¿Cómo tokenizar un texto usando SentenceTransformer?
Hola a todos.
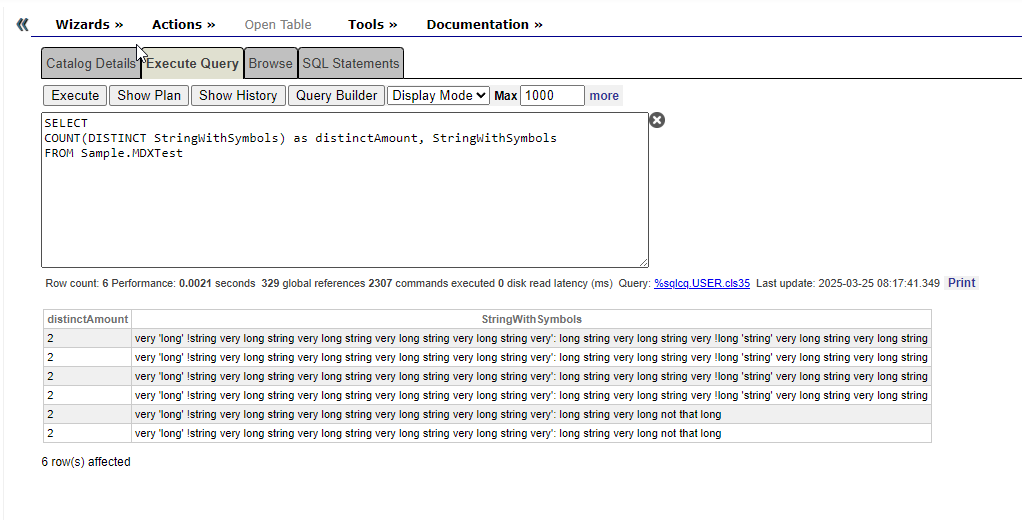
Estoy intentando crear una tabla indexada con un campo vectorial para poder buscar por su valor. He estado investigando y descubrí que, para obtener el valor del vector a partir del texto (token), se debe usar un método de Python como el siguiente:
ClassMethod TokenizeData(desc As %String) As %String [ Language = python ]
{
import iris
# Step 2: Generate Document Embeddings
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('/opt/irisbuild/all-MiniLM-L6-v2')
# Generate embeddings for each document
document_embeddings = model.encode(desc)
return document_embeddings.tolist()
}El modelo all-MiniLM-L6-v2 se descargó de https://ollama.com/library/all-minilm y se instaló en mi instancia de Docker.
Al intentar probar este método (desde Visual Studio), se generó el siguiente error:
<THROW>DebugStub+40^%Debugger.System.1 *%Exception.PythonException <PYTHON EXCEPTION> 246 <class 'OSError'>: It looks like the config file at '/opt/irisbuild/all-MiniLM-L6-v2/config.json' is not a valid JSON file.
Luego cambié el archivo config.json para crear un archivo JSon válido (solo escribí las llaves) y repetí la prueba, pero hay un nuevo error.
<THROW>DebugStub+40^%Debugger.System.1 *%Exception.PythonException <PYTHON EXCEPTION> 246 <class 'safetensors_rust.SafetensorError'>: Error while deserializing header: HeaderTooSmall
¿Alguien sabe cómo solucionar este problema?
¿Hay alguna otra forma de crear el valor del vector para poder indexarlo?
Saludos cordiales.