仮想IPアドレスを使用しないデータベースミラーリング
++更新日:2018年8月1日
Cachéデータベースミラーリングに組み込まれているInterSystems仮想IP(VIP)アドレスの使用には、特定の制限があります。 具体的に言うと、ミラーメンバーが同じネットワークサブネットに存在する場合にのみ使用できるというところです。 複数のデータセンターを使用した場合は、ネットワークの複雑さが増すため、ネットワークサブネットが物理的なデータセンターを越えて「延伸」されることはさほどありません(より詳細な説明はこちらです)。 同様の理由で、データベースがクラウドでホストされている場合、仮想IPは使用できないことがよくあります。
ロードバランサー(物理的または仮想)などのネットワークトラフィック管理のアプライアンスを使用して、クライアントアプリケーションやデバイスに単一のアドレスを提示することで、同レベルの透過性を実現できます。 ネットワークトラフィックマネージャは、クライアントを現在のミラープライマリの実際のIPアドレスに自動的にリダイレクトします。 この自動化は、災害後のHAフェイルオーバーとDRプロモーションの両方のニーズを満たすことを目的としています。
ネットワークトラフィックマネージャーの統合
今日の市場には、ネットワークトラフィックのリダイレクトに対応する多数のオプションが存在します。 アプリケーション要件に基づいてネットワークフローを制御するために、これらのオプションはそれぞれ似たような方法論もしくは複数の方法論に対応しています。 これらの方法論を単純化するために、 データベース _サーバー呼び出し型API、ネットワークアプライアンスポーリング、_または両方を組み合わせたものの、3つのカテゴリを検討していきます。
次のセクションでは、これらの方法論をそれぞれ概説し、各々をInterSystems製品と統合する方法について説明していきます。 すべてのシナリオでアービターは、ミラーメンバーが直接通信できない場合に安全なフェイルオーバーの判断を下すために使用されます。 アービターの詳細は、こちらを参照してください。
この記事では、図の例は、プライマリ、バックアップ、およびDR非同期の3つのミラーメンバーを示すものとします。 ただし、ユーザーの構成には、ミラーメンバーがより多く含まれている場合、またはより少なく含まれている場合があるということは理解しております。
オプション1:ネットワークアプライアンスのポーリング(推奨)
この方法では、ネットワーク負荷分散アプライアンスは、組み込みのポーリングメカニズムを使用して、両方のミラーメンバーと通信することでプライマリミラーメンバーを決定します。
2017.1で利用可能なCSP Gatewayの_mirror_status.cxw_ページを使用するポーリングメソッドは、ELBサーバープールに追加された各ミラーメンバーに対するELBヘルスモニターのポーリングメソッドとして使用できます。 プライマリミラーのみが「SUCCESS」と応答するため、ネットワークトラフィックはアクティブなプライマリミラーメンバーのみに転送されます。
このメソッドでは、^ZMIRRORにロジックを追加する必要はありません。 ほとんどの負荷分散ネットワークアプライアンスには、ステータスチェックの実行頻度に制限があることに注意してください。 通常、最高頻度は一般的にほとんどの稼働時間サービス水準合意書で許容される5秒以上に設定されています。
次のリソースへのHTTPリクエストは、【ローカル】キャッシュ構成のミラーメンバーのステータスをテストします。
_ /csp/bin/mirror_status.cxw_
それ以外の場合、ミラーステータスリクエストのパスは、実際のCSPページのリクエストに使用されるのと同じ階層構造を使用し、適切なキャッシュサーバーとネームスペースに解決されます。
例:/csp/user/ パスにある構成を提供するアプリケーションのミラーステータスをテストする場合は次のようになります。
_ /csp/user/mirror_status.cxw_
注意:ミラーライセンスチェックを実行しても、CSPライセンスは消費されません。
ターゲットインスタンスがアクティブなプライマリメンバーであるかどうかに応じて、ゲートウェイは以下のCSP応答のいずれかを返します。
**** 成功(プライマリメンバーである)**
_=============================== _
_ HTTP/1.1 200 OK_
_ Content-Type: text/plain_
_ Connection: close_
_ Content-Length: 7_
_ SUCCESS_
**** 失敗(プライマリメンバーではない)**
===============================
_ HTTP/1.1 503 Service Unavailable_
_ Content-Type: text/plain_
_ Connection: close_
_ Content-Length: 6_
_ FAILED_
**** 失敗(キャッシュサーバーが_Mirror_Status.cxw_のリクエストをサポートしていない)**
===============================
_ HTTP/1.1 500 Internal Server Error_
_ Content-Type: text/plain_
_ Connection: close_
_ Content-Length: 6_
_ FAILED_
ポーリングの例として、次の図を検討してみましょう。
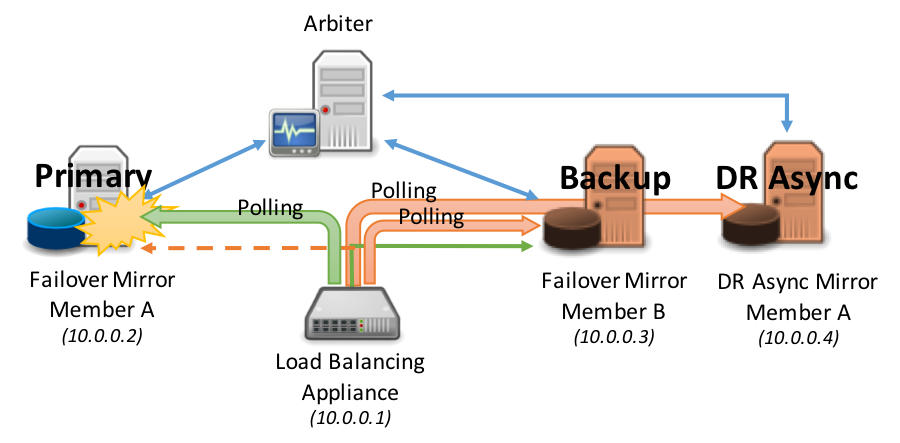
フェイルオーバーは、同期フェイルオーバーミラーメンバー間で自動的に発生します:
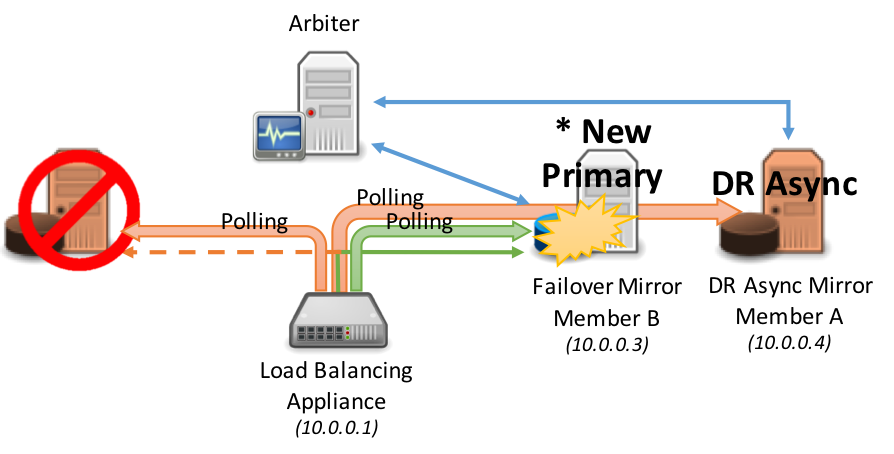
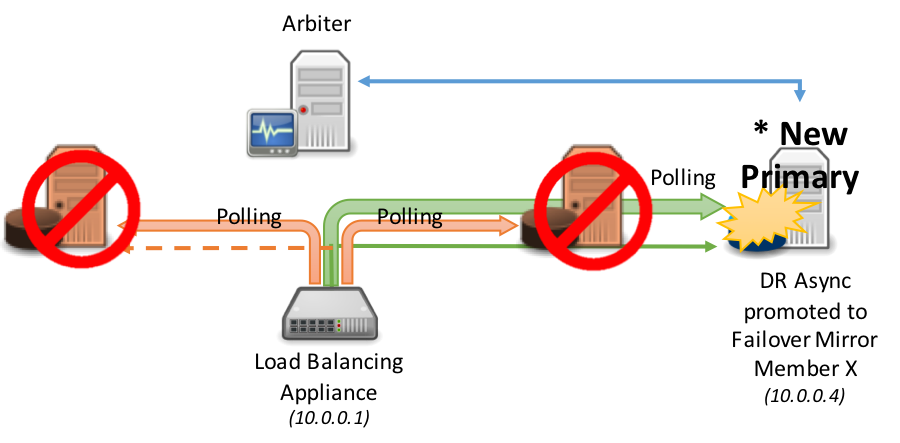
次の図は、DR非同期ミラーメンバーの負荷分散プールへの昇格を表しています。これは通常、同じ負荷分散ネットワークアプライアンスがすべてのミラーメンバーにサービスを提供していることを前提としています(地理的に分割されたシナリオについては、この記事の後半で説明します)。 標準のDR手順に従って、災害復旧メンバーの昇格には、人間による決定およびデータベースレベルでの簡単な管理アクションが必要になります。 ただし、そのアクションが実行されると、ネットワークアプライアンスでの管理アクションは必要ありません。新しいプライマリが自動的に検出されます。
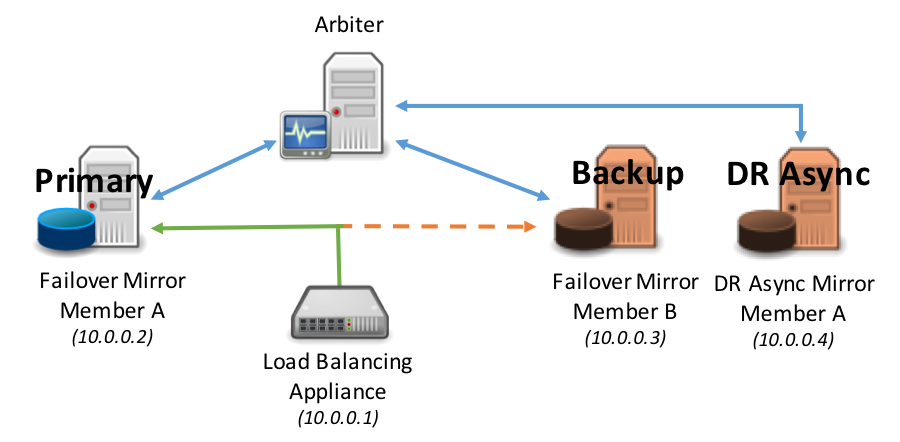
オプション2:データベースサーバー呼び出し型API
この方法では、フェイルオーバーミラーメンバーと潜在的にDR非同期ミラーメンバーの両方で定義されたサーバープールがあり、ネットワークトラフィック管理アプライアンスが使用されます。
ミラーメンバーがプライマリミラーメンバーになると、優先度または重み付けを調整して、ネットワークトラフィックを新しいプライマリミラーメンバーに転送するようにネットワークアプライアンスにただちに指示を出すために、ネットワークアプライアンスに対してAPI呼び出しが実行されます。
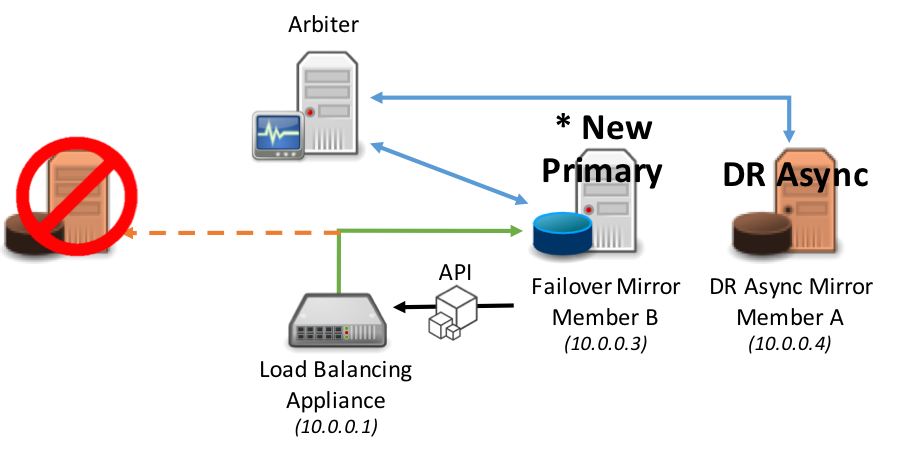
同様のモデルは、プライマリミラーメンバーとバックアップミラーメンバーの両方が利用できなくなった場合のDR非同期ミラーメンバーの昇格にも適用されます。
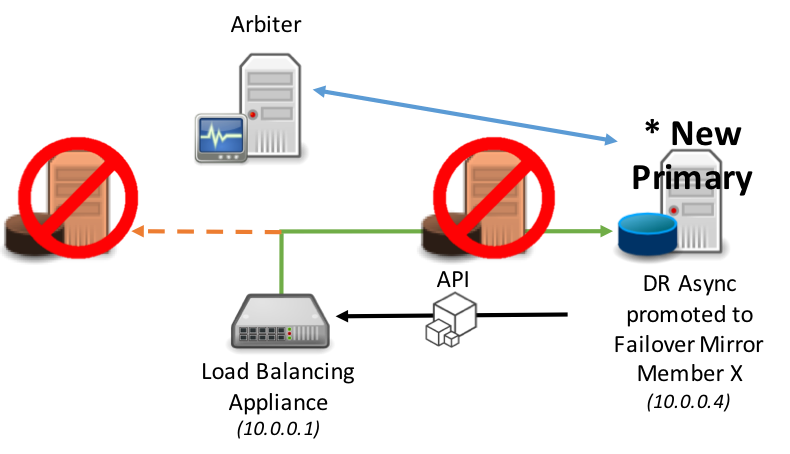
このAPIは、具体的には次のようにプロシージャコールの一部として^ZMIRRORルーチンで定義されています: $$CheckBecomePrimaryOK^ZMIRROR()
このプロシージャコールの中に、REST API、コマンドラインインターフェイスなど該当するネットワークアプライアンスで利用可能なAPIロジックやメソッドを挿入します。 仮想IPの場合と同様に、これは唐突なネットワーク構成の変更であり、障害が発生したプライマリミラーメンバーと接続している既存のクライアントに対し、フェイルオーバーが発生していることを通知するアプリケーションロジックは必要としません。 障害の性質によっては、障害そのものや、アプリケーションのタイムアウトやエラー、新しいプライマリによる古いプライマリインスタンスの強制停止、あるいはクライアントが使用したTCPキープアライブタイマーの失効が原因でこれらの接続が終了する可能性があります。
その結果、ユーザーは再接続してログインする必要がでてくるかもしれません。 この動作はあなたのアプリケーションの動作によって決まります。
オプション3:地理的に分散された展開
複数のデータセンターを備えた構成や、複数のアベイラビリティーゾーンと地理的ゾーンを備えたクラウド展開など、地理的に分散された展開では、DNSベースの負荷分散とローカル負荷分散の両方を使用するシンプルでサポートしやすいモデルで地理的なリダイレクトの慣行を考慮する必要が生じます。
この組み合わせモデルでは、各データセンター、アベイラビリティーゾーン、またはクラウド地理的地域にあるネットワークロードバランサーと合わせて、Amazon Route 53、F5 Global Traffic Manager、Citrix NetScaler Global Server Load Balancing、Cisco Global SiteSelectorなどのDNSサービスと連携する追加のネットワークアプライアンスを導入します。
このモデルでは、前述のポーリング(推奨)またはAPIメソッドのいずれかが、ミラーメンバー(フェイルオーバーまたはDR非同期のいずれか)が稼働している場所に対してローカルで使用されます。 これは、トラフィックをいずれかのデータセンターに転送できるかどうかを地理的/グローバルネットワークアプライアンスに報告するために使用されます。 また、この構成では、ローカルネットワークトラフィック管理アプライアンスは、地理的/グローバルネットワークアプライアンスに独自のVIPを提示します。
通常の定常状態では、アクティブなプライマリミラーメンバーは、プライマリであることをローカルネットワークアプライアンスに報告し、「Up」ステータスを提供します。 この「Up」ステータスは、すべてのリクエストをこのアクティブなプライマリミラーメンバーに転送するためにDNSレコードを調整および維持するよう、地理的/グローバルアプライアンスに中継されます。
同じデータセンター内でフェイルオーバーが起きた場合(バックアップ同期ミラーメンバーがプライマリになった場合)は、APIまたはポーリング方式のいずれかがローカルロードバランサーで使用され、同じデータセンター内の新しいプライマリミラーメンバーにリダイレクトされます。 新しいプライマリミラーメンバーがアクティブであり、ローカルロードバランサーは引き続き「Up」ステータスで応答しているため、地理的/グローバルアプライアンスへの変更は行われません。
次の図で、ネットワークアプライアンスへのローカル統合のためにAPI方式を使用して、例を説明します。
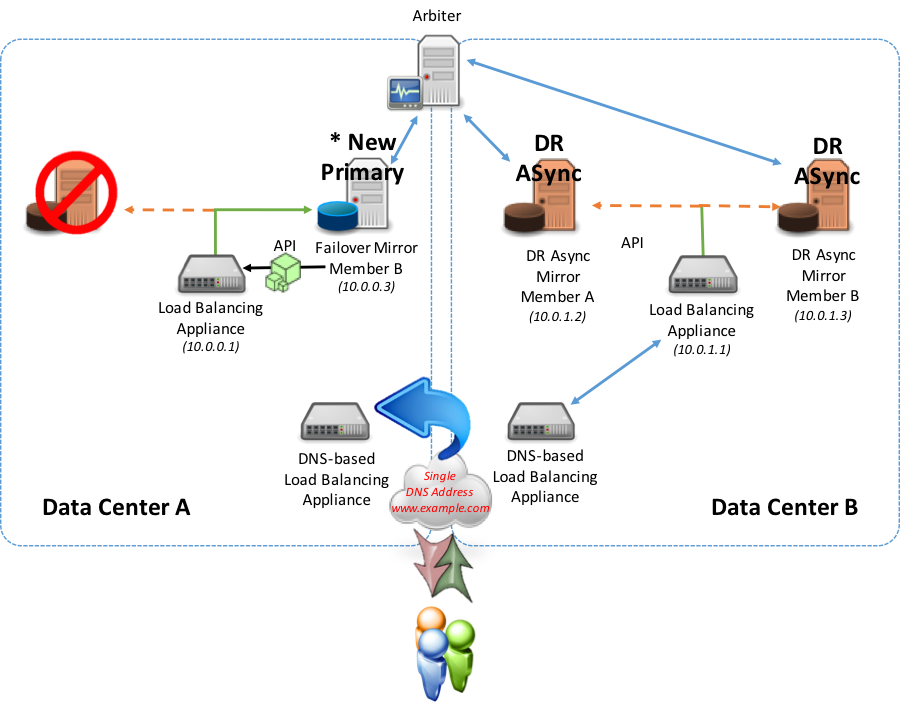
APIまたはポーリング方式のいずれかを使用した別のデータセンターへのフェイルオーバーが起きた場合(代替データセンターの同期ミラーまたはDR非同期ミラーメンバーの場合)は、新しく昇格されたプライマリミラーメンバーがプライマリとしてローカルネットワークアプライアンスへ報告を開始します。
フェイルオーバー中は、かつてプライマリが含まれていたデータセンターは、ローカルロードバランサから地理的/グローバルへの「Up」を報告しなくなります。 地理的/グローバルアプライアンスは、トラフィックをそのローカルアプライアンスには転送しません。 代替データセンターのローカルアプライアンスは、地理的/グローバルアプライアンスに「Up」と報告し、DNSレコードの更新を呼び出して、代替データセンターのローカルロードバランサーによって提示された仮想IPに転送するようにします。
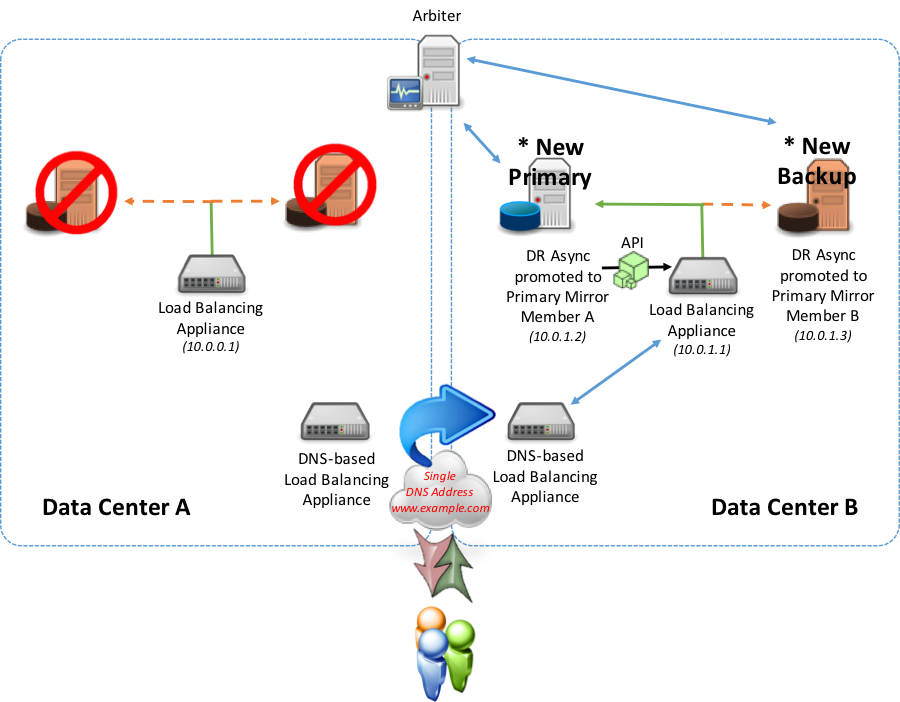
オプション4:多層的、および地理的に分散された展開
ソリューションをさらに一歩進めるには、プライベートWANの内部として、またはインターネット経由でアクセス可能なものとして、個別のWebサーバー層を導入します。 恐らくこのオプションは、大規模なエンタープライズアプリケーションの一般的な展開モデルです。
次の例では、複数のネットワークアプライアンスを使用して、Web層とデータベース層を安全に分離およびサポートする構成例を示しています。 このモデルでは、地理的に分散された2つの場所が使用され、1つは「プライマリ」場所と見なされ、もう1つはデータベース層用「災害復旧」専用の場所です。 データベース層災害復旧の場所は、プライマリな場所が何らかの理由で運転休止になった場合に使用されます。 さらに、この例のWeb層は、アクティブ - アクティブとして示されます。つまりユーザーは、最小の遅延、最小の接続数、IPアドレス範囲、または適切と思われるその他のルーティンルールなど、さまざまなルールに基づいていずれかの場所に転送されます。
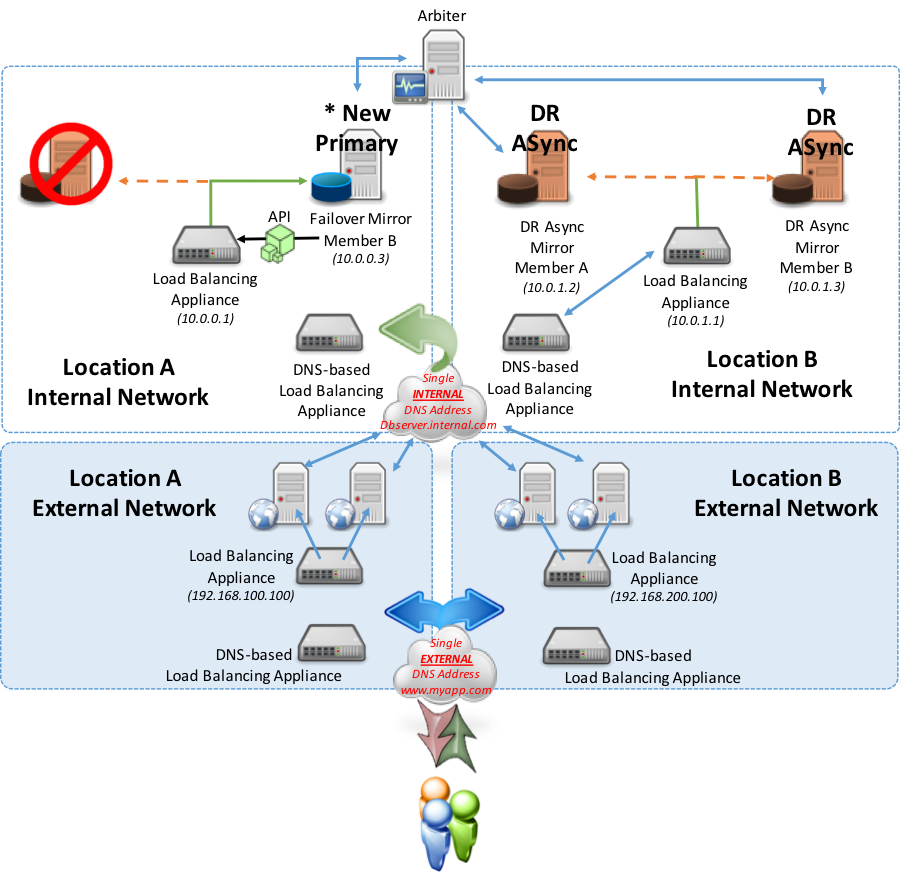
上記の例が示すように、同じ場所でフェイルオーバーが起きた場合は、自動フェイルオーバーが発生し、ローカルネットワークアプライアンスが新しいプライマリを指すようになります。 ユーザーは引き続きいずれかの場所のWebサーバーに接続し、Webサーバーは関連付けられたCSPゲートウェイで引き続き場所Aを指します。
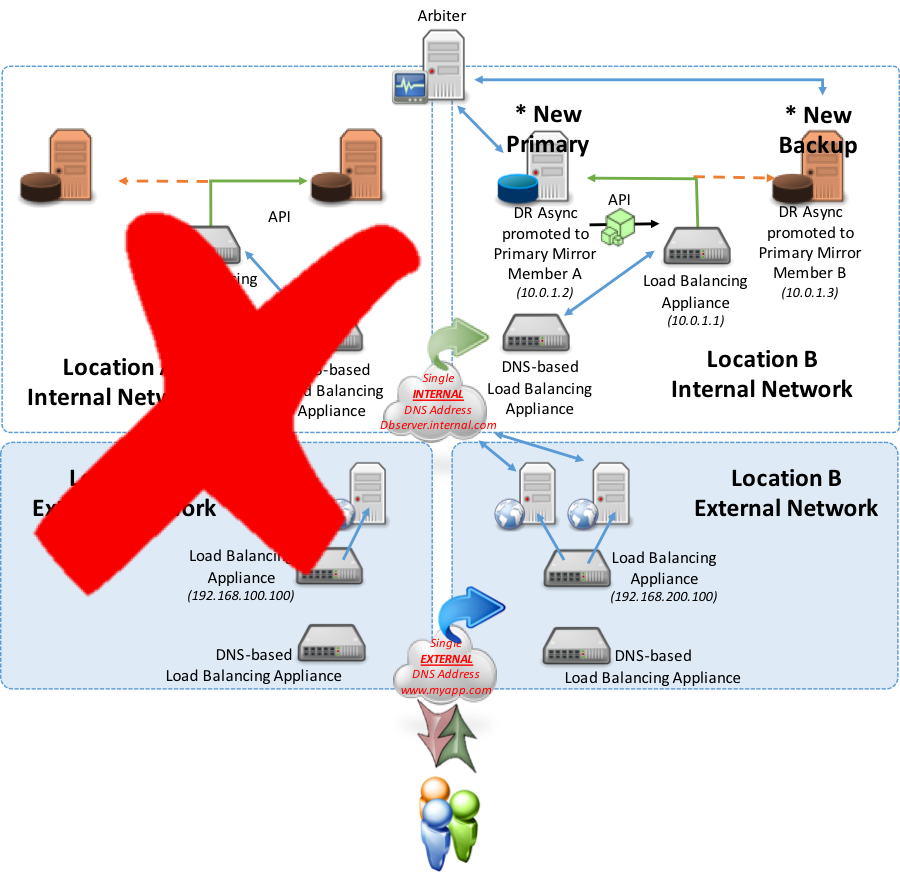
次の例では、プライマリフェイルオーバーミラーメンバーとバックアップフェイルオーバーミラーメンバーの両方が稼働していないロケーションAでの完全フェイルオーバーまたは運転休止について検討します。 このような場合、DR非同期ミラーメンバーは、プライマリおよびバックアップフェイルオーバーミラーメンバーに手動で昇格されます。 昇格されると、新しく指定されたプライマリミラーメンバーにより、ロケーションBの負荷分散アプライアンスが前述のAPIメソッドを使用して「Up」を報告できるようになります(ポーリングメソッドもオプションの1つです)。 ローカルロードバランサーが「Up」を報告するようになった結果、DNSベースのアプライアンスはそれを認識し、データベースサーバーサービスのためにトラフィックを場所Aから場所Bにリダイレクトします。
まとめ
仮想IPを使用しないにミラーフェイルオーバーを設計するには、さまざまな組み合わせが考えられます。 これらのオプションは、最も単純な高可用性シナリオまたはフェイルオーバーとDR非同期ミラーメンバーの両方を含む複数の層を備えた複数の地域に渡る展開のいずれにも適用でき、アプリケーションの最高レベルの運用回復力を維持することを目的とした、可用性が高く災害に強いソリューションを実現できます。
この記事では、あなたのアプリケーションと可用性の要件に適したフェイルオーバーを備えたデータベースミラーリングを正常に展開するために可能なさまざまな組み合わせと活用事例に関して説明いたしました。