusing System;using System.IO;using System.Data;using InterSystems.Data.IRISClient;using InterSystems.Data.IRISClient.ADO;namespace binaryfileread { class binaryfileread { [STAThread] static void Main(string[] args) { IRISCommand spIRIS; IRISConnection cnIRIS; IRISTransaction txIRIS = null; //存在するファイルを指定する FileStream fs = new FileStream( @"c:\temp\test.jpeg", FileMode.Open, FileAccess.Read); int fileSize = (int)fs.Length; // ファイルのサイズ byte[] buf = new byte[fileSize]; // データ格納用配列 long readSize; // Readメソッドで読み込んだバイト数 int remain = fileSize; // 読み込むべき残りのバイト数 readSize = fs.Read(buf, 0, (int)fs.Length); string IRISConnectString = "Server = localhost;Port=1972;Namespace=User;Password=SYS;User ID = _SYSTEM;"; cnIRIS = new IRISConnection(IRISConnectString); cnIRIS.Open(); spIRIS = new IRISCommand("Insert into MyApp.Person2(Name, Picture) Values(?, ?)", cnIRIS, txIRIS); IRISParameter pName = new IRISParameter(); pName.ParameterName = "Name"; pName.IRISDbType = IRISDbType.NVarChar; pName.Direction = ParameterDirection.Input; pName.Value = "Hoge Hoge"; spIRIS.Parameters.Add(pName); IRISParameter pPicture = new IRISParameter(); pPicture.ParameterName = "Picture"; pPicture.IRISDbType = IRISDbType.LongVarBinary; pPicture.Direction = ParameterDirection.Input; pPicture.Value = buf; spIRIS.Parameters.Add(pPicture); spIRIS.ExecuteNonQuery(); fs.Dispose(); cnIRIS.Close(); } }}
CachéとIRISでは、ADO.NETに関しては、関数等の名前がCacheからIRISに変更になっているという違いがあります。
参照の変更
まず以前の参照を削除します。
Visual Studioのソリューションエクスプローラーの所で参照をクリックします。
表示されるInterSystems.Data.CacheClientを削除します。(右クリックして削除を選ぶ)
次にプロジェクトメニューから参照の追加をクリックして、以下の2つのファイルを選択します。(プロジェクトの.Net Frameworkバージョンに合わせて、それに対応するファイルを選択する以下の例は、v4.5を選択)
c:\InterSystems\IRIS\dev\dotnet\bin\v4.5 InterSystems.Data.IRISClient.dll
jpegファイルを読んで、フォーム上にそのjpegファイルの内容を表示するサンプル
上記GitHub上の\VBImage\VBImage\Forms1.vbというファイル名です。
処理内容は、ファイルシステム上のjpeg形式のファイルを読み込んで、VB.NETのフォーム上のPictureオブジェクトとして表示します。
Caché では.NET Managed Providerの.Net Bindingを使用して実装していましたが、それをIRISの.Net Native APIをを使用して書き換えました。
Caché での実装は以下の通りです。
Imports InterSystems.Data.CacheClientImports InterSystems.Data.CacheTypesImports System.DrawingPublic Class Form1 Private Sub Button1_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles Button1.Click Dim cn As CacheConnection cn = New CacheConnection("Server=127.0.0.1;Port=1972;Namespace=User;Username=_system;Password=SYS") cn.Open() Dim img As System.IO.FileStream img = New System.IO.FileStream("C:\temp\test.jpg", System.IO.FileMode.Open, IO.FileAccess.Read) Dim f As User.Fax ' NEW ----------- f = New User.Fax(cn) img.CopyTo(f.pic) f.memo = "abcde" f.Save() f.Dispose() MsgBox("Done!") cn.Close() End Sub Private Sub Button2_Click(sender As System.Object, e As System.EventArgs) Handles Button2.Click Dim cn As CacheConnection cn = New CacheConnection("Server=127.0.0.1;Port=1972;Namespace=User;Username=_system;Password=SYS") cn.Open() Dim f As User.Fax f = User.Fax.OpenId(cn, 1) PictureBox1.Image = Image.FromStream(f.pic) cn.Close() End SubEnd Class
IRISで書き換えたソースです。
Imports InterSystems.Data.IRISClientImports InterSystems.Data.IRISClient.ADOImports System.DrawingImports System.IOPublic Class Form1 Private Sub Button1_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles Button1.Click Dim cn As IRISConnection cn = New IRISConnection("Server=127.0.0.1;Port=1972;Namespace=User;Username=_system;Password=SYS") cn.Open() Dim iris As IRIS Dim irisobject As IRISObject Dim memstream As New MemoryStream Dim str As String Dim buf As Byte() Dim pic As IRISObject iris = IRIS.CreateIRIS(cn) irisobject = iris.ClassMethodObject("User.Fax", "%New") Dim img As System.IO.FileStream img = New System.IO.FileStream("C:\temp\test.jpg", System.IO.FileMode.Open, IO.FileAccess.Read) buf = New Byte(img.Length) {} img.Read(buf, 0, img.Length) str = System.Text.Encoding.GetEncoding("ISO-8859-1").GetString(buf) pic = irisobject.GetObject("pic") pic.InvokeVoid("Write", str) irisobject.InvokeIRISStatusCode("%Save") 'Dim f As User.Fax ' NEW ----------- 'f = New User.Fax(cn) 'img.CopyTo(f.pic) 'f.memo = "abcde" 'f.Save() 'f.Dispose() MsgBox("Done!") cn.Close() End Sub Private Sub Button2_Click(sender As System.Object, e As System.EventArgs) Handles Button2.Click Dim cn As IRISConnection Dim iris As IRIS Dim irisobject As IRISObject Dim pic As IRISObject Dim memorystream As New MemoryStream Dim buf As Byte() Dim str As String Dim len As Long cn = New IRISConnection("Server=127.0.0.1;Port=1972;Namespace=User;Username=_system;Password=SYS") cn.Open() iris = IRIS.CreateIRIS(cn) irisobject = iris.ClassMethodObject("User.Fax", "%OpenId", 1) pic = irisobject.GetObject("pic") len = pic.InvokeLong("SizeGet") str = pic.InvokeString("Read", len) buf = System.Text.Encoding.GetEncoding("ISO-8859-1").GetBytes(str) memorystream.Write(buf, 0, len) PictureBox1.Image = Image.FromStream(MemoryStream) cn.Close() End SubEnd Class
良くコードを見るとわかりますが、IRIS版のほうが処理がかなり長くなっています。
結論を言うとこのケースはIRIS .Net Native APIを使用して書き換えるのは得策ではありません。ADO.NETを使用したほうが簡単に処理できます。
上記GitHub上の\VBImageADO配下にADO.NETで書き換えたサンプルも用意しましたので、ご参考下さい。
記事
Toshihiko Minamoto · 2021年3月17日
この記事では、従来のIRISミラーリング構成の代わりに、Kubernetesの Deploymentと分散永続ストレージを使って高可用性IRIS構成を構築します。 このデプロイでは、ノード、ストレージ、アベイラビリティーゾーンといったインフラストラクチャ関連の障害に耐えることが可能です。 以下に説明する方法を使用することで、RTOがわずかに延長されますが、デプロイの複雑さが大幅に軽減されます。図1 - 従来のミラーリング構成と分散ストレージを使ったKubernetesの比較
この記事に記載されているすべてのソースコードは、https://github.com/antonum/ha-iris-k8s より入手できます。要約
3ノードクラスタを実行しており、Kubernetesにいくらか詳しい方は、このまま以下のコードを使用してください。
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml
kubectl apply -f https://github.com/antonum/ha-iris-k8s/raw/main/tldr.yaml
上記の2行の意味がよくわからない方、またはこれらを実行できるシステムがない場合は、「高可用性要件」のセクションにお進みください。 説明しながら進めていきます。
最初の行は、Longhornというオープンソースの分散Kubernetesストレージをインストールしています。 2行目は、DurableSYS用にLonghornベースのボリュームを使って、InterSystems IRISデプロイをインストールしています。
すべてのポッドが実行状態になるまで待ちます。 kubectl get pods -A
上記の手順を済ませると、http://<IRIS Service Public IP>:52773/csp/sys/%25CSP.Portal.Home.zenにあるIRIS管理ポータル(デフォルトのパスワードは「SYS」)にアクセスできるようになります。また、次のようにしてIRISコマンドラインも使用できるようになります。
kubectl exec -it iris-podName-xxxx -- iris session iris
障害をシミュレートする
では、実際に操作してみましょう。 ただし、操作の前に、データベースにデータを追加して、IRISがオンラインになったときに存在することを確認してください。
kubectl exec -it iris-6d8896d584-8lzn5 -- iris session iris
USER>set ^k8stest($i(^k8stest))=$zdt($h)_" running on "_$system.INetInfo.LocalHostName()
USER>zw ^k8stest
^k8stest=1
^k8stest(1)="01/14/2021 14:13:19 running on iris-6d8896d584-8lzn5"
ここからが「カオスエンジニアリング」の始まりです。
# IRISを停止 - コンテナは自動的に再開します
kubectl exec -it iris-6d8896d584-8lzn5 -- iris stop iris quietly
# ポッドを削除 - ポッドが再作成されます
kubectl delete pod iris-6d8896d584-8lzn5
# irisポッドの配信によりノードを「強制ドレイン」 - ポッドは別のノードで再作成されます
kubectl drain aks-agentpool-29845772-vmss000001 --delete-local-data --ignore-daemonsets --force
# ノードを削除 - ポッドは別のノードで再作成されます
# ただし、kubectlでは削除できないので、 そのインスタンスまたはVMを見つけて、強制終了します。
マシンにアクセスできる場合は、電源を切るかネットワークケーブルを外します。 冗談ではありません!
高可用性要件
以下の障害に耐えられるシステムを構築しています。
コンテナ/VM内のIRISインスタンス。 IRIS - レベル障害
ポッド/コンテナの障害
個々のクラスタノードの一時的な使用不能。 アベイラビリティーゾーンが一時的にオフラインになる場合などが挙げられます。
個々のクラスタノードまたはディスクの永久的障害。
基本的に、「障害をシミュレートする」セクションで試したシナリオです。
上記のいずれかの障害が発生すると、システムは人間が手をいれなくてもオンラインになり、データも失われません。 データの永続性が保証する範囲には一応制限がありますが、 ジャーナルサイクルとアプリケーション内のトランザクションの使用状況に応じて、IRISで実現されます(https://docs.intersystems.com/irisforhealthlatestj/csp/docbook/Doc.View.cls?KEY=GCDI_journal#GCDI_journal_writecycle)。いずれにしても、RPO(目標復旧ポイント)は2秒未満です。
システムの他のコンポーネント(Kubernetes APIサービス、etcdデータベース、ロードバランサーサービス、DNSなど)はスコープ外であり、通常、Azure AKSやAWS EKSなどのマネージドKubernetesサービスで管理されます。
別の言い方をすれば、個別の計算コンポーネントやストレージコンポーネントの障害はユーザーが処理するものであり、その他のコンポーネントの障害はインフラストラクチャ/クラウドプロバイダーが対処するものと言えます。
アーキテクチャ
InterSystems IRISの高可用性について言えば、これまでミラーリングの使用が勧められてきました。 ミラーリングでは、データは、常時オンライン状態にある2つのIRISインスタンスが同期的に複製されます。 各ノードにはデータベースの完全なコピーが維持され、プライマリノードがオフラインになると、ユーザーはバックアップノードに接続し直すことができます。 基本的に、ミラーリング手法では、計算とストレージの両方の冗長性は、IRISが管理するものです。
ミラーをさまざまなアベイラビリティーゾーンにデプロイしたミラーリングにより、計算処理とストレージの障害に備えた必要な冗長性を実現し、わずか数秒という優れたRTO(目標復旧時間または障害後にシステムがオンラインに復旧するまでにかかる時間)を達成することができます。 AWSクラウドでミラーリングされたIRISのデプロイテンプレートは、https://jp.community.intersystems.com/node/486206から入手できます。
一方で、ミラーリングには、設定やバックアップ/復旧手順が複雑で、セキュリティ設定とローカルのデータベース以外のファイルの複製機能が不足しているという欠点があります。
コンテナオーケストレータ―にはKubernetesなど(今や2021年。ほかにオーケストレーターってありますか?!)がありますが、これらは、障害時に、Deploymentオブジェクトが障害のあるIRISポッド/コンテナを自動的に再起動することで、計算冗長性を実現しています。 Kubernetesアーキテクチャ図に、実行中のIRISノードが1つしかないのはこのためです。 2つ目のIRISノードを常時実行し続ける代わりに、計算可用性をKubernetesにアウトソースしています。 Kubernetesは、元のIRISポッドが何らかの理由でエラーとなった場合に、IRISポッドの再作成を確保します。
図2 フェイルオーバーのシナリオ
ここまでよろしいでしょうか。 IRISノードに障害が発生すると、Kubernetesは単に新しいノードを作成します。 クラスタによって異なりますが、計算障害が発生してからIRISがオンラインになるまでには、10~90秒かかります。 ミラーリングではわずか2秒で復旧されるわけですから、これはダウングレードとなりますが、万が一サービス停止となった場合に許容できる範囲であれば、複雑さが緩和されることは大きなメリットと言えます。 ミラーリングの構成は不要です。 セキュリティ設定やファイル複製を気にする必要もありません。
率直に言うと、KubernetesでIRISを実行し、コンテナにログインしても、高可用性環境で実行していることには気づくこともないでしょう。 単一インスタンスのIRISデプロイと全く同じように見え、何ら感触にも変化はありません。
では、ストレージはどうでしょうか。 データベースを扱っているわけですから気になります。 どのようなフェイルオーバーのシナリオであっても、システムはデータの永続性も処理する必要があります。 ミラーリングは、IRISノードのローカルである計算ノードに依存しているため、 ノードが停止するか、一時的に使用不可になってしまえば、そのノードのストレージも停止してしまいます。 ミラーリング構成では、IRISがIRISレベルでデータベースを複製するのはこれに対処するためです。
コンテナの再起動時に元の状態を維持したデータベースを使用できるだけでなく、ノードやネットワークのセグメント全体(アベイラビリティーゾーン)が停止するといったイベントに備えて、冗長性を提供できるストレージが必要です。 ほんの数年前、これを解決できる簡単な答えは存在しませんでした。 上の図から推測できるように、今ではその答えを得ています。 分散コンテナストレージです。
分散ストレージは、基盤のホストボリュームを抽象化し、k8sクラスタのすべてのノードが使用できる共同の1つのクラスターとして提示します。 この記事では、インストールが非常に簡単なLonghorn(https://longhorn.io)という無料のオープンソースのストレージを使用しますが、 OpenEBS、Porworx、StorageOSといったほかのストレージも利用できます。同じ機能が提供されています。 CNCF IncubatingプロジェクトであるRook Cephも検討する価値があるでしょう。 この種のハイエンドとしては、NetAppやPureStorageといったエンタープライズ級のストレージソリューションがあります。
手順
「要約」セクションでは、1回にすべてをインストールしました。 インストールと検証の手順の説明は、付録Bをご覧ください。
Kubernetesストレージ
まずは、コンテナとストレージ全般について、またIRISがどこに適合するのかについて説明しましょう。
デフォルトでは、コンテナ内のすべてのデータは揮発性であるため、 コンテナが停止すればデータは消失します。 Dockerでは、ボリュームの概念を使用することができるため、 基本的に、ホストOSのディレクトリをコンテナに公開することができます。
docker run --detach
--publish 52773:52773
--volume /data/dur:/dur
--env ISC_DATA_DIRECTORY=/dur/iconfig
--name iris21 --init intersystems/iris:2020.3.0.221.0
上記の例では、IRISコンテナを起動し、host-localの「/data/dur」ディレクトリを、「/dur」マウントポイントのコンテナからアクセスできるようにしています。 つまり、コンテナがこのディレクトリに何かを格納している場合、それは保持され、コンテナの次回起動時に使用できるようになります。
IRIS側では、ISC_DATA_DIRECTORYを指定することで、IRISに、コンテナの再起動時に損失してはいけないすべてのデータを特定のディレクトリに格納するように指示することができます。 ドキュメントの「Durable SYS」というIRISの機能をご覧ください( https://docs.intersystems.com/irisforhealthlatestj/csp/docbook/Doc.View.cls?KEY=ADOCK#ADOCK_iris_durable_running)。
Kubernetesでの構文は異なりますが、概念は同じです。
IRISの基本的なKubernetes Deploymentは以下のようになります。
apiVersion: apps/v1
kind: Deployment
metadata:
name: iris
spec:
selector:
matchLabels:
app: iris
strategy:
type: Recreate
replicas: 1
template:
metadata:
labels:
app: iris
spec:
containers:
- image: store/intersystems/iris-community:2020.4.0.524.0
name: iris
env:
- name: ISC_DATA_DIRECTORY
value: /external/iris
ports:
- containerPort: 52773
name: smp-http
volumeMounts:
- name: iris-external-sys
mountPath: /external
volumes:
- name: iris-external-sys
persistentVolumeClaim:
claimName: iris-pvc
上記のデプロイ仕様では、「volumes」の部分にストレージボリュームがリストされています。 このボリュームには、「iris-pvc」などのpersistentVolumeClaimを介して、コンテナの外部からアクセスできます。 volumeMountsは、このボリュームをコンテナ内に公開します。 「iris-external-sys」は、ボリュームマウントを特定のボリュームに関連付ける識別子です。 実際には複数のボリュームが存在する可能性があり、ほかのボリュームと区別するためにこの名前が使用されるわけですから、 「steve」と名付けることも可能です。
すでにお馴染みのISC_DATA_DIRECTORYは、IRISが特定のマウントポイントを使用して、コンテナの再起動後も存続する必要のあるすべてのデータを格納するように指示する環境変数です。
では、persistentVolumeClaimのiris-pvcを見てみましょう。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: iris-pvc
spec:
storageClassName: longhorn
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
かなりわかりやすいと思います。 「longhorn」ストレージクラスを使って、1つのノードでのみ読み取り/書き込みとしてマウント可能な、10ギガバイトを要求しています。
ここで重要なのは、storageClassName: longhornです。
AKSクラスタで利用できるストレージクラスを確認してみましょう。
kubectl get StorageClass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
azurefile kubernetes.io/azure-file Delete Immediate true 10d
azurefile-premium kubernetes.io/azure-file Delete Immediate true 10d
default (default) kubernetes.io/azure-disk Delete Immediate true 10d
longhorn driver.longhorn.io Delete Immediate true 10d
managed-premium kubernetes.io/azure-disk Delete Immediate true 10d
Azureのストレージクラスはほとんどありませんが、これらは、デフォルトでインストールされたクラスと、以下の一番最初のコマンドの一部でインストールしたLonghornのクラスです。
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml
永続ボリュームクレームの定義に含まれる#storageClassName: longhornをコメントアウトすると、現在「default」としてマークされているストレージクラスが使用されます。これは、通常のAzureディスクです。
分散ストレージが必要な理由を説明するために、この記事の始めに説明した、longhornストレージを使用しない「カオスエンジニアリング」実験をもう一度行ってみましょう。 最初の2つのシナリオ(IRISの停止とポッドの削除)は正常に完了し、システムは稼働状態に回復します。 ノードをドレインまたは強制終了しようとすると、システムは障害状態になります。
#forcefully drain the node
kubectl drain aks-agentpool-71521505-vmss000001 --delete-local-data --ignore-daemonsets
kubectl describe pods
...
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 57s (x9 over 2m41s) default-scheduler 0/3 nodes are available: 1 node(s) were unschedulable, 2 node(s) had volume node affinity conflict.
基本的に、KubernetesはクラスタのIRISポッドを再起動しようとしますが、最初に起動されていたノードは利用できないため、ほかの2つのノードに「ボリュームノードアフィニティの競合」が発生しています。 このストレージタイプでは、基本的にボリュームはノードホストで使用可能なディスクに関連付けられているため、最初に作成されたノードでしか使用できないのです。
ストレージクラスにlonghornを使用すると、「強制ドレイン」と「ノードの強制終了」の2つの実験は正常に完了し、間もなくしてIRISポッドの動作が再開します。 これを実現するために、Longhornは3ノードクラスタをで使用可能なストレージを制御し、3つのすべてのノードにデータを複製しています。 ノードの1つが永久的に使用不可になると、Longhornは迅速にクラスタストレージを修復します。 「ノードの強制終了」シナリオでは、IRISポッドはほかの2つのボリュームレプリカを使ってすぐに別のノードで再起動されます。 するとAKSは失われたノードに置き換わる新しいノードをプロビジョニングし、準備ができたら、Longhorn がそのノードに必要なデータを再構築します。 すべては自動的に行われるため、ユーザーが手を入れる必要はありません。
図3 置換されたノードにボリュームレプリカを再構築するLonghorn
k8sデプロイについて
デプロイの他の側面をいくつか見てみましょう。
apiVersion: apps/v1
kind: Deployment
metadata:
name: iris
spec:
selector:
matchLabels:
app: iris
strategy:
type: Recreate
replicas: 1
template:
metadata:
labels:
app: iris
spec:
containers:
- image: store/intersystems/iris-community:2020.4.0.524.0
name: iris
env:
- name: ISC_DATA_DIRECTORY
value: /external/iris
- name: ISC_CPF_MERGE_FILE
value: /external/merge/merge.cpf
ports:
- containerPort: 52773
name: smp-http
volumeMounts:
- name: iris-external-sys
mountPath: /external
- name: cpf-merge
mountPath: /external/merge
livenessProbe:
initialDelaySeconds: 25
periodSeconds: 10
exec:
command:
- /bin/sh
- -c
- "iris qlist iris | grep running"
volumes:
- name: iris-external-sys
persistentVolumeClaim:
claimName: iris-pvc
- name: cpf-merge
configMap:
name: iris-cpf-merge
strategy: Recreateとreplicas: 1では、Kubernetesに、常にIRISポッドの1つのインスタンスのみを実行し続けることを指示しています。 これが「ポッドの削除」シナリオを処理する部分です。
livenessProbeのセクションでは、IRISが常時、コンテナ内で稼働し、「IRIS停止」シナリオを処理できるようにしています。 initialDelaySecondsは、IRISが起動するまでの猶予期間です。 IRISがデプロイを起動するのにかなりの時間が掛かっている場合は、これを増やすと良いでしょう。
IRISのCPF MERGE機能を使用すると、コンテナの起動時に、iris.cpf構成ファイルのコンテンツを変更することができます。 関連するドキュメントについては、 https://docs.intersystems.com/irisforhealthlatestj/csp/docbook/DocBook.UI.Page.cls?KEY=RACS_cpf#RACS_cpf_edit_mergeをご覧ください。 この例では、Kubernetesの構成図を使って、マージファイルのコンテンツを管理しています( https://github.com/antonum/ha-iris-k8s/blob/main/iris-cpf-merge.yaml)。ここでは、IRISインスタンスが使用するグローバルバッファとgmheapの値を調整していますが、iris.cpfファイルにあるものはすべて調整できます。 デフォルトのIRISパスワードでさえも、CPFマージファイルの「PasswordHash」フィールドで変更可能です。 詳細については、https://docs.intersystems.com/irisforhealthlatestj/csp/docbook/Doc.View.cls?KEY=ADOCK#ADOCK_iris_images_password_authをご覧ください。
永続ボリュームクレーム(https://github.com/antonum/ha-iris-k8s/blob/main/iris-pvc.yaml)デプロイ(https://github.com/antonum/ha-iris-k8s/blob/main/iris-deployment.yaml)とCPFマージコンテンツを使った構成図(https://github.com/antonum/ha-iris-k8s/blob/main/iris-cpf-merge.yaml)のほかに、デプロイには、IRISデプロイをパブリックインターネットに公開するサービスが必要です(https://github.com/antonum/ha-iris-k8s/blob/main/iris-svc.yaml)。
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
iris-svc LoadBalancer 10.0.18.169 40.88.123.45 52773:31589/TCP 3d1h
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 10d
iris-svcの外部IPは、http://40.88.123.45:52773/csp/sys/%25CSP.Portal.Home.zenを介してIRIS管理ポータルにアクセスするために使用できます。 デフォルトのパスワードは「SYS」です。
ストレージのバックアップ/復元とスケーリング
Longhornには、ボリュームの構成と管理を行えるウェブベースのUIがあります。
kubectlを使用して、ポッドや実行中のlonghorn-uiコンポーネントを特定し、ポート転送を確立できます。
kubectl -n longhorn-system get pods
# longhorn-uiのポッドIDに注意してください。
kubectl port-forward longhorn-ui-df95bdf85-gpnjv 9000:8000 -n longhorn-system
Longhorn UIは、http://localhost:9000で利用できるようになります。
図4 LonghornのUI
Kubernetesコンテナストレージのほとんどのソリューションでは、高可用性のほか、バックアップ、スナップショット、および復元のための便利なオプションが用意されています。 詳細は実装によって異なりますが、一般的には、バックアップをVolumeSnapshotに関連付ける方法です。 この方法はLonghornでも利用できます。 使用しているKubernetesのバージョンとプロバイダーによっては、ボリュームスナップショット機能( https://github.com/kubernetes-csi/external-snapshotter)もインストールする必要があります。
そのようなボリュームショットの例には、「iris-volume-snapshot.yaml」が挙げられます。 使用する前に、バックアップを、LonghornのS3バケットまたはNFSボリュームに構成する必要があります。 https://longhorn.io/docs/1.0.1/snapshots-and-backups/backup-and-restore/set-backup-target/
# IRISボリュームのクラッシュコンシステントなバックアップを取得する
kubectl apply -f iris-volume-snapshot.yaml
IRISでは、バックアップ/スナップショットを取得する前にExternal Freezeを実行し、後でThawを実行することをお勧めします。 詳細については、https://docs.intersystems.com/irisforhealthlatestj/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&CLASSNAME=Backup.General#ExternalFreezeをご覧ください。
IRISボリュームのサイズを増やすには、IRISが使用する、永続ボリュームクレーム(iris-pvc.yamlファイル)のストレージリクエストを調整します。
...
resources:
requests:
storage: 10Gi #change this value to required
そして、pvcの仕様を再適用します。 Longhornは、実行中のポッドにボリュームが接続されている場合、この変更を実際に適用することはできません。 そのため、ボリュームサイズが増えるように、デプロイでレプリカ数を一時的にゼロに変更します。
高可用性 - 概要
この記事の冒頭で、高可用性の基準を設定しました。 このアーキテクチャでは、次のようにそれを実現します。
障害の領域
自動的に緩和処置を行う機能
コンテナ/VM内のIRISインスタンス。 IRIS - レベル障害
IRISが機能停止となった場合、デプロイのLiveness Probeによってコンテナが再起動されます。
ポッド/コンテナの障害
デプロイによってポッドが再作成されます。
個々のクラスタノードの一時的な使用不能。 アベイラビリティーゾーンがオフラインになる場合などが挙げられます。
デプロイによって別のノードにポッドが再作成されます。 Longhornによって、別のノードでデータが使用できるようになります。
個々のクラスタノードまたはディスクの永久的障害。
上記と同様かつ、k8sクラスタオートスケーラーによって、破損したノードが新しいノードに置き換えられます。 Longhornによって、新しいノードにデータが再構築されます。
ゾンビやその他の考慮事項
DockerコンテナでのIRISの実行を理解している方であれば、「--init」フラグを使用したことがあるでしょう。
docker run --rm -p 52773:52773 --init store/intersystems/iris-community:2020.4.0.524.0
このフラグは、「ゾンビプロセス」の形成を防止することを目的としています。 Kubernetesでは、「shareProcessNamespace: true」を使用する(セキュリティの考慮事項が適用されます)か、コンテナで「tini」を使用することができます。 以下に、tiniを使用したDockerfileの例を示します。
FROM iris-community:2020.4.0.524.0
...
# Tiniを追加します
USER root
ENV TINI_VERSION v0.19.0
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /tini
RUN chmod +x /tini
USER irisowner
ENTRYPOINT ["/tini", "--", "/iris-main"]
2021年以降、すべてのInterSystemsが提供するコンテナイメージには、デフォルトでtiniが含まれています。
いくつかのパラメーターを調整することで、「ノードの強制ドレイン/ノードの強制終了」シナリオのフェイルオーバー時間をさらに短縮することができます。
Longhornのポッド削除ポリシー(https://longhorn.io/docs/1.1.0/references/settings/#pod-deletion-policy-when-node-is-down)およびkubernetes taintベースのエビクション機能(https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/#taint-based-evictions)をご覧ください。
免責事項
InterSystemsに勤務する者として、この内容を記載しておく必要があります。この記事では、分散型Kubernetesブロックストレージの一例としてLonghornを使用しています。 InterSystemsは、個々のストレージソリューションや製品を検証ないしは公式なサポート声明を発行していません。 特定のストレージソリューションがニーズに適合しているかどうかは、ユーザー自身がテストして検証する必要があります。
分散ストレージには、ノードローカルストレージとは大きく異なるパフォーマンス特性も備わっています。 特に書き込み操作の場合、データが永続化された状態とみなされるには、データを複数の場所に書き込む必要があります。 必ずワークロードをテストし、CSIドライバが提供する特定の動作とオプションを理解するようにしてください。
InterSystemsでは基本的に、Longhornなどの特定のストレージjソリューションを検証あるいは承認していません。これは、個々のHDDブランドやサーバーハードウェアメーカーを検証しないのと同じです。 個人的には、Longhornは扱いやすいと感じています。プロジェクトのGitHubページ(https://github.com/longhorn/longhorn)では、その開発チームは積極的に応答し、よく助けていただいています。
まとめ
Kubernetesエコシステムは、過去数年間で大きな進化を遂げました。今日では、分散ブロックストレージソリューションを使用することで、IRISインスタンスやクラスタノード、さらにはアベイラビリティーゾーンの障害を維持できる高可用性構成を構築できるようにもなっています。
計算とストレージの高可用性をKubernetesコンポーネントにアウトソースできるため、従来のIRISミラーリングに比べ、システムの構成と管理が大幅に単純化しています。 ただしこの構成では、ミラーリング構成ほどのRTOとストレージレベルのパフォーマンスは得られないことがあります。
この記事では、Azure AKSをマネージドKubernetesとLonghorn分散ストレージシステムとして使用し、可用性の高いIRIS構成を構築しました。 ほかにも、AWS EKS、マネージドK8s向けのGoogle Kubernetes Engine、StorageOS、Portworx、OpenEBSなどの様々な分散コンテナストレージを探ってみると良いでしょう。エンタープライズ級のストレージソリューションには、NetApp、PureStorage、Dell EMCなどもあります。
付録A: クラウドでのKubernetesクラスタの作成
パブリッククラウドプロバイダーが提供するマネージドKubernetesサービスを使うと、このセットアップに必要なk8sクラスタを簡単に作成できます。 この記事で説明したデプロイには、AzureのAKSデフォルト構成をそのまますぐに使用することができます。
3ノードで新しいAKSクラスタを作成します。 それ以外はすべてデフォルトのままにします。
図5 AKSクラスタの作成
ローカルコンピュータにkubectlをインストールします。https://kubernetes.io/docs/tasks/tools/install-kubectl/
ローカルkubectlにASKクラスタを登録します。
図6 kubectlにAKSクラスタを登録
登録が済んだら、この記事の最初に戻って、longhornとIRISデプロイをインストールします。
AWS EKSでのインストールは、もう少し複雑です。 ノードグループのすべてのインスタンスにopen-iscsiがインストトールされていることを確認する必要があります。
sudo yum install iscsi-initiator-utils -y
GKEでのLonghornのインストールには追加の手順があります。https://longhorn.io/docs/1.0.1/advanced-resources/os-distro-specific/csi-on-gke/をご覧ください。
付録B: インストール手順
手順1 - Kubernetesクラスタとkubectl
3ノードk8sクラスタが必要です。 Azureでのクラスタの構成方法は付録Aをご覧ください。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-agentpool-29845772-vmss000000 Ready agent 10d v1.18.10
aks-agentpool-29845772-vmss000001 Ready agent 10d v1.18.10
aks-agentpool-29845772-vmss000002 Ready agent 10d v1.18.10
手順2 - Longhornをインストールする
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml
「longhorn-system」ネームスペースのすべてのポッドが実行状態であることを確認してください。 これには数分かかる場合があります。
$ kubectl get pods -n longhorn-system
NAME READY STATUS RESTARTS AGE
csi-attacher-74db7cf6d9-jgdxq 1/1 Running 0 10d
csi-attacher-74db7cf6d9-l99fs 1/1 Running 1 11d
...
longhorn-manager-flljf 1/1 Running 2 11d
longhorn-manager-x76n2 1/1 Running 1 11d
longhorn-ui-df95bdf85-gpnjv 1/1 Running 0 11d
詳細とトラブルシューティングについては、Longhornインストールガイド(https://longhorn.io/docs/1.1.0/deploy/install/install-with-kubectl)をご覧ください。
手順3 - GitHubリポジトリのクローンを作成する
$ git clone https://github.com/antonum/ha-iris-k8s.git
$ cd ha-iris-k8s
$ ls
LICENSE iris-deployment.yaml iris-volume-snapshot.yaml
README.md iris-pvc.yaml longhorn-aws-secret.yaml
iris-cpf-merge.yaml iris-svc.yaml tldr.yaml
手順4 - コンポーネントを1つずつデプロイして検証する
tldr.yamlファイルには、デプロイに必要なすべてのコンポーンネントが1つのバンドルとして含まれています。 ここでは、コンポーネントを1つずつインストールし、それぞれのセットアップを個別に検証します。
# 以前にtldr.yamlを適用したことがある場合は、削除します。
$ kubectl delete -f https://github.com/antonum/ha-iris-k8s/raw/main/tldr.yaml
# 永続ボリュームクレームを作成します
$ kubectl apply -f iris-pvc.yaml
persistentvolumeclaim/iris-pvc created
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
iris-pvc Bound pvc-fbfaf5cf-7a75-4073-862e-09f8fd190e49 10Gi RWO longhorn 10s
# 構成図を作成します
$ kubectl apply -f iris-cpf-merge.yaml
$ kubectl describe cm iris-cpf-merge
Name: iris-cpf-merge
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
merge.cpf:
----
[config]
globals=0,0,800,0,0,0
gmheap=256000
Events: <none>
# irisデプロイを作成します
$ kubectl apply -f iris-deployment.yaml
deployment.apps/iris created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
iris-65dcfd9f97-v2rwn 0/1 ContainerCreating 0 11s
# ポッド名を書き留めます。 この名前は、次のコマンドでポッドに接続する際に使用します。
$ kubectl exec -it iris-65dcfd9f97-v2rwn -- bash
irisowner@iris-65dcfd9f97-v2rwn:~$ iris session iris
Node: iris-65dcfd9f97-v2rwn, Instance: IRIS
USER>w $zv
IRIS for UNIX (Ubuntu Server LTS for x86-64 Containers) 2020.4 (Build 524U) Thu Oct 22 2020 13:04:25 EDT
# h<enter>でIRISシェルを終了
# exit<enter>でポッドを終了
# IRISコンテナのログにアクセスします
$ kubectl logs iris-65dcfd9f97-v2rwn
...
[INFO] ...started InterSystems IRIS instance IRIS
01/18/21-23:09:11:312 (1173) 0 [Utility.Event] Private webserver started on 52773
01/18/21-23:09:11:312 (1173) 0 [Utility.Event] Processing Shadows section (this system as shadow)
01/18/21-23:09:11:321 (1173) 0 [Utility.Event] Processing Monitor section
01/18/21-23:09:11:381 (1323) 0 [Utility.Event] Starting TASKMGR
01/18/21-23:09:11:392 (1324) 0 [Utility.Event] [SYSTEM MONITOR] System Monitor started in %SYS
01/18/21-23:09:11:399 (1173) 0 [Utility.Event] Shard license: 0
01/18/21-23:09:11:778 (1162) 0 [Database.SparseDBExpansion] Expanding capacity of sparse database /external/iris/mgr/iristemp/ by 10 MB.
# irisサービスを作成します
$ kubectl apply -f iris-svc.yaml
service/iris-svc created
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
iris-svc LoadBalancer 10.0.214.236 20.62.241.89 52773:30128/TCP 15s
手順5 - 管理ポータルにアクセスする
最後に、サービスの外部IP(http://20.62.241.89:52773/csp/sys/%25CSP.Portal.Home.zen)を使って、IRISの管理ポータルに接続します。ユーザー名は「_SYSTEM」、パスワードは「SYS」です。 初回ログイン時にパスワードの変更が求められます。
記事
Toshihiko Minamoto · 2023年5月23日
## **Web スクレイピングとは:**
簡単に言えば、**Web スクレイピング**、**Web ハーベスティング**、または **Web データ抽出**とは、Web サイトから大量のデータ(非構造化)を収集する自動プロセスです。 ユーザーは特定のサイトのすべてのデータまたは要件に従う特定のデータを抽出できます。 収集されたデータは、さらに分析するために、構造化された形式で保存することができます。
##
**Web スクレイピングの手順:**
1. スクレイピングする Web ページの URL を見つけます。
2. 検査により、特定の要素を選択します。
3. 選択した要素のコンテンツを取得するコードを記述します。
4. 必要な形式でデータを保存します。
たったそれだけです!!
## **Web スクレイピングに使用される一般的なライブラリ/ツール**
* Selenium - Web アプリケーションをテストするためのフレームワーク
* BeautifulSoup – HTML、XML、およびその他のマークアップ言語からデータを取得するための Python ライブラリ
* Pandas - データ操作と分析用の Python ライブラリ
## Beauthiful Soup とは?
Beautiful Soup は、Web サイトから構造化データを抽出するための純粋な Python ライブラリです。 HTML と XML ファイルからデータを解析できます。 これはヘルパーモジュールとして機能し、利用できる他の開発者ツールを使って Web ページを操作する方法と同じ方法かより優れた方法で HTML と対話します。
* `lxml` や `html5lib` などの使い慣れたパーサーと連携して、有機的な Python の方法で、解析ツリーを移動操作、検索、および変更できるようにするため、通常、プログラマーは数時間または数日間に及ぶ作業を節約できます。
* Beautiful Soup のもう 1 つの強力で便利な機能は、フェッチされるドキュメントを Unicode に変換し、送信されるドキュメントを UTF-8 に変換するインテリジェンスです。 ドキュメント自体にエンコーディングが指定されていないか、Beautiful Soup がエンコーディングを検出できない場合を除き、開発者がその操作に注意する必要はありません。
* 他の一般的な解析またはスクレイピング手法と比較した場合も**高速**と見なされています。
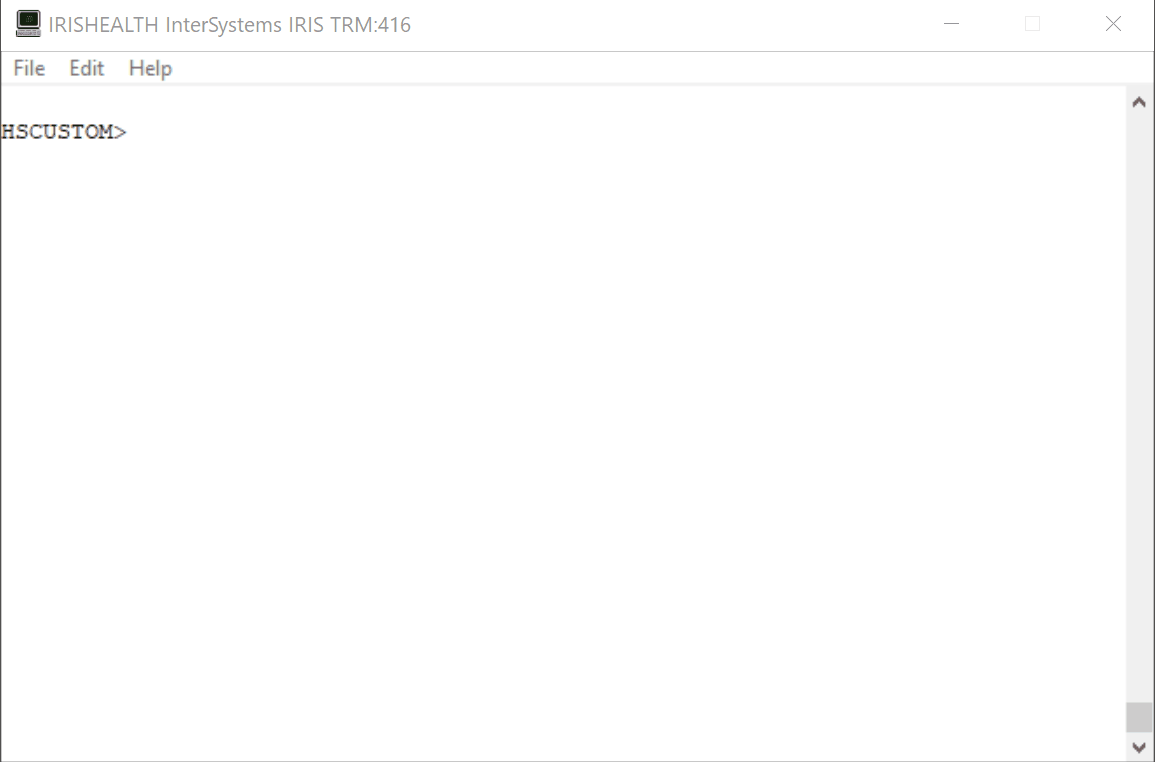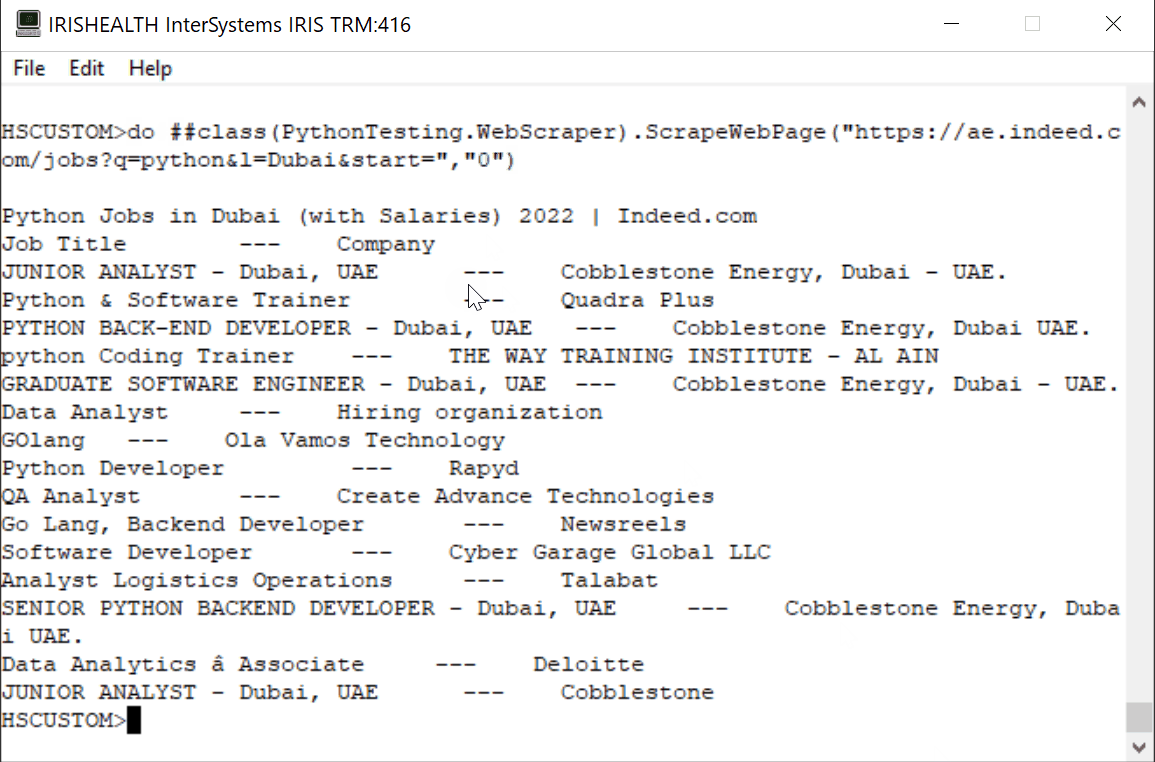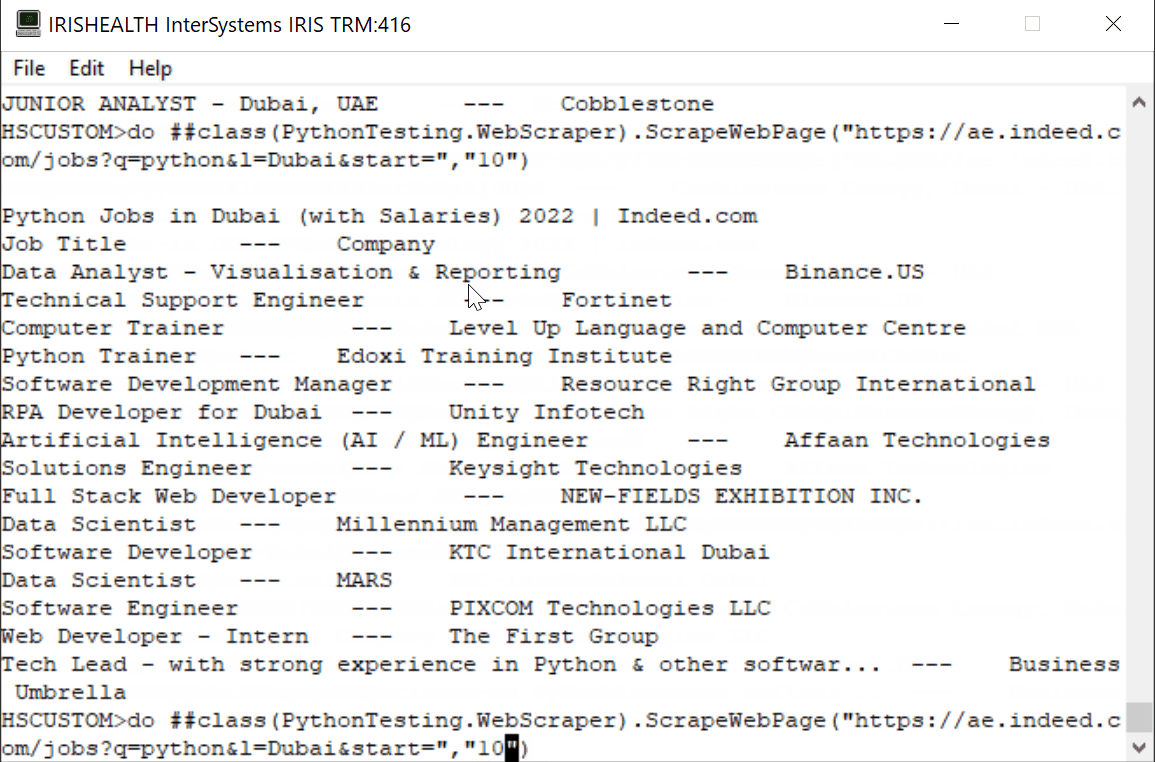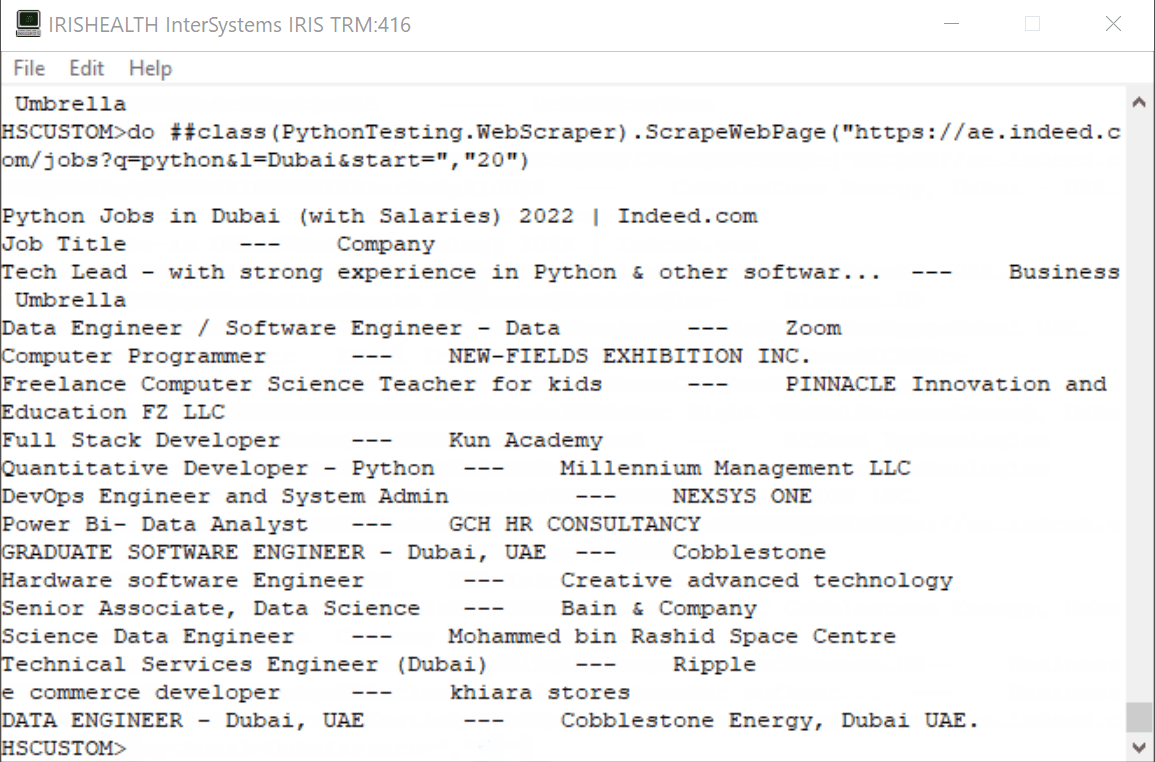
## **今日の記事では、Embedded Python と Object Script を使用して、ae.indeed.com にある Python の求人情報と企業をスクレイピングします。**
### ステップ 1 - スクレイピングする Web ページの URL を見つけます。
Url = https://ae.indeed.com/jobs?q=python&l=Dubai&start=0
スクレイピングするデータのある Web ページは以下のようになります。
.png)
**単純化と学習の目的で、"Job Title"(役職)と "Company"(会社)を抽出します。出力は以下のスクリーンショットのようになります。**
**以下の 2 つの Python ライブラリを使用します。**
* **requests** Requests は、Python プログラミング言語の HTTP ライブラリです。 プロジェクトの目標は、HTTP リクエストを単純化し、人間が読みやすくすることです。
* **bs4 for BeautifulSoup** Beautiful Soup は、HTML と XML ドキュメントを解析するための Python パッケージです。 HTML からデータを抽出するために使用できる解析済みページの解析ツリーを作成します。Web スクレイピングに役立ちます。
**以下の Python パッケージをインストールしましょう(Windows)。**
irispip install --target C:\InterSystems\IRISHealth\mgr\python bs4
irispip install --target C:\InterSystems\IRISHealth\mgr\python requests
.png)
**Python ライブラリを ObjectScript にインポートしましょう**
Class PythonTesting.WebScraper Extends %Persistent
{
// pUrl = https://ae.indeed.com/jobs?q=python&l=Dubai&start=
// pPage = 0
ClassMethod ScrapeWebPage(pUrl, pPage)
{
// imports the requests python library
set requests = ##class(%SYS.Python).Import("requests")
// import the bs4 python library
set soup = ##class(%SYS.Python).Import("bs4")
// import builtins package which contains all of the built-in identifiers
set builtins = ##class(%SYS.Python).Import("builtins")
}
**Requests を使って HTML データを収集しましょう。**
_注意: 「my user agent」でグーグル検索し取得した、ユーザーエージェント_
_URL は "https://ae.indeed.com/jobs?q=python&l=Dubai&start=" で、pPage はページ番号です。_
Requests を使って URL に HTTP GET リクエストを行い、そのレスポンスを "req" に格納します。
set headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"}
set url = "https://ae.indeed.com/jobs?q=python&l=Dubai&start="_pPage
set req = requests.get(url,"headers="_headers)
req オブジェクトには、Web ページから返された HTML が含まれます。
**これを BeautifulSoup HTML パーサーで実行し、求人データを抽出できるようにします。**
set soupData = soup.BeautifulSoup(req.content, "html.parser")
set title = soupData.title.text
W !,title
**タイトルは以下のように表示されます**
.png)
### ステップ 2 - 検査し、必要な要素を選択します。
**このシナリオでは、通常 <div> タグに含まれる求人リストに注目しています。ブラウザ内で要素を検査すると、その div クラスが見つかります。**
ここでは、必要な情報は、「 <div class="cardOutline tapItem ... </div>」 に格納されています。
### ステップ 3 - 選択した要素のコンテンツを取得するコードを記述します。
**BeautifulSoup の find_all 機能を使用して、クラス名 "cardOutline" を含むすべての <div> タグを検索します。**
//parameters to python would be sent as a python dictionary
set divClass = {"class":"cardOutline"}
set divsArr = soupData."find_all"("div",divClass...)
これによりリストが返されます。これをループ処理すると、Job Titles と Company を抽出できます。
###ステップ 4 - 必要なフォーマットでデータを保存/表示します。
以下の例では、データをターミナルに書き出します。
set len = builtins.len(divsArr)
W !, "Job Title",$C(9)_" --- "_$C(9),"Company"
for i = 1:1:len {
Set item = divsArr."__getitem__"(i - 1)
set title = $ZSTRIP(item.find("a").text,"W")
set companyClass = {"class_":"companyName"}
set company = $ZSTRIP(item.find("span", companyClass...).text,"W")
W !,title,$C(9)," --- ",$C(9),company
}
builtins.len() を使用して、divsArr リストの長さを取得していることに注意してください。
識別子名:
ObjectScript と Python の識別子の命名規則は異なります。 たとえば、Python のメソッド名ではアンダースコア(_)を使用でき、\__getitem\__ や \__class\__ のようにいわゆる「ダンダー」といわれる特殊なメソッドや属性で実際に広く使用されています(「ダンダー」は「double underscore = 二重アンダースコア」の略です)。 このような識別子を ObjectScript で使用するには、二重引用符で囲みます:
識別子名に関する InterSystems ドキュメント
## クラスメソッドの例
ClassMethod ScrapeWebPage(pUrl, pPage)
// pUrl = https://ae.indeed.com/jobs?q=python&l=Dubai&start=
// pPage = 0
ClassMethod ScrapeWebPage(pUrl, pPage)
{
set requests = ##class(%SYS.Python).Import("requests")
set soup = ##class(%SYS.Python).Import("bs4")
set builtins = ##class(%SYS.Python).Builtins()
set headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"}
set url = pUrl_pPage
set req = requests.get(url,"headers="_headers)
set soupData = soup.BeautifulSoup(req.content, "html.parser")
set title = soupData.title.text
W !,title
set divClass = {"class_":"cardOutline"}
set divsArr = soupData."find_all"("div",divClass...)
set len = builtins.len(divsArr)
W !, "Job Title",$C(9)_" --- "_$C(9),"Company"
for i = 1:1:len {
Set item = divsArr."__getitem__"(i - 1)
set title = $ZSTRIP(item.find("a").text,"W")
set companyClass = {"class_":"companyName"}
set company = $ZSTRIP(item.find("span", companyClass...).text,"W")
W !,title,$C(9)," --- ",$C(9),company
}
}
## 今後の内容..
ObjectScript とEmbedded Python と数行のコードを使用して、いつも使用する求人サイトのデータをスクレイピングし、求人タイトル、会社、給料、職務内容、メールアドレス/リンクを簡単に収集できます。
たとえば、ページが複数ある場合、ページを使用して簡単にそれらをトラバースできます。
このデータを Pandas データフレームに追加して重複を削除したら、関心のある特定のキーワードに基づいてフィルターを適用できます。
このデータを NumPy で実行してラインチャートを取得します。
または、One-Hot エンコーディングをデータに実行し、ML モデルを作成/トレーニングします。興味のある特定の求人情報がある場合は、自分に通知を送信するようにします。 😉
それではコーディングをお楽しみください!!!
「いいね」ボタンも忘れずに押してください 😃
記事
Toshihiko Minamoto · 2020年10月22日
InterSystems IRIS 2019.1は公開されてからしばらく経ちますが、気づかれていない可能性のある、JSONの処理の強化機能について説明したいと思います。 最新のアプリケーションを構築する際、特にRESTエンドポイントを操作する際は、JSONをシリアル化形式として扱うことが重要です。
## JSONの書式
まず、JSONに書式設定を適用すると、人の目で読みやすくなります。 コードをデバックする際に、特定のサイズでJSONコンテンツを確認する場合に非常に役立ちます。 構造が単純化されていれば、ざっと目を通すことが容易にはなりますが、ネストされている複数の要素に遭遇すると、あっという間に読みづらくなります。 以下に簡単な例を示します。
{"name":"Gobi","type":"desert","location":{"continent":"Asia","countries":["China","Mongolia"]},"dimensions":{"length":1500,"length_unit":"km","width":800,"width_unit":"km"}}
人の目でより読みやすい形式を適用すると、コンテンツの構造を調べやすくなります。 適切な改行やインデントを使用した同一のJSON構造を見てみましょう。
{
"name":"Gobi",
"type":"desert",
"location":{
"continent":"Asia",
"countries":[
"China",
"Mongolia"
]
},
"dimensions":{
"length":1500,
"length_unit":"km",
"width":800,
"width_unit":"km"
}
}
この単純な例だけでも、出力がかなり大きくなるため、多くのシステムでこの書式がデフォルト設定となっていない理由は明確でしょう。 ただし、この詳細な書式により、基礎構造を簡単に読み取れるようになり、何かが間違っているかどうかを見つけやすくなります。
InterSystems IRIS 2019.1では、%JSONという名前のパッケージが導入されました。 パッケージには、上記で示したとおり、動的なオブジェクトと配列、そしてJSON文字列をより読みやすくできる整形ツールなど、いくつかの便利なユーティリティがあります。 %JSON.Formatterは非常に単純なインターフェースを持つクラスです。 すべてのメソッドはインスタンスメソッドであるため、必ずインスタンスを取得するところから始めます。
USER>set formatter = ##class(%JSON.Formatter).%New()
この選択の背景には、インデント(空白またはタブなど)特定の文字や行末記号の特定の文字を使えるように整形ツールを1回構成し、それ以降、必要な個所に使用できるようになるという理由があります。
Format()メソッドは、動的なオブジェクト化配列またはJSON文字列を取ります。 では、動的なオブジェクトを使用した簡単な例を見てみましょう。
USER>do formatter.Format({"type":"string"})
{
"type":"string"
}
そして、以下は、同じJSONコンテンツでJSON文字列を使った例です。
USER>do formatter.Format("{""type"":""string""}")
{
"type":"string"
}
Format()メソッドは、整形された文字列を現在のデバイスに出力しますが、直接変数に出力する場合のFormatToString()とFormatToStream() も表示されます。
## 変速を変える
上記は素晴らしい機能ですが、それだけでは記事にする価値はないかもしれません。 InterSystems IRIS 2019.1では、永続オブジェクトと一時オブジェクトをJSONとの間でシリアル化する便利な方法も導入されています。 ここで調べるクラスは %JSON.Adaptorです。 概念が%XML.Adaptorに非常に似ているため、その名前が付けられています。 JSONとの間でシリアル化するクラスは、%JSON.Adaptorをサブクラス化する必要があります。 クラスは、いくつかの便利なメソッドを継承しますが、中でも%JSONImport()と%JSONExport()の継承は非常に役立ちます。 これについては例で示すのが一番良いでしょう。 次のクラスがあったとします。
Class Model.Event Extends (%Persistent, %JSON.Adaptor)
{
Property Name As %String;
Property Location As Model.Location;
}
および
Class Model.Location Extends (%Persistent, %JSON.Adaptor)
{
Property City As %String;
Property Country As %String;
}
ご覧の通り、永続的なイベントクラスがあり、ロケーションにリンクしています。 両方のクラスは%JSON.Adaptorから継承されています。 このため、オブジェクトグラフを作成し、それをJSON文字列として直接エクスポートすることができます。
USER>set event = ##class(Model.Event).%New()
USER>set event.Name = "Global Summit"
USER>set location = ##class(Model.Location).%New()
USER>set location.City = "Boston"
USER>set location.Country = "United States of America"
USER>set event.Location = location
USER>do event.%JSONExport()
{"Name":"Global Summit","Location":{"City":"Boston","Country":"United States of America"}}
もちろん、%JSONImport()を使用して、逆の方向にエクスポートすることもできます。
USER>set jsonEvent = {"Name":"Global Summit","Location":{"City":"Boston","Country":"United States of America"}}
USER>set event = ##class(Model.Event).%New()
USER>do event.%JSONImport(jsonEvent)
USER>write event.Name
Global Summit
USER>write event.Location.City
Boston
インポートメソッドとエクスポートメソッドは、任意のネストされた構造で機能します。 %XML.Adaptorと同様に、対応するパラメーターを設定して、個々のプロパティのマッピングロジックを指定できます。 Model.Eventクラスを次の定義に変更してみましょう。
Class Model.Event Extends (%Persistent, %JSON.Adaptor)
{
Property Name As %String(%JSONFIELDNAME = "eventName");
Property Location As Model.Location(%JSONINCLUDE = "INPUTONLY");
}
上記の例とオブジェクト構造が変数eventに割り当てられていると仮定した場合、%JSONExport()を呼び出すと、次の結果が返されます。
USER>do event.%JSONExport()
{"eventName":"Global Summit"}
Nameプロパティは、eventNameフィールド名にマッピングされ、Locationプロパティは %JSONExport()呼び出しから除外されますが、存在する場合は%JSONImport()呼び出し中にJSONコンテンツに入力されます。 マッピングを調整するには、次のようなパラメーターを使用できます。
* %JSONFIELDNAME: JSONコンテンツのフィールド名に対応します。
* %JSONIGNORENULL: 開発者が文字列プロパティの空の文字列のデフォルト処理をオーバーライドできるようにします。
* %JSONINCLUDE : このプロパティがJSON出力/入力に含まれるかどうかを制御します。
* %JSONNULL: これがtrue(=1)である場合、未指定のプロパティはnull値としてエクスポートされます。 そうでない場合は、プロパティに対応するフィールドはエクスポート中に省略されます。
* %JSONREFERENCE: オブジェクト参照の処理方法を指定します。 デフォルトは「OBJECT」で、参照先クラスのプロパティが参照先オブジェクトを表すために使用されることを示します。 その他のオプションは「ID」、「OID」、および「GUID」です。
これにより高度な制御が可能になり、非常に便利です。 オブジェクトを手動でJSONにマッピングする時代は終わりました。
## あともう一つ
マッピングパラメーターをプロパティレベルで設定する代わりに、XDataブロックにJSONマッピングを定義することも可能です。 次に示すOnlyLowercaseTopLevelという名前のXDataブロックには、上記のeventクラスと同じ設定が行われています。
Class Model.Event Extends (%Persistent, %JSON.Adaptor)
{
Property Name As %String;
Property Location As Model.Location;
XData OnlyLowercaseTopLevel
{
<Mapping xmlns="http://www.intersystems.com/jsonmapping">
<Property Name="Name" FieldName="eventName"/>
<Property Name="Location" Include="INPUTONLY"/>
</Mapping>
}
}
重要な違いが1つあります。それは、XDataブロックのJSONマッピングはデフォルトの動作を変更しないが、対応する%JSONImport()と%JSONExport()の呼び出しで最後の引数として参照する必要があるということです。例を示します。
USER>do event.%JSONExport("OnlyLowercaseTopLevel")
{"eventName":"Global Summit"}
指定された名前のXDataブロックが存在しない場合、デフォルトのマッピングが使用されます。 このアプローチを使用すると、複数のマッピングを構成し、各呼び出しに必要なマッピングを個別に参照することができます。そのため、マッピングをより柔軟で再利用可能にしながら、より高い制御性を得ることができます。
これらの機能強化によって作業が楽になることを願っています。皆さんからのフィードバックを楽しみしています。 ぜひコメントを残してください。
記事
Toshihiko Minamoto · 2021年9月28日
Cachéでのデータ同期については、オブジェクトとテーブルを同期させるさまざまな方法があります。
データベースレベルでは、[シャドーイング](https://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_shadow)または[ミラーリング](https://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror)を使用できます。
これは非常によく機能し、データの一部分だけを同期する必要がある場合には、
[グローバルマッピング](https://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GORIENT_devtasks_mappings_global)を使用してより小さなピースにデータを分割することができます。
または、クラス/テーブルレベルで双方向の同期が必要な場合には、[オブジェクト同期機能](https://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GOBJ_objsync)を使用することができます。
これらすべての優れた機能には次のような制限があります。Caché/IRISからCaché/IRISにしか機能しません。
外部のデータベースにデータを同期する必要がある場合には、ほかのソリューションが必要です。
このソリューションは、かなり以前からCaché/IRISに提供されており、非常に良く機能します。
[^OBJ.DSTIME](https://docs.intersystems.com/ens20181j/csp/docbook/DocBook.UI.Page.cls?KEY=D2IMP_ch_current#D2IMP_current_cube_sync_and_mirroring)で解決です。
これは、Deep Seeとのデータ同期を可能にするために構築されました。
Modified,New,Deleted
をシグナルすることで、オブジェクト/テーブルの変更に関する非常に単純なジャーナルを維持します。 これはDeep Seeだけでなく、あらゆる種類のデータ同期でも有用です。
グローバル ^OBJ.DSTIMEにはこのほかに2つの機能があります。
* 永続クラスの[%SYSTEM.DSTIME](https://docs.intersystems.com/latest/csp/documatic/%25CSP.Documatic.cls?PAGE=CLASS&LIBRARY=%25SYS&CLASSNAME=%25SYSTEM.DSTIME)にラップされているため、通常のSQLテーブルとして変更を選択するために使用することもできます。
* 同期されたジャンクの制御を可能にするバージョンID(DSTIMEという名前)を維持します。 - 最後のバージョンをフェッチする - バージョンを増加する - フェッチされたバージョンに基づいて、必要な場所に変更をアップロードする
純粋なSQLで同期を行う場合、SQLを理解するあらゆるデータベースをターゲットとすることができます。
クラス %SYSTEM.DSTIME を拡張して、[こちらに例](https://github.com/rcemper/Sync-Data-with-DSTIME-ZPM)を置きました。SAMPLESで試すことができます。
これはCaché 2018.1.3とIRIS 2020.2で機能するコーディングの例です。
新しいバージョンと同期されません。
また、InterSystemsのサポートによるサービスはありません!
記事
Megumi Kakechi · 2021年12月9日
これは、InterSystems FAQサイトの記事です。
【 管理ポータルへのパスワード認証設定方法 】
管理ポータルの、 [ホーム] > [システム管理] > [セキュリティ] > [アプリケーション] > [ウェブ・アプリケーション]で /csp/sys、および、/csp/sys/ 以下の各アプリケーション(/csp/sys/expなど) の編集画面を開き、“許可された認証方法” の、“パスワード” をチェックして保存します。
また、これと同様のことを、ターミナルから、^SECURITYルーチンを使用して実行することも可能です。以下は/csp/sys/アプリケーションに対する実行例です。*実行は%SYSネームスペースで行って下さい。*
※入力箇所は青字で記載%SYS>do ^SECURITY 1) User setup2) Role setup3) Service setup4) Resource setup5) Application setup6) Auditing setup8) SSL configuration setup9) Mobile phone service provider setup10) OpenAM Identity Services setup11) Encryption key setup12) System parameter setup13) X509 User setup14) KMIP server setup15) Exit Option? 5 1) Web applications2) Doc DB applications3) Privileged Routine applications4) Client applications5) Exit Option? 1 1) Create application2) Edit application3) List applications4) Detailed list applications5) Delete application6) Export applications7) Import applications8) Exit Option? 2 Application to edit? /csp/sys // ? 入力でアプリケーション一覧を表示Description? システム管理ポータル =>Enabled? Yes => Yes // そのままEnterCSP/ZEN Enabled? Yes => YesBusiness Intelligence Enabled? No => NoiKnow Enabled? No => NoInbound Web Services Enabled? Yes => YesRequire resource to use application? No => NoRole to always add to application?New match role to add to application?Do you want to go back and re-edit any match roles or target roles? No => NoAllow 認証なし access? Yes => No // 認証なしログインを不可設定Allow パスワード authentication? No => Yes // パスワードログインのみ可能:(このあと、メニューが終わるまでデフォルトのままEnter)
※ 認証方法を変更後、アクセスに必要なユーザ名/パスワードが分からない等でターミナルやシステム管理ポータルにアクセスできなくなる危険性を回避するため、変更を元に戻すためのターミナルやシステム管理ポータルを予め開いておくことをお奨めします。
【スタジオ・ターミナルへのパスワード認証設定】
管理ポータルの、 [ホーム] > [システム管理] > [セキュリティ] > [サービス]で、以下のサービスのリンクを押下して、定義編集画面を開き、“許可する認証の有効/無効:”の、“パスワード”をチェックします。
スタジオ : %Service_Bindings ターミナル : %Service_Console
また、これと同様のことを、ターミナルから、^SECURITYルーチンを使用して実行することも可能です。実行手順は、前述の管理ポータルの場合と同様です。最初のオプション選択で、3) Service setup を選択し、設定して下さい。
^SECURITYルーチンについては、以下ドキュメントをご参照ください。SECURITYルーチンについて【IRIS】
記事
Mihoko Iijima · 2022年3月29日
これは、InterSystems FAQサイトの記事です。
メール送付のコードを記述する前に、管理ポータルで SSL/TLS 構成を作成します。
管理ポータル > システム管理 > セキュリティ > SSL/TLS 構成
メール送付までの流れは以下の通りです。
メールメッセージ用クラス:%Net.MailMessage のインスタンスを作成し、送信元メールアドレス、宛先メールアドレス、件名、本文を設定します。
認証情報設定用クラス:%Net.Authenticator のインスタンスを作成し、メール送付時に使用する認証情報を設定します。
SMTP用クラス:%Net.SMTP のインスタンスを作成し、SMTP サーバの設定、管理ポータルで作成した SSL/TLS 構成名の指定、2で作成した認証情報と 1で作成したメールメッセージを使用して、メールを送信します。
ターミナルからの実行例は以下の通りです(Gmail を利用しています)。
《メモ》現在(2022年5月30日以降)、Gmailを利用したメール送付を行う場合 OAuth2.0 の利用が必須となりました。Gmailを利用する場合の手順ついては、「OAuth 2.0 を利用して IRIS から Gmail を送信する」をご参照ください。
《そのほかの注意》Gmailを利用する場合、Gmailアカウントに対して「安全性の低いアプリのアクセス」を有効にする必要があります。また、GmailのSMTPを経由してメール送信するため、Gmailアカウントに対して「アプリ パスワード」を設定する必要があります。
詳細は、Googleアカウントのヘルプページ「アプリ パスワードでログインする」ご参照ください。
// メールメッセージ用インスタンスを準備します
set message=##class(%Net.MailMessage).%New()
set message.From = "<送信元メールアドレス>"
do message.To.Insert("<宛先メールアドレス>")
// メールの件名を設定
set message.Subject = "これはテストメールです"
// メール本文の設定(末尾に改行を入れるメソッド)
do message.TextData.WriteLine("本日は快晴でした")
// メール本文の設定(指定した文字のみを出力するメソッド)
do message.TextData.Write("明日も晴れるといいです。")
// 認証情報設定
set auth = ##class(%Net.Authenticator).%New()
set auth.UserName = "<ユーザID>"
set auth.Password = "<パスワード>"
// SSLを使用する場合(Gmailの例)
set mbox = ##class(%Net.SMTP).%New()
set mbox.smtpserver = "smtp.gmail.com"
set mbox.port="465" // TLS の場合は "587" // SSL 構成のセットアップ
set mbox.authenticator = auth
set mbox.AuthFrom = auth.UserName
set mbox.SSLConfiguration = "GMAILSSL" // SSL 構成名(管理ポータルで設定)
set mbox.UseSTARTTLS=0 // (0は既定)TLSの場合は 1
// メール送信
set status = mbox.Send(message)
write $system.OBJ.DisplayError(status)
// メモ: エラーメッセージだけを文字で取得する場合は以下実行します
write $system.Status.GetErrorText(status)
お知らせ
Masahito Miura · 2023年3月28日
インターシステムズは、新旧すべての製品について、お客様に高品質な製品サポートを提供することをお約束します。Caché はリリースされて 25 年になります。製品リリースを重ねるに応じてそのサポートは進展されていきます。
2018 年にリリースされた InterSystems IRIS は、Caché と Ensemble の後継製品です。 多くの Caché/Ensemble のお客様が IRIS に移行しているか、今後数年のうちに移行する予定です。 Caché や Ensemble を使い続けているお客様は、以下の重要なお知らせにご留意ください:
Caché/Ensemble のメンテナンス・リリースは、今後 4 年間 (2027 年の第 1 四半期まで) 継続されます。 2027 年 3 月 31 日以降は、Caché/Ensemble のメンテナンス・リリースの予定はありません。
これらのメンテナンス・リリースは、重要な欠陥、セキュリティの脆弱性および Windows と Red Hat Enterprise Linux (RHEL) の新しいバージョンについて、弊社の判断で対応します。 その他のプラットフォームについては、メンテナン ス・リリースを予定していません。(Caché/Ensemble の使用を継続されているお客様の大半は Windows または RedHat を使用されています)
弊社の計画では、12 か月ごとにメンテナンス・リリースを提供し、必要に応じて追加のセキュリティ・リリースを提 供する予定です。(製品リリースの新しい頻度についてについてを参照)
Caché や Ensemble の製品サポートの終了日を発表する予定はありません。 インターシステムズは、既存のサポート契約またはサブスクリプション契約に基づき、他のすべての製品と同じ対応レベルでサポートを提供し続けます。
また、従来からのポリシーと同様に、すべての Caché および Ensemble プラットフォームでアドホック修正がベストエフォートで提供される予定です。製品の問題修正 (新機能ではない) は、リスクや複雑性に基づいて、弊社の判断で既存の Caché/Ensemble リリースにバックポートされる予定です。 弊社は、常にお客様のお役に立てるよう最善を尽くすことを目指しております。
ご質問がある場合は、John.Paladino@InterSystems.com (クライアント・サービス担当副社長) またはセールス・アカウント・マネージャにご連絡ください。
記事
Mihoko Iijima · 2023年6月29日
これは InterSystems FAQ サイトの記事です。
LOAD DATAは、バージョン2022.1から追加されたSQLコマンドで、CSVファイルやJDBCソースからデータをテーブルにロードするコマンドです。データが存在するテーブルにLOAD DATAを実行した場合、データは追記されます。
※ バージョン2022.1をご利用いただく場合は、バージョン2022.1.3 をご利用ください。(2022.1.0~2022.1.2は、使用するJARファイルの不備により動作しません。)
LOAD DATAを利用する際、Javaの外部サーバ(Javaゲートウェイ)を使用するため、IRISをインストールした環境にJavaのインストールが必要です。サポート対象のJavaバージョンについては、ドキュメントの「サポート対象Javaテクノロジ」をご参照ください。
LOAD DATAを利用するためには、Javaインストール済、かつ外部言語サーバで %Java_Server 設定済の環境である必要があります。
※ 環境変数JAVA_HOMEの設定がある場合は以下 %Java_Serverの設定は不要です。
%Java_Server 設定詳細は以下の通りです。
Javaホームディレクトリ:インストールしたJavaのホームディレクトリを指定します。
利用手順は以下の通りです。
以下のCSVを読み込む場合の手順を説明します。
ProductID,ProductName,PriceP0101,貼るホッカイロミニ(10個),300P0102,貼るホッカイロ(10個),460P0103,貼るホッカイロ足裏(30個),1000
1) テーブル定義の作成
ロードしたいCSVのセルの並びに合わせてテーブル定義を作成します。
CREATE TABLE Test.Product(
ProductID VARCHAR(10) PRIMARY KEY,
ProductName VARCHAR(50),
Price INTEGER
)
2) LOAD DATAを実行する
ヘッダ付きのUTF-8で保存したCSVファイルを利用する場合のコマンド指定方法は以下の通りです。
LOAD DATA FROM FILE 'ファイルフルパス'
INTO スキーマ名.テーブル名
USING {"from":{"file":{"charset":"UTF-8","header":true}}}
実際の実行例は以下の通りです。
LOAD DATA FROM FILE 'c:\temp\test.csv'
INTO Test.Product
USING {"from":{"file":{"charset":"UTF-8","header":true}}}
※LOAD DATAの実行にはJavaの外部サーバを利用しています。初回実行時、外部サーバを開始するため少し時間がかかります。
3) 実行結果を確認する
ロードに失敗してスキップされたレコード数を確認する場合
select * from %SQL_Diag.Result
ロードに失敗した各レコードに関する詳細情報を参照する場合
select * from %SQL_Diag.Message
%SQL_Diag.Message テーブルには、%SQL_Diag.Result の外部キーが含まれているため、以下のように2つのテーブルを組み合わせてエラー詳細を確認することもできます。
SELECT * FROM %SQL_Diag.Message
JOIN %SQL_Diag.Result ON %SQL_Diag.Result.resultId = %SQL_Diag.Message.diagResult
where %SQL_Diag.Result.resultId=1
LOAD DATAについて詳細は、ドキュメント「LOAD DATA」もご参照ください。