Posing a question to consider during the current Grand Prix competition.
I wanted to share an observation about using PDFs with LangChain.
When loading the text out of a PDF, I noticed there was an artifact of gaps within some of the words extracted.
For example (highlighted in red)
It was concerning this would affect:
1) The quality of document search for related content
2) The ability of OpenAI model to generate answers
What might be needed to stitch these words back together to improve things?
Could this use a word dictionary?
What would be the risk of linking two seperate words together.
Pushing ahead the unanticipated outcome was:
- It didn't make a difference to either the document search or the ability to generate answers.
I suspect this is down to the way that OpenAI encoding and tokenizing operate.
The number of tokens is always higher than the number of words.
So tokens are already like "partial" words where tokens follow one another.
Thus the spaces in the middle of words didn't affect the answer.
Please share your experiences of Ghosts / Curious effects when using LangChain with IRIS.
 Open Exchange
Open Exchange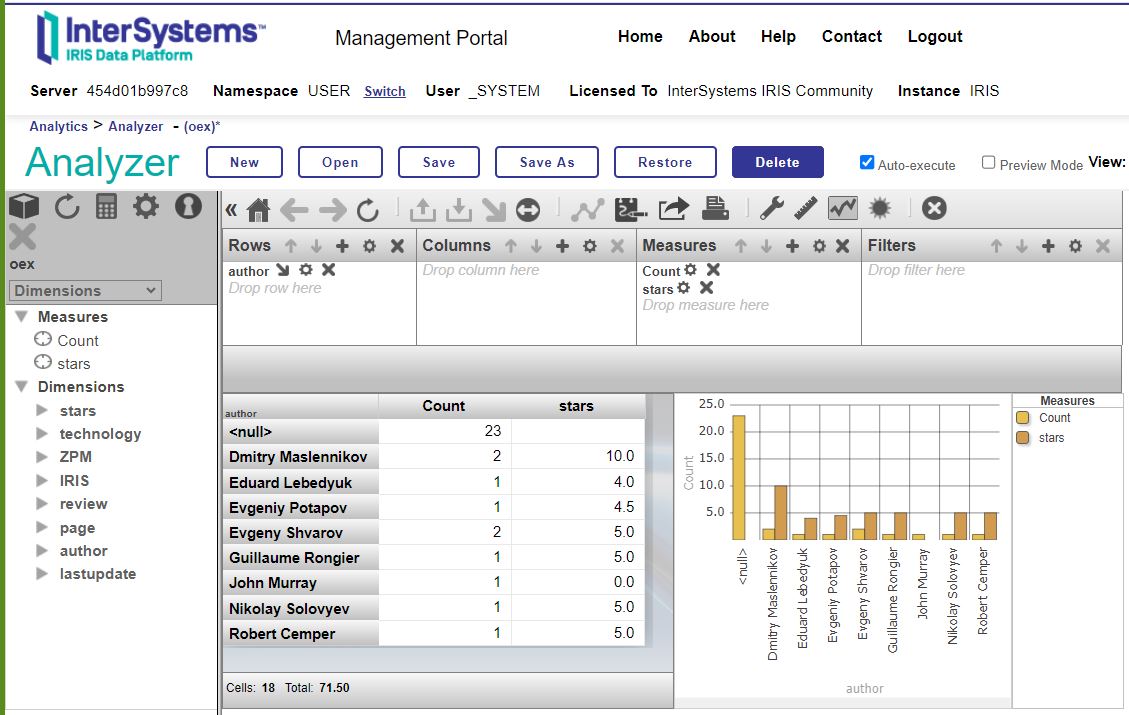 -
-
.png)
.png)
