Desde hace un tiempo tenía pendiente hacer algún tipo de prueba de concepto con la funcionalidad de Workflow, la cual, como tantas otras funcionalidades presentes en IRIS, suele pasar bastante desapercibida para nuestros clientes (y por lo cual entono el mea culpa). Por ello me decidí hace unos días a desarrollar un ejemplo de cómo configurar y explotar esta funcionalidad conectándola con una interfaz de usuario desarrollada en Angular.
Para evitar un articulo demasiado largo y hacerlo más asequible voy a dividirlo en 3 entregas. En este primer artículo presentaré la funcionalidad de Workflow así como el ejemplo que vamos a plantear. El segundo artículo entrará en el detalle de la configuración y la implementación de la producción que se encargará de gestionar el Workflow. Finalmente mostraremos como acceder a la información disponible en nuestro Worflow mediante una aplicación web.
InterSystems IRIS Workflow Engine
Qué mejor forma de explicar qué es esta funcionalidad de Workflow que copiar la descripción que da la documentación de IRIS.
Un sistema de gestión de flujo de trabajo automatiza la distribución de tareas entre los usuarios. Automatizar la distribución de tareas de acuerdo con una estrategia predefinida hace que la asignación de tareas sea más eficiente y su ejecución más responsable. Un ejemplo típico es una aplicación de escritorio de ayuda que acepta informes de problemas de los clientes, envía los informes a los miembros de las organizaciones apropiadas para que tomen medidas y, una vez resuelto el problema, informa los resultados al cliente.
InterSystems IRIS Workflow Engine proporciona un nivel mucho más alto de funcionalidad que los sistemas tradicionales e independientes de gestión de flujo de trabajo.
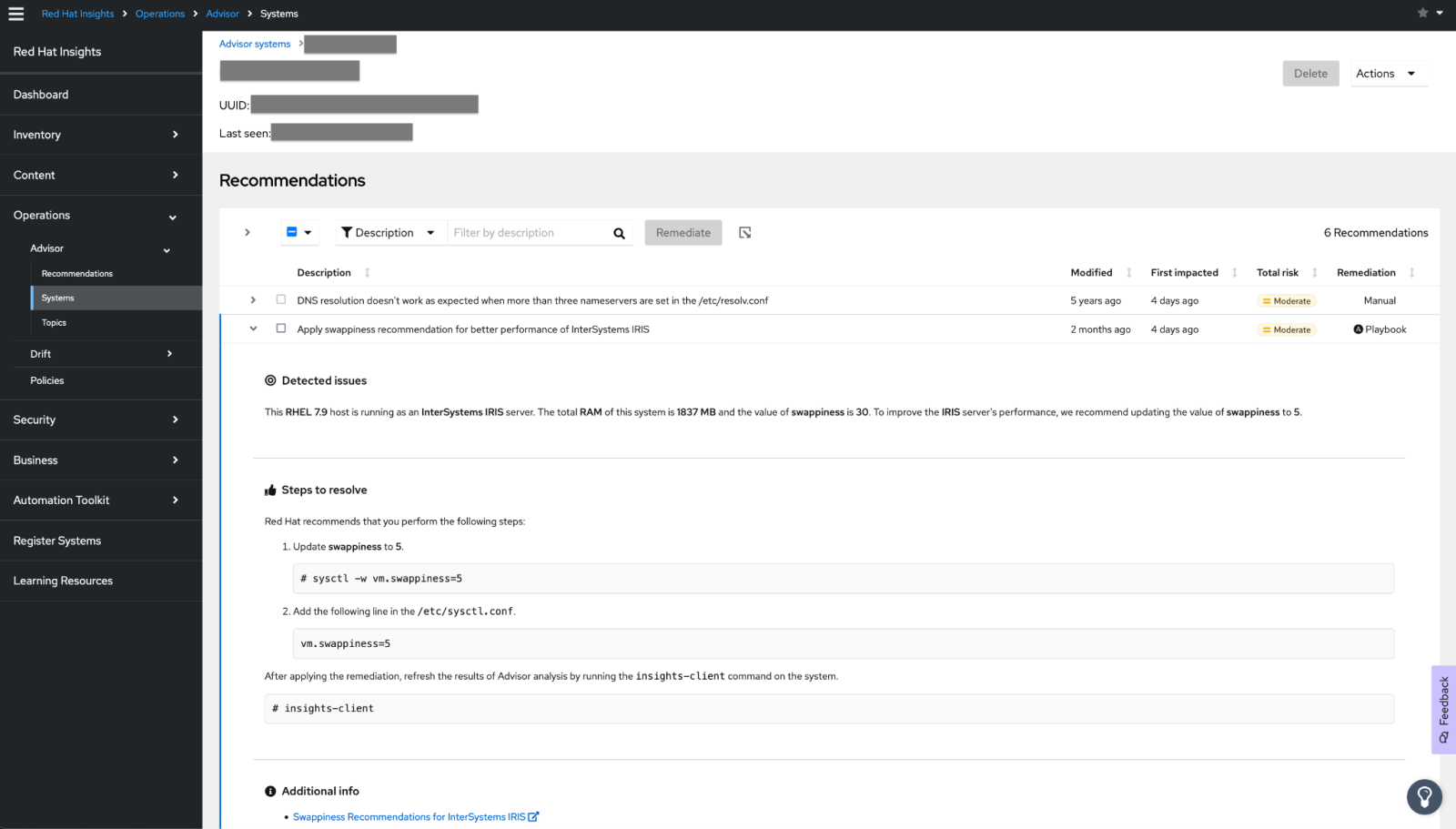
¿Donde encontramos las funcionalidades de Worflow en nuestro IRIS? Muy sencillo, desde el portal de gestión:
.png)
Expliquemos someramente cada una de las opciones disponibles antes de meternos con el proyecto de ejemplo.
Workflow Roles
Esta opción hace referencia a roles en los que encuadraremos a los usuarios que harán uso de la funcionalidad. La definición de rol es un tanto confusa, particularmente yo prefiero verlo más como tipos de tareas que podremos crear desde nuestra producción. El nombre asignado a estos roles deberá coincidir con los nombres de las Business Operations que posteriormente declararemos en nuestra producción para crear tareas asociadas a dichos roles.
Workflow Users
Usuarios de IRIS que podrán ser asignados a las diferentes tareas, se asociarán con uno o más roles. Los usuarios deben estar dados de alta en IRIS.
Workflow Tasks
Lista de tareas creadas en el sistema con su información asociada, desde esta ventana se podrán asignar tareas a los diferentes usuarios correspondientes al rol de la tarea.
¿Qué son estas tareas? Muy sencillo, las tareas son instancias de la clase EnsLib.Workflow.TaskRequest, el objeto de este tipo se enviará desde el Business Process en el que se ha generado a una Business Operation de la clase EnsLib.Workflow.Operation y con el nombre del rol que hayamos creado previamente. Esta acción creará a su vez una instancia de la clase EnsLib.Workflow.TaskResponse. El Business Operation no retornará respuesta hasta que no se ejecute el método de CompleteTask de la instancia de la clase TaskResponse.
.png)
Workflow Worklist
Similar a la anterior funcionalidad, nos muestra también una la lista de tareas con la información asociada a las mismas pero en este caso únicamente las que están activas.
.png)
Ejemplo de Workflow
El proyecto que podéis encontrar asociado a este artículo plantea un ejemplo simplificado de solución a un problema típico de las organizaciones de salud como es el del tratamiento de pacientes crónicos. Este tipo de pacientes exigen un control continuado y un seguimiento estricto para el que en muchas ocasiones los profesionales involucrados en los cuidados no cuentan con los medios más adecuados.
En el ejemplo vamos a ver cómo se puede realizar un seguimiento de pacientes con hipertensión. Supondremos que los pacientes se toman diariamente la tensión arterial con un tensiómetro que remitirá la lectura al servidor en el que se encuentra instalado nuestro InterSystems IRIS. En el caso de que la lectura de la tensión arterial se superen los valores 140 de sistólica y 90 de diastólica se informará al paciente de que deberá tomarse una segunda vez la tensión pasado un determinado tiempo y, si la lectura vuelve a superar los límites, se informará tanto al paciente como al médico de la situación para que este decida qué medida tomar.
Para ello dividiremos este flujo de tareas en dos etapas:
Etapa 1: Recepción de lectura diaria de tensión arterial.
- Recepción en la producción de mensaje HL7 con las medidas de tensión arterial.
- Comprobación de la existencia del usuario en el sistema (y creación del mismo si no existe), posteriormente registro del usuario en los roles implicados en el workflow.
- Extracción de los datos de tensión arterial y comparación con el criterio de alerta.
- Si los datos superan los criterios de alerta:
- Creación de tarea para el paciente informándole de la situación y solicitándole una nueva toma de la tensión arterial.
- Creación de tarea automática para gestionar la segunda lectura de la tensión arterial.
- Si los datos no superan los criterios de alerta se cierra el proceso hasta la siguiente lectura que se reciba el día siguiente.
Etapa 2: Recepción de segunda lectura tras superar la primera lectura los valores de alerta.
- Recepción del mensaje de HL7 con la segunda lectura.
- Recuperación de la tarea automática pendiente.
- Si los niveles de tensión arterial superan los criterios de alerta:
- Se cierra la tarea automática indicando el estado de aviso.
- Se crea una tarea manual para el médico informando de la situación del paciente.
- Se crea una tarea manual para el paciente alertando de la situación y de que se ha informado a su médico.
- Si los niveles no superan los criterios de alerta:
- Se cierra la tarea automática indicando en la misma que no hay peligro.
En el próximo artículo entraremos más en detalle en el diseño de nuestro diagrama de flujo encargado de reflejar lo expuesto anteriormente.
Interfaz de usuario
Como habéis podido observar en los pantallazos adjuntos la interfaz de usuario que InterSystems IRIS proporciona para la gestión de tareas es, por decirlo de alguna manera, bastante espartana, pero una de las ventajas que tenemos con IRIS es que podemos crear nuestra propia API Rest para gestionar nuestro flujo de tareas de una forma sencillísima, este punto lo trataremos en nuestro último artículo.
Para ofrecer una interfaz amigable a los usuarios hemos desarrollado una pequeña aplicación web en Angular utilizando Angular Material que nos permitirá crear una interfaz simulando una aplicación de móvil.
.png)
Esta aplicación móvil se conectará a InterSystems IRIS haciendo uso de JSON Web Tokens y realizará peticiones HTTP a una determinada aplicación web publicada en IRIS, de tal forma que las acciones que tomen los diferentes actores sobre las tareas se vean reflejadas sobre el flujo de tareas definido.
En el próximo capítulo...
Tras esta introducción a la funcionalidad de Workflow en nuestro próximo artículo mostraremos como implementar mediante un BPL el flujo de tareas necesario para resolver el ejemplo que hemos presentado, configuraremos la producción al completo y veremos como son las principales clases involucradas en el Workflow (EnsLib.Workflow.TaskRequest y EnsLib.Workflow.TaskResponse).
¡Muchas gracias a todos por vuestra atención!
 【ご参考】
【ご参考】
 Open Exchange
Open Exchange