クリアフィルター
記事
Toshihiko Minamoto · 2022年3月1日
これは、適応性とパフォーマンスに優れた SQL エクスペリエンスを提供する 2021.2 SQL 強化機能に関する連載第 2 回目の記事です。 この記事では、前の記事で説明したランタイムプランの選択機能の主要な入力であるテーブル統計の収集におけるイノベーションに焦点を当てます。
皆さんには次のことを何度もお伝えしてきました:
『Tune tableを実行しましょう!』
[`TUNE TABLE` SQL コマンド](https://docs.intersystems.com/iris20211/csp/docbookj/DocBook.UI.Page.cls?KEY=RSQL_tunetable)または[`$SYSTEM.SQL.Stats.Table` ObjectScript API](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?&LIBRARY=%25SYS&CLASSNAME=%25SYSTEM.SQL.Stats.Table#GatherTableStats) を通じてテーブルをチューニングすることは、IRIS SQL が適切なクエリプランをはじき出すのに役立つテーブルデータの統計情報を収集することです。 これらの統計情報には、テーブル内のおおよその行数など、オプティマイザーが JOIN の順序(通常、最も小さいテーブルから始めるのが最も効率的です)などを決定する上で役立つ重要な情報が含まれています。 クエリのパフォーマンスについて InterSystems サポートに寄せられる多くの問い合わせは、`TUNE TABLE` を実行してもう一度試すだけで解消されます。このコマンドを実行することで、既存のプランが無効になり、次の呼び出しによって新しい統計が得られるためです。 サポートへの問い合わせから、こういったユーザーがテーブルの統計情報を収集していなかった理由が 2 つわかりました。テーブル統計について知らなかった、または本番システムでチューニングを実行した際のオーバーヘッドの余裕がなかったという理由です。 2021.2 では、この 2 つの理由に対処しました。
### ブロックレベルのサンプリング
2 つ目の理由から始めましょう。統計を収集するコストです。 テーブル統計を収集するには多大な I/O が必要となるため、_テーブル全体をスキャンしているのであれば_、オーバーヘッドも高まります。 API ではすでに、行の一部のみサンプリングすることをサポートしていましたが、この操作にはかなりのコストがかかるというご意見をいただいていました。 2021.2 では、マスターマップグローバルをループすることでランダムな行を選択するのではなく、その下の物理ストレージにすぐにアクセスしてそのグローバルにカーネルが実際のデータベースブロックのランダムなサンプルを取得するように変更しました。 サンプリングされたこれらのブロックから、それらが保存する SQL テーブル行を推論し、通常のフィールド単位の統計情報構築ロジックに対応します。
これを大規模なビールフェスティバルへの参加に例えると、すべての通路を歩き、いくつかの醸造所のブースを選んでそれぞれのボトルをカートに入れるのではなく、単に主催者に依頼してランダムなボトルが入った木箱を渡してもらうので歩かなくても済む、というものです。 (実際のビール試飲会では、歩き回ったほうが適切ですが)。 酔いを醒ますために、以下に、ブロックベースのアプローチ(青い十字)に対する今までの行ベースのアプローチ(赤い十字)をプロットした単純なグラフを示しています。 これは、一部のお客様が `TUNE TABLE` を実行することを警戒している巨大なテーブルについては大きなメリットがあることを表しています。
ブロックサンプリングの制限はあまりありませんが、最も重要なのは、デフォルトのストレージマッピングでないテーブル(例: `%Storage.SQL` を使用してグローバル構造をカスタムマッピングしているテーブル)では使用できないことです。 このような場合には、過去に機能していた方法である、行ベースのサンプリングに戻ります。
### 自動チューニング
オーバーヘッドに関する認識の問題が片付いたところで、お客様が `TUNE TABLE` を実行していなかったもう 1 つの理由について考えましょう。その存在を知らなかったという理由です。 それについて文書化することもできました(また、ドキュメントを改善する余地が常にあることは認識しています)が、この非常に効率的なブロックサンプリングは、私たちが長年求めてきたことを実行する機会であると捉えました。すべてを自動化するということです。 2021.2 からは、統計がまったく提供されていないテーブルに対してクエリを準備する場合、最初に上記のブロックサンプリングメカニズムを使用してそれらの統計を収集し、クエリプランニングに統計を使用し、以降のクエリで使用できるように、テーブルメタデータに保存します。
仰々しく聞こえるかもしれませんが、上記のグラフは、GB サイズのテーブルでは、この統計収集の作業がわずか数秒で開始していることがわかります。 不適切なクエリプランを使用してそのようなテーブルをクエリしている場合(適切な統計がないため)は、事前に簡易サンプリングを実行するよりもはるかにコストがかかる可能性があります。 もちろん、これは、ブロックサンプリングを使用できるテーブルのみに行い、行ベースのサンプリングのみをサポートする特殊なテーブルの場合は、(残念ながら)統計なしで対処するしかありません。
他の新機能と同様に、皆さんの最初の体験に関する感想とフィードバックをお送りください。 この分野では、テーブルの使用状況に基づいて統計を最新の状態に維持するなど、自動化に関するアイデアは他にもありますが、そういった機能をラボ外部の使用体験に基づくものにしたいと考えています。
記事
Toshihiko Minamoto · 2022年11月2日
> **良識のある人にはルールなんていらない。**
>
> _ドクター_
日付と時間のマスターになるのは簡単なことではありません。いつも問題になる上、どのようなプログラミング言語でも混乱することがあります。そこでこのタスクが可能な限り単純になるように、分かりやすく説明していくつかのヒントをご紹介しましょう。
さぁ、[ターディス](https://ja.wikipedia.org/wiki/%E3%82%BF%E3%83%BC%E3%83%87%E3%82%A3%E3%82%B9)に乗り込みましょう。あなたを**時間の支配者**にして差し上げます。

## 基本から始めよう
普段、他の言語を使用しているのであれば、InterSystems Object Script(以降「IOS」と呼びますが、Apple モバイルと勘違いしないように)の日付は少し独特です。
ターミナルで [$HOROLOG](https://docs.intersystems.com/healthconnectlatest/csp/docbookj/DocBook.UI.Page.cls?KEY=RCOS_VHOROLOG) を実行して現在の日付と時刻を取得する場合、2 つの部分に分割されているのがわかります。
WRITE $HOROLOG
> 66149,67164
最初の値は日にちです。正確には 1840 年 12 月 31 日以来の日数であり、つまり値 1 は 1841 年 1 月 1 日となります。2 つ目の値は今日の 00:00 時以来の秒数です。
この例では、66149 は 09/02/2022(欧州フォーマットの dd/mm/yyyy なので 2 月 9 日)、67164 は 18:39:24 に対応しています。 このフォーマットを日付と時刻の**内部フォーマット**と呼ぶことにします。
混乱してきましたか? (日付と時刻の)宇宙の大きな秘密を解明し始めることにしましょう。
## 内部フォーマットをわかりやすいフォーマットに変換するには?
それについては、[$ZDATETIME](https://docs.intersystems.com/healthconnectlatest/csp/docbookj/DocBook.UI.Page.cls?KEY=RCOS_fzdatetime) コマンドを使用します。
基本的なコマンドは以下のようになります。
SET RightNow = $HOROLOG
WRITE RightNow
> 66149,67164
WRITE $ZDATETIME(RightNow)
> 02/09/2022 18:39:24
デフォルトでは、アメリカ式フォーマット(mm/dd/yyyy)を使用します。 別のフォーマットで日付を表す場合は、欧州フォーマット(dd/mm/yyyy)など2 つ目のパラメーターを使用し、この場合は値 4 を指定します(詳細については、ドキュメントの [$ZDATETIME.dformat](https://docs.intersystems.com/healthconnectlatest/csp/docbookj/DocBook.UI.Page.cls?KEY=RCOS_fzdatetime#RCOS_fzdatetime_dformat) をご覧ください)。
SET RightNow = $HOROLOG
WRITE RightNow
> 66149,67164
WRITE $ZDATETIME(RightNow,4)
> 09/02/2022 18:39:24
このオプションは、ローカル変数で定義したものを区切り文字と年フォーマットを使用します。
また、別の時間フォーマットを使用したい場合、たとえば 24 時間制ではなく 12 時間制(午前/午後)を使用したい場合は、3 つ目のパラメータを値 3 とし、秒数を表示しない場合は、値 4 を使用します(ドキュメントの [ $ZDATETIME.tformat](https://docs.intersystems.com/healthconnectlatest/csp/docbookj/DocBook.UI.Page.cls?KEY=RCOS_fzdatetime#RCOS_fzdatetime_tformat) を参照)。
SET RightNow = $HOROLOG
WRITE RightNow
> 66149,67164
WRITE $ZDATETIME(RightNow,4,3)
> 09/02/2022 06:39:24PM
WRITE $ZDATETIME(RightNow,4,4)
> 09/02/2022 06:39PM
わかってきましたか? ではもっと詳しく見てみましょう。
### ODBC フォーマット
このフォーマットはローカル構成に依存しておらず、常に yyyy-mm-dd として表示されます。この値は 3 です。 CSV、HL7 などのファイルでエクスポートされるデータを作成する際は、これを使用することをお勧めします。
SET RightNow = $HOROLOG
WRITE RightNow
> 66149,67164
WRITE $ZDATETIME(RightNow,3)
> 2022-02-09 18:39:24
### 曜日、曜日名、年間通産日
| 値 | 説明 |
| -- | ------------------------------------------------------------------------- |
| 10 | 曜日は 0 から 6 の値で、日曜日は 0、土曜日は 6 です。 |
| 11 | 曜日の略名で、ユーザーが定義するローカル構成に基づいて返します。IRIS のデフォルトインストールは enuw(英語、米国、Unicode)です。 |
| 12 | ロング形式の曜日名。 11 と同じです。 |
| 14 | 年間通産日。つまり 1 月 1 日からの日数です。 |
日付と時刻を個別に扱う場合は、それぞれ $ZDATE コマンドと $ZTIME コマンドを使用します。 フォーマットのパラメーターは、[$ZDATETIME.dformat](https://docs.intersystems.com/healthconnectlatest/csp/docbookj/DocBook.UI.Page.cls?KEY=RCOS_fzdatetime#RCOS_fzdatetime_dformat)と[$ZDATETIME.tformat](https://docs.intersystems.com/healthconnectlatest/csp/docbookj/DocBook.UI.Page.cls?KEY=RCOS_fzdatetime#RCOS_fzdatetime_tformat)で定義されているパラメーターと同じです。
SET RightNow = $HOROLOG
WRITE RightNow
> 66149,67164
WRITE $ZDATE(RightNow,10)
> 3
WRITE $ZDATE(RightNow,11)
> Wed
WRITE $ZDATE(RightNow,12)
> Wednesday
## 日付を内部フォーマットに変換するには?
では、逆のステップを見てみましょう。日付のあるテキストを IOS フォーマットに変換する方法です。 このタスクでは、[$ZDATETIMEH](https://docs.intersystems.com/healthconnectlatest/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_fzdatetimeh) コマンドを使用します。
今度は、日付と時刻に使用されているフォーマット($ZDATETIMEH を使用している場合)、または日付($ZDATEH)または時刻($ZTIMEH)に使用されているフォーマットを個別に示す必要があります。
フォーマットは同じです。つまり、ODBC フォーマット(yyyy-mm-dd)の日付を持つ文字列がある場合は、値 3 を使用します。
SET MyDatetime = "2022-02-09 18:39:24"
SET Interna1 = $ZDATETIMEH(MyDatetime, 3, 1) // ODBC フォーマット
SET MyDatetime = "09/02/2022 18:39:24"
SET Interna2 = $ZDATETIMEH(MyDatetime, 4, 1) // 欧州フォーマット
SET MyDatetime = "02/09/2022 06:39:24PM"
SET Interna3 = $ZDATETIMEH(MyDatetime, 1, 3) // 米国フォーマット、12 時間制 AM/PM
WRITE Interna1,!,Interna2,!,Interna3
> 66149,67164
66149,67164
66149,67164
論理的に、文字列が特定のフォーマットを使用しており、誤ったパラメーターを指定した場合は、2 月 9 日ではなく 9 月 2 日として理解するなど、どのようなことでも起こりえます。
フォーマットを混在させないようにしましょう。後で問題になります。
SET MyDatetime = "09/02/2022"
/// 米国フォーマット
SET InternalDate = $ZDATEH(MyDatetime, 1)
/// 欧州フォーマット
SET OtherDate = $ZDATETIME(InternalDate, 4)
WRITE InternalDate,!,OtherDate
> 66354
02/09/2022
もちろん、欧州式の日付を設定し、米国式に変換しようとすると ... バレンタインデーはどうなってしまうのでしょうか?
SET MyDatetime = "14/02/2022"
SET InternalDate = $ZDATEH(MyDatetime, 1) // 米国フォーマット。 14 月は存在しません!!!
^
<ILLEGAL VALUE>
ハートブレイクなバレンタインデーと同じように... コードブレイクしてしまいました。
では、学習した内容を使って、何かやってみましょう。
READ !,"Please indicate your date of birth (dd/mm/yyyy): ",dateOfBirth
SET internalFormat = $ZDATEH(dateOfBirth, 4)
SET dayOfWeek= $ZDATE(internalFormat, 10)
SET nameOfDay = $ZDATE(internalFormat, 12)
WRITE !,"The day of the week of your birth is: ",nameOfDay
IF dayOfWeek = 5 WRITE "you always liked to party!!!" // 金曜日生まれ
後で、これを他のやり方で行う方法と、エラーの処理方法を見ることにしましょう。
###
### 次の章: タイムトラベルの方法
## トリビア
なぜ 1841年1月1日の値が値1 となるのでしょうか?
それが選択された理由は、オブジェクトスクリプトを拡張した [MUMPS プログラミング言語](https://ja.wikipedia.org/wiki/MUMPS)が設計されたときに、南北戦争の退役軍人として当時生存していた最年長 121 歳のアメリカ人が生まれる前のうるう年でない年であったためです。
>オブジェクトスクリプトを拡張した MUMPS プログラミング言語が設計されたときに
これは逆ですね。MUMPSプログラミング言語を拡張したオブジェクトスクリプト
記事
Toshihiko Minamoto · 2023年3月23日
腎臓病は、医学会でよく知られるいくつかのパラメーターから発見することが可能です。 この測定により、医学界とコンピューター化されたシステム(特に AI)を支援すべく、科学者である Akshay Singh は、腎臓病の検出/予測における ML アルゴリズムをトレーニングするための非常に便利なデータセットを公開しました。 このデータセットは、ML の最大級のデータリポジトリとして最もよく知られている Kaggle に公開されています。https://www.kaggle.com/datasets/akshayksingh/kidney-disease-dataset
## データセットについて
腎臓病データセットには、以下のメタデータ情報が含まれています(出典: https://www.kaggle.com/datasets/akshayksingh/kidney-disease-dataset)
* 赤血球、足浮腫、血糖値などの 25 種類の特徴量を含む 400 行のデータセット。
* 患者が慢性腎臓病を患っているかどうかを分類することが目的
* 分類は、'classification' と名付けられた属性が 'ckd'(慢性腎臓病)であるか 'notckd' であるかに基づいて行われます。
* データセットの作成者は、テキストと数値のマッピングやその他の変更点を含むデータセットのクリーニングを実施しました。 クリーニングの後、データセット作成者は EDA(探索的データ解析)を行い、データセットをトレーニングとテストに分割し、それらにモデルを適用しました。 分類結果は、最初はあまり満足のいくものではないことがわかっています。 そこで、Nan 値のある行をドロップする代わりに、ラムダ関数を使用して、それらの行を各カラムのモードに置き換えて、 もう一度データセットをトレーニングセットとテストセットに分割し、モデルに適用しました。 今度は、結果が改善され、ランダムフォレストと意思決定ツリーが、1.0 と 0 の誤分類の精度で最も良く実行することがわかりました。 分類のパフォーマンスは、混合行列、分類レポート、および制度の出力によって測定されています。
### データセットの情報(出典: https://archive.ics.uci.edu/ml/datasets/chronic\_kidney\_disease )
データセットの収集には以下の表現を使用しています。
age - 年齢
bp - 血圧
sg - 比重
al - アルブミン値
su - 糖分
rbc - 赤血球
pc - 膿細胞
pcc - 膿細胞の塊
ba - 細菌
bgr - ランダム血糖値
bu - 血液尿素
sc - 血清クレアチニン
sod - ナトリウム
pot - カリウム
hemo - ヘモグロビン
pcv - ヘマトクリット値
wc - 白血球数
rc - 赤血球数
htn - 高血圧
dm - 糖尿病
cad - 冠動脈疾患
appet - 食欲
pe - 足浮腫
ane - 貧血症
class - クラス
### 属性の情報(出典: https://archive.ics.uci.edu/ml/datasets/chronic\_kidney\_disease)
24 + class = 25(数値 11 個、名義尺度 14 個)を使用します。
1. 年齢(数値)
年数
2. 血圧(数値)
bp(mm/Hg)
3. 比重(名義尺度)
sg - (1.005,1.010,1.015,1.020,1.025)
4. アルブミン値(名義尺度)
al - (0,1,2,3,4,5)
5. 糖分(名義尺度)
su - (0,1,2,3,4,5)
6. 赤血球(名義尺度)
rbc - (normal,abnormal)
7. 膿細胞(名義尺度)
pc - (normal,abnormal)
8. 膿細胞集塊(名義尺度)
pcc - (present,notpresent)
9. 最近(名義尺度)
ba - (present,notpresent)
10. ランダム血糖値(数値)
bgr(mgs/dl)
11. 血液尿素(数値)
bu(mgs/dl)
12. 血清クレアチニン(数値)
sc(mgs/dl)
13. ナトリウム(数値)
sod(mEq/L)
14. カリウム(数値)
pot(mEq/L)
15. ヘモグロビン(数値)
hemo(gms)
16. ヘマトクリット値(数値)
17. 白血球数(数値)
wc(cells/cumm)
18. 赤血球数(数値)
rc(100万/cmm)
19. 高血圧(名義尺度)
htn - (yes,no)
20. 糖尿病(名義尺度)
dm - (yes,no)
21. 冠動脈疾患(名義尺度)
cad - (yes,no)
22. 食欲(名義尺度)
appet - (good,poor)
23. 足浮腫(名義尺度)
pe - (yes,no)
24. 貧血症(名義尺度)
ane - (yes,no)
25. 区分(名義尺度)
class - (ckd,notckd)
## Kaggle から腎臓データを取得する
Kaggle の腎臓データは、Health-Dataset アプリケーション(https://openexchange.intersystems.com/package/Health-Dataset)を使って IRIS テーブルに読み込めます。 これを行うには、module.xml プロジェクトから依存関係(Health Dataset 用の ModuleReference)を設定します。
Health Dataset アプリケーションリファレンスを使用した Module.xml
<?xmlversion="1.0" encoding="UTF-8"?>
<Export generator="Cache" version="25"> <Documentname="predict-diseases.ZPM">
<Module>
<Name>predict-diseases</Name>
<Version>1.0.0</Version>
<Packaging>module</Packaging>
<SourcesRoot>src/iris</SourcesRoot>
<Resource Name="dc.predict.disease.PKG"/>
<Dependencies>
<ModuleReference>
<Name>swagger-ui</Name>
<Version>1.*.*</Version>
</ModuleReference>
<ModuleReference>
<Name>dataset-health</Name>
<Version>*</Version>
</ModuleReference>
</Dependencies>
<CSPApplication
Url="/predict-diseases"
DispatchClass="dc.predict.disease.PredictDiseaseRESTApp"
MatchRoles=":{$dbrole}"
PasswordAuthEnabled="1"
UnauthenticatedEnabled="1"
Recurse="1"
UseCookies="2"
CookiePath="/predict-diseases"
/>
<CSPApplication
CookiePath="/disease-predictor/"
DefaultTimeout="900" SourcePath="/src/csp"
DeployPath="${cspdir}/csp/${namespace}/"
MatchRoles=":{$dbrole}"
PasswordAuthEnabled="0"
Recurse="1"
ServeFiles="1"
ServeFilesTimeout="3600"
UnauthenticatedEnabled="1"
Url="/disease-predictor"
UseSessionCookie="2"
/>
</Module>
</Document>
</Export>
## 腎臓病を予測するための Web フロントエンドとバックエンドのアプリケーション
Open Exchange アプリのリンク(https://openexchange.intersystems.com/package/Disease-Predictor)に移動し、以下の手順に従います。
1. リポジトリを任意のローカルディレクトリに Clone/git pull します。
$ git clone https://github.com/yurimarx/predict-diseases.git
2. このディレクトリで Docker ターミナルを開き、以下を実行します。
$ docker-compose build
3. IRIS コンテナを実行します。
$ docker-compose up -d
4. AI モデルをトレーニングするため管理ポータルのクエリ実行(http://localhost:52773/csp/sys/exp/%25CSP.UI.Portal.SQL.Home.zen?$NAMESPACE=USER)に移動します。
5. トレーニングに使用するビューを作成します。
CREATE VIEW KidneyDiseaseTrain AS SELECT age, al, ane, appet, ba, bgr, bp, bu, cad, classification, dm, hemo, htn, pc, pcc, pcv, pe, pot, rbc, rc, sc, sg, sod, su, wc FROM dc_data_health.KidneyDisease
6. ビューを使用して AI モデルを作成します。
CREATE MODEL KidneyDiseaseModel PREDICTING (classification) FROM KidneyDiseaseTrain
7. モデルをトレーニングします。
TRAIN MODEL KidneyDiseaseModel
8. [http://localhost:52773/disease-predictor/index.html](http://localhost:52773/disease-predictor/index.html) に移動し、Disease Predictor フロントエンドを使用して、以下のように疾患を予測します。
## 背後の処理
### 腎臓病を予測するためのバックエンドのクラスメソッド
InterSystems IRIS では、前に作成されたモデルを使って、SELECT の実行により予測することができます。
腎臓病を予測するためのバックエンドのクラスメソッド
/// 腎臓病の予測
ClassMethod PredictKidneyDisease() As %Status
{
Try {
Set data = {}.%FromJSON(%request.Content)
Set %response.Status = 200
Set %response.Headers("Access-Control-Allow-Origin")="*"
Set qry = "SELECT PREDICT(KidneyDiseaseModel) As PredictedKidneyDisease, "
_"age, al, ane, appet, ba, bgr, bp, bu, cad, dm, "
_"hemo, htn, pc, pcc, pcv, pe, pot, rbc, rc, sc, sg, sod, su, wc "
_"FROM (SELECT "_data.age_" AS age, "
_data.al_" As al, "
_"'"_data.ane_"'"_" AS ane, "
_"'"_data.appet_"'"_" AS appet, "
_"'"_data.ba_"'"_" As ba, "
_data.bgr_" As bgr, "
_data.bp_" AS bp, "
_data.bu_" AS bu, "
_"'"_data.cad_"'"_" As cad, "
_"'"_data.dm_"'"_" As dm, "
_data.hemo_" AS hemo, "
_"'"_data.htn_"'"_" AS htn, "
_"'"_data.pc_"'"_" As pc, " _"'"_data.pcc_"'"_" As pcc, "
_data.pcv_" AS pcv, "
_"'"_data.pe_"'"_" AS pe, "
_data.pot_" As pot, "
_"'"_data.rbc_"'"_" As rbc, "
_data.rc_" AS rc, "
_data.sc_" AS sc, "
_data.sg_" As sg, "
_data.sod_" As sod, "
_data.su_" AS su, "
_data.wc_" AS wc)"
Set tStatement = ##class(%SQL.Statement).%New()
Set qStatus = tStatement.%Prepare(qry)
If qStatus'=1 {WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT}
Set rset = tStatement.%Execute()
Do rset.%Next()
Set Response = {}
Set Response.classification = rset.PredictedKidneyDisease
Set Response.age = rset.age
Set Response.al = rset.al
Set Response.ane = rset.ane
Set Response.appet = rset.appet
Set Response.ba = rset.ba
Set Response.bgr = rset.bgr
Set Response.bp = rset.bp
Set Response.bu = rset.bu
Set Response.cad = rset.cad
Set Response.dm = rset.dm
Set Response.hemo = rset.hemo
Set Response.htn = rset.htn
Set Response.pc = rset.pc
Set Response.pcc = rset.pcc
Set Response.pcv = rset.pcv
Set Response.pe = rset.pe
Set Response.pot = rset.pot
Set Response.rbc = rset.rbc
Set Response.rc = rset.rc
Set Response.sc = rset.sc
Set Response.sg = rset.sg
Set Response.sod = rset.sod
Set Response.su = rset.su
Set Response.wc = rset.wc
Write Response.%ToJSON()
Return 1
} Catch err {
write !, "Error name: ", ?20, err.Name,
!, "Error code: ", ?20, err.Code,
!, "Error location: ", ?20, err.Location,
!, "Additional data: ", ?20, err.Data, !
Return
}
}
これで、どの Web アプリケーションもこの予測を使用して、結果を表示できるようになりました。 predict-diseases アプリケーションのソースコードは、frontend フォルダをご覧ください。
記事
Toshihiko Minamoto · 2023年5月2日
開発者のみなさん、こんにちは。
vscode上で動作するObjectScriptエクステンションがリリースされ、vscodeを開発環境として使用できるようになり、GitHubリポジトリと連携できるようになりました。その一方で、使い慣れたIRISやCacheのスタジオからGitHubを扱いたいという要望は根強くあり、GitHubと連携するツールがOpen Exchange上にいくつか公開されています。
そこで、Open exchangeに収録されているツールの中で新しい「git for shared development environment」を使い、環境を作成してみましたので、その手順をお伝えします。
ご利用される際のご参考になれば幸いです。
Git for windows のインストール
Git for windows のサイト よりキットをダウンロードし、そのexeファイル (git-2.xx.xx xx-bit.exe) を起動します。ライセンスの確認画面が表示されますので、「Install」ボタンをクリックします。
SSHキーペアの作成
コマンドプロンプトを起動し、ssh-keygen コマンドを実行します。
C:\Users\username> ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (C:\Users\username/.ssh/id_rsa): <-- Enter
Enter passphrase (empty for no passphrase): <-- Enter
Enter same passphrase again: <-- Enter
Your identification has been saved in C:\Users\username/.ssh/id_rsa.
Your public key has been saved in C:\Users\username/.ssh/id_rsa.pub.
:
C:\Users\username>
注意:このツールではSSHキーペアを使ってGitHubにアクセスすることを前提にしています。httpだとうまく動作しないことがありますので、ご注意ください。
GitHub への公開鍵の登録
WebブラウザにてGitHubのSSH公開鍵登録画面(https://github.com/settings/keys)にアクセス(GitHubアカウントへのログインが必要です)し、「New SSH key」をクリックします。Add new画面にて、Titleに公開鍵の名称(何でも構いません)を入力し、Keyに先ほど作成したid_rsa.pubファイルの中身を貼り付け、「Add SSH key」ボタンをクリックします。
InterSystems Package Manager (IPM:旧ZPM)のインストール
以下のURLよりIPMのキット(zpm-0.x.x.xml)をダウンロードします。https://pm.community.intersystems.com/packages/zpm/latest/installer
ダウンロードしたzpm-0.x.x.xmlを%SYSネームスペースにロードします。
USER> zn "%SYS"
%SYS> do $SYSTEM.OBJ.Import(ファイル名,"c")
IPMをインストールいただくことで、簡単にOpen Exchangeに収録されている対応ツールやパッケージをダウンロード、インストールできます。特に依存関係のあるパッケージもインストールされますので簡単です。
Git for Shared Development Environment のインストール
Git for Shared Development Environmentは以下のOpenExchangeに掲載されており、スタジオからgitを使用してGitHubとの連携を行うツールです。https://openexchange.intersystems.com/package/Git-for-Shared-Development-Environments
ターミナルを起動し、開発環境のネームスペースに移動、IPMを使用してインストールします。
USER> zn "DEV"
DEV> zpm "install git-source-control"
設定メソッドを実行し、gitのパスやローカルリポジトリのフォルダ、SSH秘密鍵、Git操作ユーザを設定します。
DEV>d ##class(SourceControl.Git.API).Configure()
Configured SourceControl.Git.Extension as source control class for namespace DEV
Configured default mappings for classes, routines, and include files. You can customize these in the global:
^SYS("SourceControl","Git","settings","mappings")
Path to git executable: "C:\Program Files\Git\bin\git.exe" => <-- Enterのみ
Local git repo root folder: c:\temp\DEV\ => <-- ローカルリポジトリのフォルダを入力
Path to private key file (for ssh remotes): c:\Users\user\.ssh\id_rsa <-- 先ほど作成したSSH秘密鍵のファイル名
Event handler class for git pull:
SourceControl.Git.PullEventHandler.Default => <-- Enterのみ
Character to replace % symbol when importing %-classes into the file systems: <-- Enterのみ
Attribution: Git username for user 'username': username => <-- Git操作を行うユーザ名
Attribution: Email address for user 'username':
username@pc.company.com => <-- Git操作を行うユーザのメールアドレス
Settings saved.
DEV>
ローカルリポジトリの初期化
Git for windowsバージョン2.35.2以降ではセキュリティが強化されており、ローカルリポジトリフォルダの所有者がローカルシステムアカウントでない場合、エラーが発生するようになりました。そのため、一旦フォルダを削除します。
C:\Users\username> rmdir C:\Temp\DEV
スタジオを起動し、開発環境のネームスペースに接続します。「Git」メニューの「Initialize」をクリック、ローカルリポジトリを初期化します。
「Git」メニューが表示されないときは、管理ポータルを起動し、「システム管理」「構成」「追加設定」「ソースコントロール」をクリックしますと、以下のような画面が表示されます。
ここで画面左のネームスペースで開発環境のネームスペースを選択し、ソースコントロールクラス名にて「SourceControl.Git.Extension」クラスをクリック、画面上の「保存」ボタンをクリックします。その後、スタジオを再起動することで「Git」メニューが表示されるようになります。
リモートリポジトリの設定とソースコードの取り込み
コマンドプロンプトより、リモートリポジトリ(github.com/username/xxx.git)を登録します
C:\Users\username> cd C:\Temp\DEV
C:\Temp\DEV> git remote add origin git@github.com:username/xxx.git
リモートリポジトリからソースコードをpullし、テンポラリフォルダにソースコードを取り込みます。
C:\Temp\DEV> git pull origin master
remote: Enumerating objects: 79, done.
remote: Counting objects: 100% (79/79), done.
remote: Compressing objects: 100% (51/51), done.
remote: Total 79 (delta 14), reused 77 (delta 14), pack-reused 0
Unpacking objects: 100% (79/79), 42.87 KiB | 142.00 KiB/s, done.
From github.com:miniclub/xxx
* branch master -> FETCH_HEAD
* [new branch] master -> origin/master
ブランチがmasterでない場合、以下のようにブランチ名を指定し、git checkoutで現在のブランチを変更してください。
C:\Temp\DEV> git pull origin dev
:
C:\Temp\DEV> git chekout dev
マッピング情報の変更
取り込んだリモートリポジトリのフォルダ構成に合わせてマッピング情報を変更します。
スタジオを起動し、開発環境のネームスペースに接続、「Git」「Settings」メニューをクリックします。設定画面が表示されますので、「Mappings」欄に移動します。
表の左からソースコードの拡張子、名前、関連パスとなっており、赤枠で囲まれた関連パスをリポジトリのフォルダ構成に応じて変更します。
例えば、vscodeで作成したリポジトリではクラスやルーチンは全てsrcフォルダ配下に入りますので、それらの値は全て「src/」となります。
ソースコードのインポート
「Git」「Import (force)」メニューで、ローカルリポジトリフォルダのソースコードをIRISに読み込みます。
以上で、GitHubに登録されたリポジトリのソースコードをIRISに取り込むことができました。クラスやルーチンを修正した後、各ファイルを表示した状態で「Git」「Commit changes to file」メニューをクリックすることで変更をコミットし、「Git」「Push to remote branch」でリモートリポジトリに反映させることが。
最後までお読みいただきありがとうございます。
一度お試しいただいて、ご意見やご質問等ございましたら、コメント欄に書き込みいただければと思います。
記事
Mihoko Iijima · 2023年6月2日
開発者の皆さん、こんにちは!
この記事では、ワークフローコンポーネントを使ってみよう!~使用手順解説~ でご紹介したユーザ操作画面(ユーザポータル)を任意のWebアプリに変更する際に便利な REST API の使用方法をご紹介します。
ワークフロー用 REST APIですが、開発者コミュニティのサンプル公開ページ:Open Exchange に公開されているAPIでどなたでも自由にご利用いただけます。
Open Exchangeの検索ボックスに「Workflow rest」と入力すると出てきます。EnsembleWorkflow が対象のサンプルです。
ちなみに、2023年6月2日時点で724のアプリケーションが公開されているようです👀
以下の内容もぜひご確認ください。
ワークフローコンポーネントでどんなことができるのか?の概要説明については、ウェビナー(オンデマンド再生)をご参照ください。
コンテナで動くサンプルもご用意しています。流れを先に確認されたい場合は、システム連携の自動的な流れの中にユーザからの指示を介入できる「ワークフローコンポーネント」のサンプル の手順に沿って動作をご確認ください。
EnsembleWorkflow のページに移動したらボタンをクリックするとサンプルがあるGitリポジトリに移動します。
InterSystems Package Manager(IPM)でもインストールできますが、この記事ではGitリポジトリから入手する方法で記載しています。
リポジトリに移動すると、isc/wf/REST.clsクラスが確認できます。このクラスをお手元のIRISにインストールし、RESTのエンドポイント(=ウェブアプリケーションパスの設定)を作成したら利用できます。
以降の説明では、お手元のIRISにこのクラスをインポートした後の手順をご紹介します。
クラス定義のインポート方法については、1つ前の記事「ワークフローコンポーネントを使ってみよう!~使用手順解説~」の 4) サンプルのインポート をご参照ください。
この後の説明は、「システム連携の自動的な流れの中にユーザからの指示を介入できる「ワークフローコンポーネント」のサンプル」 の手順に沿って作成したワークフロータスクを処理できる環境があることを前提としています。
サンプルをインポートすると「isc.wf.REST」の名称でクラスがインポートされます。このクラス名を使用してRESTのエンドポイントを作成します。
IRISの管理ポータルを開きます(ウェブサーバ名、ポート番号は環境に合わせてご変更ください)👉 http://localhost:52773/csp/sys/UtilHome.csp
管理ポータル > [システム管理] > [セキュリティ] > [アプリケーション] > [ウェブ・アプリケーション] に移動します。
ボタンをクリックし、新しいウェブ・アプリケーションを作成します。
以下の項目を設定します。
「名前」にエンドポイントのパスを指定します。例では、/wfsample としています。(/ を先頭につけ忘れないようにしてください)
「ネームスペース」にクラス定義をインポートしたネームスペースを指定します。例では、USER を選択しています。
「REST」の「ディスパッチ・クラス」にインポートしたクラス名を指定します。例では、isc.wf.REST を指定しています。
セキュリティの設定の「許可された認証方法」を「パスワード」のみに変更します。
ワークフローユーザ名でログインが必要となりますので、パスワードのみにします。
設定が完了したら、画面上にある保存ボタンをクリックします。
保存後表示される「アプリケーション・ロール」タブを選択し、このパスを通過できたときに付与されるロールを設定します。
適切なロールを事前に作成し追加するほうが適切ですが、以下の例では事前定義ロールの%Allを指定する例でご紹介します。
「利用可能」から %Allを選択
▶アイコンを利用して%Allを「選択済み」に移動
「付与する」ボタンクリック
これで準備完了です。早速RESTでアクセスしてみます。
ワークフロータスクが0件の場合は、サンプルデータを更新しタスクを作成してください。
手順については「システム連携の自動的な流れの中にユーザからの指示を介入できる「ワークフローコンポーネント」のサンプル」の「5.メモ」をご参照ください。
(例では、RESTクライアントにPostmanを使用しています。)
タスク一覧を取得:GET
http://ウェブサーバ/エンドポイント/tasks で取得できます。(ワークフローユーザを利用してBasic認証でアクセスします。パスワードは設定されたパスワードをご利用ください。)
例)http://localhost:52773/wfsample/tasks
タスク一覧のJSONオブジェクトの中に、idプロパティがあります。このidの値を利用して、1件のタスク詳細をGETできます。
1件のタスク詳細取得:GET
http://ウェブサーバ/エンドポイント/task/id で取得できます。(ワークフローユーザを利用してBasic認証でアクセスします。パスワードは設定されたパスワードをご利用ください。)
例)http://localhost:52773/wfsample/task/8||ManagerA
1件のタスクを処理する:POST
http://ウェブサーバ/エンドポイント/task/id をPOST要求で実行します。(ワークフローユーザを利用してBasic認証でアクセスします。パスワードは設定されたパスワードをご利用ください。)
例)http://localhost:52773/wfsample/task/8||ManagerA
特定した1件のタスクを処理します。今回の例では、承認か却下のボタンを押すことができるので、承認のボタンを押すアクションを実施します。
POST時に送付するJSONは以下の通りです。
{
"action": "承認",
"formFields": {
"RejectedReason": ""
}
}
action にボタン名を指定します。
formFields.RejectedReasonには「却下理由」を指定します。「承認」の時は空を設定し渡します。
この時のトレースは以下の通りです。
「承認」の情報が渡されています。
では次に、却下を試します。
別のタスクIDを利用して、却下理由(RejectedReason)も含めてPOSTします。
トレースを確認します。
「却下」の情報が渡されていることと「却下理由」も渡されていることを確認できます。
REST APIでワークフロー用データにアクセスできれば、IRIS付属のユーザポータルではなくお好みのWebアプリケーションをユーザポータルとして利用することもできます。
システム連携の流れの中にユーザからの指示を含めたい処理がある!!という場合には、ぜひこのワークフローコンポーネントをご利用ください😀
記事
Shintaro Kaminaka · 2020年8月12日
最初の記事では、RESTForms(永続クラス用のREST API)について説明をしました。 基本的な機能についてはすでに説明しましたが、ここではクエリ機能を中心とする高度な機能について説明します。
* 基本クエリ
* クエリ引数
* カスタムクエリ
### クエリ
クエリを使用すると、任意の条件に基づいてデータの一部を取得できます。 RESTFormsには、2種類のクエリがあります。
* 基本クエリは一度定義すればすべてのRESTFormsクラスに対して機能します。異なっているのはフィールドリストのみです。
* カスタムクエリはそれが指定され、使用できるクラスに対してのみ機能しますが、開発者はクエリの本文に完全にアクセスできます。
### 基本クエリ
一度定義すると、すべてのクラスか一部のクラスですぐに使用できます。 基本クエリはシステムによって定義されているものもありますが、開発者が追加することもできます。これらのクエリはすべて、SELECTのフィールドリストのみを定義します。 その他すべて(絞り込み、ページネーションなど)はRESTFormsによって行われます。 form/objects/:class/:query を呼び出すと、単純なクエリを実行できます。 2番目の :query パラメーターはクエリ名(クエリの SELECT と FROM の間の内容)を定義します。
デフォルトのクエリタイプは次のとおりです。
|クエリ|説明|
|------------|-------------------------|
|all|すべての情報|
|info|displayName と id|
|infoclass|displayName、id、class|
|count|行数|
例えば、Form.Test.Personオブジェクトに関する基本的な情報を取得するには、infoclassクエリを実行できます。 form/objects/Form.Test.Person/infoclass
{"children": [
{"_id":"1", "displayName":"Alice", "_class":"Form.Test.Person"},
{"_id":"2", "displayName":"Charlie", "_class":"Form.Test.Person"},
{"_id":"3", "displayName":"William", "_class":"Form.Test.Person"}
]}
RESTFormsは次の場所で myq という名前のクエリを探します(最初にヒットするまで)。
1. フォームクラス内のqueryMYQクラスメソッド
2. クエリクラス内のMYQパラメーター
3. クエリクラス内のqueryMYQクラスメソッド
4. Form.REST.Objectsクラス内のMYQパラメーター
5. Form.REST.Objectsクラス内のqueryMYQクラスメソッド
独自のクエリクラスを定義できます(上記リストの項目2、3用)。このクエリクラスは、すべてのクラスで使用可能なクエリの定義を保持する特別なクラスです。
そのクラスで myq という名前の独自クエリを定義する手順は以下のとおりです。
1. (1回だけ)YourClassName クラスを定義します。
2. そのクラスで MYQ パラメーターか queryMYQ クラスメソッドを定義します。 パラメーターはメソッドよりも優先されます。
3. メソッドまたはパラメーターは、SQLクエリのSELECTとFROMの間の部分を返す必要があります。
4. (1回だけ)ターミナルで以下を実行します。
Do ##class(For.Settings).setSetting("queryclass", YourClassName)
メソッドの署名は以下のとおりです。
ClassMethod queryMYQ(class As %String) As %String
クラス固有のクエリを定義することもできます。 myq という名前の独自クラスクエリを定義する手順は以下のとおりです。
1. フォームクラスで queryMYQ クラスメソッドを定義します。
2. メソッドの署名は以下のとおりです。ClassMethod queryMYQ() As %String
3. メソッドは、SQLクエリのSELECTとFROMの間の部分を返す必要があります。
URL 引数
フィルターやその他のパラメーターをURLで指定できます。 すべての引数は省略可能です。
| 引数 | サンプル値 | 説明 |
| ------------ | ------------------- | ----------------------------------------- |
| size | 2 | ページサイズ |
| page | 1 | ページ番号 |
| filter | 値+contains+W | WHERE句 |
| orderby | 値+desc | ORDER BY句 |
| collation | UPPER | COLLATION句 |
| nocount | 1 | レコード数を削除(クエリを高速化します)|
これらの引数に関するいくつかの情報を次に示します。
### ORDER BY句
結果の順序を変更します。 値は、カラム名またはカラム名+desc です。 カラム名は、SQLテーブルのカラム名またはカラム番号です。
### WHERE句
絞り込み条件の書式は、カラム名+条件+値です。
カラム名+条件+値+カラム名2+条件2+値2のように、複数の条件を指定できます。
矢印構文とシリアルオブジェクトもサポートされています: Column_ColumnField+条件+値
Valueに空白が含まれている場合、サーバーに送信する前にタブに置き換えます。
| URL | SQL |
| ---------------------- | -------------- |
| neq | != |
| eq | = |
| gte | >= |
| gt | > |
| lte | <= |
| lt | < |
| startswith | %STARTSWITH |
| contains | [ |
| doesnotcontain | '[ |
| in | IN |
| like | LIKE |
リクエストの例:
form/objects/Form.Test.Simple/info?size=2&page=1&orderby=text
form/objects/Form.Test.Simple/all?orderby=text+desc
form/objects/Form.Test.Simple/all?filter=text+eq+Hello
form/objects/Form.Test.Person/infoclass?filter=company_name+contains+a
form/objects/Form.Test.Simple/all?filter=text+in+A9044~B5920
SQLアクセスには、ユーザーに適切なSQL権限(フォームテーブルに対するSELECT)を付与する必要があることに注意してください。
### COLLATION句
書式は、collation=UPPER または collation=EXACT です。 指定した照合順序をWHERE句で強制します。 省略した場合、デフォルトの照合順序が使用されます。
### ページネーション
ページネーションは、デフォルトで1ページあたり25レコードになります。 ページサイズと現在のページを変更するには、size 引数と page 引数を(1を基準として)指定します。
### カスタムクエリ
form/objects/:class/custom/:query を呼び出すと、カスタムクエリを実行できます。 カスタムクエリを使用すると、開発者はクエリの内容全体を決めることができます。 size および page 以外のURLパラメーターは指定できません。 メソッドは他のすべてのURLパラメーターを解析する必要があります(またはForm.JSON.SQLからデフォルトのパーサーを呼び出す必要があります)。
myq という名前のカスタムクエリを定義する手順は以下のとおりです。
1. フォームクラスで customqueryMYQ クラスメソッドを定義します。
2. メソッドの署名は以下のとおりです。ClassMethod customqueryMYQ() As %String
3. メソッドは有効なSQLクエリを返す必要があります。
### デモ
[現在デモ環境はお試しいただくことができません。]
こちらでRESTFormsをオンラインで試すことができます(ユーザー名:Demo、パスワード:Demo)。
また、RESTFormsUIアプリケーション(RESTFormsデータエディタ)もあります。こちらをご確認ください(ユーザー名:Demo、パスワード:Demo)。 クラスリストのスクリーンショットを以下に掲載しています。
### まとめ
RESTFormsは、幅広くカスタマイズ可能なクエリ機能を提供します。
### 次の内容
次の記事では、いくつかの高度な機能について説明します。
* メタデータの解釈
* セキュリティと権限
* オブジェクト名
### リンク
* [RESTForms GitHubリポジトリ](https://github.com/intersystems-ru/RESTForms/)
RESTForms UI GitHubリポジトリ
記事
Mihoko Iijima · 2022年10月23日
FHIR開発者の皆さん、こんにちは!
IRIS の FHIR リポジトリは、HL7 FHIR 標準プロファイルに対する検証をサポートしていますが、カスタムプロファイルに対する検証は、まだサポートできていません(将来のリリースバージョンで対応予定です)。
カスタムプロファイルの Search Parameter の追加はサポートしています!詳しくは、「動画:FHIR プロファイル」をご参照ください。
この記事では、IRIS の FHIR リポジトリに対して、カスタムプロファイルの検証を行う方法についてご紹介します。
方法としては、HL7 FHIR が提供している FHIR Validator で提供しているJARファイル(validator_cli.jar)を利用します。
利用のためには、FHIR リソースの検証のタイミングで、JARファイルの検証を実行するようにFHIRサーバサイドの動作をカスタマイズする必要があります。
ということで、大まかな準備は以下の通りです。
1) Java用外部サーバ(External Language Servers)の開始
IRISから FHIR Validator で提供しているJARファイル(validator_cli.jar)を利用するため、Java用外部サーバを開始します。
2) 検証ロジックを加工する
FHIRリポジトリのデフォルトの動作を変更するため、FHIRサーバーサイドのカスタマイズクラス群を用意します(サンプルをご提供しています)。
イメージは以下の通りです。
今回は、FHIRリソースの検証を外部のJARファイルで行うため、FHIRサーバーサイドの加工(絵の青い破線の部分)を行いますが、この他にも、
「このリソースに〇〇というデータがあるときは登録させたくない」
「このリソースに△△のデータが含まれているときは応答として返したくない」
や、
患者さんのお名前を匿名化したい!
のような実装を行う場合も、同様に、カスタマイズクラス群を作成します。
この記事では、外部の検証機能を使用するようにカスタマイズする流れをご紹介しますが、その他のカスタマイズ内容詳細については、以下記事をご参照ください。
FHIRリポジトリをカスタマイズしよう!パート1
「このリソースに〇〇というデータがあるときは登録させたくない」や「このリソースに△△のデータが含まれているときは応答として返したくない」のカスタマイズ例を紹介しています。
FHIRリポジトリをカスタマイズしよう!パート2(カスタムOperation編)
患者さんのお名前を匿名化するカスタムオペレーションの作成例を紹介しています。
デモをご覧いただく場合は、こちらのビデオをご覧ください。
それでは、具体的な手順をご紹介します。サンプルはこちら👉 https://github.com/Intersystems-jp/FHIRValidation-Test
事前準備:最初に、FHIR ValidatorのJARを利用して検証のテストを行います。
[1] JARのダウンロード
validator_cli.jar を https://github.com/hapifhir/org.hl7.fhir.core/releases/latest/download/validator_cli.jar からダウンロードします。
サンプル一式をgit cloneまたはダウンロードいただいた場合は、lib にJARを配置してください。
もちろん、任意ディレクトリに配置することもできますが、JARの呼び出しをまとめたJavaサンプルコードのコンパイルなどを簡単に行っていただくため、compile.bat/compile.sh をご用意しています。
この bat/sh の中でJARの場所を指定してるので、サンプルをそのままご利用いただく場合は、lib 以下に配置してください。
[2] JDKのバージョンの確認
JDKのバージョンについては、https://confluence.hl7.org/pages/viewpage.action?pageId=35718580#UsingtheFHIRValidator-JDKVersionをご確認ください。
例では、OpenJDK11をインストールして利用しています。IRISがサポートするJDKについては、こちらをご参照ください。(8と11をサポートしています)
[3]-1 JARの呼び出しをまとめたJavaファイルの準備(Windows)
1. 事前準備
環境変数 JAVA_HOMEにJavaインストールディレクトリを設定します。
2. JavaValidatorFacade.java をコンパイルする
.\compile.bat
3. Jarファイルを作る
.\updateJar.bat
[3]-2 JARの呼び出しをまとめたJavaファイルの準備(Linux)
1. JavaValidatorFacade.java をコンパイルする
./compile.sh
2. Jarファイルを作る
./updateJar.sh
[4]検証のテスト
検証初回実行時、標準プロファイルのパッケージがない場合、https://confluence.hl7.org/display/FHIR/FHIR+Package+Cache からスキーマをダウンロードするため初回のみ時間がかかります。
Windows の場合、以下ディレクトリに保存されます(通常のユーザの場合)。
C:\Users<username>.fhir
Linuxの場合、以下ディレクトリに保存されます。
~/.fhir
サンプルファイル(test_Patient.json)を利用してテストを行います。
実行例).\run.bat または ./run.sh <プロファイルのJSONがあるディレクトリ> <テストするリソースのJSON>
《メモ》run.bat/run.sh の第1引数はカスタムプロファイル用ファイルを配置する予定のディレクトリを指定します(空でも実行できます)。例では、fhirprofileを指定しています。
以下、Windowsでの実行例です(WindowsとLinuxとで出力内容に違いはありません。)。
1つのワーニングが出ていますが、Success と返ります。
(ワーニングの理由:meta.profileに指定しているURLが実在しないため)
PS C:\WorkSpace\FHIRValidation-Test> .\run.bat C:\WorkSpace\FHIRValidation-Test\fhirprofile\ C:\WorkSpace\FHIRValidation-Test\sample\test_Patient.json
C:\WorkSpace\FHIRValidation-Test>"C:\Program Files\jdk-11\bin\java" -cp lib\validator_cli.jar;lib\JavaValidatorFacade.jar ISJSample.JavaValidatorFacade C:\WorkSpace\FHIRValidation-Test\fhirprofile\ C:\WorkSpace\FHIRValidation-Test\sample\test_Patient.json
Load hl7.terminology.r4#4.0.0 - 4164 resources (00:04.784)
Load C:\WorkSpace\FHIRValidation-Test\fhirprofile - 0 resources (00:00.005)
Validate C:\WorkSpace\FHIRValidation-Test\sample\test_Patient.json
Validate Patient against http://hl7.org/fhir/StructureDefinition/Patient..........20..........40..........60..........80.........|
00:00.485
Success: 0 errors, 1 warnings, 1 notes
{
"resourceType" : "OperationOutcome",
"text" : {
"status" : "extensions",
"div" : "<div xmlns=\"http://www.w3.org/1999/xhtml\"><table class=\"grid\"><tr><td><b>Severity</b></td><td><b>Location</b></td><td><b>Code</b></td><td><b>Details</b></td><td><b>Diagnostics</b></td><td><b>Source</b></td></tr><tr><td>INFORMATION</td><td/><td>Structural Issue</td><td>Canonical URL 'http://intersystems.com/fhir/ISJSample/StructureDefinition/JP_Patient' does not resolve</td><td/><td>No display for Extension</td></tr><tr><td>WARNING</td><td/><td>Structural Issue</td><td>Profile reference 'http://intersystems.com/fhir/ISJSample/StructureDefinition/JP_Patient' has not been checked because it is unknown, and the validator is set to not fetch unknown profiles</td><td/><td>No display for Extension</td></tr></table></div>"
},
"extension" : [{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-file",
"valueString" : "C:\\WorkSpace\\FHIRValidation-Test\\sample\\test_Patient.json"
}],
"issue" : [{
"extension" : [{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-issue-line",
"valueInteger" : 6
},
{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-issue-col",
"valueInteger" : 8
},
{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-issue-source",
"valueCode" : "InstanceValidator"
},
{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-message-id",
"valueCode" : "TYPE_SPECIFIC_CHECKS_DT_CANONICAL_RESOLVE"
}],
"severity" : "information",
"code" : "structure",
"details" : {
"text" : "Canonical URL 'http://intersystems.com/fhir/ISJSample/StructureDefinition/JP_Patient' does not resolve"
},
"expression" : ["Patient.meta.profile[0]"]
},
{
"extension" : [{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-issue-line",
"valueInteger" : 1
},
{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-issue-col",
"valueInteger" : 2
},
{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-issue-source",
"valueCode" : "InstanceValidator"
},
{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-message-id",
"valueCode" : "VALIDATION_VAL_PROFILE_UNKNOWN_NOT_POLICY"
}],
"severity" : "warning",
"code" : "structure",
"details" : {
"text" : "Profile reference 'http://intersystems.com/fhir/ISJSample/StructureDefinition/JP_Patient' has not been checked because it is unknown, and the validator is set to not fetch unknown profiles"
},
"expression" : ["Patient.meta.profile[0]"]
}]
}
続いて、test_Patient.json 15行目の gender に不正な値(例では"Man")を設定し、検証エラーが発生するか確認します。
今度は FAILUREと表示されます。(先ほどと同じワーニングに対するメッセージは省いています。)
PS C:\WorkSpace\FHIRValidation-Test> .\run.bat C:\WorkSpace\FHIRValidation-Test\fhirprofile\ C:\WorkSpace\FHIRValidation-Test\sample\test_Patient.json
C:\WorkSpace\FHIRValidation-Test>"C:\Program Files\jdk-11\bin\java" -cp lib\validator_cli.jar;lib\JavaValidatorFacade.jar ISJSample.JavaValidatorFacade C:\WorkSpace\FHIRValidation-Test\fhirprofile\ C:\WorkSpace\FHIRValidation-Test\sample\test_Patient.json
Load C:\WorkSpace\FHIRValidation-Test\fhirprofile2 - 0 resources (00:00.004)
Validate C:\WorkSpace\FHIRValidation-Test\sample\test_Patient.json
Validate Patient against http://hl7.org/fhir/StructureDefinition/Patient..........20..........40..........60..........80.........|
00:00.428
*FAILURE*: 1 errors, 1 warnings, 1 notes
{
"resourceType" : "OperationOutcome",
"text" : {
"status" : "extensions",
"div" : "<div xmlns=\"http://www.w3.org/1999/xhtml\"><table class=\"grid\"><tr><td><b>Severity</b></td><td><b>Location</b></td><td><b>Code</b></td><td><b>Details</b></td><td><b>Diagnostics</b></td><td><b>Source</b></td></tr><tr><td>ERROR</td><td/><td>Invalid Code</td><td>The value provided ('man') is not in the value set 'AdministrativeGender' (http://hl7.org/fhir/ValueSet/administrative-gender|4.0.1), and a code is required from this value set) (error message = Unknown Code http://hl7.org/fhir/administrative-gender#man in http://hl7.org/fhir/administrative-gender)</td><td/><td>No display for Extension</td></tr><tr><td>INFORMATION</td><td/><td>Structural Issue</td><td>Canonical URL 'http://intersystems.com/fhir/ISJSample/StructureDefinition/JP_Patient' does not resolve</td><td/><td>No display for Extension</td></tr><tr><td>WARNING</td><td/><td>Structural Issue</td><td>Profile reference 'http://intersystems.com/fhir/ISJSample/StructureDefinition/JP_Patient' has not been checked because it is unknown, and the validator is set to not fetch unknown profiles</td><td/><td>No display for Extension</td></tr></table></div>"
},
"extension" : [{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-file",
"valueString" : "C:\\WorkSpace\\FHIRValidation-Test\\sample\\test_Patient.json"
}],
"issue" : [{
"extension" : [{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-issue-line",
"valueInteger" : 15
},
{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-issue-col",
"valueInteger" : 21
},
{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-issue-source",
"valueCode" : "TerminologyEngine"
},
{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-message-id",
"valueCode" : "Terminology_TX_NoValid_16"
}],
"severity" : "error",
"code" : "code-invalid",
"details" : {
"text" : "The value provided ('man') is not in the value set 'AdministrativeGender' (http://hl7.org/fhir/ValueSet/administrative-gender|4.0.1), and a code is required from this value set) (error message = Unknown Code http://hl7.org/fhir/administrative-gender#man in http://hl7.org/fhir/administrative-gender)"
},
"expression" : ["Patient.gender"]
},
ここまでで、 FHIR Validator から提供されているJARを利用した検証のテストは完了です。
ここからは、IRIS の FHIRサーバーサイドのカスタマイズを行っていきます。
<カスタマイズ概要>
1) Java用外部サーバ(External Language Servers)の開始
2) 検証ロジックを加工する
まずは、1) Java用外部サーバ(External Language Servers)の開始 を行うための手順をご紹介します。
[5] ISJSample.JavaValidatorFacade クラスを実行するためJava用外部サーバを起動
実行環境に合わせて設定を追加します。
管理ポータル > システム管理 > 構成 > 接続性 > External Lanaugae Server > %Java Server
設定項目
値
クラスパス
validator_cli.jarとJavaValidatorFacade.jarのパス
Java Home Directory
Javaのインストールディレクトリ
(図例はWindowsでの例です)
設定が終わったら start のリンクをクリックします。以下のようなログが表示されます。
Start External Language Server %Java Server:
お待ちください...結果が以下に表示されます:
2022-10-07 19:48:59 Starting Java Gateway Server '%Java Server'
2022-10-07 19:48:59 Executing O.S. command: C:\Program Files\jdk-11\bin\java.exe -Xrs -Djava.system.class.loader=com.intersystems.gateway.ClassLoader -classpath C:\WorkSpace\FHIRValidation-Test\lib\validator_cli.jar;C:\WorkSpace\FHIRValidation-Test\lib\JavaValidatorFacade.jar;C:\InterSystems\IRISHealth\dev\java\lib\1.8\intersystems-jdbc-3.3.1.jar com.intersystems.gateway.JavaGateway 53272 "" "JP7430MIIJIMA:IRISHEALTH:%Java Server" 127.0.0.1 ""
2022-10-07 19:49:10 Execution returned: ''
2022-10-07 19:49:10 Gateway Server start-up confirmation skipped
2022-10-07 19:49:10 Starting background process to monitor the Gateway Server
2022-10-07 19:49:10 Job command successful, started monitor process '26376'
ここからは、2) 検証ロジックを加工する を行うための手順をご紹介します。
[6]FHIRリポジトリのカスタマイズ用クラスの準備
以下説明は、IRIS for Health 2022.1を利用した例で記載しています。
詳細はドキュメント:FHIRサーバのカスタマイズ もご参照ください。
!!FHIRリポジトリを作成する前に、ネームスペースにカスタマイズ用クラス群を準備する必要があります!!
サンプルでは、以下の説明に登場するクラス群をISJSample以下に用意しています。インポート方法は 「5.インポート」をご参照ください。
1. クラス一覧
それぞれのクラスの関係は以下のイメージです。
2.作成したクラスにパラメータを設定
最初から作成される場合は、以下のクラスパラメータを設定してください。サンプルをそのままご利用いただく場合は修正不要です。
1で作成したクラスにパラメータを設定します。
ISJSample.FHIRValidationInteractions クラス
ResourceValidatorClassに検証実行用カスタムクラス名(ISJSample.FHIRResourceValidator)を指定
BatchHandlerClassにBundleのtype=batchまたはtransactionを処理するカスタムクラス名(ISJSample.FHIRBundleProcessor)を指定
ISJSample.FHIRValidationInteractionsStrategy クラス
StrategyKeyにInteractionsStrategyの一意の識別子を指定
InteractionsClassにInteractionsのカスタムクラス名(ISJSample.FHIRValidationInteractions)を指定
ISJSample.FHIRBundleProcessor クラス
BundleValidatorClassにBundle検証用カスタムクラス名(ISJSample.FHIRBundleValidator)を指定
ISJSample.FHIRValidationRepoManager クラス
StrategyClassに InteractionStrategyのカスタムクラス名(ISJSample.FHIRValidationInteractionsStrategy)を指定
StrategyKeyにInteratcionsStrategyで指定したStrategyKeyの値を指定
《補足》
この他、ISJSample.FHIRValidationInteractionsクラスとISJSample.FHIRResourceValidatorクラスでメソッドをオーバーライドしています。
ISJSample.FHIRValidationInteractionsクラスでは、Bundleに含まれるリソースに対して検証が2回呼び出されないように StartTransactionBundle()メソッドとEndTransactionBundle()メソッドのオーバーライドしています。 %inTransactionFlag変数の設定を追加
Method StartTransactionBundle(pBundleTransactionId As %Integer)
{
do ##super(pBundleTransactionId)
set %inTransactionFlag=$$$YES
}
Method EndTransactionBundle()
{
kill %inTransactionFlag
do ##super()
}
ISJSample.FHIRResourceValidatorクラスでは、ValidateResource()をオーバーライドしています。 %inTransactionFlgが$$$YES ではないとき、検証を実行するように変更
Method ValidateResource(pResourceObject As %DynamicObject)
{
//do ##super(pResourceObject)
if $get(%inTransactionFlag,$$$NO)'=$$$YES {
do ##class(ISJSample.FHIRValidation).validate(pResourceObject)
}
}
ISJSample.FHIRBundleValidator クラスでは、スーパークラスのValidateBundle()をオーバーライドし、ISJSample.FHIRValidationクラスのvalidate()を呼び出しています。
ClassMethod ValidateBundle(pResourceObject As %Library.DynamicObject, pFHIRVersion As %String)
{
//do ##super(pResourceObject,pFHIRVersion)
do ##class(ISJSample.FHIRValidation).validate(pResourceObject)
}
3. カスタム検証用クラス(ISJSample.FHIRResourceValidator)の修正
最初から作成される場合は、以下のクラスパラメータを設定してください。サンプルをそのままご利用いただく場合は修正不要です。
スーパークラスのValidateResource()をオーバーライドし、ISJSample.FHIRValidationクラスのvalidate()を呼びしています。
4.カスタム検証用クラスが使用するパラメータ値の設定
管理ポータル > Health > 作成したネームスペース > Configuration Registry に移動し、以下のKeyとValueを設定します。
項目名(Key)
設定例(Value)
意味
/FHIR/Validation/SkipIfNoProfile
1
設定値 1:検証をスキップする(リソースのmeta.profileの値が空や設定されていない場合に、検証をスキップする設定です。)
設定値 0:検証をスキップしない
/FHIR/Validation/JavaGatewayServer
127.0.0.1
Java用外部サーバのIPアドレスまたはサーバ名
/FHIR/Validation/JavaGatewayPort
53272
Java用外部サーバが使用するポート番号
/FHIR/Validation/ProfileLocation
C:\WorkSpace\FHIRValidation-Test\fhirprofile
カスタムプロファイルのディレクトリを指定(フルパス)
/FHIR/Validation/TerminologyServer
(設定なし)
TerminologyサーバのURLを指定
5.サンプルクラスのインポート
VSCodeをお使いの方は、対象ネームスペースに接続後、ISJSampleディレクトリ を右クリックし[Import and Compile]をクリックします(または、クラス定義を Ctrl + S で保存することでインポートできます)。
スタジオをお使いの方は、対象ネームスペースに接続し、ISJSampleディレクトリ 以下 *.clsを複数選択し、スタジオのエリアにドラッグ&ドロップすることでインポートできます。
管理ポータルからインポートする場合は、管理ポータル > システムエクスプローラー > クラス > 対象ネームスペース選択 > [インポート]ボタンクリック で表示されるインポート画面でISJSampleディレクトリ を選択し、インポートを実行します。 詳細は図例をご参照ください。
[7]FHIRリポジトリの作成
InteratcionsStrategyクラスのカスタムクラスがコンパイル済であることを確認し、以下GUIで作成します。
管理ポータル > Health > 作成したネームスペース > FHIR Configuration > Server Configuration > Add Endpoint
!!Interactions sterategy classに作成したクラス名: ISJSample.FHIRValidationInteractionsStrategyを指定してからリポジトリを作成して下さい!!
リポジトリ作成後、デバッグモードから認証なし設定します(Debuggingの「Allow Unauthenticated Access」にチェック)
[8]テスト実行
Postmanで以下実行します。
通常のPOSTでテストしてもいいのですが、何度も同じリソースを使って検証のテストを行うような場合には、リソースの検証だけを行う $validate オペレーションの利用が便利です。
例では、URL末尾に /$validate をつけています。この指定があるだけとリソースの検証のみを行うことができます(/$validate をなくして実行すると通常のPOST要求の流れで検証が行われます)。
設定項目
値
URL
<エンドポイント>/Patient/$validate
Method
POST
Header
Content-Type に application/json+fhir;charset=utf-8
Body
PatientリソースのJSON
結果は以下の通りです。
{
"resourceType": "OperationOutcome",
"issue": [
{
"severity": "information",
"code": "informational",
"diagnostics": "All OK",
"details": {
"text": "All OK"
}
}
]
}
Bundleの場合は以下の通りです。
設定項目
値
URL
<エンドポイント>/Bundle/$validate
Method
POST
Header
Content-Type に application/json+fhir;charset=utf-8
Body
Bundle用JSON
ここまでで、手続きは完了です。
次は、いよいよ、カスタムプロファイルの検証を実行してみます!
[9]JPCoreのプロファイルを適用する方法
1.JPCoreのアーティファクトを用意する
公開されているJPCoreのプロファイル FHIR JP Core 実装ガイドパッケージをダウンロードされるか、公式Git を clone して、SUSHIを利用してImplementation Guide(IG)などのJSONのファイル群(アーティファクト)を作成する方法があります。
参照元:HL7FHIR JP Core実装ガイド<Draft Ver.1>の公開について(ご案内)
以下例は、2022年10月24日にダウンロードしたFHIR JP Core 実装ガイド V1.1.0 のパッケージを利用して記述しています。
※2022年11月5日にダウンロードした v1.1.1のパッケージでも以下の例が動作することを確認しています。
2. 1.で用意したアーティファクトをプロファイル配置用ディレクトリにコピーして検証を実行する
テストする場合は、run.bat または run.sh の第1引数にアーティファクトがあるディレクトリを指定します。
例では、 FHIR JP Core 実装ガイド にある V1.1のtgz版をダウンロードして展開したディレクトリにあるJSONファイルを fhirprofile以下にコピーした状態で実行しています。
以下、Windowsでの実行例です(WindowsとLinuxとで出力内容に違いはありません。)。
PS C:\WorkSpace\FHIRValidation-Test> .\run.bat C:\WorkSpace\FHIRValidation-Test\fhirprofile C:\WorkSpace\FHIRValidation-Test\sample\test_Patient-JPCore.json
C:\WorkSpace\FHIRValidation-Test>"C:\Program Files\jdk-11\bin\java" -cp lib\validator_cli.jar;lib\JavaValidatorFacade.jar ISJSample.JavaValidatorFacade C:\WorkSpace\FHIRValidation-Test\fhirprofile C:\WorkSpace\FHIRValidation-Test\sample\test_Patient-JPCore.json
Load hl7.terminology.r4#4.0.0 - 4164 resources (00:04.947)
Load C:\WorkSpace\FHIRValidation-Test\fhirprofile - 241 resources (00:00.465)
Unable to generate snapshot for http://jpfhir.jp/fhir/core/StructureDefinition/JP_MedicationRequest: Attempt to use a snapshot on profile 'http://jpfhir.jp/fhir/core/StructureDefinition/JP_MedicationRequestBase' as Base for generating a snapshot for the profile http://jpfhir.jp/fhir/core/StructureDefinition/JP_MedicationRequest before it is generated
Unable to generate snapshot for http://jpfhir.jp/fhir/core/StructureDefinition/JP_MedicationRequest_Injection: Attempt to use a snapshot on profile 'http://jpfhir.jp/fhir/core/StructureDefinition/JP_MedicationRequestBase' as Base for generating a snapshot for the profile http://jpfhir.jp/fhir/core/StructureDefinition/JP_MedicationRequest_Injection before it is generated
Unable to generate snapshot for http://jpfhir.jp/fhir/core/StructureDefinition/JP_MedicationRequest: Profile JP_MedicationRequest (http://jpfhir.jp/fhir/core/StructureDefinition/JP_MedicationRequest), element null. Error generating snapshot: Error sorting Differential: The element MedicationRequest.dosageInstruction is out of order (and maybe others after it)
Unable to generate snapshot for http://jpfhir.jp/fhir/core/StructureDefinition/JP_MedicationRequest_Injection: Profile JP_MedicationRequest_Injection (http://jpfhir.jp/fhir/core/StructureDefinition/JP_MedicationRequest_Injection), element null. Error generating snapshot: Error sorting Differential: The element MedicationRequest.dosageInstruction is out of order (and maybe others after it)
Validate C:\WorkSpace\FHIRValidation-Test\sample\test_Patient-JPCore.json
Validate Patient against http://hl7.org/fhir/StructureDefinition/Patient..........20..........40..........60..........80.........|
Validate Patient against http://jpfhir.jp/fhir/core/StructureDefinition/JP_Patient..........20..........40..........60..........80..........100|
00:00.641
Success: 0 errors, 0 warnings, 1 notes
{
"resourceType" : "OperationOutcome",
"text" : {
"status" : "extensions",
"div" : "<div xmlns=\"http://www.w3.org/1999/xhtml\"><p>All OK</p><table class=\"grid\"><tr><td><b>Severity</b></td><td><b>Location</b></td><td><b>Code</b></td><td><b>Details</b></td><td><b>Diagnostics</b></td></tr><tr><td>INFORMATION</td><td/><td>Informational Note</td><td>All OK</td><td/></tr></table></div>"
},
"extension" : [{
"url" : "http://hl7.org/fhir/StructureDefinition/operationoutcome-file",
"valueString" : "C:\\WorkSpace\\FHIRValidation-Test\\sample\\test_Patient-JPCore.json"
}],
"issue" : [{
"severity" : "information",
"code" : "informational",
"details" : {
"text" : "All OK"
}
}]
}
実行に指定しているtest_Patient-JPCore.jsonには、JPCoreが定義しているextension.Race(患者の人種)の情報が含まれます。
例)
"birthDate": "1970-01-01",
"extension":[
{
"url": "http://jpfhir.jp/fhir/core/Extension/StructureDefinition/JP_Patient_Race",
"valueCodeableConcept": {
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/v3-Race",
"code": "2039-6",
"display": "Japanese"
}
]
}
}
],
3. IRISから実行する。
実行前にカスタムプロファイルのアーティファクトがあるディレクトリが正確に設定されているか確認します。
IRISの管理ポータル > Health > ネームスペース選択 > Configuration Registry > /FHIR/Validation/ProfileLocation Valueを確認
《メモ》Configuration Registry の Key には、ISJSample.FHIRValidationクラスに定義されているパラメータ名を設定しています。
Value の取得は以下ユーティリティクラスのメソッドを実行することで取得できます。
##class(HS.Registry.Config).GetKeyValue(..#ProfileLocationKEY)
設定値が管理ポータルで変更できるので、プロファイルを参照する場所を変える場合は、/FHIR/Validation/ProfileLocation を変更するだけでOKです。
以下、Postmanからのテスト例です。
設定項目
値
URL
<エンドポイント>/Patient/$validate
Method
POST
Header
Content-Type に application/json+fhir;charset=utf-8
Body
JPCore対応用PatientリソースのJSON
検証がOKであることを確認したら、JPCoreのプロファイルを正しく認識しているかどうかテストするため、患者の人種(Race)の情報に誤ったデータタイプの情報を設定し検証します。
RaceのデータタイプはExtension(CodeableConcept)が指定されているため、valueCodeableConceptにCodeableConceptタイプの情報を持つ必要がありますが、以下の例では、valueStringにstringの情報を設定しています。
"extension":[
{
"url": "http://jpfhir.jp/fhir/core/Extension/StructureDefinition/JP_Patient_Race",
"valueString":"日本人"
}
],
以下、Postmanからのテスト例です。
設定項目
値
URL
<エンドポイント>/Patient/$validate
Method
POST
Header
Content-Type に application/json+fhir;charset=utf-8
Body
JPCore対応用PatientリソースのJSON:検証失敗用
例と同様に、JPCore V1.1のtgz版プロファイルを利用している場合のPatientリソース内タイプの確認については、https://jpfhir.jp/fhir/core/V1B/StructureDefinition-jp-patient.html をご参照ください。
RESTクライアントからの実行結果は以下の通りです。(CodeableConceptのタイプではなくstringの情報が来ていることでエラーが発生しています)
{
"resourceType": "OperationOutcome",
"issue": [
{
"severity": "error",
"code": "structure",
"diagnostics": "5001",
"details": {
"text": "This element does not match any known slice defined in the profile http://jpfhir.jp/fhir/core/Extension/StructureDefinition/JP_Patient_Race and slicing is CLOSED: Patient.extension[0].value.ofType(string): Does not match slice 'valueCodeableConcept' (discriminator: ($this is CodeableConcept))"
},
"expression": [
"Patient.extension[0].value.ofType(string)"
]
},
{
"severity": "error",
"code": "structure",
"diagnostics": "5001",
"details": {
"text": "The Extension 'http://jpfhir.jp/fhir/core/Extension/StructureDefinition/JP_Patient_Race' definition allows for the types [CodeableConcept] but found type string"
},
"expression": [
"Patient.extension[0]"
]
}
]
}
以上です!
最後までお読みいただきありがとうございました
今回の記事は、JP Coreのカスタムプロファイルの適用でご紹介しましたが、カスタムプロファイルの作成からコンパイルまでの手続きなどについては、以下の記事でご紹介しています。
FHIRプロファイル作成ツールであるSUSHIの握り方使い方を紹介している記事 👉 SUSHIを使ってFHIRプロファイルを作成しようパート1
Extensionの追加と、Extensionで追加した項目に対するSearchParameterの定義を行い、IRISのFHIRリポジトリに適用し、新しいSearchParameterが利用できるまでの流れをご紹介している記事 👉 SUSHIを使ってFHIRプロファイルを作成しようパート2
ぜひご覧ください!
記事
Toshihiko Minamoto · 2020年10月8日
Ansible は Caché とアプリケーションコンポーネントをいかに迅速にデータプラットフォームのベンチマークにデプロイするかという課題を解決するのに役立ちました。 同じツールと方法をテストラボ、トレーニングシステム、開発環境、またはその他の環境の立ち上げも使うことができます。 顧客サイトにアプリケーションをデプロイする場合、デプロイの大部分を自動化し、アプリケーションのベストプラクティス標準に合わせてシステム、Caché、アプリケーションを確実に構成することができます。
## 概要
テクノロジーアーキテクトである私たちのグループの仕事の一つに、さまざまなベンダーのハードウェアやオペレーティングシステムでの InterSystems データプラットフォームのベンチマークがあります。 多くの場合、インフラストラクチャはリリース前のものであり、返却や他者への引き渡しが必要になるまでの時間が決まっているため、ベンチマークを迅速かつ正確に設定し、実際のベンチマーク作業にできるだけ多くの時間をかけることが不可欠です。
私たちは長年にわたってシェルスクリプトレットとチートシートやチェックリストからのカットアンドペーストを使用し、多くのベンチマークインストール作業を自動化していましたが、多くのサーバーがあり、異なるオペレーティングシステムを使用する場合は特に非常に激しくエラーが発生する傾向がありました。SLES 11、Red Hat 6、Red Hat 7、AIX などでのサービスのインストールや使用には、微妙で厄介な違いがある場合があるからです。
私はシステムの自動構成と管理に使用できるいくつかのソフトウェアオプションを検討した後、データプラットフォームアプリケーションとベンチマークコンポーネントをプロビジョニングする作業のために Ansible を選択しました。 なお、Ansible がデプロイと構成に**最適な**ソリューションであると決めつけているわけではありませんのでご了承ください。 私は Ansible を選択する前に、Puppet や Chef などの他のツールの機能や操作を確認しました。 あなたの組織がすでに他のツールを使用しており、あなたがそれを使用できるのなら、私が Ansible で使用する方法やコマンドなどは他のソフトウェアに読み替えることができるはずです。この投稿が、使用しているツールに関係なく役立つことを願っています。
これは、InterSystems データプラットフォームのアプリケーションをデプロイする際に Ansible を使用する方法を説明する連載の最初の投稿です。 この投稿では、Caché をインストールして基盤を構築する方法について説明します。次の投稿では、ソリューションを拡張し、%installer クラスの使用を含むアプリケーションのインストールについて掲載します。 この記事では以下について説明します。
* Ansible の概要とインストール。
* 簡単な管理とスケーリングのための Ansible のレイアウト。
* 1つ以上のサーバーでの Caché のインストール。
## Ansible とは?
Ansible では複雑なタスクを自動化しながら1つ以上のサーバーを構成でき、新しいサーバーを非常に簡単に追加できます。 タスクは冪等性が保たれるように設計されています(同じサーバーで同じスクリプトを何度でも実行でき、結果のサーバー構成は同じになります)。
Ansible をプロビジョニングタスク用に選択した主な理由は、システム要件が最小(Linux サーバーに Python 2.7 がインストールされていること)であり、自己完結型のソリューションであることです。Ansible のコードは管理サーバーにのみインストールされ、プッシュアーキテクチャを使用して OpenSSH 経由でターゲットサーバー上のコマンドとスクリプトを実行します。 プロビジョニングされるサーバーにはエージェントは必要ありません。 対照的に、Chef と Puppet はプルクライアントアーキテクチャであり、クライアントサーバー(Web、データベースなど)にソフトウェアが読み込まれ、クライアントは継続的に更新をマスターにポーリングします。 Ansible のプッシュアーキテクチャは、スケジュールに応じてサーバーを段階的に実装するのにも適しています。
Ansible はオープンソースであり、コミュニティによってメンテナンスされています。 Ansible, Inc は 2015 年 から Red Hat が所有しています。 Ansible, Inc は付加価値の高いライフサイクル製品(Ansible Tower)と共に有償のサポートとトレーニングを提供していますが、この投稿で使用されているものはすべてオープンソースのコマンドラインバージョンです。 活発なコミュニティ(Ansible Galaxy)があり、Web サーバー、ftp、Kerbros のインストールなどの多数のタスク用にダウンロードできる既成のソリューションが豊富に存在し、拡充され続けています。 完全なベンチマークのデプロイプロジェクトの例に、RHEL、SLES、または Solaris に(他のプラットフォームと共に)Apache 2.x をインストールして構成するためにダウンロードしてカスタマイズした Apache モジュールを含めています。
Ansible のダウンロードとインストールの手順は、Ansible の Web サイトと github にあります。 質問がある場合や貢献したい場合は、活発なコミュニティがあります。
https://www.ansible.com/get-started
http://docs.ansible.com
## Ansible のインストール
この投稿の例は、Red Hat 7.0 および 7.2 が稼働中の VM でテストされています。また、Centos 7 を搭載した私のノートパソコンで VirtualBox と Vagrant を使用し、Ansible コントローラーサーバーの初期テストも行いました。 Caché をコントローラーにインストールする必要はないため、Caché でサポートされているよりも多くのプラットフォームからオペレーティングシステムを選択できます。 話を簡単にするため、私は Red Hat で利用可能な Ansible の最新 rpm バージョン(Ansible 1.9.4)を使用しました。それ以降のバージョンは github から入手できます。
この例では、cache-2015.2.2.805.0-lnxrhx64 をインストールしていますが、HealthShare または Ensemble ディストリビューションにも同じ一般的な手順を適用できます。 後述するように、特定のファイル名、ディレクトリパスなどの変数を使用してインストールオプションをパラメーター化します。
この最初の投稿ではタスクを基本的な Caché のインストールに限定しています。そのため、ほとんどのタスクはプラットフォームに依存しません。 Ansible プレイブックが開始する最初のタスクの 1 つは、ターゲットマシンのマニフェスト(オペレーティングシステム、インターフェースカード、メモリ情報、CPU 数、ディスクレイアウトなど)を取得することです。このターゲットオペレーティングシステムの情報は、ターゲットで実行される実際のコマンドから Ansible スクリプトのコマンドを抽象化するためにコマンドが実行される際に使用されます(Red Hat の service httpd on や SLES の /etc/init.d/apache2 など)。
ここでは皆さんがプラットフォームの説明に従い、説明を読んで管理マシンに Ansible をインストールしたと想定します。
Ansible では Linux システムをコントローラーとして使用する必要がありますが、ターゲットシステムは Linux または Windows にすることができます。 Windows ターゲットの詳細については、Ansible のドキュメントを参照してください。
### コントローラーシステムのインストール例:RHEL/CentOS 7 64ビット上の Ansible
Red Hat または CentOSでは、Ansible を含む epel-release(Enterprise Linux 用の追加パッケージ)RPM を先にインストールする必要があります。 epel プロジェクトは多くの有用なオープンソースパッケージ(ネットワーク、システム管理、監視など)をまとめて提供しており、主要な Linux ディストリビューション向けに設計されています。
[root@localhost tmp]# wget http://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-5.noarch.rpm
:
:
[root@localhost tmp]# rpm -ivh epel-release-7-5.noarch.rpm
:
:
[root@localhost tmp]# yum --enablerepo=epel info ansible
Loaded plugins: langpacks, product-id, search-disabled-repos, subscription-manager
Installed Packages
Name : ansible
Arch : noarch
Version : 1.9.4
Release : 1.el7
Size : 7.0 M
Repo : installed
From repo : epel
Summary : SSH-based configuration management, deployment, and task execution system
URL : http://ansible.com
License : GPLv3+
Description :
: Ansible is a radically simple model-driven configuration management,
: multi-node deployment, and remote task execution system. Ansible works
: over SSH and does not require any software or daemons to be installed
: on remote nodes. Extension modules can be written in any language and
: are transferred to managed machines automatically.
[root@localhost tmp]#
[root@localhost tmp]# sudo yum install ansible
:
:
[root@localhost tmp]# ansible --version
ansible 1.9.4
configured module search path = None
**成功しました。 始めましょう!**
## Ansible について
インベントリ、プレイブック、モジュール、ロールなどのさまざまな Ansible コンポーネントの使用方法を Ansible のドキュメントでよく確認する必要があります。
管理を単純化し、大規模で複雑なスクリプトファイルを回避するため、事前定義されたディレクトリ構造と検索パスが使用されています。 この投稿では Ansible の推奨事項を使用し、より大きなインストールの例を作ることを検討する際のモデルとして使用できるファイル構造を使用する予定です。
使用されている Ansible モジュールはコメントが付いた分かりやすいもので、github から入手できます。 ファイルをダウンロードして内容を読み、ワークフローの感触をつかんでください。
この例のベースディレクトリには、次のファイルがあります。
* ansible.cfg:Ansible のデフォルト値を変更します。
* inventory:作業環境を定義し、記述します (サーバー名/IPなど)。
* >任意の名前<.yml ファイル:これらのファイルは、特定のサーバーのロールに対して実行されるタスクセットを記述します。
### 用語集
今後の説明をより分かりやすくするため、いくつかの Ansible 用語について簡単に説明します。
モジュールは、システムで実行する自動化アクションを作成するビルディングブロックです。 各モジュールは特定のタスク用に構築されており、パラメーターを使用してそのタスクを変更できます。 例えば、ファイルのコピー、ユーザーの作成、コマンドの実行、サービスの開始などがあります。 現在、デフォルトの Ansible インストールには 400 種類以上のモジュールが含まれており、さらにはコミュニティからも多くのモジュールが提供されていますが、独自に作成することもできます。
モジュールは自動化ワークフローを実行する手段として、プレイとプレイブックを作成するために組み合わされます。 プレイは複数のタスクを持つことができ、プレイブックは複数のプレイを持つことができます。
ロールを使うと、複数のプレイブックを組み合わせることができます。 ロールは、ターゲットサーバーの使用状況に応じてサーバーのコンポーネント構成をグループ化するものと考えることができます。 この投稿のロールの例では、サーバーを構築するための構成レイヤーを構築します。
私のベンチマーク環境では、次のロールを使用してサーバーを構築しています。
* hs\_server\_common: OS の構成、Apache のインストール、Caché のインストール。
* webserver: Webファイル(csp、html、js など)のコピー、アプリケーション用のApacheの構成。
* generator: ファイルのコピー、Webストレスジェネレーターのデータベース / ネームスペース / グローバルマッピングなどの作成と構成。
* dbserver:ファイルのコピー、DBサーバーシステムの設定 / アプリケーションデータベース / ネームスペース / グローバルマッピングなどの構成。
これらのロールを組み合わせて、さまざまなサーバータイプを構築できます。
* hs\_server\_common + webserver + generator = Web ストレスジェネレーターサーバー。
* hs\_server\_common + webserver = アプリケーション Web サーバー。
* hs\_server\_common + dbsevrer = データベースサーバー。
ロールを構成するものや各ロールに含まれる構成は、デプロイされるアプリケーションによって大きく異なります。 この投稿の例では、オペレーティングシステムの事前構成を前提とする最小限のタスクセットを使用しますが、Ansible や Galaxy で利用可能なモジュールを使用すると、はるかに複雑なフル機能のシステム構成が可能になります。
## Caché のインストールに関するメモ {.MsoNormal}
私はいくつかの興味く便利な機能を紹介するため例を記載しましたが、その中でも以下は特に注目すべきものです。 注: これらの例は、InterSystems データプラットフォーム(Caché、HealthShare、Ensemble)をインストールするためのガイドとして使用できます。 HealthShare をインストールする例を書きましたが、HealthShare と Caché には同じ機能があります。
**./testserver/roles/hs\_server\_common/tasks/main.yml**
これは、一般的な OS の構成、Apache のインストール、Caché のインストールの各タスクに使えるメインラインスクリプトです。 この投稿ではCaché をインストールおよび構成するため、Red Hat のインクルードファイルのみに短縮しています。 Ansible が起動した後、オペレーティングシステムの情報がスクリプトで決定を行うために使用できる _ansible\_os\_family_ などの _ansible_* _変数に保持されていることがわかります。
**./testserver/roles/hs\_server\_common/tasks/configure-healthshare2015.yml**
これは、Caché をインストールするためのメインスクリプトです。 スクリプトを見ると、次のようなターゲット上のタスクの論理ワークフローがわかります。
* オペレーティングシステムのユーザーとグループを作成する。
* コントローラーのマニフェストフォルダーからインストールファイルをコピーする。
* インストールファイルを解凍する。
* サイレントインストールを使用して Caché をインストールする(以下の注意書きを参照)。
* Caché キーファイルをコピーする。
* デフォルト Caché インスタンスを設定する。
* Apache を再起動する。
* Caché を再起動する。
Caché のサイレントインストールには、次のようないくつかのオプションがあります。
* parameters.is ファイルを使用する。 テンプレートの .isc ファイルは以前のインストールによって作成されたもので、そのまま使用することも、変更して使用することもできます。
* 環境で設定されたキーと値のペアで cinstall_silent を使用する。
* %installer クラスを使用する。
この例では、install\_silent を使用することを選択しましたが、Ansible でテンプレートファイルを使用する方法を示すため、パラメーターファイルを使用する代替方法もコメントに含めています(./roles/hs\_server\_common/templates/parameters\_hs20152_rh64.isc を参照してください)。
後の投稿では、Caché をインストールする際とデータベースおよびネームスペースを設定する際に %installer クラスを使用する方法を説明します。 インストールオプションの詳細は、Caché のオンラインドキュメントで確認できます。また、コミュニティには %installer クラスの使用に関する素晴らしい投稿もあります。
パラメーターファイルは、旧バージョンの Caché で Caché 組み込みの Apache バージョン以外の Web サーバで CSP Gateway を使用するように Cachéをインストールして構成する場合に役立ちます。 この機能は、Caché 2016.1の %installer で使用できます。
**./testserver/roles/hs\_server\_common/tasks/setup_RedHat.yml**
この例は、システム固有の変数(ansible_*)の使用方法とオペレーティングシステム変数の設定を説明するためのものです。
**./testserver/roles/hs\_server\_common/vars/***
変数ファイルのキーと値のペアには変数が含まれています。ご覧のとおり、さまざまな環境や状況で同じスクリプトを再利用することができます。
## Caché インストールの実行
この例では、システムが使用可能であり、次のように設定されていることを想定しています。
1. コントローラーに Ansible がインストールされており、次のディレクトリに GitHub からファイルと構造が読み込まれていること。
* **./testserver/*** : インベントリ、.yml ファイルなどを含むディレクトリツリー。 次のディレクトリを含みます。
* **./testserver/Distribution_Files/Cache** : (Caché ディストリビューションと cache.key を含むマニフェスト)。
2. ターゲットマシンに Red Hat と Apache がインストールされていること。
テスト環境に合わせてインストールをカスタマイズするには、次のファイルを編集する必要があります。
1. **inventory_test**
テストサーバー名または IP アドレスを編集する必要があります。
2. **./testserver/roles/hs\_server\_common/vars/healthshare2015.yml**
テスト環境に合わせてパスを編集する必要があります。 ターゲットサーバーの次のパスを確認します。
* **common\_install\_base_path**: マニフェストファイルがコピーされ、解凍され、Caché インストールが実行されるパスです。
* **ISC\_PACKAGE\_INSTALLDIR**: Caché のインストールディレクトリです。
ディレクトリパスが存在しない場合は、ターゲットサーバー上に作成されます。
注意: 自動デプロイの機能の一つに、複数サーバーの並行構築があります。 インベントリファイルに複数のサーバーがある場合、各ステップが各ターゲットサーバーで同時に完了した後、次のステップがグループ内の各サーバーで開始します。 いずれかのサーバーでステップが失敗した場合、スクリプトは停止します。 また、問題解決に役立つエラーメッセージが表示されます。 エラーを解消したら、再び最初から実行するだけです。これは、冪等性が保たれるように設計されているというスクリプトの重要な特徴です。 冪等性とは、あるモジュールが例えばファイルコピーを目的としてステップ内で実行される際、ファイルがすでに存在した場合はそのステップが再実行されず、スクリプトが次のステップに進むことを意味します。 コピーなどのモジュールにはコピーを強制するように設定できるパラメーターがありますが、これはデフォルトではありません。 スクリプトを詳しく調べると、"creates" パラメータがいくつかのケースで使用されていることがわかります。次に例を示します。
- name: unattended install of hs using cinstall_silent
shell: >
ISC_PACKAGE_INSTANCENAME="{{ ISC_PACKAGE_INSTANCENAME }}"
ISC_PACKAGE_INSTALLDIR="{{ ISC_PACKAGE_INSTALLDIR }}"
ISC_PACKAGE_UNICODE="{{ ISC_PACKAGE_UNICODE }}"
ISC_PACKAGE_INITIAL_SECURITY="{{ ISC_PACKAGE_INITIAL_SECURITY }}"
ISC_PACKAGE_MGRUSER="{{ ISC_PACKAGE_MGRUSER }}"
ISC_PACKAGE_MGRGROUP="{{ ISC_PACKAGE_MGRGROUP }}"
ISC_PACKAGE_USER_PASSWORD="{{ ISC_PACKAGE_USER_PASSWORD }}"
ISC_PACKAGE_CACHEUSER="{{ ISC_PACKAGE_CACHEUSER }}"
ISC_PACKAGE_CACHEGROUP="{{ ISC_PACKAGE_CACHEGROUP }}" ./cinstall_silent
chdir="{{ common_install_base_path }}/{{ hs_install_unpack_path }}"
args:
creates: "{{ ISC_PACKAGE_INSTALLDIR }}/cinstall.log"
上の節は creates パラメータを使用し、このアクションが cinstall.log ファイルを作成することを Ansible モジュール(この場合は shell モジュール)に知らせています。 モジュールがこのファイルを検出した場合(Caché はすでにインストールされている状態)、このステップは実行されません。
すべての設定が完了したら、インストールを実行できます。
$ ansible-playbook dbserver.yml
PLAY [dbservers] **************************************************************
GATHERING FACTS ***************************************************************
ok: [db1]
TASK: [hs_server_common | include_vars healthshare2015.yml] *******************
ok: [db1]
TASK: [hs_server_common | include_vars os-RedHat.yml] *************************
ok: [db1]
etc
etc
etc
TASK: [hs_server_common | Create default cache group] *************************
changed: [db1]
TASK: [hs_server_common | Create default cache manager group] *****************
changed: [db1]
TASK: [hs_server_common | Create default cache user] **************************
changed: [db1]
TASK: [hs_server_common | Create default cache system users] ******************
changed: [db1]
TASK: [hs_server_common | Create full hs install temp directory] **************
changed: [db1]
TASK: [hs_server_common | Check tar file (gunzipped already) does not exist] ***
ok: [db1]
TASK: [hs_server_common | Copy healthshare install file] **********************
changed: [db1]
TASK: [hs_server_common | un zip hs folder] ***********************************
changed: [db1]
TASK: [hs_server_common | un tar hs install] **********************************
changed: [db1]
TASK: [hs_server_common | Create hs install directory] ************************
changed: [db1]
TASK: [hs_server_common | touch ztrak.conf.] **********************************
changed: [db1]
TASK: [hs_server_common | Process parameters file] ****************************
changed: [db1]
TASK: [hs_server_common | unattended install of hs using cinstall_silent] *****
changed: [db1]
TASK: [hs_server_common | copy hs key] ****************************************
changed: [db1]
TASK: [hs_server_common | Set default hs instance] ****************************
changed: [db1]
TASK: [hs_server_common | restart apache to initialize CSP.ini file] **********
changed: [db1]
NOTIFIED: [hs_server_common | restart healthshare] ****************************
changed: [db1]
PLAY RECAP ********************************************************************
db1 : ok=32 changed=21 unreachable=0 failed=0
ターゲットサーバーを見ると、db サーバーの Caché が稼働しています。
$ ccontrol list
Configuration 'H2015' (default)
directory: /test/hs2015
versionid: 2015.2.1.705.0
conf file: cache.cpf (SuperServer port = 1972, WebServer = 57772)
status: running, since Wed Feb 17 15:59:11 2016
state: ok
## 最後に
次の投稿では、構成ファイルの編集や %installer クラスを使用したアプリケーションの構成など、他のタスクでスクリプトを構築します。
この投稿に興味を持ち、独自のデプロイを作成し始めた方は、ご質問やご提案がございましたらお気軽にお問い合わせください。 私は仮想化とパフォーマンスについて Global Summit で定期的に講演を行っています。今年の Global Summit に参加される予定の方は自己紹介をお願いします。Ansible やその他のシステムアーキテクチャに関する皆様のご経験をお聞かせください。
記事
Shintaro Kaminaka · 2021年10月18日
## 特報!!
この記事の中でご紹介している、FHIRオペレーションのデモを含め、FHIR PathやFHIRプロファイル対応などの2021.1のFHIR関連新機能をご紹介するウェビナーが、**2021年10月21日 12:30~13:00** に開催されます!!ご興味ある方はこちらからご登録ください!!
### [InterSystems IRIS 開発者向けウェビナーシリーズ](https://www.intersystems.com/jp/iris-tech-webinar/)
開発者の皆さん、こんにちは。
今日は前回の[FHIRリポジトリをカスタマイズしよう!パート1](https://jp.community.intersystems.com/node/504516)の記事に続き、パート2として、カスタムオペレーションの実装方法をご紹介したいと思います。この記事で紹介している内容のFHIRリポジトリカスタムオペレーションに関するドキュメントマニュアルは[こちら](https://docs.intersystems.com/irisforhealthlatest/csp/docbookj/DocBook.UI.Page.cls?KEY=HXFHIR_server_customize_operations)になります。
この記事はIRIS for Health 2021.1 をベースに記載しています。バージョンによって実装方法が異なるケースも考えられますので、該当のバージョンのドキュメントをご参照ください。場合によっては新しいバージョンへアップグレードもご検討ください。
## FHIRのOperation(オペレーション)とは?
まず、FHIRのOperationについて、簡単にご紹介したいと思います。
HL7 FHIR公式ページの[Operationのページ](http://hl7.org/fhir/operations.html)には以下のように記載されています。
> The RESTful API defines a set of common interactions (read, update, search, etc.) performed on a repository of typed resources. These interactions follow the RESTful paradigm of managing state by Create/Read/Update/Delete actions on a set of identified resources. **While this approach solves many use cases, there is some functionality that can be met more efficiently using an RPC-like paradigm, where named operations are performed with inputs and outputs (Execute).**
FHIRにおけるデータのアクセスがRESTのCRUDを基本とするのはご存知の通りですが、RPC的なアプローチでより効率的なデータアクセス、データ処理を実現しようというアプローチがFHIRのOperationと言えます。
HL7 FHIR公式ページで規定されているOpeartionは[こちら一覧のページ](http://hl7.org/fhir/operationslist.html)に記載されています。
代表的な所では、Patientリソースで指定できる *$everything* オペレーションや、Observationリソースで指定できる *$lastn* オペレーションがありますので紹介します。
# $everything オペレーション
*$everything* オペレーションはPatientリソースと組み合わせて使用します。詳細は[こちらのページ](http://hl7.org/fhir/patient-operation-everything.html)を参照してください。
IRIS for Health のFHIRリポジトリの場合は、リソースの論理IDまで指定して
```
GET /Patient/5/$everything
```
のように指定して実行できます。
この場合、Patientリソースの論理ID=5に紐づいた関連するリソース(Observation, MedicationRequest, Procedure, Encounter など)を自動的に収集してBundle形式でクライアントに返してくれます。
例えばある患者さんの診療情報を一覧として見せたい場合などには便利な機能です。
# $lastn オペレーション
*$lastn* オペレーションはObservationリソースと組み合わせ使用します。詳細は[こちらのページ](http://hl7.org/fhir/observation-operation-lastn.html)を参照してください。
IRIS for Health のFHIRリポジトリの場合は以下のように指定できます。categoryおよびpatient(またsubject)は必須の指定パラメータとなっています。
```
GET /Observation/$lastn?max=10&category=vital-signs&patient=Patient/123
```
このクエリでは、PatientリソースのID=123の患者に関連した、「vital-signs」カテゴリーに含まれる、最新 **10件** のObservationリソースがBundle形式でクライアントに返されます。直近のデータだけを使ってグラフを表示したい、というようなニーズにはぴったりですね。
## カスタムオペレーションを作成してみよう
FHIRのオペレーションとはどのようなものか?具体例を2つ挙げてご紹介しました。
カスタムオペレーションはこのようなオペレーションを、プロジェクトのニーズに応じて、自分で定義して実装し利用することができるようになる機能です。定義したカスタムオペレーションはCapability Statementに含めて公開することができます。
以下の手順でカスタムオペレーションを構築することができます。
# 1. 3つのカスタムクラス(Interactions等)を用意する
まず、最初の手順として、前回の[FHIRリポジトリをカスタマイズしよう!パート1](https://jp.community.intersystems.com/node/504516)で記載した、3つのカスタムクラスを用意します。詳しい内容はパート1の記事をご覧ください。
# 2. カスタムオペレーション用のクラスを用意し、Interactionsクラスから参照する
Interactionsクラス等と同様に、カスタムオペレーション用のクラスを継承します。
HS.FHIRServer.Storage.BuiltInOperationsを継承し、任意の名称のクラスを作成します。この記事ではCustomFS.MyOperationとします。
(場合によっては、HS.FHIRServer.API.OperationHandlerクラスを継承して作成することもありますが、FHIRリポジトリを利用している場合は、HS.FHIRServer.Storage.BuiltInOperationsを継承し、$everythingなどの実装済みのオペレーションが引き続き使用できるようにする必要があります。詳細はドキュメントをご覧ください。)
これでFHIRリポジトリのカスタマイズに関連して作成したクラスは4つになりましたね。
| ベースクラス | 継承して作成したクラス |
|:----------|:------------|
| HS.FHIRServer.Storage.Json.Interactions | CustomFS.MyInteractions |
| HS.FHIRServer.Storage.Json.InteractionsStrategy | CustomFS.MyInteractionsStrategy |
| HS.FHIRServer.Storage.Json.RepoManager | CustomFS.MyRepoManager |
| (new!) **HS.FHIRServer.Storage.BuiltInOperations** | **CustomFS.MyOperation** |
さらに、このFHIRリポジトリのサーバ処理でこのカスタムオペレーション用のクラスが使用されるように、InteractionsクラスのOperationHandlerClassパラメータでこのクラスを指定します。
```
Class CustomFS.MyInteractions Extends HS.FHIRServer.Storage.Json.Interactions
{
Parameter OperationHandlerClass As %String = "CustomFS.MyOperations";
```
# 3. カスタムオペレーションの処理を実装する
いよいよ、具体的にカスタムオペレーションの処理内容を実装していきます。2.で作成した、CustomFS.MyOperationsクラス内にメソッドを作成して実装します。
まず作成するオペレーションは影響範囲の応じて3つに分けることができます。
この3つの影響範囲=Scope + オペレーション名により、作成するべきメソッド名が決まってきます。
### メソッド名命名ルールについて
メソッド名命名には以下のようなルールがあります。
FHIR*Scope*Op*OperationName*
まずメソッド名の先頭は **FHIR** です。
次に *Scope* には以下の3つのタイプのいずれかが入ります。
| Scope | 説明 |
|:----------|:------------|
| **System** | "ベース" の FHIR エンドポイントに追加する操作を指定します (例えば、http://fhirserver.org/fhir)。これらの操作は、サーバ全体に適用されます。 |
| **Type** | FHIR エンドポイントにリソース・タイプと共に追加する操作を指定します (例えば、http://fhirserver.org/fhir/Patient)。これらの操作は、指定されたリソース・タイプのすべてのインスタンスで動作します。 |
| **Instance** | リソースの特定のインスタンスを指す FHIR エンドポイントに追加する操作を指定します (例えば、http://fhirserver.org/fhir/Patient/1)。これらの操作は、リソースの特定のインスタンスでのみ動作します。 |
以下の図も影響範囲の理解の参考になると思います。
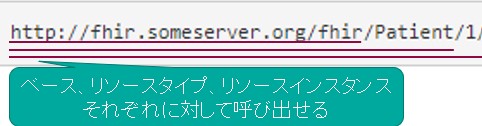
そして、"Op" に続き、先頭を大文字にしたオペレーション名が続きます。
例えば、「$deleteall」というカスタムオペレーションをSystemレベルで作成したいなら
**FHIRSystemOpDeleteall**
というメソッドを作成します。
「$anonymize」というカスタムオペレーションをInstanceレベルで作成したいなら
**FHIRInstanceOpAnonymize**
というメソッドを作成します。
つまり **"FHIR" _ (System or Type or Instance) _ "Op" _ (先頭大文字にしたオペレーション名)** という命名ルールですね。
### メソッドの実装方法
では、実際に、Instanceレベルの$anonymizeオペレーションを作成していきましょう。このオペレーションの目的はPatientリソースのnameエレメントの中身を匿名化)(*******で埋める)を実装することです。
このメソッドは
```
GET /Patient/5/$anonymize
```
のような形で実装されることを想定しています。
上記の例ででてきたように、FHIRInstanceOpAnonymizeメソッドを以下のように実装します。サンプルなので詳細なエラーハンドリングまでは実装していません。
```
ClassMethod FHIRInstanceOpAnonymize(pService As HS.FHIRServer.API.Service, pRequest As HS.FHIRServer.API.Data.Request, pResponse As HS.FHIRServer.API.Data.Response)
{
///RestClientクラスを利用してFHIRサーバへのアクセスを実行。指定された論理IDのPatientリソースを取得する
Set clientObj = ##class(HS.FHIRServer.RestClient.FHIRService).CreateInstance(pRequest.SessionApplication)
Do clientObj.SetResponseFormat("JSON")
set clientResponseObj=clientObj.Read(pRequest.RequestMethod,pRequest.Type,pRequest.Id)
set pResponse.Json=clientResponseObj.Json
set pResponse.Status=clientResponseObj.Status
set pResponse.ETag=clientResponseObj.ETag
set pResponse.LastModified=clientResponseObj.LastModified
set pResponse.Location=clientResponseObj.Location
set pResponse.IsPrettyOut=clientResponseObj.IsPrettyOut
//匿名化処理を実行する
if pResponse.Status="200" {
//DynamicObjectからnameエレメントのIteratorを取得し繰り返し処理
set iter=pResponse.Json.name.%GetIterator()
while iter.%GetNext(.key,.value) {
do pResponse.Json.name.%Get(key).%Set("text","***********")
do pResponse.Json.name.%Get(key).%Set("family","***********")
do pResponse.Json.name.%Get(key).%Set("given","***********")
}
}
}
```
パート1のカスタマイズ処理では、実際に検索(GET)されたデータや、送信(POST/PUT)されたデータに対してカスタム処理を実施しましたが、オペレーションの場合はベースとなる検索を実行する必要があります。もちろん、オペレーションの実装目的によっては、検索をする必要がない場合もあるでしょう。
このメソッドでは、得られた検索結果に対して、DynamicObjectのデータ操作を使用して、データを更新し匿名化を行っています。
# 4. 作成したカスタムオペレーションの定義をCapability Statementに追加する
次に、ロジックを作成したカスタムオペレーションの定義をCapability Statementに追加します。まず、先ほどと同じCustomFS.MyOperationクラスにCapability Statement追加用のAddSupportedOperationsメソッドを記述します。
```
ClassMethod AddSupportedOperations(pMap As %DynamicObject)
{
Do ##super(pMap)
Do pMap.%Set("anonymize","http://myfhirserver/fhir/OperationDefinition/patient-anonymize")
}
```
メソッド内の、pMap.%Setの最初の引数は"オペレーション名"、2番目の引数はそのオペレーションの定義を表すURIを記載します。
2番目の引数は例えば、先述のPatient/[id]/$everything オペレーションであれば、[こちらのページ](http://hl7.org/fhir/patient-operation-everything.html)に記載されているように
> http://hl7.org/fhir/OperationDefinition/Patient-everything
となります。例えば、あるデータ連携プロジェクトに基づいて実装した場合は、そのプロジェクトの実装ガイド内で規定されたURIになるでしょうし、自プロジェクト内で利便性のために構築したということであれば、任意のURIを指定することもできます。
次にコマンドラインユーティリティを起動して、この変更を反映します。
以下はCUSTOMFSネームスペース内で実行した例になります。
```
USER>zn "customfs"
CUSTOMFS>d ##Class(HS.FHIRServer.ConsoleSetup).Setup()
Query returns no results
HS.FHIRServer.Installer:InstallNamespace Created FHIR web application
HS.FHIRServer.Installer:InstallNamespace Created FHIR API web application
What do you want to do?
0) Quit
1) Create a FHIRServer Endpoint
2) Add a profile package to an endpoint
3) Display a FHIRServer Endpoint Configuration
4) Configure a FHIRServer Endpoint
5) Decommission a FHIRServer Endpoint
6) Delete a FHIRServer Endpoint
7) Update the CapabilityStatement Resource
8) Index new SearchParameters for an Endpoint
9) Upload a FHIR metadata package
10) Delete a FHIR metadata package
Choose your Option[1] (0-10): 7
For which Endpoint do you want to update the CapabilityStatement?
1) /csp/healthshare/customfs/fhir/r4 [enabled] (for Strategy 'CustomFS' and Metadata Set 'hl7.fhir.r4.core@4.0.1')
Choose the Endpoint[1] (1-1): 1
Update the /csp/healthshare/customfs/fhir/r4 service CapabilityStatement to reflect the endpoint strategy. Proceed? (y/n): yes
```
以上の手順を実行すると、FHIRリポジトリのCapability Statementにカスタムオペレーションのエントリが追加されます!
Capability StatementはFHIRリポジトリに以下のリクエストをすると取得できます。anonymizeオペレーションがちゃんと追加されていますね。
```
GET http://fhirserver/csp/healthshare/customfs/fhir/r4/metadata
```
```
"operation": [
{
"name": "everything",
"definition": "http://hl7.org/fhir/OperationDefinition/Patient-everything"
},
(略)
{
"name": "anonymize",
"definition": "http://myfhirserver/fhir/OperationDefinition/patient-anonymize"
},
```
# 5. 実行して動作を確認してみよう
以上で、カスタムオペレーション $anoymize の実装は完了です。早速動作確認してみましょう!
まずカスタムオペレーションなしで普通にPatientリソースのデータをリクエストしてみます。
```
GET http://localhost:52785/csp/healthshare/customfs/fhir/r4/Patient/2
```
私のデモ環境では、以下のようなnameエレメントを持つデータが格納されていました。
```
{
"resourceType": "Patient",
"id": "2",
(略)
"name": [
{
"extension": [
{
"url": "http://hl7.org/fhir/StructureDefinition/iso21090-EN-representation",
"valueCode": "IDE"
}
],
"use": "official",
"text": "山田 太郎",
"family": "山田",
"given": [
"太郎"
]
},
{
"extension": [
{
"url": "http://hl7.org/fhir/StructureDefinition/iso21090-EN-representation",
"valueCode": "SYL"
}
],
"use": "official",
"text": "ヤマダ タロウ",
"family": "ヤマダ",
"given": [
"タロウ"
]
}
```
次に、実装した $anonymizeを追加して実行してみます!
```
GET http://localhost:52785/csp/healthshare/customfs/fhir/r4/Patient/2/$anonymize
```
以下のように匿名化されたデータが取得できました!
```
{
"resourceType": "Patient",
"id": "2",
(略)
"name": [
{
"extension": [
{
"url": "http://hl7.org/fhir/StructureDefinition/iso21090-EN-representation",
"valueCode": "IDE"
}
],
"use": "official",
"text": "***********",
"family": "***********",
"given": "***********"
},
{
"extension": [
{
"url": "http://hl7.org/fhir/StructureDefinition/iso21090-EN-representation",
"valueCode": "SYL"
}
],
"use": "official",
"text": "***********",
"family": "***********",
"given": "***********"
}
],
```
# カスタマイズを実装する際のTips
パート1、パート2とIRIS for HealthのFHIRリポジトリをカスタマイズする方法をご紹介してきました。
ここで、カスタマイズの際のTipsを一つご紹介します。
IRISのFHIRリポジトリ処理では、パフォーマンス最適化のために、個別のプロセス内でFHIR処理用のサービスインスタンスが起動され、再利用される仕組みになっています。そのため、条件によっては、サーバ側のカスタム処理を書き換えたのにそれが反映されないことがあります。そのような際にはいくつかの対応方法があります。
1. FHIR Server Configurationページで「New Service Instance」のチェックを有効にする
開発環境であれば、この方法をお勧めします。FHIRリクエスト毎に新しいService Instanceが立ち上がるので、必ず変更が反映されます。ただし、パフォーマンスへの影響を考えると、本番環境で設定することはお勧めしません。
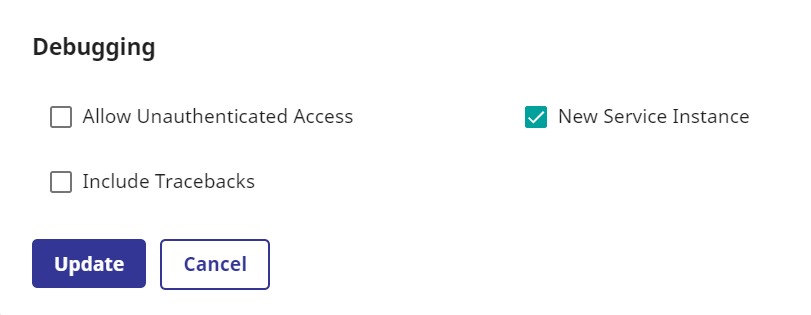
2. Web Gateway Management 画面からすべてのセッションをクリアする
System Status画面ですべてのセッションをクリアすることによって、起動しているIRIS側のプロセスもすべて再起動されます。下記画像の黄色の部分をクリックします。
3. 再起動する(常に最強の手段)
## まとめ
いかがでしたでしょうか?
IRIS for HealthのFHIRリポジトリカスタマイズ機能を利用することによって、プロジェクト開発で求められる様々な要件に柔軟に対応することができます。もちろん、カスタマイズを多用することが、FHIRの持つ汎用性に影響を及ぼすことを考慮する必要がありますが、パート1/2の記事でご紹介したカスタマイズ機能を効果的に使えば、より高度なFHIRアプリケーションの構築も可能になります。
パート1、パート2の内容を含むIRISのクラスを[こちらのGitHubサイト](https://github.com/Intersystems-jp/FHIR_Customize)からダウンロードすることができます。
また新たなカスタマイズ手法が実装されたらこちらの開発者コミュニティで紹介したいと思います。
記事
Toshihiko Minamoto · 2021年1月14日
前回のつづきとして、いよいよIRISのインターオペラビリティ機能を使ってMQTTブローカーからメッセージを受信し、データベースに格納する方法について解説したいと思います。IRISのインターオペラビリティ機能につきましてはこちらをご参照ください。
ネームスペース作成
インストール時に作成されているUSERネームスペースはInteroperabilityに必要なライブラリを参照するためのマッピングができていません。そのため、新たにネームスペースを作成する必要があります。作成方法は、以下の通りです。
システム管理ポータルを起動し、「システム管理」「構成」「システム構成」「ネームスペース」をクリックします。
以下のようなネームスペース一覧画面が表示されますので、上にある「新規ネームスペース作成」ボタンをクリックします。
以下のような新規ネームスペース作成画面が表示されますので、「ネームスペース名」欄にネームスペースの名称を入力し、「グローバルのための既存のデータベースを選択」欄、「ルーチンのための既存のデータベースを選択」欄で共にデータベース「USER」を選択します。
「相互運用プロダクション用にネームスペースを有効化」欄にチェックが付いていることを確認の上、画面上の「保存」ボタンをクリックします。
以下のような処理ログが表示されますので、画面下の「閉じる」ボタンをクリックします。
以上でネームスペースが作成できました。
気象データテーブルの作成
以下のように観測地点、取得時刻、気温、湿度、気圧を格納するクラス(MQTT.Data.WeatherInfo)を作成します。
/// 気象データ
Class MQTT.Data.WeatherInfo Extends %Persistent
{
/// 観測地点 (ClientID)
Property PointName As %String;
/// 取得時刻
Property MeasureTime As %TimeStamp;
/// 気温
Property Temperature As %Numeric;
/// 湿度
Property Humidity As %Numeric;
/// 気圧
Property Pressure As %Numeric;
Index PointDate On (PointName, MeasureTime);
}
気象データ格納オペレーションの作成
以下のように、MQTT.BO.StoreDataというビジネスオペレーションクラスを作成し、MQTTメッセージ(EnsLib.MQTT.Message)からデータを取得しMQTT.Data.WeatherInfoクラスに格納するStoreData()メソッドを追加します。MessageMapの設定も忘れずに追加してください。
/// MQTTメッセージのデータベースへの保存
Class MQTT.StoreData Extends Ens.BusinessOperation [ Language = objectscript ]
{
Parameter INVOCATION = "Queue";
Method StoreData(pRequest As EnsLib.MQTT.Message, Output pResponse As Ens.Response) As %Status
{
set obj=##class(MQTT.Data.WeatherInfo).%New()
set obj.MeasureTime=$zdatetime($horolog,3)
set obj.Temperature=$piece(pRequest.StringValue,",")
set obj.Humidity=$piece(pRequest.StringValue,",",2)
set obj.Pressure=$piece(pRequest.StringValue,",",3)
set obj.PointName=$piece(pRequest.Topic,"/",2)
return obj.%Save()
}
XData MessageMap
{
<MapItems>
<MapItem MessageType="EnsLib.MQTT.Message">
<Method>StoreData</Method>
</MapItem>
</MapItems>
}
}
プロダクションの作成
システム管理ポータルより「Interoperability」「構成」「プロダクション」メニューをクリックします。以下のようにインターオペラビリティ機能を実行するネームスペースを聞いてきますので、先ほど作成したネームスペース(TEST)を選択します。
以下のようにプロダクション構成画面が表示されますので、画面中央上にある「プロダクション設定」リンクをクリックし、右にある「アクション」タブをクリック、「新規」ボタンをクリックします。
以下のようなダイアログボックスが表示されますので、パッケージ名、プロダクション名を入力し、「OK」ボタンをクリックします。
ビジネスオペレーションの作成
アイテムが無いプロダクション構成画面が表示されますので、画面上の「オペレーション」の右にある「+」ボタンをクリックします。
クリックしますと以下のようなダイアログボックスが表示されますので、「オペレーションクラス」欄に先ほど作成したMQTT.BO.StoreDataクラスを選択し、「オペレーション名」欄にオペレーション名(メッセージ保存)、「有効にする」にチェックを入れ、「OK」ボタンをクリックします。
ビジネスサービスの作成
MQTTブローカーからメッセージを受信するMQTTサービスを作成します。画面左上の「サービス」の右にある「+」ボタンをクリックしますと、以下のようなダイアログボックスが表示されます。
ここで「サービスクラス」欄にて「EnsLib.MQTT.Service.Passthrough」を選択します。
「サービス名」欄にサービス名(MQTTサービス)を入力し、「有効にする」をチェック、「OK」ボタンをクリックします。
MQTTに接続するための設定
最初の記事にて設定したMQTTブローカー(mosquitto)にアクセスするには認証や暗号化通信が必要です。認証に必要な認証情報は以下の手順で作成します。
管理ポータルより「Interoperability」「構成」「認証情報」メニューをクリックします。
以下の画面が表示されますので、「ID」欄にMQTTAccess、「ユーザ名」欄に「iris」、「パスワード」欄に最初の記事で入力したユーザirisのパスワードを入力し、保存ボタンをクリックします。
認証の次は暗号化です。暗号化通信を行うにはCAの証明書が必要になりますので、以下の手順でSSL/TLS構成を作成します。
管理ポータルより「システム管理」「セキュリティ」「SSL/TLS構成」メニューをクリックします。
以下のようにSSL/TLS構成一覧が表示されますので、画面上の「新規構成の作成」ボタンをクリックします。
SSL/TLS構成編集画面にて以下のように構成名(mqtt_srv)、タイプ(クライアントをチェック)、サーバ証明書の検証(必須をチェック)を入力し、「信頼済み認証局の証明書を含むファイル」欄に最初の記事の中で作成した自己認証局の証明書のファイルを設定、「保存」ボタンをクリックします。
サービスの設定
前のトピックで作成した認証情報やCAの証明書を使い、MQTTサービスの設定を行います。
以下のようなプロダクション構成画面にて「MQTTサービス」をクリックし、右にある「設定」をクリックします。
ここで以下の項目を設定し、画面上の「適用」をクリックします。
基本設定 - ターゲット構成:「メッセージ保存」
MQTT - ClientID:「MQTTSRV1」
MQTT - CredentialsName: 「MQTTAccess」
MQTT - SSLConfigName:「mqtt_srv」
MQTT - Topic:「point/#」
MQTT - Url:「ssl://localhost:8883」
プロダクションの起動
以上で設定は完了しましたので、プロダクション構成画面から「開始する」ボタンをクリックします。
管理ポータルより、「システムエクスプローラ」「SQL」メニューをクリックし、「クエリ実行」タブをクリック、以下のSQLを実行させて、1分おきにレコードが増えていれば成功です。
select * from MQTT_Data.WeatherInfo
まとめ
3回にわたって、Mosquittoの設定やESP8266 ( arduino )などのマイコンのプログラミング、IRISのプログラム例を紹介しました。このことから、マイコンからInterSystems IRISにデータが渡せることをご理解いただけたかと思います。また、IRISの公開鍵基盤を使用して証明書等作成できることもご確認いただけたかと思います。
ご意見、ご質問等ございましたら、ご遠慮なくコメントに追加いただければと思います。最後までお読みいただきありがとうございました。
記事
Toshihiko Minamoto · 2020年12月1日
%Net.SSH.Session クラスを使用すると、SSH を使ってサーバーに接続することができます。 一般的にはSFTP、特に FTP インバウンドアダプタとFTPアウトバウンドアダプタで使用されています。
この記事では、簡単な例を示しながら、このクラスを使用して SSH サーバーに接続する方法、認証のオプションを記述する方法、そして問題が発生した場合のデバッグ方法について説明します。
次は接続を行う例です。
~~~
Set SSH = ##class(%Net.SSH.Session).%New()
Set return=SSH.Connect("ftp.intersystems.com")
~~~
上記のコードは新しい接続を作成してから、ftp.intersystems.com の SFTP サーバーにデフォルトのポートで接続します。 この時点で、クライアントとサーバーは暗号化アルゴリズムとオプションを選択済みですが、ユーザーはまだログインしていません。
接続したら、認証方法を選択できます。 選択できるメソッドには次の 3 つがあります。
- AuthenticateWithUsername
- AuthenticateWithKeyPair
- AuthenticateWithKeyboardInteractive
上記はそれぞれ異なる認証方式です。 各方式を簡単に説明します。
#### AuthenticateWithUsername
これは、ユーザー名とパスワードを使用します。
#### AuthenticateWithKeyPair
これは、公開鍵と秘密鍵のペアを使用します。 公開鍵は事前にサーバーに読み込まれている必要があり、それに一致する秘密鍵が必要となります。 秘密鍵がディスク上で暗号化されている場合、メソッドへの呼び出しで、それを復号化するためのパスフレーズを指定します。 注意: 秘密鍵を他人に送信してはいけません。
公開鍵は OpenSSH 形式であり、秘密鍵は PEM で暗号化されている必要があります。 OpenSSH の形式は次のような書式です。
~~~
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCfi2Vq+u0rtt2OC84pyrkq1k7WkrS+s76u3a+2gdD43KQ2Z3vSUUfksymJjp11JBZEpOtBVIAy221UKdc7j7Qk6sUjZaK8LIy+bzDVwMyFWgVvQge7EjdWjrJLBRCDXYML6y1Y25XexThkTWSGyXzGNdr+wfIHYn/mIt0hfvrusauvT/9Wz8K2MGAj4BL7UQZpFJrlXzGmewe6++6cZDQQYi0aztwLK798oc9j0LsccdMpqWrjqoU1uANFhYIuUu/T47TEhT+e6M+KFYK5TR998eJTO25IjdN2Tgw0feXhQFF/nngbol0bA4auSPaZQsgokKK+E+Q/8UtBdetEofuV user@hostname
~~~
PEM で暗号化されている秘密鍵には、ファイルの上部に次のようなヘッダーがあります。
~~~
-----BEGIN RSA PRIVATE KEY-----
~~~
そして、最後に次の行があります。
~~~
-----END RSA PRIVATE KEY-----
~~~
#### AuthenticateWithKeyboardInteractive
これは、Cache 2018.1 以降で提供されている新しいオプションです。 チャレンジレスポンス認証を実行できます。 たとえば、テキストメッセージで送信されるか、Google 認証システムアプリで生成されたワンタイムパスワードを要求することがあるでしょう。 この認証方式を使用するには、サーバーが送信するプロンプトを処理するためのラムダ関数を記述する必要があります。
この認証方式を、ユーザーのパスワード認証と同じように、ユーザー名とパスワードのプロンプトのみで使用しているサーバーに遭遇することがあるかもしれませんが、 以下に説明する SSH デバッグフラグを使えば、これに遭遇しているかどうかを判定しやすくなります。
**認証に関する注意事項:** 1 つの接続で 2 つの認証方式の使用を検討している方は、Cache 2018.1 または InterSystems IRIS を使用してください。 これらのバージョンには、鍵ペアとユーザー名といった、複数の方式を使用できるようにするための更新があります。
## 問題が発生した場合
### 発生する可能性のある一般的なエラー
#### バナーの取得に失敗しました(Failed getting banner)
これは次のように表示されます。
~~~
ERROR #7500: SSH Connect Error '-2146430963': SSH Error [8010100D]: Failed getting banner [FFFFFFFF8010100D] at Session.cpp:231,0
~~~
SSH クライアントが最初に行うのは、バナーの取得です。 このエラーが発生した場合、適切なサーバーに接続しており、それが SFTP サーバーであることを確認してください。
たとえば、サーバーが実際には FTPS サーバーであった場合に、このエラーが発生します。 FTPS サーバーは SSH ではなく SSL を使用するため、%Net.SSH.Session クラスでは動作しません。 FTPS サーバーに接続するには、%Net.FtpSession クラスを使用してください。
#### 暗号化鍵を交換できません(Unable to exchange encryption keys)
このエラーは次のように表示されます。
~~~
ERROR #7500: SSH Connect Error '-2146430971': SSH Error [80101005]: Unable to exchange encryption keys [80101005] at Session.cpp:238,0
~~~
このエラーは通常、クライアントとサーバーの暗号化または MAC アルゴリズムが合致しなかったことを指しています。 これが発生した場合は、新しいアルゴリズムのサポートを追加するために、クライアントかサーバーのいずれかをアップグレードする必要があるかもしれません。
2017.1 より前のバージョンの Cache を使用している場合は、2017.1 以降を使用することをお勧めします。 libssh2 ライブラリは 2017.1 でアップグレードされており、新しいアルゴリズムがいくつか追加されています。
詳細については、以下に説明するデバッグフラグが提供するログを参照してください。
#### 提供された公開鍵の署名が無効です(Invalid signature for supplied public key)
~~~
Error [80101013]: Invalid signature for supplied public key, or bad username/public key combination [80101013] at Session.cpp:418
~~~
これは非常に誤解を招きやすいエラーです。 サーバーが 2 つの認証方式を必要としているにも関わらず、1 つしか提供しなかった場合に発生します。 この場合は、そのまま続けて次の方式を試しましょう! このエラーがあっても、すべてうまく動作する可能性があります。
#### Error -37
エラー -37 に関するメッセージが表示されることがあります。 たとえば、次のデバッグログを見てください。
~~~
[libssh2] 0.369332 Failure Event: -37 - Failed getting banner
~~~
エラー -37 が示されている場合は必ず、失敗した操作が再試行されます。 このエラーが最終的な失敗の原因であることはありません。 ほかのエラーメッセージを確認してください。
### SSH デバッグフラグ
接続に SSH デバッグフラグを使うと、SSH 接続の詳細なログを取得できます。 このフラグを有効にするには、SetTraceMethod メソッドを使います。 次に、このフラグを使った接続の例を示します。
~~~
Set SSH = ##class(%Net.SSH.Session).%New()
Do SSH.SetTraceMask(511,"/tmp/ssh.log")
Set Status=SSH.Connect("ftp.intersystems.com")
~~~
SetTraceMask の最初の引数は、何を収集するかを指示します。 ビットの 10進表現です。 511 は 512 を除くすべてのビットを要求しており、最も一般的に使用される設定です。 各ビットに関する詳細については、%Net.SSH.Session クラスのクラスドキュメントをご覧ください。
2 つ目の引数は、接続に関するログ情報をどのファイルに格納するかを指示します。 この例では、/tmp/ssh.log ファイルを指定しましたが、任意の絶対または相対パスを使用できます。
上記の例では、Connect メソッドのみを実行しました。 認証に問題がある場合は、該当する認証方式も実行する必要があります。
テストを実行したら、ログファイルで情報を確認できます。 ログファイルの解釈に不安がある場合は、WRC をご覧ください。
記事
Toshihiko Minamoto · 2020年8月17日
この記事では、スナップショットを使用したソリューションとの統合の例を使って、_外部バックアップ_による Caché のバックアップ方法を紹介します。 このところ私が目にするソリューションの大半は、Linux の VMware にデプロイされているため、この記事の大半では、例として、ソリューションが VMware スナップショットテクノロジーをどのように統合しているかを説明しています。
## Caché バックアップ - すぐ使えますか?
Caché をインストールすると、Caché データベースを中断せずにバックアップできる Caché オンラインバックアップが含まれています。 しかし、システムがスケールアップするにつれ、より効率的なバックアップソリューションを検討する必要があります。 Caché データベースを含み、システムをバックアップするには、スナップショットテクノロジーに統合された_外部バックアップ_をお勧めします。
## 外部バックアップに関して特別な考慮事項はありますか?
詳しい内容は[外部バックアップ](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_backup#GCDI_backup_methods_ext)のオンラインドキュメンテーションに説明されていますが、 主な考慮事項は次のとおりです。
> 「スナップショットの整合性を確保するために、スナップショットが作成される間、Caché はデータベースへの書き込みをfreezeする方法を提供しています。 スナップショットの作成中は、データベースファイルへの物理的な書き込みのみがfreezeされるため、ユーザーは中断されることなくメモリ内で更新を実行し続けることができます。」
また、仮想化されたシステム上でのスナップショットプロセスの一部によって、バックアップされている VM にスタンタイムと呼ばれる短い無応答状態が発生することにも注意してください。 通常は 1 秒未満であるため、ユーザーが気付いたり、システムの動作に影響を与えたりすることはありませんが、状況によってはこの無応答状態が長引くことがあります。 無応答状態が Caché データベースミラーリングの QoS タイムアウトより長引く場合、バックアップノードはプライマリに障害が発生したとみなし、フェイルオーバーします。 この記事の後の方で、ミラーリング QoS タイムアウトを変更する必要がある場合に、スタンタイムをどのように確認できるかについて説明します。
[InterSystems データプラットフォームとパフォーマンスに関する他の連載記事のリストはこちらにあります。](https://jp.community.intersystems.com/node/477596/)
この記事では、Caché オンラインドキュメンテーション『[Backup and Restore Guide](http://docs.intersystems.com/latestj/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_backup)(バックアップと復元ガイド)』も確認する必要があります。
# バックアップの選択肢
## 最小限のバックアップソリューション - Caché Online Backup
ほかのソリューションがない場合は、ダウンタイム無しでバックアップを行えるこのソリューションが InterSystems データプラットフォームに同梱されています。 _Caché オンラインバックアップ_は、Caché データベースファイルのみをバックアップするもので、データに割り当てられたデータベースのすべてのブロックをキャプチャし、出力をシーケンシャルファイルに書き込みます。 Caché Online Backup は累積バックアップと増分バックアップをサポートしています。
VMware の文脈では、Caché Online Backup はゲスト内で発生するバックアップソリューションです。 ほかのゲスト内ソリューションと同様に、Caché Online Backup の動作は、アプリケーションが仮想化されていようが、ホストで直接実行していようが、基本的に変わりません。 Caché Online Backup は、システムバックアップと連携しながら Caché のオンラインバックアップ出力ファイルを、アプリケーションが使用しているその他すべてのファイルシステムとともに、バックアップメディアにコピーします。 最小限のシステムバックアップには、インストールディレクトリ、ジャーナルおよび代替ジャーナルディレクトリ、アプリケーションファイル、およびアプリケーションが使用する外部ファイルを含むすべてのディレクトリを含める必要があります。
Caché Online Backup は、Caché データベースやアドホックバックアップのみをバックアップする低コストのソリューションを実装したいと考えている小規模サイト向けのエントリレベルのアプローチとして捉えてください。ミラーリングをセットアップする際のバックアップなどに役立てられます。 しかし、データベースのサイズが増加したり、Caché が顧客のデータランドスケープの一部でしかない場合は、_外部バックアップ_にスナップショットテクノロジーとサードパーティ製ユーティリティを合わせたソリューションがベストプラクティスとして推奨されます。非データベースファイルのバックアップ、より高速な復旧時間、エンタープライズ全体のデータビュー、より優れたカタログと管理用ツールなど、さまざまなメリットが得られます。
## 推奨されるバックアップソリューション - 外部バックアップ
VMware を例として使用します。VMware で仮想化すると、VM 全体を保護するための追加機能と選択肢が追加されます。 ソリューションの仮想化が完了した時点で、オペレーティングシステム、アプリケーション、データを含むシステムを .vmdk(とその他の)ファイル内に効果的にカプセル化したことになります。 これらのファイルの管理は非常に簡単で、必要となった場合にはシステム全体の復旧に使用できるため、オペレーティングシステム、ドライバ、サードパーティ製アプリケーション、データベースとデータベースファイルなどのコンポーネントを個別に復旧して構成する必要のある物理システムで同じような状況が発生した場合とは大きく異なります。
# VMware のスナップショット
VMware の vSphere Data Protection(VDP)や、Veeam や Commvault などのサードパーティ製バックアップソリューションでは、VMware 仮想マシンスナップショットを使用してバックアップを作成しています。 VMware スナップショットの概要を説明しますが、詳細については、VMware ドキュメンテーションを参照してください。
スナップショットは VM 全体に適用されるものであり、オペレーティングシステムとすべてのアプリケーションまたはデータベースエンジンはスナップショットが発生していることを認識しないということに注意してください。 また、次のことにも注意してください。
> VMware スナップショット自体はバックアップではありません!
スナップショットは、バックアップソフトウェアによるバックアップの作成を_可能にします_が、スナップショット自体はバックアップではありません。
VDP とサードパーティ製バックアップソリューションは、バックアップアプリケーションとともに VMware スナップショットプロセスを使用して、スナップショットの作成と、非常に重要となるその削除を管理します。 おおまかに見ると、VMware スナップショットを使用した外部バックアップのイベントのプロセスと順序は次のとおりです。
- サードパーティ製バックアップソフトウェアは ESXi ホストに対し、VMware スナップショットをトリガーするように要求します。
- VM の .vmdk ファイルは読み取り専用状態となり、各 VM の .vmdk ファイルに子 vmdk 差分ファイルが作成されます。
- 書き込み時コピーを使用して、VM へのすべての変更が差分ファイルに書き込まれます。 すべての読み取りは、最初に差分ファイルから行われます。
- バックアップソフトウェアは、読み取り専用の親 .vmdk ファイルからバックアップターゲットへのコピーを管理します。
- バックアップが完了すると、スナップショットがコミットされます(VM ディスクは、親に書き込まれた差分ファイルのブロックの書き込みと更新を再開します)。
- VMware スナップショットが削除されます。
バックアップソリューションは、変更ブロック追跡(CBT)などのほかの機能も使用し、増分または累積バックアップを可能にして速度と効率性(容量節約において特に重要)を実現します。また、一般的に、データの重複解除や圧縮、スケジューリング、整合性チェックなどで IP アドレスが更新された VM のマウント、VM とファイルレベルの完全復元、およびカタログ管理などの重要な機能性も追加します。
> 適切に管理されていない、または長期間実行されたままの VMware スナップショットは、ストレージを過剰に消費し(データの変更量が増えるにつれ、差分ファイルが増加し続けるため)、VM の速度を低下させてしまう可能性があります。
本番インスタンスで手動スナップショットを実行する前に、十分に検討する必要があります。 なぜ実行しようとしているのか、 スナップショットが作成された*時間に戻す*とどうなるか、 作成とロールバック間のすべてのアプリケーショントランザクションはどうなるか、といったことを検討してください。
バックアップソフトウェアがスナップショットを作成し、削除しても問題ありません。 スナップショットの存続期間は、短期間であるものなのです。 また、バックアップ戦略においては、ユーザーやパフォーマンスへの影響をさらに最小限に抑えられるように、システムの使用率が低い時間を選ぶことも重要です。
## スナップショットに関する Caché データベースの考慮事項
スナップショットを作成する前に、保留中のすべての書き込みがコミットされ、データベースが一貫した状態になるように データベースを静止させる必要があります。 Caché は、スナップショットが作成される間、データベースへの書き込みをコミットして短時間フリーズ(停止)するメソッドと API を提供しています。 こうすることで、スナップショットの作成中は、データベースファイルへの物理的な書き込みのみがフリーズされるため、ユーザーは中断されることなくメモリ内で更新を実行し続けることができます。 スナップショットがトリガーされると、データベースの書き込みが再開し、バックアップはバックアップメディアへのデータのコピーを続行します。 フリーズからの復旧は、非常に短時間(数秒)で発生します。
書き込みを一時停止するのに加え、Caché Freeze は、ジャーナルファイルの切り替えとジャーナルへのバックアップマーカーの書き込みも処理します。 ジャーナルファイルは、物理データベースの書き込みがフリーズしている間、通常通りに書き込みを続けます。 物理データベースの書き込みがフリーズしている間にシステムがクラッシュした場合、データは、起動時に、通常通りジャーナルから復元されます。
以下の図は、整合性のあるデータベースイメージを使用してバックアップを作成するための、VMware スナップショットを使用した Freeze と Thaw の手順を示しています。

> _Freeze から Thaw の時間が短いところに注目してください。読み取り専用の親をバックアップターゲットにコピーする時間でなく、スナップショットを作成する時間のみです。_
# Caché の Freeze と Thaw の統合
vSphere では、スナップショット作成のいずれか側で自動的にスクリプトを呼び出すことができ、この時に、Caché Freeze と Thaw が呼び出されます。 注意: この機能が正しく機能するために、ESXi ホストは _VMware ツール_を介してゲストオペレーティングシステムにディスクを静止するように要求します。
> VMware ツールは、ゲストオペレーティングシステムにインストールされている必要があります。
スクリプトは、厳密な命名規則と場所のルールに準じる必要があります。 ファイルの権限も設定されていなければなりません。 以下は、Linux の VMware の場合のスクリプト名です。
# /usr/sbin/pre-freeze-script
# /usr/sbin/post-thaw-script
以下は、InterSystems のチームが内部テストラボインスタンスに対して、Veeam バックアップで使用する Freeze と Thaw のスクリプト例ですが、ほかのソリューションでも動作するはずです。 これらの例は、vSphere 6 と Red Hat 7 で検証され、使用されています。
> これらのスクリプトは例として使用でき、方法を示すものではありますが、各自の環境で必ず検証してください!
### Freeze 前スクリプトの例:
#!/bin/sh
#
# Script called by VMWare immediately prior to snapshot for backup.
# Tested on Red Hat 7.2
#
LOGDIR=/var/log
SNAPLOG=$LOGDIR/snapshot.log
echo >> $SNAPLOG
echo "`date`: Pre freeze script started" >> $SNAPLOG
exit_code=0
# Only for running instances
for INST in `ccontrol qall 2>/dev/null | tail -n +3 | grep '^up' | cut -c5- | awk '{print $1}'`; do
echo "`date`: Attempting to freeze $INST" >> $SNAPLOG
# Detailed instances specific log
LOGFILE=$LOGDIR/$INST-pre_post.log
# Freeze
csession $INST -U '%SYS' "##Class(Backup.General).ExternalFreeze(\"$LOGFILE\",,,,,,1800)" >> $SNAPLOG $
status=$?
case $status in
5) echo "`date`: $INST IS FROZEN" >> $SNAPLOG
;;
3) echo "`date`: $INST FREEZE FAILED" >> $SNAPLOG
logger -p user.err "freeze of $INST failed"
exit_code=1
;;
*) echo "`date`: ERROR: Unknown status code: $status" >> $SNAPLOG
logger -p user.err "ERROR when freezing $INST"
exit_code=1
;;
esac
echo "`date`: Completed freeze of $INST" >> $SNAPLOG
done
echo "`date`: Pre freeze script finished" >> $SNAPLOG
exit $exit_code
### Thaw スクリプトの例:
#!/bin/sh
#
# Script called by VMWare immediately after backup snapshot has been created
# Tested on Red Hat 7.2
#
LOGDIR=/var/log
SNAPLOG=$LOGDIR/snapshot.log
echo >> $SNAPLOG
echo "`date`: Post thaw script started" >> $SNAPLOG
exit_code=0
if [ -d "$LOGDIR" ]; then
# Only for running instances
for INST in `ccontrol qall 2>/dev/null | tail -n +3 | grep '^up' | cut -c5- | awk '{print $1}'`; do
echo "`date`: Attempting to thaw $INST" >> $SNAPLOG
# Detailed instances specific log
LOGFILE=$LOGDIR/$INST-pre_post.log
# Thaw
csession $INST -U%SYS "##Class(Backup.General).ExternalThaw(\"$LOGFILE\")" >> $SNAPLOG 2>&1
status=$?
case $status in
5) echo "`date`: $INST IS THAWED" >> $SNAPLOG
csession $INST -U%SYS "##Class(Backup.General).ExternalSetHistory(\"$LOGFILE\")" >> $SNAPLOG$
;;
3) echo "`date`: $INST THAW FAILED" >> $SNAPLOG
logger -p user.err "thaw of $INST failed"
exit_code=1
;;
*) echo "`date`: ERROR: Unknown status code: $status" >> $SNAPLOG
logger -p user.err "ERROR when thawing $INST"
exit_code=1
;;
esac
echo "`date`: Completed thaw of $INST" >> $SNAPLOG
done
fi
echo "`date`: Post thaw script finished" >> $SNAPLOG
exit $exit_code
### 権限の設定を必ず行ってください:
# sudo chown root.root /usr/sbin/pre-freeze-script /usr/sbin/post-thaw-script
# sudo chmod 0700 /usr/sbin/pre-freeze-script /usr/sbin/post-thaw-script
## Freeze と Thaw のテスト
スクリプトが正しく動作することをテストするには、VM でスナップショットを手動で実行し、スクリプトの出力を確認することができます。 以下のスクリーンショットは、[Take VM Snapshot(VM スナップショットの作成)]ダイアログとオプションを示します。

**選択解除**- [Snapshot the virtual machine's memory(仮想マシンのメモリをスナップショットする)]
**選択** - [Quiesce guest file system (Needs VMware Tools installed)(ゲストファイルシステムを静止する: VMware ツールのインストールが必要)]チェックボックス。スナップショットを作成する際にゲストオペレーティングシステムで実行中のプロセスを一時停止し、ファイルシステムのコンテンツが既知の整合性のある状態を保つようにします。
> 重要! テストの後、スナップショットを必ず削除してください!!!!
スナップショットが作成される際に、静止フラグが真であり、仮想マシンがオンである場合、VMware ツールによって仮想マシンのファイルシステムが静止されます。 ファイルシステムの静止は、ディスク上のデータをバックアップに適した状態にするプロセスです。 このプロセスには、オペレーティングシステムのメモリ内キャッシュからディスクへのダーティバッファのフラッシュといった操作が含まれる場合があります。
以下の出力は、操作の一環としてスナップショットを含むバックアップを実行した後に、上記の Freeze/Thaw スクリプトの例で設定された `$SNAPSHOT` ログファイルのコンテンツを示しています。
Wed Jan 4 16:30:35 EST 2017: Pre freeze script started
Wed Jan 4 16:30:35 EST 2017: Attempting to freeze H20152
Wed Jan 4 16:30:36 EST 2017: H20152 IS FROZEN
Wed Jan 4 16:30:36 EST 2017: Completed freeze of H20152
Wed Jan 4 16:30:36 EST 2017: Pre freeze script finished
Wed Jan 4 16:30:41 EST 2017: Post thaw script started
Wed Jan 4 16:30:41 EST 2017: Attempting to thaw H20152
Wed Jan 4 16:30:42 EST 2017: H20152 IS THAWED
Wed Jan 4 16:30:42 EST 2017: Completed thaw of H20152
Wed Jan 4 16:30:42 EST 2017: Post thaw script finished
この例では、Freeze から Thaw までに 6 秒経過していることがわかります(16:30:36~16:30:42)。 この間、ユーザー操作は中断されていません。 _独自のシステムからメトリックを収集する必要があります_が、背景としては、この例は、IO ボトルネックがなく、平均 200 万 Glorefs/秒、17 万 Gloupds/秒、および毎秒あたり平均 1,100 個の物理読み取りと書き込みデーモン 1 サイクル当たりの書き込み 3,000 個の BM でアプリケーションベンチマークを実行しているシステムから得たものです。
> メモリはスナップショットの一部ではないため、再起動すると、VM は再起動して復元されることに注意してください。 データベースファイルは整合性のある状態です。 バックアップを「再開」するのではなく、ファイルを既知の時点の状態にする必要があります。 その後で、ファイルが復元されたら、ジャーナルと、アプリケーションとトランザクションの整合性に必要なその他の復元手順をロールフォワードできます。
その他のデータ保護を追加するには、[ジャーナルの切り替え](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_journal#GCDI_journal_util_JRNSWTCH "Journal switch")を単独で実行することもでき、ジャーナルは、たとえば 1 時間ごとに別の場所にバックアップまたは複製されます。
以下は、上記の Freeze と Thaw スクリプトの `$LOGFILE` の出力で、スナップショットのジャーナルの詳細を示しています。
01/04/2017 16:30:35: Backup.General.ExternalFreeze: Suspending system
Journal file switched to:
/trak/jnl/jrnpri/h20152/H20152_20170104.011
01/04/2017 16:30:35: Backup.General.ExternalFreeze: Start a journal restore for this backup with journal file: /trak/jnl/jrnpri/h20152/H20152_20170104.011
Journal marker set at
offset 197192 of /trak/jnl/jrnpri/h20152/H20152_20170104.011
01/04/2017 16:30:36: Backup.General.ExternalFreeze: System suspended
01/04/2017 16:30:41: Backup.General.ExternalThaw: Resuming system
01/04/2017 16:30:42: Backup.General.ExternalThaw: System resumed
# VM スタンタイム
VM スナップショットの作成時、バックアップが完了してスナップショットがコミットされた後、VM を短時間フリーズする必要があります。 この短時間のフリーズは、VM のスタンと呼ばれることがよくあります。 スタンタイムについてよく説明されたブログ記事は、[こちら](http://cormachogan.com/2015/04/28/when-and-why-do-we-stun-a-virtual-machine/ "Blog Post on stun times")をご覧ください。 以下に要約した内容を示し、Caché データベースの考慮事項に照らして説明します。
スタンタイムに関する記事より: 「VM スナップショットを作成するには、(i)デバイスの状態をディスクにシリアル化し、(ii)現在実行中のディスクを閉じてスナップショットポイントを作成するために、VM は「スタン」されます(無応答状態になります)。… 統合時、VM は、ディスクを閉じて統合に最適な状態にするために、「スタン」されます。」
スタンタイムは、通常数百ミリ秒です。ただし、コミットフェーズ中にディスクの書き込みアクティビティが非常に高い場合には、スタンタイムが数秒に長引くことがあります。
> VM が、Caché データベースミラーリングに参加するプライマリまたはバックアップメンバーであり、スタンタイムがミラーのサービス品質(QoS)タイムアウトより長引く場合、ミラーはプライマリ VM に失敗としてレポートし、ミラーのテイクオーバーを開始します。
**2018 年 3 月更新:** 同僚の Pter Greskoff から指摘されました。バックアップミラーメンバーは、VM スタン中またはプライマリミラーメンバーが利用不可である場合には、QoS タイムアウトの半分超という短時間でフェイルオーバーを開始することがあります。
QoS の考慮事項とフェイルオーバーのシナリオの詳細については、「[Quality of Service Timeout Guide for Mirroring](https://community.intersystems.com/post/quality-service-timeout-guide-mirroring)(ミラーリングのサービス品質タイムアウトに関するガイド)」という素晴らしい記事を参照できますが、以下に、VM スタンタイムと QoS に関する要約を示します。
> バックアップミラーが、QoS タイムアウトの半分の時間内にプライマリミラーからメッセージを受信しない場合、ミラーはプライマリが動作しているかどうかを確認するメッセージを送信します。 それからバックアップはさらに QoS タイムアウトの半分の時間、プライマリマシンからの応答を待機します。 プライマリからの応答がない場合、プライマリは停止しているとみなされ、バックアップがテイクオーバーします。
ビジー状態のシステムでは、プライマリからバックアップミラーにジャーナルが継続的に送信されるため、バックアップはプライマリが動作しているかどうかを確認する必要はありません。 ただし、バックアップが発生している可能性が高い静止時間中、アプリケーションがアイドル状態である場合、QoS タイムアウトの半分以上の時間、プライマリとバックアップミラーの間でメッセージのやり取りがない可能性があります。
これは Peter が提示した例ですが、このタイムフレームを、QoS タイムアウトが :08 秒で VM スタンタイムが :07 秒のアイドル状態にあるシステムで考えてみましょう。
- :00 プライマリは キープライブでアービターに ping し、アービターは即座に応答
- :01 バックアップメンバーはプライマリにキープアライブを送信し、プライマリは即座に応答
- :02
- :03 VM スタンの開始
- :04 プライマリはアービターにキープアライブを送信しようとするが、スタンが完了するまで到達しない
- :05 QoS の半分の時間が経過したため、バックアップメンバーはプライマリに ping を送信
- :06
- :07
- :08 QoS タイムアウトが過ぎてもアービターはプライマリからの応答を受信しないため、接続を閉じる
- :09 バックアップはプライマリからの応答を受信していないため、接続が失われたことをアービターに確認し、テイクオーバーを開始
- :10 VM スタンが終了するが、間に合わない!!
上記のリンク先の記事にある「_Pitfalls and Concerns when Configuring your Quality of Service Timeout_(サービス品質タイムアウトを構成する際の落とし穴と考慮事項)」のセクションもお読みください。QoS を必要な期間だけ確保する際のバランスが説明されています。 QoS が長すぎる場合、特に 30 秒を超える場合も問題を引き起こす可能性があります。
**2018 年 3 月更新の終了:**
ミラーリングの QoS の詳細については、[ドキュメンテーション](https://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror#GHA_mirror_set_tunable_params_qos)を参照してください。
> スタンタイムを最小限に抑える戦略には、データベースアクティビティが低い場合にバックアップを実行することと、ストレージを十分にセットアップすることが挙げられます。
上記で述べたように、スナップショットの作成時に指定できるオプションがいくつかあります。その 1 つは、スナップショットにメモリ状態を含めることです。_Caché データベースのバックアップにはメモリ状態は不要である_ことに注意してください。 メモリフラグが設定されている場合、仮想マシンの内部状態のダンプがスナップショットに含められます。 メモリスナップショットの作成には、もっと長い時間がかかります。 メモリスナップショットは、実行中の仮想マシンの状態を、スナップショットが作成された時の状態に戻すために使用されます。 これは、データベースファイルのバックアップには必要ありません。
> メモリスナップショットを作成する場合、仮想マシンの状態全体が停止しますが、**スタンタイムはさまざま**です。
前述のとおり、バックアップでは、整合性のある使用可能なバックアップを保証するために、手動スナップショットで、またはバックアップソフトウェアによって、静止フラグを true に設定する必要があります。
## VMware ログでスタンタイムを確認
ESXi 5.0 より、スナップショットのスタンタイムは、以下のようなメッセージで仮想マシンのログファイル(vmware.log)に記録されます。
`2017-01-04T22:15:58.846Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 38123 us`
スタンタイムはミリ秒単位であるため、上記の例にある `38123 us` は 38123/1,000,000 秒または 0.038 秒となります。
スタンタイムが許容範囲内であることを確認するため、またはスタンタイムが長引くせいで問題が発生していると思われる場合にトラブルシューティングを実施するため、関心のある VM のフォルダから vmware.log ファイルをダウンロードして確認することができます。 ダウンロードしたら、以下の Linux コマンドの例を使うなどして、ログを抽出しソートできます。
### vmware.log ファイルのダウンロード例
vSphere 管理コンソールまたは ESXi ホストコマンドラインから VMware サポートバンドルを作成するなど、サポートログのダウンロードにはいくつかの方法があります。 全詳細については VMware ドキュメンテーションを参照できますが、以下は、スタンタイムを確認できるように、`vmware.log` ファイルを含む非常に小さなサポートバンドルを作成して収集する簡単な方法です。
VM ファイルが配置されているディレクトリの正式な名称が必要となります。 ssh を使用してデータベース VM が実行している ESXi ホストにログオンし、コマンド `vim-cmd vmsvc/getallvms ` を使用して vmx ファイルとそれに関連付けられた一意の正式名称を一覧表示します。
たとえば、この記事で使用されているデータベース VM の正式な名称は次のように出力されます。 `26 vsan-tc2016-db1 [vsanDatastore] e2fe4e58-dbd1-5e79-e3e2-246e9613a6f0/vsan-tc2016-db1.vmx rhel7_64Guest vmx-11`
次に、ログファイルのみを収集してバンドルするコマンドを実行します。
`vm-support -a VirtualMachines:logs`
コマンドによって、以下の例のように、サポートバンドルの場所が表示されます。 `To see the files collected, check '/vmfs/volumes/datastore1 (3)/esx-esxvsan4.iscinternal.com-2016-12-30--07.19-9235879.tgz'`.
これで、sftp を使用してファイルをホストから転送し、さらに処理して確認できるようになりました。
この例では、サポートバンドルを解凍した後に、データベース VM の正式名称に対応するパスに移動します。 この場合は、 `/vmfs/volumes//e2fe4e58-dbd1-5e79-e3e2-246e9613a6f0` というパスになります。
そこで番号付きの複数のログファイルが表示されます。最新のログファイルには番号は付きません。つまり、`vmware.log` と示されます。 ログはわずか数百 KB ですが、たくさんの情報が記載されています。ただし、注目するのは stun/unstun の時間のみで、`grep` を使うと簡単に見つけ出すことができます。 次は、その記載例です。
$ grep Unstun vmware.log
2017-01-04T21:30:19.662Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 1091706 us
---
2017-01-04T22:15:58.846Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 38123 us
2017-01-04T22:15:59.573Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 298346 us
2017-01-04T22:16:03.672Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 301099 us
2017-01-04T22:16:06.471Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 341616 us
2017-01-04T22:16:24.813Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 264392 us
2017-01-04T22:16:30.921Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 221633 us
この例では、2つのグループのスタンタイムを確認できます。1 つはスナップショップ作成時、そしてもう 1 つは、各ディスクのスナップショットが削除/統合された 45 分後(バックアップソフトウェアが読み取り専用 vmx ファイルのコピーを完了したとき)のものです。 上記の例では、最初のスタンタイムは 1 秒をわずかに上回っていますが、ほとんどのスタンタイムは 1 秒未満であることがわかります。
短時間のスタンタイムは、エンドユーザーが気付くものではありませんが、 Caché データベースミラーリングなどのシステムプロセスは、インスタンスが「アライブ」であるかどうかを継続的に監視しています。 スタンタイムがミラーリング QoS タイムアウトを超える場合、ノードは接続不可能であり「停止」状態とみなされ、フェイルオーバーがトリガーされます。
_ヒント:_ すべてのログを確認するか、トラブルシューティングを実行する場合には、grep コマンドが役立ちます。すべての `vmware*.log` ファイルに対して grep を使用し、異常値、またはスタンタイムが QoS タイムアウトに達しているインスタンスを探してください。 以下のコマンドは、出力をパイプ処理し、awk で書式設定しています。
`grep Unstun vmware* | awk '{ printf ("%'"'"'d", $8)} {print " ---" $0}' | sort -nr`
# 最後に
通常稼働時に定期的にシステムを監視し、スタンタイムと、ミラーリングなどの HA 向けの QoS タイムアウトへの影響を理解しておく必要があります。 前述のとおり、スタンタイムまたはスタン解除タイムを最小限に抑える戦略には、データベースとストレージのアクティビティが低い場合にバックアップを実行することと、ストレージを十分にセットアップすることが挙げられます。 常時監視の場合、ログは、VMware ログのインサイトなどのツールを使用して処理できるかもしれません。
InterSystems データプラットフォームのバックアップと復元操作について、今後の記事で再度取り上げる予定です。 それまでは、システムのワークフローに基づいたコメントや提案がある場合は、以下のコメントセクションに投稿してください。
記事
Toshihiko Minamoto · 2020年12月22日
HealthShare の理想的な Apache HTTPD Web サーバー構成に関するお問い合わせをよくいただいています。 この記事では、真っ先に推奨される HealthShare 製品の Web サーバー構成について概要を説明します。
何よりもまず第一に、Apache HTTPD バージョン 2.4.x(64ビット)を使用することをお勧めします。 2.2.x のような旧バージョンも使用できますが、HealthShare のパフォーマンスとスケーラビリティを確保するにはバージョン 2.2 はお勧めできません。
## **Apache の構成**
### NSD を使用しない Apache API モジュール {#ApacheWebServer-ApacheAPIModulewithoutNSD}
HealthShare では、NSD を使用しない Apache API モジュールをインストールオプションに指定する必要があります。 動的にリンクされるモジュールのバージョンは、Apache のバージョンによって異なります。
* CSPa24.so(Apache バージョン 2.4.x)
Apache の httpd.conf での Caché Server Pages の構成は、このドキュメントで詳しく説明する HealthShare のインストールによって実行するのが最善です。 ただし、この設定は手動で実行することもできます。 詳細については、InterSystems のドキュメントに掲載されている Apache 構成ガイド「推奨オプション:NSD を使用しない Apache API モジュール(CSPa24.so)」を参照してください。
## **Apache マルチプロセッシングモジュール(MPM)の推奨事項** {#ApacheWebServer-ApacheMulti-ProcessingModuleRecommendations}
### Apache Prefork MPM と Worker MPM {#ApacheWebServer-ApachePreforkMPMVs.WorkerMPM}
Apache HTTPD Web サーバーには、Prefork / Worker / Event の 3 つのマルチプロセッシングモジュール(MPM)が付属しています。 MPM はマシンのネットワークポートへのバインド、リクエストの受理、およびリクエストを処理するように子プロセスに割り当てたりする役割を担います。Apache はデフォルトで通常はトランザクションが多い場合や同時接続による負荷が高い場合には適切に拡張できない Prefork MPM で構成されています。
HealthShare の本番システムでは、Apache MPM **_Worker_** を有効にしてパフォーマンスとスケーラビリティを確保する必要があります。 Worker MPM が推奨される理由は次のとおりです。
* Prefork MPM はそれぞれ 1 つのスレッドを持つ複数の子プロセスを使用し、各プロセスが一度に 1 つの接続を処理します。 Prefork を使用する場合は各プロセスが一度に 1 つのリクエストしか処理できないため、同時リクエストが発生した場合に支障が出ます。この場合、リクエストはサーバープロセスが解放されるまでキューに格納されます。 また、スケーリングするには大量のメモリを消費する Prefork の子プロセスがさらに必要になります。
* Worker MPM は、それぞれ多数のスレッドを持つ複数の子プロセスを使用します。 各スレッドが一度に 1 つの接続を処理することで同時実行性が大幅に向上し、メモリ要件が低くなります。 Worker の場合はビジー状態の可能性があるシングルスレッドの Prefork プロセスとは異なり、通常はリクエストの処理に使用できる空きスレッドがあるため、Prefork よりも高度に同時リクエストを処理できます。
### Apache Worker MPM のパラメーター {#ApacheWebServer-ApacheWorkerMPMParameters}
Worker はスレッドを使用してリクエストを処理するため、Prefork プロセスベースのサーバーよりも少ないシステムリソースで多数のリクエストを処理できます。
Worker MPM の制御に使用される最も重要なディレクティブは、各子プロセスが生成するスレッドの数を制御する **ThreadsPerChild** と起動可能なスレッドの最大数を制御する **MaxRequestWorkers** です。
推奨される Worker MPM 共通ディレクティブの値を以下の表に詳しく記載しています。
推奨される Apache HTTPD Web サーバーのパラメーター
Apache Worker MPM のディレクティブ
推奨値
コメント
MaxRequestWorkers
HealthShare Clinical Viewer の最大同時接続ユーザー数、または他の HealthShare コンポーネントの場合は定義されているすべての本番インターフェースの着信ビジネスサービスのプールサイズの合計値に設定されます。* 注意: 構成時に不明であれば「1000」で開始してください
MaxRequestWorkers は同時に処理されるリクエストの数を制限します。つまり、クライアントにサービスを提供するために使用できるスレッドの総数を制限します。MaxRequestWorkers は低すぎる値に設定するとリソースが無駄になり、高すぎる値に設定するとサーバーのパフォーマンスに影響が出るため、正しく設定しなければなりません。Worker の数を超える接続があった場合、接続はキューに格納されてしまいます。 デフォルトのキューは、ListenBackLog ディレクティブで調整できます。
MaxSpareThreads
250
MaxSpareThreads はサーバー全体のアイドルなスレッドの数を制御します。 サーバー上にアイドルなスレッドが多すぎる場合、アイドルなスレッドの数がこの数より少なくなるまで子プロセスが強制終了されます。 スペアスレッドの量をデフォルトより多くすると、プロセスが再生成される確率が低くなります。
MinSpareThreads
75
MinSpareThreads はサーバー全体のアイドルなスレッドの数を制御します。 サーバー上にアイドルなスレッドが不足している場合、アイドルなスレッドの数がこの数より多くなるまで子プロセスが生成されます。 スペアスレッドの量をデフォルトより少なくすると、プロセスが再生成される確率が低くなります。
ServerLimit
MaxRequestWorkers を ThreadsPerChild で割った値
サーバー稼働中における MaxRequestWorkers の最大値です。 ServerLimit はアクティブな子プロセス数の厳密な上限値であり、MaxRequestWorkers ディレクティブを ThreadsPerChild ディレクティブで割った値以上である必要があります。 worker では MaxRequestWorkers および ThreadsPerChild の設定で 16(デフォルト)以上のサーバープロセスが必要な場合にのみ、このディレクティブを使用してください。
StartServers
20
StartServers ディレクティブは起動時に生成される子サーバープロセスの数を設定します。 プロセス数は負荷に応じて動的に制御されるため、サーバーが起動時に大量の接続を処理できるようにする場合を除き、通常はこのパラメーターを調整する理由はほとんどありません。
ThreadsPerChild
25
このディレクティブは各子プロセスが生成するスレッドの数を設定します。デフォルトでは 25 です。 デフォルト値を増やすと単一のプロセスに過度に依存する可能性があるため、デフォルト値を維持することをお勧めします。
詳細については、関連する Apache バージョンのドキュメントを参照してください。
* [Apache 2.4 の MPM 共通ディレクティブ](http://httpd.apache.org/docs/2.4/mod/mpm_common.html)
### Apache 2.4 の Worker MPM 構成の例 {#ApacheWebServer-ExampleApache2.4WorkerMPMConfiguration}
このセクションでは、最大 500 人の TrakCare ユーザーが同時接続できるようにするために必要な RHEL7 の Apache 2.4 Web サーバー用に Worker MPM の構成について詳しく説明します。
1. まず、以下のコマンドを使用して MPM を確認します。
2. 必要に応じて、構成ファイル /etc/httpd/conf.modules.d/00-mpm.conf を編集します。コメント文字 # の追加や削除を行い、Worker MPM モジュールのみがロードされるようにしてください。 Worker MPM セクションを、以下と同じ順序で次の値に変更します。
3. Apache を再起動します。
4. Apache が正常に再起動したら、以下のコマンドを実行して worker プロセスを検証します。 次のような内容が表示され、httpd.worker プロセスを確認できます。
## **Apache の強化** {#ApacheWebServer-ApacheHardening}
### Apache に必要なモジュール {#ApacheWebServer-ApacheRequiredModules}
公式の Apache 配布パッケージをインストールすると、デフォルトで特定の Apache モジュールセットが有効になります。 Apache のこのデフォルト構成では、これらのモジュールが各 httpd プロセスにロードされます。 次の理由により、HealthShare に必要のないすべてのモジュールを無効にすることをお勧めします。
* httpd デーモンプロセスのメモリ使用量が削減されます。
* 不正なモジュールに起因するセグメンテーション違反の可能性が低下します。
* セキュリティの脆弱性が削減されます。
HealthShare に推奨される Apache モジュールの詳細を以下の表に記載しています。 以下に掲載されていないモジュールは無効にすることができます。
| モジュール名 | 説明 |
| ----------- | ------------------------------------------------------------- |
| alias | ホストファイルシステム内のさまざまな場所をドキュメントツリーにマッピングする機能と、URL リダイレクト機能を提供します。 |
| authz_host | クライアントのホスト名、IPアドレスに基づいてアクセス制御を行います。 |
| dir | 末尾のスラッシュを補完してリダイレクトする機能と、ディレクトリのインデックスファイルを扱う機能を提供します。 |
| headers | HTTP リクエストとレスポンスヘッダーを制御および変更するためのモジュールです。 |
| log_config | サーバーに対して発行されるリクエストのログを記録します。 |
| mime | リクエストされたファイル名の拡張子をファイルの振る舞いと内容に関連付けます。 |
| negotiation | クライアントの特性に応じて最適なドキュメントの内容を選択する機能を提供します。 |
| setenvif | リクエストの特徴に基づいて環境変数を設定できるようにします。 |
| status | サーバーのステータスとパフォーマンスに関する統計を表示します。 |
### モジュールを無効にする
セキュリティの脆弱性を減らすように構成を強化するには、不要なモジュールを無効にする必要があります。 Web サーバーのセキュリティポリシーを管理するのはお客様の役割です。 少なくとも、以下のモジュールを無効にする必要があります。
| モジュール名 | 説明 |
| --------- | -------------------------------------------------------------------------------- |
| asis | 独自の HTTP ヘッダーを含むファイルを送信する機能を提供します。 |
| autoindex | index.html ファイルが存在しない場合にディレクトリインデックスを生成し、ディレクトリをリスト表示する機能を提供します。 |
| env | CGI スクリプトと SSI ページに渡される環境変数を変更する機能を提供します。 |
| cgi | cgi - CGI スクリプトを実行する機能を提供します。 |
| actions | メディアタイプまたはリクエストメソッドに基づいて CGI スクリプトを実行し、リクエストに応じてアクションをトリガーする機能を提供します。 |
| include | サーバーで解析された HTML ドキュメント(サーバーサイドインクルード)を使用可能にするモジュールです。 |
| filter | リクエストの高度なフィルタリング機能を提供します。 |
| version | IfVersion を使用して構成ファイル内でバージョン情報を処理できるようにします。 |
| userdir | リクエストをユーザー専用のディレクトリにマッピングする機能を提供します。 具体的には、URL の ~username がサーバー内のディレクトリに変換されます。 |
## **Apache SSL/TLS** {#ApacheWebServer-ApacheSSLTLS}
転送中のデータを保護し、機密性を確保して認証を行うため、InterSystems は HealthShare サーバーとクライアント間のすべての TCP/IP 通信を SSL/TLS で暗号化し、さらにはユーザーのブラウザクライアントと提案されたアーキテクチャの Web サーバーレイヤー間のすべての通信に HTTPS を使用することを推奨しています。 所属する組織に固有のセキュリティ要件に準拠していることを確認するには、必ず所属する組織のセキュリティポリシーを参照してください。
SSL/TLS 証明書を提供および管理するのはお客様の役割です。
SSL 証明書を使用している場合は、ssl\_module(mod\_ssl.so)を追加してください。
## **追加の Apache 強化パラメーター** {#ApacheWebServer-AdditionalHardeningApacheParameters}
Apache 構成をさらに強化するには、httpd.conf で次の変更を行ってください。
* 潜在的なクロスサイトトレーシングの問題を防ぐため、TraceEnable をオフにする必要があります。

* Web サーバーのバージョンが表示されないようにするため、ServerSignature をオフにする必要があります。

## 補足的な Apache 構成パラメーター {#ApacheWebServer-SupplementalApacheConfigurationParameters}
### Keep-Alive {#ApacheWebServer-Keep-Alive}
Apache の Keep-Alive 設定は、新しいリクエストのたびに新しい接続をオープンせず、同じ TCP 接続を使用して HTTP 通信を行えるようにするものです。 Keep-Alive はクライアントとサーバー間に持続的な接続を維持します。 Keep-Alive オプションを有効にすると、ネットワークの輻輳が軽減され、後続リクエストの遅延が少なくなり、同時接続のオープンに起因する CPU 消費が低下し、パフォーマンスが向上します。 Keep-Alive はデフォルトでオンになっており、HTTP v1.1 標準では当然オンにすることが求められています。
ただし、Keep-Alive を有効にする場合は注意が必要です。Internet Explorer は古いバージョンでの既知のタイムアウトの問題を回避するため、 IE10 以降でなければなりません。 また、ファイアウォール、ロードバランサー、プロキシなどの仲介者が「持続的なTCP接続」に干渉し、予期せず接続が閉じられてしまう可能性もあります。
Keep-Alive を有効にする場合は、Keep-Alive のタイムアウト値も設定する必要があります。 Apache デフォルトの Keep-Alive タイムアウト値は非常に小さく、壊れた AJAX(hyperevent などの)リクエストに関連して問題が発生する可能性があるため、ほとんどの構成では大きくする必要があります。 これらの問題は、サーバーの Keep-Alive タイムアウト値がクライアントのタイムアウト値よりも大きくなるように調整することで回避できます。 つまり、サーバーではなくクライアントがタイムアウトして接続を閉じるようにすべきです。 ブラウザが当然オープンしていると考えている接続を(特に POST する場合に)使用しようとすると、問題が発生します(ほとんどの場合は IE で発生し、他のブラウザではそれほど発生しません)。
HealthShare Web サーバーに推奨される KeepAlive と KeepAliveTimeout の値については、以下を参照してください。
Apache で KeepAlive を有効にするには、httpd.conf で以下のように変更を行ってください。

### CSP Gateway {#ApacheWebServer-CSPGateway}
CSP Gateway の KeepAlive パラメーターについては、各リクエストの HTTP レスポンスヘッダーによって KeepAlive のステータスが決まるため、この値はデフォルトの「No Action」のままにしてください。
記事
Toshihiko Minamoto · 2021年4月19日
**++更新日:2018年8月1日**
Cachéデータベースミラーリングに組み込まれているInterSystems仮想IP(VIP)アドレスの使用には、特定の制限があります。 具体的に言うと、ミラーメンバーが同じネットワークサブネットに存在する場合にのみ使用できるというところです。 複数のデータセンターを使用した場合は、ネットワークの複雑さが増すため、ネットワークサブネットが物理的なデータセンターを越えて「延伸」されることはさほどありません(より詳細な説明は[こちら](https://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror#GHA_mirror_set_comm_network_dual)です)。 同様の理由で、データベースがクラウドでホストされている場合、仮想IPは使用できないことがよくあります。
ロードバランサー(物理的または仮想)などのネットワークトラフィック管理のアプライアンスを使用して、クライアントアプリケーションやデバイスに単一のアドレスを提示することで、同レベルの透過性を実現できます。 ネットワークトラフィックマネージャは、クライアントを現在のミラープライマリの実際のIPアドレスに自動的にリダイレクトします。 この自動化は、災害後のHAフェイルオーバーとDRプロモーションの両方のニーズを満たすことを目的としています。
# ネットワークトラフィックマネージャーの統合
今日の市場には、ネットワークトラフィックのリダイレクトに対応する多数のオプションが存在します。 アプリケーション要件に基づいてネットワークフローを制御するために、これらのオプションはそれぞれ似たような方法論もしくは複数の方法論に対応しています。 これらの方法論を単純化するために、 _データベース_ _サーバー呼び出し型API、ネットワークアプライアンスポーリング、_または両方を組み合わせたものの、3つのカテゴリを検討していきます。
次のセクションでは、これらの方法論をそれぞれ概説し、各々をInterSystems製品と統合する方法について説明していきます。 すべてのシナリオでアービターは、ミラーメンバーが直接通信できない場合に安全なフェイルオーバーの判断を下すために使用されます。 アービターの詳細は、[こちら](http://docs.intersystems.com/cache20161/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror#GHA_mirror_set_arbiter)を参照してください。
この記事では、図の例は、プライマリ、バックアップ、およびDR非同期の3つのミラーメンバーを示すものとします。 ただし、ユーザーの構成には、ミラーメンバーがより多く含まれている場合、またはより少なく含まれている場合があるということは理解しております。
## オプション1:ネットワークアプライアンスのポーリング(_推奨_)
この方法では、ネットワーク負荷分散アプライアンスは、組み込みのポーリングメカニズムを使用して、両方のミラーメンバーと通信することでプライマリミラーメンバーを決定します。
2017.1で利用可能なCSP Gatewayの_mirror_status.cxw_ページを使用するポーリングメソッドは、ELBサーバープールに追加された各ミラーメンバーに対するELBヘルスモニターのポーリングメソッドとして使用できます。 プライマリミラーのみが「SUCCESS」と応答するため、ネットワークトラフィックはアクティブなプライマリミラーメンバーのみに転送されます。
このメソッドでは、^ZMIRRORにロジックを追加する必要はありません。 ほとんどの負荷分散ネットワークアプライアンスには、ステータスチェックの実行頻度に制限があることに注意してください。 通常、最高頻度は一般的にほとんどの稼働時間サービス水準合意書で許容される5秒以上に設定されています。
次のリソースへのHTTPリクエストは、【ローカル】キャッシュ構成のミラーメンバーのステータスをテストします。
**_ `/csp/bin/mirror_status.cxw`_**
それ以外の場合、ミラーステータスリクエストのパスは、実際のCSPページのリクエストに使用されるのと同じ階層構造を使用し、適切なキャッシュサーバーとネームスペースに解決されます。
例:/csp/user/ パスにある構成を提供するアプリケーションのミラーステータスをテストする場合は次のようになります。
**_ `/csp/user/mirror_status.cxw`_**
**注意:ミラーライセンスチェックを実行しても、CSPライセンスは消費されません。**
ターゲットインスタンスがアクティブなプライマリメンバーであるかどうかに応じて、ゲートウェイは以下のCSP応答のいずれかを返します。
**** 成功(プライマリメンバーである)**
_=============================== _
_ HTTP/1.1 200 OK_
_ Content-Type: text/plain_
_ Connection: close_
_ Content-Length: 7_
_ SUCCESS_
**** 失敗(プライマリメンバーではない)**
_===============================_
_ HTTP/1.1 503 Service Unavailable_
_ Content-Type: text/plain_
_ Connection: close_
_ Content-Length: 6_
_ FAILED_
**** 失敗(キャッシュサーバーが_Mirror_Status.cxw_のリクエストをサポートしていない)**
_===============================_
_ HTTP/1.1 500 Internal Server Error_
_ Content-Type: text/plain_
_ Connection: close_
_ Content-Length: 6_
_ FAILED_
ポーリングの例として、次の図を検討してみましょう。
フェイルオーバーは、同期フェイルオーバーミラーメンバー間で自動的に発生します:
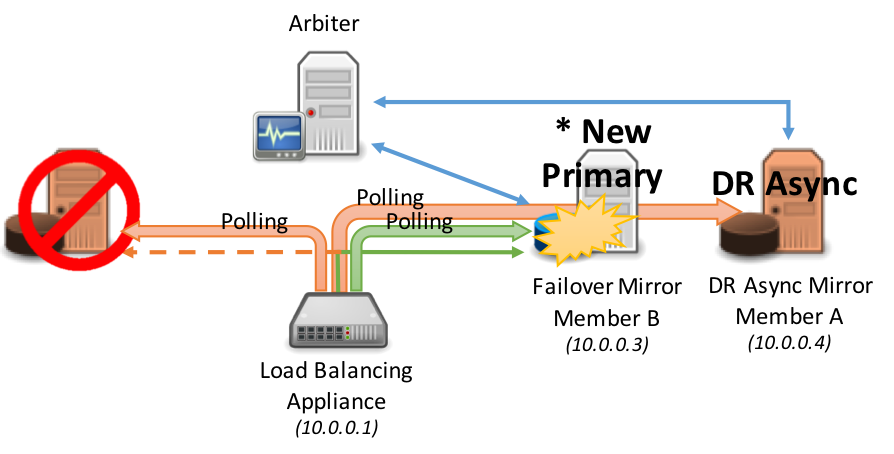
次の図は、DR非同期ミラーメンバーの負荷分散プールへの昇格を表しています。これは通常、同じ負荷分散ネットワークアプライアンスがすべてのミラーメンバーにサービスを提供していることを前提としています(地理的に分割されたシナリオについては、この記事の後半で説明します)。 標準のDR手順に従って、災害復旧メンバーの昇格には、人間による決定およびデータベースレベルでの簡単な管理アクションが必要になります。 ただし、そのアクションが実行されると、ネットワークアプライアンスでの管理アクションは必要ありません。新しいプライマリが自動的に検出されます。
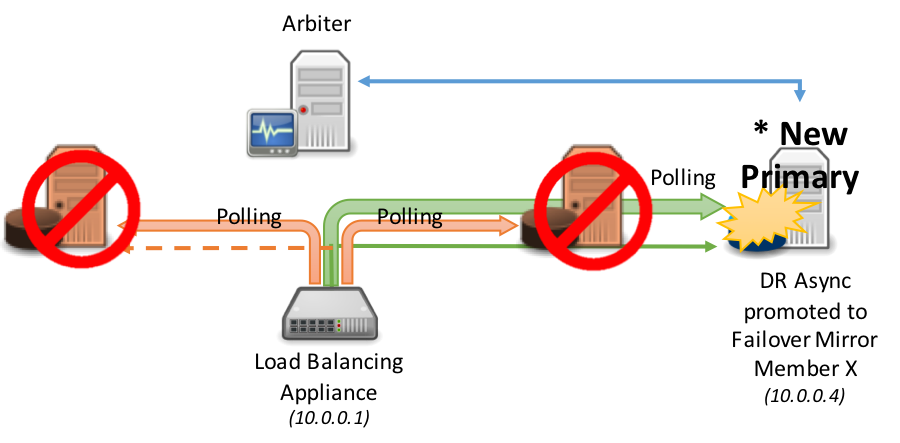
## オプション2:データベースサーバー呼び出し型API
この方法では、フェイルオーバーミラーメンバーと潜在的にDR非同期ミラーメンバーの両方で定義されたサーバープールがあり、ネットワークトラフィック管理アプライアンスが使用されます。
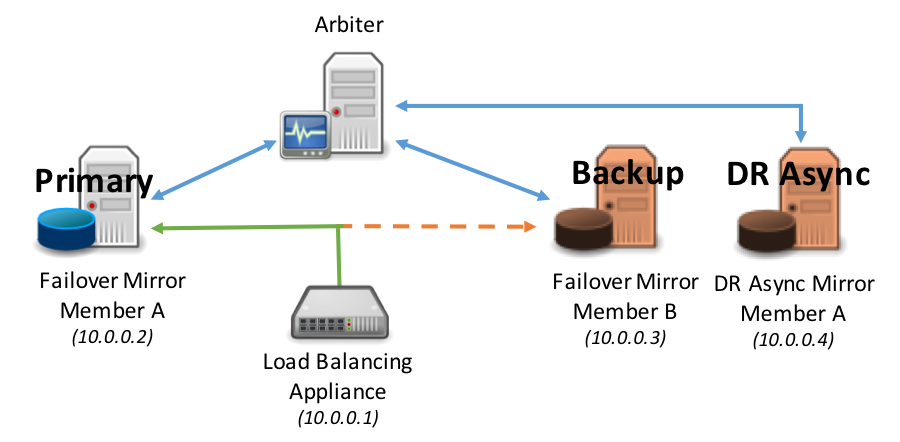
ミラーメンバーがプライマリミラーメンバーになると、優先度または重み付けを調整して、ネットワークトラフィックを新しいプライマリミラーメンバーに転送するようにネットワークアプライアンスにただちに指示を出すために、ネットワークアプライアンスに対してAPI呼び出しが実行されます。
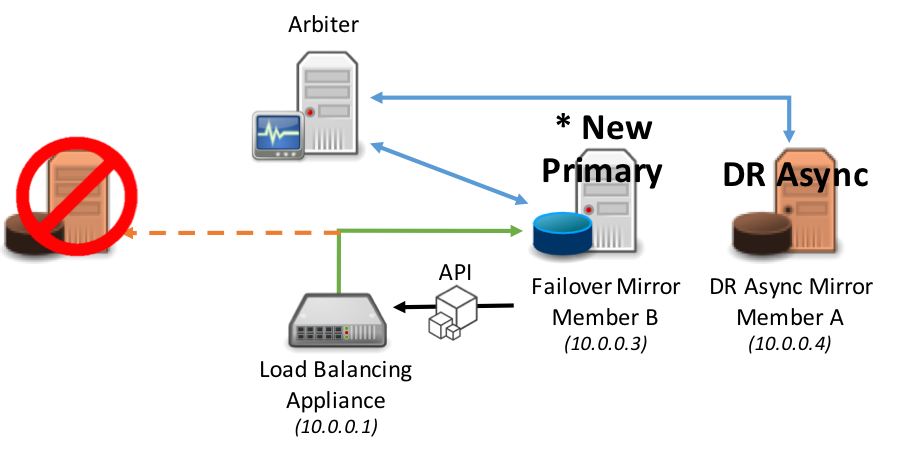
同様のモデルは、プライマリミラーメンバーとバックアップミラーメンバーの両方が利用できなくなった場合のDR非同期ミラーメンバーの昇格にも適用されます。
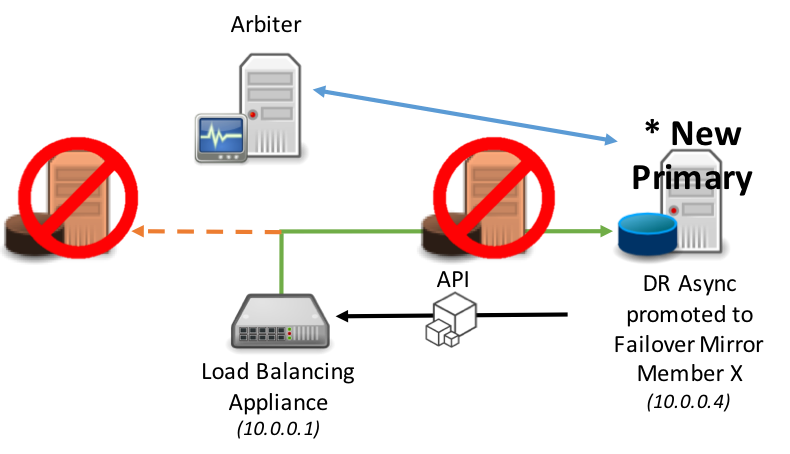
このAPIは、具体的には次のようにプロシージャコールの一部として^ZMIRRORルーチンで定義されています: **_$$CheckBecomePrimaryOK^ZMIRROR()_**
このプロシージャコールの中に、REST API、コマンドラインインターフェイスなど該当するネットワークアプライアンスで利用可能なAPIロジックやメソッドを挿入します。 仮想IPの場合と同様に、これは唐突なネットワーク構成の変更であり、障害が発生したプライマリミラーメンバーと接続している既存のクライアントに対し、フェイルオーバーが発生していることを通知するアプリケーションロジックは必要としません。 障害の性質によっては、障害そのものや、アプリケーションのタイムアウトやエラー、新しいプライマリによる古いプライマリインスタンスの強制停止、あるいはクライアントが使用したTCPキープアライブタイマーの失効が原因でこれらの接続が終了する可能性があります。
その結果、ユーザーは再接続してログインする必要がでてくるかもしれません。 この動作はあなたのアプリケーションの動作によって決まります。
## オプション3:地理的に分散された展開
複数のデータセンターを備えた構成や、複数のアベイラビリティーゾーンと地理的ゾーンを備えたクラウド展開など、地理的に分散された展開では、DNSベースの負荷分散とローカル負荷分散の両方を使用するシンプルでサポートしやすいモデルで地理的なリダイレクトの慣行を考慮する必要が生じます。
この組み合わせモデルでは、各データセンター、アベイラビリティーゾーン、またはクラウド地理的地域にあるネットワークロードバランサーと合わせて、Amazon Route 53、F5 Global Traffic Manager、Citrix NetScaler Global Server Load Balancing、Cisco Global SiteSelectorなどのDNSサービスと連携する追加のネットワークアプライアンスを導入します。
このモデルでは、前述のポーリング(_推奨_)またはAPIメソッドのいずれかが、ミラーメンバー(フェイルオーバーまたはDR非同期のいずれか)が稼働している場所に対してローカルで使用されます。 これは、トラフィックをいずれかのデータセンターに転送できるかどうかを地理的/グローバルネットワークアプライアンスに報告するために使用されます。 また、この構成では、ローカルネットワークトラフィック管理アプライアンスは、地理的/グローバルネットワークアプライアンスに独自のVIPを提示します。
通常の定常状態では、アクティブなプライマリミラーメンバーは、プライマリであることをローカルネットワークアプライアンスに報告し、「Up」ステータスを提供します。 この「Up」ステータスは、すべてのリクエストをこのアクティブなプライマリミラーメンバーに転送するためにDNSレコードを調整および維持するよう、地理的/グローバルアプライアンスに中継されます。
同じデータセンター内でフェイルオーバーが起きた場合(バックアップ同期ミラーメンバーがプライマリになった場合)は、APIまたはポーリング方式のいずれかがローカルロードバランサーで使用され、同じデータセンター内の新しいプライマリミラーメンバーにリダイレクトされます。 新しいプライマリミラーメンバーがアクティブであり、ローカルロードバランサーは引き続き「Up」ステータスで応答しているため、地理的/グローバルアプライアンスへの変更は行われません。
次の図で、ネットワークアプライアンスへのローカル統合のためにAPI方式を使用して、例を説明します。
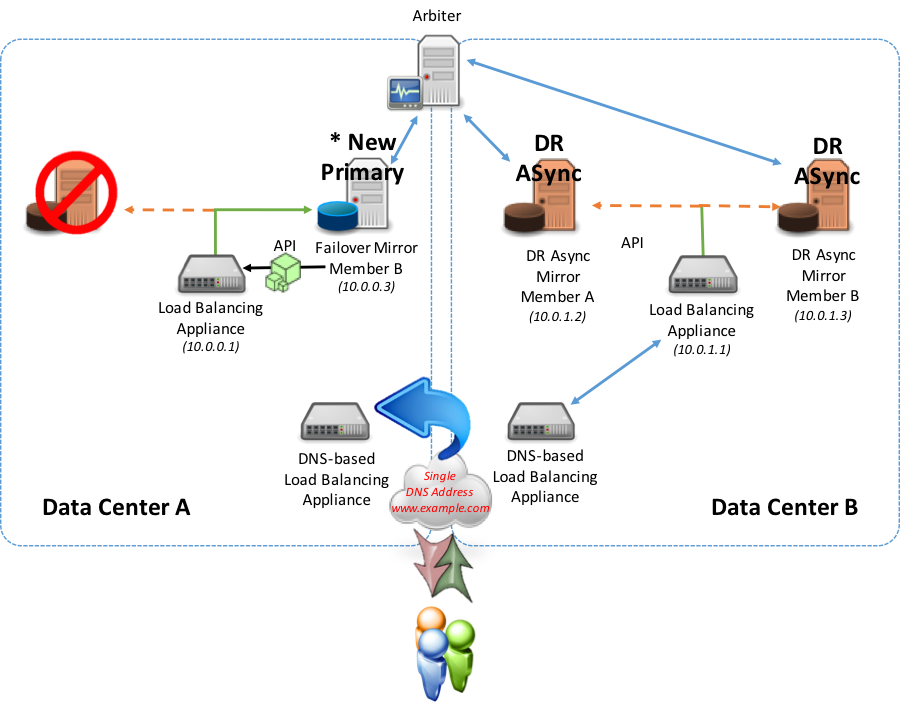
APIまたはポーリング方式のいずれかを使用した別のデータセンターへのフェイルオーバーが起きた場合(代替データセンターの同期ミラーまたはDR非同期ミラーメンバーの場合)は、新しく昇格されたプライマリミラーメンバーがプライマリとしてローカルネットワークアプライアンスへ報告を開始します。
フェイルオーバー中は、かつてプライマリが含まれていたデータセンターは、ローカルロードバランサから地理的/グローバルへの「Up」を報告しなくなります。 地理的/グローバルアプライアンスは、トラフィックをそのローカルアプライアンスには転送しません。 代替データセンターのローカルアプライアンスは、地理的/グローバルアプライアンスに「Up」と報告し、DNSレコードの更新を呼び出して、代替データセンターのローカルロードバランサーによって提示された仮想IPに転送するようにします。
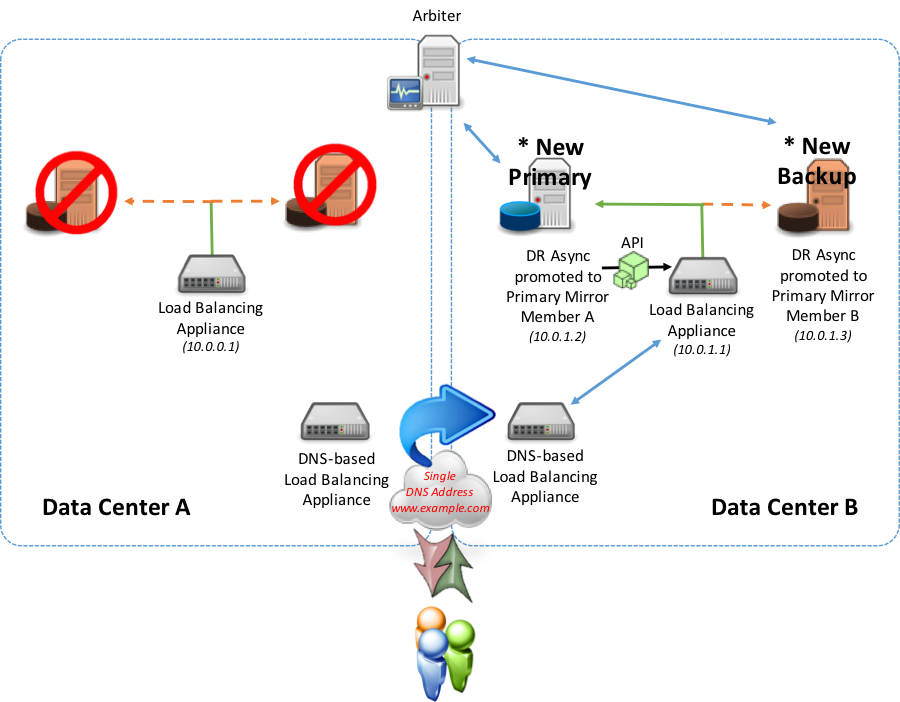
## オプション4:多層的、および地理的に分散された展開
ソリューションをさらに一歩進めるには、プライベートWANの内部として、またはインターネット経由でアクセス可能なものとして、個別のWebサーバー層を導入します。 恐らくこのオプションは、大規模なエンタープライズアプリケーションの一般的な展開モデルです。
次の例では、複数のネットワークアプライアンスを使用して、Web層とデータベース層を安全に分離およびサポートする構成例を示しています。 このモデルでは、地理的に分散された2つの場所が使用され、1つは「プライマリ」場所と見なされ、もう1つはデータベース層用「災害復旧」専用の場所です。 データベース層災害復旧の場所は、プライマリな場所が何らかの理由で運転休止になった場合に使用されます。 さらに、この例のWeb層は、アクティブ - アクティブとして示されます。つまりユーザーは、最小の遅延、最小の接続数、IPアドレス範囲、または適切と思われるその他のルーティンルールなど、さまざまなルールに基づいていずれかの場所に転送されます。
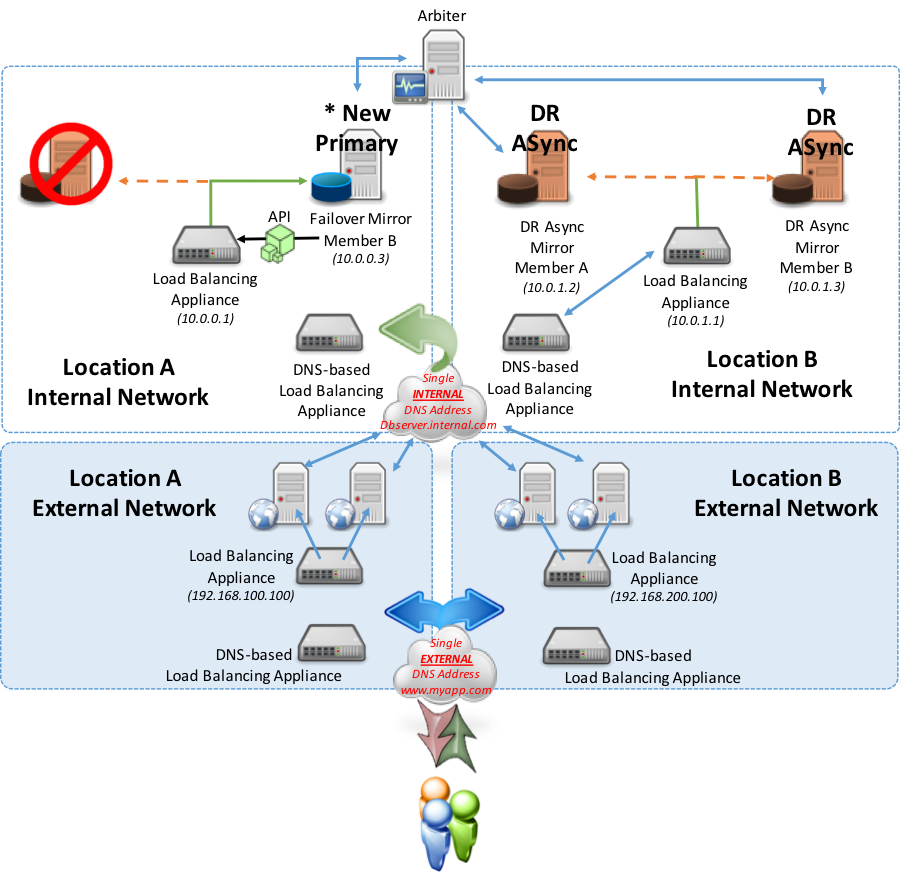
上記の例が示すように、同じ場所でフェイルオーバーが起きた場合は、自動フェイルオーバーが発生し、ローカルネットワークアプライアンスが新しいプライマリを指すようになります。 ユーザーは引き続きいずれかの場所のWebサーバーに接続し、Webサーバーは関連付けられたCSPゲートウェイで引き続き場所Aを指します。
次の例では、プライマリフェイルオーバーミラーメンバーとバックアップフェイルオーバーミラーメンバーの両方が稼働していないロケーションAでの完全フェイルオーバーまたは運転休止について検討します。 このような場合、DR非同期ミラーメンバーは、プライマリおよびバックアップフェイルオーバーミラーメンバーに手動で昇格されます。 昇格されると、新しく指定されたプライマリミラーメンバーにより、ロケーションBの負荷分散アプライアンスが前述のAPIメソッドを使用して「Up」を報告できるようになります(ポーリングメソッドもオプションの1つです)。 ローカルロードバランサーが「Up」を報告するようになった結果、DNSベースのアプライアンスはそれを認識し、データベースサーバーサービスのためにトラフィックを場所Aから場所Bにリダイレクトします。
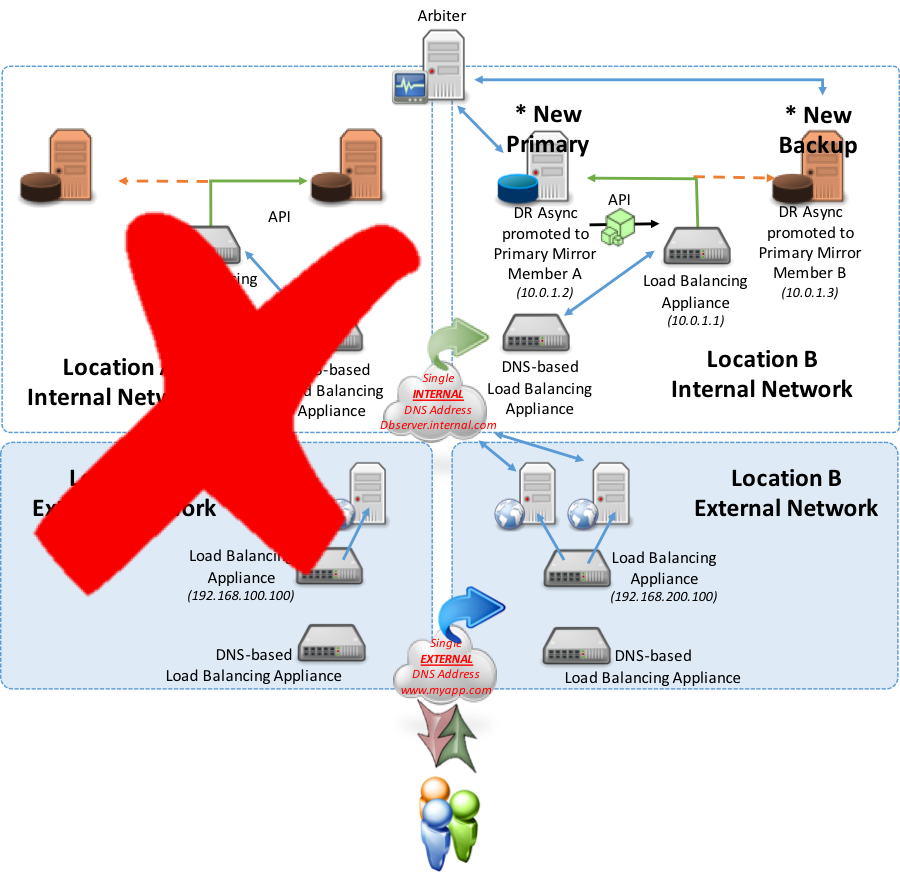
## まとめ
仮想IPを使用しないにミラーフェイルオーバーを設計するには、さまざまな組み合わせが考えられます。 これらのオプションは、最も単純な高可用性シナリオまたはフェイルオーバーとDR非同期ミラーメンバーの両方を含む複数の層を備えた複数の地域に渡る展開のいずれにも適用でき、アプリケーションの最高レベルの運用回復力を維持することを目的とした、可用性が高く災害に強いソリューションを実現できます。
この記事では、あなたのアプリケーションと可用性の要件に適したフェイルオーバーを備えたデータベースミラーリングを正常に展開するために可能なさまざまな組み合わせと活用事例に関して説明いたしました。
記事
Mihoko Iijima · 2022年2月28日
開発者のみなさん、こんにちは。
今回は、スーパーやコンビニでもらうレシートを写真で撮り、OCR を使ってレシートの画像から文字列を切り出して IRIS に登録する流れを試してみました。
サンプルでは、Google の Vision API を利用してレシートの JPG 画像から購入物品をテキストで抽出しています。
サンプルコード一式 👉 https://github.com/Intersystems-jp/iris-embeddedpython-OCR
最初、オンラインラーニングで使っている 「tesseract-OCR」を使ってみようと思ったのですが、レシートには半角カナが混在していたりで、半カナがなかなかうまく切り出せず、あきらめました・・(半角カナがなかったら日本語もばっちり読めていたのですが・・)
もし、tesseract-OCR で半カナを切り出す良い方法をご存知の方いらっしゃいましたら、ぜひ教えてください!
今回試すにあたり、Vision API の使い方を詳しく書いているページがありましたのでコードなど参考させていただきました。ありがとうございました。
【Google Colab】Vision APIで『レシートOCR』
全体の流れですが、レシートの写真を JPG にし、Python の google-cloud-vision モジュールを使用して JPG を Vision API に渡し、テキストを切り出します。
切り出されたテキストを画像の位置に合わせて一旦ソートし、レシートに記載されているものが店名なのか、商品名なのか、金額なのか、など、IRIS に登録したい項目を Python の正規表現モジュール re を使用してチェックし IRIS に登録しています。
IRIS にデータを登録する部分はSQLでもできますが、今回のサンプルでは1対多のリレーションシップを使った永続クラスを利用しています。
(永続クラスに対してSQLでも操作ができるので、お好みの文法で操作できます)
1側クラス:Okaimono.Receipt
レシートの基本情報を格納します。(店名、買い物時間、購入合計、割引金額など)
多側クラス:Okaimono.Item
レシートに記載された詳細項目の項目名と金額を格納します。
サンプルの実行方法については、こちらをご参照ください。
以下、コードについて少しご紹介します。
Python 側のコード:receipt.py は、ほぼこちらの素晴らしい記事👉【Google Colab】Vision APIで『レシートOCR』 を参考にさせていただきましたので、詳しくは記事をご参照ください。
Vision API で切り出したテキストですが、IRISへ登録するために必要な情報を正規表現で取り出して Python の list に設定し、receiptIRIS.py に渡して IRIS に保存しています。
レシートの項目ですが、お店によって表記が様々だったため(半カナ混在だったり全角だけだったり、記号が付いたりつかなかったり、など)、ご紹介するサンプルでは「オーケー」のレシートに合った正規表現を利用しています。コンビニや他スーパーの場合、サンプルの正規表現に合わないと思いますので、receipt.py の 72 行目~ 80 行目辺りをご変更いただくことで、お好みのレシートを読めるようになります。ぜひお試しください。
今回、IRIS に登録するデータは、1対多のリレーションシップクラスを利用しているので、データの登録には SQL ではなくオブジェクトの文法を利用しています(もちろんSQLでも登録できます)。
具体的にどんなコードを書いているかというと、前回の記事「Embedded Python 試してみました」と同様に、Python から IRIS 内のクラスを操作するための iris モジュールのインポートと、クラスの操作に使用する iris.cls() を利用しています。
Okaimono.Receipt のインスタンス生成は以下の通りです。
import iris
receipt=iris.cls("Okaimono.Receipt")._New()
receipt.StoreName="○×商店"
そして、作成された Python の list を読みながら、レシートの詳細項目を登録します。
コードはこんな感じです。
Okaimono.Item のインスタンスを生成し、Name プロパティとPrice プロパティに値を登録し、
item=iris.cls("Okaimono.Item")._New()
item.Name="チョコ"
item.Price="100"
Okaimono.Item のインスタンス と Okaimono.Receipt のインスタンスを関連付けます。(Okaimono.Item クラスの Receiptリレーションシッププロパティを利用して Okaimono.Receipt クラスのインスタンスを代入しています)
item.Receipt=receipt
この方法の他に、1側の Okaimono.Receipt の Items プロパティ(リレーションシッププロパティ)に提供される Insert() メソッドを使用して Okaimono.Item のインスタンスを Okaimono.Receipt のインスタンスに割り当てる方法もあります。(どちらか一方の割り当て方法で大丈夫です)
receipt.Items.Insert(item)
上記操作をレシートに記載された購入品目分実行し、最後にレシートを IRIS に保存します。
st=receipt._Save()
これで、Okaimono.Receipt に紐づく Okaimono.Item が一括で保存されます。
以下の文例は、2つの商品を購入したときのレシート登録例です。
USER>do ##class(%SYS.Python).Shell()
Python 3.9.5 (default, Jan 25 2022, 13:57:42) [MSC v.1927 64 bit (AMD64)] on win32
Type quit() or Ctrl-D to exit this shell.
>>> import iris
>>> receipt=iris.cls("Okaimono.Receipt")._New()
>>> receipt.StoreName="テストストア"
>>> receipt.TotalPrice=778
>>> it1=iris.cls("Okaimono.Item")._New()
>>> it1.Name="お弁当"
>>> it1.Price=598
>>> receipt.Items.Insert(it1)
1
>>> it2=iris.cls("Okaimono.Item")._New()
>>> it2.Name="ジュース"
>>> it2.Price=180
>>> it2.Receipt=receipt
>>> receipt._Save()
1
>>>
登録されたデータを確認します。
IRIS では、1対多のリレーションシップ定義を行った場合、多側クラス(Okaimono.Item)のリレーションシップ用プロパティ:Receipt が外部キーカラムのようにテーブルに投影されます。
以下、確認例です。
まずは、Okaimono.Receipt データを確認します。
SELECT * FROM Okaimono.Receipt
上記実行例では、「テストストア」のデータは ID=2 で登録されています。
続いて、Okaimono.Item データを確認します。
SELECT * FROM Okaimono.Item
Receipt 列には、リレーションシッププロパティで定義した1側クラス(Okaimono.Receipt)の ID が登録されていることがわかります。
では、次に、Receipt が 2(Okaimono.Receipt の ID=2)の Okaimono.Item 全情報と Okaimono.Receipt の StoreName と TotalPrice を取得してみます。
SELECT *,Receipt->StoreName,Receipt->TotalPrice FROM Okaimono.Item Where Receipt=2
IRIS 独自の矢印構文(->)を利用しています。この構文はオブジェクトの定義によって作成された外部キー用カラムを利用して、参照先テーブルのカラムを指定できる文法で、Receipt->StoreName は、Okaimono.Item テーブルに紐づく Okaimono.Receipt テーブルの StoreName カラムを指定しています。
これは、1対多のリレーションシップやオブジェクト参照を利用している場合に利用できる方法で、内部的には左外部結合と一緒の処理を行っています。
IRIS 独自の書き方ではありますが、意外とすっきりと記述できるので見やすさ重視の場合に利用いただくケースもあります。
矢印構文について詳細はドキュメントもご参照ください。
ちなみに、Pythonシェル上で 1件の Okaimono.Receipt をオープンし、Okaimono.Receipt に紐づく Okaimono.Item を取得する場合のオブジェクトの文法は以下の通りです。
ID=2 の Okaimono.Receipt をオープンします。
>>> r1=iris.cls("Okaimono.Receipt")._OpenId(2)
何個の Okaimono.Item と紐づいているか確認するには、Okaimono.Receipt クラスのリレーションシッププロパティ=Items に対して Count() を使用します。
>>> r1.Items.Count()
2
1件目の Okaimono.Item を取得する例は以下の通りです。
>>> it1=r1.Items.GetAt(1)
>>> it1.Name
'お弁当'
>>> it1.Price
598
2件目も確認してみます。
>>> it2=r1.Items.GetAt(2)
>>> it2.Name
'ジュース'
>>> it2.Price
180
こんな感じで、SQLからもオブジェクトからも操作できることが確認できました。
Embedded Python の登場で、Python の便利なモジュールや公開されているサンプルコードが IRIS から実行しやすくなりました。
みなさんのお手元でもぜひお試しください!
そして、お試しいただいた内容など、お気軽にコミュニティに投稿してみてください!お待ちしてます🔥