 Open Exchange
Open ExchangeHola desarrolladores:
Al observar la avalancha de herramientas de desarrollo impulsadas por IA y al estilo vibe coding que han estado apareciendo últimamente casi cada mes, con funciones cada vez más emocionantes, me preguntaba si sería posible aprovecharlas con InterSystems IRIS. Al menos para construir un frontend. Y la respuesta es: ¡sí! Al menos con el enfoque que seguí en este ejemplo.
Aquí tenéis mi receta para crear la interfaz de usuario mediante prompts frente al backend de InterSystems IRIS:
- Tened una API REST en el lado de IRIS, que refleje una especificación Open API (swagger).
- Generad la interfaz de usuario con cualquier herramienta de vibe coding (por ejemplo, Lovable) y apuntad la interfaz al endpoint de la API REST.
- ¡Y listo!
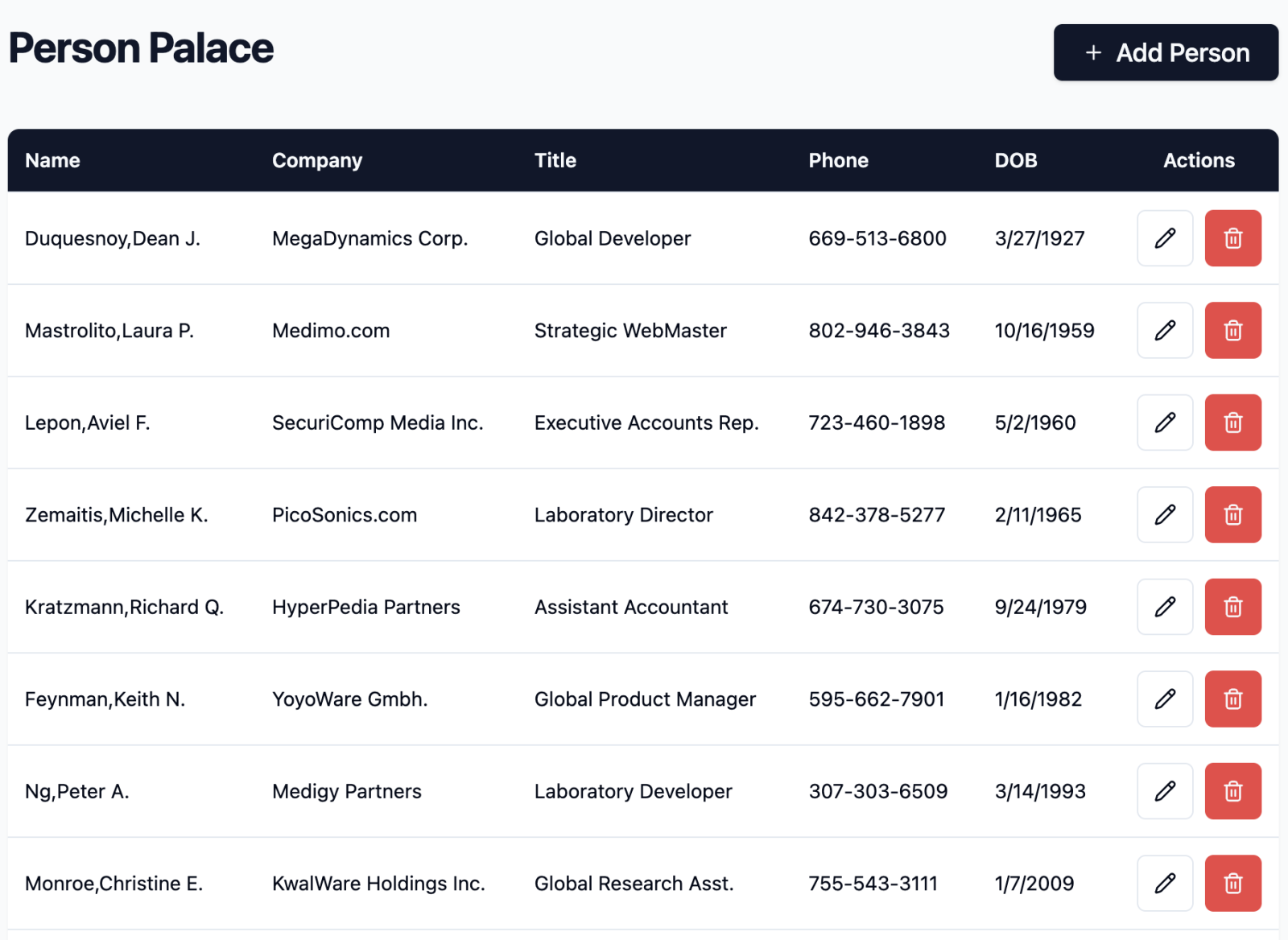
Aquí tenéis el resultado de mi propio experimento: una interfaz 100 % generada por prompts frente a la API REST de IRIS, que permite listar, crear, actualizar y eliminar entradas de una clase persistente (Open Exchange, código del frontend, vídeo).
¿Cómo es la receta en detalle?
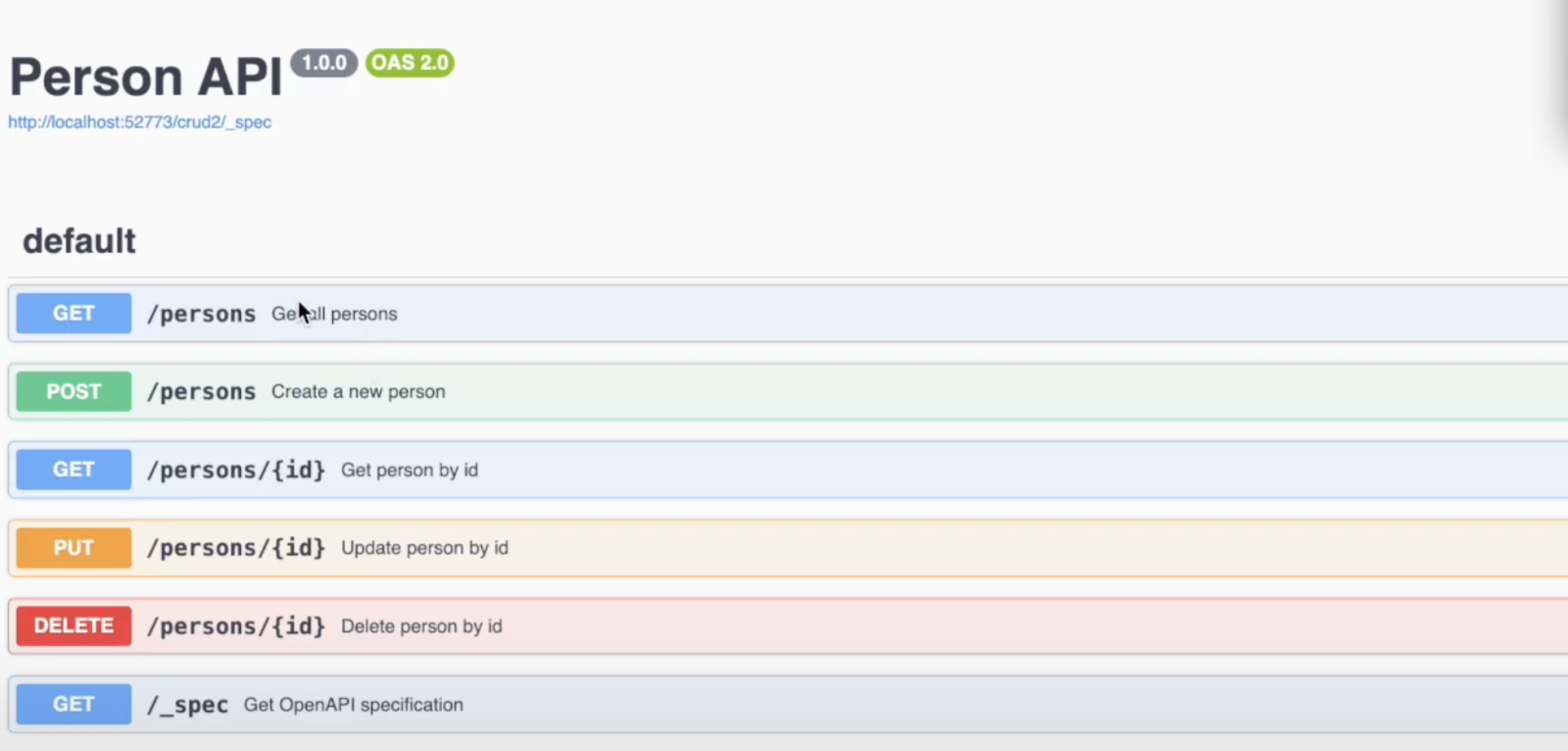
¿Cómo obtener la especificación Open API (Swagger) frente al backend de IRIS?
Tomé como plantilla la clase persistente dc.Person, que contiene algunos campos simples: Nombre, Apellido, Empresa, Edad, etc.
Pensé que podría utilizar ChatGPT para generar la especificación Swagger, pero creo que se volvería un poco tímido si le paso directamente ObjectScript, así que generé la DDL correspondiente a la clase desde el terminal:
Do $SYSTEM.SQL.Schema.ExportDDL("dc_Sample","*","/home/irisowner/dev/data/ddl.sql")Y le pasé a ChatGPT el DDL con este prompt:
Please create an Open API spec in JSON version 2.0 vs the following DDL which will allow to get all the entries and individual ones, create, update, delete entries. Also, add _spec endpoint with OperationId GetSpec. Please provide meaningful operation id's for all the endpoints. The DDL: CREATE TABLE dc_Sample.Person( %PUBLICROWID, Company VARCHAR(50), DOB DATE, Name VARCHAR(-1), Phone VARCHAR(-1), Title VARCHAR(50) ) GO CREATE INDEX DOBIndex ON dc_Sample.Person(DOB) GO
Y funcionó bastante bien: aquí tenéis el resultado.
Después, usé la herramienta de línea de comandos %REST para generar las clases del backend REST.
Tras eso, implementé la lógica REST de IRIS con ObjectScript para las llamadas GET, PUT, POST y DELETE openexchange.intersystems.com/package/iris-web-swagger-ui. Casi todo lo hice a mano ;) con algo de ayuda del Co-pilot en VSCode.
Probé la API REST manualmente con Swagger-UI y, cuando todo estuvo listo, comencé a construir la interfaz de usuario.
La interfaz de usuario fue generada mediante prompts usando la herramienta Lovable.dev, a la que le pasé el siguiente prompt:
Please create a modern, convenient UI vs. the following open API spec, which will allow list, create, update, and delete persons
{ "swagger": "2.0", "info": { "title": "Person API", "version": "1.0.0" }, ...
(...) el promt seguía con toda la especificación Swagger.
Una vez que la interfaz fue construida y probada manualmente, le pedí a Lovable que la conectara con el endpoint REST API en IRIS. Primero lo hice localmente en Docker y, tras algunas pruebas y correcciones de errores (también vía prompts), desplegué el resultado final.
Algunos detalles y lecciones aprendidas:
- La seguridad de la API REST en el lado de IRIS no siempre es evidente desde el inicio, en especial por temas relacionados con CORS. Por ejemplo, tuve que añadir una clase especial cors.cls y modificar manualmente la especificación Swagger para que CORS funcionara correctamente.
- La documentación Swagger no funciona automáticamente en Docker con IRIS, pero se puede solucionar creando un endpoint especial _spec y añadiendo unas líneas de código en ObjectScript.
- La especificación Swagger para IRIS debe ser la versión 2.0, no la 3.1 ni la más reciente.
En resumen:
Este enfoque resulta ser una forma bastante efectiva para que un desarrollador backend en IRIS construya prototipos completos de aplicaciones full-stack en muy poco tiempo y sin necesidad de conocimientos previos de desarrollo frontend.
Contadme qué opináis.
¿Y cuál ha sido vuestra experiencia vibe coding con IRIS?
Aquí tenéis el vídeo con la demostración:
%20(2).jpg)