ISC 开发者们,我向你们致敬 👑。
多卷数据库
下面有关多卷数据的解释直接从文档搬过来的:
在InterSystems IRIS的默认配置中,数据库会使用单个 IRIS.DAT 文件保存数据。 你也可以将数据库配置为在当其达到指定大小阈值时自动保存到另外的文件(IRIS–0001.VOL、IRIS–0002.VOL 等等)中。 这些文件可能位于与 IRIS.DAT 相同的目录中和/或一组其他的目录中。
我这里想做的是设置一个较小阈值,并检查在备用目录上保存的多个扩展的数据卷。毫无疑问,这对镜像、性能 以及管理的影响是巨大的。简单来说,,前瞻性的解决方案考虑是否可以注入一个“回调”机制,并在溢出扩展之前即时地配置一个新的云存储卷。。
环境
我在 2024.1 (Build 263U) 上有一个正在运行的IRIS实例,我的 $ISC_DATA_DIRECTORY 设置为一个 50Gi 的OpenEBS PVC,这是大概一个月前配置的。
我向命名空间添加了一个额外的 OpenEBS PVC:
#kind: PersistentVolumeClaim
#apiVersion: v1
#metadata:
# name: jiva-iris-volume-claim
#spec:
# storageClassName: openebs-jiva-csi-default
# accessModes:
# - ReadWriteOnce
# resources:
# requests:
# storage: 50Gi
#--
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: jiva-iris-volume-claim-mv
spec:
storageClassName: openebs-jiva-csi-default
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Gi应用
sween@run1:~$ kubectl apply -f deezwatts-volume.yaml -n rivian
persistentvolumeclaim/jiva-iris-volume-claim-mv created随后,通过初始化容器应用这些设置。
<snips>
volumes:
- name: task-pv-storage
persistentVolumeClaim:
claimName: jiva-iris-volume-claim
- name: task-pv-storage-mvd
persistentVolumeClaim:
claimName: jiva-iris-volume-claim-mv
<snips>
volumeMounts:
- name: task-pv-storage
mountPath: /data
- name: task-pv-storage-mvd
mountPath: /data-mvd现在,我们将另一个磁盘卷设置为 `/data-mvd` 的多卷扩展存储

设置
以下是使用 System Management进行设置
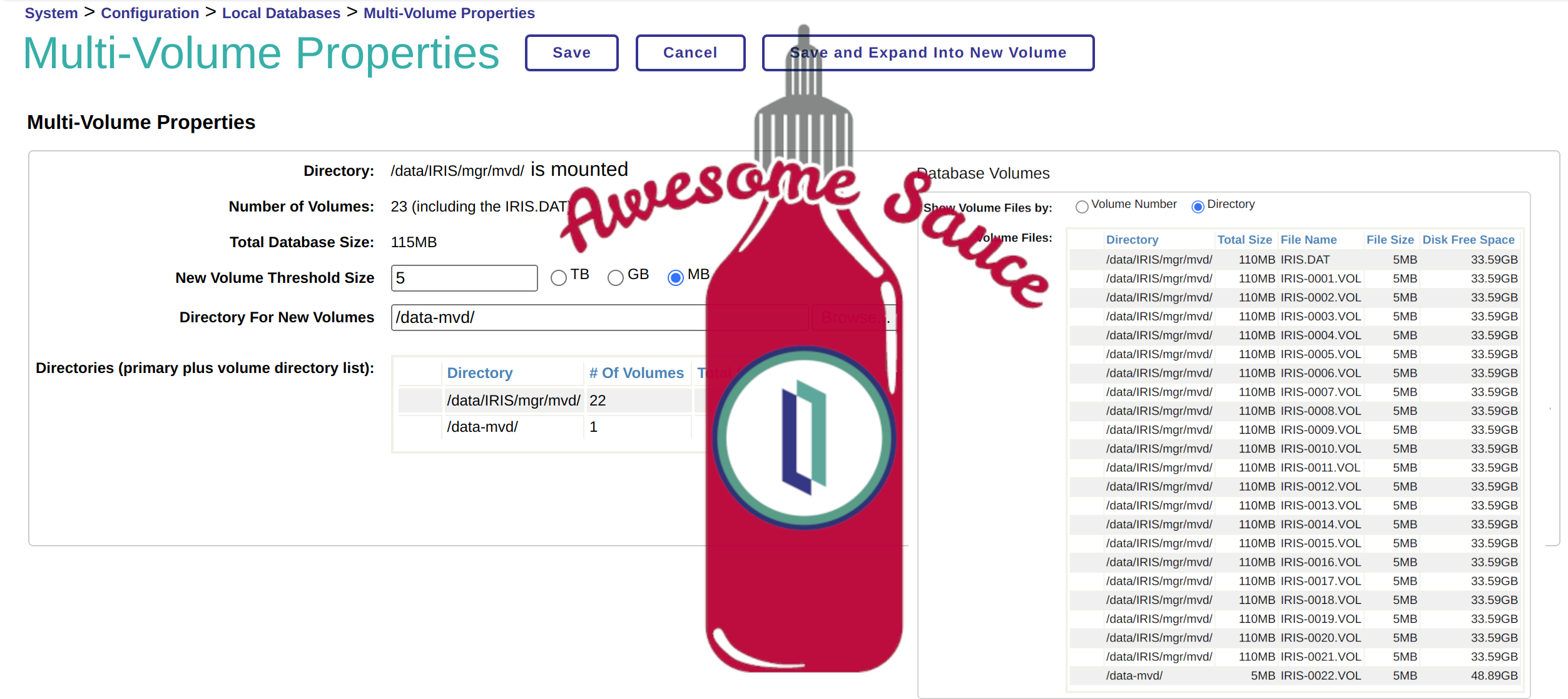
首先在IRIS的实例中创建数据库,并设置创建数据库的一些基本属性。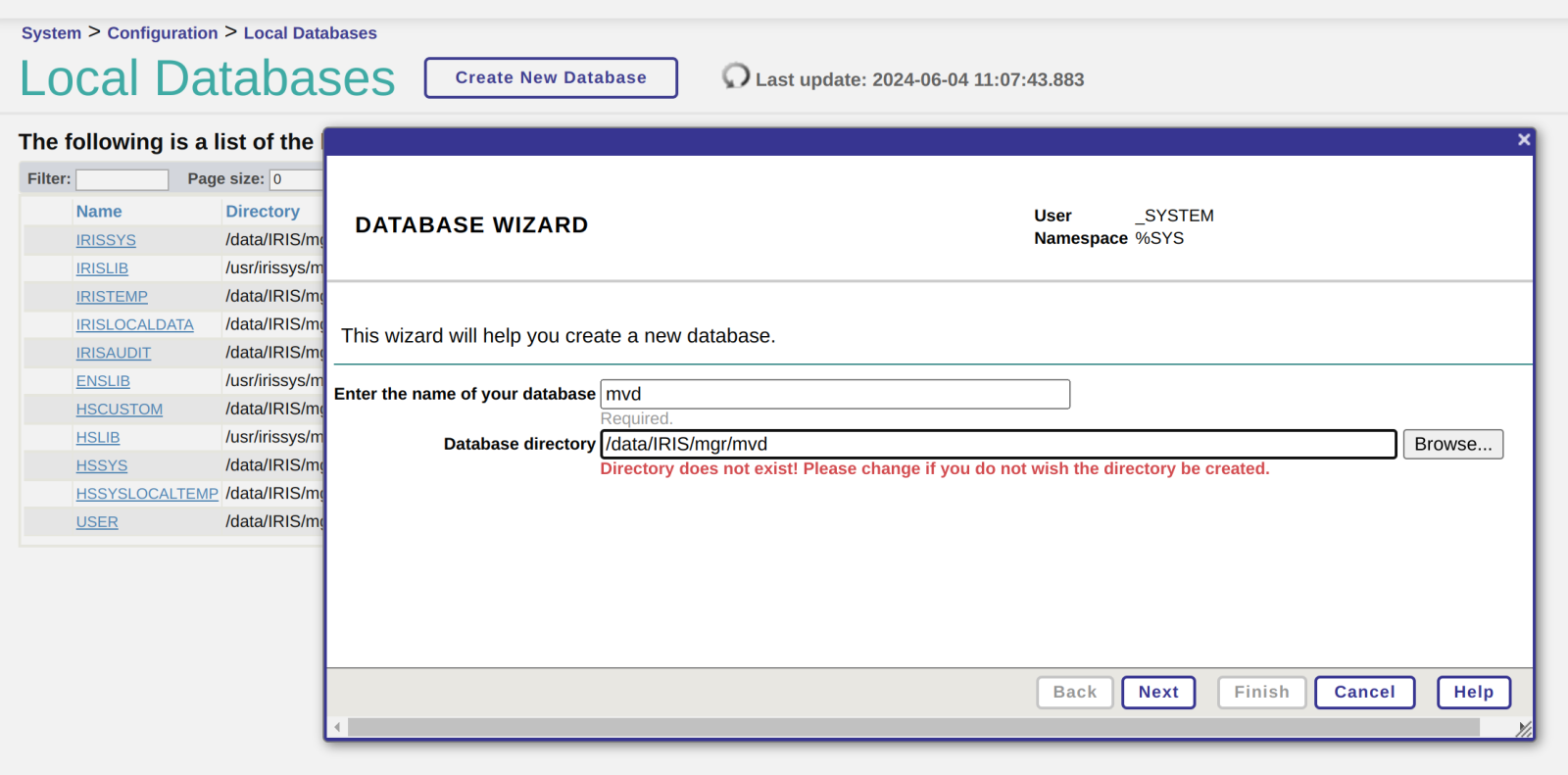
我们创建了数据库“mvd”,以及主数据库文件保存路径,在点击Next后,向导页面会有一些新的设置内容:
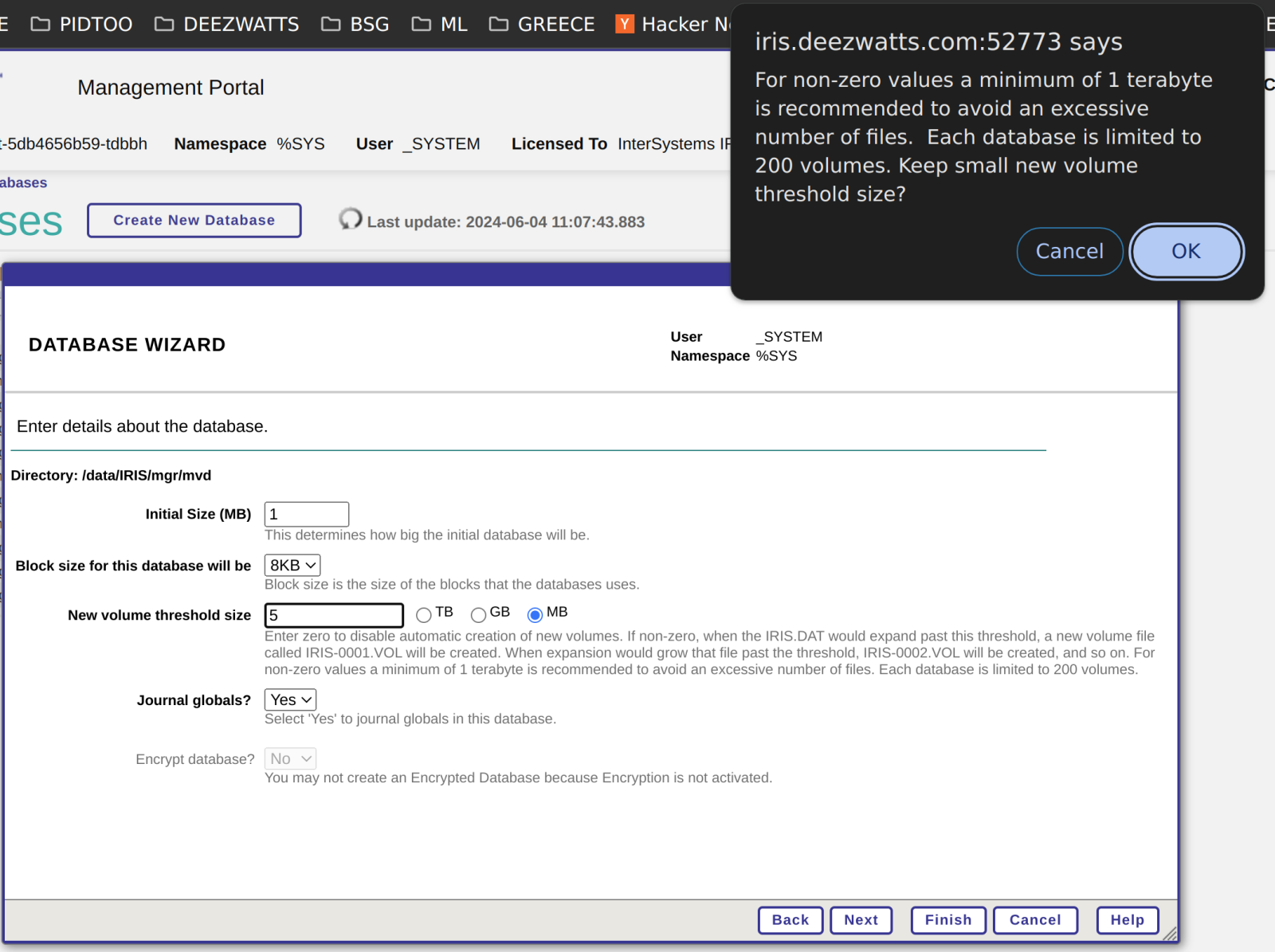
New Volume Threshold 设置触发扩展存储的数据库大小,在设置后请注意配置参数下方的提示,这个提示非常重要。否则,你又会看到相关的警告。
输入值为零则禁用新卷的自动创建。 如果不为零,当 IRIS.DAT 大小达到到此阈值时,将创建名为 IRIS-0001.VOL 的新数据库文件。 当新数据库文件再次达到阈值时,将创建 IRIS-0002.VOL文件,依此类推。 对于非零值,建议至少设置为 1 TB,以避免文件数量过多。 每个数据库被限制为最多扩展使用200 个数据库文件。
第二步,挂载新的数据库,在挂载之前无法对其进行其他配置。
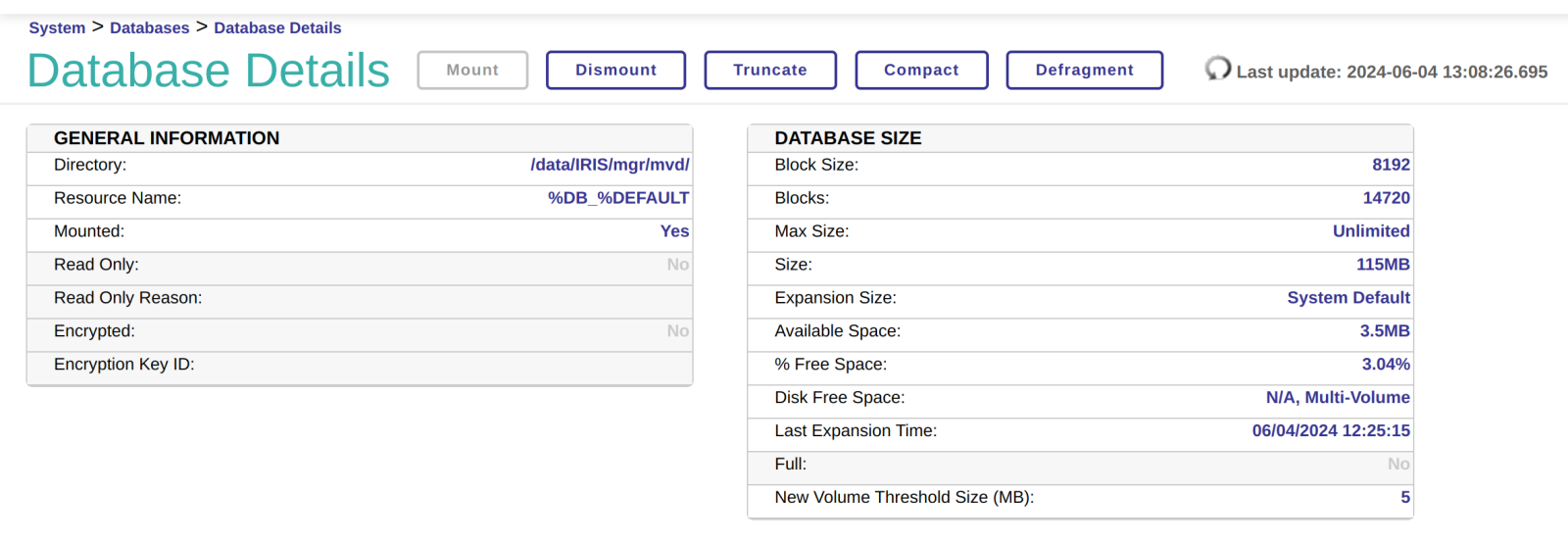
现在,我们可以在数据库列表中看到 Volumes 的选项
.png)
点进Volumes后,我们可以为扩展使用多个数据库文件的数据库设置备用保存位置。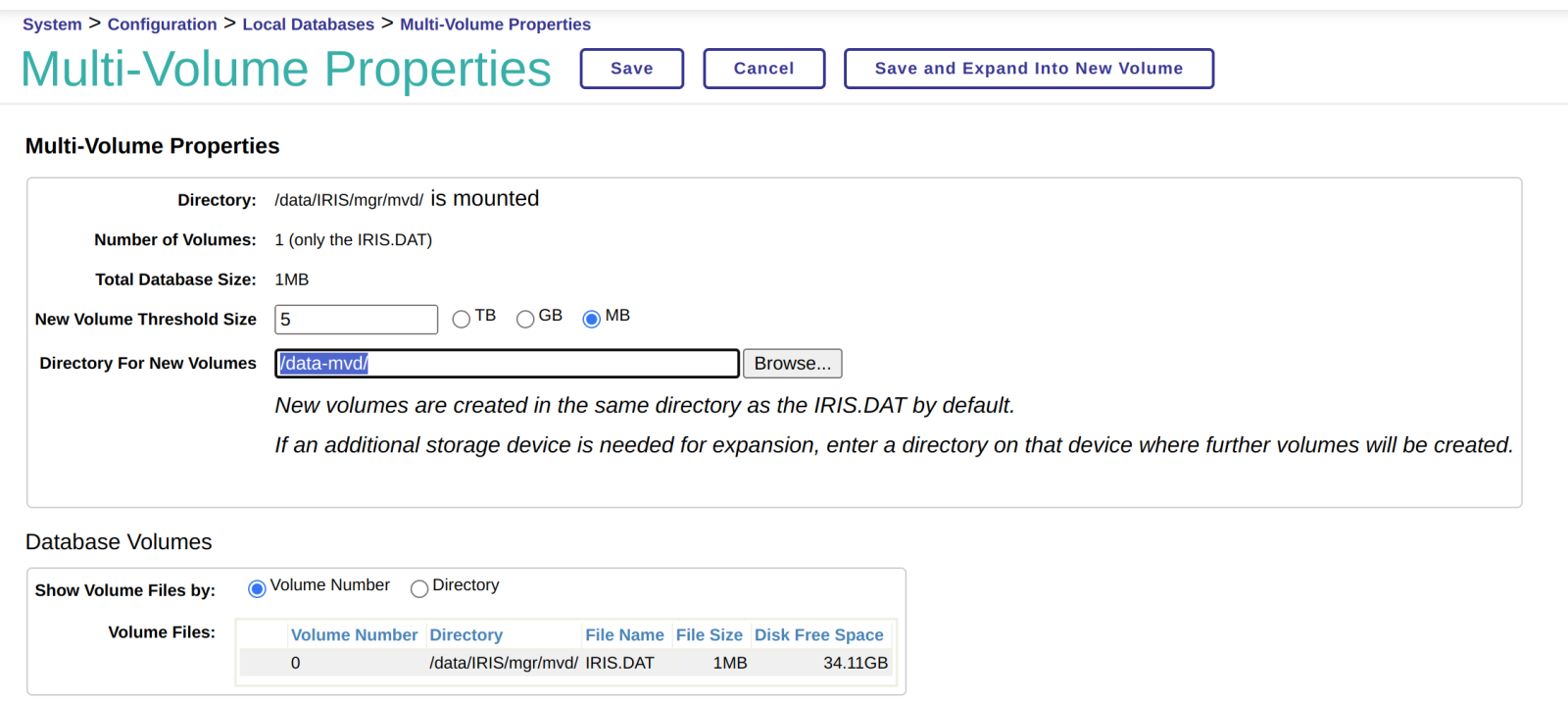
扩展
由于我在这个例子中将数据库阈值设置的相当小,它会生成多个数据库文件。
为了将IRIS.DAT 中的空间耗尽,我新建了一个命名空间使用该数据库: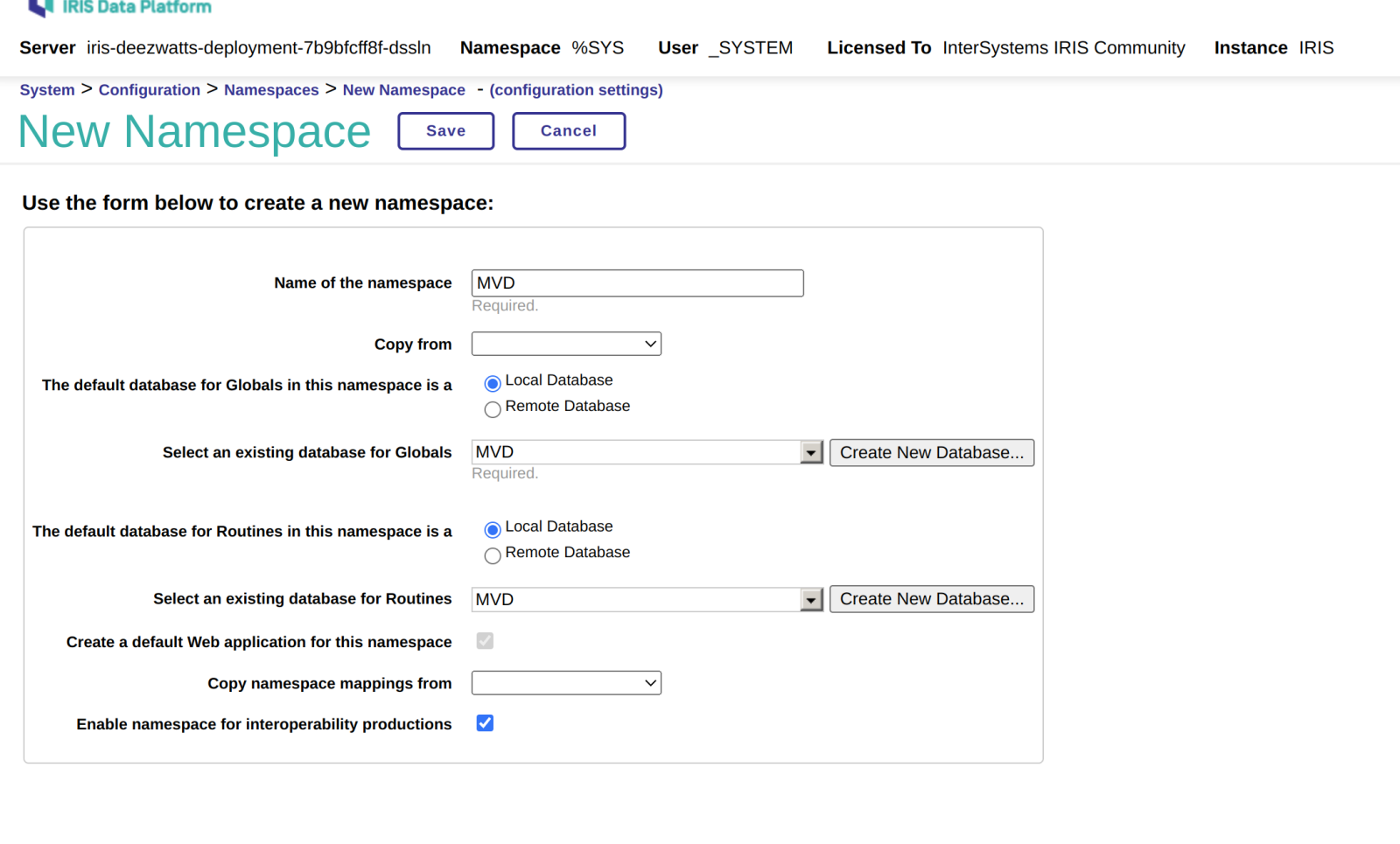
在该命名空间中,我调用 ZPM,从 openexchange 安装了点东西,并运行。
irisowner@iris-deezwatts-deployment-7b9bfcff8f-dssln:~$ irissession IRIS
Node: iris-deezwatts-deployment-7b9bfcff8f-dssln, Instance: IRIS
USER>zn "MVD"
MVD>zn "%SYS" d ##class(Security.SSLConfigs).Create("z") s r=##class(%Net.HttpRequest).%New(),r.Server="pm.community.intersystems.com",r.SSLConfiguration="z" d r.Get("/packages/zpm/latest/installer"),$system.OBJ.LoadStream(r.HttpResponse.Data,"c")
Load started on 06/04/2024 13:43:08
Loading file /data/IRIS/mgr/Temp/z9mu1CvnPnaGbA.xml as xml
Imported class: %ZPM.Installer
Compiling class %ZPM.Installer
Compiling routine %ZPM.Installer.1
Load finished successfully.
%SYS>zpm
=============================================================================
|| Welcome to the Package Manager Shell (ZPM). version 0.7.1 ||
|| Enter q/quit to exit the shell. Enter ?/help to view available commands ||
|| Current registry https://pm.community.intersystems.com ||
=============================================================================
zpm:%SYS>install "zpm-registry"在数据库 UI 中查看其属性:
.png)
pod 中设置的文件夹下的内容:
irisowner@iris-deezwatts-deployment-7b9bfcff8f-dssln:/data-mvd$ ls -ltr /data-mv*
total 5140
drwxrwxrwx 2 irisowner irisowner 16384 Jun 4 11:56 lost+found
-rw-rw---- 1 irisowner irisowner 20 Jun 4 12:11 iris.dbdir
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:25 IRIS-0022.VOL
irisowner@iris-deezwatts-deployment-7b9bfcff8f-dssln:/data-mvd$ ls -ltr /data/IRIS/mgr/mvd
total 164
drwxrwxrwx 2 irisowner irisowner 4096 Jun 4 11:15 stream
-rw-rw---- 1 irisowner irisowner 63 Jun 4 12:01 iris.lck
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0001.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0002.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0003.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0004.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0005.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0006.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0007.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0008.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0009.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0010.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0012.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0015.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0018.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0016.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0019.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0020.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0017.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0014.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0013.VOL
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 12:11 IRIS-0011.VOL
-rwxrwxrwx 1 irisowner irisowner 5242880 Jun 4 13:08 IRIS.DAT
-rw-rw---- 1 irisowner irisowner 5242880 Jun 4 13:08 IRIS-0021.VOL看来我有新玩具了!
结论
这篇帖子很短,可能发到讨论区更合适。不过我得回去工作了,这是我从 @jtrog 那看到新特性。期待未来在社区看到更多使用这项功能的分享和体验。
我们峰会上见!
 Open Exchange
Open Exchange
.png) under the answer.
under the answer..png)
.png)
.png)
.png)