Text to IRIS SQL with LangChain:Pythonプログラミングコンテスト受賞作品紹介!
開発者の皆さん、こんにちは!
この記事は、2024年7月に開催された「InterSystems Pythonプログラミングコンテスト2024」でエキスパート投票、コミュニティ投票の両方で1位を獲得された @Henry Pereira さん @José Pereira さん @Henrique Dias Dias さんが開発された sqlzilla について、アプリを動かしてみた感想と、中の構造について @José Pereira さんが投稿された「Text to IRIS with LangChain」の翻訳をご紹介します。
第2回 InterSystems Japan 技術文書ライティングコンテスト 開催! では、生成AIに関連する記事を投稿いただくと、ボーナスポイントを4点獲得できます📢 @José Pereira さんの記事を💡ヒント💡に皆様の操作体験談、アイデアなどを共有いただければと思います。
開発されたアプリSQLzilla についての概要ですが、Open Exchange の sqlzilla のREADMEに以下のように紹介されています。
「SQLzilla は、Python と AI のパワーを活用して、自然言語の SQL クエリ生成を通じてデータ アクセスを簡素化し、複雑なデータ クエリとプログラミング経験の少ないユーザーとの間のギャップを埋めます。」 「SQLクエリ生成」とありますので、アプリには Aviationスキーマ以下3つのテーブルとサンプルデータが用意されています。
- Aviation.Aircraft
- Aviation.Crew
- Aviation.Event
3つのテーブルには、米国国家運輸安全委員会に報告された航空事故の選択されたサブセットのデータが含まれています。
メモ: サンプルリポジトリ で提供されるデータセットは、http://www.ntsb.gov から入手できる完全な NTSB データセットの小さなサブセットであるためデモ目的のみで提供されており、正確であることを意図または保証するものではありません。(提供元:National Transportation Safety Board)
例えば、Aviation.Aircraftには、AircraftCategoryカラムがあり、航空機の種別が登録されています。
[SQL]IRISAPP>>SELECT AircraftCategory FROM Aviation.Aircraft GROUP BY AircraftCategory
1. SELECT AircraftCategory FROM Aviation.Aircraft GROUP BY AircraftCategory
| AircraftCategory |
| -- |
| AIRPLANE |
| HELICOPTER |
| GYROCRAFT |
| GLIDER |
| BALLOON |
| POWERED PARACHUTE |
| WEIGHT SHIFT |
また、DepartureCity には、出発都市名が登録されています。
SELECT top 10 DepartureCity FROM Aviation.Aircraft WHERE AircraftCategory='AIRPLANE' GROUP BY DepartureCity
| DepartureCity |
| -- |
| WILBUR |
| IRONWOOD |
| STANIEL CAY |
| OAK ISLAND |
| CLEVELAND |
| DECATUR |
| MARSHALLTOWN |
| MARANA |
| TONOPAH |
| MURRIETA/TEMECU |
また、Aviation.Eventテーブルには発生した事故の情報が含まれていて、InjuriesHighestには負傷者数の状況を文字で表現した情報が含まれています。
SELECT InjuriesHighest FROM Aviation.Event GROUP BY InjuriesHighest
| InjuriesHighest |
| -- |
| NONE |
| FATAL |
| SERIOUS |
| MINOR |
さて、これらのテーブルを使って具体的にどのようなことをしてくれるアプリなのか?ですが(説明文より以下抜粋)
「SQLzilla は、ユーザーがデータベースを操作する方法を変革する革新的なプロジェクトです。InterSystems IRIS と統合することで、SQL に詳しくないユーザーでもさまざまなテーブルからデータを簡単に抽出して分析できるツールを作成しました。」
つまり、
SQLに詳しくないユーザでも、自分の欲しい情報に対して質問するとSQLを組み立てて返してきてくれる便利アプリということになります。
以下、アプリケーションを動作させてみたときの図です。(日本語で質問してもしっかりSQLを組み立ててくれています!)
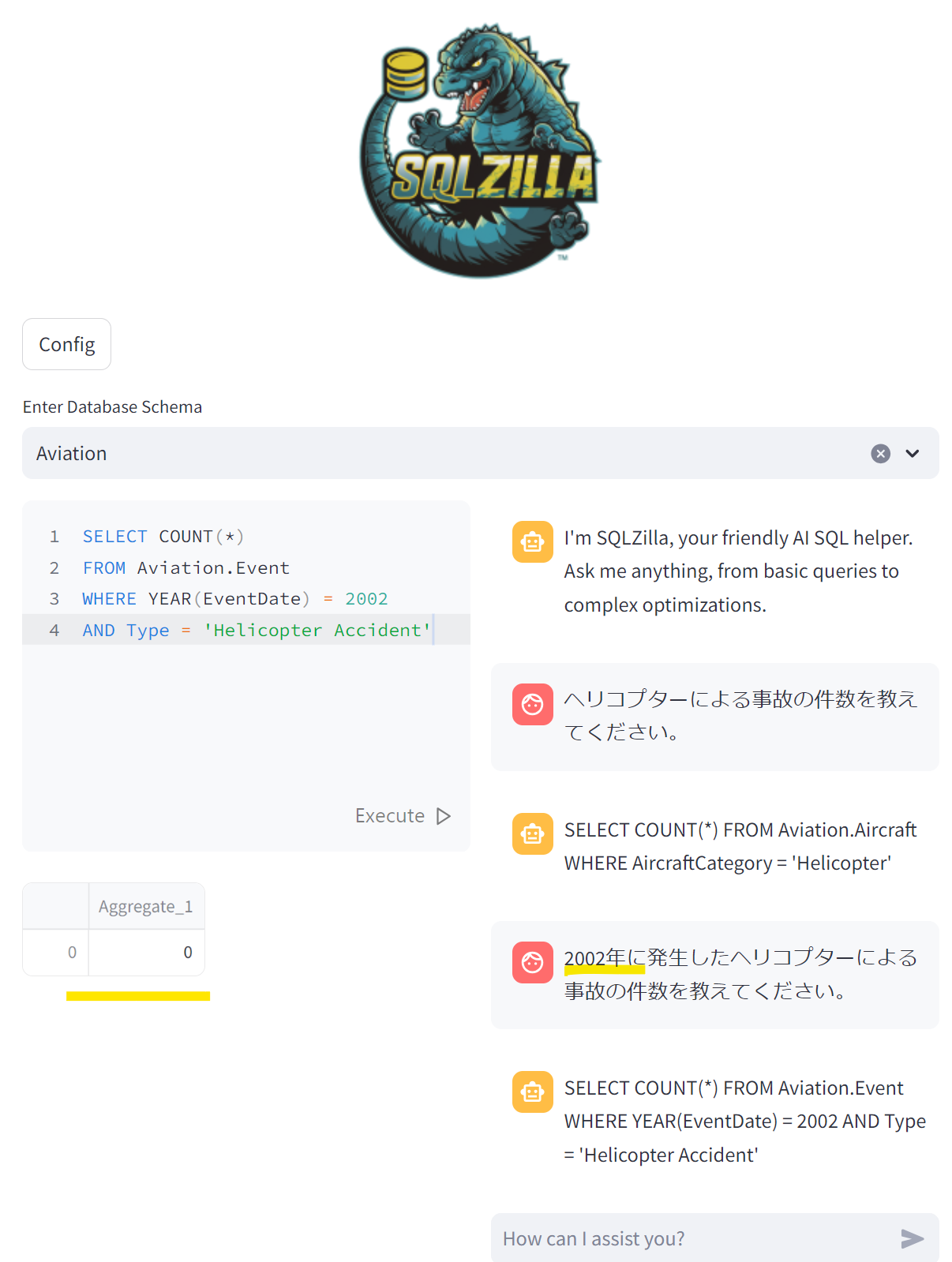
入力した質問によって生成されたSQLは以下の通りです。
- ヘリコプターによる事故の件数を教えてください。
SELECT COUNT(*) FROM Aviation.Aircraft WHERE AircraftCategory = 'Helicopter'
- 2002年に発生したヘリコプターによる事故の件数を教えてください。
SELECT COUNT(*) FROM Aviation.Event WHERE YEAR(EventDate) = 2002 AND Type = 'Helicopter Accident'
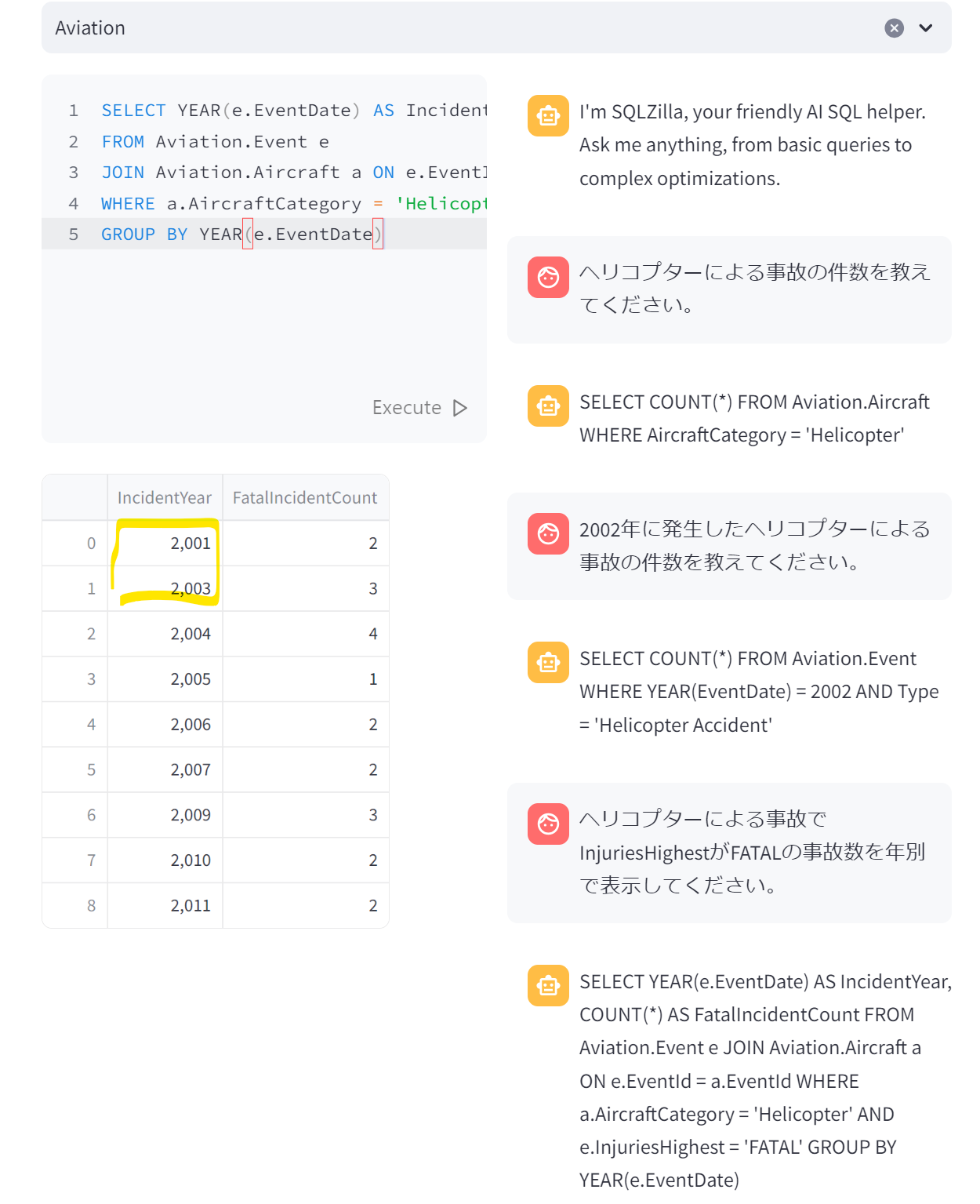
- ヘリコプターによる事故でInjuriesHighestがFATALの事故数を年別で表示してください。
SELECT YEAR(e.EventDate) AS IncidentYear, COUNT(*) AS FatalIncidentCount FROM Aviation.Event e JOIN Aviation.Aircraft a ON e.EventId = a.EventId WHERE a.AircraftCategory = 'Helicopter' AND e.InjuriesHighest = 'FATAL' GROUP BY YEAR(e.EventDate)
アプリ詳細は、ぜひ Open Exchange の sqlzilla をご参照ください。
素晴らしいです!!
※ このサンプルを動作させるためには、OpenAIのAPIキーが必要となりますので、お試しになる場合は事前にご準備ください。
Open Exchange の sqlzilla のREADMEにも記載がありますが、コンテナを使う場合は以下3コマンドでサンプルを動作させることができます。
まずはソースコードをclone して
git clone https://github.com/musketeers-br/sqlzilla.git
コンテナをビルドし
docker-compose build --no-cache --progress=plain
コンテナを開始するだけ
docker-compose up -d
後は、アプリ画面を起動するだけ!
コンテナ以外でも操作する方法が提供されています。詳しくは、 sqlzilla のREADMEご参照ください。(ぜひREADMEの一番下までご覧ください!)
記事の紹介
アプリの中でどのようにSQLを生成させているか、については、 @José Pereira さんが投稿された「Text to IRIS with LangChain」の翻訳記事でご紹介します。
LangChainフレームワーク、IRIS Vector Search、LLMを使って、ユーザープロンプトからIRIS互換のSQLを生成する方法についての実験をご紹介します。
この記事は このノートブック を元にしています。 OpenExchange の このアプリケーション を使えば、すぐに使える環境で実行できます。
セットアップ
最初に必要なライブラリをインストールします。
!pip install --upgrade --quiet langchain langchain-openai langchain-iris pandas
次に、必要なモジュールをインポートし、環境をセットアップします。
import os
import datetime
import hashlib
from copy import deepcopy
from sqlalchemy import create_engine
import getpass
import pandas as pd
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.docstore.document import Document
from langchain_community.document_loaders import DataFrameLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_core.output_parsers import StrOutputParser
from langchain.globals import set_llm_cache
from langchain.cache import SQLiteCache
from langchain_iris import IRISVector
SQLiteCacheを使ってLLMコールをキャッシュします。
# Cache for LLM calls
set_llm_cache(SQLiteCache(database_path=".langchain.db"))
IRISデータベースへ接続するためのパラメータをセットします。
# IRIS database connection parameters
os.environ["ISC_LOCAL_SQL_HOSTNAME"] = "localhost"
os.environ["ISC_LOCAL_SQL_PORT"] = "1972"
os.environ["ISC_LOCAL_SQL_NAMESPACE"] = "IRISAPP"
os.environ["ISC_LOCAL_SQL_USER"] = "_system"
os.environ["ISC_LOCAL_SQL_PWD"] = "SYS"
OpenAI APIキーが環境変数に設定されていない場合は、ユーザ入力が求められます。
if not "OPENAI_API_KEY" in os.environ:
os.environ["OPENAI_API_KEY"] = getpass.getpass()
IRISデータベースの接続文字列を作成します。
# IRIS database connection string
args = {
'hostname': os.getenv("ISC_LOCAL_SQL_HOSTNAME"),
'port': os.getenv("ISC_LOCAL_SQL_PORT"),
'namespace': os.getenv("ISC_LOCAL_SQL_NAMESPACE"),
'username': os.getenv("ISC_LOCAL_SQL_USER"),
'password': os.getenv("ISC_LOCAL_SQL_PWD")
}
iris_conn_str = f"iris://{args['username']}:{args['password']}@{args['hostname']}:{args['port']}/{args['namespace']}"
IRISデータベースとの接続を確立します。
# Connection to IRIS database
engine = create_engine(iris_conn_str)
cnx = engine.connect().connection
システムプロンプトのコンテキスト情報を保持するdictionaryを用意します。
# Dict for context information for system prompt
context = {}
context["top_k"] = 3
プロンプトの作成
ユーザー入力をIRISデータベースと互換性のあるSQLクエリに変換するために、言語モデル用の効果的なプロンプトを作成する必要があります。
SQLクエリを生成するための基本的な指示を提供する初期プロンプトから始めます。
このテンプレートはLangChain's default prompts for MSSQL から派生し、IRISデータベース用にカスタマイズされています。
# Basic prompt template with IRIS database SQL instructions
iris_sql_template = """
You are an InterSystems IRIS expert. Given an input question, first create a syntactically correct InterSystems IRIS query to run and return the answer to the input question.
Unless the user specifies in the question a specific number of examples to obtain, query for at most {top_k} results using the TOP clause as per InterSystems IRIS. You can order the results to return the most informative data in the database.
Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in single quotes ('') to denote them as delimited identifiers.
Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Pay attention to use CAST(CURRENT_DATE as date) function to get the current date, if the question involves "today".
Use double quotes to delimit columns identifiers.
Return just plain SQL; don't apply any kind of formatting.
"""
次のような文章をテンプレートに設定しています: あなたは InterSystems IRIS のエキスパートです。 入力された質問に対して、まず、構文的に正しい InterSystems IRIS クエリを作成し、そのクエリを実行し て、入力された質問に対する回答を返します。 ユーザが質問で特定の数の例を取得するように指定しない限り、InterSystems IRIS に従って、TOP 節を使用して最大 {top_k} の結果をクエリします。 テーブルのすべての列に対してクエリを実行してはなりません。 質問に答えるために必要なカラムのみを問い合わせなければなりません。 各カラム名をシングルクォート('')で囲み、区切り識別子にします。 以下の表で確認できるカラム名のみを使用するように注意してください。 存在しないカラムを問い合わせないように注意してください。 また、どのカラムがどのテーブルにあるかに注意すること。 質問内容が "今日 "を含む場合は、CAST(CURRENT_DATE as date)関数を使用して現在の日付を取得することに注意すること。 カラムの識別子を区切るには二重引用符を使用すること。 単なるSQLを返すこと。いかなるフォーマットも適用しないこと。
この基本プロンプトは、言語モデル(LLM)がIRISデータベースに対する特定のガイダンスを持つSQLエキスパートとして機能するように設定しています。
次に、ハルシネーション(幻覚)を避けるために、データベーススキーマに関する情報を補助プロンプトとして提供します。
# SQL template extension for including tables context information
tables_prompt_template = """
Only use the following tables:
{table_info}
"""
LLMの回答の精度を高めるために、私たちはfew-shot プロンプトと呼ばれるテクニックを使いました。 これはLLMにいくつかの例を提示するものです。
# SQL template extension for including few shots
prompt_sql_few_shots_template = """
Below are a number of examples of questions and their corresponding SQL queries.
{examples_value}
"""
私たちは few-shot の例のためにテンプレートを以下のように定義しています。
# Few shots prompt template
example_prompt_template = "User input: {input}\nSQL query: {query}"
example_prompt = PromptTemplate.from_template(example_prompt_template)
私たちは、 few-shot テンプレートを使ってユーザー・プロンプトを作っています。
# User prompt template
user_prompt = "\n" + example_prompt.invoke({"input": "{input}", "query": ""}).to_string()
最後に、すべてのプロンプトを組み合わせて最終的なプロンプトを作成します。
# Complete prompt template
prompt = (
ChatPromptTemplate.from_messages([("system", iris_sql_template)])
+ ChatPromptTemplate.from_messages([("system", tables_prompt_template)])
+ ChatPromptTemplate.from_messages([("system", prompt_sql_few_shots_template)])
+ ChatPromptTemplate.from_messages([("human", user_prompt)])
)
prompt
このプロンプトは、変数 examples_value, input, table_info, and top_k を想定しています。
プロンプトの構成は以下の通りです。
ChatPromptTemplate(
input_variables=['examples_value', 'input', 'table_info', 'top_k'],
messages=[
SystemMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=['top_k'],
template=iris_sql_template
)
),
SystemMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=['table_info'],
template=tables_prompt_template
)
),
SystemMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=['examples_value'],
template=prompt_sql_few_shots_template
)
),
HumanMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=['input'],
template=user_prompt
)
)
]
)
プロンプトがどのようにLLMに送られるかを視覚化するために、必要な変数にプレースホルダーの値を使うことができます。
prompt_value = prompt.invoke({
"top_k": "<top_k>",
"table_info": "<table_info>",
"examples_value": "<examples_value>",
"input": "<input>"
})
print(prompt_value.to_string())
System:
You are an InterSystems IRIS expert. Given an input question, first create a syntactically correct InterSystems IRIS query to run and return the answer to the input question.
Unless the user specifies in the question a specific number of examples to obtain, query for at most <top_k> results using the TOP clause as per InterSystems IRIS. You can order the results to return the most informative data in the database.
Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in single quotes ('') to denote them as delimited identifiers.
Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Pay attention to use CAST(CURRENT_DATE as date) function to get the current date, if the question involves "today".
Use double quotes to delimit columns identifiers.
Return just plain SQL; don't apply any kind of formatting.
System:
Only use the following tables:
<table_info>
System:
Below are a number of examples of questions and their corresponding SQL queries.
<examples_value>
Human:
User input: <input>
SQL query:
これで、必要な変数を与えることで、このプロンプトをLLMに送る準備ができました。 準備ができたら次のステップに進みましょう。
テーブル情報の提供
正確なSQLクエリを作成するためには、言語モデル(LLM)にデータベース・テーブルに関する詳細な情報を提供する必要があります。
この情報がないと、LLMは一見もっともらしく見えますが、ハルシネーション(幻覚)により正しくないクエリを生成する可能性があります。 そこで、最初のステップとして、IRISデータベースからテーブル定義を取得する関数を作成します。
テーブル定義情報を取得する関数
以下の関数はINFORMATION_SCHEMAに問い合わせ、指定されたスキーマのテーブル定義を取得します。
特定のテーブルが指定された場合は、そのテーブルの定義を取得します。そうでない場合は、スキーマ内の全てのテーブルの定義を取得します。
def get_table_definitions_array(cnx, schema, table=None):
cursor = cnx.cursor()
# Base query to get columns information
query = """
SELECT TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME, DATA_TYPE, IS_NULLABLE, COLUMN_DEFAULT, PRIMARY_KEY, null EXTRA
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = %s
"""
# Parameters for the query
params = [schema]
# Adding optional filters
if table:
query += " AND TABLE_NAME = %s"
params.append(table)
# Execute the query
cursor.execute(query, params)
# Fetch the results
rows = cursor.fetchall()
# Process the results to generate the table definition(s)
table_definitions = {}
for row in rows:
table_schema, table_name, column_name, column_type, is_nullable, column_default, column_key, extra = row
if table_name not in table_definitions:
table_definitions[table_name] = []
table_definitions[table_name].append({
"column_name": column_name,
"column_type": column_type,
"is_nullable": is_nullable,
"column_default": column_default,
"column_key": column_key,
"extra": extra
})
primary_keys = {}
# Build the output string
result = []
for table_name, columns in table_definitions.items():
table_def = f"CREATE TABLE {schema}.{table_name} (\n"
column_definitions = []
for column in columns:
column_def = f" {column['column_name']} {column['column_type']}"
if column['is_nullable'] == "NO":
column_def += " NOT NULL"
if column['column_default'] is not None:
column_def += f" DEFAULT {column['column_default']}"
if column['extra']:
column_def += f" {column['extra']}"
column_definitions.append(column_def)
if table_name in primary_keys:
pk_def = f" PRIMARY KEY ({', '.join(primary_keys[table_name])})"
column_definitions.append(pk_def)
table_def += ",\n".join(column_definitions)
table_def += "\n);"
result.append(table_def)
return result
スキーマのテーブル定義を取得する
この例では、Aviationスキーマを使用しています。Aviationスキーマ情報一式については こちら から入手できます。
# Retrieve table definitions for the Aviation schema
tables = get_table_definitions_array(cnx, "Aviation")
print(tables)
この関数は、Aviation スキーマ内のすべてのテーブルの CREATE TABLE ステートメントを返します。
[
'CREATE TABLE Aviation.Aircraft (\n Event bigint NOT NULL,\n ID varchar NOT NULL,\n AccidentExplosion varchar,\n AccidentFire varchar,\n AirFrameHours varchar,\n AirFrameHoursSince varchar,\n AirFrameHoursSinceLastInspection varchar,\n AircraftCategory varchar,\n AircraftCertMaxGrossWeight integer,\n AircraftHomeBuilt varchar,\n AircraftKey integer NOT NULL,\n AircraftManufacturer varchar,\n AircraftModel varchar,\n AircraftRegistrationClass varchar,\n AircraftSerialNo varchar,\n AircraftSeries varchar,\n Damage varchar,\n DepartureAirportId varchar,\n DepartureCity varchar,\n DepartureCountry varchar,\n DepartureSameAsEvent varchar,\n DepartureState varchar,\n DepartureTime integer,\n DepartureTimeZone varchar,\n DestinationAirportId varchar,\n DestinationCity varchar,\n DestinationCountry varchar,\n DestinationSameAsLocal varchar,\n DestinationState varchar,\n EngineCount integer,\n EvacuationOccurred varchar,\n EventId varchar NOT NULL,\n FlightMedical varchar,\n FlightMedicalType varchar,\n FlightPhase integer,\n FlightPlan varchar,\n FlightPlanActivated varchar,\n FlightSiteSeeing varchar,\n FlightType varchar,\n GearType varchar,\n LastInspectionDate timestamp,\n LastInspectionType varchar,\n Missing varchar,\n OperationDomestic varchar,\n OperationScheduled varchar,\n OperationType varchar,\n OperatorCertificate varchar,\n OperatorCertificateNum varchar,\n OperatorCode varchar,\n OperatorCountry varchar,\n OperatorIndividual varchar,\n OperatorName varchar,\n OperatorState varchar,\n Owner varchar,\n OwnerCertified varchar,\n OwnerCountry varchar,\n OwnerState varchar,\n RegistrationNumber varchar,\n ReportedToICAO varchar,\n SeatsCabinCrew integer,\n SeatsFlightCrew integer,\n SeatsPassengers integer,\n SeatsTotal integer,\n SecondPilot varchar,\n childsub bigint NOT NULL DEFAULT $i(^Aviation.EventC("Aircraft"))\n);',
'CREATE TABLE Aviation.Crew (\n Aircraft varchar NOT NULL,\n ID varchar NOT NULL,\n Age integer,\n AircraftKey integer NOT NULL,\n Category varchar,\n CrewNumber integer NOT NULL,\n EventId varchar NOT NULL,\n Injury varchar,\n MedicalCertification varchar,\n MedicalCertificationDate timestamp,\n MedicalCertificationValid varchar,\n Seat varchar,\n SeatbeltUsed varchar,\n Sex varchar,\n ShoulderHarnessUsed varchar,\n ToxicologyTestPerformed varchar,\n childsub bigint NOT NULL DEFAULT $i(^Aviation.AircraftC("Crew"))\n);',
'CREATE TABLE Aviation.Event (\n ID bigint NOT NULL DEFAULT $i(^Aviation.EventD),\n AirportDirection integer,\n AirportDistance varchar,\n AirportElevation integer,\n AirportLocation varchar,\n AirportName varchar,\n Altimeter varchar,\n EventDate timestamp,\n EventId varchar NOT NULL,\n EventTime integer,\n FAADistrictOffice varchar,\n InjuriesGroundFatal integer,\n InjuriesGroundMinor integer,\n InjuriesGroundSerious integer,\n InjuriesHighest varchar,\n InjuriesTotal integer,\n InjuriesTotalFatal integer,\n InjuriesTotalMinor integer,\n InjuriesTotalNone integer,\n InjuriesTotalSerious integer,\n InvestigatingAgency varchar,\n LightConditions varchar,\n LocationCity varchar,\n LocationCoordsLatitude double,\n LocationCoordsLongitude double,\n LocationCountry varchar,\n LocationSiteZipCode varchar,\n LocationState varchar,\n MidAir varchar,\n NTSBId varchar,\n NarrativeCause varchar,\n NarrativeFull varchar,\n NarrativeSummary varchar,\n OnGroundCollision varchar,\n SkyConditionCeiling varchar,\n SkyConditionCeilingHeight integer,\n SkyConditionNonCeiling varchar,\n SkyConditionNonCeilingHeight integer,\n TimeZone varchar,\n Type varchar,\n Visibility varchar,\n WeatherAirTemperature integer,\n WeatherPrecipitation varchar,\n WindDirection integer,\n WindDirectionIndicator varchar,\n WindGust integer,\n WindGustIndicator varchar,\n WindVelocity integer,\n WindVelocityIndicator varchar\n);'
]
これらのテーブル定義ができたので、次のステップに進むことができます。
これにより、LLMがSQLクエリを生成する際に、データベース・スキーマに関する正確で包括的な情報が得られるようになります。
最も関連性の高いテーブルを選ぶ
データベース、特に大規模なデータベースを扱う場合、プロンプト内のすべてのテーブルのデータ定義言語(DDL)を送信することは非現実的です。
このアプローチは小規模なデータベースでは有効かもしれませんが、現実のデータベースには数百から数千のテーブルが含まれていることが多く、すべてのテーブルを処理するのは非効率的です。
さらに、SQLクエリを効率的に生成するために、言語モデルがデータベース内のすべてのテーブルを認識する必要があるとは考えにくいです。 この課題に対処するため、セマンティック検索機能を活用し、ユーザーのクエリに基づいて最も関連性の高いテーブルのみを選択することができます。
アプローチ
IRIS Vector Searchでセマンティック検索を使用することでこれを実現します。
この方法は、SQL要素の識別子(テーブル、フィールド、キーなど)に意味のある名前がある場合に最も効果的です。識別子が任意のコードである場合は、代わりにデータ dictionaryの使用を検討してください。
手順
- テーブル情報の取得
まず、テーブル定義をpandas DataFrameに取り出します。
# Retrieve table definitions into a pandas DataFrame
table_def = get_table_definitions_array(cnx=cnx, schema='Aviation')
table_df = pd.DataFrame(data=table_def, columns=["col_def"])
table_df["id"] = table_df.index + 1
table_df
DataFrame(table_df)は以下のようになります。
| col_def | id | |
|---|---|---|
| 0 | CREATE TABLE Aviation.Aircraft (\n Event bigi... | 1 |
| 1 | CREATE TABLE Aviation.Crew (\n Aircraft varch... | 2 |
| 2 | CREATE TABLE Aviation.Event (\n ID bigint NOT... | 3 |
- 定義をDocumentsに分割する
次に、テーブル定義をLangchain Documentsに分割します。 このステップは、大きなテキストの塊を扱い、テキスト埋め込みを抽出するために非常に重要です。
loader = DataFrameLoader(table_df, page_content_column="col_def")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=400, chunk_overlap=20, separator="\n")
tables_docs = text_splitter.split_documents(documents)
tables_docs
その結果、tables_docsリストには、次のようにメタデータ付きの分割ドキュメントが含まれます。
[Document(metadata={'id': 1}, page_content='CREATE TABLE Aviation.Aircraft (\n Event bigint NOT NULL,\n ID varchar NOT NULL,\n ...'),
Document(metadata={'id': 2}, page_content='CREATE TABLE Aviation.Crew (\n Aircraft varchar NOT NULL,\n ID varchar NOT NULL,\n ...'),
Document(metadata={'id': 3}, page_content='CREATE TABLE Aviation.Event (\n ID bigint NOT NULL DEFAULT $i(^Aviation.EventD),\n ...')]
- 埋め込み(Embedding)の抽出とIRISへの保存
次に,langchain-irisのIRISVectorクラスを使って埋め込みベクトルを抽出し、それをIRISに格納します。
tables_vector_store = IRISVector.from_documents(
embedding=OpenAIEmbeddings(),
documents=tables_docs,
connection_string=iris_conn_str,
collection_name="sql_tables",
pre_delete_collection=True
)
注意: pre_delete_collection フラグは、各テスト実行で新鮮なコレクションを確保するために、デモ用に True に設定されています。 本番環境では、このフラグは通常 False に設定します。
- 関連文書の検索
テーブルに埋め込み(Embedding)が保存されたことで、ユーザー入力に基づいて関連するテーブルを検索できるようになりました。
input_query = "List the first 2 manufacturers"
relevant_tables_docs = tables_vector_store.similarity_search(input_query, k=3)
relevant_tables_docs
例えば、manufacturers を検索すると、次のような結果が返ってきます。
[Document(metadata={'id': 1}, page_content='GearType varchar,\n LastInspectionDate timestamp,\n ...'),
Document(metadata={'id': 1}, page_content='AircraftModel varchar,\n AircraftRegistrationClass varchar,\n ...'),
Document(metadata={'id': 3}, page_content='LocationSiteZipCode varchar,\n LocationState varchar,\n ...')]
メタデータから、テーブルID 1 (Aviation.Aircraft)だけが関連性があり、クエリと一致していることがわかります。
- エッジケースへの対応
このアプローチは一般的に効果的ではありますが、常に完璧とは限りません。 たとえば、事故現場のクエリを実行すると、関連性の低いテーブルが返されることもあります。
input_query = "List the top 10 most crash sites"
relevant_tables_docs = tables_vector_store.similarity_search(input_query, k=3)
relevant_tables_docs
結果は以下の通りです。
[Document(metadata={'id': 3}, page_content='LocationSiteZipCode varchar,\n LocationState varchar,\n ...'),
Document(metadata={'id': 3}, page_content='InjuriesGroundSerious integer,\n InjuriesHighest varchar,\n ...'),
Document(metadata={'id': 1}, page_content='CREATE TABLE Aviation.Aircraft (\n Event bigint NOT NULL,\n ID varchar NOT NULL,\n ...')]
正しいAviation.Eventテーブルを2回取得したにもかかわらず、Aviation.Aircraftテーブルも表示されることがあります。これは、この例の範囲を超えているため、将来の実装に委ねられます。
- 関連テーブルを取得する関数を定義する
このプロセスを自動化するため、ユーザー入力に基づいて関連するテーブルをフィルタリングして返す関数を定義します。
def get_relevant_tables(user_input, tables_vector_store, table_df):
relevant_tables_docs = tables_vector_store.similarity_search(user_input)
relevant_tables_docs_indices = [x.metadata["id"] for x in relevant_tables_docs]
indices = table_df["id"].isin(relevant_tables_docs_indices)
relevant_tables_array = [x for x in table_df[indices]["col_def"]]
return relevant_tables_array
この機能は、LLMに送信する関連テーブルのみを効率的に検索し、プロンプトの長さを短縮し、クエリ全体のパフォーマンスを向上させるのに役立ちます。
最も適切な例を選ぶ(Few-Shotプロンプティング)
言語モデル(LLM)を扱うとき、適切な例を提供することは、正確で文脈的に適切な応答を保証するのに役立ちます。
これらの例は "Few-Shot" 例と呼ばれ、LLMが処理すべきクエリの構造とコンテキストを理解するためのガイドとなります。今回のケースでは、IRISのSQL構文とデータベースで使用可能なテーブルを幅広くカバーする多様なSQLクエリを examples_value 変数に入力する必要があります。これは、LLMが正しくないクエリーや無関係なクエリーを生成するのを防ぐのに役立ちます。
クエリ例の定義
以下は、様々なSQL操作を説明するために作られたクエリ例のリストです。
examples = [
{"input": "List all aircrafts.", "query": "SELECT * FROM Aviation.Aircraft"},
{"input": "Find all incidents for the aircraft with ID 'N12345'.", "query": "SELECT * FROM Aviation.Event WHERE EventId IN (SELECT EventId FROM Aviation.Aircraft WHERE ID = 'N12345')"},
{"input": "List all incidents in the 'Commercial' operation type.", "query": "SELECT * FROM Aviation.Event WHERE EventId IN (SELECT EventId FROM Aviation.Aircraft WHERE OperationType = 'Commercial')"},
{"input": "Find the total number of incidents.", "query": "SELECT COUNT(*) FROM Aviation.Event"},
{"input": "List all incidents that occurred in 'Canada'.", "query": "SELECT * FROM Aviation.Event WHERE LocationCountry = 'Canada'"},
{"input": "How many incidents are associated with the aircraft with AircraftKey 5?", "query": "SELECT COUNT(*) FROM Aviation.Aircraft WHERE AircraftKey = 5"},
{"input": "Find the total number of distinct aircrafts involved in incidents.", "query": "SELECT COUNT(DISTINCT AircraftKey) FROM Aviation.Aircraft"},
{"input": "List all incidents that occurred after 5 PM.", "query": "SELECT * FROM Aviation.Event WHERE EventTime > 1700"},
{"input": "Who are the top 5 operators by the number of incidents?", "query": "SELECT TOP 5 OperatorName, COUNT(*) AS IncidentCount FROM Aviation.Aircraft GROUP BY OperatorName ORDER BY IncidentCount DESC"},
{"input": "Which incidents occurred in the year 2020?", "query": "SELECT * FROM Aviation.Event WHERE YEAR(EventDate) = '2020'"},
{"input": "What was the month with most events in the year 2020?", "query": "SELECT TOP 1 MONTH(EventDate) EventMonth, COUNT(*) EventCount FROM Aviation.Event WHERE YEAR(EventDate) = '2020' GROUP BY MONTH(EventDate) ORDER BY EventCount DESC"},
{"input": "How many crew members were involved in incidents?", "query": "SELECT COUNT(*) FROM Aviation.Crew"},
{"input": "List all incidents with detailed aircraft information for incidents that occurred in the year 2012.", "query": "SELECT e.EventId, e.EventDate, a.AircraftManufacturer, a.AircraftModel, a.AircraftCategory FROM Aviation.Event e JOIN Aviation.Aircraft a ON e.EventId = a.EventId WHERE Year(e.EventDate) = 2012"},
{"input": "Find all incidents where there were more than 5 injuries and include the aircraft manufacturer and model.", "query": "SELECT e.EventId, e.InjuriesTotal, a.AircraftManufacturer, a.AircraftModel FROM Aviation.Event e JOIN Aviation.Aircraft a ON e.EventId = a.EventId WHERE e.InjuriesTotal > 5"},
{"input": "List all crew members involved in incidents with serious injuries, along with the incident date and location.", "query": "SELECT c.CrewNumber AS 'Crew Number', c.Age, c.Sex AS Gender, e.EventDate AS 'Event Date', e.LocationCity AS 'Location City', e.LocationState AS 'Location State' FROM Aviation.Crew c JOIN Aviation.Event e ON c.EventId = e.EventId WHERE c.Injury = 'Serious'"}
]
関連する事例の選択
例のリストが増え続けることを考えると、LLMにすべての例を提供することは現実的ではありません。代わりに、IRIS Vector SearchとSemanticSimilarityExampleSelectorクラスを使用して、ユーザーのプロンプトに基づいて最も関連性の高い例を特定します。
Example Selector を定義する
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
OpenAIEmbeddings(),
IRISVector,
k=5,
input_keys=["input"],
connection_string=iris_conn_str,
collection_name="sql_samples",
pre_delete_collection=True
)
注意: pre_delete_collection フラグは、各テスト実行で新鮮なコレクションを確保するためのデモンストレーション目的で使用されています。本番環境では、不要な削除を避けるためにこのフラグを False に設定する必要があります。
Selectorに問い合わせる
与えられた入力に最も関連する例を見つけるには、次のようにSelector を使用します。
input_query = "Find all events in 2010 informing the Event Id and date, location city and state, aircraft manufacturer and model."
relevant_examples = example_selector.select_examples({"input": input_query})
結果は以下のようになります。
[{'input': 'List all incidents with detailed aircraft information for incidents that occurred in the year 2012.', 'query': 'SELECT e.EventId, e.EventDate, a.AircraftManufacturer, a.AircraftModel, a.AircraftCategory FROM Aviation.Event e JOIN Aviation.Aircraft a ON e.EventId = a.EventId WHERE Year(e.EventDate) = 2012'},
{'input': "Find all incidents for the aircraft with ID 'N12345'.", 'query': "SELECT * FROM Aviation.Event WHERE EventId IN (SELECT EventId FROM Aviation.Aircraft WHERE ID = 'N12345')"},
{'input': 'Find all incidents where there were more than 5 injuries and include the aircraft manufacturer and model.', 'query': 'SELECT e.EventId, e.InjuriesTotal, a.AircraftManufacturer, a.AircraftModel FROM Aviation.Event e JOIN Aviation.Aircraft a ON e.EventId = a.EventId WHERE e.InjuriesTotal > 5'},
{'input': 'List all aircrafts.', 'query': 'SELECT * FROM Aviation.Aircraft'},
{'input': 'Find the total number of distinct aircrafts involved in incidents.', 'query': 'SELECT COUNT(DISTINCT AircraftKey) FROM Aviation.Aircraft'}]
数量に関連した例が特に必要な場合は、それに応じてSelectorに問い合わせることができます。
input_query = "What is the number of incidents involving Boeing aircraft."
quantity_examples = example_selector.select_examples({"input": input_query})
出力は以下の通りです。
[{'input': 'How many incidents are associated with the aircraft with AircraftKey 5?', 'query': 'SELECT COUNT(*) FROM Aviation.Aircraft WHERE AircraftKey = 5'},
{'input': 'Find the total number of distinct aircrafts involved in incidents.', 'query': 'SELECT COUNT(DISTINCT AircraftKey) FROM Aviation.Aircraft'},
{'input': 'How many crew members were involved in incidents?', 'query': 'SELECT COUNT(*) FROM Aviation.Crew'},
{'input': 'Find all incidents where there were more than 5 injuries and include the aircraft manufacturer and model.', 'query': 'SELECT e.EventId, e.InjuriesTotal, a.AircraftManufacturer, a.AircraftModel FROM Aviation.Event e JOIN Aviation.Aircraft a ON e.EventId = a.EventId WHERE e.InjuriesTotal > 5'},
{'input': 'List all incidents with detailed aircraft information for incidents that occurred in the year 2012.', 'query': 'SELECT e.EventId, e.EventDate, a.AircraftManufacturer, a.AircraftModel, a.AircraftCategory FROM Aviation.Event e JOIN Aviation.Aircraft a ON e.EventId = a.EventId WHERE Year(e.EventDate) = 2012'}]
この出力には、特にカウントと量を扱った例が含まれています。
今後の検討事項
SemanticSimilarityExampleSelectorは強力ですが、選択された例がすべて完璧であるとは限らないことに注意することが重要です。
将来的な改良には、フィルターやしきい値を追加して関連性の低い結果を除外し、最も適切な例だけがLLMに提供されるようにすることが含まれるかもしれません。
精度テスト
プロンプトとSQLクエリ生成のパフォーマンスを評価するために、一連のテストを設定し実行する必要があります。その目的は、LLMがユーザーの入力に基づいてSQLクエリを生成する際に、例題に基づいたfew shotを使用する場合と使用しない場合の、その精度を評価することである。
SQLクエリを生成する関数
まず、LLMを使って、提供されたコンテキスト、プロンプト、ユーザー入力、その他のパラメーターに基づいてSQLクエリーを生成する関数を定義します。
def get_sql_from_text(context, prompt, user_input, use_few_shots, tables_vector_store, table_df, example_selector=None, example_prompt=None):
relevant_tables = get_relevant_tables(user_input, tables_vector_store, table_df)
context["table_info"] = "\n\n".join(relevant_tables)
examples = example_selector.select_examples({"input": user_input}) if example_selector else []
context["examples_value"] = "\n\n".join([
example_prompt.invoke(x).to_string() for x in examples
])
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
output_parser = StrOutputParser()
chain_model = prompt | model | output_parser
response = chain_model.invoke({
"top_k": context["top_k"],
"table_info": context["table_info"],
"examples_value": context["examples_value"],
"input": user_input
})
return response
プロンプトの実行
例文がある場合とない場合のプロンプトをテストします。
# Prompt execution **with** few shots
input = "Find all events in 2010 informing the Event Id and date, location city and state, aircraft manufacturer and model."
response_with_few_shots = get_sql_from_text(
context,
prompt,
user_input=input,
use_few_shots=True,
tables_vector_store=tables_vector_store,
table_df=table_df,
example_selector=example_selector,
example_prompt=example_prompt,
)
print(response_with_few_shots)
SELECT e.EventId, e.EventDate, e.LocationCity, e.LocationState, a.AircraftManufacturer, a.AircraftModel
FROM Aviation.Event e
JOIN Aviation.Aircraft a ON e.EventId = a.EventId
WHERE Year(e.EventDate) = 2010
# Prompt execution **without** few shots
input = "Find all events in 2010 informing the Event Id and date, location city and state, aircraft manufacturer and model."
response_with_no_few_shots = get_sql_from_text(
context,
prompt,
user_input=input,
use_few_shots=False,
tables_vector_store=tables_vector_store,
table_df=table_df,
)
print(response_with_no_few_shots)
SELECT TOP 3 "EventId", "EventDate", "LocationCity", "LocationState", "AircraftManufacturer", "AircraftModel"
FROM Aviation.Event e
JOIN Aviation.Aircraft a ON e.ID = a.Event
WHERE e.EventDate >= '2010-01-01' AND e.EventDate < '2011-01-01'
Utility Functions for Testing
生成されたSQLクエリをテストするために、いくつかのユーティリティ関数を定義します。
def execute_sql_query(cnx, query):
try:
cursor = cnx.cursor()
cursor.execute(query)
rows = cursor.fetchall()
return rows
except:
print('Error running query:')
print(query)
print('-'*80)
return None
def sql_result_equals(cnx, query, expected):
rows = execute_sql_query(cnx, query)
result = [set(row._asdict().values()) for row in rows or []]
if result != expected and rows is not None:
print('Result not as expected for query:')
print(query)
print('-'*80)
return result == expected
# SQL test for prompt **with** few shots
print("SQL is OK" if not execute_sql_query(cnx, response_with_few_shots) is None else "SQL is not OK")
SQL is OK
# SQL test for prompt **without** few shots
print("SQL is OK" if not execute_sql_query(cnx, response_with_no_few_shots) is None else "SQL is not OK")
error on running query:
SELECT TOP 3 "EventId", "EventDate", "LocationCity", "LocationState", "AircraftManufacturer", "AircraftModel"
FROM Aviation.Event e
JOIN Aviation.Aircraft a ON e.ID = a.Event
WHERE e.EventDate >= '2010-01-01' AND e.EventDate < '2011-01-01'
--------------------------------------------------------------------------------
SQL is not OK
テストの定義と実行
一連のテストケースを定義し、実行します。
tests = [{
"input": "What were the top 3 years with the most recorded events?",
"expected": [{128, 2003}, {122, 2007}, {117, 2005}]
},{
"input": "How many incidents involving Boeing aircraft.",
"expected": [{5}]
},{
"input": "How many incidents that resulted in fatalities.",
"expected": [{237}]
},{
"input": "List event Id and date and, crew number, age and gender for incidents that occurred in 2013.",
"expected": [{1, datetime.datetime(2013, 3, 4, 11, 6), '20130305X71252', 59, 'M'},
{1, datetime.datetime(2013, 1, 1, 15, 0), '20130101X94035', 32, 'M'},
{2, datetime.datetime(2013, 1, 1, 15, 0), '20130101X94035', 35, 'M'},
{1, datetime.datetime(2013, 1, 12, 15, 0), '20130113X42535', 25, 'M'},
{2, datetime.datetime(2013, 1, 12, 15, 0), '20130113X42535', 34, 'M'},
{1, datetime.datetime(2013, 2, 1, 15, 0), '20130203X53401', 29, 'M'},
{1, datetime.datetime(2013, 2, 15, 15, 0), '20130218X70747', 27, 'M'},
{1, datetime.datetime(2013, 3, 2, 15, 0), '20130303X21011', 49, 'M'},
{1, datetime.datetime(2013, 3, 23, 13, 52), '20130326X85150', 'M', None}]
},{
"input": "Find the total number of incidents that occurred in the United States.",
"expected": [{1178}]
},{
"input": "List all incidents latitude and longitude coordinates with more than 5 injuries that occurred in 2010.",
"expected": [{-78.76833333333333, 43.25277777777778}]
},{
"input": "Find all incidents in 2010 informing the Event Id and date, location city and state, aircraft manufacturer and model.",
"expected": [
{datetime.datetime(2010, 5, 20, 13, 43), '20100520X60222', 'CIRRUS DESIGN CORP', 'Farmingdale', 'New York', 'SR22'},
{datetime.datetime(2010, 4, 11, 15, 0), '20100411X73253', 'CZECH AIRCRAFT WORKS SPOL SRO', 'Millbrook', 'New York', 'SPORTCRUISER'},
{'108', datetime.datetime(2010, 1, 9, 12, 55), '20100111X41106', 'Bayport', 'New York', 'STINSON'},
{datetime.datetime(2010, 8, 1, 14, 20), '20100801X85218', 'A185F', 'CESSNA', 'New York', 'Newfane'}
]
}]
精度評価
テストを実施し、精度を計算します。
def execute_tests(cnx, context, prompt, use_few_shots, tables_vector_store, table_df, example_selector, example_prompt):
tests_generated_sql = [(x, get_sql_from_text(
context,
prompt,
user_input=x['input'],
use_few_shots=use_few_shots,
tables_vector_store=tables_vector_store,
table_df=table_df,
example_selector=example_selector if use_few_shots else None,
example_prompt=example_prompt if use_few_shots else None,
)) for x in deepcopy(tests)]
tests_sql_executions = [(x[0], sql_result_equals(cnx, x[1], x[0]['expected']))
for x in tests_generated_sql]
accuracy = sum(1 for i in tests_sql_executions if i[1] == True) / len(tests_sql_executions)
print(f'Accuracy: {accuracy}')
print('-'*80)
結果
# Accuracy tests for prompts executed **without** few shots
use_few_shots = False
execute_tests(
cnx,
context,
prompt,
use_few_shots,
tables_vector_store,
table_df,
example_selector,
example_prompt
)
error on running query:
SELECT "EventDate", COUNT("EventId") as "TotalEvents"
FROM Aviation.Event
GROUP BY "EventDate"
ORDER BY "TotalEvents" DESC
TOP 3;
--------------------------------------------------------------------------------
error on running query:
SELECT "EventId", "EventDate", "C"."CrewNumber", "C"."Age", "C"."Sex"
FROM "Aviation.Event" AS "E"
JOIN "Aviation.Crew" AS "C" ON "E"."ID" = "C"."EventId"
WHERE "E"."EventDate" >= '2013-01-01' AND "E"."EventDate" < '2014-01-01'
--------------------------------------------------------------------------------
result not expected for query:
SELECT TOP 3 "e"."EventId", "e"."EventDate", "e"."LocationCity", "e"."LocationState", "a"."AircraftManufacturer", "a"."AircraftModel"
FROM "Aviation"."Event" AS "e"
JOIN "Aviation"."Aircraft" AS "a" ON "e"."ID" = "a"."Event"
WHERE "e"."EventDate" >= '2010-01-01' AND "e"."EventDate" < '2011-01-01'
--------------------------------------------------------------------------------
accuracy: 0.5714285714285714
--------------------------------------------------------------------------------
# Accuracy tests for prompts executed **with** few shots
use_few_shots = True
execute_tests(
cnx,
context,
prompt,
use_few_shots,
tables_vector_store,
table_df,
example_selector,
example_prompt
)
error on running query:
SELECT e.EventId, e.EventDate, e.LocationCity, e.LocationState, a.AircraftManufacturer, a.AircraftModel
FROM Aviation.Event e
JOIN Aviation.Aircraft a ON e.EventId = a.EventId
WHERE Year(e.EventDate) = 2010 TOP 3
--------------------------------------------------------------------------------
accuracy: 0.8571428571428571
--------------------------------------------------------------------------------
結論
例(few shots)を使って生成されたSQLクエリの精度は、例なしで生成されたもの(85%対57%)に比べて約49%高くなりました。
ご参考
- https://python.langchain.com/v0.1/docs/expression_language/get_started/
- https://python.langchain.com/v0.1/docs/use_cases/sql/prompting/
- https://python.langchain.com/v0.1/docs/modules/model_io/prompts/composition/
[このノートブック]: https://github.com/musketeers-br/sqlzilla/blob/master/jupyter/SQLFromText-article.ipynb
Comments
どうもありがとうございます @Mihoko Iijima