
Any time a change is made to the configuration of a running Production, an update is needed to apply any changes in configuration or default settings to the running Production. This has historically been a manual step by the user. Now, if the CCR Client Tools cause a running Production to need update, the Production is updated automatically. This means users will no longer have to navigate to the Production Configuration page and click the 'Update Production' button every time they load an ItemSet. Additionally, this automatic Production update runs not only when deploying changes, but when making them! If editing the Production in source control, these changes are applied to the running Production automatically after compile of the Production class.
Another manual step when source controlling Productions is applying changes in Business Host code to the running Production. Just updating the Production does not apply these changes automatically. To apply these code changes, a user would need to restart Config Items belonging to the custom Business Host class. This could involve hunting down potentially many items within the Production if an ItemSet contains changes to multiple custom Host classes. Now, for clients on at least IRIS 2019.4.0, Business Host class compilation triggers all Config Items of that class to be automatically restarted. Should any Config Items fail to automatically restart, these will be reported to the user in either the output from ItemSet Load or the output window of the IDE where the class was compiled. Then the user can take necessary manual steps for restarting just these items. See example Transport Log text when an item fails to automatically restart:
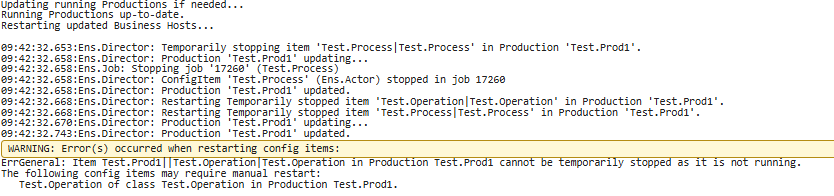
If using an Instance-Wide CCR Client Configuration, this change will also automatically apply these changes to all running Production Namespaces! An edit to a custom Business Host class in one Namespace triggers Config Item restarts in all affected Productions.
These workflow changes to source controlling Productions are intended to save time and reduce risk. When a user introduces changes to a Production, these changes are immediately activated and made tangible. To make sure you have this feature, check the output of Version^%buildccr for a ItemSet class version of at least 231. Big thanks to @Eduard Lebedyuk for his input and his article describing how to address these issues when source controlling Productions with GitLab: Continuous Delivery of your InterSystems solution using GitLab - Part XI:.
.png)