IRIS BI開発者向けチュートリアルを試してみる(5)
はじめに
IRIS BIチュートリアル試してみたシリーズの5回目です。
今回も、前回同様チュートリアルの「キューブの作成」ページになります。
前回はキューブを作成し、そのキューブを使用していくつかのピボットテーブルを作成しました。
その中で気になった点を今回は修正していきます。では、はじめていきましょう。
キューブの調整
前回の作業の中で、ピボットテーブル作成時に気になった点は以下のものがありました。
- Age メンバの並び順が数値の順になっていない
- 担当医師不在の場合に、医師名に「,」のみ表示される
- 同姓同名の医師が存在した場合に、データが一緒くたになってしまう
では、これらを解消していきましょう。アーキテクト画面で Tutorial キューブを開きます。
キューブが開いたら、 Age レベルをクリックし、続いて [要素を追加] をクリックします。
要素名に AgeSort と入力し、要素選択は プロパティ を指定します。
AgeSort プロパティができました。
では、AgeSort プロパティの詳細設定を変えます。詳細ペインの [表現] に以下の式を設定します。
$CASE($LENGTH(%source.Age),2:%source.Age,:"0"_%source.Age)Ageが1ケタの場合は、頭にゼロを付けるという式ですね。
もう1箇所、[プロパティ値でメンバを並び替え] に、昇順を意味する asc を指定します。
指定ができたら、キューブを一旦保存しておきます。
続いて、Doctor に関する設定を変更していきます。DocD ディメンジョンの Doctor レベルをクリックし、詳細ペインに設定されている数式をメモ帳などにコピーしておきます。(後の作業で使用します)
%source.PrimaryCarePhysician.LastName_", "_%source.PrimaryCarePhysician.FirstName詳細ペインの [ソース値] のところを、プロパティ を選択し、すぐ下のテキストボックスに PrimaryCarePhysician と入力します。
テキストボックス横の虫眼鏡アイコンをクリックすると、選択のダイアログが出てきますので、そこから選択することも可能です。
引き続き、Doctor に対するプロパティを追加します。Doctor レベルが選択されている状態で [要素を追加] リンクをクリックし、ダイアログを開きます。
要素名に DoctorName 、要素タイプに プロパティ を指定します。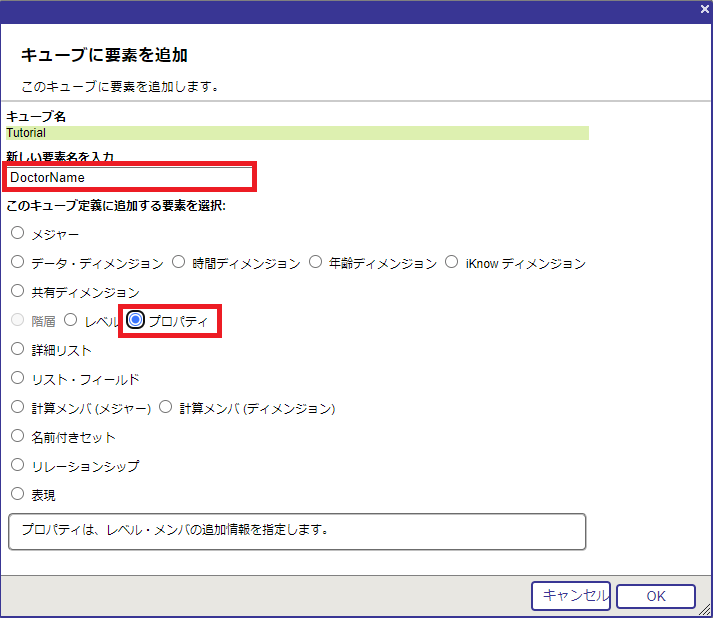
DoctorName プロパティが追加されました。このプロパティの詳細設定を変更します。
[表現] のところに、先ほどコピーした数式を貼り付けます。
加えて、[メンバの名前として使用] のチェックを ON にし、[プロパティ値でメンバを並べ替え] に asc を指定します。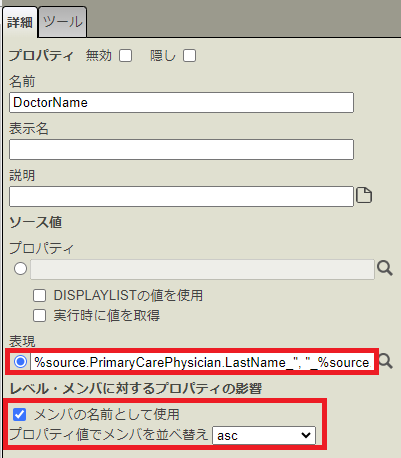
設定ができたら、キューブを保存、コンパイル、ビルドします。ビルドの際のオプションは [すべて構築] にします。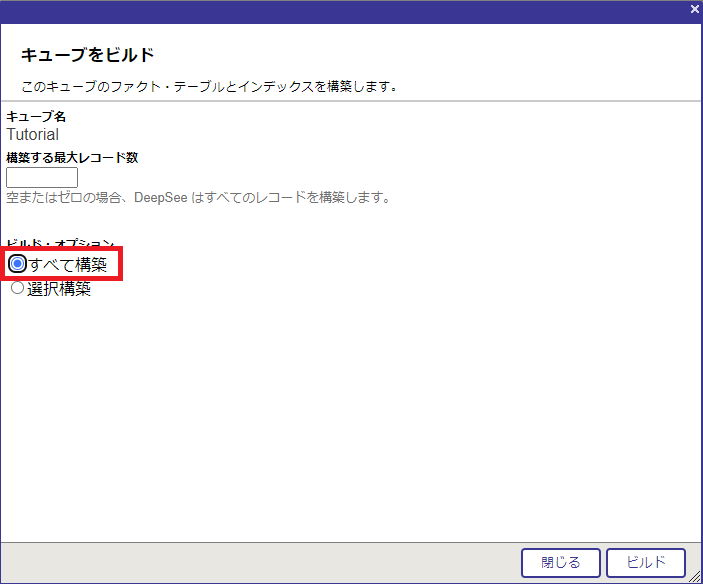
これで、キューブの設定変更ができました。では、再びアナライザで確認してみましょう。
もし、変更前の状態からアナライザ画面を開いていた場合には、キューブの再読み込みを行いましょう。
変更した内容を確認してみます。AgeD ディメンジョンを展開すると AgeSort プロパティが追加されているはずです。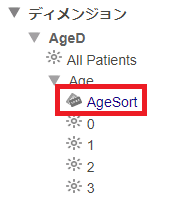
また DocD ディメンジョンには DoctorName プロパティが追加されているはずです。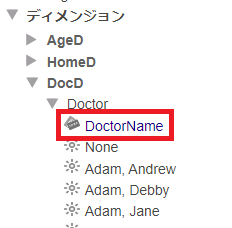
では、前回と同じピボットテーブルを作成して確認します。Age レベルを [行] にドラッグ&ドロップします。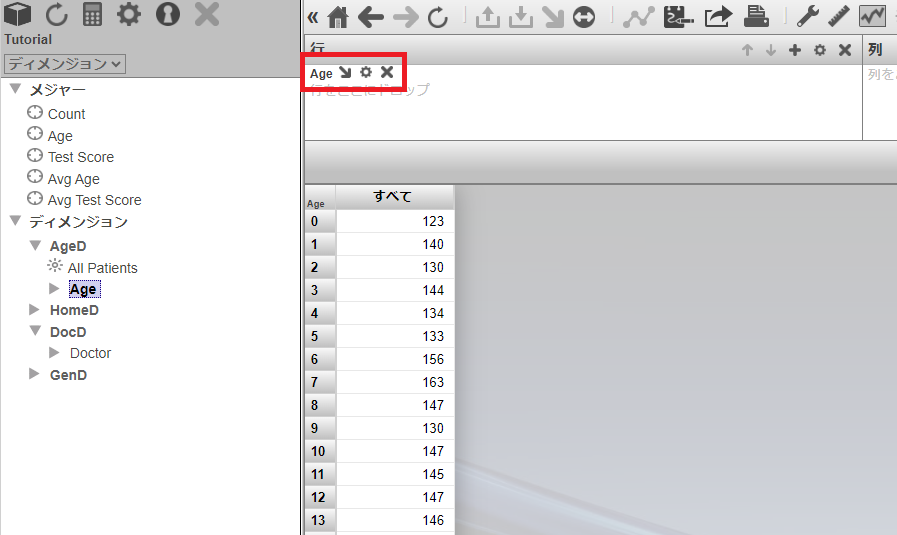
※注意:サンプルデータはランダムに作成されるため、こちらの画面表示とみなさまの実行結果は一致しないことがあります。
Age の値が 0→1→2…と数値順になりましたね。
次は医師名の確認です。[行] を Age から Doctor に入れ替えます。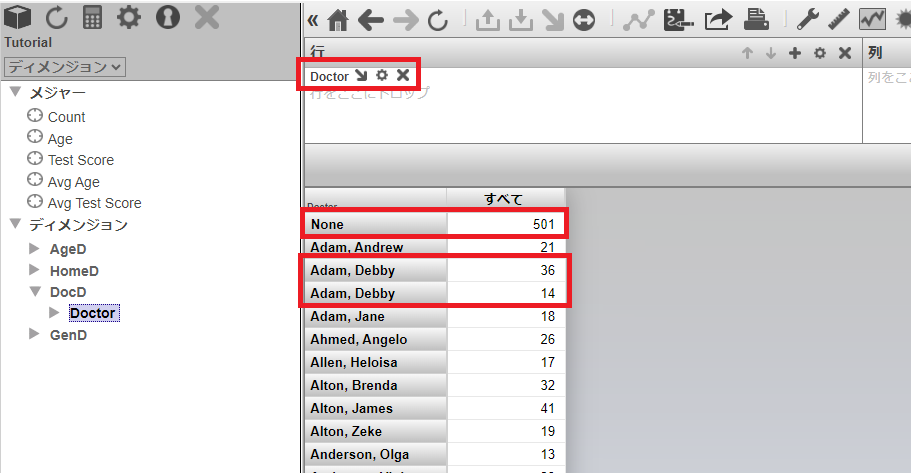
変更前はカンマ表示されていた医師名が None と表示されるようになりました。
また、私の場合はAdam, Debby 医師が2名いたようですが、別々に表示されるようになりました。
キューブへのリストの追加
次は、リストの作成と設定を行います。リストは3回目の記事で登場しましたね。
まずは、リストの基になる項目を確認します。別のウィンドウで管理ポータル画面を開き、システムエクスプローラ → SQL で以下のSQLを実行します。
select patientid, age,testscore,homecity->name as "City",
primarycarephysician->lastname as "Doctor" from BI_Study.Patient患者ID(PatientID)、年齢(Age)、検査値(TestScore)、市(City)、医師の苗字(Doctor)の5項目が一覧表示されます。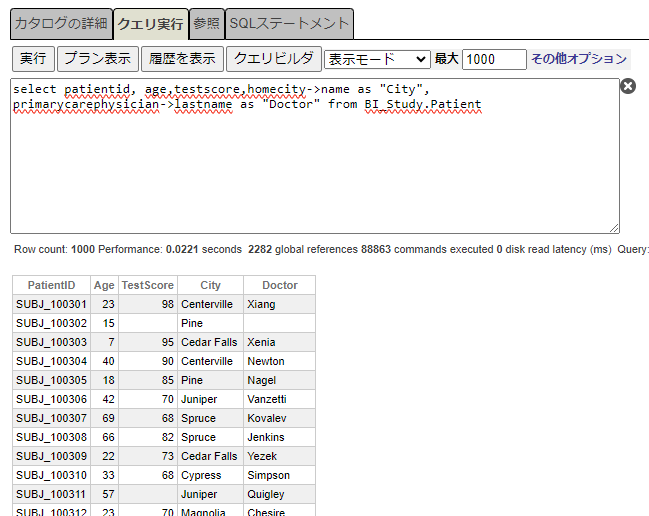
これと同じものをリスト表示させます。アーキテクト画面に戻り、[要素を追加] リンクをクリックします。
要素名に SampleListing と入力し、要素選択で [詳細リスト] を選びます。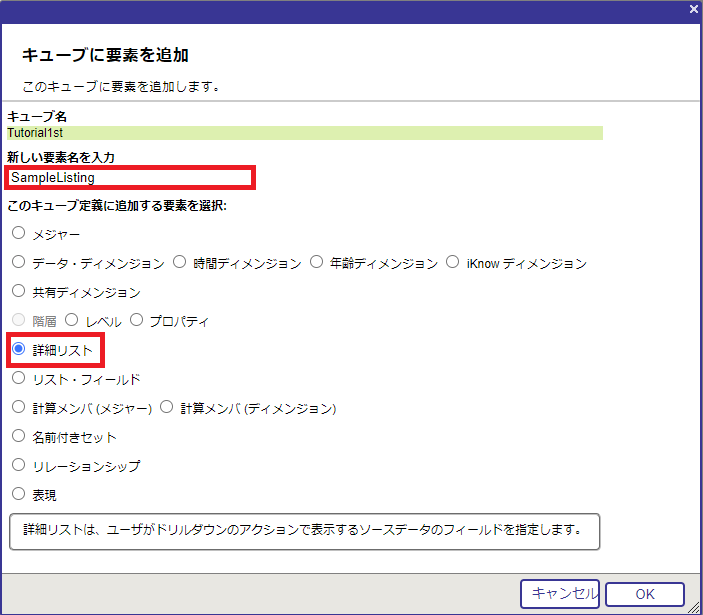
[OK] をクリックすると、モデル・ビューワの詳細リストに、SampleListing が追加されます。
SampleListing が選択されている状態で、詳細ペインの [フィールドリスト] に、先ほどのSQLの項目名指定の部分を貼り付けます。以下の内容です。
patientid, age,testscore,homecity->name as "City", primarycarephysician->lastname as "Doctor"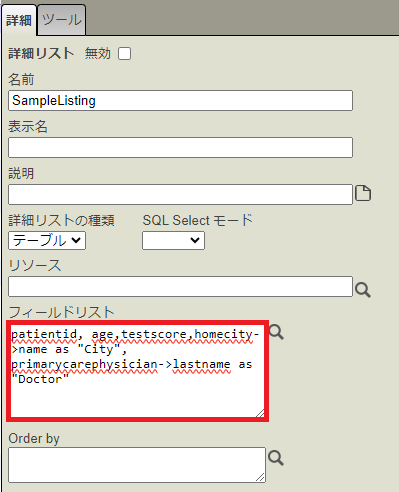
では、変更を保存してコンパイルします。今回はビルドは不要です。
アナライザ画面で、作成したリストの確認をしてみましょう。変更前の状態の場合は再読み込みを行ってください。
[行] にDoctor を指定し、作成されたピボットテーブルの中のどこかの値を選択して、リスト表示ボタンをクリックします。双眼鏡のアイコンです。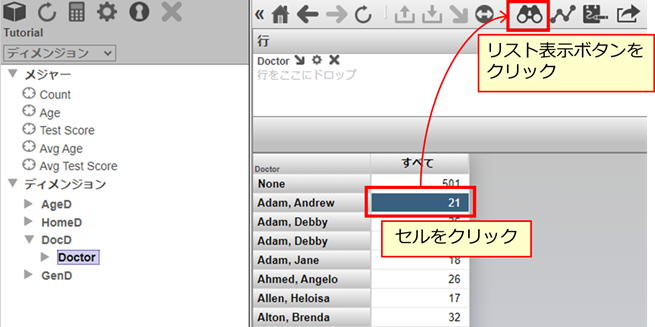
画面がリストに切り替わりました。21件のデータが一覧表示されました。.png)
このリストの並び順を変更してみます。アーキテクト画面に戻り、先ほどの SampleListing を選択します。
詳細ペインの [Order by] に、以下の値を指定します。
age,homecity->name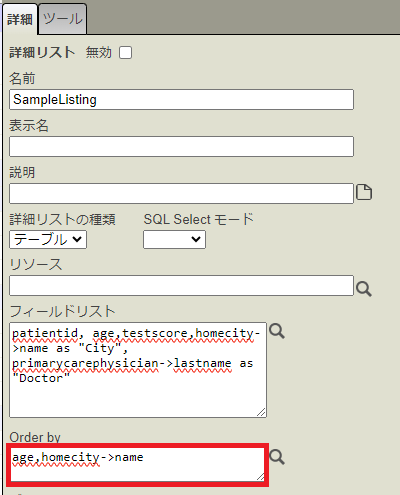
キューブを保存、コンパイルして、再びアナライザ画面で先ほどを同じ作業を行ってみます。キューブを再読み込みすることも忘れずに。
今度はリストが年齢の小さい順(昇順)、市名の昇順に並んでいます。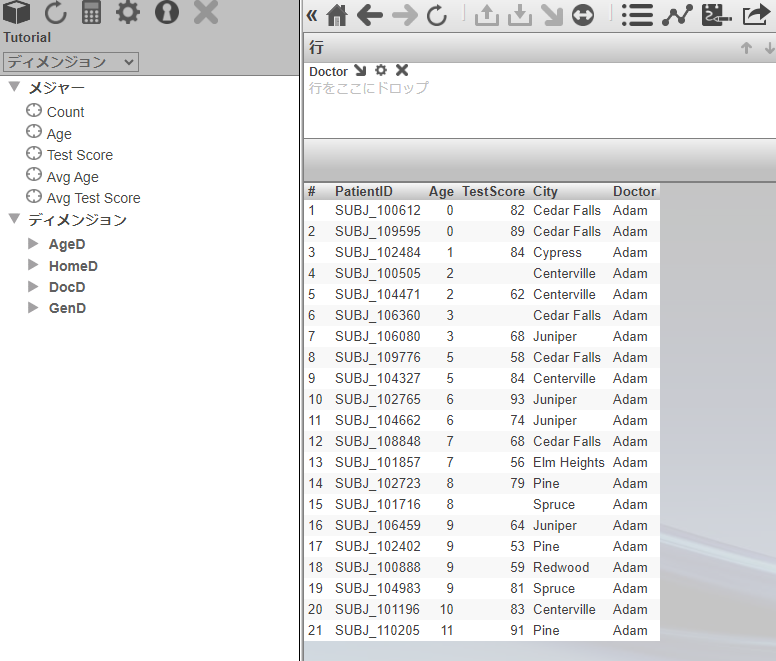
ファクトテーブルおよびレベルテーブルの確認
キューブの作成に伴って、ファクトテーブルとレベルテーブルが裏側で作成されます。
では、いったいどんなテーブルが作成されるのかを垣間見ていきたいと思います。
管理ポータル画面から、SQL画面を開き、以下のSQL文を実行します。
select top 1 ID,age,gender,homecity->name,primarycarephysician->lastname,
primarycarephysician->firstname, testscore from BI_Study.patient以下のような結果が返ってきました。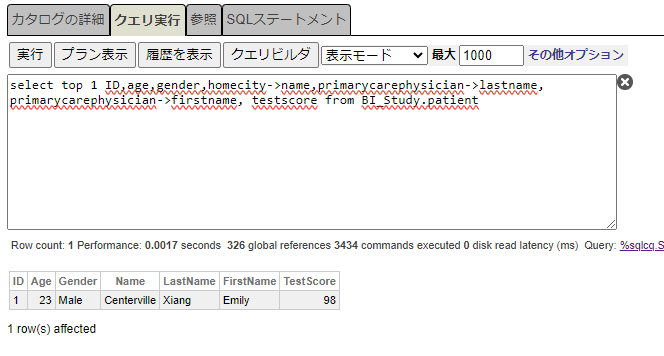
次に、画面左側の一覧から Tutorial_Cube.Fact テーブルを選択し、[テーブルを開く] でテーブルの中身を見てみます。
スキーマを Tutorial_Cube に絞り込むと探しやすいかもしれません。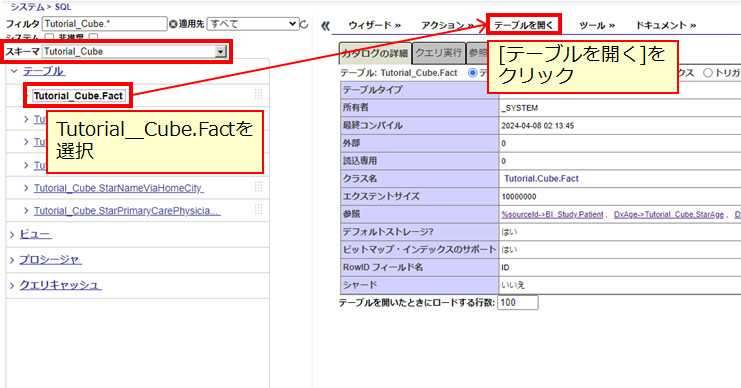
テーブルの内容が表示されました。数値項目だらけのテーブルですね。。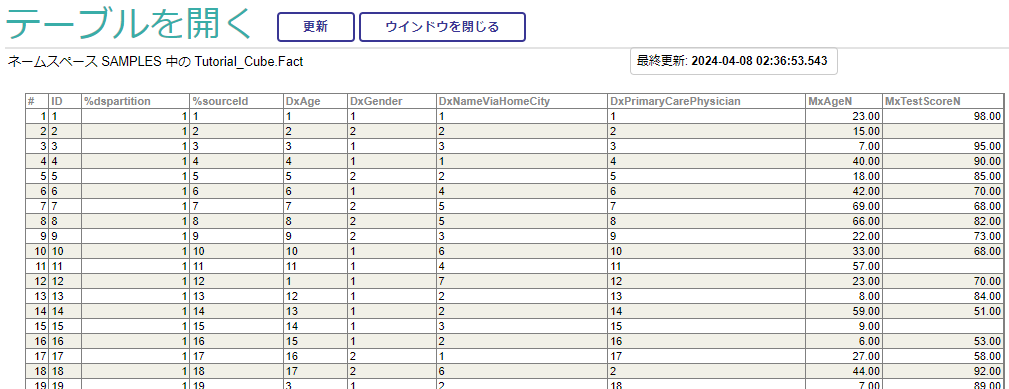
ファクトテーブルは、以下の要素で構成されています。
- ベースとなったテーブルのレコードID(%sourceId)
- キューブ内で定義したレベルに該当する項目(名前が"Dx"で始まるカラム)
- キューブ内で定義したメジャーに該当する項目(名前が"Mx"で始まるカラム)
先ほどSQLで検索したID=1のレコードが1行目にあります。MxAgeNが23.00、MxTestScoreNが98.00なので一致してますね。
続いてレベルテーブルを見ていきます。開いている Fact テーブルのウィンドウを閉じ、左側のリストから Tutorial_Cube.StarGender テーブルを選択して、[テーブルを開く] リンクをクリックします。
2件のレコードを持つテーブルです。性別(Gender)を表すので、Male と Female の2パターンだけのようですね。
先ほどのファクトテーブルの DxGender カラムの値が、こちらの ID と連動する、いわゆる結合キーとなります。
続いて Tutorial_Cube.StarAge テーブルを開きます。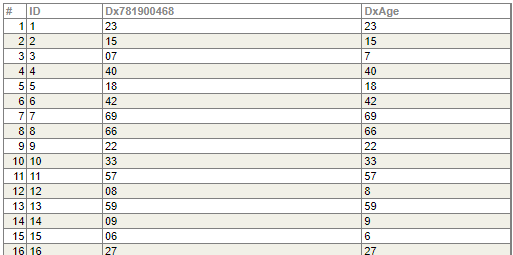
IDの他に2つのカラム、DxAge と Dx781900468 があります。同じような値が入っていますが、3行目を見ると「07」と「7」がセットされています。
Dx781900468 の値は、先ほど作った AgeSort プロパティの値ですね。
次は Tutorial_Cube.StarNameViaHomeCity テーブルを開きます。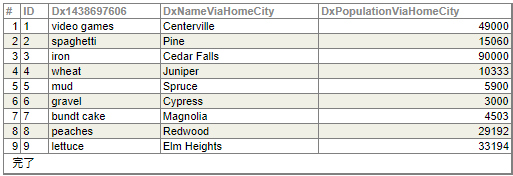
City レベルに該当するカラムと、追加した2つのプロパティのカラムが存在します。
最後に Tutorial_Cube.StarPrimaryCarePhysician テーブルを見てみます。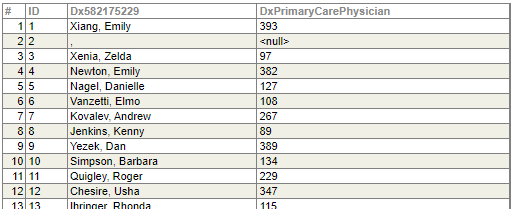
ベーステーブルの PrimaryCarePhysician カラムと、プロパティで定義した DoctorName の2つのカラムがあります。
2行目は PrimaryCarePhysician の値が null になっており、DoctorName の値はカンマがセットされています。
モデルの定義でヌル置換文字列を設定(None)したので、これに該当するレコードは、アナライザで「,」でなく「None」表示されるようになったということです。
なお、これらのテーブルのカラム名ですが、詳細ペインの [ファクトテーブルのフィールド名] または [レベルテーブルのフィールド名] で設定できます。
試しに、DoctorName プロパティのカラム名を DxDoctorName としてみます。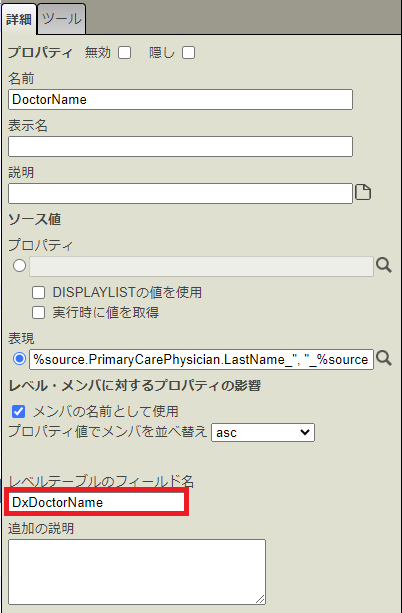
キューブを保存、コンパイルし、再びSQL画面からテーブルを開いてみると、DxDoctorName に変わっていることが分かります。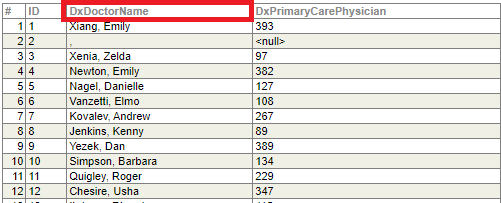
おわりに
今回はアーキテクト画面でキューブの設定について学びました。
また、キューブ作成に伴って作成されるファクトテーブルとレベルテーブルについても確認しました。
これでチュートリアルのちょうど半分が終わりました。次回からは後半戦、キューブ定義の拡張を行っていきます。お楽しみに!