クリアフィルター
記事
Mihoko Iijima · 2022年2月28日
開発者のみなさん、こんにちは。
今回は、スーパーやコンビニでもらうレシートを写真で撮り、OCR を使ってレシートの画像から文字列を切り出して IRIS に登録する流れを試してみました。
サンプルでは、Google の Vision API を利用してレシートの JPG 画像から購入物品をテキストで抽出しています。
サンプルコード一式 👉 https://github.com/Intersystems-jp/iris-embeddedpython-OCR
最初、オンラインラーニングで使っている 「tesseract-OCR」を使ってみようと思ったのですが、レシートには半角カナが混在していたりで、半カナがなかなかうまく切り出せず、あきらめました・・(半角カナがなかったら日本語もばっちり読めていたのですが・・)
もし、tesseract-OCR で半カナを切り出す良い方法をご存知の方いらっしゃいましたら、ぜひ教えてください!
今回試すにあたり、Vision API の使い方を詳しく書いているページがありましたのでコードなど参考させていただきました。ありがとうございました。
【Google Colab】Vision APIで『レシートOCR』
全体の流れですが、レシートの写真を JPG にし、Python の google-cloud-vision モジュールを使用して JPG を Vision API に渡し、テキストを切り出します。
切り出されたテキストを画像の位置に合わせて一旦ソートし、レシートに記載されているものが店名なのか、商品名なのか、金額なのか、など、IRIS に登録したい項目を Python の正規表現モジュール re を使用してチェックし IRIS に登録しています。
IRIS にデータを登録する部分はSQLでもできますが、今回のサンプルでは1対多のリレーションシップを使った永続クラスを利用しています。
(永続クラスに対してSQLでも操作ができるので、お好みの文法で操作できます)
1側クラス:Okaimono.Receipt
レシートの基本情報を格納します。(店名、買い物時間、購入合計、割引金額など)
多側クラス:Okaimono.Item
レシートに記載された詳細項目の項目名と金額を格納します。
サンプルの実行方法については、こちらをご参照ください。
以下、コードについて少しご紹介します。
Python 側のコード:receipt.py は、ほぼこちらの素晴らしい記事👉【Google Colab】Vision APIで『レシートOCR』 を参考にさせていただきましたので、詳しくは記事をご参照ください。
Vision API で切り出したテキストですが、IRISへ登録するために必要な情報を正規表現で取り出して Python の list に設定し、receiptIRIS.py に渡して IRIS に保存しています。
レシートの項目ですが、お店によって表記が様々だったため(半カナ混在だったり全角だけだったり、記号が付いたりつかなかったり、など)、ご紹介するサンプルでは「オーケー」のレシートに合った正規表現を利用しています。コンビニや他スーパーの場合、サンプルの正規表現に合わないと思いますので、receipt.py の 72 行目~ 80 行目辺りをご変更いただくことで、お好みのレシートを読めるようになります。ぜひお試しください。
今回、IRIS に登録するデータは、1対多のリレーションシップクラスを利用しているので、データの登録には SQL ではなくオブジェクトの文法を利用しています(もちろんSQLでも登録できます)。
具体的にどんなコードを書いているかというと、前回の記事「Embedded Python 試してみました」と同様に、Python から IRIS 内のクラスを操作するための iris モジュールのインポートと、クラスの操作に使用する iris.cls() を利用しています。
Okaimono.Receipt のインスタンス生成は以下の通りです。
import iris
receipt=iris.cls("Okaimono.Receipt")._New()
receipt.StoreName="○×商店"
そして、作成された Python の list を読みながら、レシートの詳細項目を登録します。
コードはこんな感じです。
Okaimono.Item のインスタンスを生成し、Name プロパティとPrice プロパティに値を登録し、
item=iris.cls("Okaimono.Item")._New()
item.Name="チョコ"
item.Price="100"
Okaimono.Item のインスタンス と Okaimono.Receipt のインスタンスを関連付けます。(Okaimono.Item クラスの Receiptリレーションシッププロパティを利用して Okaimono.Receipt クラスのインスタンスを代入しています)
item.Receipt=receipt
この方法の他に、1側の Okaimono.Receipt の Items プロパティ(リレーションシッププロパティ)に提供される Insert() メソッドを使用して Okaimono.Item のインスタンスを Okaimono.Receipt のインスタンスに割り当てる方法もあります。(どちらか一方の割り当て方法で大丈夫です)
receipt.Items.Insert(item)
上記操作をレシートに記載された購入品目分実行し、最後にレシートを IRIS に保存します。
st=receipt._Save()
これで、Okaimono.Receipt に紐づく Okaimono.Item が一括で保存されます。
以下の文例は、2つの商品を購入したときのレシート登録例です。
USER>do ##class(%SYS.Python).Shell()
Python 3.9.5 (default, Jan 25 2022, 13:57:42) [MSC v.1927 64 bit (AMD64)] on win32
Type quit() or Ctrl-D to exit this shell.
>>> import iris
>>> receipt=iris.cls("Okaimono.Receipt")._New()
>>> receipt.StoreName="テストストア"
>>> receipt.TotalPrice=778
>>> it1=iris.cls("Okaimono.Item")._New()
>>> it1.Name="お弁当"
>>> it1.Price=598
>>> receipt.Items.Insert(it1)
1
>>> it2=iris.cls("Okaimono.Item")._New()
>>> it2.Name="ジュース"
>>> it2.Price=180
>>> it2.Receipt=receipt
>>> receipt._Save()
1
>>>
登録されたデータを確認します。
IRIS では、1対多のリレーションシップ定義を行った場合、多側クラス(Okaimono.Item)のリレーションシップ用プロパティ:Receipt が外部キーカラムのようにテーブルに投影されます。
以下、確認例です。
まずは、Okaimono.Receipt データを確認します。
SELECT * FROM Okaimono.Receipt
上記実行例では、「テストストア」のデータは ID=2 で登録されています。
続いて、Okaimono.Item データを確認します。
SELECT * FROM Okaimono.Item
Receipt 列には、リレーションシッププロパティで定義した1側クラス(Okaimono.Receipt)の ID が登録されていることがわかります。
では、次に、Receipt が 2(Okaimono.Receipt の ID=2)の Okaimono.Item 全情報と Okaimono.Receipt の StoreName と TotalPrice を取得してみます。
SELECT *,Receipt->StoreName,Receipt->TotalPrice FROM Okaimono.Item Where Receipt=2
IRIS 独自の矢印構文(->)を利用しています。この構文はオブジェクトの定義によって作成された外部キー用カラムを利用して、参照先テーブルのカラムを指定できる文法で、Receipt->StoreName は、Okaimono.Item テーブルに紐づく Okaimono.Receipt テーブルの StoreName カラムを指定しています。
これは、1対多のリレーションシップやオブジェクト参照を利用している場合に利用できる方法で、内部的には左外部結合と一緒の処理を行っています。
IRIS 独自の書き方ではありますが、意外とすっきりと記述できるので見やすさ重視の場合に利用いただくケースもあります。
矢印構文について詳細はドキュメントもご参照ください。
ちなみに、Pythonシェル上で 1件の Okaimono.Receipt をオープンし、Okaimono.Receipt に紐づく Okaimono.Item を取得する場合のオブジェクトの文法は以下の通りです。
ID=2 の Okaimono.Receipt をオープンします。
>>> r1=iris.cls("Okaimono.Receipt")._OpenId(2)
何個の Okaimono.Item と紐づいているか確認するには、Okaimono.Receipt クラスのリレーションシッププロパティ=Items に対して Count() を使用します。
>>> r1.Items.Count()
2
1件目の Okaimono.Item を取得する例は以下の通りです。
>>> it1=r1.Items.GetAt(1)
>>> it1.Name
'お弁当'
>>> it1.Price
598
2件目も確認してみます。
>>> it2=r1.Items.GetAt(2)
>>> it2.Name
'ジュース'
>>> it2.Price
180
こんな感じで、SQLからもオブジェクトからも操作できることが確認できました。
Embedded Python の登場で、Python の便利なモジュールや公開されているサンプルコードが IRIS から実行しやすくなりました。
みなさんのお手元でもぜひお試しください!
そして、お試しいただいた内容など、お気軽にコミュニティに投稿してみてください!お待ちしてます🔥
記事
Mihoko Iijima · 2022年4月14日
これは、InterSystems FAQサイトの記事です。
アプリケーションモニタが提供する %Monitor.System.Diskspace(ディスク容量メトリック)を利用して指定サイズを下回る場合にメール通知を行うように設定を追加することができます。
アプリケーション・モニタのメトリック【IRIS】アプリケーション・モニタのメトリック
システム提供のアプリケーションモニタは、デフォルトでは全て無効化されています。使用を開始するためには、対象のモニタを有効化し、システムモニタを再起動します。
アプリケーションモニタの有効/無効やシステムモニタの停止/開始は、システムルーチン ^%SYSMONMGR を利用します。
以下の例では、ディスクの空き容量が 100MB を下回る場合にメール通知を行う設定手順について説明します。
手順は以下の通りです。
1) ^%SYSMONMGR を起動し、アプリケーションモニタから %Monitor.System.Diskspace を有効化する
2) アラート対象とする閾値を変更する(例では、通知は最初の1回のみとしています)
3) Email通知設定を行う
4) システムモニタを再起動する
1) ^%SYSMONMGR を起動し、アプリケーションモニタから %Monitor.System.Diskspace を有効化する
ドキュメントは以下ご参照ください。Manage Monitor Classes【IRIS】Manage Monitor Classes
%SYS>do ^%SYSMONMGR
1) Start/Stop System Monitor
2) Set System Monitor Options
3) Configure System Monitor Classes
4) View System Monitor State
5) Manage Application Monitor
6) Manage Health Monitor
7) View System Data
8) Exit
Option? 5 → 5 を入力してEnter押下
1) Set Sample Interval
2) Manage Monitor Classes
3) Change Default Notification Method
4) Manage Email Options
5) Manage Alerts
6) Exit
Option? 2 → 2 を入力してEnter押下
1) Activate/Deactivate Monitor Class
2) List Monitor Classes
3) Register Monitor System Classes
4) Remove/Purge Monitor Class
5) Set Class Sample Interval
6) Debug Monitor Classes
7) Exit
Option? 1 → 1 を入力してEnter押下
Class? ? → ? を入力してEnter押下
Num MetricsClassName Activated
1) %Monitor.System.HistoryMemory N
2) %Monitor.System.HistoryPerf N
3) %Monitor.System.HistorySys N
4) %Monitor.System.HistoryUser N
5) %Monitor.System.AuditCount N
6) %Monitor.System.AuditEvents N
7) %Monitor.System.Clients N
8) %Monitor.System.Diskspace N
9) %Monitor.System.Freespace N
10) %Monitor.System.Globals N
11) %Monitor.System.Journals N
12) %Monitor.System.License N
13) %Monitor.System.LockTable N
14) %Monitor.System.Processes N
15) %Monitor.System.Routines N
16) %Monitor.System.Servers N
17) %Monitor.System.SystemMetrics N
18) %Monitor.System.CSPGateway N
Class? 8 %Monitor.System.Diskspace →上のリストの 8 を指定してEnter押下
Activate class? Yes => yes → yes を入力してEnter押下
1) Activate/Deactivate Monitor Class
2) List Monitor Classes
3) Register Monitor System Classes
4) Remove/Purge Monitor Class
5) Set Class Sample Interval
6) Debug Monitor Classes
7) Exit
Option? →Enter押下(前のメニューに戻ります)
1) Set Sample Interval
2) Manage Monitor Classes
3) Change Default Notification Method
4) Manage Email Options
5) Manage Alerts
6) Exit
Option?
2) アラート対象とする閾値を変更する(例では、通知は最初の1回のみとしています)
※以下実行例は、1) の続きで記述しています。^%SYSMONMGRの実行から始めている場合は、5) Manage Application Monitor 選択後の画面から開始してください。
ドキュメントは以下ご参照ください。Manage Alerts【IRIS】Manage Alerts
1) Set Sample Interval
2) Manage Monitor Classes
3) Change Default Notification Method
4) Manage Email Options
5) Manage Alerts
6) Exit
Option? 5 → 5 を入力してEnter押下
1) Create Alert
2) Edit Alert
3) List Alerts
4) Delete Alert
5) Enable/Disable Alert
6) Clear NotifyOnce Alert
7) Exit
Option? 1 → 1 を入力してEnter押下
Alert name? test disk free space alert → 任意のアラート名を入力してEnter押下
Application? %SYS (Enter '-' to reset) => → Enter押下
Action (0=default,1=email,2=method)? 0 => 1 → 1 を入力してEnter押下
Raise this alert during sampling? Yes => yes → yes を入力してEnter押下
Class? ? → ? を入力してEnter押下
Num MetricsClassName Activated
1) %Monitor.System.HistoryMemory N
2) %Monitor.System.HistoryPerf N
3) %Monitor.System.HistorySys N
4) %Monitor.System.HistoryUser N
5) %Monitor.System.AuditCount N
6) %Monitor.System.AuditEvents N
7) %Monitor.System.Clients N
8) %Monitor.System.Diskspace Y
9) %Monitor.System.Freespace N
10) %Monitor.System.Globals N
11) %Monitor.System.Journals N
12) %Monitor.System.License N
13) %Monitor.System.LockTable N
14) %Monitor.System.Processes N
15) %Monitor.System.Routines N
16) %Monitor.System.Servers N
17) %Monitor.System.SystemMetrics N
18) %Monitor.System.CSPGateway N
Class? 8 %Monitor.System.Diskspace → 上のリストの 8 を指定してEnter押下
Property? ? → ? を入力してEnter押下
Num Name Activated
1) Database Y
2) Directory Y
3) Diskspace Y
4) Diskstatus Y
Property? 3 Diskspace → 上のリストの 3 を指定してEnter押下
Property? Properties list: Diskspace
Evaluation expression (e.g., "%1=99")? %1<100 ←MB単位に指定します。例では「100MB未満の場合アラート」を指定してEnter押下
Expression expands to: If Diskspace<100. OK? Yes => Yes → Yes を入力してEnter押下
Notify once only? No => yes → yes を入力してEnter押下
1) Create Alert
2) Edit Alert
3) List Alerts
4) Delete Alert
5) Enable/Disable Alert
6) Clear NotifyOnce Alert
7) Exit
Option? →Enter押下(前のメニューに戻ります)
1) Set Sample Interval
2) Manage Monitor Classes
3) Change Default Notification Method
4) Manage Email Options
5) Manage Alerts
6) Exit
Option? →Enter押下(前のメニューに戻ります)
3) Email通知設定を行う
以下の例では、gmail を利用する例をご紹介しています。gmail は SSL構成を事前に作成する必要があります。管理ポータルの以下メニューから事前に作成してください。
管理ポータル > システム管理 > セキュリティ管理 > SSL/TLS構成
※ 構成名以外はデフォルト値を利用します。
※以下実行例は、2)の続きで記述しています。^%SYSMONMGR の実行から始めている場合は、5) Manage Application Monitor 選択後の画面から開始してください。
ドキュメントは以下ご参照ください。Manage Email Options【IRIS】Manage Email Options
1) Start/Stop System Monitor
2) Set System Monitor Options
3) Configure System Monitor Classes
4) View System Monitor State
5) Manage Application Monitor
6) Manage Health Monitor
7) View System Data
8) Exit
Option? 5 → 5 を入力してEnter押下
1) Set Sample Interval
2) Manage Monitor Classes
3) Change Default Notification Method
4) Manage Email Options
5) Manage Alerts
6) Exit
Option? 4 → 4 を入力してEnter押下
1) Enable/Disable Email
2) Set Sender
3) Set Server
4) Manage Recipients
5) Set Authorization
6) Test Email
7) Exit
Option? 3 → 3 を入力してEnter押下
Mail server? smtp.gmail.com → メールサーバを入力してEnter押下
Mail server port? 587 → メールサーバのポート番号を入力してEnter押下
Mail server SSLConfiguration? gmail → 管理ポータルで設定したSSL構成名を入力してEnter押下
Mail server UseSTARTTLS? 0 => 1 → 1を入力してEnter押下
1) Enable/Disable Email
2) Set Sender
3) Set Server
4) Manage Recipients
5) Set Authorization
6) Test Email
7) Exit
Option? 2 → 2 を入力してEnter押下
Sender? sendertest@gmail.com → 差出人のメールアドレスを入力してEnter押下
1) Enable/Disable Email
2) Set Sender
3) Set Server
4) Manage Recipients
5) Set Authorization
6) Test Email
7) Exit
Option? 5 → 5 を入力してEnter押下
User name? xxxabctestaccount@gmail.com → 認証用アカウント名を入力してEnter押下
Password? → パスワードを入力してEnter押下
1) Enable/Disable Email
2) Set Sender
3) Set Server
4) Manage Recipients
5) Set Authorization
6) Test Email
7) Exit
Option? 4 → 4 を入力してEnter押下
1) List Recipients
2) Add Recipient
3) Remove Recipient
4) Exit
Option? 2 → 2 を入力してEnter押下
Email Address? abc@testcorp.com → 送信先メールアドレスを入力してEnter押下
1) List Recipients
2) Add Recipient
3) Remove Recipient
4) Exit
Option? →Enter押下(前のメニューに戻ります)
1) Enable/Disable Email
2) Set Sender
3) Set Server
4) Manage Recipients
5) Set Authorization
6) Test Email
7) Exit
Option? 1 → 1 を入力してEnter押下
Email is currently OFF
Change Email setting? No => yes → yes を入力してEnter押下
1) Enable/Disable Email
2) Set Sender
3) Set Server
4) Manage Recipients
5) Set Authorization
6) Test Email
7) Exit
Option? 6 → 6 を入力してEnter押下
Sending email on Mail Server smtp.gmail.com
From: sendertest@gmail.com
To: abc@testcorp.com
1) Enable/Disable Email
2) Set Sender
3) Set Server
4) Manage Recipients
5) Set Authorization
6) Test Email
7) Exit
Option? →Enter押下(前のメニューに戻ります)
1) Set Sample Interval
2) Manage Monitor Classes
3) Change Default Notification Method
4) Manage Email Options
5) Manage Alerts
6) Exit
Option? →Enter押下(前のメニューに戻ります)
1) Start/Stop System Monitor
2) Set System Monitor Options
3) Configure System Monitor Classes
4) View System Monitor State
5) Manage Application Monitor
6) Manage Health Monitor
7) View System Data
8) Exit
Option? →Enter押下(前のメニューに戻ります)
4) システムモニタを再起動する
設定を反映させるため、システムモニタを一度停止し、開始します。
ドキュメントは以下ご参照ください。Start/Stop System Monitor【IRIS】Start/Stop System Monitor
%SYS>do ^%SYSMONMGR
1) Start/Stop System Monitor
2) Set System Monitor Options
3) Configure System Monitor Classes
4) View System Monitor State
5) Manage Application Monitor
6) Manage Health Monitor
7) View System Data
8) Exit
Option? 1 → 1 を入力してEnter押下
1) Start System Monitor
2) Stop System Monitor
3) Exit
Option? 2 → 2 を入力してEnter押下
Stopping System Monitor... System Monitor stopped
1) Start System Monitor
2) Stop System Monitor
3) Exit
Option? 1 → 1 を入力してEnter押下
Starting System Monitor... System Monitor started
1) Start System Monitor
2) Stop System Monitor
3) Exit
Option? →Enter押下(前のメニューに戻ります)
1) Start/Stop System Monitor
2) Set System Monitor Options
3) Configure System Monitor Classes
4) View System Monitor State
5) Manage Application Monitor
6) Manage Health Monitor
7) View System Data
8) Exit
Option? →Enter押下(ネームスペースのプロンプトに戻ります)
%SYS>
この記事に関連する記事もあります。以下ご参照ください。
SYS.Database クラスの FreeSpace クエリを使用してデータベースのあるディスクの空き容量を確認する方法
記事
Toshihiko Minamoto · 2022年10月25日
私が一番興味を持っているのは、組み込み Python におけるグローバルの使用についてです。そこで、提供されている公式ドキュメントを確認しました。
#1 グローバルの導入グローバルとは何かについての一般的な説明。 次の章につながっています。
#2 ObjectScript の詳細について組み込み Python の記述はありません。さらに先に進むと...
#3 組み込み Python
3.1 組み込み Python の概要3.1.1 グローバルの使用グローバルを使ったことなければ、素晴らしい内容です。が、驚くほど原始的な例が使われています。3.2 組み込み Python の使用最後の望み: >>> でも、目に見えるものが何もありません。残念どころではありません! Python 用の IRIS Native API でさえ、もっと説明されています。何を期待していたかと言うと...
グローバルノードの SET、GET、KILL
Native API: 基本的なノード操作 そして
$DATA()、$ORDER()、$QUERY() によるナビゲーション
Native API: nextSubscript() と isDefined() によるイテレーションそこで、自分で調査し、リバースエンジニアリングを行って、実験しなければなりませんでした。
そしてわかったこと:
すべての例は IRIS for Windows (x86-64) 2022.1 (Build 209U) にある Python Shell で説明されており、暗黙的な print() 関数を集中的に使用している。
グローバル
何をするにも、iris.gref クラスを使って、グローバルの参照オブジェクトを作成することから始める必要があります。グローバル名は、直接文字列として、またはCOS/ISOS の間接式のように変数として渡されます。グローバルを扱っていることが明確であるため、最初のキャレット (^) は不要です!
>>> globalname='rcc'
>>> nglob=iris.gref(globalname)
>>> glob=iris.gref('rcc')
>>> cglob=iris.gref('^rcc')
上記は、同じグローバルへの 3 つのグローバル参照です。単なる参照であり、このグローバルが存在するかことを示すものではありません。
対話式ドキュメント: print(glob.__doc__)InterSystems IRIS グローバル参照オブジェクト。グローバルへの参照を取得するには、iris.gref() メソッドを使用します。
サブスクリプト
すべてのグローバルサブスクリプトは、Py リストの [sub1,sub2] として渡されます。 COS/ISOS とあまり変わりません。トップレベルに特別な処理が必要なだけです。サブスクリプトなしを示すには、空のリストではなく、この [None] を使用します。
SET
グローバルを設定するには、COS/ISOS と同様に「直接」行うことができます。
>>> glob[1,1]=11
または、gref.set() メソッドを使用することもできます。
>>> glob.set([1,3],13)
対話式ドキュメント: print(glob.set.__doc__)グローバルのキーが指定されている場合、グローバルのそのキーに格納された値を設定します。 例: g.set([i,j], 10) は、グローバル g のキー i,j にあるノードの値を 10 に設定します。
グローバルノードのコンテンツにアクセスするには、COS/ISOS と同様に「直接」行うことができます。
>>> glob[1,3]
13
または、gref.get() メソッドを使用することもできます。
>>> glob.get([1,1])
11
対話式ドキュメント: print(glob.get.__doc__)グローバルのキーが指定されている場合、グローバルのそのノードに格納された値を返します。例: x = g.get([i,j]) は x を、グローバル g のキー i,j に格納された値に設定します。
注意: これは COS/ISOS の $GET() ではありません。
>>> glob.get([1,99])
Traceback (most recent call last):
File "", line 1, in <module>
KeyError: 'Global Undefined'
>>>
ただし、直接使用すると、COS/ISOS の $GET() のように動作します。
>>> x=glob[1,99]
>>> print(x)
None
>>>
この None は、SQL が表現するところの NULL を指します。 後で、もう一度出現します。
KILL
期待される結果を達成する gref.kill() メソッドのみがあります。
>>> glob.kill([1,3])
>>> y=glob[1,3]
>>> print(y)
None
>>>
対話式ドキュメント: print(glob.kill.__doc__)グローバルのキーが指定されている場合、グローバルのそのノードとサブツリーをキルします。例: g.kill([i,j]) は、グローバル g のキー i,j に格納されたノードとその子孫ノードをキルします。
$DATA()
関連するメソッドは gref.data() です。対話式ドキュメント: print(glob.data.__doc__)グローバルのキーが指定されている場合、その状態を返します。例: x = g.data([i,j]) は x を 0、1、10、11 に設定します。 0-if が未定義、1-定義済み、10-未定義で子孫あり、11-値と子孫あり期待どおりに動作します。
>>> glob.data()
10
>>> glob.data([None])
10
>>> glob[None]=9
>>> glob.data([None])
11
>>> glob.data([1,1])
1
>>> glob.data([1,3])
0
>>>
$ORDER()
この例では、グローバル ^rcc にノードをいくつか追加しました。
>zw ^rcc
^rcc=9
^rcc(1,1)=11
^rcc(1,2)=12
^rcc(2,3,4)=234
^rcc(2,3,5)=235
^rcc(2,4,4)=244
^rcc(7)=7
関連するメソッドは gref.order() です。対話式ドキュメント: print(glob.order.__doc__)グローバルのキーが指定されている場合、そのグローバルの次のキーを返します。例: j = g.order([i,j]) は j を、グローバル g の次の第 2 レベルのキーに設定します。つまり、以下のようになります。
>>> print(glob.order([]))
1
>>> print(glob.order([1]))
2
>>> print(glob.order([2]))
7
>>> print(glob.order([7]))
None
>>> print(glob.order([1,'']))
1
>>> print(glob.order([1,1]))
2
>>> print(glob.order([2,3,]))
4
>>> print(glob.order([2,3,""]))
4
>>> print(glob.order([2,3,4]))
5
>>> print(glob.order([2,4,4]))
None
>>>
ここでは、参照として欠落しているサブスクリプトまたは空の文字列は同等です。
$QUERY()
関連するメソッドは gref.query() です。対話式ドキュメント: print(glob.query.__doc__)指定されたキーからグローバルをトラバースし、各キーと値をタプルとして返します。例: for (key, value) in g.query([i,j]) は、キー i,j から g をトラバースし、各キーと値を返します。
このメソッドの動作は COS/ISOS と異なります。
開始ノード以降のすべてのノードを返します。
格納されたコンテンツを含めます。
None と示されているコンテンツのない仮想ノードも返します。 ここでの小さな例は、次のようになります(読みやすいように囲んでいます)。
>>> print(list(glob.query()))
[(['1'], None), (['1', '1'], 11), (['1', '2'], 12), (['2'], None),
(['2', '3'], None), (['2', '3', '4'], 234), (['2', '3', '5'], 235),
(['2', '4'], None), (['2', '4', '4'], 244), (['7'], 7)]
>>>
もっと読みやすくすると、次のようになります。
>>> for (key, value) in glob.query():
... print(key,''.ljust(20-len(str(list(key))),'>'),value)
...
['1'] >>>>>>>>>>>>>>> None
['1', '1'] >>>>>>>>>> 11
['1', '2'] >>>>>>>>>> 12
['2'] >>>>>>>>>>>>>>> None
['2', '3'] >>>>>>>>>> None
['2', '3', '4'] >>>>> 234
['2', '3', '5'] >>>>> 235
['2', '4'] >>>>>>>>>> None
['2', '4', '4'] >>>>> 244
['7'] >>>>>>>>>>>>>>> 7
>>>
絶対に ZWRITE ではありません!
もう 1 つのオプションは、gref.keys() のみを使用してサブスクリプトを取得する方法です。対話式ドキュメント: print(glob.keys.__doc__)指定されたキーからグローバルをトラバースし、そのグローバルの各キーを返します。例: for key in g.keys([i, j]) は、キー i,j から g をトラバースし、各キーを返します。 >>>
>>> list(glob.keys())
[['1'], ['1', '1'], ['1', '2'], ['2'], ['2', '3'], ['2', '3', '4'],
['2', '3', '5'], ['2', '4'], ['2', '4', '4'], ['7']]
>>>
そして、これで gref.orderiter() を見つけました。対話式ドキュメント: print(glob.orderiter.__doc__)指定されたキーからグローバルをトラバースし、次のキーと値をタプルとして返します。例: for (key, value) in g.orderiter([i,j]) は、キー i,j から g をトラバースし、次のキーと値を返します。
$QUERY() のようにコンテンツをフェッチして、そのコンテンツを次のサブノードに提供することも行う $ORDER() のように動作します。以下を見てください。
>>> list(glob.orderiter([]))
[(['1'], None), (['1', '1'], 11)]
>>> list(glob.orderiter([1]))
[(['2'], None), (['2', '3'], None), (['2', '3', '4'], 234)]
>>> list(glob.orderiter([2]))
[(['7'], 7)]
>>>
最後に、gref.getAsBytes() メソッドがあります。対話式ドキュメント: print(glob.getAsBytes.__doc__)グローバルのキーが指定されている場合、そのグローバルのそのノードに格納されている文字列をバイトで返します。例: x = g.getAsBytes([i,j]) は x をグローバル g のキー i,j に格納されている値をバイトとして設定します。
数値には失敗しますが、 文字列には有効です。
>>> glob[5]="robert"
>>> glob.get([5])
'robert'
>>> glob.getAsBytes([5])
b'robert'
また、COS/ISOS で set ^rcc(9)=$lB(99,"robert") を実行すると以下のようになります。
>>> glob[9]
'\x03\x04c\x08\x01robert'
>>> glob.getAsBytes([9])
b'\x03\x04c\x08\x01robert'
>>>
これらのメソッドを以下のようにして検出しました。
>>> for meth in glob.__dir__():
... meth
...
'__len__'
'__getitem__'
'__setitem__'
'__delitem__'
'__new__'
'data'
'get'
'set'
'kill'
'getAsBytes'
'order'
'query'
'orderiter'
'keys'
'__doc__'
'__repr__'
'__hash__'
'__str__'
'__getattribute__'
'__setattr__'
'__delattr__'
'__lt__'
'__le__'
'__eq__'
'__ne__'
'__gt__'
'__ge__'
'__init__'
'__reduce_ex__'
'__reduce__'
'__subclasshook__'
'__init_subclass__'
'__format__'
'__sizeof__'
'__dir__'
'__class__'
>>>
これで、組み込み Python からグローバルに直接アクセスする必要がある場合に、作業が楽になることを願っています。個人的に学んだこと: ほとんどの場合に、ドキュメントがあります。 . . . どこにあるかは別ですが。ただ、探し回る必要があるだけです。
動画デモ
Traduction française
記事
Tomohiro Iwamoto · 2020年12月10日
この記事は、GitHub Actions を使って GKE に InterSystems IRIS Solution をデプロイするの継続記事で、そこではGitHub Actions パイプラインを使って、 Terraform で作成された Google Kubernetes クラスタにzpm-registry をデプロイしています。 繰り返しにならないよう、次の項目を満たしたものを開始点とします。
訳者注) 上記の記事を読まれてから、本記事に進まれることをお勧めしますが、GKE上のサービスにドメイン名を紐づける方法を解説した単独記事としてもお読みいただけます。
リポジトリ Github Actions + GKE + zpm example をフォーク済みで、フォークでの Actions を許可していること。 この記事を通して、ルートディレクトリは <root_repo_dir>として参照されます。
Terraform ファイルのプレースホルダを置換済みであること。
GitHub Actions を使って GKE に InterSystems IRIS Solution をデプロイする の唯一の表に記載されているすべてのシークレットを(GitHub Actions Secrets ページで)作成済みであること。
コピーペースト作業を単純化するために、すべてのコードサンプルが、GitHub-GKE-TLS リポジトリに保存されるようになっていること。
上記のすべてを満たしていることを前提に、先に進みましょう。
はじめに
前回、zpm-registry への接続は、次のように行いました。
curl -XGET -u _system:SYS 104.199.6.32:52773/registry/packages/-/all
IP アドレスの前にプロトコルがない場合は HTTP を使用していることを示します。つまり、トラフィックは非暗号化であるため、かの悪名高いイブ によってパスワードを盗み聞きされる可能性があります。
イブが盗聴できないようにするには、トラフィックを暗号化する、つまり HTTPS を使用する必要があります。 それは可能なことなのでしょうか。
104.199.6.32:52773/registry/packages → https://104.199.6.32:52773/registry/packages
概して言えば、可能です。 IP アドレスの証明書を取得すればよいのですが、 このソリューションには欠点があります。 詳細については、Using an IP Address in an SSL Certificate と SSL for IP Address を読んでいただきたいのですが、 要約すると、静的 IP アドレスが必要であり、その機能を備えた証明書プロバイダーは無料ではありません。 メリットについても、疑わしい部分があります。
一般的な無料プロバイダーは、9 Best Free SSL Certificate Sources にも紹介されているように、幸いにも存在はします。 その 1 つは Let’s Encrypt ですが、証明書を発行するのはドメイン名に対してのみです。ちなみに、証明書に IP アドレスを追加する計画は上がってはいます。
したがって、トラフィックを暗号化するには、まず、ドメイン名を取得する必要があります。 ドメイン名をすでにお持ちの方は、次のセクションにスキップしてください。
ドメイン名の取得
ドメインレジストラからドメイン名を購入します。 かなりの数のレジストラが存在し、 価格はドメイン名やサービスレベルによって異なります。 開発の目的には、たとえば .dev のドメインを使うことができますし、おそらく安価でもあります。
ここでは、ドメイン登録プロセスには触れませんが、それほど複雑なものではありません。これ以降では、登録済みのドメイン名を example.com として説明することにします。 これを自分のドメインに置き換えてください。
ドメイン登録プロセスが完了すると、ドメイン名とドメインゾーンを得られますが、 これらは別々のものとして考える必要があります。 Definition - Domains vs. Zones の説明と短い DNS Zones の動画を見て、この違いを理解してください。
簡単に説明すると、ドメインを組織と考えた場合、ゾーンはその組織内の部署として捉えることができます。 このチュートリアルでは、ドメインは example.com であり、ゾーンも同様に example.com と呼んでいます。 (小さな組織では、部署が 1 つしかない場合があります。) 各 DNS ゾーンには、ゾーン内の IP アドレスとドメイン名を認識する特別なサーバーが必要です。 これらのリンクは、リソースレコード(RR)と呼ばれており、 それぞれに種類が異なる場合があります(DNS Record types をご覧ください)。 最も広く使用されているのは、A レコードです。
「ネームサーバー」は、ドメインレジストラが提供する特別なサーバーです。 たとえば、私が契約しているレジストラからは、次の 2 つのネームサーバーが提供されています。
ns39.domaincontrol.com
ns40.domaincontrol.com
次のようなリソースレコード(サーバードメイン名 = IP アドレス)を作成する必要があります。
zpm.example.com = 104.199.6.32
これは、ゾーン example.com に A レコードを作成して行います。 このレコードを保存すると、世界中にあるほかの DNS サーバーによってこの更新内容が認識され、最終的に、 zpm-registry を zpm.example.com:52773/registry/ という名前で参照できるようになります。
ドメインと kubernetes
覚えているかと思いますが、zpm サービスの IP アドレスは、Kubernetes Service(Load Balancer タイプ)をデプロイ中に作成されました。 zpm-registry を試して削除した後にもう一度 zpm-registry をデプロイすることにした場合は、別の IP アドレスが割り当てられる可能性があります。 その場合は、もう一度 DNS レジストラの Web コンソールにアクセスして、zpm.example.com の IP アドレスを新たに設定してください。
これには、もう 1 つの方法があります。 Kubernetes のデプロイ中に、External DNS という、Kubernetes Services または Ingress から新しく作成された IP アドレスを取得して対応する DNS レコードを作成する、ヘルパーツールをデプロイできます。 このツールはすべてのレジストラをサポートしているわけではありませんが、DNS ゾーン、ネームサーバーの提供、およびリソースレコードの保存を行える、Google Cloud DNS をサポートしています。
Google Cloud DNS を使用するには、レジストラの Web コンソールで、DNS ゾーンの example.com の管理を Google Cloud DNS に移行する必要があります。 これを行うには、ドメインレジストラが提供したネームサーバーを Google Cloud DNS が提供するものに変更します。 Google コンソールに example.com ゾーンを作成し、Google が提供するネームサーバーをコピーして貼り付けてください。 詳細は以下を参照してください。
コードに外部 DNS を追加して Google Cloud DNS を作成する方法を見てみましょう。 ただし、スペースを節約するために、ここではコードの一部のみを記載します。 前述のとおり、完全なサンプルは、 GitHub GKE TLS リポジトリにあります。
外部 DNS の追加
このアプリケーションを GKE にデプロイするには、Helm を利用します。 これについては、「An Introduction to Helm, the Package Manager for Kubernetes」と公式ドキュメント が役立つでしょう。
パイプラインファイルの「kubernetes-deploy」ステージの最後のジョブとして、次の行を追加してください。 また、「env」セクションには、新しい変数もいくつか追加します。
$ cat <root_repo_dir>/.github/workflows/workflow.yaml
...
env:
...
DNS_ZONE: example.com
HELM_VERSION: 3.1.1
EXTERNAL_DNS_CHART_VERSION: 2.20.6
...
jobs:
...
kubernetes-deploy:
...
steps:
...
- name: Install External DNS run: |
wget -q https://get.helm.sh/helm-v${HELM_VERSION}-linux-amd64.tar.gz
tar -zxvf helm-v${HELM_VERSION}-linux-amd64.tar.gz cd linux-amd64
./helm version
./helm repo add bitnami https://charts.bitnami.com/bitnami
gcloud container clusters get-credentials ${GKE_CLUSTER} --zone ${GKE_ZONE} --project ${PROJECT_ID}
echo ${GOOGLE_CREDENTIALS} > ./credentials.json
kubectl create secret generic external-dns --from-file=./credentials.json --dry-run -o yaml | kubectl apply -f -
./helm upgrade external-dns bitnami/external-dns \
--install \
--atomic \
--version=${EXTERNAL_DNS_CHART_VERSION} \
--set provider=google \
--set google.project=${PROJECT_ID} \
--set google.serviceAccountSecret=external-dns \
--set registry=txt \
--set txtOwnerId=k8s \
--set policy=sync \
--set domainFilters={${DNS_ZONE}} \
--set rbac.create=true
--set が設定するパラメータについては、External DNS チャートのドキュメントを参照してください。 とりあえず上記の行を追加して、次に進みましょう。
クラウド DNS の作成
まず、<root_repo_dir>/terraform/ ディレクトリに新しいファイルを追加します。 あなたのドメインゾーンを使用してください。
$ cat <root_repo_dir>/terraform/clouddns.tf
resource "google_dns_managed_zone" "my-zone" {
name = "zpm-zone"
dns_name = "example.com."
description = "My DNS zone"
}
また、Terraform に代わって機能するユーザーには、少なくとも次のロールが与えられていることを確認してください(DNS 管理者および Kubernetes Engine 管理者ロールに注意してください)。
GitHub Actions パイプラインを実行している場合は、これらが作成されます。 External DNS とCloud DNS の準備ができたら(実質的に準備できた時点で)、zpm-service をロードバランサーサービスタイプとは異なる方法で公開する方法を検討できるようになります。
Kubernetes
zpm-service は、通常の Kubernetes サービスロードバランサーを使って公開されています。 ファイル <root_repo_dir>/k8s/service.yaml を参照してください。 Kubernetes Service についての詳細は、「Service を使用したアプリケーションの公開」をお読みください。 重要なのは、ロードバランサーサービスにはドメイン名を設定する機能がないため、Kubernetes Services リソースが作成した実際の Google ロードバランサーが TCP/UDP レベルの OSI を操作するということです。 このレベルは、HTTP と証明書について何も関知していないため、 Google ネットワークロードバランサーを HTTP ロードバランサーに置き換える必要があります。 このようなロードバランサーを作るには、Kubernetes Service の代わりに Kubernetes Ingress リソースを使用できます。
ここで、「Kubernetes NodePort vs LoadBalancer vs Ingress? When should I use what?」を読んでおくと良いでしょう。
では、先に進みましょう。 コードでの Ingress の使用とはどいうことでしょうか。 <root_repo_dir>/k8s/ ディレクトリに移動し、次の変更を行います。 Service のタイプは NodePort です。
$ cat <root_repo_dir>/k8s/service.yaml
apiVersion: v1
kind: Service
metadata:
name: zpm-registry
namespace: iris
spec:
selector:
app: zpm-registry
ports:
- protocol: TCP
port: 52773
targetPort: 52773
type: NodePort
次に、Ingress マニフェストを追加する必要があります。
$ cat <root_repo_dir>/k8s/ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: gce
networking.gke.io/managed-certificates: zpm-registry-certificate
external-dns.alpha.kubernetes.io/hostname: zpm.example.com
name: zpm-registry
namespace: iris
spec:
rules:
- host: zpm.example.com
http:
paths:
- backend:
serviceName: zpm-registry
servicePort: 52773
path: /*
また、太字で示されている行をワークフローファイルに追加します。
$ cat <root_repo_dir>/.github/workflows/workflow.yaml
...
- name: Apply Kubernetes manifests
working-directory: ./k8s/
...
kubectl apply -f service.yaml
kubectl apply -f ingress.yaml
このマニフェストをデプロイすると、Google Cloud コントローラによって、外部 HTTP ロードバランサーが作成されます。これは、ホストである zpm.example.com へのトラフィックをリスンし、このトラフィックを、Kubernetes NodePort Service デプロイ中に開かれたポート経由で、すべての Kubernetes ノードに送信します。 このポートは任意ですが、完全に自動化されているため、気にする必要はありません。
アノテーションを使用すると、Ingress のより詳細な構成を定義することができます。
annotations:
kubernetes.io/ingress.class: gce
networking.gke.io/managed-certificates: zpm-registry-certificate
external-dns.alpha.kubernetes.io/hostname: zpm.example.com
最初の行は、"gce" Ingress コントローラを使用することを示します。 このエンティティは、Ingress リソースに従って HTTP ロードバランサーを作成します。
2 行目は、証明書に関連する行です。 この設定については、後で説明します。
3 行目は、指定されたホスト名(zpm.example.com)を HTTP ロードバランサーの IP アドレスにバインドする外部 DNS を設定します。
このマニフェストを実装した場合、(約 10 分後に)Ingress が作成されてはいても、ほかのすべてが機能しているわけではないことがわかります。
"Backend services"とは何でしょうか。このうちの 1 つはうまく機能していないようです。
"k8s-be-31407-..." や "k8s-be-31445-..."などの名前がありますか? これらは、1 つの Kubernetes ノードで開かれているポートです。 ポートの番号はそれぞれ異なります。
31407 は、ヘルスチェック用に開かれているポートで、ノードが連続してアライブであるように、HTTP ロードバランサーが送信するポートです。
Kubernetes に接続して、ノードポート 31407 をプロキシすると、ヘルスチェックの結果を確認できます。
$ gcloud container clusters get-credentials <CLUSTER_NAME> --zone <LOCATION> --project <PROJECT_ID>
$ kubectl proxy &
$ curl localhost:8001/healthz
ok
$ fg
^Ctrl+C
もう 1 つの 31445 ポートは、zpm-registry サービス用に開かれている NodePort です。
$ kubectl -n iris get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
zpm-registry NodePort 10.23.255.89 <NONE> 52773:31445/TCP 24m
また、デフォルトのヘルスチェックでは、HTTPロードバランサーはこのサービスが停止しているというレポートを送信します。 本当にそうなのでしょうか?
それらのヘルスチェックの詳細を確認する必要があります。 Backend service 名をクリックし、 下に少しスクロールして、ヘルスチェック名を確認してください。
詳細を確認するには、ヘルスチェック名をクリックします。
ヘルスチェックの "/" パスを "/csp/sys/UtilHome.csp" のように、IRIS が理解できるパスに置き換える必要があります。
$ curl -I localhost:52773/csp/sys/UtilHome.csp
Handling connection for 52773
HTTP/1.1 200 OK
では、ヘルスチェックに新しいパスを設定するには、どうすればよいのでしょうか。 デフォルトの "/" パスが存在する場合は、その代わりに、Readiness/Liveness probesを使用してください。
Kubernetes StatefulSet マニフェストにプローブを追加してみましょう。
$ cat <root_repo_dir>/k8s/statefulset.tpl
...
containers:
- image: DOCKER_REPO_NAME:DOCKER_IMAGE_TAG
...
ports:
- containerPort: 52773
name: web
readinessProbe:
httpGet:
path: /csp/sys/UtilHome.csp
port: 52773
initialDelaySeconds: 10
periodSeconds: 10
livenessProbe:
httpGet:
path: /csp/sys/UtilHome.csp
port: 52773
periodSeconds: 10
volumeMounts:
- mountPath: /opt/zpm/REGISTRY-DATA
name: zpm-registry-volume
- mountPath: /mount-helper
name: mount-helper
ここまでで、いくつかの変更を加えて、メインイベントである証明書への扉を開くことができました。 では、ラストスパートに取り掛かるとしましょう。
証明書の取得
Kubernetes の SSL/TLS 証明書を取得するさまざまな方法を説明した次の動画をぜひご覧ください。
Create a Kubernetes TLS Ingress from scratch in Minikube
Automatically Provision TLS Certificates in K8s with cert-manager
Use cert-manager with Let's Encrypt® Certificates Tutorial: Automatic Browser-Trusted HTTPS
Super easy new way to add HTTPS to Kubernetes apps with ManagedCertificates on GKE
要約すると、証明書を取得するにはいくつかの方法があり、openssl 自己証明書、Let’s Encrypt の certbot(手動)、Let's Encrypt に接続した cert-manager(自動)、そしてネイティブの Google アプローチである Managed Certificate を使用できます。ここでは、単純にするために、最後の Managed Certificate を使用します。
では追加しましょう。
$ cat <root_repo_dir>/k8s/managed-certificate.yaml
apiVersion: networking.gke.io/v1beta1
kind: ManagedCertificate
metadata:
name: zpm-registry-certificate
namespace: iris
spec:
domains:
- zpm.example.com
太字で示された行をデプロイパイプラインに追加します。
$ cat <root_repo_dir>/.github/workflows/workflow.yaml
...
- name: Apply Kubernetes manifests
working-directory: ./k8s/
run: |
gcloud container clusters get-credentials ${GKE_CLUSTER} --zone ${GKE_ZONE} --project ${PROJECT_ID}
kubectl apply -f namespace.yaml
kubectl apply -f managed-certificate.yaml
kubectl apply -f service.yaml
...
Ingress での有効化は、Ingress アノテーションとして先に行いましたが、覚えていますか?
$ cat <root_repo_dir>/k8s/ingress.yaml
...
annotations:
kubernetes.io/ingress.class: gce
networking.gke.io/managed-certificates: zpm-registry-certificate
...
これで、すべての変更をリポジトリにプッシュする準備が整いました。
$ git add .github/ terraform/ k8s/$ git commit -m "Add TLS to GKE deploy"$ git push
15 分ほどすると(クラスタプロビジョニングを実行する必要があります)、「緑信号」の Ingress を確認できるでしょう。
次に、Google が提供した少なくとも 2 つのネームサーバーをドメイン名レジストラコンソールで設定する必要があります(Google Domains 以外のレジストラを使用している場合)。
このプロセスはレジストラによって異なるため、ここでは説明しません。通常、レジストラのドキュメントで詳しく説明されています。
Google は、External DNS が自動的に作成した新しいリソースレコードをすでに認識しています。
$ dig +short @ns-cloud-b1.googledomains.com. zpm.example.com34.102.202.2
このレコードが世界中に伝搬されるまでにはしばらく時間がかかりますが、 とはいえ、最終的には次のようになります。
$ dig +short zpm.example.com34.102.202.2
証明書のステータスを確認することをお勧めします。
$ gcloud container clusters get-credentials <CLUSTER_NAME> --zone <LOCATION> --project <PROJECT_ID>
$ kubectl -n iris get managedcertificate zpm-registry-certificate -ojson | jq '.status'
{
"certificateName": "mcrt-158f20bb-cdd3-451d-8cb1-4a172244c14f",
"certificateStatus": "Provisioning",
"domainStatus": [
{
"domain": "zpm.myardyas.online",
"status": "Provisioning"
}
]
}
さまざまなステータスの意味については、「Google マネージド SSL 証明書の使用」のページをご覧ください。 証明書を初めてプロビジョニングする場合は、1 時間ほどかかることがあります。
domainStatus "FailedNotVisible" が発生することがありますが、 この場合は、Google ネームサーバーを DNS レジストラコンソールで実際に追加していることを確認してください。
certificateStatus と domainStatus の両方が利用可能になるまで待つことをお勧めします。「Google マネージド SSL 証明書の使用」で説明されているとおり、しばらく時間がかかることがありますが、 最終的には、次のようにして zpm-registry を呼び出せるようになるでしょう。
curl -XGET -u _system:SYS https://zpm.example.com/registry/packages/-/all
まとめ
Google は、Kubernetes リソースに基づいて、必要なすべての Google リソースを作成することに長けています。
また、Google マネージド証明書は、証明書の取得を大幅に単純化できる優れた機能です。
Google リソース(GKE、CloudDNS)の維持には費用が掛かります。そのため、いつものように不要になったら忘れずに削除するようにしてください。
記事
Shintaro Kaminaka · 2021年4月19日
開発者の皆さん、こんにちは。
このシリーズでは、IRIS for Healthの使い方ではなく、関連技術として、FHIRプロファイル作成ツールであるSUSHIの握り方使い方を紹介していきたいと思います。
このツールをうまく使うことで、FHIRプロジェクトのプロファイル情報(仕様や制限、拡張などの情報)をうまく整理し、公開することができます。
その前にSUSHIとは何でしょうか?簡単にですが、順番に説明していきたいと思います。
## FHIR って?
**FHIR**とは _Fast Healthcare Interoperability Resources_ の略であり、Web通信の一般的技術であるRESTを使用して、可読性が高く取り扱いがし易いJSON/XML形式の�データの集合(=リソース)をやり取りする短期間で実装可能な**医療情報交換標準規格**、という定義になっています。
簡単に言えば、医療のデータの表現方法として皆で共通したフォーマットを使うことによって、システム間や施設間などでの情報の伝達や交換をやりやすいようにしよう!ということですね。
FHIRには様々な[リソース](http://hl7.org/fhir/resourcelist.html)が定義されています。例えば患者さんの情報には[Patientリソース](http://hl7.org/fhir/patient.html)という定義があり、これを使って表現されます。
FHIR公式サイトには多くの[サンプル](http://hl7.org/fhir/patient-examples.html)が掲載されていますので、一部抜粋してみます。
例えばこのようなJSON形式で表現されます。患者番号(Identifier)、氏名(name)、性別(gender)などが表現されています。
```
{
"resourceType": "Patient",
"id": "pat1",
"text": {
"status": "generated",
"div": "\n \n Patient Donald DUCK @ Acme Healthcare, Inc. MR = 654321\n \n "
},
"identifier": [
{
"use": "usual",
"type": {
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/v2-0203",
"code": "MR"
}
]
},
"system": "urn:oid:0.1.2.3.4.5.6.7",
"value": "654321"
}
],
"active": true,
"name": [
{
"use": "official",
"family": "Donald",
"given": [
"Duck"
]
}
],
"gender": "male",
"以下略"
}
```
## FHIRプロファイルって?
FHIRではJSONやXMLという表現形式だけではなく、何の情報をどのようなJSONキー名称で記載するか、どのようなコードを使用するか、どのような構造で表現するかいった決まりが存在します。それを[FHIRプロファイル](http://hl7.org/fhir/profiling.html)と呼んでいます。
プロファイルは用語として色々な意味で使われています。
広義では・・・
FHIRリソースおよびFHIRサーバに関する制約の定義の集合。それを表すアーティファクト(成果物)。
狭義では・・・
あるリソースに対して、特定の制約を適用したコンフォーマンス・リソース(適合性リソース) 。
この場合、プロファイルはリソース単位に存在する(例)Pateintプロファイル、Observationプロファイル…
詳細については、こちらの[FHIRプロファイルに関するJapan Virtual Summit 2021動画](https://youtu.be/B-B6ge_0nHg)をご覧ください。(約20分)
FHIRの公式Webサイトでは各リソースについて既定の仕様が開示されています。ですが、各リソースの使い方の自由度がとても高く、そのままでは実際に相互運用性のあるデータ交換をすることはこ困難です。ですので、事前の「申し合わせ」にもとづいて、リソースの記述に「規則」を改めて設ける必要があります。この「申し合わせ」「規則」に相当するのは、実装ガイドライン(Implementation Guide)とプロファイル(Profile)に相当します。
実装ガイドラインは主に文章で記述されたもので、WordやExcel、HTML等でも記述されています。一方、ProfileはFHIRのStructureDefinitionリソースを使って計算可能なJSON形式で記述をしています。このFHIRのプロファイル自体もFHIRのリソースで表現できる、というのがFHIRの特徴の一つでもあります。例えばIRIS for Healthのような製品でその定義を取り込んで、機能拡張ができるように、JSON形式で仕様まで表現できるようになっているのです。
実装ガイドラインは様々なツールで作れますが、米国HL7協会はProfileから実装ガイドラインを自動的に生成するIG Publisherを公開しています。このツールを使えば、米国HL7協会が出しているフォーマットで実装ガイドラインのHTMLファイル等を生成することができます。この記事後半ではその方法についても紹介しています。
例えばこれは、US Coreと呼ばれる米国で標準的に使用されることが推奨されたPatientリソースの記法上の規約を表現した、「StructureDefinition」というリソースです。
([引用元](https://www.hl7.org/fhir/us/core/StructureDefinition-us-core-patient.json.html))
```
{
"resourceType" : "StructureDefinition",
"id" : "us-core-patient",
"text" : {
"status" : "extensions",
"div" : "省略"
},
"url" : "http://hl7.org/fhir/us/core/StructureDefinition/us-core-patient",
"version" : "3.1.1",
"name" : "USCorePatientProfile",
"title" : "US Core Patient Profile",
"status" : "active",
"experimental" : false,
"date" : "2020-06-27",
"publisher" : "HL7 US Realm Steering Committee",
"contact" : [
{
"telecom" : [
{
"system" : "url",
"value" : "http://www.healthit.gov"
}
]
}
],
"以下略"
```
FHIRプロファイルを表現されるリソースとしては他にも[ImplementationGuide](http://hl7.org/fhir/implementationguide.html)やFHIRサーバの一連の機能をまとめた[CapabilityStatement](http://hl7.org/fhir/capabilitystatement.html)などがあります。
## FHIR Shorthand とは?
というわけで、ではFHIRプロファイルを作成するには↑のJSON構造を作っていけばいいんだな!?ということになる訳ですが、これを手作業でやるのはどう考えて難しいし煩雑ですよね。間違えそうです。
これを補助するためのアプリケーションやツールが公開されており、商用製品やオープンソースなどいくつかの選択肢があります。
こちらの[ページ](https://confluence.hl7.org/pages/viewpage.action?pageId=35718864#ProfileTooling-Editing&AuthoringProfiles)をご覧ください。
例えばオランダのFirely社のForgeなどは有名ですが、最近では**FHIR Shorthand** ([リンク](https://build.fhir.org/ig/HL7/fhir-shorthand/index.html))という**FHIRアーティファクトを定義するためのドメイン固有の言語**も広く使われるようになってきています。
FHIR Shorthandは言語の一種であり、例えば以下のような定義ファイル=FSH(フィッシュ)ファイルを作成しながら、FHIRプロファイルを作成することができます。
以下にサンプルのFSHファイルを例示します。[引用元](https://build.fhir.org/ig/HL7/fhir-shorthand/overview.html#fsh-line-by-line-walkthrough) 例えば、このプロファイルの名前(Profile: CancerDiseaseStatus)、ベースとなる元のFHIRリソース(Parent: Observation)、カーディナリティを変更するエレメントの指定(bodySite 0..0)などの内容を含んでいます。
```
Alias: LNC = http://loinc.org
Alias: SCT = http://snomed.info/sct
Profile: CancerDiseaseStatus
Parent: Observation
Id: mcode-cancer-disease-status
Title: "Cancer Disease Status"
Description: "A clinician's qualitative judgment on the current trend of the cancer, e.g., whether it is stable, worsening (progressing), or improving (responding)."
* ^status = #draft
* extension contains EvidenceType named evidenceType 0..*
* extension[evidenceType].valueCodeableConcept from CancerDiseaseStatusEvidenceTypeVS (required)
* status and code and subject and effective[x] and valueCodeableConcept MS
* bodySite 0..0
* specimen 0..0
* device 0..0
* referenceRange 0..0
* hasMember 0..0
* component 0..0
* interpretation 0..1
* subject 1..1
* basedOn only Reference(ServiceRequest or MedicationRequest)
(省略)
```
## SUSHIって?
FHIR/FHIRプロファイル/FHIR Shorthandと順に説明してきましたが、ついにSUSHIの説明です。
SUSHI (an acronym for “SUSHI Unshortens SHorthand Inputs”) (4) is a reference implementation of a FSH compiler that translates FSH into FHIR artifacts such as profiles, extensions, and value sets. SUSHI is installed on your own computer and runs locally from the command line. ([引用元](https://build.fhir.org/ig/HL7/fhir-shorthand/overview.html#sushi))
> (訳)SUSHI("SUSHI Unshortens SHorthand Inputs "の略)は、FSHファイルをプロファイル、エクステンション、バリューセットなどのFHIRアーティファクトに変換するFSHコンパイラのリファレンス実装である。SUSHIは自分のコンピュータにインストールされ、コマンドラインからローカルに実行される。
つまり、**先ほどのFHIR Shorthandを記述したFSH(フィッシュ)ファイルを、SUSHIで処理すると、StructureDefinitionなどのファイルが生成される**、ということです。
この仕組みを説明したわかりやいようで、ちょっとわかりにくい一枚の絵があります
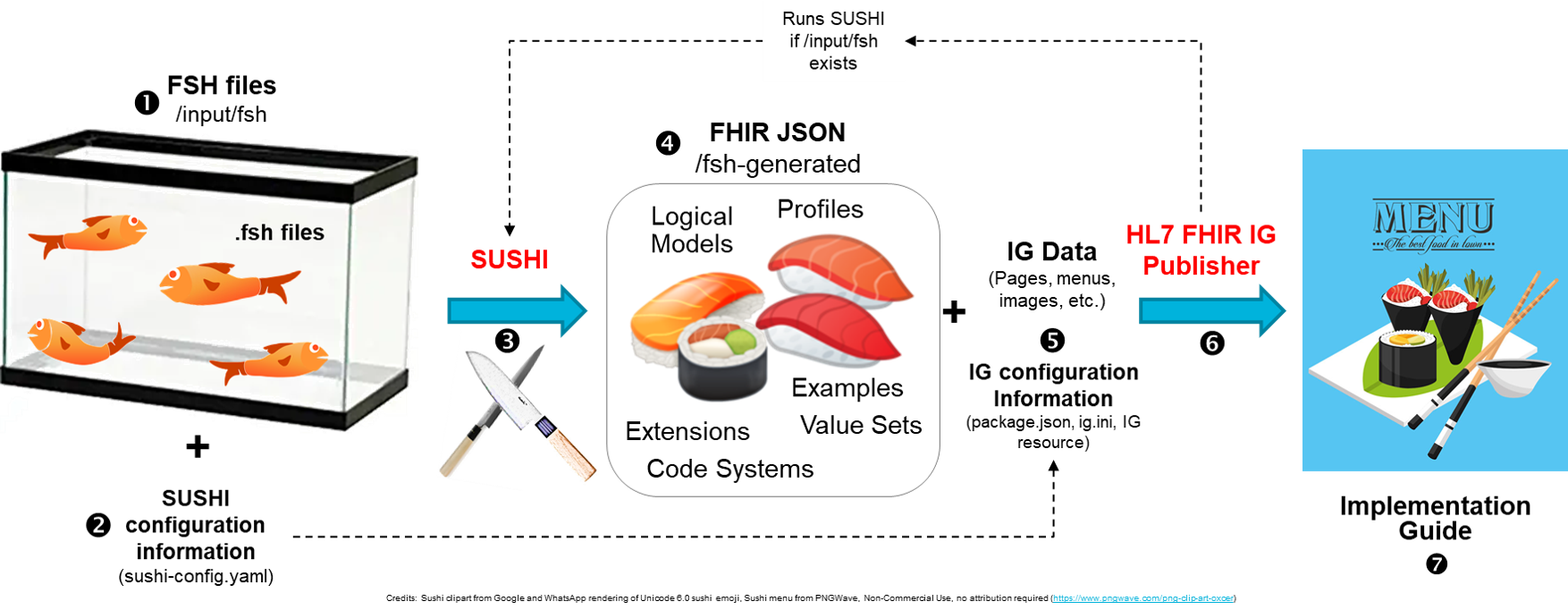
(この絵では、魚を処理(=コンパイル)して、寿司ができるようなイメージで書かれてるんですが、実際はコンパイルをしているのが「SUSHIコンパイラ」で、できあがるのは「プロファイルなどのFHIRアーティファクト」なのでちょっと違うと思うんですよね・・・。お寿司の説明にProfilesやExtensions等の記載はありますけども。)
駆け足でSUSHIとは何か、までご紹介してきましたがご理解いただけたでしょうか?
## FSH Schoolに行こう
肝心なSUSHIのインストール方法や基本的な使い方ですが、それらについてはここで説明するよりも、非常に丁寧に紹介されたオフィシャルサイトがありますので、そちらをご紹介したいと思います。
その名も[FSH School](https://fshschool.org/)です。
SUSHIを使って生成されるのは、StrudctureDefinitionなどのリソース(JSONファイル)ですが、同じくこのサイトで紹介されている、"IG Publisherツール"を使うことによって、それらを取りまとめたHTMLのソースまで生成することができます。
まずはこの[SUSHI Tutorial](https://fshschool.org/docs/tutorials/basic/)に内容に沿って、基本的な機能の確認をされることをお勧めします。
うまくいかないときは、ダウンロードできるフォルダに含まれる完成版FSH Tank(!)であるFishExampleCompleteディレクトリを参照されると良いと思います。
私はWindows環境で試しました。Node.jsもインストールされていなかったので、[こちらのサイト](https://blog.katsubemakito.net/nodejs/install-windows10)の情報を参考にさせていただきました。
また、チュートリアルに以下の記載がある通り、IG Publisherを使ったHTMLファイルの出力には Jekyll というツールが必要になります。
>Warning
Before proceeding to the next command: If you have never run the IG Publisher, you may need to install Jekyll first. See Installing the IG Publisher for details.
こちらの[サイト](http://jekyll-windows.juthilo.com/1-ruby-and-devkit/)からJekyllのキット等は入手できます。
## SUSHI実行例
私の環境で、チュートリアルの完成版を使ったsushiコマンド実行結果を掲載します。
コマンド等の詳細はこちらのサイト([Running SUSHI](https://fshschool.org/docs/sushi/running/))をご覧ください。
```
>sushi .
info Running SUSHI v1.2.0 (implements FHIR Shorthand specification v1.1.0)
info Arguments:
info C:\Users\kaminaka\Documents\Work\FHIR\SUSHI\fsh-tutorial-master\FishExampleComplete
info No output path specified. Output to .
info Using configuration file: C:\Users\kaminaka\Documents\Work\FHIR\SUSHI\fsh-tutorial-master\FishExampleComplete\sushi-config.yaml
info Importing FSH text...
info Preprocessed 2 documents with 3 aliases.
info Imported 4 definitions and 1 instances.
info Checking local cache for hl7.fhir.r4.core#4.0.1...
info Found hl7.fhir.r4.core#4.0.1 in local cache.
info Loaded package hl7.fhir.r4.core#4.0.1
(node:26584) Warning: Accessing non-existent property 'INVALID_ALT_NUMBER' of module exports inside circular dependency
(Use `node --trace-warnings ...` to show where the warning was created)
(node:26584) Warning: Accessing non-existent property 'INVALID_ALT_NUMBER' of module exports inside circular dependency
info Converting FSH to FHIR resources...
info Converted 3 FHIR StructureDefinitions.
info Converted 1 FHIR ValueSets.
info Converted 1 FHIR instances.
info Exporting FHIR resources as JSON...
info Exported 5 FHIR resources as JSON.
info Assembling Implementation Guide sources...
info Generated ImplementationGuide-fish.json
info Assembled Implementation Guide sources; ready for IG Publisher.
╔════════════════════════ SUSHI RESULTS ══════════════════════════╗
║ ╭──────────┬────────────┬───────────┬─────────────┬───────────╮ ║
║ │ Profiles │ Extensions │ ValueSets │ CodeSystems │ Instances │ ║
║ ├──────────┼────────────┼───────────┼─────────────┼───────────┤ ║
║ │ 2 │ 1 │ 1 │ 0 │ 1 │ ║
║ ╰──────────┴────────────┴───────────┴─────────────┴───────────╯ ║
║ ║
╠═════════════════════════════════════════════════════════════════╣
║ It doesn't get any betta than this! 0 Errors 0 Warnings ║
╚═════════════════════════════════════════════════════════════════╝
```
実行するとFSHファイルのコンパイルが実行され、最後にいくつのProfilesやExtensionが生成されたか、表示されます。問題なければ、"info"だけが表示されますが、FSHファイルの定義に誤りがあると、WarningやErrorも表示されます。エラーメッセージは比較的親切で何が問題が把握しやすいと思います。(個人的には最後の表に掲載される、なぞの「魚一言?」みたいな一文が楽しみです。)
実行後には、プロジェクトフォルダ内のfsh-generatedフォルダにStructureDefinitionのJSONファイルが生成されているのが確認できます。
続いて、「_updatePublisher」コマンドで、IG Publisherツールを入手し、「_genonce」コマンドでIG Publisherを起動し、HTMLファイル群も生成してみます。この実行ログは長いので割愛します。
実行後、同じプロジェクトフォルダ内の output フォルダを確認すると多くのファイルが生成されているのがわかります。index.htmlファイルを開くと以下のようなページが生成されていることが確認できます。
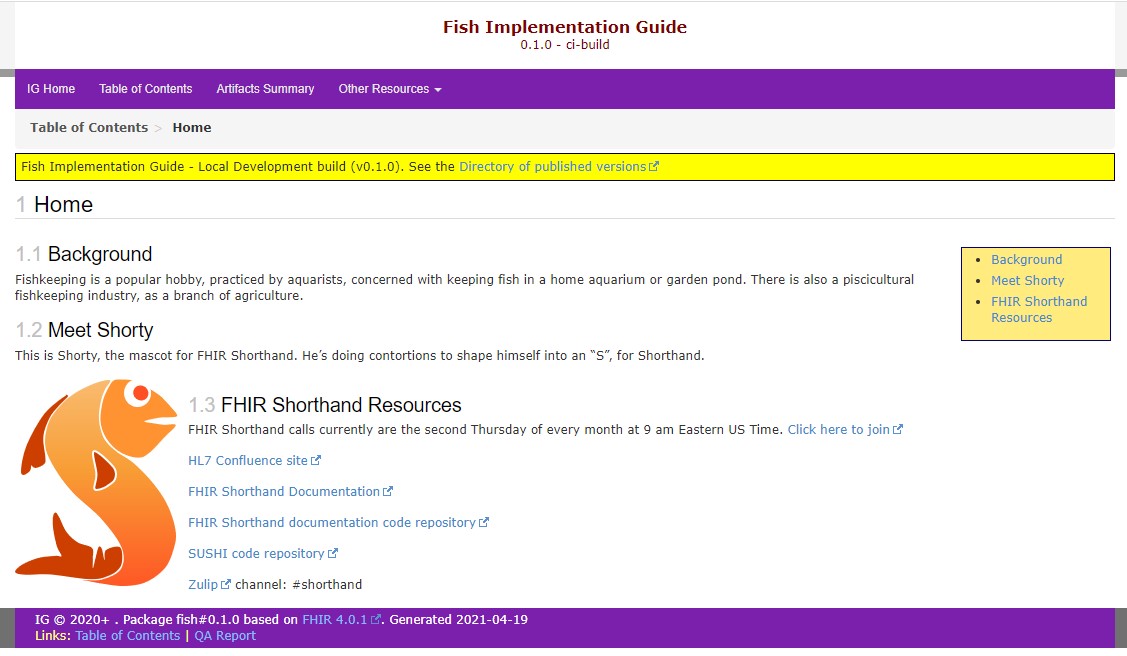
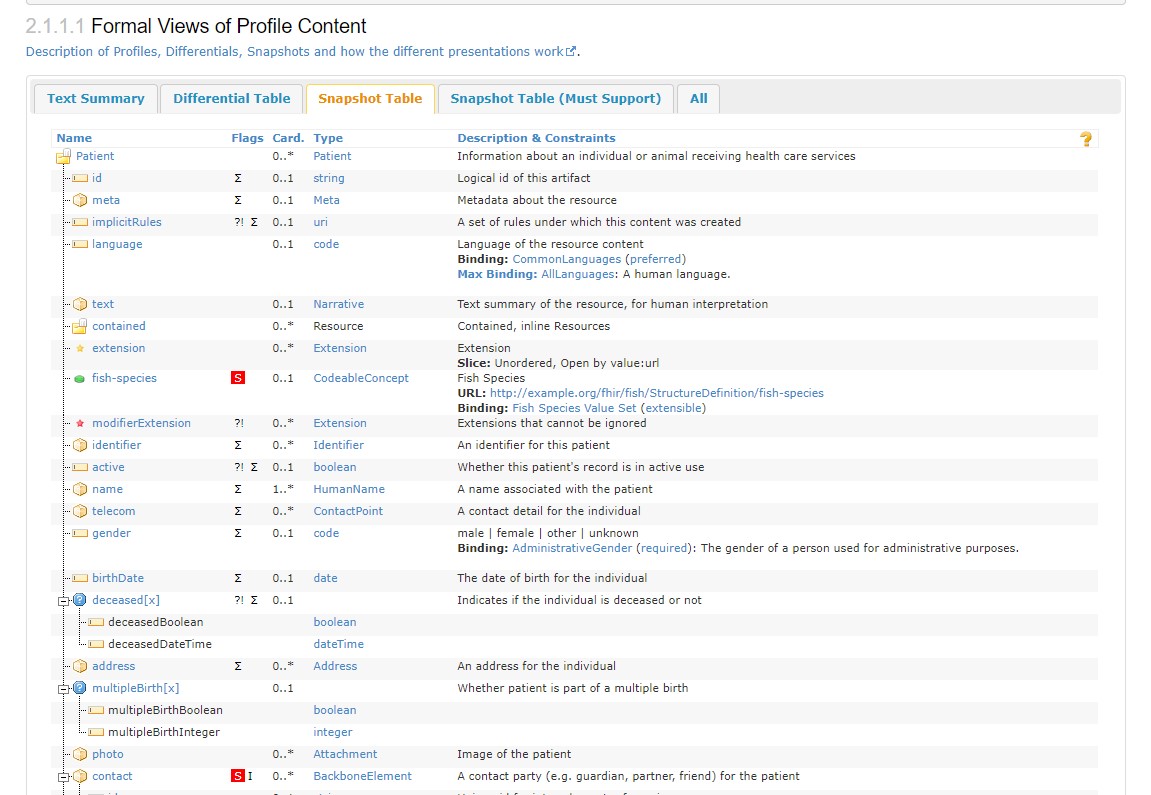
このようなFHIR公式サイトでも見慣れた、リソースの説明ページなども自動生成されます。
## Implementation Guide(実装ガイド)を書いてみよう
私もこのツール群を触り始めて日が浅いですが、簡単なスタートアップとして、実装ガイドを記述していく方法をご紹介したいと思います。
詳細な使い方についてはFSH Schoolサイト内の情報をご覧ください。[こちら](https://fshschool.org/downloads/)で紹介されているのFHIR DevDaysのスライド等も大変参考になると思います。
まず sushi --init コマンドでプロジェクト構造のひな型を作りましょう。
```
C:\Users\kaminaka\Documents\Work\FHIR\SUSHI\TestProject>sushi --init
╭───────────────────────────────────────────────────────────╮
│ This interactive tool will use your answers to create a │
│ working SUSHI project configured with your project's │
│ basic information. │
╰───────────────────────────────────────────────────────────╯
Name (Default: ExampleIG): MyFirstSUSHIProject
Id (Default: fhir.example): myfirstsushi
Canonical (Default: http://example.org): http://example.org/myfirstsushi
Status (Default: draft):
Version (Default: 0.1.0):
Initialize SUSHI project in C:\Users\kaminaka\Documents\Work\FHIR\SUSHI\TestProject\MyFirstSUSHIProject? [y/n]: y
Downloading publisher scripts from https://github.com/HL7/ig-publisher-scripts
(node:13972) Warning: Accessing non-existent property 'INVALID_ALT_NUMBER' of module exports inside circular dependency
(Use `node --trace-warnings ...` to show where the warning was created)
(node:13972) Warning: Accessing non-existent property 'INVALID_ALT_NUMBER' of module exports inside circular dependency
╭───────────────────────────────────────────────────────────╮
│ Project initialized at: ./MyFirstSUSHIProject │
├───────────────────────────────────────────────────────────┤
│ Now try this: │
│ │
│ > cd MyFirstSUSHIProject │
│ > sushi . │
│ │
│ For guidance on project structure and configuration see │
│ the SUSHI documentation: https://fshschool.org/docs/sushi │
╰───────────────────────────────────────────────────────────╯
```
実行すると必要最低限の設定ファイルやFSHファイルが作成されます。
次に少し修正をしてみましょう。
その前にエディタの紹介です。fshファイルを修正するための[Extension](https://marketplace.visualstudio.com/items?itemName=kmahalingam.vscode-language-fsh)が公開されているので、Visual Studio Codeの使用がおすすめです。
せっかくなので、日本語の情報を入力してどのように反映されるか見ていきたいと思います。
まず、sushi-config.yaml を修正します。実装ガイドのタイトルを追加し、メニュー画面も日本語表記に変更した上で、コンテンツ一覧ページ(tuc.html)とカスタムページ(mycustompage.html)を追加しています。
sushi-config.yaml
```
# ╭──────────────────────────────────────ImplementationGuide───────────────────────────────────────╮
# │ The properties below are used to create the ImplementationGuide resource. For a list of │
# │ supported properties, see: https://fshschool.org/sushi/configuration/ │
# ╰────────────────────────────────────────────────────────────────────────────────────────────────╯
id: myfirstsushi
canonical: http://example.org/myfirstsushi
name: MyFirstSUSHIProject
# titleを追加して、ページ上部に表示されるようにします。
title: ○○FHIRプロジェクト 実装ガイド
status: draft
publisher: InterSystems Japan/S.Kaminaka
description: SUSHIを使ったFHIRプロジェクト実装ガイドのサンプルです。
version: 0.1.0
fhirVersion: 4.0.1
copyrightYear: 2021+
releaseLabel: ci-build
# ╭────────────────────────────────────────────menu.xml────────────────────────────────────────────╮
# │ To use a provided input/includes/menu.xml file, delete the "menu" property below. │
# ╰────────────────────────────────────────────────────────────────────────────────────────────────╯
# メニューを日本語表示されるように変更します。
menu:
実装ガイドホーム: index.html
コンテンツ一覧: toc.html
FHIRアーティファクトサマリ: artifacts.html
カスタムページ: mycustompage.html
```
インデックスページや、カスタムページはマークダウンで記述できます。
index.md
```
# MyFirstSUSHIProject
Feel free to modify this index page with your own awesome content!
### プロジェクトの背景
pagecontent/index.md ファイルを変更して、htmlファイル内の記載内容を変更できます。
ページを記述にはマークダウン記法を使用することができます。
### 参考情報へのリンク
(略)
```
mycustompage.md
```
## これはカスタムページです。
マークダウンファイルを用意しておくとhtmlファイルが生成されます。
プロジェクトに応じたページを生成し、実装ガイドに含めることができます。
```
最後に最も重要なFSHファイルを修正します。このひな形には、Patientプロファイル用のFSHファイルが含まれているので、それを少しだけ修正しました。
patient.fsh
```
// This is a simple example of a FSH file.
// This file can be renamed, and additional FSH files can be added.
// SUSHI will look for definitions in any file using the .fsh ending.
Profile: MyPatient
Parent: Patient
Title: "○○プロジェクトのPatientプロファイル"
* name 1..* MS
// ^shortを変更して、一覧表示画面の説明部分を変更できます。
* name ^short = "患者さんの氏名を格納します。"
* name ^definition = "患者さんの氏名を格納するエレメント。NeXEHRS JP COREに準拠した漢字・カナ記法を使用します。"
```
それでは、以下のコマンドを実行して、生成された実装ガイドページを確認してみましょう。
> sushi.
> _updatePublisher
> _genonce
以下のような情報を含むページが簡単に生成できます。
あわせてStructureDefinitionやImplementationGuideなどのJSONファイルももちろん生成されています。
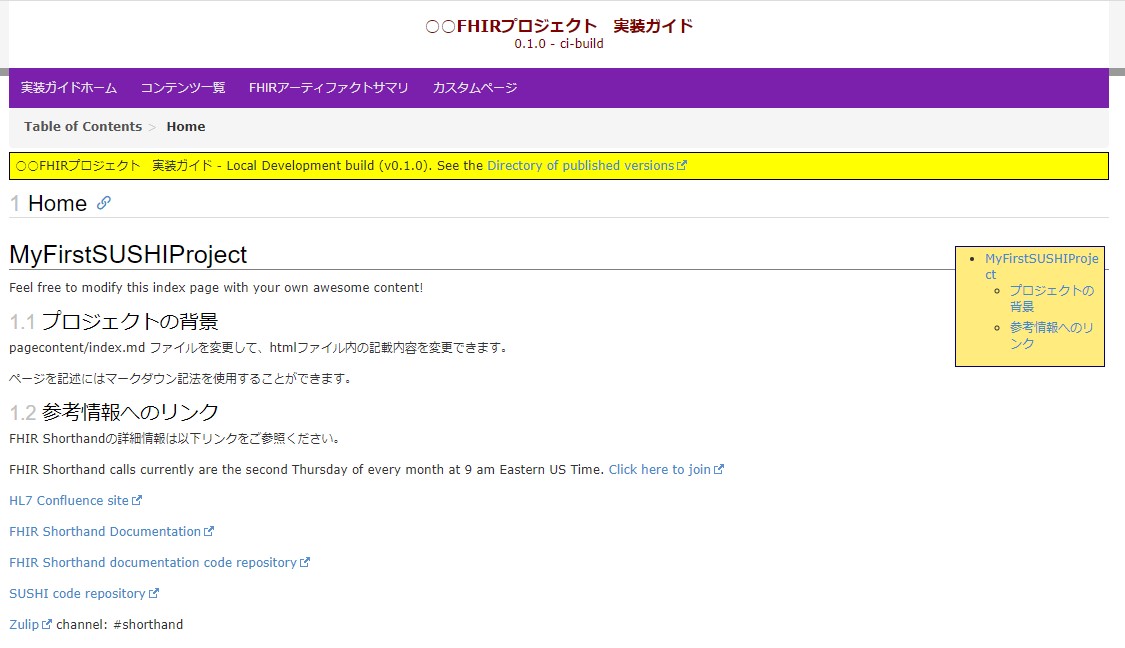
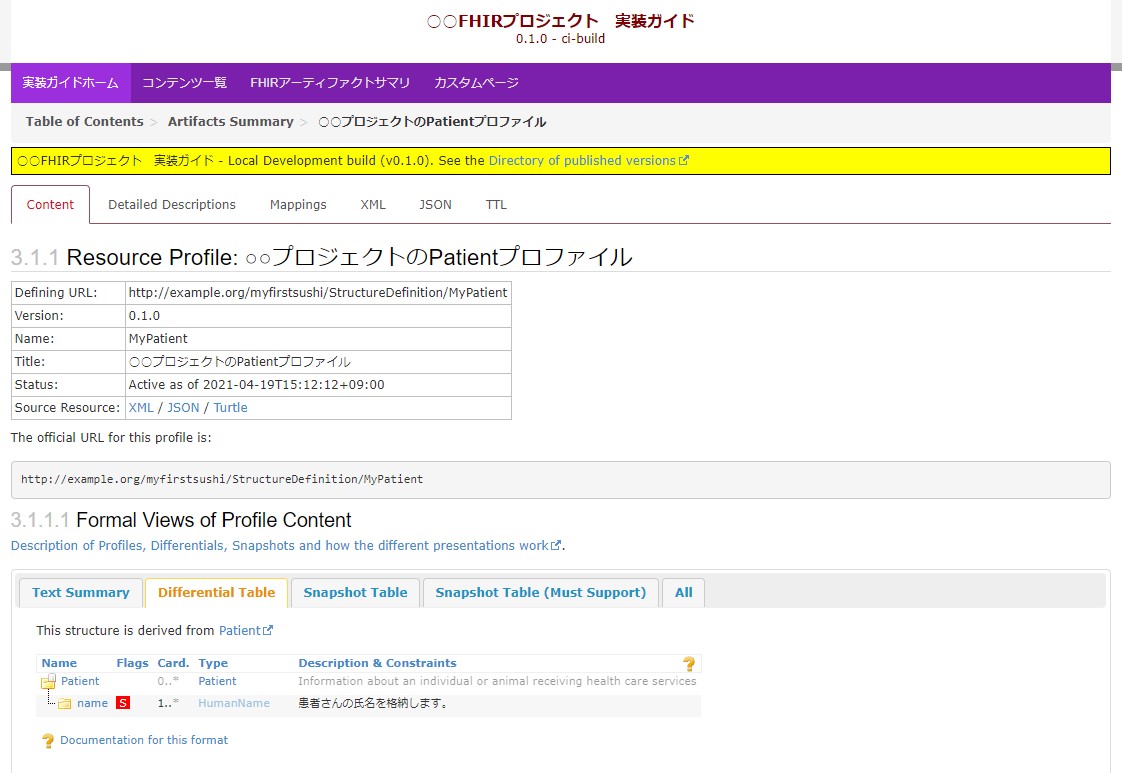
## まとめ
いかがでしたでしょうか?
単にFHIRプロファイルのJSONファイルを生成するだけでなく、HTMLファイルを生成する機能も付随しているので、このツールをうまく使えばFHIRの仕様を分かりやすく伝えることが可能なコンテンツが簡単に作成できるのではないかと考えています。
このツール自体はInterSystemsとは直接関係ない製品ではありますが、FHIRプロジェクトの情報交換に役立つツールということで、この開発者コミュニティでご紹介させていただきました。
この記事を見て試していただいた方、あるいはすでに使いこなしている方、使い方のコツや便利な機能やシンタックスなどをご紹介いただけると嬉しく思います。
次回のこのシリーズでは、SUSHIで生成したSearch Parameterの定義ファイルをIRIS for Healthで読み込んで、検索パラメータを拡張する内容に取り組んでみたいと考えています。
(2021/4/20 特にプロファイルの説明について、説明が曖昧な箇所をご指摘いただきましたので修正しました。ご指摘ありがとうございました。)
記事
Mihoko Iijima · 2022年3月29日
これは、InterSystems FAQサイトの記事です。
データベースの空き容量は、システムモニタを使用して監視することができます。
システムモニタは、システム開始時に自動開始され、予め設定された閾値に対してアラートが通知されます。
システムの閾値については以下ドキュメントをご参照ください。システム・モニタのステータスおよびリソース・メトリック【IRIS】システム・モニタのステータスおよびリソース・メトリック
データベースの空き容量については、システムデフォルトでは 50 MBを下回る場合にアラートが通知され、メッセージログ(コンソールログ)にアラート(深刻度 2)として記録され、alerts.log ファイルにも出力されます。
データベースの空き容量を任意サイズで監視したい場合、システムモニタに含まれる「アプリケーションモニタ」を利用して設定します。注意:アプリケーションモニタでは、アラート対象となる情報があってもメッセージログ(コンソールログ)に出力しないため、メール通知/メソッド実行 を使用して通知するように設定します。
例えば、空き容量が 100MB を下回った時にアラートを通知したい場合は、アプリケーションモニタが提供する %Monitor.System.Sample.Freespace(空き容量メトリック)を利用します。
その他のアプリケーションモニタの閾値(メトリック)については、以下ドキュメントをご参照ください。アプリケーション・モニタのメトリック【IRIS】アプリケーション・モニタのメトリック
システム提供のアプリケーションモニタは、デフォルトでは全て無効化されています。使用を開始するためには、対象のモニタを有効化し、システムモニタを再起動します。
アプリケーションモニタの有効/無効やシステムモニタの停止/開始は、システムルーチン ^%SYSMONMGR を利用します。
以下の例では、データベースの空き容量が 100MB を下回る場合にメール通知を行う設定手順について説明します。
手順は以下の通りです。
1) ^%SYSMONMGR を起動し、アプリケーションモニタから %Monitor.System.Freespace を有効化する
2) アラート対象とする閾値を変更する(例では、通知は最初の1回のみとしています)
3) Email通知設定を行う
4) システムモニタを再起動する
1) ^%SYSMONMGR を起動し、アプリケーションモニタから %Monitor.System.Freespace を有効化する
ドキュメントは以下ご参照ください。Manage Monitor Classes【IRIS】Manage Monitor Classes
%SYS>do ^%SYSMONMGR
1) Start/Stop System Monitor
2) Set System Monitor Options
3) Configure System Monitor Classes
4) View System Monitor State
5) Manage Application Monitor
6) Manage Health Monitor
7) View System Data
8) Exit
Option? 5 → 5 を入力してEnter押下
1) Set Sample Interval
2) Manage Monitor Classes
3) Change Default Notification Method
4) Manage Email Options
5) Manage Alerts
6) Exit
Option? 2 → 2 を入力してEnter押下
1) Activate/Deactivate Monitor Class
2) List Monitor Classes
3) Register Monitor System Classes
4) Remove/Purge Monitor Class
5) Set Class Sample Interval
6) Debug Monitor Classes
7) Exit
Option? 1 → 1 を入力してEnter押下
Class? ? → ? を入力してEnter押下
Num MetricsClassName Activated
1) %Monitor.System.HistoryMemory N
2) %Monitor.System.HistoryPerf N
3) %Monitor.System.HistorySys N
4) %Monitor.System.HistoryUser N
5) %Monitor.System.AuditCount N
6) %Monitor.System.AuditEvents N
7) %Monitor.System.Clients N
8) %Monitor.System.Diskspace N
9) %Monitor.System.Freespace N
10) %Monitor.System.Globals N
11) %Monitor.System.Journals N
12) %Monitor.System.License N
13) %Monitor.System.LockTable N
14) %Monitor.System.Processes N
15) %Monitor.System.Routines N
16) %Monitor.System.Servers N
17) %Monitor.System.SystemMetrics N
18) %Monitor.System.CSPGateway N
Class? 9 %Monitor.System.Freespace →上のリストの 9 を指定してEnter押下
Activate class? Yes => yes → yes を入力してEnter押下
1) Activate/Deactivate Monitor Class
2) List Monitor Classes
3) Register Monitor System Classes
4) Remove/Purge Monitor Class
5) Set Class Sample Interval
6) Debug Monitor Classes
7) Exit Option? →Enter押下(前のメニューに戻ります)
1) Set Sample Interval
2) Manage Monitor Classes
3) Change Default Notification Method
4) Manage Email Options
5) Manage Alerts
6) Exit
Option?
2) アラート対象とする閾値を変更する(例では、通知は最初の1回のみとしています)
※以下実行例は、1) の続きで記述しています。^%SYSMONMGRの実行から始めている場合は、5) Manage Application Monitor 選択後の画面から開始してください。
ドキュメントは以下ご参照ください。Manage Alerts【IRIS】Manage Alerts
1) Set Sample Interval
2) Manage Monitor Classes
3) Change Default Notification Method
4) Manage Email Options
5) Manage Alerts
6) Exit
Option? 5 → 5 を入力してEnter押下
1) Create Alert
2) Edit Alert
3) List Alerts
4) Delete Alert
5) Enable/Disable Alert
6) Clear NotifyOnce Alert
7) Exit
Option? 1 → 1 を入力してEnter押下
Alert name? test database free space alert → 任意のアラート名を入力してEnter押下
Application? %SYS (Enter '-' to reset) => → Enter押下
Action (0=default,1=email,2=method)? 0 => 1 → 1 を入力してEnter押下
Raise this alert during sampling? Yes => yes → yes を入力してEnter押下
Class? ? → ? を入力してEnter押下
Num MetricsClassName Activated
1) %Monitor.System.HistoryMemory N
2) %Monitor.System.HistoryPerf N
3) %Monitor.System.HistorySys N
4) %Monitor.System.HistoryUser N
5) %Monitor.System.AuditCount N
6) %Monitor.System.AuditEvents N
7) %Monitor.System.Clients N
8) %Monitor.System.Diskspace N
9) %Monitor.System.Freespace Y
10) %Monitor.System.Globals N
11) %Monitor.System.Journals N
12) %Monitor.System.License N
13) %Monitor.System.LockTable N
14) %Monitor.System.Processes N
15) %Monitor.System.Routines N
16) %Monitor.System.Servers N
17) %Monitor.System.SystemMetrics N
18) %Monitor.System.CSPGateway N
Class? 9 %Monitor.System.Freespace → 上のリストの 9 を指定してEnter押下
Property? ? → ? を入力してEnter押下
Num Name Activated
1) CurSize Y
2) DBName Y
3) Directory Y
4) DiskFreeSpace Y
5) FreeSpace Y
6) MaxSize Y
Property? 5 FreeSpace → 上のリストの 5 を指定してEnter押下
Property? Properties list: FreeSpace
Evaluation expression (e.g., "%1=99")? %1<100 ←MB単位に指定します。例では「100MB未満の場合アラート」を指定してEnter押下
Expression expands to: If FreeSpace<100. OK? Yes => Yes → Yes を入力してEnter押下
Notify once only? No => yes → yes を入力してEnter押下
1) Create Alert
2) Edit Alert
3) List Alerts
4) Delete Alert
5) Enable/Disable Alert
6) Clear NotifyOnce Alert
7) Exit
Option? →Enter押下(前のメニューに戻ります)
1) Set Sample Interval
2) Manage Monitor Classes
3) Change Default Notification Method
4) Manage Email Options
5) Manage Alerts
6) Exit
Option? →Enter押下(前のメニューに戻ります)
3) Email通知設定を行う
以下の例では、gmail を利用する例をご紹介しています。gmail は SSL構成を事前に作成する必要があります。管理ポータルの以下メニューから事前に作成してください。
管理ポータル > システム管理 > セキュリティ管理 > SSL/TLS構成
※以下実行例は、2)の続きで記述しています。^%SYSMONMGR の実行から始めている場合は、5) Manage Application Monitor 選択後の画面から開始してください。
ドキュメントは以下ご参照ください。Manage Email Options【IRIS】Manage Email Options
1) Start/Stop System Monitor
2) Set System Monitor Options
3) Configure System Monitor Classes
4) View System Monitor State
5) Manage Application Monitor
6) Manage Health Monitor
7) View System Data
8) Exit
Option? 5 → 5 を入力してEnter押下
1) Set Sample Interval
2) Manage Monitor Classes
3) Change Default Notification Method
4) Manage Email Options
5) Manage Alerts
6) Exit
Option? 4 → 4 を入力してEnter押下
1) Enable/Disable Email
2) Set Sender
3) Set Server
4) Manage Recipients
5) Set Authorization
6) Test Email
7) Exit
Option? 3 → 3 を入力してEnter押下
Mail server? smtp.gmail.com → メールサーバを入力してEnter押下
Mail server port? 587 → メールサーバのポート番号を入力してEnter押下
Mail server SSLConfiguration? gmail → 管理ポータルで設定したSSL構成名を入力してEnter押下
Mail server UseSTARTTLS? 0 => 1 → 1を入力してEnter押下
1) Enable/Disable Email
2) Set Sender
3) Set Server
4) Manage Recipients
5) Set Authorization
6) Test Email
7) Exit
Option? 2 → 2 を入力してEnter押下
Sender? sendertest@gmail.com → 差出人のメールアドレスを入力してEnter押下
1) Enable/Disable Email
2) Set Sender
3) Set Server
4) Manage Recipients
5) Set Authorization
6) Test Email
7) Exit
Option? 5 → 5 を入力してEnter押下
User name? xxxabctestaccount@gmail.com → 認証用アカウント名を入力してEnter押下
Password? → パスワードを入力してEnter押下
1) Enable/Disable Email
2) Set Sender
3) Set Server
4) Manage Recipients
5) Set Authorization
6) Test Email
7) Exit
Option? 4 → 4 を入力してEnter押下
1) List Recipients
2) Add Recipient
3) Remove Recipient
4) Exit
Option? 2 → 2 を入力してEnter押下
Email Address? abc@testcorp.com → 送信先メールアドレスを入力してEnter押下
1) List Recipients
2) Add Recipient
3) Remove Recipient
4) Exit
Option? →Enter押下(前のメニューに戻ります)
1) Enable/Disable Email
2) Set Sender
3) Set Server
4) Manage Recipients
5) Set Authorization
6) Test Email
7) Exit
Option? 1 → 1 を入力してEnter押下
Email is currently OFF
Change Email setting? No => yes → yes を入力してEnter押下
1) Enable/Disable Email
2) Set Sender
3) Set Server
4) Manage Recipients
5) Set Authorization
6) Test Email
7) Exit
Option? 6 → 6 を入力してEnter押下
Sending email on Mail Server smtp.gmail.com
From: sendertest@gmail.com
To: abc@testcorp.com
1) Enable/Disable Email
2) Set Sender
3) Set Server
4) Manage Recipients
5) Set Authorization
6) Test Email
7) Exit
Option? →Enter押下(前のメニューに戻ります)
1) Set Sample Interval
2) Manage Monitor Classes
3) Change Default Notification Method
4) Manage Email Options
5) Manage Alerts
6) Exit
Option? →Enter押下(前のメニューに戻ります)
1) Start/Stop System Monitor
2) Set System Monitor Options
3) Configure System Monitor Classes
4) View System Monitor State
5) Manage Application Monitor
6) Manage Health Monitor
7) View System Data
8) Exit
Option? →Enter押下(前のメニューに戻ります)
4) システムモニタを再起動する
設定を反映させるため、システムモニタを一度停止し、開始します。
ドキュメントは以下ご参照ください。Start/Stop System Monitor【IRIS】Start/Stop System Monitor
%SYS>do ^%SYSMONMGR
1) Start/Stop System Monitor
2) Set System Monitor Options
3) Configure System Monitor Classes
4) View System Monitor State
5) Manage Application Monitor
6) Manage Health Monitor
7) View System Data
8) Exit
Option? 1 → 1 を入力してEnter押下
1) Start System Monitor
2) Stop System Monitor
3) Exit
Option? 2 → 2 を入力してEnter押下
Stopping System Monitor... System Monitor stopped
1) Start System Monitor
2) Stop System Monitor
3) Exit
Option? 1 → 1 を入力してEnter押下
Starting System Monitor... System Monitor started
1) Start System Monitor
2) Stop System Monitor
3) Exit
Option? →Enter押下(前のメニューに戻ります)
1) Start/Stop System Monitor
2) Set System Monitor Options
3) Configure System Monitor Classes
4) View System Monitor State
5) Manage Application Monitor
6) Manage Health Monitor
7) View System Data
8) Exit
Option? →Enter押下(ネームスペースのプロンプトに戻ります)
%SYS>
記事
Toshihiko Minamoto · 2023年2月8日
InterSystems IRIS 2020.1 には、重要なアプリケーションの構築を支援する新機能と機能改善が多数盛り込まれています。 2019.1 から 2020.1 までに行われた多数の大幅なパフォーマンス改善のほかに、最近の SQL の歴史において最も大きな変更点の 1 つであるユニバーサルクエリキャッシュ(UQC)が導入されています。 この記事では、SQL ベースのアプリケーションに対するそのインパクトについて、技術的な観点で詳しく説明しています。
### UQC とは?
スクラブルで頭字語として使用されればゲームチェンジャーとなる可能性もあるでしょうが、ユニバーサルクエリキャッシュは、あらゆる種類の SQL ステートメントを単一のキャッシュで管理することで、ボード全体の SQL 操作を単純化することを目的としています。 これまでは、[動的 SQL](https://docs.intersystems.com/irislatest/csp/docbookj/Doc.View.cls?KEY=GSQL_dynsql)(%SQL.Statementインフラストラクチャを使用)や JDBC 、 ODBC にて発行されるステートメントは、Prepare 時に [キャッシュドクエリ](https://docs.intersystems.com/irislatest/csp/docbookj/Doc.View.cls?KEY=GSQLOPT_cachedqueries)として最適化されたコードにコンパイルされていました。 一方、[埋め込み SQL](https://docs.intersystems.com/irislatest/csp/docbookj/Doc.View.cls?KEY=GSQL_esql) を使用する場合(&SQL() 構文を使用)、クエリを実行するコードはインラインで生成され、アプリケーションの一部となっていました。 このため、埋め込み SQL は、IRIS がサポートする他のすべての形態の SQL クエリとは非常に異なって処理されていました。
キャッシュドクエリクラスは、ステートメントを発行したコードから独立しており、新しいインデックスの追加やアップグレードの後に、更新されたテーブルの統計に基づいてより効率的なアクセスパスを得るなどのために、必要に応じてパージしたり生成し直したりすることが可能です([アップグレード時に凍結されたクエリプラン](https://docs.intersystems.com/irislatest/csp/docbookj/Doc.View.cls?KEY=GSQLOPT_frozenplans#GSQLOPT_frozenplans_upgrade)の注意事項もご覧ください)。 一方、埋め込み SQL は静的であり、新しいテーブル統計とインデックスを自動的に利用することができませんでした。
2020.1 では、ユニバーサルクエリキャッシュの導入により、埋め込み SQL にもキャッシュ済みクエリクラスを生成できるようになり、このコードをアプリケーションロジックを保持するクラスに混在させることがなくなりました。 最も重要なメリットは、埋め込み SQL では、より新しいテーブル統計または新しいインデックスを利用するために、ソースクラスを再コンパイルする必要がなくなったことです。 UQC で参照されているテーブルが更新されると、新しいキャッシュ済みクエリクラスが自動的に生成されるため、生成可能な最も効率の良いコードが確実に実行されます。 埋め込み SQL をクラスに生成すると、他のすべてのクエリが既に使用しているより高速なカーソル変数ストレージを利用できます。 つまり、膨大な作業を行うクエリが以前よりも速く実行されるということです。 また、UQC によって、クラスのコンパイル順の管理において管理者を悩ませることの多かったクラス間の SQL 依存関係がすべて取り除かれます。
これによって作業が大きく変わります。多大な労力をつぎ込んで、「想像力に溢れる」セットアップに対応するために大規模なテストを行ってはいるものの(デプロイ済みのコード、アプリケーションコード内でのネームスペースの切り替えなど)、その想像を超えるセットアップがまだまだ存在するかもしれません。 そのため、埋め込み SQL を大量に(そして創造性豊かに)使用しているアプリケーションを 2020.1 にアップグレードする際には、特に注意してください。また、通常と異なることに気づいた場合は、[WRC](http://wrc.intersystems.com/) までご連絡ください。
### 埋め込み SQL と動的 SQL は 1 つに統一されたのですか?
動的 SQL と埋め込み SQL の使用方法については、現在でもセマンティックがある程度異なっています。 埋め込み SQL は名前付きカーソルを操作しますが、これは動的 SQL のクエリに対する実際のオブジェクトハンドルを操作するよりも少し扱いにくいものです。 ただし、これは個人の好みに大きく左右される問題であるため、明らかに、楽しむためだけに、あるフレーバーから別のフレーバーにアプリケーションを書き直す理由はありません。
パフォーマンスについては、埋め込み SQL には動的 SQL よりも高速だという評判がありましたが、ここ数年におけるコード生成とオブジェクト処理の改善により、その差はほとんどなくなっています。 とは言え、埋め込み SQL のカーソルの値は変数に直接取得することが可能であるため、動的 SQL の相当するオブジェクトプロパティを通じて値にアクセスするよりも、わずかに高速ではあります。 したがって、確かにより高速ではありますが、その差はほんのわずかであるため、多くの場合、(主観的に!)開発の利便性を上回ることはありません。
### 但し書き
UQC の導入により、2020.1 の埋め込み SQL に、同じルーチンまたはクラスのコンテキストにとどまるのではなく、キャッシュ済みクエリオブジェクト内の別のクラスメソッドをバックグラウンドで呼び出してクエリを実行するという、以前にはなかった非常に小さくも固定されたオーバーヘッドが存在するようになりました。 キャッシュ済みのクエリコードの生成とコンパイルにおける作業は、以前は、&SQL() コンストラクトを含むクラスまたはルーチンのコンパイルの一環でしたが、現在は、動的 SQL と同様に、またより現実的なテーブル統計を利用して、クエリが初めて呼び出されるときに行われるようになっています。 開発者は、新しい /compileembedded=1 コンパイルフラグを使って埋め込み SQL を強制的にコンパイルできます。
これとは別に、生成されたキャッシュ済みのクエリコードで高速な i%var アクセスを使用してカーソルの状態情報を保持するのには様々なメリットがあり、ほとんどの重要なクエリで固定オーバーヘッドが相殺され、実際に埋め込み SQL が以前のバージョンよりも高速になります。 パフォーマンスが低下する可能性があるのは、2019.4 に比べれば、ほんの少数のステートメント(非常に単純な INSERT など)です。 独自に行った実験では、そのような単純なクエリでは約 6%、複雑なクエリでは 3% のパフォーマンスの_増加_が見られました。
一方で、2019.4 より前のバージョンからアップグレードするユーザーは、パフォーマンスの_改善_以外は、何も感じられない可能性があります。 2019.1 から 2019.4 までは、SQL とカーネルレイヤーにおいて、UQC で導入される小さな固定オーバーヘッドをはるかに上回る他のパフォーマンス改善が多数行われているためです。 これらの多数の変更点の概要については、[こちらの GS セッション録画](https://community.intersystems.com/post/new-video-sql-performance-need-speed)をご覧ください。
### まとめ
簡単に言えば、ユニバーサルクエリキャッシュによって、最新の統計と利用可能なインデックスを考慮するようにクエリプランが素早く確実に更新されるため、DBA の業務がより楽になります。 特に、SQL アプリケーションを別のお客様環境にデプロイする場合には、一番ピッタリな SQLを開発者が自由に選択できる重要な機能強化と言えます。
この記事は、@Mark.Hansonと@ Tom.Woodfin からいただいた貴重な貢献に基づいています
記事
Toshihiko Minamoto · 2024年3月25日
バージョン 2023.3(InterSystems IRIS for Health)の新機能は、FHIR プロファイル基準の検証を実行する機能です。
(*)
この記事では、この機能の基本的な概要を説明します。
FHIR が重要な場合は、この新機能を絶対にお試しになることをお勧めします。このままお読みください。
背景情報
FHIR 規格は、$validate という演算を定義します。 この演算は、リソースを検証する API を提供することを意図しています。
FHIR Validation に関する概要を理解するには、こちらの FHIR ドキュメントをご覧ください。
また、Global Summit 2023 での私の「Performing Advanced FHIR Validation」セッションもご覧ください。最初の方で、様々な種類の検証に関する情報を提供しています。
この検証の一部は、特定のプロファイルに対する検証です。 プロファイリングについてはこちらをご覧ください。
簡単な例として、Patient Resource の基本的な FHIR 定義では、識別子の基数を '0..*' として定義します。つまり、Patient には識別子が何もなく(ゼロ)、それでも有効であるということです。 しかし、US Core Patient Profile は、'1..*' の帰趨を定義しています。つまり、Patient に識別子がない場合、有効ではないということになります。
別の例では、上記の US Core Patient の例に従うと、race や birthsex などの拡張が使用されることがあります。
FHIR Profiling についての詳細は、Global Summit 2022 で @Patrick.Jamieson3621 が講演した 「Using FHIR Shorthand」セッションをご覧ください。Pat が FSH(FHIR の略)の使用について説明していますが、Profiling の一般的なトピックの説明から始まっています。
以前のバージョンでは、FHIR Server はこの種(プロファイルベース)の検証をサポートしていませんでしたが、最新バージョン(2023.3)からはサポートされています。
使用方法
ドキュメントには、プロファイルベースの検証に $validate を呼び出す方法についてのセクションが含まれています。
$validate 演算を呼び出す基本的な方法には 2 つあります。
クエリ URL でのプロファイリング
1 つ目は、Request Body の Resource と URL パラメーターとしてのプロファイルを含めた POST 送信です。
たとえば、Postman では:
または curl を使用(プロファイル URL パラメーターの値のスラッシュのエンコーディングに注意してください。Postman によって処理されます):
curl --location 'http://fhirserver/endpoint/Patient/$validate?profile=http%3A%2F%2Fhl7.org%2Ffhir%2Fus%2Fcore%2FStructureDefinition%2Fus-core-patient' --header 'Content-Type: application/fhir+json' --header 'Accept: application/fhir+json' --header 'Authorization: Basic U3VwZXJVc2VyOnN5cw==' --data "@data.json"
上記で参照される data.json には、例としてこの有効な US Core Patient が含まれています。
{
"resourceType" : "Patient",
"id" : "example",
"meta" : {
"profile" : ["http://hl7.org/fhir/us/core/StructureDefinition/us-core-patient|7.0.0-ballot"]
},
"text" : {
"status" : "generated",
"div" : "<div xmlns=\"http://www.w3.org/1999/xhtml\"><p style=\"border: 1px #661aff solid; background-color: #e6e6ff; padding: 10px;\"></div>"
},
"extension" : [{
"extension" : [{
"url" : "ombCategory",
"valueCoding" : {
"system" : "urn:oid:2.16.840.1.113883.6.238",
"code" : "2106-3",
"display" : "White"
}
},
{
"url" : "ombCategory",
"valueCoding" : {
"system" : "urn:oid:2.16.840.1.113883.6.238",
"code" : "1002-5",
"display" : "American Indian or Alaska Native"
}
},
{
"url" : "ombCategory",
"valueCoding" : {
"system" : "urn:oid:2.16.840.1.113883.6.238",
"code" : "2028-9",
"display" : "Asian"
}
},
{
"url" : "detailed",
"valueCoding" : {
"system" : "urn:oid:2.16.840.1.113883.6.238",
"code" : "1586-7",
"display" : "Shoshone"
}
},
{
"url" : "detailed",
"valueCoding" : {
"system" : "urn:oid:2.16.840.1.113883.6.238",
"code" : "2036-2",
"display" : "Filipino"
}
},
{
"url" : "text",
"valueString" : "Mixed"
}],
"url" : "http://hl7.org/fhir/us/core/StructureDefinition/us-core-race"
},
{
"extension" : [{
"url" : "ombCategory",
"valueCoding" : {
"system" : "urn:oid:2.16.840.1.113883.6.238",
"code" : "2135-2",
"display" : "Hispanic or Latino"
}
},
{
"url" : "detailed",
"valueCoding" : {
"system" : "urn:oid:2.16.840.1.113883.6.238",
"code" : "2184-0",
"display" : "Dominican"
}
},
{
"url" : "detailed",
"valueCoding" : {
"system" : "urn:oid:2.16.840.1.113883.6.238",
"code" : "2148-5",
"display" : "Mexican"
}
},
{
"url" : "text",
"valueString" : "Hispanic or Latino"
}],
"url" : "http://hl7.org/fhir/us/core/StructureDefinition/us-core-ethnicity"
},
{
"url" : "http://hl7.org/fhir/us/core/StructureDefinition/us-core-birthsex",
"valueCode" : "F"
}
],
"identifier" : [{
"use" : "usual",
"type" : {
"coding" : [{
"system" : "http://terminology.hl7.org/CodeSystem/v2-0203",
"code" : "MR",
"display" : "Medical Record Number"
}],
"text" : "Medical Record Number"
},
"system" : "http://hospital.smarthealthit.org",
"value" : "1032702"
}],
"active" : true,
"name" : [{
"use" : "old",
"family" : "Shaw",
"given" : ["Amy",
"V."],
"period" : {
"start" : "2016-12-06",
"end" : "2020-07-22"
}
},
{
"family" : "Baxter",
"given" : ["Amy",
"V."],
"suffix" : ["PharmD"],
"period" : {
"start" : "2020-07-22"
}
}],
"telecom" : [{
"system" : "phone",
"value" : "555-555-5555",
"use" : "home"
},
{
"system" : "email",
"value" : "amy.shaw@example.com"
}],
"gender" : "female",
"birthDate" : "1987-02-20",
"address" : [{
"use" : "old",
"line" : ["49 MEADOW ST"],
"city" : "MOUNDS",
"state" : "OK",
"postalCode" : "74047",
"country" : "US",
"period" : {
"start" : "2016-12-06",
"end" : "2020-07-22"
}
},
{
"line" : ["183 MOUNTAIN VIEW ST"],
"city" : "MOUNDS",
"state" : "OK",
"postalCode" : "74048",
"country" : "US",
"period" : {
"start" : "2020-07-22"
}
}]
}
この演算のリソースは OperationOutcome Resource です。
Resource が有効(上記のとおり)である場合、この種のレスポンスが得られます。
{
"resourceType": "OperationOutcome",
"issue": [
{
"severity": "information",
"code": "informational",
"details": {
"text": "All OK"
}
}
]
}
ただし、例えば上記の Resource から識別子を省略すると、この OperationOutcome が得られます。
{
"resourceType": "OperationOutcome",
"issue": [
{
"severity": "error",
"code": "invariant",
"details": {
"text": "generated-us-core-patient-1: Constraint violation: identifier.count() >= 1 and identifier.all(system.exists() and value.exists())"
},
"diagnostics": "Caused by: [[expression: identifier.count() >= 1, result: false, location: Patient]]",
"expression": [
"Patient"
]
}
]
}
クエリ本文でのプロファイリング
データを $validate に送信するもう 1 つの方法は、Parameters 配列内のリソースをプロファイルやその他のオプションとともに指定して POST 送信することです。
Postman では、これは以下のようになります。
curl を使用した場合:
curl --location 'http://fhirserver/endpoint/Patient/$validate' --header 'Content-Type: application/fhir+json' --header 'Accept: application/fhir+json' --header 'Authorization: Basic U3VwZXJVc2VyOnN5cw==' --data "@data.json"
URL にはプロファイルは含まれませんが、ボディのペイロード(または上記の例の data.json)は以下のようになります。
{
"resourceType": "Parameters",
"parameter": [
{
"name": "mode",
"valueString": "profile"
},
{
"name": "profile",
"valueUri": "http://hl7.org/fhir/us/core/StructureDefinition/us-core-patient"
},
{
"name": "resource",
"resource": {
"resourceType": "Patient"
}
}
]
}
実際の Patient Resource は前の例と同じであるため除外しました。
ただし、ここで異なるのは、mode パラメーター要素と profile パラメーター要素であり、リソースは「resource」という独自のパラメーター要素内に含まれています。
ID が URL のどこに含まれるかなど(たとえば、更新または削除を検証するため)、mode のその他のオプションについては、上記で参照したドキュメントをご覧ください。
便宜上、上記のサンプルリクエストなどの Postman コレクションを含む単純な Open Exchange パッケージを作成しました。
コードを使用
標準 REST API 経由で $validate 演算を呼び出す代わりに、ユースケースが適切であれば、内部的にクラスメソッドを呼び出すこともできます。
既存の HS.FHIRServer.Util.ResourceValidator:ValidateResource() メソッド(こちらのドキュメントでも説明)と同様に、ValidateAgainstProfile() という新しいメソッドも追加されており、それを利用できます。
範囲
現在(v2023.3)では、この種の検証(プロファイル基準の検証)は $validate 演算の一部としてのみ行われ、Resource の作成や更新時には行われないことに注意しておくことが重要です。 そこでは、より「基本的な」検証が行われます。 必要であれば、より「高度な」プロファイル基準の検証を使って、POST または PUT される前に Resouce を実行することができます。
別のオプションも、今後のバージョンで提供される可能性があります。
セットアップに関する注意事項
一般に、FHIR Server がほとんどの Profile Validator セットアップを処理します。
確認が必要なのは、サポートされている Java 11 JDK がインストールされていることです(現在、Oracle のものか OpenJDK のもの)。
詳細は、Profile Validation Server の構成に関するドキュメントをご覧ください。
基本的に、Validator JAR を実行するために、外部言語(Java)サーバーが実行中であることが確認されています(JAR ファイルはインストールフォルダの dev/fhir/java にあります。ちなみに、logs フォルダを覗くと、以下のような警告が表示されます:
CodeSystem-account-status.json : Expected: JsonArray but found: OBJECT for element: identifier
気にする必要はありません。 Validator はデフォルトで多数のプロファイルを読み込むものであり、その一部にはフォーマットエラーがあります)。
つまり、外部言語サーバーのリストを見ると、以下のようなものを確認できます。
Validator がプロファイルに対して検証する必要がある場合、初めてプロファイルをロードする必要があることに注意してください。そのため、パフォーマンスを向上させるために、HS.FHIRServer.Installer:InitalizeProfileValidator() メソッドを呼び出すことができます。
do ##class(HS.FHIRServer.Installer).InitializeProfileValidator()
これについても上記で参照したドキュメントには、Validator の構成に関して説明されています。
実際、この呼び出しをインスタンスの %ZSTART 起動ルーチンに含めることもできます。
また、これについても関連するクラスリファレンスで説明されています。
このメソッドは、検証操作中にプロファイルを読み込むことによるパフォーマンスへの影響がないように、インスタンスまたは外部言語サーバーの再起動後に呼び出すことが推奨されています。
今後の予定
今後のバージョンでは、Validator 内と Validator 周りにより多くの機能を提供する予定です。
ただし、例えば現時点でも、外部用語サーバーを使った検証(LOINC コードなど)を実行する場合、別のアプローチを使用することができます。1 つは、前述の Global Summit セッションで説明と実践が行われている方法で、同僚の @Dmitry.Zasypkin のサンプル(Open Exchange で提供)に基づくものです。
謝辞
この新機能を調べながらこの記事を準備するにあたって貴重な情報を提供してい頂いた @Kimberly.Santos にお礼申し上げます。
(*)Microsoft Bing の DALL-E 3 を使用して上記の画像を作成してくれた画像クリエーターに感謝しています。
記事
Toshihiko Minamoto · 2020年4月21日
Mirroring 101
Cachéミラーリングは、CachéおよびEnsembleベースのアプリケーションに適した信頼性が高く、安価で実装しやすい高可用性および災害復旧ソリューションです。 ミラーリングは幅広い計画停止シナリオや計画外停止シナリオで自動フェイルオーバーを提供するもので、通常はアプリケーションの回復時間を数秒に抑制します。 論理的にデータが複製されるため、単一障害点およびデータ破損の原因となるストレージが排除されます。 ほとんど、またはダウンタイムなしでアップグレードを実行できます。
ただし、Cachéミラーの展開にはかなり大がかりな計画が必要であり、さまざまな手順が要求されます。 また、他の重要なインフラストラクチャコンポーネントと同様に、運用中のミラーには継続的な監視とメンテナンスが必要とされます。
この記事はよくある質問のリスト、あるいはミラーリングの理解と評価、ミラーの計画、ミラーの設定、ミラーの管理という簡単な一連のガイドとして利用することができます。 それぞれの回答には、各トピックの詳細なディスカッションへのリンクと各タスクの段階的手順へのリンクが含まれています。
ミラーを導入する計画を始める準備ができたら、まずはCaché高可用性ガイドの「ミラーリング」の章のミラーリングのアーキテクチャと計画セクションから必ず読み始めるようにしてください。
よくある質問
ミラーリングの理解と評価
ミラーリングのメリットとは?
仮想化環境にミラーを導入できますか?
クラウドにミラーを導入できますか?
ミラーの基本的な設計はどうなっていますか?
データベースのコピーは、実際の本番データベースとどのように同期されますか?
自動フェールオーバーはどのようにトリガーされますか? フェールオーバーで対応できない状況はありますか?
ミラーは災害復旧(DR)機能を提供しますか?
ミラーの計画
ミラーのアーキテクチャはどのように計画すべきですか? メンバー構成や物理的配置はどのようになりますか?
ネットワークや遅延に関してどのようなことを考慮すべきですか? ミラーにはどのようなネットワーク構成が必要ですか?
フェイルオーバー時にアプリケーションの接続を新しいプライマリにリダイレクトするためのオプションにはどのようなものがありますか?
ミラー内のCachéインスタンスの互換性要件にはどのようなものがありますか?
既存のデータベースをミラーに移行するには?
仮想化環境にミラーを導入する場合に考慮すべきことはありますか?
ミラーの設定
どのような構成ガイドラインを考慮する必要がありますか?
ミラーを保護するには?
ミラー仮想IPアドレス(ミラーVIP)を構成するには?
アービターはどこにどのように配置すべきですか?
ISCAgentをインストールして起動するには?
ミラーを作成して構成するには?
ミラーデータベースを作成するには? 既存のデータベースをミラーに追加するには?
フェールオーバーした後、ECPにアプリケーションサーバーの接続をリダイレクトさせるには?
クラウドなどでミラーVIPが使用できない場合にアプリケーションの接続をリダイレクトさせるには?
Cachéシャドウをミラーに変換するには?
他にどのような構成情報を調べる必要がありますか?
ミラーの管理
ミラーの動作状態を監視するには?
ミラーを変更するには?変更できる 設定は?
ミラーにメンバーを追加できますか? メン バーを削除できますか? ミラーを完全に削除するには?
メンバーをミラーから一時的に削除する必要がある場合は?
ミラーはまとめてアップグレードする必要がありますか? そのためには、ミラーを本番環境から外す必要がありますか?
他にどのようなミラーまたはミラー関連の管理手順と情報を知っておくべきですか?
ミラーの停止手順
ミラーリングの理解と評価
ミラーリングのメリットとは?
CachéおよびEnsembleベースのアプリケーションでは、主にフェールオーバークラスター 、仮想化HA 、およびCachéミラーリングの3つの手法で高可用性を確保しています。 最初の2つの最大の欠点は、共有ストレージに依存していることです。そのため、ストレージの障害が発生すると甚大な被害が発生します。これは必要に応じてストレージレベルで冗長性を確保することにより改善できますが、ある種のデータ破損も引き続き発生する可能性があります。 さらに、ソフトウェアのアップグレードにはかなりのダウンタイムが必要であり、多くの障害ではアプリケーションの復旧に数分程度の時間を要する可能性があります。
ミラーリングでは2つの物理的に独立したシステムを使用して別々のストレージに論理データを複製することで、共有ストレージの問題を回避しています。また、アップグレードに必要とされるダウンタイムはゼロまたは最小限に抑えられているため、アプリケーションの復旧時間は通常数秒となります。 また、この手法では本番データセンターから適切な距離に災害復旧サイトを配置し、ミラーリングによる信頼性の高い堅牢な災害復旧機能を提供することができます。
ミラーリングの主な制限事項として、データベース自体のみを複製することが挙げられます。そのため、アプリケーションが必要とする外部ファイルには追加のソリューションが必要であり、現状はセキュリティと構成管理が分散化されています。
以下の情報源では、これらのHA手法の詳細な分析と比較、およびミラーリングのメリットに関する詳細な情報を提供しています。
システムフェールオーバー戦略(Caché高可用性ガイド)
高可用性手法(ホワイトペーパー)
事業継続性を実現する高可用性(ビデオ)
Cachéミラーリング:高可用性の冒険(ビデオ)
ミラーリング:スループットの設計(オンライン学習)
InterSystems Caché:データベースミラーリング:概要(ホワイトペーパー)
HealthShare:ミラーリングによる高可用性の実現(オンライン学習)
仮想化環境にミラーを導入できますか?
ミラーリングはよく仮想化環境に導入されています。 ミラーによって自動フェールオーバーを介した計画停止や計画外停止への即時対応が実現するいっぽうで、仮想化HAソフトウェアが計画外のマシンやOSの停止が発生した後にミラーメンバーをホストしている仮想マシンを自動的に再起動します。 そのため、障害が発生したメンバーはミラーにすばやく再参加し、バックアップとして機能することができます(または必要に応じてプライマリの役割を引き継ぐことができます)。
この手法の利用に関する情報は、InterSystemsのホワイトペーパー「高可用性手法」を参照してください。
クラウドにミラーを導入できますか?
ミラーリングは効果的にクラウドに導入できます 。 クラウドネットワークの制限により、フェイルオーバーした後に仮想IPアドレス(ミラーVIP)を使用してアプリケーションの接続をリダイレクトすることは通常は不可能ですが、これはロードバランサーなどのネットワークトラフィックマネージャーを使用することで実質的に解決できます 。
ミラーの基本的な設計はどうなっていますか?
通常、Cachéミラーにはフェールオーバーメンバーと呼ばれる物理的に独立したホスト上の2つのCachéインスタンスが含まれています。ミラーによってプライマリの役割が自動的に片方のインスタンスに割り当てられ、もう片方はバックアップになります。 アプリケーションがプライマリのデータベースを更新するいっぽうで、ミラーはバックアップのデータベースをプライマリのデータベースと同期させます。
プライマリに障害が発生するか使用できなくなると、バックアップが自動的にプライマリの役割を引き継ぎ、アプリケーションの接続がそちらにリダイレクトされます。 また、プライマリインスタンスが稼働できる状態に復帰したら自動的にバックアップになります。
メンテナンスやアップグレードのための計画停止中に可用性を維持するため、オペレーターは手動でフェールオーバーさせることができます。
ミラーには、必要に応じて災害復旧とビジネスインテリジェンス、およびデータウェアハウジングを目的とした非同期メンバーと呼ばれる追加のメンバーが含まれます。
ミラーは災害復旧が主な目的である場合など、1つのフェールオーバーメンバーと複数の非同期メンバーで動作することもできます。
データベースのコピーは、実際の本番データベースとどのように同期されますか?
ミラーのバックアップと非同期メンバーは、最後にバックアップされてからCachéインスタンスのデータベースに加えられた時系列の変更記録を含むジャーナルファイルを使用してプライマリと同期されます。 ミラー内ではプライマリからジャーナルファイルが送信され、他のメンバー上で記録が取り込まれます。つまり、ジャーナルファイルに記録された変更がデータベースのローカルコピーに適用され、プライマリの最新の状態に維持されます。
ジャーナルレコードはプライマリからバックアップに同期的に転送され、プライマリは要所要所でバックアップの承認を待ちます。 このような仕組みによってフェールオーバーメンバーが厳密に同期され、バックアップが有効になり、プライマリの役割を引き継げるようにもなります。 非同期メンバーはプライマリから非同期的にジャーナルデータを受信するため、結果としていくつかのジャーナルレコードを遅れて受信することがあります。
自動フェールオーバーはどのようにトリガーされますか? フェールオーバーで対応できない状況はありますか?
バックアップが自動的に役割を引き継げるのは、手動操作を行わなくてはプライマリを動作させることができなくなったことを認識した場合だけです。 フェールオーバーメンバー間の直接通信が途切れると、バックアップは両方のフェールオーバーメンバーと独立した接続を維持している3番目のシステムであるアービターの力を借りてこの状況を確認します。
また、バックアップがプライマリの最新ジャーナルデータを持っていることや取得できていることを確認できない場合、自動フェールオーバーは発生しません。 ISCAgentsと呼ばれる各フェールオーバーホスト上のCachéインスタンスとは独立して実行されるエージェントのプロセスが、この動作や自動フェールオーバーのロジックやメカニズムの他の場面に関与しています。
アービターが適切に機能していると仮定すれば、ほぼあらゆるプライマリの計画外停止に対応できます。有効なバックアップが障害が発生した、あるいは利用不可能なプライマリから役割を引き継ぐのを妨げるのは、両方のフェールオーバーメンバーをお互いに、さらにはアービターから分離するようなネットワーク障害だけです。
ミラーは災害復旧(DR)機能を提供しますか?
非同期ミラーメンバーの種類の1つに、災害復旧(DR)非同期メンバーがあります。 DR非同期メンバーはプライマリ上のデータベースをすべてミラーリングしたデータベースのコピーを持ち、いつでもフェールオーバーメンバーに昇格できます。 停止によってミラーの中に機能するフェールオーバーメンバーが存在しなくなる場合、昇格されたDR非同期メンバーに手動でフェールオーバーさせることができます。その場合のデータ損失範囲は、停止が発生した時点でDR非同期メンバーがプライマリからどの程度遅れているか、ならびに旧プライマリのホストシステムが機能しており、追加のジャーナルデータを取得できるかどうかによって決まります。 昇格されたDR非同期メンバーは、その他多くの計画停止や計画外停止の状況でも役立ちます。
ミラーの計画
ミラーのアーキテクチャはどのように計画すべきですか? メンバー構成や物理的配置はどのようになりますか?
ミラーのサイズ・メンバー構成・物理的配置は、ミラーを導入する理由やインフラストラ上および運用上の多くの要因によって決まり、非常に多くの構成が可能です。
2つのフェイルオーバーメンバーを持つミラーは、自動フェールオーバーによって高可用性を実現します。 オプションの非同期メンバーのうち、1つ以上のDR非同期メンバーがデータセキュリティ機能と災害復旧機能を提供できますが、レポート非同期メンバーはデータマイニングやビジネスインテリジェンスなどの目的に使用されます。 単一のレポート非同期メンバーは最大10個の独立したミラーに属することができ、企業全体のデータウェアハウスとして機能し、別々の場所から関連するデータベース一式をまとめることができます。
自動フェールオーバーが必要でない限り、ミラーは単一のフェールオーバーメンバーと、災害復旧およびレポート作成を目的とした多数の非同期メンバーで構成することもできます。
ミラーには最大で16個のメンバーを含めることができます。 フェールオーバーメンバーは遅延の少ない接続が必要とされるために通常は同じ場所に配置されますが、非同期メンバーはローカルまたは個別のデータセンターに配置できます。
複数のミラーメンバーを単一のホストに組み込むことができますが、計画が別途必要になります。
ネットワークや遅延に関してどのようなことを考慮すべきですか? ミラーにはどのようなネットワーク構成が必要ですか?
重要なネットワーク構成の考慮事項には、アプリケーションのパフォーマンスに関する重要な考慮事項である信頼性、帯域幅、ネットワークの遅延時間などがあります。 通常はプライマリから他のメンバーに転送されるジャーナルデータを圧縮することが好まれますが、常にそうであるとは限りません。
ミラーを支えるのに必要なネットワーク構成を計画する前に、各ミラーメンバーがさまざまな目的に使用される複数の異なるネットワークアドレスを持っていることを理解する必要があります。 ミラー構成およびネットワーク構成のサンプルが、必要なネットワーク構成を定義するのに役立ちます。このサンプルでは、単一のデータセンター、コンピュータールーム、またはキャンパス内のミラー、およびデュアルデータセンターを使ってDR機能を地理的に分散したミラーを紹介しています。
フェイルオーバー時にアプリケーションの接続を新しいプライマリにリダイレクトするためのオプションにはどのようなものがありますか?
ミラーリングとCachéには、ミラー用の仮想IPアドレス(VIP)の使用、ECPデータサーバーのミラー接続としての認識、ミラー対応のCSPゲートウェイといった複数の自動リダイレクトオプションが組み込まれています。
ミラー用のVIPは一般的に非常に効果的なソリューションですが、ネットワーク構成関連を中心にいくつかの事前計画が必要になります。
ロードバランサーなどのネットワークトラフィックマネージャーの使用、自動または手動でのDNSの更新、アプリケーションレベルのプログラミング、ユーザーレベルの手順を含め、さまざまな外部テクノロジーも利用できます。
ミラー内のCachéインスタンスの互換性要件にはどのようなものがありますか?
ミラーに追加するシステムを決める前に、Cachéインスタンスとプラットフォームのエンディアンに関する要件を必ず確認してください。 フェールオーバーメンバーはいつでもプライマリおよびバックアップとしての役割を交換できるため、できるだけ同じようなシステムにしなければなりません。CPUとメモリは同じまたは近い構成に、ストレージサブシステムは同等にしなければなりません。
既存のデータベースをミラーに移行するには?
任意のCachéデータベースをミラーに簡単に追加できます。必要なのはデータベースをバックアップして復元する機能か、CACHE.DATをコピーする機能のいずれかだけです。 手順については、次のセクションで説明します。
仮想化環境にミラーを導入する場合に考慮すべきことはありますか?
仮想化環境でミラーリングを使用する場合、仮想ミラーメンバーホストと物理ホスト・ストレージ間の正しい関係を計画することが重要です。ミラーと仮想化プラットフォームの両方の側面から見た重要な運用上の考慮事項もあります。
ミラーの設定
どのような構成ガイドラインを考慮する必要がありますか?
ミラー仮想IPアドレス(VIP)を構成する場合、InterSystemsは同じスーパーサーバーポートとウェブサーバーポートを使用するようにフェールオーバーメンバーを構成することを推奨しています。
プライマリフェールオーバーメンバー上のCachéインスタンス構成(ユーザー、役割、名前空間、マッピングなど)やミラー化されていないデータ(SQLゲートウェイやウェブサーバー構成に関連するファイルなど)は、他のミラーメンバー上のミラーによって複製されません。 したがって、バックアップやDR非同期メンバー(昇格されている場合もあります)がフェールオーバー発生時にプライマリから役割を引き継ぐために必要なすべての設定やファイルをそれらのメンバーに手動で複製し、必要に応じて更新する必要があります。
ミラーメンバーとして構成されているシステムではインターネット制御メッセージプロトコル(ICMP)を無効にしないでください。ミラーリングはICMPを利用してメンバーが到達可能かどうかを検出しています。
ジャーナリングはミラー同期の基礎であるため、一般的にはフェールオーバーメンバーのジャーナリングのパフォーマンスを監視および最適化し、ジャーナリングのベストプラクティスに従うことが不可欠です。 InterSystemsでは特にすべてのミラーメンバーで共有メモリヒープサイズを増やすことを推奨しています。
ミラーを保護するには?
ミラーリング通信の保護には、X.509証明書を使用してミラー内の全トラフィックを暗号化するSSL/TLSが主に使用されます。 SSL/TLSによる保護を強く推奨します。 ミラーでSSL/TLSを有効にするには、最初に各ミラーメンバーでミラーのSSL/TLS構成を作成する必要があります。ミラーを作成する前にこの構成を行うのが最も便利かもしれません。 SSL/TLSが有効になっている場合、ミラーに追加される各メンバーはプライマリ側で承認を受ける必要があります。あるメンバーのX.509証明書が更新された場合も同様です。
SSL/TLSを使用するミラーに対する保護をさらに強化するため、ジャーナルの暗号化を有効化することができます。 これにより、ジャーナルレコードはプライマリ上で作製される際に有効な暗号鍵のいずれかを使用して暗号化され、他のメンバー上でジャーナルが取り込まれる前に復号化されます。 バックアップとすべての非同期メンバーでは同じ鍵を有効化する必要があり、バックアップとDR非同期メンバーもその鍵を使用してデータを暗号化する必要があります。
ミラーが使用するネットワークを構成する方法も、ミラーの安全性に重大な影響を及ぼします。
ミラー仮想IPアドレス(ミラーVIP)を構成するには?
ミラーVIPは、ミラーを作成する際やメンバーを追加する際、またはミラーを変更する際に詳細を入力することで構成されます。ただし、必要な情報を特定したり、場合によってはミラーメンバーのホストやCachéインスタンスを構成したりといった準備が必要になります。
アービターはどこにどのように配置すべきですか?
アービターは、アービターとフェールオーバーメンバーの計画外停止が同時に発生するリスクを最小限に抑えるように配置すべきです(両方のフェールオーバーが発生した場合、アービターは無意味になります)。そのため、アービターの配置場所は主にフェイルオーバーメンバーの場所によって決まります。 複数のミラーがある場合、それぞれに対して適切に配置されているという条件で単一のシステムをアービターとして構成できます。 1つのミラーに対して1つ以上のフェイルオーバーメンバーかDR非同期メンバーをホストしているシステムは、そのミラーのアービターとして構成しないでください。
Cachéバージョン2015.1以降のインスタンスを1つ以上ホストしているシステムなど、バージョン2015.1以降のISCAgentを実行しているシステムはアービターとして構成できます。 ISCAgentをインストールすることで、2015.1未満のCachéインスタンスをホストしているシステムを含む他のサポート対象システム(OpenVMSシステムを除く)をアービターとして構成できます。
ISCAgentをインストールして起動するには?
ISCAgentはCachéと一緒に自動的にインストールされるため、すべてのミラーメンバーにインストールされています。 ただし、エージェントは各ミラーメンバーのシステム起動時に起動するよう構成する必要があります。
ミラーを作成して構成するには?
ミラーを構成するには、次のような複数の手順を実施する必要があります。
ミラーを作成して最初のフェールオーバーメンバーを構成する
2番目のフェールオーバーメンバーを構成する(必要な場合)
2番目のフェールオーバーメンバーを承認する(SSL/TLSを使用する場合に推奨)
非同期ミラーメンバーを構成する(必要に応じてDRまたはレポートのいずれかを構成)
新しい非同期メンバーを承認する(SSL/TLSを使用する場合に推奨)
これらの手順のいずれかを完了すると、Mirror Monitorでミラーの状態を調査し、意図したとおりの結果を得られたかを確認することができます。
ミラーデータベースを作成するには? 既存のデータベースをミラーに追加するには?
データベースをミラーに追加する前に、ミラーリングできるものとできないもの、ミラーリングとシャドーイングの同時使用、ミラーリングデータベースのプロパティの伝播、およびミラーリング対象となっているインスタンスごとのデータベースの最大数に関する一定のミラーデータベースの考慮事項を確認することをお勧めします。
ミラーデータベースの作成と既存データベースの追加手順は異なります。ミラーデータベースへの変更はミラーされたジャーナルファイルに記録され、非ミラージャーナルファイルとは異なるからです。 データベースがミラーデータベースとして作成されている場合は最初からミラージャーナルファイルが使用されます。そのため、プライマリを始めとする各ミラーメンバーに同じミラー名のミラーデータベースを作成することで、簡単に新しいデータベースをミラーに追加することができます。
プライマリ上にミラーデータベースとして既存の非ミラーデータベースを追加する場合、非ミラージャーナルファイルからミラージャーナルファイルを使用するように切り替わります。 そのため、単純に他のメンバー上にデータベースを作成することはできません。なぜなら、ミラーは非ミラージャーナルファイルを他のメンバーに転送できないからです。 代わりに、データベースがプライマリのミラーに追加された後にデータベースをバックアップして他のメンバーに復元するか、そのCACHE.DATファイルを他のメンバーにコピーする必要があります。
フェールオーバーした後、ECPにアプリケーションサーバーの接続をリダイレクトさせるには?
ミラーVIPを構成したかどうかにかかわらず、接続する各ECPアプリケーションサーバー上のミラー接続としてミラーECPデータサーバーを構成することにより、ECP接続を新しいプライマリにリダイレクトさせることができます。 (アプリケーションサーバーは指定されたホストから定期的に情報を収集し、フェールオーバーを自動的に検出して新しいプライマリに切り替えるため、VIPを使用しません。)
クラウドなどでミラーVIPが使用できない場合にアプリケーションの接続をリダイレクトさせるには?
ミラーVIPはミラーメンバーが同じネットワークサブネット上にある場合にのみ使用できますので、一般的にはミラーメンバーが別々のデータセンターにある場合は使用できません。 同様の理由で、VIPは一般的にクラウドに導入できるオプションではありません。
VIPと同レベルの透過性を実現するために使用され、クライアントアプリケーションやデバイスに単一のアドレスを提示するロードバランサーなどのネットワークトラフィックマネージャーの使用(物理または仮想)を含め、さまざまな外部テクノロジーも利用できます。 その他に想定される手順には、自動または手動でのDNSの更新、アプリケーションレベルのプログラミング、およびユーザーレベルの手順などがあります。
Cachéシャドウをミラーに変換するには?
ミラーリングは、シャドウのソースと宛先、およびそれらの間にマッピングされたシャドウデータベースをプライマリ、バックアップまたは非同期メンバーを含むミラーとミラーベーデータベースに変換するシャドウ・ミラーユーティリティを提供します。
他にどのような構成情報を調べる必要がありますか?
通常はデフォルトで十分ですが、必要に応じてISCAgentポート番号をカスタマイズできます。
プライマリフェールオーバーメンバーでは、必要に応じて既存の^ZSTUまたは^ZSTARTルーチンからユーザー定義の^ZMIRRORルーチンにコードを移動することができます。これにより、特定のミラーリングイベント用に独自構成固有のロジックと機構をミラーが初期化されるまで実行しないように実装することができます。
Ensembleでミラーリングを使用する場合、ミラーデータを含むEnsemble名前空間の特別な要件とミラー環境でのEnsemble Autostartの機能に注意する必要があります。
ミラーの管理
ミラーの動作状態を監視するには?
任意のミラーメンバーのCaché管理ポータルで読み込めるMirror Monitorでは、以下の詳細な情報を確認できます。
SSL/TLSを使用中のメンバーのx.509 DNを含むミラーとその各メンバーの動作状態。
フェールオーバーメンバーの場合は、両方のフェールオーバーメンバーのネットワークアドレスとアービターの接続状態、およびアービターのアドレス。非同期メンバーの場合は、レポート非同期メンバーが属するミラー。
バックアップおよび非同期メンバーの場合は、プライマリからのジャーナルデータ転送とジャーナルデータの取り込みの状態、およびプライマリから届くジャーナルデータの転送速度。
Mirror Monitorを読み込むメンバー上のミラーデータベースの状態。
Mirror Monitorでは、メンバーのジャーナルファイルの表示や検索、DR非同期メンバーのフェールオーバーメンバーへの昇格・バックアップのDR非同期メンバーへの降格、ミラーデータベースの有効化・キャッチアップ・削除などのさまざまな操作を実行できます。
ミラーメンバーのミラー通信プロセスを監視するため、該当ミラーメンバーの%SYS名前空間でCachéシステム状態ルーチン(^%SS)を使用できます。
ミラーを変更するには?変更できる設定は?
ミラーの構成(SSL/TLS、ミラーVIPその他)を変更したり、ネットワーク構成変更時にメンバーのネットワークアドレスを更新したりするには、プライマリでミラーを編集してください。 また、プライマリのミラーを編集して他のメンバー上でのX.509証明書の更新を承認する必要があります。
非同期の種類を変更し、レポート非同期メンバーを別のミラーに追加し、その他非同期メンバー固有の変更を行うには、非同期メンバーのミラーを編集してください。
Mirror Monitorを使用して任意のメンバー(およびそのメンバーのみ)のミラーからミラーデータベースを削除できますが、その影響は関連するメンバーの種類によって異なります。
ミラーにメンバーを追加できますか? メンバーを削除できますか? ミラーを完全に削除するには?
ミラーにはいつでも合計16メンバーの上限まで非同期メンバーを追加できます。 フェールオーバーメンバーが1つで非同期メンバーが15未満の場合はいつでもバックアップを追加できます。 DR非同期メンバーを昇格してフェールオーバーメンバーにすることでバックアップを置き換え、現在のバックアップをDR非同期メンバーに自動的に降格させることもできます。
任意のメンバーでミラーを編集し、ミラーからそのメンバーを削除できます。 ミラーを完全に削除するには、特定の順序でメンバーを削除し、追加の手順を実行する必要があります。
メンバーをミラーから一時的に削除する必要がある場合は?
Mirror Monitorを使用すればメンテナンスや(非同期メンバーの場合に)ネットワーク負荷軽減などを目的としてミラーからメンバーを切り離すことで、無期限にバックアップまたは非同期メンバーのミラーを停止することができます。
非同期メンバーでは、プライマリから非同期メンバーへのジャーナルデータ転送を止めることなくミラー内の全データベースに対してジャーナルの取り込みを停止することもできます。
ミラーはまとめてアップグレードする必要がありますか? そのためには、ミラーを本番環境から外す必要がありますか?
ミラーを構成するすべてのフェールオーバーメンバーとDR非同期メンバーは同じバージョンのCachéでなければならず、違っていても構わないのはミラーをアップグレードする間だけです。 アップグレードされたメンバーがプライマリになると、他のフェールオーバーメンバーやDR非同期メンバーは同様にアップグレードされるまで使用できなくなります。 一般的に、レポート非同期メンバーを同じバージョンに同時にアップグレードするのがベストプラクティスとされています。
アップグレード手順は、メンテナンスリリースのアップグレード、ミラーデータベースへの変更を一切伴わないメジャーアップグレード、ミラーデータベースへの変更を伴うメジャーアップグレードのどれを行うかによって決まります。 定められた手順は、アプリケーションのダウンタイムを最小限に抑えるよう工夫されています。通常、最初の2つのケースではダウンタイムを完全員回避できます。また、最後のケースでは一般的に計画フェールオーバーを実行して必要なミラーデータベースの変更にかかる時間内に限定されます。
計画ダウンタイム中にメジャーアップグレードを行い、アプリケーションのダウンタイムを最小限に抑える必要がない場合に採用できるより簡単な手順もあります。
他にどのようなミラーまたはミラー関連の管理手順と情報を知っておくべきですか?
各メンバーに有効なミラーのSSL/TLS構成があるという前提で、まだそれを利用していないミラーのSSL/TLS保護を有効化できます。
ミラーにSSL/TLS保護を使用しており、プライマリ上のジャーナルデータを暗号化する有効な暗号鍵がバックアップとすべての非同期メンバーで有効化されているという前提で、ジャーナルの暗号化を利用していないミラーでジャーナルの暗号化を有効化できます。
ハードウェアとネットワークの構成に応じてミラーのサービス品質タイムアウト(QoSタイムアウト)設定を調整することができます。この設定はフェールオーバー機構で重要な役割を果たします。 一般的に、専用ローカルネットワークを持つ(仮想化されていない)物理ホストに展開されたミラーでより迅速な停止への対応が求められる場合にこの設定を減らすことができます。
ミラーデータベースの更新内容の大部分が高圧縮データ(圧縮済みの画像など)や暗号化されたデータである場合、ジャーナルデータの圧縮は効果的ではないと予想され、CPU時間を浪費する可能性があります。 このような場合は、ミラーを構成または変更してジャーナルデータを非圧縮に設定することができます。 (Cachéデータベースの暗号化やジャーナルの暗号化を利用しても、圧縮を選択したことにはなりません。)
プライマリと他のミラーメンバー間のネットワーク遅延が問題になる場合は、プライマリおよびバックアップ/非同期メンバーがそれぞれ適切なサイズの送信および受信バッファを確立できるようにオペレーティングシステムのTCPパラメーターを微調整することで遅延を緩和できる場合があります。
^MIRRORルーチンはあらゆるミラーリングタスク用に、管理ポータルの代わりとなるコマンドラインを提供します。 SYS.Mirror APIは管理ポータルと^MIRRORルーチンを通じて利用可能なミラー操作をプログラムで呼び出すためのメソッドを提供します。
ミラーの停止手順
さまざまな計画的および計画外のミラー停止シナリオに対処するための推奨手順の概要については、ミラーの停止手順を参照してください。
記事
Tomoko Furuzono · 2020年9月17日
Caché 2017以降のSQLエンジンには新しい統計一式が含まれています。 これらの統計は、クエリの実行回数とその実行所要時間を記録します。
これは、多くのSQLステートメントを含むアプリケーションのパフォーマンスを監視する人や最適化を試みる人にとっては宝物のような機能ですが、一部の人々が望むほどデータにアクセスするのは簡単ではありません。
この記事と関連するサンプルコードでは、このような情報の使用方法と、日次統計の概要を定期的に抽出してアプリケーションのSQLパフォーマンス履歴記録を保持する方法について説明します。
※詳細については、下記ドキュメントページもご参考になさってください。
https://docs.intersystems.com/iris20201/csp/docbook/DocBook.UI.Page.cls?KEY=GSQLOPT_sqlstmts
記録内容
SQLステートメントが実行されるたびに、所要時間が記録されます。 この処理は非常に軽量であり、オフにすることはできません。 コストを最小限に抑えるため、統計はメモリに保持されてから定期的にディスクに書き込まれます。 このデータには当日にクエリが実行された回数と、その平均所要時間と合計所要時間が含まれます。
データはすぐにはディスクに書き込まれません。ただし、統計はデータが書き込まれた後に通常は1時間ごとに実行されるようにスケジュールされている「SQLクエリ統計の更新」タスクによって更新されます。 このタスクは手動で起動できますが、クエリをテスト中にリアルタイムで統計を表示したい場合は、プロセス全体の実行時間が若干長くなります。
警告:InterSystems IRIS 2019以前では、%Studio.Project:Deploy メカニズムを使用して配置されたクラスやルーチンに埋め込まれたSQLのこれらの統計は収集されません。 サンプルコードを破壊するものは何もありませんが、コストがかかるものが何も表示されないため、すべてが正常であると思い込んでしまう可能性があります(私はそう思い込んでしまいました)。
確認できる情報
クエリのリストを管理ポータルで確認できます。 [SQL] ページに移動し、[SQLステートメント] タブをクリックしてください。 これは実行中および調査中の新しいクエリには適していますが、膨大な数のクエリが実行中の場合は管理しきれなくなる可能性があります。
別の方法として、SQLを使用してクエリを検索することができます。 情報は、INFORMATION_SCHEMAスキーマのテーブルに保存されます。 このスキーマには多数のテーブルが含まれていますが、この記事の最後にいくつかのサンプルSQLクエリを掲載しています。
統計が削除されるタイミング
クエリのデータは、クエリが再コンパイルされるたびに削除されます。 そのため、動的クエリの場合はキャッシュ済みのクエリがパージされる可能性があります。 埋め込みSQLの場合、それはSQLが埋め込まれているクラスやルーチンが再コンパイルされるタイミングになります 。
※IRIS2020.1 以降では、埋め込みSQLも動的クエリと同様に、クエリが再コンパイルされるたびにデータが削除されます。
稼働中のサイトでは1日以上統計が保持されると思われますが、統計を保持しているテーブルは、レポートや長期分析を実行するための長期参照ソースには使用できません。
情報を要約するには
パフォーマンスレポートを生成する際は、作業しやすい永続的なテーブルに毎晩データを抽出することをお勧めします。 クラスが日中にコンパイルされる場合は一部の情報が失われる可能性がありますが、それによってスロークエリの分析に実質的な違いが出ることはほとんどありません。
以下のコードは、各クエリの日次概要に統計を抽出する方法の例です。 このコードには3つの短いクラスが含まれています。
毎晩実行する必要があるタスク。
DRL.MonitorSQLは、INFORMATION_SCHEMAテーブルからデータを抽出して保存するメインクラスです。
3番目のクラスであるDRL.MonitorSQLTextは(長い可能性がある)クエリテキストを1回だけ保存し、毎日の統計にクエリのハッシュのみを保存する最適化です。
サンプルに関する注意
このタスクは前日分のデータを抽出するため、午前0時を過ぎた直後にスケジュールする必要があります。
履歴データが存在する場合は、それをエクスポートできます。 過去120日間を抽出するには以下を実行します。
Do ##class(DRL.MonitorSQL).Capture($h-120,$h-1)
最も古いバージョンの統計ではDateがSQLに公開されていなかったため、サンプルコードでは^rIndexグローバルを直接読み取っています。
私が含めたバリエーションはインスタンス内のすべての名前空間を通ってループしますが、それが常に適切であるとは限りません。
抽出されたデータに対してクエリを実行するには
データを抽出したあと、以下のクエリを実行することで最も重いクエリを見つけることができます。
SELECT top 20
S.RunDate,S.RoutineName,S.TotalHits,S.SumpTIme,S.Hash,t.QueryText
from DRL.MonitorSQL S
left join DRL.MonitorSQLText T on S.Hash=T.Hash
where RunDate='08/25/2019'
order by SumpTime desc
また、高コストなクエリのハッシュを選択すると、そのクエリの履歴を表示できます。
SELECT S.RunDate,S.RoutineName,S.TotalHits,S.SumpTIme,S.Hash,t.QueryText
from DRL.MonitorSQL S
left join DRL.MonitorSQLText T on S.Hash=T.Hash
where S.Hash='CgOlfRw7pGL4tYbiijYznQ84kmQ='
order by RunDate
私は今年の初めに本番サイトからデータを収集し、最も高コストなクエリを調べました。 1つのクエリの平均実行時間は6秒未満でしたが、1日あたり14,000回呼び出されており、毎日合計で24時間近くかかっていました。 事実上、この1つのクエリで1つのコアが完全に占有されていました。 さらに悪いことに、1時間かかる2番目のクエリは1番目のクエリのバリエーションでした。
RunDate
RoutineName
Total Hits
Total Time
Hash
QueryText(略記)
03/16/2019
14,576
85,094
5xDSguu4PvK04se2pPiOexeh6aE=
DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) …
03/16/2019
15,552
3,326
rCQX+CKPwFR9zOplmtMhxVnQxyw=
DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) , …
03/16/2019
16,892
597
yW3catzQzC0KE9euvIJ + o4mDwKc =
DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) , :%col(5) , :%col(6) , :%col(7) ,
03/16/2019
16,664
436
giShyiqNR3K6pZEt7RWAcen55rs=
DECLARE C CURSOR FOR SELECT * , TKGROUP INTO :%col(1) , :%col(2) , :%col(3) , ..
03/16/2019
74,550
342
4ZClMPqMfyje4m9Wed0NJzxz9qw=
DECLARE C CURSOR FOR SELECT …
表1:顧客サイトでの実際の結果
INFORMATION_SCHEMAスキーマのテーブル
このスキーマのテーブルは統計だけでなく、使用されているクエリ、カラム、インデックスなどを 追跡しています。 通常はそのSQLステートメントが最初のテーブルになり、"Statements.Hash = OtherTable.Statement" のような形で結合されます。
これらのテーブルに直接アクセスし、1日で最も高コストなクエリを見つけるための対応するクエリは以下のようになります。
SELECT DS.Day,Loc.Location,DS.StatCount,DS.StatTotal,S.Statement,S.Hash
FROM INFORMATION_SCHEMA.STATEMENT_DAILY_STATS DS
left join INFORMATION_SCHEMA.STATEMENTS S
on S.Hash=DS.Statement
left join INFORMATION_SCHEMA.STATEMENT_LOCATIONS Loc
on S.Hash=Loc.Statement
where Day='08/26/2019'
order by DS.stattotal desc
より体系的なプロセスのセットアップを検討しているかどうかに関係なく、SQLを使用する大規模アプリケーションを持つすべての方に今すぐこのクエリを実行することをお勧めします。
特定のクエリが高コストであると表示される場合は、次を実行して履歴を取得できます。
SELECT DS.Day,Loc.Location,DS.StatCount,DS.StatTotal,S.Statement,S.Hash
FROM INFORMATION_SCHEMA.STATEMENT_DAILY_STATS DS
left join INFORMATION_SCHEMA.STATEMENTS S
on S.Hash=DS.Statement
left join INFORMATION_SCHEMA.STATEMENT_LOCATIONS Loc
on S.Hash=Loc.Statement
where S.Hash='jDqCKaksff/4up7Ob0UXlkT2xKY='
order by DS.Day
日次統計を週出するためのコードサンプル
Class DRL.MonitorSQLTask Extends %SYS.Task.Definition
{
Parameter TaskName = "SQL Statistics Summary";
Method OnTask() As %Status
{
set tSC=$$$OK
TRY {
do ##class(DRL.MonitorSQL).Run()
}
CATCH exp {
set tSC=$SYSTEM.Status.Error("Error in SQL Monitor Summary Task")
}
quit tSC
}
}
Class DRL.MonitorSQLText Extends %Persistent
{
/// Hash of query text
Property Hash As %String;
/// query text for hash
Property QueryText As %String(MAXLEN = 9999);
Index IndHash On Hash [ IdKey, Unique ];
}
/// Summary of very low cost SQL query statistics collected in Cache 2017.1 and later. <br/>
/// Refer to documentation on "SQL Statement Details" for information on the source data. <br/>
/// Data is stored by date and time to support queries over time. <br/>
/// Typically run to summarise the SQL query data from the previous day.
Class DRL.MonitorSQL Extends %Persistent
{
/// RunDate and RunTime uniquely identify a run
Property RunDate As %Date;
/// Time the capture was started
/// RunDate and RunTime uniquely identify a run
Property RunTime As %Time; /// Count of total hits for the time period for
Property TotalHits As %Integer; /// Sum of pTime
Property SumPTime As %Numeric(SCALE = 4); /// Routine where SQL is found
Property RoutineName As %String(MAXLEN = 1024); /// Hash of query text
Property Hash As %String; Property Variance As %Numeric(SCALE = 4); /// Namespace where queries are run
Property Namespace As %String; /// Default run will process the previous days data for a single day.
/// Other date range combinations can be achieved using the Capture method.
ClassMethod Run()
{
//Each run is identified by the start date / time to keep related items together
set h=$h-1
do ..Capture(+h,+h)
} /// Captures historic statistics for a range of dates
ClassMethod Capture(dfrom, dto)
{
set oldstatsvalue=$system.SQL.SetSQLStatsJob(-1)
set currNS=$znspace
set tSC=##class(%SYS.Namespace).ListAll(.nsArray)
set ns=""
set time=$piece($h,",",2)
kill ^||TMP.MonitorSQL
do {
set ns=$o(nsArray(ns))
quit:ns=""
use 0 write !,"processing namespace ",ns
zn ns
for dateh=dfrom:1:dto {
set hash=""
set purgedun=0
do {
set hash=$order(^rINDEXSQL("sqlidx",1,hash))
continue:hash=""
set stats=$get(^rINDEXSQL("sqlidx",1,hash,"stat",dateh))
continue:stats=""
set ^||TMP.MonitorSQL(dateh,ns,hash)=stats
&SQL(SELECT Location into :tLocation FROM INFORMATION_SCHEMA.STATEMENT_LOCATIONS WHERE Statement=:hash)
if SQLCODE'=0 set Location=""
set ^||TMP.MonitorSQL(dateh,ns,hash,"Location")=tLocation
&SQL(SELECT Statement INTO :Statement FROM INFORMATION_SCHEMA.STATEMENTS WHERE Hash=:hash)
if SQLCODE'=0 set Statement=""
set ^||TMP.MonitorSQL(dateh,ns,hash,"QueryText")=Statement
} while hash'=""
}
} while ns'=""
zn currNS
set dateh=""
do {
set dateh=$o(^||TMP.MonitorSQL(dateh))
quit:dateh=""
set ns=""
do {
set ns=$o(^||TMP.MonitorSQL(dateh,ns))
quit:ns=""
set hash=""
do {
set hash=$o(^||TMP.MonitorSQL(dateh,ns,hash))
quit:hash=""
set stats=$g(^||TMP.MonitorSQL(dateh,ns,hash))
continue:stats=""
// The first time through the loop delete all statistics for the day so it is re-runnable
// But if we run for a day after the raw data has been purged, it will wreck eveything
// so do it here, where we already know there are results to insert in their place.
if purgedun=0 {
&SQL(DELETE FROM websys.MonitorSQL WHERE RunDate=:dateh )
set purgedun=1
}
set tObj=##class(DRL.MonitorSQL).%New() set tObj.Namespace=ns
set tObj.RunDate=dateh
set tObj.RunTime=time
set tObj.Hash=hash
set tObj.TotalHits=$listget(stats,1)
set tObj.SumPTime=$listget(stats,2)
set tObj.Variance=$listget(stats,3)
set tObj.Variance=$listget(stats,3)
set queryText=^||TMP.MonitorSQL(dateh,ns,hash,"QueryText")
set tObj.RoutineName=^||TMP.MonitorSQL(dateh,ns,hash,"Location")
&SQL(Select ID into :TextID from DRL.MonitorSQLText where Hash=:hash)
if SQLCODE'=0 {
set textref=##class(DRL.MonitorSQLText).%New()
set textref.Hash=tObj.Hash
set textref.QueryText=queryText
set sc=textref.%Save()
}
set tSc=tObj.%Save()
//avoid dupicating the query text in each record because it can be very long. Use a lookup
//table keyed on the hash. If it doesn't exist add it.
if $$$ISERR(tSc) do $system.OBJ.DisplayError(tSc)
if $$$ISERR(tSc) do $system.OBJ.DisplayError(tSc)
}while hash'=""
} while ns'=""
} while dateh'=""
do $system.SQL.SetSQLStatsJob(0)
} Query Export(RunDateH1 As %Date, RunDateH2 As %Date) As %SQLQuery
{
SELECT S.Hash,RoutineName,RunDate,RunTime,SumPTime,TotalHits,Variance,RoutineName,T.QueryText
FROM DRL.MonitorSQL S LEFT JOIN DRL.MonitorSQLText T on S.Hash=T.Hash
WHERE RunDate>=:RunDateH1 AND RunDate<=:RunDateH2
}
}
記事
Tomohiro Iwamoto · 2020年8月17日
# 本稿について
本稿では、InterSystems IRISを使用してSQLベースのベンチマークを行う際に、実施していただきたい項目をご紹介します。
Linuxを念頭においていますが、Windowsでも考慮すべき点は同じです。
## メモリ自動設定をやめる
パフォーマンスに直結する、データベースバッファサイズの[自動設定](https://docs.intersystems.com/irislatestj/csp/docbook/Doc.View.cls?KEY=GSA_config#GSA_config_system_startup)はデフォルトで有効になっています。自動設定は、実メモリの搭載量にかかわらず、データベースバッファを最大で1GBしか確保しません。
> 更新: 2020年11月20日 バージョン2020.3から、確保を試みるデータベースバッファが実メモリの25%に変更されました。
搭載実メモリ64GB未満の場合は実メモリの50%程度、搭載実メモリ64GB以上の場合は実メモリの70%を目途に、明示的に設定を行ってください。
設定するにはiris停止状態で、iris.cpfファイル(IRISインストール先\mgr\iris.cpf)を変更します。下記はブロックサイズ8KB用(既定値です)のデータベースバッファサイズの自動構成を4096(MB)に変更する例です。
修正前
```
[config]
globals=0,0,0,0,0,0
```
修正後
```
[config]
globals=0,0,4096,0,0,0
```
詳細は[こちら](https://docs.intersystems.com/irislatestj/csp/docbook/Doc.View.cls?KEY=GSCALE_vertical#GSCALE_vertical_memory_initial)です。
また、Linuxの場合、[ヒュージ・ページ有効化](https://docs.intersystems.com/irislatestj/csp/docbook/Doc.View.cls?KEY=GSCALE_vertical#GSCALE_vertical_memory_large)の設定を行ってください。設定値の目安ですが、IRIS起動時のメッセージから、確保される共有メモリサイズ(下記だと749MB)を読み取り、その値めがけて設定するのが簡単です。
> コンテナバージョンは非rootで動作するため、ヒュージ・ページは利用できません
```
$ iris start iris
Starting IRIS
Using 'iris.cpf' configuration file
Starting Control Process
Allocated 749MB shared memory: 512MB global buffers, 64MB routine buffer
$ cat /proc/meminfo
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
```
ページサイズが2048kBですので、750MB(丸めました)を確保するには750/2=375ページ必要になります。構成を変えると必要な共有メモリサイズも変わりますので、再調整してください。
```
$ echo 375 > /proc/sys/vm/nr_hugepages
$ iris start iris
Starting IRIS
Using 'iris.cpf' configuration file
Starting Control Process
Allocated 750MB shared memory using Huge Pages: 512MB global buffers, 64MB routine buffer
```
メモリ関連の設定値は、パフォーマンスに大きく影響しますので、比較対象のDBMSが存在するのであればその設定値に見合う値を設定するようにしてください。
## データベース関連ファイルの配置
特にクラウド上でのベンチマークの場合、ストレージのレイアウトがパフォーマンスに大きな影響を与えます。クラウドではストレージごとのIOPSが厳格に制御されているためです。
[こちら](https://docs.intersystems.com/irislatestj/csp/docbook/DocBook.UI.Page.cls?KEY=GCI_prepare_install#GCI_filesystem)に細かな推奨事項が掲載されていますが、まずは下記のように、アクセス特性の異なる要素を、それぞれ別のストレージに配置することをお勧めします。
```
Filesystem Size Used Avail Use% Mounted on
/dev/sdc 850G 130G 720G 16% /irissys/data (IRIS本体のインストール先、ユーザデータべース)
/dev/sdd 800G 949M 799G 1% /irissys/wij (ライトイメージジャーナルファイル)
/dev/sde 200G 242M 200G 1% /irissys/journal1 (ジャーナルファイル)
/dev/sdf 100G 135M 100G 1% /irissys/journal2 (予備のジャーナルファイル保存エリア)
```
サイズは用途次第です。WIJに割り当てているサイズが大きめなのは、IOPS性能がファイルシステムの容量に比例するクラウドを使用するケースを意識したためで、IOPSとサイズが連動しないオンプレミス環境では、これほどのサイズは必要ありません。
## テーブルへのインデックス追加
IRISのテーブルへのインデックス追加は一部のDWH製品のように自動ではありません。多くのRDBMS製品と同様に、CREATE TABLE命令の実行時に、プライマリキー制約やユニーク制約が指定されている場合、インデックが追加されますが、それ以外のインデックスはCREATE INDEX命令で明示的に追加する必要があります。
どのようなインデックスが有用なのかは、実行するクエリに依存します。
一般的に、ジョインの結合条件(ON句)となるフィールド、クエリやUPDATE文の選択条件(WHERE句)となるフィールド、グルーピングされる(GROUP BY)フィールドが対象となります。
[インデックスの対象](https://docs.intersystems.com/irislatestj/csp/docbook/DocBook.UI.Page.cls?KEY=GSQLOPT_optquery#GSQLOPT_optquery_indexfields)を参照ください。
## データベースファイルのサイズ
IRISのデータベースファイルの初期値は1MBです。既定では、ディスク容量が許容する限り自動拡張を行いますので、エラーにはなりませんが、パフォーマンスは劣化します。ベンチマークプログラムでそのことに気づくことはありません。お勧めは、一度ベンチマークを実行して、必要な容量まで自動拡張を行い、データを削除(DROP TABLEやTRUNCATE TABLEを実行)した後に、再度ベンチマークを実行することです。
## 統計情報の取得
IRISはクエリの実行プランを最適化するために、テーブルデータに関する統計情報を使用します。
統計情報の取得処理(TuneTable/TuneSchema)は、初期データロード後に明示的に実行する必要があります。
> IRISバージョン2022.1以降、統計情報の取得処理が一度も実行されていない場合、初回のクエリ実行時に自動実行されるようになりました。そのため、初回のクエリに若干のオーバヘッドが発生します。
TuneTable(テーブル対象)/TuneSchema(スキーマ対象)を実行すると、既存のクエリプランがパージされるので、次回の初回クエリ実行時はクエリ解析・プラン生成にかかる分だけ時間が多めにかかります。
また、TuneTable/TuneSchema実行後にインデックスを追加した場合には、そのテーブルに対してTuneTableを再実行してください。
これらを考慮すると、ベンチマークで安定した計測結果を得るには、テストデータのロード後に、明示的に下記を実施することが重要になります。
- TuneTable/TuneSchemaを実行
- 最低でも一度は全クエリを実行する
> もちろん、これらの性能を計測したい場合は、その限りではありません。
TuneTable/TuneSchemaは、管理ポータル及びCLIで、手動で[実行可能](http://docs.intersystems.com/irislatestj/csp/docbook/Doc.View.cls?KEY=GSQLOPT_opttable#GSQLOPT_opttable_tunetable_run)です。ベンチマーク測定時は、データの再投入やインデックスの追加や削除といった、統計情報の更新を繰り返し実行する必要性が高くなることを考慮すると、手動での更新は避けて、下記のObjectScriptのCLIやSQL文で実施するのが効果的です。
下記コマンドはスキーマMySchemaで始まる全てのテーブルの統計情報を取得します。
```
MYDB>d $SYSTEM.SQL.Stats.Table.GatherSchemaStats("MySchema")
```
下記コマンドは指定したテーブルのテーブルの統計情報を取得します。
```
MYDB>d $SYSTEM.SQL.Stats.Table.GatherTableStats("MySchema.MyTable")
```
あるいはSQL文として、データロード実行後にベンチマークプログラム内で実行する事も可能です。
```SQL
TUNE TABLE MySchema.MyTable
```
## タイムスタンプ型に%TimeStampではなく%PosixTimeを使用する
更新: 2020年11月20日 使用方法を、SQL文の修正が不要な方法に変更しました
> IRISバージョン2022.1以降、SQLのTimeStamp型の既定値が%PosixTimeに変更されました。この変更によりテーブルを新規作成した際のTimeStamp型は%PosixTimeになります。
```
create table TEST (ts TIMESTAMP)
```
これを、下記のように変更してください。
```
create table TEST (ts POSIXTIME)
```
デフォルトではSQLのTIMESTAMP型は、IRIS内部では%TimeStamp型で保持されます。
%TimeStamp型は、データを文字列として保存するのに対して、%PosixTimeは64bitの整数で保持します。その分、ディスクやメモリ上のデータサイズや比較演算処理などで有利になります。両者はxDBC上は、共にTIMESTAMP型となり、互換性がありますので、DML文の修正は不要です(敢えて指摘するとすれば、ミリ秒以下の精度が異なります)。以下は、実行例です。%PosixTimeに対するクエリのほうが、程度の差こそあれ、高速になっています。
```
create table TEST (ts TIMESTAMP, pt POSIXTIME)
create index idxts on TABLE TEST (ts)
create index idxpt on TABLE TEST (pt)
insert into TEST ... 100万レコードほどINSERT
select count(*),DATEPART(year,pt) yyyy from TEST group by DATEPART(year,pt)
平均 669ミリ秒
select count(*),DATEPART(year,ts) yyyy from TEST group by DATEPART(year,ts)
平均 998ミリ秒
select count(*) from TEST where DATEPART(year,pt)='1990'
平均 533ミリ秒
select count(*) from TEST where DATEPART(year,ts)='1990'
平均 823ミリ秒
select count(*) from TEST where pt>='1980-01-01 00:00:00' and pt='1980-01-01 00:00:00' and ts IRISバージョン2022.1以降、既定値がPosixTimeに変更されましたので、構成ファイルの変更は不要です。
```
[SQL]
TimePrecision=0 (修正前)
TimePrecision=6 (修正後)
[SqlSysDatatypes]
TIMESTAMP=%Library.TimeStamp (修正前)
TIMESTAMP=%Library.PosixTime (修正後)
```
## バイナリデータの保存には可能であればVARBINARYを使用する。
バイナリデータを保存する場合、サイズの上限が指定できる場合はVARBINARYを使用してください。LONGVARBINARYはサイズ上限が無い代わりに、内部でストリーム形式で保存する機構を伴うためパフォーマンスが低下します。
```
CREATE TABLE TestTable (ts TIMESTAMP, binaryA VARBINARY(512), binaryB VARBINARY(256))
```
VARBINARY使用時には、行全体のサイズに注意が必要です。SQLの行は、IRIS内部では、既定では下記のフォーマットで、1つのノードのデータ部(IRISの内部形式の用語でKV形式のバリューに相当します)に格納されます。このノードの[サイズ上限]((https://docs.intersystems.com/irislatestj/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_types#GCOS_types_strings_long))は3,641,144バイトです。
長さ|データタイプ|データ|長さ|データタイプ|データ|...
この長さを超えると、\という内部エラーが発生し、INSERTが失敗します。
## Query ソース保存有効化
実行プランがコード化されたものがソースコードとして保存されます。デフォルトでは無効です。本稿では扱っていませんが、後の解析で有用になることもありますので、念のため有効化しておきます。
```
[SQL]
SaveMAC=1
記事
Tomohiro Iwamoto · 2020年6月8日
VMware vSphereで実行する大規模な本番データベースのCPUキャパシティプランニングについて、お客様やベンダー、または社内のチームから説明するように頼まれることが良くあります。
要約すると、大規模な本番データベースのCPUのサイジングには、いくつかの単純なベストプラクティスがあります。
物理CPUコア当たり1つのvCPUを計画する。
NUMAを考慮し、CPUとメモリをNUMAノードに対してローカルに維持できるようVMの理想的なサイズを決定する。
仮想マシンを適正化する。 vCPUは必要な場合にのみ追加する。
このことから、通常いくつかの一般的な疑問が生まれます。
ハイパースレッディングにより、VMwareでは物理CPUの2倍の数でVMを作成できます。 これはキャパシティが2倍になるということか? できるだけ多くのCPUを使ってVMを作成すべきではないのか?
NUMAノードとは? NUMAに配慮する必要があるのか?
VMを適正化する必要があるが、どうすれば適正化されたことがわかるのか?
こういった疑問につては、下の例を使って答えることにします。 ただし、ベストプラクティスは決定事項ではありません。 ときには妥協することも必要です。 たとえば、大規模なデータベースVMはNUMAノードに収まらない可能性が高く、それはそれでも良いのです。 ベストプラクティスは、アプリケーションと環境に合わせて評価・検証する必要のあるガイドラインです。
この記事は、InterSystemsデータプラットフォームで実行するデータベースを例として書いていますが、概念とルールは、一般的にあらゆる大規模(モンスター)VMのキャパシティとパフォーマンスプランニングにも適用されます。
仮想化のベストプラクティスとパフォーマンスとキャパシティ計画に関するその他の記事: 「InterSystemsデータプラットフォームとパフォーマンス」シリーズの「その他の記事」セクションを参照してください。
モンスターVM
この記事は主に、「ワイドVM」と呼ばれることもあるモンスターVMのデプロイについて書いています。 高トランザクションデータベースのCPUリソース要件は、こういったデータベースがモンスターVMにデプロイされることが多い事を意味します。
モンスターVMとは、単一の物理NUMAノードよりも多い仮想CPUまたはメモリを備えたVMです。
CPUアーキテクチャとNUMA
現行のIntelプロセッサアーキテクチャには、NUMA(Non-Uniform Memory Architecture)アーキテクチャがあります。 たとえば、この記事の検証用に使用しているサーバーは次の構成になっています。
CPUソケット2個。各ソケットに12コアのプロセッサを装着(Intel E5-2680 v3)。
256 GBメモリ(16 x 16 GB RDIMM)
各12コアプロセッサには、独自のローカルメモリ(128 GBのRDIMMとローカルキャッシュ)があり、同じホスト内のほかのプロセッサのメモリにもアクセスできます。 CPU、CPUキャッシュ、および128 GB RDIMMメモリを1つのパッケージとした12コアをそれぞれNUMAノードと呼びます。 別のプロセッサのメモリにアクセスするために、NUMAノードは高速インターコネクトで接続されます。
ローカルRDIMMとキャッシュメモリにアクセスするプロセッサで実行するプロセスは、別のプロセッサのリモートメモリにアクセスするためにインターコネクトを経由する場合に比べ、レイテンシが低くなります。 インターコネクト経由のアクセスではレイテンシが高くなるため、パフォーマンスが一定しません。 同じ設計は3つ以上のソケットを持つサーバーにも適用されます。 ソケットが4つあるIntelサーバーには、4つのNUMAノードがあります。
ESXiは物理NUMAを認識し、ESXi CPUスケジューラはNUMAシステムのパフォーマンスを最適化するように設計されています。 ESXiがパフォーマンスを最大化する方法の1つは、物理NUMAノードにデータの局所性を作成することです。 この記事の例では、vCPUが12でメモリが128 GB未満のVMがある場合、ESXiはそのVMを物理NUMAノードの1つで実行するように割り当てます。 このことから次のルールについて言うことができます。
可能であれば、CPUとメモリをNUMAノードに対してローカルに維持できるようにVMのサイズを決定する。
NUMAノードより大きなモンスターVMが必要な場合は、それでもかまいません。ESXiは非常に優れた機能によって、要件を自動的に計算して管理することができます。 たとえば、ESXiは、最適なパフォーマンスを得るために、物理NUMAノードにインテリジェントにスケジュールする仮想NUMAノード(vNUMA)を作成します。 vNUMA構造は、オペレーティングシステムに公開されます。 たとえば、2つの12コアプロセッサを搭載したホストサーバーと16 vCPUを備えたVMがある場合、ESXiは8つの物理コアを2つのプロセッサに使用して、VM vCPUをスケジュールするため、オペレーティングシステム(LinuxまたはWindows)に2つのNUMAノードが表示されます。
また、VMを適正化して、必要以上のリソースを割り当てないようにすることも重要です。リソースが無駄になり、パフォーマンスが低下する可能性があります。 VMを適正化すればNUMAのサイズ設定にも役立つだけでなく、特に低から中程度のCPU使用率のある24 vCPUのVMよりもCPU使用率の高い(ただし安全な)12 vCPUのVMの方が、より効率的でパフォーマンスの改善が得られます。特にこのホストに、スケジュールされる必要がありリソースを争っているほかのVMがある場合はなおさらです。 このこともルールをさらに強化する要因といえます。
仮想マシンを適正化する。
注意: NUMAのIntel実装とAMD実装には違いがあります。 AMDには、プロセッサごとに複数のNUMAがあります。 顧客のサーバーでAMDプロセッサを見たのはしばらく前になりますが、それを使用している場合は、計画の一環としてNUMAのレイアウトを確認してください。
ワイドVMとライセンス
最適なNUMAスケジュール設定を得る、ワイドVMの構成は 2017年6月訂正: ソケットあたり1 vCPUでVMを構成します。 たとえば、24 vCPUのVMは、デフォルトでそれぞれが1つのコアを持つ24 CPUソケットとして構成されます。
VMwareのベストプラクティスのルールに従ってください。
例については、VMwareブログに記載のこちらの記事を参照してください。
VMwareのブログ記事には詳細が説明されていますが、これを執筆したMark Achtemichukは次の経験則を推奨しています。
高度なvNUMA設定はたくさんあるが、デフォルトの設定を変更しなければいけないのは、まれなケースのみ。
仮想マシンvCPU数は、単一の物理NUMAノードの物理コア数を超えるまでは、必ず、ソケットあたりのコア数が反映されるように構成すること。
NUMAノードにある物理コア数以上のvCPUを構成する必要がある場合は、最少数のNUMAノード間でvCPU数を均一に分割すること。
仮想マシンのサイズが単一の物理NUMAノードを超える場合、奇数のvCPU数を割り当てないこと。
vCPUホットアド(Hot-add)は、vNUMAを無効にしてもかまわない場合にのみ有効にすること。
ホストの物理コアの合計数以上に大きいVMを作成しないこと。
Cachéライセンスはコアを計数するため問題ではありませんが、Caché以外のソフトウェアやデータベースの場合は、VMに24ソケットを指定するとソフトウェアライセンスに違いが生じる場合があるため、ベンダーと確認する必要があります。
ハイパースレッディングとCPUスケジューラ
ハイパースレッディング(HT)の話が持ち上がるとよく聞くのが「ハイパースレッディングはCPUコア数を2倍にする」ということです。 これは明らかに物理的に可能なことではありません。コア数が物理的に増えたり減ったりすることはありえません。 ハイパースレッディングは有効にすべきものであり、有効になればシステムのパフォーマンスを向上させることができます。 期待値はおそらくアプリケーションパフォーマンスにおいて20%増かもしれませんが、実際の量はアプリケーションとワークロードによって決まります。 が、それでも2倍ではありません。
VMwareのベストプラクティスの記事で説明したように、大規模な本番データベースVMをサイジングするには、vCPUに完全専用の物理コアがサーバーにあると仮定することから始まります。基本的に、キャパシティ計画を実施する際はハイパースレッディングを無視するということです。 たとえば:
24コアのホストサーバーの場合、利用可能なヘッドルームがあることを考えて、本番データベースに合計で最大24 vCPUを計画します。
ピーク処理期間のアプリケーション、オペレーティングシステム、およびVMwareのパフォーマンスをしばらく監視したら、より高い統合が可能であるかどうかを判断することができます。 ベストプラクティスの記事では、ルールを次のように述べました。
1つの物理CPU(ハイパースレッディングを含む)= 1つのvCPU(ハイパースレッディングを含む)
ハイパースレッディングでCPUが2倍にならない理由
Intel Xeonプロセッサ上のHTは、1つの物理コア上に2つの論理CPUを作成する方法です。 オペレーティングシステムは、2つの論理プロセッサに対して効率的にスケジュールを設定できます。論理プロセッサ上のプロセスまたはスレッドがIOなどを待機している場合、物理CPUリソースは、別の論理プロセッサによって使用されます。 ある時点において進行できるのは1つの論理プロセッサのみであるため、物理コアがより効果的に使用されていても、パフォーマンスは2倍にならないのです。
ホストBIOSでHTが有効化されている場合、VMを作成する際に、HT論理プロセッサあたりのvCPUを構成することができます。 たとえば、HTが有効になっている24物理コアのサーバーで、最大48 vCPUのVMを作成することができます。 ESXi CPUスケジューラは、最初に個別の物理コアで(NUMAを考慮しながら)VMプロセスを実行することにより、処理を最適化します。 モンスターデータベースVMに物理コア数以上のvCPUを割り当てるとスケーリングにメリットがあるのかについては、この記事の後の方で説明することにします。
co-stopとCPUスケジューリング
ホストとアプリケーションのパフォーマンスを監視した後、ホストCPUリソースのオーバーコミットが可能であると判断する場合があります。 これがよいことかどうかは、アプリケーションとワークロードに大きく依存します。 スケジューラと監視すべき重要なメトリックを理解することで、ホストリソースをオーバーコミットしていないことを確認できます。
たまに、VMが進行するには、VMのvCPUと同じ数の空き論理CPUが必要だということを聞くことがあります。 たとえば、12 vCPUのVMは、実行が進む前に12個の論理CPUが「利用可能」になるまで「待機」する必要があります。 ただし、バージョン3以降のESXiではそうでないことに注意してください。 ESXiは、アプリケーションのパフォーマンスを向上させるために効率的なスケジューリングを使用しています。
複数の協調動作するスレッドまたはプロセスは頻繁に同期するため、一緒にスケジューリングしない場合、操作のレイテンシが増加する可能性があります。 たとえば、スピンループ内で別のスレッドがスケジュールされるのを待機しているスレッドです。 最良のパフォーマンスを得るために、ESXiはできる限り多くの兄弟vCPUを一緒にスケジュールしようとします。 ただし、CPUスケジューラは、統合環境で複数のVMがCPUリソースを争う場合に、vCPUを柔軟にスケジュールすることができます。 兄弟vCPUが進行しないにも関わらず一部のvCPUが進行してしまうと大きな時間差(これをスキューと呼ぶ)が生まれてしまうため、この場合は先行のvCPUがそれ自体を停止するかどうかを決定します(co-stop)。 co-stop(またはco-start)するのは、VM全体ではなくvCPUであることに注意してください。 これは、リソースのオーバーコミットがある場合でもうまく機能しますが、CPUのオーバーコミットが多すぎると必然的にパフォーマンスに影響します。 後の例2で、オーバーコミットとco-stopの例を示します。
これは、VM間のCPUリソースの争奪戦ではありません。ESXiのCPUスケジューラの仕事は、CPUのシェア数、予約、限界といったポリシーを確実に守りながら、CPU使用率を最大化し、公平性、スループット、応答性、スケーラビリティを確保することにあります。 予約とシェアを使用して本番ワークロードに優先順を付ける話はこの記事の目的から外れてしまい、アプリケーションやワークロードの組み合わせによって異なります。 Caché固有の推奨事項がある場合は、これについて後で触れるかもしれません。 CPUスケジューラにはさまざまな要因がかかわっているため、このセクションではその表面をざっと紹介しています。 詳細については、この記事の最後に記載する参考情報にあるVMwareのホワイトペーパーやその他のリンクを参照してください。
例
さまざまなvCPU構成を説明するために、高トランザクションレートのブラウザベースの病院情報システムアプリケーションを使って、一連のベンチマークを実行しました。 VMwareが作成したDVDストアデータベースベンチマークの概念に似ています。
ベンチマークのスクリプトは、ライブの病院実装から得た観察とメトリックを基に作成されており、使用率の高いワークフロー、トランザクション、およびシステムリソースを最も使用するコンポーネントが含まれています。 ほかのホスト上のドライバーVMは、ランダム化された入力データを使用したスクリプトを設定されたワークフロートランザクションレートで実行することで、Webセッション(ユーザー)をシミュレートします。 レート 1x のベンチマークがベースラインです。 レートは段階的に増減できます。
データベースとオペレーティングシステムのメトリックに加え、ベンチマークデータベースVMのパフォーマンスを測定するのに適したメトリックは、サーバーで測定されるコンポーネント(またはトランザクション)の応答時間です。 コンポーネントとは、エンドユーザー画面の一部分などを指します。 コンポーネントの応答時間が増加すると、ユーザー側においてはアプリケーションの応答時間に悪影響がでます。 パフォーマンスの高いデータベースシステムは、一貫した高いパフォーマンスをエンドユーザーに提供できるものでなければなりません。 次のグラフでは、最も遅く使用頻度の高いコンポーネントの応答時間の平均を算出し、一貫したテストパフォーマンスとエンドユーザーエクスペリエンスの指標を測定しています。 平均的なコンポーネント応答時間は1秒未満であり、ユーザー画面は、1つのコンポーネント、または複雑な画面の場合は多くのコンポーネントで構成されています。
常にピーク時のワークロードと、アクティビティの予定外の急増に対応するためのバッファに対してサイジングを行っていることを覚えておきましょう。 私の場合は通常、平均80%のピークCPU使用率を目指しています。
ベンチマークのハードウェアとソフトウェアの全リストはこの記事の最後にあります。
例1. 適正化 - ホストあたり1つのモンスターVM
たとえば、24個の物理コアホスト上の24 vCPUのVMといったように、ホストサーバーのすべての物理コアを使用できるようにサイジングされたデータベースVMを作成することができます。 HAを得るためにCachéデータベースミラーで「ベアメタル」サーバーを実行したりオペレーティングシステムのフェイルオーバークラスタリングといった複雑なものを導入したりせずとも、データベースVMは、DRSやVMware HAなどの管理・HA向けvSphereクラスタに含まれます。
古い考え方で、5年後のハードウェア使用期間の最後に期待されるキャパシティに対してプライマリデータベースVMのサイズを決定するお客様を見てきましたが、上記で説明したように、適正化する方が有効と言えます。VMのサイズが過大に設定されていなければ、パフォーマンスと統合が改善され、HAの管理もより簡単になります。メンテナンスやホスト障害が発生した場合は、テトリスのように、データベースのモンスターVMを別のホストに移行して、そこで再起動しなければなりません。 トランザクションレートが大幅に増加すると予測される場合は、定期メンテナンス中に前もってvCPUを追加することができます。
「ホットアド」CPUオプションはvNUMAを無効にするため、モンスターVMには使用しないでください。
24コアホストでの一連の検証を示す次のグラフを考察してみましょう。 3x トランザクションレートは、この24コアシステムのスイートスポットであり、キャパシティプランニングの目標です。
ホストでは単一のVMが実行している。
12、24、36、48 vCPUでのパフォーマンスを示すために4つのVMサイズを使用している。
各VMサイズに対し、トランザクションレート(1x、2x、3x、4x、5x)が実行された(可能な場合)。
コンポーネント応答時間としてパフォーマンス/ユーザーエクスペリエンスを示している(棒グラフ表示)。
平均CPU%使用率はゲストVM(線グラフ表示)
すべてのVMサイズのホストCPU使用率は、4x レートで100%に達した(赤い破線)。
このグラフには多くのことが示されていますが、2つのことに注目できます。
24 vCPUのVM(オレンジ)は、目標の3x トランザクションレートにスムーズにスケールアップしています。 3x レートにおいては、ゲスト内のVMは平均76%CPUに達成しています(ピーク時は約91%)。 ホストCPUの使用率はゲストVMとあまり変わりません。 コンポーネント応答時間は3xまでほぼ一定しているため、ユーザーは満足しています。 目標のトランザクションレートに関して言えば、このVMは適正化されていると言えます。
適正化についてはわかりましたが、vCPUの増加についてはどうでしょうか。これは、ハイパースレッディングを使用するということです。 パフォーマンスとスケーラビリティを2倍にすることは可能でしょうか。 短く言えば、答えは「ノー!」です。
この場合、この答えは、4x 以降のコンポーネント応答時間を見るとわかります。 割り当てられる論理コア数(vCPU)が多いほどパフォーマンスは「向上」しますが、一定しておらず、3x までのような一貫性がありません。 割り当てられるvCPU数が増えても、ユーザーは4x での応答時間が遅くなっていることを報告するでしょう。 vSphereが示したように、4xでは、ホストはすでに100%CPU使用率で横ばいになっていたことを思い出しましょう。 vCPU数が高い場合、ゲスト内CPUメトリック(vmstat)が100%使用率未満を示していたとしても、これは物理リソースには当てはまりません。 ゲストオペレーティングシステムは仮想化されていることを認識しないため、それに与えられたリソースに対して示しているだけであることに注意してください。 また、ゲストオペレーティングシステムはHTスレッドも認識しないため、すべてのvCPUは物理コアとして示されます。
ポイントは、データベースプロセス(3x トランザクションレートのCachéプロセスは200個以上ある)は非常にビジーであり、プロセッサを非常に効率的に使用しますが、ほかの作業をスケジュールするかこのホストにほかのVMを統合するための論理プロセッサにはあまり余裕がないということです。 たとえば、Caché処理の大部分はメモリ内で行われるため、IOの待機時間はあまりありません。 そのため、物理コアより多いvCPUを割り当てることはできますが、ホストの使用率がすでに100%に達しているため、あまり得がないのです。
Cachéは高いワークロードの処理に非常に優れています。 ホストやVMが100%のCPU使用率に達していても、アプリケーションは実行し続けており、トランザクションレートも増加し続けます。スケーリングは線形ではなく、応答時間が長引けば、ユーザーエクスペリエンスに影響があります。ただし、アプリケーションが「崖から落ちる」わけではなく、快適な場所でないにしても、ユーザーは作業を続行できるでしょう。 応答時間の影響をそれほど受けないアプリケーションであれば、限界まで押したとしても、Cachéは安全に動作し続けます。
データベースVMやホストを100%CPUで実行するのは好ましいことではないことを覚えておいてください。 VMには予定外の急増や予測していなかった増加に対応できるキャパシティが必要であり、ESXiハイパーバイザーには、すべてのネットワーキング、ストレージなどでのアクティビティに使用するリソースが必要です。
私は常にピーク時のCPU使用率を80%で計画するようにしていますが、 それでも、vCPUのサイズを物理コア数までに設定するようにし、極端な状況でも論理スレッド上にESXiハイパーバイザー用のヘッドルームをいくらか残すようにしています。
ハイパーコンバージド(HCI)ソリューションを実行している場合は、HCIのCPU要件もホストレベルで考慮する必要があります。 詳細は、HCIに関する前の記事を参照してください。 HCIにデプロイされたVMの基本的なCPUサイジングは、ほかのVMと変わりません。
独自の環境とアプリケーションですべての設定を確認・検証する必要があることを忘れないでください。
例2. オーバーコミットされたリソース
アプリケーションパフォーマンスは「遅い」にもかかわらず、ゲストオペレーティングシステムではCPUリソースに余裕があることが示される顧客サイトを見たことがあります。
ゲストオペレーティングシステムは仮想化を認識しないことに注意してください。 残念ながらvmstat(pButtonsの場合)が示すゲスト内のメトリックは当てにならないことがあるため、システムの状態とキャパシティを正確に理解するには、ホストレベルのメトリックとESXiのメトリック(esxtopなど)も取得する必要があります。
上のグラフからもわかるように、ホストが100%使用率を示す場合、ゲストVMの使用率は低く示されることがあります。 36 vCPUのVM(赤)は4x レートで80%の平均CPU使用率を示していますが、ホストでは100%となっています。 公開後にほかのVMがホストに移行した場合や、きちんと構成されていないDRSルールによってリソースがオーバーコミットされている場合など、適正化されたVMでもリソース不足となることがあります。
主なメトリックを示すために、この一連の検証では以下のように構成しました。
ホストで実行する2つのデータベースVM
一定の2xトランザクションレートで実行する24vCPU(グラフには表示されていません)
1x、2x、3xレートで実行する24vCPU(グラフに3つのメトリックが表示されています)
リソースを使う別のデータベースでは、3x レートにおけるゲストOS(RHEL 7)のvmstatは86%の平均CPU使用率を示しており、実行キューは平均25です。 ただし、このシステムのユーザーは、プロセスが遅くなるにつれコンポーネント応答時間が急増するため、大きな不満を訴えると考えられます。
次のグラフが示すように、co-stopと準備時間からユーザーパフォーマンスがこれほど悪い理由を読み取ることができます。 準備時間(%Ready)とco-stop(%CoStop)メトリックは、CPUリソースが目標の3xレートで大幅にオーバーコミットされていることを示しています。 ホストの実行レートが2x(other VM)、かつこのデータベースVMは3xレートであるわけですから、特に驚くことでもないでしょう。
このグラフは、ホスト上の合計CPU負荷が増加すると準備時間が増加することを示しています。
準備時間とは、VMの実行準備は整っているが、CPUリソースが利用できないために実行できない時間です。
co-stopも増加します。 データベースVMを進行させられるのに十分な空き論理CPUがありません(上記のHTの項目で説明しました)。 その結果、物理CPUリソースの競合により処理が遅延しています。
pButtonsとvmstatのサポートビューに、仮想オペレーティングシステムのみが表示されるという状況を顧客サイトで見たことがあります。 vmstatはCPUヘッドルームを示していましたが、ユーザーのパフォーマンスエクスペリエンスはひどいものでした。
ここでの教訓は、ESXiメトリックとホストレベルビューが利用できるようになるまで実際の問題が診断されなかったということです。一般的なクラスタCPUリソース不足によってCPUリソースのオーバーコミットが発生し、状況を悪化すべく、粗末なDRSルールによって高トランザクションデータベースVMがまとめてホストリソースに移行され、ホストリソースを圧迫していたのです。
例3. オーバーコミットされたリソース
この例では、3xトランザクションレートで実行する24 vCPUデータベースVMをベースラインとし、一定した3xトランザクションレートで2つの24 vCPUデータベースVMを使用しました。
平均ベースラインCPU使用率(上の例1を参照)は、VMが76%でホストが85%でした。 1つの24 vCPUデータベースVMが24個のの物理プロセッサをすべて使用しています。 2つの24 vCPU VMを実行すると、VMはリソースを争い、サーバーで48個の論理実行スレッドすべてを使用することになります。
単一のVMではホストは100%使用されていませんでしたが、2つの非常にビジーな24 vCPU VMがホスト上の24個の物理コアを使用しようとすると(HTを使用してでさえも)、スループットとパフォーマンスが大幅に低下するのがわかります。 Cachéは利用可能なCPUリソースを非常に効率よく使用できますが、VMあたりのデータベーススループットは16%低下し、さらに重要なことに、コンポーネント(ユーザー)応答時間が50%以上増加しています。
最後に
この記事の目的は、一般的な疑問にお答えすることでした。 CPUホストリソースとVMware CPUスケジューラの詳細については、下の参考情報を参照してください。
システムの最後の一滴までパフォーマンスを絞り出す、特別に高度な調整やESXi設定がたくさんありますが、基本的なルールは非常にシンプルです。
大規模な本番データベースの場合:
物理CPUコアあたり1 vCPUで計画する。
NUMAを考慮し、CPUとメモリをNUMAノードに対してローカルに維持できるようVMの理想的なサイズを決定する。
仮想マシンを適正化する。 vCPUは必要な場合にのみ追加する。
VMを統合する場合は、大規模なデータベースは非常にビジーであり、ピーク時にCPU(物理と論理)を大量に使用することに注意してください。 監視で安全だということがわかるまで、オーバーサブスクライブしてはいけません。
参考情報
VMwareブログ「When to Overcommit vCPU:pCPU for Monster VMs」
Introduction 2016 NUMA Deep Dive Series
The CPU Scheduler in VMware vSphere 5.1
検証について
この記事で使用した例は、オールフラッシュアレイに接続された2つのDell R730プロセッサで構成されるvSphereクラスタで実行しました。 例では、ネットワークまたはストレージにボトルネックはありませんでした。
Caché 2016.2.1.803.0
PowerEdge R730
2x Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50 GHz
16x 16 GB RDIMM、2133 MT/秒、デュアルランク、x4 データ幅
SAS 12 Gbps HBA外部コントローラ
ハイパースレッディング(HT)有効
PowerVault MD3420、12G SAS、2U-24ドライブ
24x 24 960 GBソリッドステートドライブSAS読み取り処理集中型MLC 12 Gbps 2.5インチホットプラグドライブ、PX04SR
2 コントローラー、12G SAS、2U MD34xx、8Gキャッシュ
VMware ESXi 6.0.0ビルド2494585
VMはベストプラクティスに合わせて構成されています。VMXNET3、PVSCSIなど
RHEL 7
LargePages
ベースラインの1x レートの平均は700,000 glorefs/秒(データベースアクセス/秒)でした。 5x レートの平均は、24 vCPUで3,000,000 glorefs/秒超でした。 検証では、一貫したパフォーマンスが達成されるまで慣らし運転を行い、その後で15分間、サンプルを取得し平均を算出しました。
これらの例は理論を説明することだけを目的としているため、独自アプリケーションでは必ず検証する必要があります。
また、前の記事「InterSystemsデータプラットフォームとパフォーマンス - VMバックアップとCachéのFreeze/Thawスクリプト」もお読みください。
記事
Toshihiko Minamoto · 2021年8月31日
[最初の記事](https://jp.community.intersystems.com/node/501166)では、Caché Webアプリケーションのテストとデバッグを外部ツールを用いて行うことについて説明しました。 2回目となるこの記事では、Cachéツールの使用について説明します。
以下について説明します。
* CSP GatewayとWebappの構成
* CSP Gatewayのロギング
* CSP Gatewayのトレース
* ISCLOG
* カスタムロギング
* セッションイベント
* デバイスへの出力
### CSP GatewayとWebappの構成
まず初めに、フロントエンドアプリケーションをデバッグする場合、特にそれを開発している場合は、キャッシュは必要ありません。 本番システムでは役立ちますが、開発中には不要です。 Webアプリケーションのロギングを無効にするには、システム管理ポータル → メニュー → Webアプリケーションの管理 → <あなたのWebアプリ>に移動して、Serve Files Timeoutを0に設定します。 そして[保存]ボタンを押します。
次に、webアプリケーションの既存のキャッシュを消去する必要があります。 これを行うには、システム管理ポータル → システム管理 → 構成 → CSP Gatewayの管理 → システムステータスに移動します。 「Cached Forms」テーブルを探し、その最後の行にある「Total」の消去ボタン(ドット)を押してWebアプリケーションのキャッシュを消去します。
### CSP Gatewayのロギング
CSP Gatewayに関しては、受信リクエストのロギングがサポートされています(ドキュメント)。 [デフォルトのパラメーター]タブで、希望するログレベル(v9aなど)を指定して、変更を保存します。 v9aは、すべてのHTTPリクエストをGatewayホームディレクトリのhttp.logに記録します(ほかのオプションについてはドキュメントをご覧ください)。 リクエストは次のようにキャプチャされます。
GET /forms/form/info/Form.Test.Person HTTP/1.1
Host: localhost:57772
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0
Accept: application/json, text/plain, */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: http://localhost:57772/formsui/index.html
Cookie: CSPSESSIONID-SP-57772-UP-forms-=001000000000yxiocLLb8bbc9SVXQJC5WMU831n2sENf4OGeGa; CSPWSERVERID=144zwBTP
Dnt: 1
Connection: keep-alive
Cache-Control: max-age=0
また、パフォーマンスを記録するオプションもあります。 結果はファイルに出力されるか、[イベントログの表示]タブで閲覧することができます。
### CSP Gatewayのトレース
そして最後に、CSP Gatewayの[HTTPトレースの表示]タブでリクエストとレスポンスをトレースすることができます。 トレースを有効にすると、リクエストのキャプチャがすぐに開始します。 デバッグを終えたら、忘れずに無効にしてください。 デバッグセッションは次のように行われます。
注意: トレースのやり方がわかっている場合は、エラーを簡単に理解し、問題を再現することができます。 ロギングは統計収集、パフォーマンスプロファイリングなどに使用します。
また、ほとんどのWebサーバーにも、ロギングとパフォーマンス追跡ツールが備わっています。
### ISCLOG
CSP Gatewayは、ネットワークの問題の特定とパフォーマンスの追跡には役立ちますが、Caché内で起きていることをログするにほかのツールが必要となります。 そのようなツールの中でも汎用性に優れているのがISCLOGです。 [ドキュメント](http://docs.intersystems.com/latestj/csp/docbook/DocBook.UI.Page.cls?KEY=GCSP_logging)をご覧ください。
これは、現在のリクエスト処理に関する情報を保存できるグローバル変数です。 ロギングを開始するには、以下を実行します。
set ^%ISCLOG = 2
ロギングを終了するには、以下を実行します。
set ^%ISCLOG = 0
リクエストは次のようにロギングされます。
^%ISCLOG=0
^%ISCLOG("Data")=24
^%ISCLOG("Data",1)=$lb(2,"CSPServer","Header from CSP Size:3744 CMD:h IdSource:3","4664","FORMS","2017-06-07 10:49:21.341","%SYS.cspServer2","","")
^%ISCLOG("Data",1,0)="^h30000 "_$c(14,0,0)_"A"
^%ISCLOG("Data",2)=$lb(2,"CSPServer","[UpdateURL] Looking up: //localhost/forms/form/info path found: //localhost/forms/ Appl= "_$c(2,1,3,4)_"@"_$c(3,4,1,2,1,9,1)_"/forms/"_$c(2,1,3,4,1,2,1,2,1,2,4,3,4,1,2,1,9,1,7,1)_":%All"_$c(8,1)_"/forms"_$c(7,1)_"FORMS"_$c(2,1,2,1,3,4,1,2,1,2,1,3,4,1,2,1,4,4,132,3,3,4,2,3,4,2,2,1,4,4,16,14,2,4,3,4,1,3,4,1,2,1,3,4,1,2,1,16,1)_"Form.REST.Main"_$c(2,4,2,4),"4664","FORMS","2017-06-07 10:49:21.342","%CSP.Request.1","124","L3DfNILTaE")
^%ISCLOG("Data",3)=$lb(2,"CSPServer","[UpdateURL] Found cls: Form.REST.Main nocharsetconvert: charset:UTF-8 convert charset:UTF8","4664","FORMS","2017-06-07 10:49:21.342","%CSP.Request.1","124","L3DfNILTaE")
^%ISCLOG("Data",4)=$lb(2,"CSPServer","[HTML] Determined request type","4664","FORMS","2017-06-07 10:49:21.342","%SYS.cspServer2","124","L3DfNILTaE")
^%ISCLOG("Data",4,0)=$lb("usesession",1,"i%Class","Form.REST.Main","i%Service","REST","NOLOCKITEM","","i%GatewayError","")
^%ISCLOG("Data",5)=$lb(2,"CSPSession","[%LoadData] Loading CSP session, nosave=0","4664","FORMS","2017-06-07 10:49:21.342","%CSP.Session.1","","L3DfNILTaE")
^%ISCLOG("Data",5,0)=$lb(900,,0,5567742244,$c(149)_"Ù"_$c(3)_"ó»à"_$c(127)_",½"_$c(149,10)_"\"_$c(18)_"v"_$c(128,135)_"3Vô"_$c(11)_"*"_$c(154)_"PÏG¥"_$c(140,157,145,10,131)_"*",2,"FORMS","001000000000L3DfNILTaE1cDBJNjyQdyLwKq4wCXP82ld8gic",,0,"ru","L3DfNILTaE",2,1,"/forms/",$lb("UnknownUser","%All,%Developer","%All,%Developer",64,-559038737),"","","","2017-06-07 10:48:51","2017-06-07 10:49:04","Basic ZGV2OjEyMw==","Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0","","",0,"/forms/","","","",4,"","","","","http://localhost:57772/formsui/index.html")
^%ISCLOG("Data",6)=$lb(2,"CSPServer","[CSPDispatch]Requested GET /forms/form/info","4664","FORMS","2017-06-07 10:49:21.342","%SYS.cspServer","124","L3DfNILTaE")
^%ISCLOG("Data",7)=$lb(2,"CSPServer","[CSPDispatch] ** Start processing request newSes=0","4664","FORMS","2017-06-07 10:49:21.342","%SYS.cspServer","124","L3DfNILTaE")
^%ISCLOG("Data",7,0)="/forms/form/info"
^%ISCLOG("Data",8)=$lb(2,"CSPServer","[CSPDispatch] Service type is REST has-soapaction=0 nosave=0","4664","FORMS","2017-06-07 10:49:21.342","%SYS.cspServer","124","L3DfNILTaE")
^%ISCLOG("Data",9)=$lb(2,"CSPServer","[CSPDispatch]About to run page: Form.REST.Main","4664","FORMS","2017-06-07 10:49:21.342","%SYS.cspServer","124","L3DfNILTaE")
^%ISCLOG("Data",9,0)=$lb("UnknownUser","%All,%Developer","%All,%Developer",64,-559038737)
^%ISCLOG("Data",10)=$lb(2,"CSPServer","[callPage] url=/forms/form/info ; Appl: /forms/ newsession=0","4664","FORMS","2017-06-07 10:49:21.342","%SYS.cspServer","124","L3DfNILTaE")
^%ISCLOG("Data",11)=$lb(2,"CSPServer","[callPage]Imported security context ; User: UnknownUser ; Roles: %All,%Developer","4664","FORMS","2017-06-07 10:49:21.342","%SYS.cspServer","124","L3DfNILTaE")
^%ISCLOG("Data",12)=$lb(2,"CSPServer","[OutputCSPGatewayData]: chd=1;","4664","FORMS","2017-06-07 10:49:21.431","%CSP.Response.1","","L3DfNILTaE")
^%ISCLOG("Data",13)=$lb(2,"CSPResponse","[WriteHTTPHeaderCookies] Session cookie: CSPSESSIONID-SP-57772-UP-forms-=001000000000L3DfNILTaE1cDBJNjyQdyLwKq4wCXP82ld8gic; path=/forms/; httpOnly;","4664","FORMS","2017-06-07 10:49:21.431","%CSP.Response.1","124","L3DfNILTaE")
^%ISCLOG("Data",14)=$lb(2,"CSPServer","[callPage] Return Status","4664","FORMS","2017-06-07 10:49:21.431","%SYS.cspServer","124","L3DfNILTaE")
^%ISCLOG("Data",14,0)=1
^%ISCLOG("Data",15)=$lb(2,"CSPServer","[OutputCSPGatewayData]: chd=1;","4664","FORMS","2017-06-07 10:49:21.431","%CSP.Response.1","","L3DfNILTaE")
^%ISCLOG("Data",16)=$lb(2,"CSPServer","[Cleanup]Page EndSession=0; needToGetALicense=-1; nosave=0; loginredirect=0; sessionContext=1","4664","FORMS","2017-06-07 10:49:21.431","%SYS.cspServer","124","L3DfNILTaE")
^%ISCLOG("Data",17)=$lb(2,"CSPSession","[Cleanup] EndSession=0 nosave=0","4664","FORMS","2017-06-07 10:49:21.431","%SYS.cspServer","124","L3DfNILTaE")
^%ISCLOG("Data",18)=$lb(2,"CSPSession","[%SaveData] Saved: ","4664","FORMS","2017-06-07 10:49:21.431","%CSP.Session.1","","L3DfNILTaE")
^%ISCLOG("Data",18,0)=$lb(900,,0,5567742261,$c(149)_"Ù"_$c(3)_"ó»à"_$c(127)_",½"_$c(149,10)_"\"_$c(18)_"v"_$c(128,135)_"3Vô"_$c(11)_"*"_$c(154)_"PÏG¥"_$c(140,157,145,10,131)_"*",2,"FORMS","001000000000L3DfNILTaE1cDBJNjyQdyLwKq4wCXP82ld8gic",,0,"ru","L3DfNILTaE",2,1,"/forms/",$lb("UnknownUser","%All,%Developer","%All,%Developer",64,-559038737),"","","","2017-06-07 10:48:51","2017-06-07 10:49:21","Basic ZGV2OjEyMw==","Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0","","",0,"/forms/","","","",5,"","","","","http://localhost:57772/formsui/index.html")
^%ISCLOG("Data",19)=$lb(2,"CSPServer","[Cleanup] Restoring roles before running destructor","4664","FORMS","2017-06-07 10:49:21.431","%SYS.cspServer","","L3DfNILTaE")
^%ISCLOG("Data",19,0)=$lb("UnknownUser","%All,%Developer","%All,%Developer",64,-559038737)
^%ISCLOG("Data",20)=$lb(2,"CSPServer","[Cleanup] End","4664","FORMS","2017-06-07 10:49:21.431","%SYS.cspServer","","L3DfNILTaE")
^%ISCLOG("Data",20,0)=""
^%ISCLOG("Data",21)=$lb(2,"GatewayRequest","[CSPGWClientRequest] GWID: ed-pc:57772; Request: sys_get_system_metricsTimeout: 5","11112","%SYS","2017-06-07 10:49:23.141","%SYS.cspServer3","","")
^%ISCLOG("Data",22)=$lb(2,"GatewayRequest","[CSPGWClientRequest] GWID: 127.0.0.1:57772; Request: sys_get_system_metricsTimeout: 5","11112","%SYS","2017-06-07 10:49:23.141","%SYS.cspServer3","","")
^%ISCLOG("Data",23)=$lb(2,"GatewayRequest","[SendSimpleCmd:Server:Failed] WebServer: 127.0.0.1:57772; Gateway Server Request Failed","11112","%SYS","2017-06-07 10:49:23.141","%CSP.Mgr.GatewayMgrImpl.1","","")
^%ISCLOG("Data",23,0)=0
^%ISCLOG("Data",24)=$lb(2,"GatewayRequest","[GetMetrics]","11112","%SYS","2017-06-07 10:49:23.141","%CSP.Mgr.GatewayMgrImpl.1","","")
^%ISCLOG("Data",24,0)=""
また、以下のような簡単なスクリプトを使用して、グローバルをファイルに出力することができます。
set p="c:\temp\isclog.txt"
open p:"NW"
use p zw ^%ISCLOG
close p
### カスタムロギング
デフォルトのロギングツールも非常に優れていますが、いくつかの問題があります。
* 内容が一般的であり、アプリケーションが認識されない
* より詳細なオプションを使うと、パフォーマンスに影響する
* 構造化されていないため、情報の抽出が困難な場合がある
そのため、より具体的なケースを網羅するために、独自のカスタムロギングシステムを作成することができます。 以下は、%requestオブジェクトの一部を記録する永続クラスのサンプルです。
/// Incoming request
Class Log.Request Extends %Persistent
{
/// A string indicating HTTP method used for this request.
Property method As %String;
/// A string containing the URL up to and including the page name
/// and extension, but not including the query string.
Property url As %String(MAXLEN = "");
/// A string indicating the type of browser from which the request
/// originated, as determined from the HTTP_USER_AGENT header.
Property userAgent As %String(MAXLEN = "");
/// A string indicating the MIME Content-Type of the request.
Property contentType As %String(MAXLEN = "");
/// Character set this request was send in, if not specified in the HTTP headers
/// it defaults to the character set of the page it is being submitted to.
Property charSet As %String(MAXLEN = "");
/// A %CSP.Stream containing the content submitted
/// with this request.
Property content As %Stream.GlobalBinary;
/// True if the communication between the browser and the web server was using
/// the secure https protocol. False for a normal http connection.
Property secure As %Boolean;
Property cgiEnvs As array Of %String(MAXLEN = "", SQLPROJECTION = "table/column");
Property data As array Of %String(MAXLEN = "", SQLPROJECTION = "table/column");
ClassMethod add() As %Status
{
set request = ..%New()
quit request.%Save()
}
Method %OnNew() As %Status [ Private, ServerOnly = 1 ]
{
#dim %request As %CSP.Request
#dim sc As %Status = $$$OK
quit:'$isObject($g(%request)) $$$ERROR($$$GeneralError, "Not a web context")
set ..charSet = %request.CharSet
if $isObject(%request.Content) {
do ..content.CopyFromAndSave(%request.Content)
} else {
set ..content = ""
}
set ..contentType = %request.ContentType
set ..method = %request.Method
set ..secure = %request.Secure
set ..url = %request.URL
set ..userAgent = %request.UserAgent
set cgi = ""
for {
set cgi=$order(%request.CgiEnvs(cgi))
quit:cgi=""
do ..cgiEnvs.SetAt(%request.CgiEnvs(cgi), cgi)
}
// Only gets first data if more than one data with the same name is present
set data = ""
for {
set data=$order(%request.Data(data))
quit:data=""
do ..data.SetAt(%request.Get(data), data)
}
quit sc
}
}
Log.Request テーブルに新しいレコードを追加するには、コードに次の呼び出しを追加します。
do ##class(Log.Request).add()
これは非常に基本的なサンプルであり、必要に応じてコメント、変数、またはほかの様々なものを記録するように拡張することができ、そうすることが推奨されます。 このアプローチの主なメリットは、記録されたデータに対してSQLクエリを実行できることにあります。 独自のロギングシステムの構築に関する詳細は、[こちらの記事](https://community.intersystems.com/post/logging-using-macros-intersystems-cach%C3%A9)をご覧ください。
### セッションイベント
イベントクラスは、[%CSP.Session](http://docs.intersystems.com/latestj/csp/documatic/%25CSP.Documatic.cls?PAGE=CLASS&LIBRARY=%25SYS&CLASSNAME=%25CSP.Session)オブジェクトの寿命中に呼び出されるインターフェースを定義するクラスです。 これを使用するには、 [%CSP.SessionEvents](http://docs.intersystems.com/latestj/csp/documatic/%25CSP.Documatic.cls?PAGE=CLASS&LIBRARY=%25SYS&CLASSNAME=%25CSP.SessionEvents)をサブクラス化して、実行するメソッドコードを実装する必要があります。 次に、CSPアプリケーション構成内で、イベントクラスを作成したクラスに設定します。
次のコールバックを利用できます。
OnApplicationChange
OnEndRequest
OnEndSession
OnLogin
OnLogout
OnStartRequest
OnStartSession
* OnTimeout
たとえば上記のカスタムロギングは、これらのメソッドから呼び出すことができます。
### デバイスへの出力
最も単純なオプションの1つは、すべてのオブジェクトをレスポンスとして出力するCSPユーティリティメソッドです。 これをコードの任意の場所に追加するだけで出力できます。
set %response.ContentType = "html"
do ##class(%CSP.Utils).DisplayAllObjects()
return $$$OK
### まとめ
Webアプリケーションのデバッグにはさまざまなツールを使用することができます。 手元のタスクに最適なものを選択するようにしてください。
皆さんは、CachéからWebアプリケーションをデバッグする際には、どのようなヒントやトリックを使用していますか?
記事
Toshihiko Minamoto · 2020年12月16日
今回は、InterSystems IRIS に特有のことではなく、職場で Windows 10 Pro または Enterprise を搭載した PC またはノートパソコンがサーバーとして使用されている環境で Docker を使用する場合に重要と思われる点について触れたいと思います。
ご存知かと思いますが、コンテナテクノロジーは基本的に Linux の世界で生まれ、最近では Linux のホストで使用されており、その最大のポテンシャルを伺わせています。 Windows を普段から使用するユーザーの間では、Microsoft と Docker 両社によるここ数年の重大な試みにより、Windows のシステムで Linux イメージを基にコンテナを実行することがとても簡単になったと理解されています。しかし、生産システムでの使用がサポートされておらず、それが大きな問題となっています。特に、Windows と Linux のファイルシステムに大きな違いがあるため、安心してホストシステム内でコンテナの外に持続データを保管するということができないのです。 ついには、コンテナを実行するために、_Docker for Windows _自体で Linux の小さな仮想マシン (_MobiLinux_) が使用されるようになり、Windows ユーザーに対しては透過的に実行されます。また、先ほど述べたように、データベースの存続がコンテナよりも短くて構わないのであれば、パーフェクトに動作します。
では、何が言いたいかというと、問題を回避して処理を単純化するには、完全な Linux システムが必要になるが、Windows ベースのサーバーを使用していると、仮想マシンを使用する以外に方法がない場合が多い、ということです。 少なくとも、Windows の WSL2 がリリースされるまでの話ですが、それはまた別の機会に触れたいと思います。もちろん、十分堅牢に動作するまでは時間がかかるでしょう。
この記事では、必要に応じて、Windows サーバーの Ubuntu システムで Docker コンテナを使用できる環境をインストールする方法について分かりやすく説明します。 それでは、始めましょう。
1. Hyper-V を有効にする
まだ有効にしていない方は、`Windows Features`を追加し、Hyper-V を有効にしてください。 そして再起動します (現在の私のロケールにより、テキストはスペイン語になっています。 ドン・キホーテの言語をご存知ない方は手順を参照しながら「解明」できることを願っています 😉 )
.png)
2. Hyper-V 上で Ubuntu の仮想マシンを作成する
これ以上簡単に仮想マシン (VM) を作成する方法はないと思います。 `Hyper-V Manager` のウィンドウを開き、 Quick Create... オプション (画面一番上近く) を選択します。そして、画面に表示されている Ubuntu バージョンのいずれかを使って仮想マシンを作成します (どの Linux の場合でも、_iso _file をダウンロードすれば、別のディストリビューションの VM を作成できます)。 私は、使用可能な Ubuntu の最新リリース 19.10 を選択しました。 ここで表示されるものはすべて 18.04 に対応しています。 イメージのダウンロードにかかる時間によりますが、15~20 分ほどで新しい VM が作成され、使用を開始できます。
重要: Default Switch オプションはそのままにしておいてください。. ホストと仮想マシンの両方からインターネットにアクセスできることが保証されます。
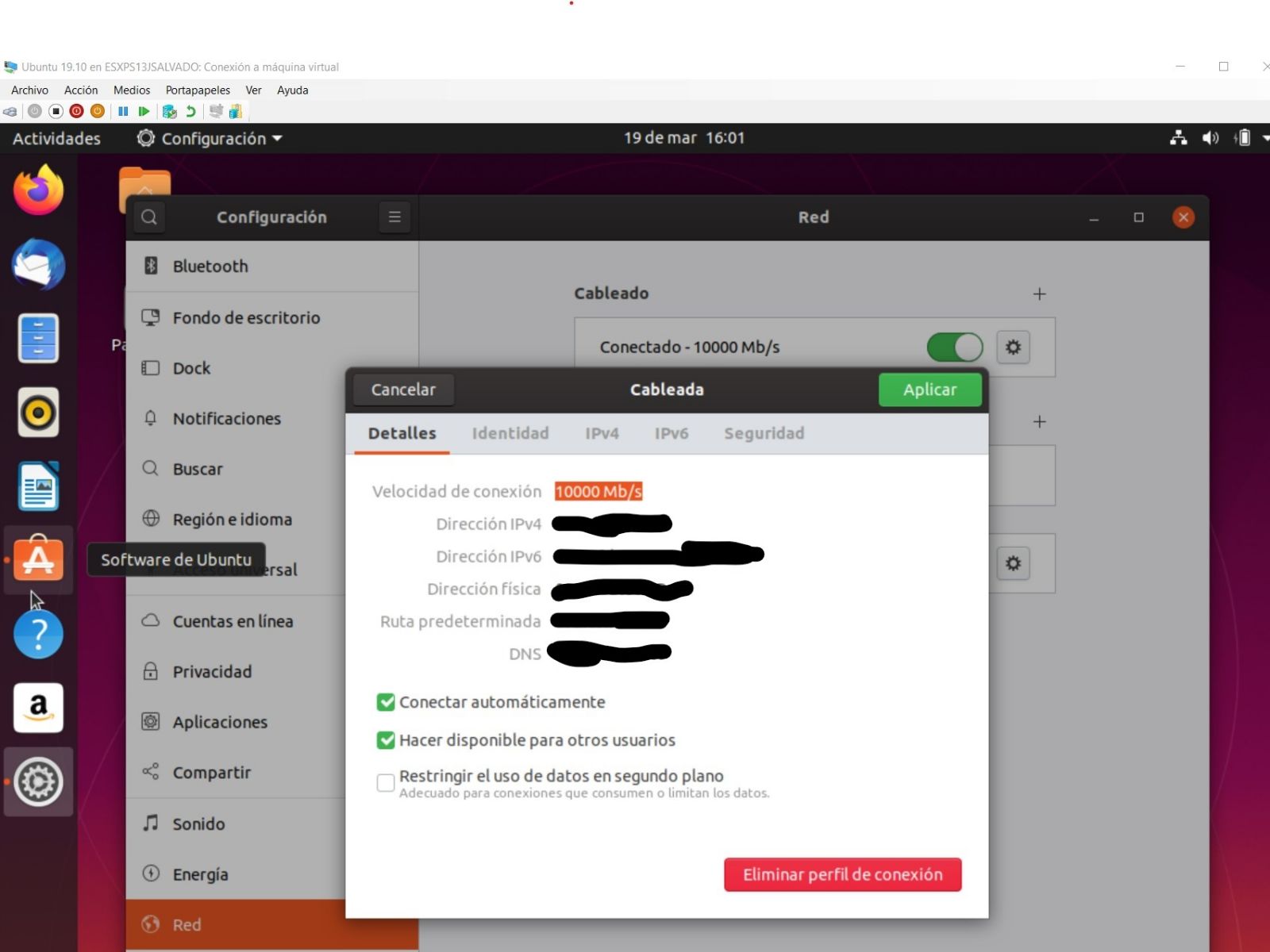
3. ローカルサブネットを作成する
仮想マシンを使用するときによく目にする問題の 1 つに、ネットワーク設定に関連して起こるものがあります。動作が不安定であったり、WiFi に接続しているときは動作してもケーブルだと駄目な場合があったり、もしくはその逆の場合もあります。また、Windows ホストで VPN を確立すると、VM のインターネットアクセスを失ったり、VM (Linux) とホスト (Windows) 間のコミュニケーションが遮断されたりすることもあり、はっきり言って大変なんです! ノートパソコンで開発作業を行ったり、簡単なデモやプレゼン資料を作成したりするとき、つまりインターネットにアクセスできることよりも、自分のホストと VM が確実に通信できることの方が重要であるときに、自分の作業環境を信頼できなくなってしまいます。
アドホックのローカルサブネットを Windows ホストと仮想マシン間で共有すれば、それを解決できます。 相互に通信し合えるようにするには、そのサブネットを使用します。 ホストと VM に特定の IP を割り当てれば準備完了です。
その方法はいたって簡単。 まずは、`Hyper-V Manager` にある Virtual Switch Manager... に移動します。
.png)
そこで、_New Virtual Switch __ _オプションを選択します (VM の新しいネットワークカードとして機能します)。
.png)
_内部ネットワーク _ として定義し、好きな名前を選び、他のオプションはデフォルトのままにしておきます。
.png)
_`Windows Control Panel --> Network and Sharing Center`_ と移動すれば、作成したばかりのスイッチが既に表示されています。
.png)
4. ホストと仮想マシン間で共有されるローカルサブネットを設定する
この時点で、新しいローカルネットワークの設定を完了します。 そのためには、_Mi Nuevo Conmutador LOCAL_ にカーソルを合わせて、Properties をクリックし、それから IPv4 protocol へと移動して固定 IP アドレスを割り当てます。
.png)
重要: ここで割り当てる IP は、このローカルサブネットのホスト (Windows) IP となります。
5. 新しいローカルネットワークを設定し、仮想マシンにリンクする
ここで、 `Hyper-V Manager` に戻ります。 VM が実行中であれば、停止してください。 停止したら、その設定に移動し、新しい内部仮想スイッチを追加します。
.png)
_(注意: 画像には他のスイッチ Hyper-V Conmutador INTERNO が表示されています。 これは私のもう 1 つのサブネット用のもので、 この設定には必要ありません) _
「Add」をクリックしたら、 前回作成したスイッチを選択します。
.png)
これが済んだら、「Apply」、「Accept」と順にクリックして準備完了です! 仮想マシンを起動し、もう一度ログインしてから内部接続の設定を完了します。 そうするには、VM が起動した後に画面右上のネットワークアイコンをクリックします。すると 2 つのネットワーク _eth0_ y _eth1_ が表示されます。 _eth1_ は、この時点では切断された状態で表示されます。
.png)
Ethernet (eht1) の設定に移動し、このローカルサブネットに固定 IP を割り当てます (例: IP _155.100.101.1_、サブネットマスク _ 255.255.255.0_)。
.png)
これで完了です。 これで仮想マシンが出来上がり、ホストと同じサブネットを共有する IP 155.100.101.1 として識別されます。
7. 仮想マシンから Windows 10 へのアクセスを許可する
大抵の場合、Windows 10 のデフォルト設定では、他のサーバーからのアクセスが許可されていません。Windows システムについては、たった今作成した VM がまさにそのサーバー (外部の潜在的に危険なサーバー) に該当します。このため、こういった仮想マシンからホストに接続するには、ファイアウォールにルールを追加する必要があります。 どうするのかって? いたって簡単です。`Windows Control Panel` の中から `Windows Defender Firewall` を見つけて、Advance Configuration に移動し、新規の *Entry Rule* を作成します。
.png)
1 つのポートまたは 1 つ以上の範囲を設定できます... (すべてのポートに対しルールを設定することもできます)...
.png)
ここで役に立つのが _Allow Connection_ です。
.png)
_ネットワークのすべてのタイプ_オプションを選択し...
.png)
ルールに名前を付けます。
.png)
ここで**重要**なことがあります。上記の手順が終わったら、新しく作成したルールのプロパティをもう一度開き、ルールをローカルサブネット内の接続に対してのみ適用できるよう*適用範囲を制限*しておきます。
.png)
8. 準備。 Docker と他に使用するアプリケーションを新しい Ubuntu 仮想マシンにインストールする
インストールプロセスを完了し、新しい VM を最新の状態に整え、インターネットアクセスなども準備ができたら、 好きなアプリをインストールできます。 少なくとも、元々の目的である Docker、また会社のネットワークへの接続に必要であれば VPN クライアント、さらには VS Code、Eclipse+Atelier などのアプリもインストールできます。
具体的に、VM 内で Docker をインストールする場合は、こちらの手順に従ってください: 。
Docker ランタイムの動作確認、テストイメージのダウンロードなどが済んだら、準備完了です。
_**¡You're all set!**_ が表示されたら、Ubuntu 仮想マシンでコンテナを (ハードウェアのキャパシティ内で) 制限なしに動作させることができます。同仮想マシンには、Windows 10 ホストやブラウザー、アプリなどから接続したり、またはその逆、Ubuntu VM から Windows 10 ホストに接続したりもできます。 このすべてに共有ローカルサブネット内で設定した IP アドレスが使用されるため、VPN を確立するしないに関わらず、またインターネットへのアクセスに Wi-Fi アダプターを使用するのか、イーサネットケーブルを使用するのかに関わらず、接続に失敗することはありません。
それから、アドバイスがもう 1 つだけあります。 Windows 10 と仮想マシンの間でファイルを交換する場合は、[WinSCP](https://winscp.net/eng/download.php) を使用すると簡単で便利です。 無料ですし、とても良く機能します。
もちろん、使える設定は他にもありますが、私は一番確実な方法としてこれを使っています。 お役に立つことを期待しています。 皆さんの悩みの種を取り除くことができれば、この記事を書いた価値があったと言えるでしょう。
¡ハッピーコーディング!
Windows10 ホストで実行される Hyper-V Ubuntu 仮想マシンで Docker を使用できるように環境を設定する
今回は、InterSystems IRIS に特有のことではなく、職場で Windows 10 Pro または Enterprise を搭載した PC またはノートパソコンがサーバーとして使用されている環境で Docker を使用する場合に重要と思われる点について触れたいと思います。
ご存知かと思いますが、コンテナテクノロジーは基本的に Linux の世界で生まれ、最近では Linux のホストで使用されており、その最大のポテンシャルを伺わせています。 Windows を普段から使用するユーザーの間では、Microsoft と Docker 両社によるここ数年の重大な試みにより、Windows のシステムで Linux イメージを基にコンテナを実行することがとても簡単になったと理解されています。しかし、生産システムでの使用がサポートされておらず、それが大きな問題となっています。特に、Windows と Linux のファイルシステムに大きな違いがあるため、安心してホストシステム内でコンテナの外に持続データを保管するということができないのです。 ついには、コンテナを実行するために、_Docker for Windows _自体で Linux の小さな仮想マシン (_MobiLinux_) が使用されるようになり、Windows ユーザーに対しては透過的に実行されます。また、先ほど述べたように、データベースの存続がコンテナよりも短くて構わないのであれば、パーフェクトに動作します。
では、何が言いたいかというと、問題を回避して処理を単純化するには、完全な Linux システムが必要になるが、Windows ベースのサーバーを使用していると、仮想マシンを使用する以外に方法がない場合が多い、ということです。 少なくとも、Windows の WSL2 がリリースされるまでの話ですが、それはまた別の機会に触れたいと思います。もちろん、十分堅牢に動作するまでは時間がかかるでしょう。
この記事では、必要に応じて、Windows サーバーの Ubuntu システムで Docker コンテナを使用できる環境をインストールする方法について分かりやすく説明します。 それでは、始めましょう。
1. Hyper-V を有効にする
まだ有効にしていない方は、`Windows Features`を追加し、Hyper-V を有効にしてください。 そして再起動します (現在の私のロケールにより、テキストはスペイン語になっています。 ドン・キホーテの言語をご存知ない方は手順を参照しながら「解明」できることを願っています 😉 )
.png)
2. Hyper-V 上で Ubuntu の仮想マシンを作成する
これ以上簡単に仮想マシン (VM) を作成する方法はないと思います。 `Hyper-V Manager` のウィンドウを開き、 Quick Create... オプション (画面一番上近く) を選択します。そして、画面に表示されている Ubuntu バージョンのいずれかを使って仮想マシンを作成します (どの Linux の場合でも、_iso _file をダウンロードすれば、別のディストリビューションの VM を作成できます)。 私は、使用可能な Ubuntu の最新リリース 19.10 を選択しました。 ここで表示されるものはすべて 18.04 に対応しています。 イメージのダウンロードにかかる時間によりますが、15~20 分ほどで新しい VM が作成され、使用を開始できます。
重要: Default Switch オプションはそのままにしておいてください。. ホストと仮想マシンの両方からインターネットにアクセスできることが保証されます。

3. ローカルサブネットを作成する
仮想マシンを使用するときによく目にする問題の 1 つに、ネットワーク設定に関連して起こるものがあります。動作が不安定であったり、WiFi に接続しているときは動作してもケーブルだと駄目な場合があったり、もしくはその逆の場合もあります。また、Windows ホストで VPN を確立すると、VM のインターネットアクセスを失ったり、VM (Linux) とホスト (Windows) 間のコミュニケーションが遮断されたりすることもあり、はっきり言って大変なんです! ノートパソコンで開発作業を行ったり、簡単なデモやプレゼン資料を作成したりするとき、つまりインターネットにアクセスできることよりも、自分のホストと VM が確実に通信できることの方が重要であるときに、自分の作業環境を信頼できなくなってしまいます。
アドホックのローカルサブネットを Windows ホストと仮想マシン間で共有すれば、それを解決できます。 相互に通信し合えるようにするには、そのサブネットを使用します。 ホストと VM に特定の IP を割り当てれば準備完了です。
その方法はいたって簡単。 まずは、`Hyper-V Manager` にある Virtual Switch Manager... に移動します。
.png)
そこで、_New Virtual Switch __ _オプションを選択します (VM の新しいネットワークカードとして機能します)。
.png)
_内部ネットワーク _ として定義し、好きな名前を選び、他のオプションはデフォルトのままにしておきます。
.png)
_`Windows Control Panel --> Network and Sharing Center`_ と移動すれば、作成したばかりのスイッチが既に表示されています。
.png)
4. ホストと仮想マシン間で共有されるローカルサブネットを設定する
この時点で、新しいローカルネットワークの設定を完了します。 そのためには、_Mi Nuevo Conmutador LOCAL_ にカーソルを合わせて、Properties をクリックし、それから IPv4 protocol へと移動して固定 IP アドレスを割り当てます。
.png)
重要: ここで割り当てる IP は、このローカルサブネットのホスト (Windows) IP となります。
5. 新しいローカルネットワークを設定し、仮想マシンにリンクする
ここで、 `Hyper-V Manager` に戻ります。 VM が実行中であれば、停止してください。 停止したら、その設定に移動し、新しい内部仮想スイッチを追加します。
.png)
_(注意: 画像には他のスイッチ Hyper-V Conmutador INTERNO が表示されています。 これは私のもう 1 つのサブネット用のもので、 この設定には必要ありません) _
「Add」をクリックしたら、 前回作成したスイッチを選択します。
.png)
これが済んだら、「Apply」、「Accept」と順にクリックして準備完了です! 仮想マシンを起動し、もう一度ログインしてから内部接続の設定を完了します。 そうするには、VM が起動した後に画面右上のネットワークアイコンをクリックします。すると 2 つのネットワーク _eth0_ y _eth1_ が表示されます。 _eth1_ は、この時点では切断された状態で表示されます。
.png)
Ethernet (eht1) の設定に移動し、このローカルサブネットに固定 IP を割り当てます (例: IP _155.100.101.1_、サブネットマスク _ 255.255.255.0_)。
.png)
これで完了です。 これで仮想マシンが出来上がり、ホストと同じサブネットを共有する IP 155.100.101.1 として識別されます。
7. 仮想マシンから Windows 10 へのアクセスを許可する
大抵の場合、Windows 10 のデフォルト設定では、他のサーバーからのアクセスが許可されていません。Windows システムについては、たった今作成した VM がまさにそのサーバー (外部の潜在的に危険なサーバー) に該当します。このため、こういった仮想マシンからホストに接続するには、ファイアウォールにルールを追加する必要があります。 どうするのかって? いたって簡単です。`Windows Control Panel` の中から `Windows Defender Firewall` を見つけて、Advance Configuration に移動し、新規の *Entry Rule* を作成します。
.png)
1 つのポートまたは 1 つ以上の範囲を設定できます... (すべてのポートに対しルールを設定することもできます)...
.png)
ここで役に立つのが _Allow Connection_ です。
.png)
_ネットワークのすべてのタイプ_オプションを選択し...
.png)
ルールに名前を付けます。
.png)
ここで**重要**なことがあります。上記の手順が終わったら、新しく作成したルールのプロパティをもう一度開き、ルールをローカルサブネット内の接続に対してのみ適用できるよう*適用範囲を制限*しておきます。
.png)
8. 準備。 Docker と他に使用するアプリケーションを新しい Ubuntu 仮想マシンにインストールする
インストールプロセスを完了し、新しい VM を最新の状態に整え、インターネットアクセスなども準備ができたら、 好きなアプリをインストールできます。 少なくとも、元々の目的である Docker、また会社のネットワークへの接続に必要であれば VPN クライアント、さらには VS Code、Eclipse+Atelier などのアプリもインストールできます。
具体的に、VM 内で Docker をインストールする場合は、こちらの手順に従ってください: 。
Docker ランタイムの動作確認、テストイメージのダウンロードなどが済んだら、準備完了です。
_**¡You're all set!**_ が表示されたら、Ubuntu 仮想マシンでコンテナを (ハードウェアのキャパシティ内で) 制限なしに動作させることができます。同仮想マシンには、Windows 10 ホストやブラウザー、アプリなどから接続したり、またはその逆、Ubuntu VM から Windows 10 ホストに接続したりもできます。 このすべてに共有ローカルサブネット内で設定した IP アドレスが使用されるため、VPN を確立するしないに関わらず、またインターネットへのアクセスに Wi-Fi アダプターを使用するのか、イーサネットケーブルを使用するのかに関わらず、接続に失敗することはありません。
それから、アドバイスがもう 1 つだけあります。 Windows 10 と仮想マシンの間でファイルを交換する場合は、[WinSCP](https://winscp.net/eng/download.php) を使用すると簡単で便利です。 無料ですし、とても良く機能します。
もちろん、使える設定は他にもありますが、私は一番確実な方法としてこれを使っています。 お役に立つことを期待しています。 皆さんの悩みの種を取り除くことができれば、この記事を書いた価値があったと言えるでしょう。
¡ハッピーコーディング!
記事
Toshihiko Minamoto · 2021年1月21日
InterSystems Caché のグローバルは、デベロッパーにとって非常に便利な機能を提供します。 しかし、グローバルが高速な上に効率が良いのはなぜでしょう?
### 理論
基本的に、Caché データベースとは、データベースと同じ名前を持ち、CACHE.DAT ファイルを含んだカタログのことです。 Unix システムでは、このデータベースを普通のディスクパーティションにすることもできます。
Caché のデータはすべてブロックとして保管され、バランスド B\* ツリーとして整理されます。 基本的にすべてのグローバルがツリーに保管されると考えると、グローバルのサブスクリプトはツリーの枝を意味する一方で、グローバルのサブスクリプトの値はツリーの葉として保管されると言えます。 バランスド B\* ツリーと通常の B ツリーの違いは、前者の枝には [$Order](http://docs.intersystems.com/latestj/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_forder) と [$Query](http://docs.intersystems.com/latestj/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_fquery) の両関数を使ってサブスクリプト (この記事ではグローバル) のイテレーションをスピーディに実行するのに役立つ適切なリンクがあり、ツリーの幹に戻る必要がないという点です。
デフォルトで、データベースファイルの各ブロックのサイズは 8,192 バイトに固定されています。 既存のデータベースのブロックサイズは変更できません。 新しいデータベースを作成する場合は、保管するデータ型に合わせて、16kB、32 kB、または 64 kB をブロックサイズに選択できます。 但し、すべてのデータはブロック毎に読み取られることを覚えておきましょう。つまり、1 バイトの値を 1 つだけリクエストする場合でも、システムはリクエストされたデータブロックの前にいくつかのブロックを読み取ります。 また、Caché はデータを再利用するためにデータベースブロックをメモリに格納するグローバルバッファを使うことと、ブロックサイズと同じサイズとグローバルバッファを使用することを覚えておきましょう。 対応するブロックサイズのグローバルバッファがシステムにない場合は、そのブロックサイズの既存のデータベースをマウントしたり、新しいデータベースを作成したりはできません。 実際使用するブロックサイズでメモリサイズを定義することをおすすめします。 データベースブロックよりも大きいバッファブロックを使用することは可能ですが、その場合、各バッファブロックには 1 つのデータベースブロック、もしくはさらに小さいブロックしか保管されません。
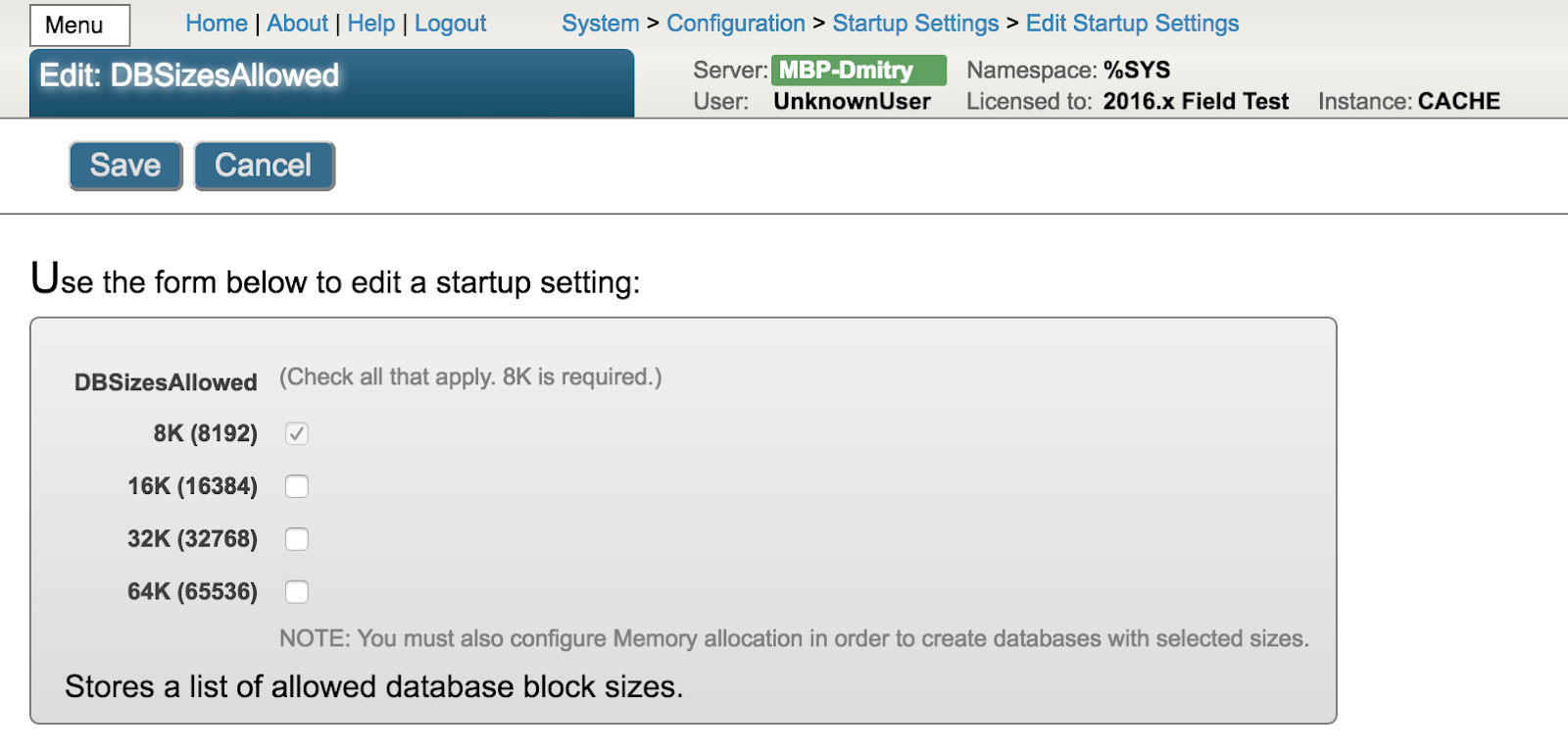
この画像では、8 kB のグローバルバッファのメモリがそれぞれ 8 kB のブロックで構成されるデータベースに割り当てられています。 このデータベースのブロックのうち、空でないものは、それぞれのマップが 62,464 個のブロック (それぞれ 8 kB のブロック) を定義するかたちでマップに定義されています。
### ブロックタイプ
システムは複数のブロックタイプに対応しています。 各レベルにおいて、ブロックの適切なリンクは同じタイプのブロックまたはデータの終わりを意味する Null ブロックにポイントしている必要があります。
* **タイプ 9**: グローバルカタログのブロック。 通常このブロックでは、既存のすべてのグローバルがそれぞれのパラメーターと併せて説明されます。このパラメーターには、グローバルのサブスクリプトのコレーション (照合順序) が含まれています。大切なパラメーターの 1 つで、グローバル作成後には変更できません。
* **タイプ 66**: 高レベルポインタのブロック。 このブロックの上に置けるのは、グローバルカタログのブロックのみです。
* **タイプ 6**: 低レベルポインタのブロック。 このブロックの上に置けるのは高レベルポインタのブロックのみで、これより下に置けるのはデータブロックのみです。
* **タイプ 70**: 高レベルポインタと低レベルポイントの両方で構成されるブロック。 このブロックは、対応するグローバルに保管される値の数が少ないため、複数のレベルのブロックを設ける必要がない場合に使用されます。 このブロックは通常、グローバルカタログのブロックと同様、データブロックにポイントします。
* **タイプ 2**: 比較的大きなグローバルを保管するポインターのブロック。 値を複数のデータブロックに均等に割り当てるには、ポインタのブロックにレベルを追加すると便利です。 このブロックは通常、ポインタのブロックの間に置かれます。
* **タイプ 8**: データブロック。 通常このブロックには、1 つのノードの値ではなく、複数のグローバルノードの値が保管されます。
* **タイプ 24**: ラージストリングのブロック。 1 つのグローバルの値がブロックサイズよりも大きい場合、その値はラージストリングの特殊ブロックに記録される一方で、データブロックのノードにはラージストリングのブロック一覧へのリンクが合計サイズと共に保管されます。
* **タイプ 16**: マップブロック。 このブロックは、未割り当てのブロックに関する情報を保管するようにデザインされています。
典型的な Caché データベースの最初のブロックには、データベースファイルそのものに関するサービス情報、2 つ目のブロックには複数のブロックからなるマップが含まれます。 最初のカタログブロックは 3 番目 (ブロック #3) に位置付けされ、1 つのデータベースに複数のカタログブロックを保管できます。 この後は、ポインタブロック (枝)、データブロック (葉)、そしてラージストリングのブロックが続きます。 先ほども触れましたが、グローバルカタログのブロックには、データベースやグローバル設定に存在するすべてのグローバルに関する情報が保管されます (そうでない場合は、そのようなグローバルに置かれます)。 この場合、そのようなグローバルを説明するノードには、低レベルの Null ポインタが割り当てられます。 既存のグローバルの一覧は、管理ポータルのグローバルカタログから表示できます。 また、このポータルでは、削除したグローバルをカタログに保存 (照合順序を保存するなど) したり、デフォルトの、またはカスタマイズしたコレ―ションを設定した新しいグローバルを作成したりできます。
一般的に、ブロックのツリーは下の画像のように描くことができます。 赤く表示されているのは、ブロックへのリンクです。
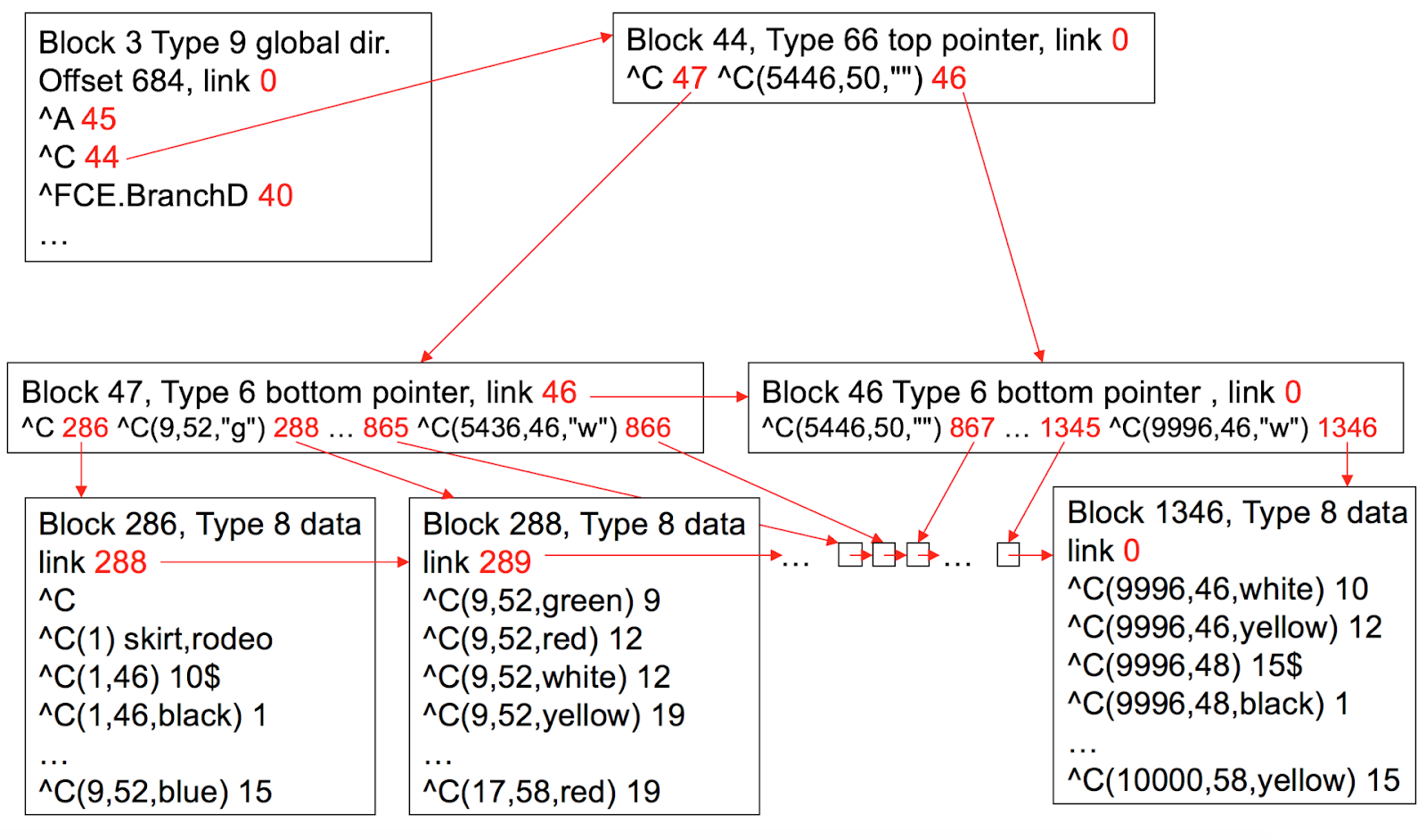
### データベースの整合性
Caché の現在のバージョンでは、データベースの最も重大な問題を解決しましたので、データベースのパフォーマンスが低下するリスクは極めて低くなっています。 それでも、定期的に ^Integrity ツールを使って自動整合性チェックを実行することをおすすめします。同ツールは、データベースページもしくはタスクマネージャーのマネジメントポータルを使って、%SYS ネームスペースのターミナルで起動できます。 自動整合性チェックは、デフォルトでセットアップされており、事前に定義もされているので、有効化するだけで実行できます。
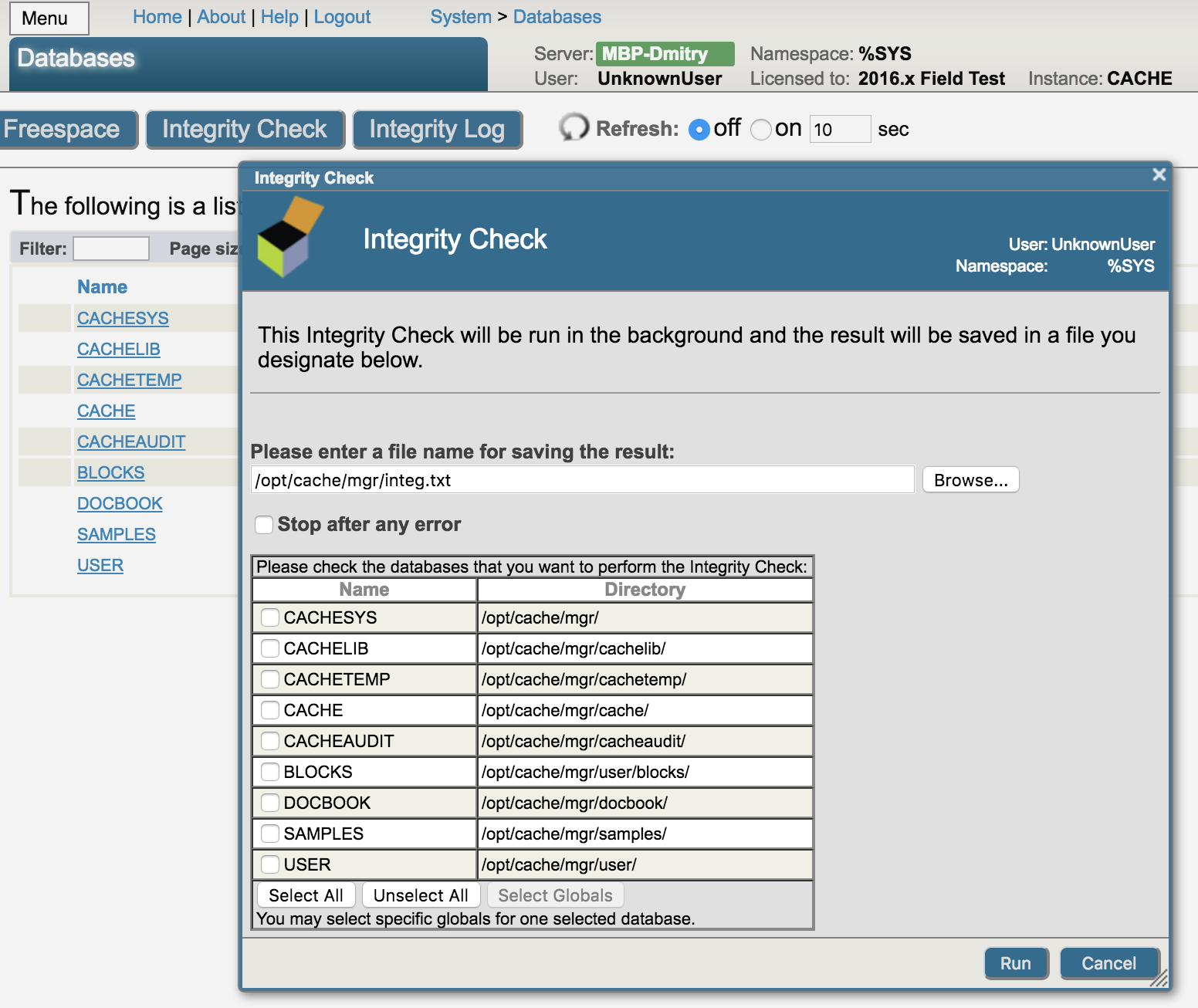
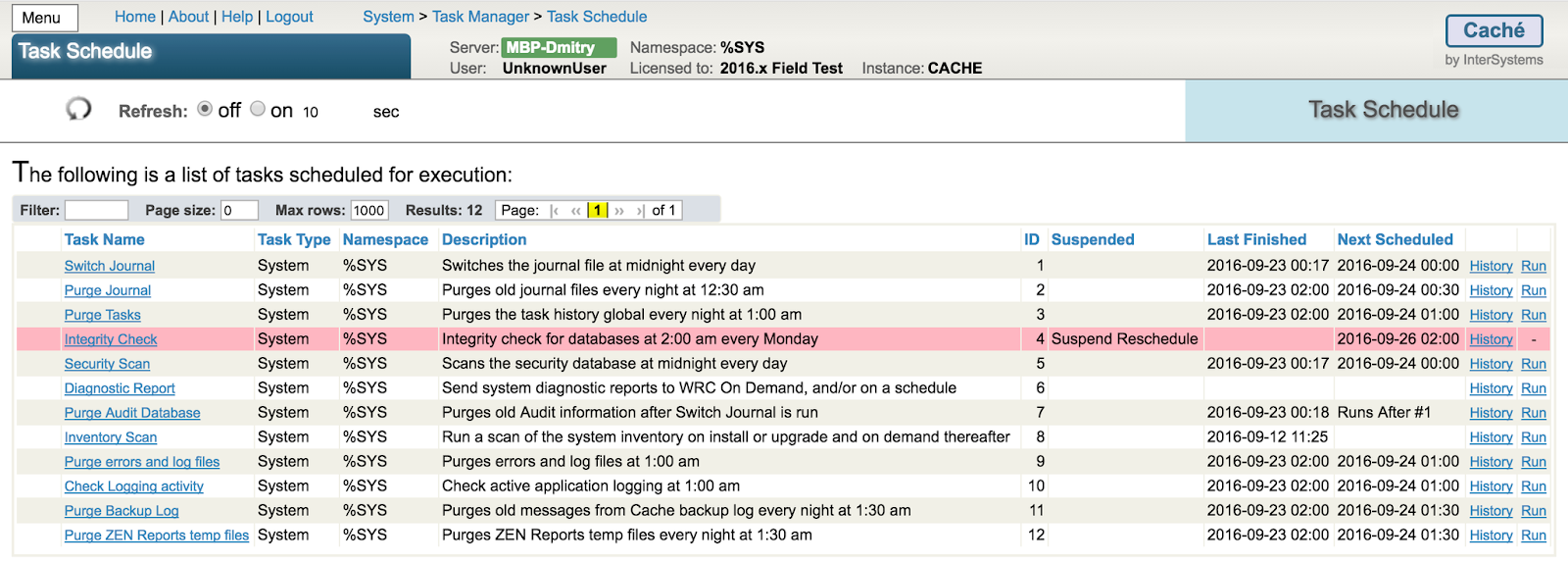
整合性チェックでは、OSI モデルの下位層でのリンク検証、ブロックタイプの確認、適切なリンクの分析、グローバルノードと適用される照合順序のマッチングが行われます。 整合性チェックの最中にエラーが出る場合は、%SYS ネームスペースから ^REPAIR ツールを実行できます。 このツールを使えば、どのブロックでも表示できる上に、必要であれば、データベースを修正するなどの変更を施すことができます。
### 実践
しかし、ここまで紹介した内容は理論にすぎません。 グローバルとそのブロックの実態を見極めるのは未だに容易なことではありません。 現時点で、ブロックを表示するには、上述した ^REPAIR ツールを使う方法しかありません。 下に示すのがこのプログラムの典型的な出力です。
1 年前、私は新しいツールを開発するプロジェクトに着手しました。それは、データベースを破損させるリスクなしにブロックのツリーをイテレーションし、それらのブロックをウェブ UI に視覚化し、その視覚化されたイメージを SVG または PNG に保存するオプションを提供するというものです。 このプロジェクトは名付けて CacheBlocksExplorer。ソースコードは、[Github](https://github.com/daimor/CacheBlocksExplorer) からダウンロードしていただけます。
実装した機能には以下の通りです。
* システム内の構成済みのデータベースや単純にマウントされたデータベースを表示する。
* 情報をブロック別、ブロックタイプ別、右ポインタ別、リンク付ノードの一覧別に表示する。
* 前述のレベルよりも低いレベルのブロックにポイントしているノードに関する詳細を表示する。
* ブロックへのリンクを削除することにより、そのブロックを非表示にする (そのブロックに保管されているデータを損傷することはありません)。
To-Do リスト:
適切なリンクを表示する: 現在のバージョンでは、適切なリンクはブロックに関する情報の中に表示されていますが、矢印として表示する方がベターでしょう。
ラージストリングのブロックを表示する: 現在のバージョンでは表示されていない。
グローバルカタログのブロックを3 番目のブロックだけでなく、すべて表示する。
ツリー全体も表示したいのですが、何十万個もあるブロックとそれぞれのリンクを一緒にすばやくレンダリングできるライブラリは、まだ見つかっていません。現在のライブラリは、ウェブブラウザーにレンダリングしていますが、そのスピードは Caché が構造全体を読み取るスピードよりもかなり遅いです。
次回の記事では、私の自作ツール Cache Block Explorer を実際に使い、その機能をさらに詳しく説明するほか、使用例をいくつか紹介し、グローバルやブロックに関する実行可能なデータを数多く取得する方法を披露したいと思います。