 Open Exchange
Open ExchangeOlá Colegas!
Muitas vezes, durante o desenvolvimento de um frontend de aplicação ou qualquer outra comunicação com API REST, vale a pena usar o Swagger UI - uma IU de teste para aplicações REST que segue a especificação Open API 2.0. Geralmente, é bem trabalhoso, pois permite testes manuais rápidos em relação à API REST, suas respostas e os dados contidos nela.
Recentemente eu introduzi o suporte ao Swagger para o modelo InterSystems IRIS FHIR para API FHIR R4:
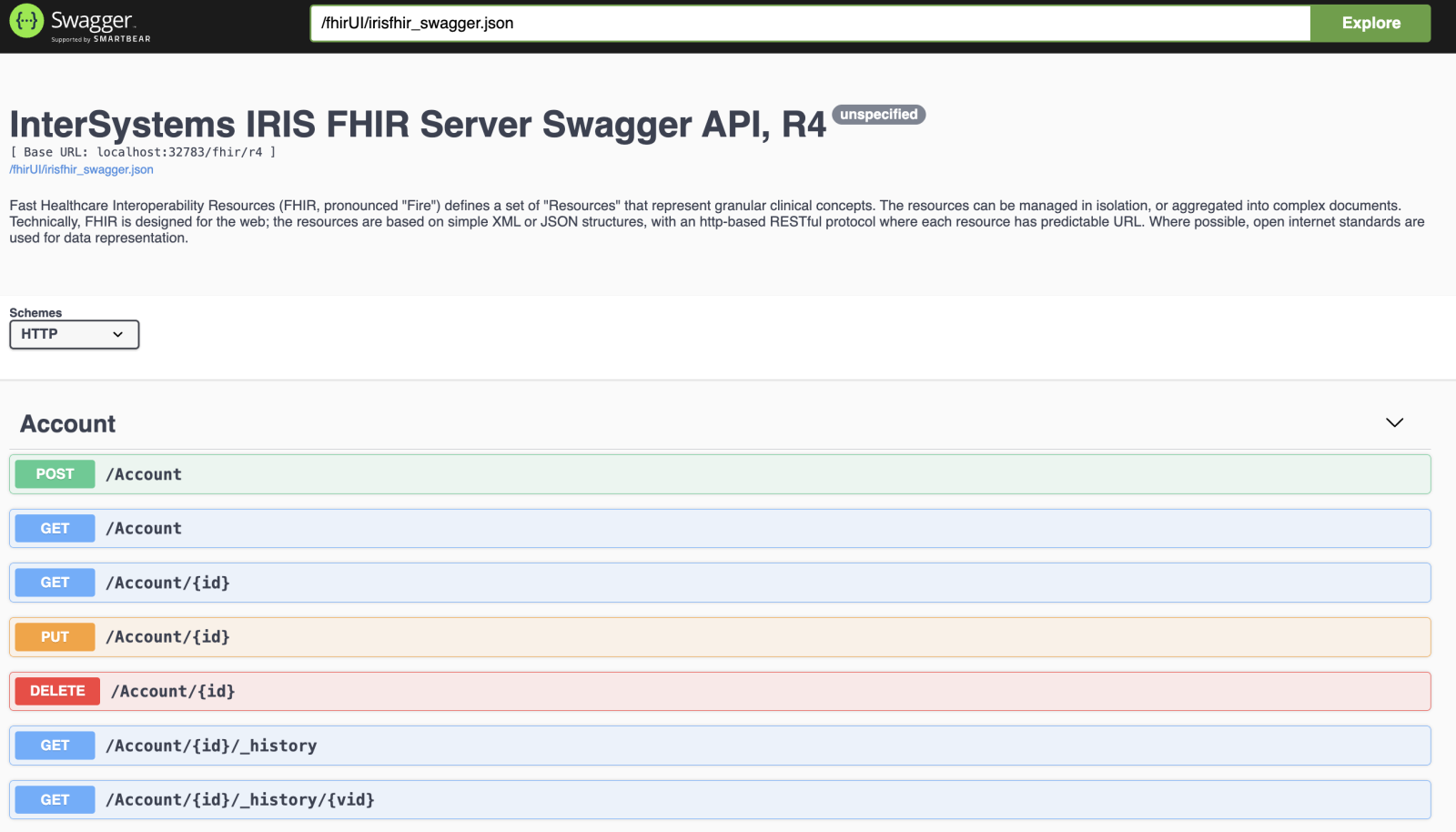
Como fazê-lo funcionar.
Certifique-se de ter o docker instalado.
Clone o repositorio:
git clone git@github.com:intersystems-community/iris-fhir-template.git
e inicie:
docker compose up -d
Uma vez que tudo esteja montado abra o swagger em:
http://localhost:32783/swagger-ui/index.html
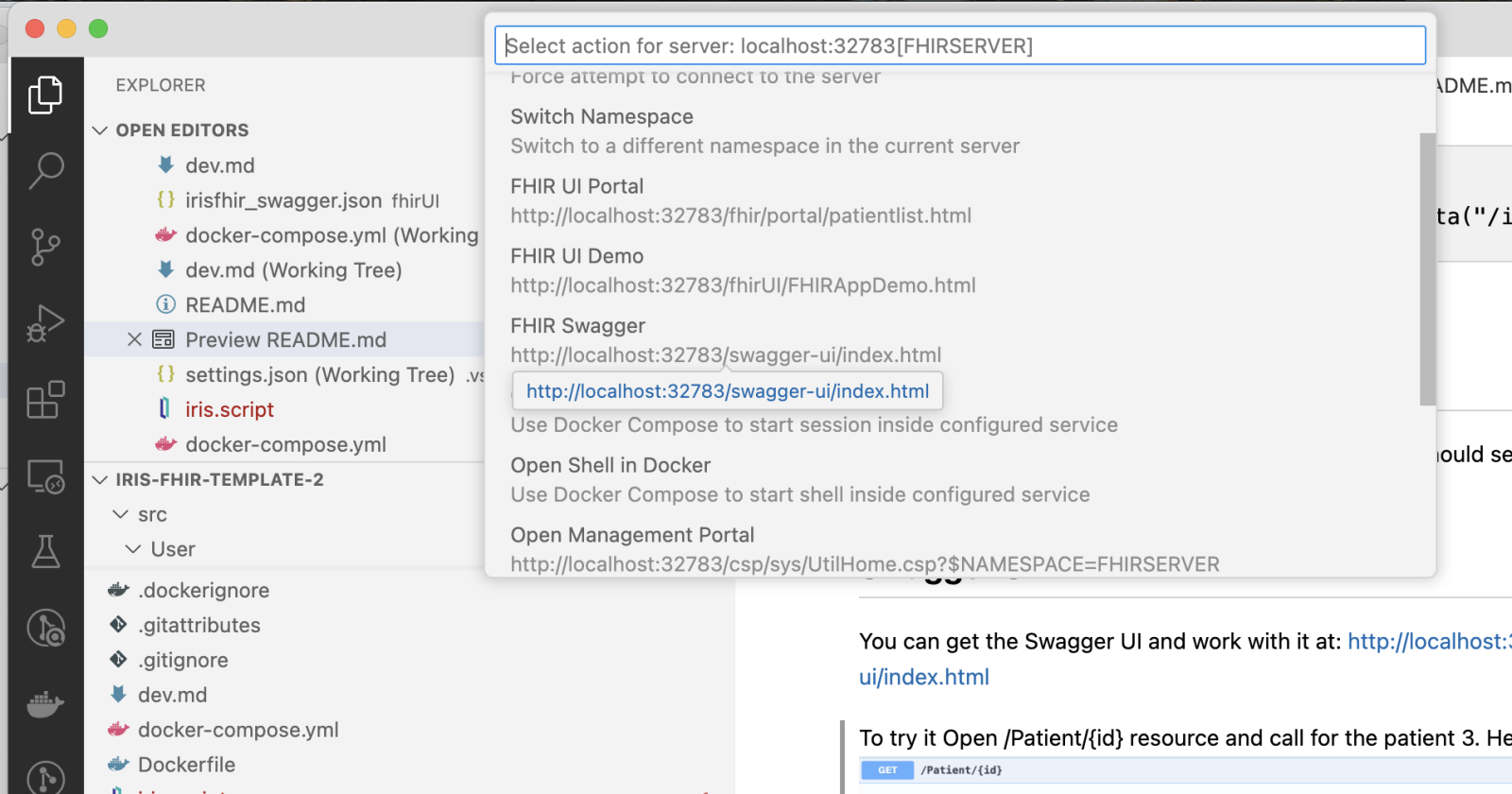
Ou se você puxá-lo no VS Code, você pode abrir através do menu InterSystems:
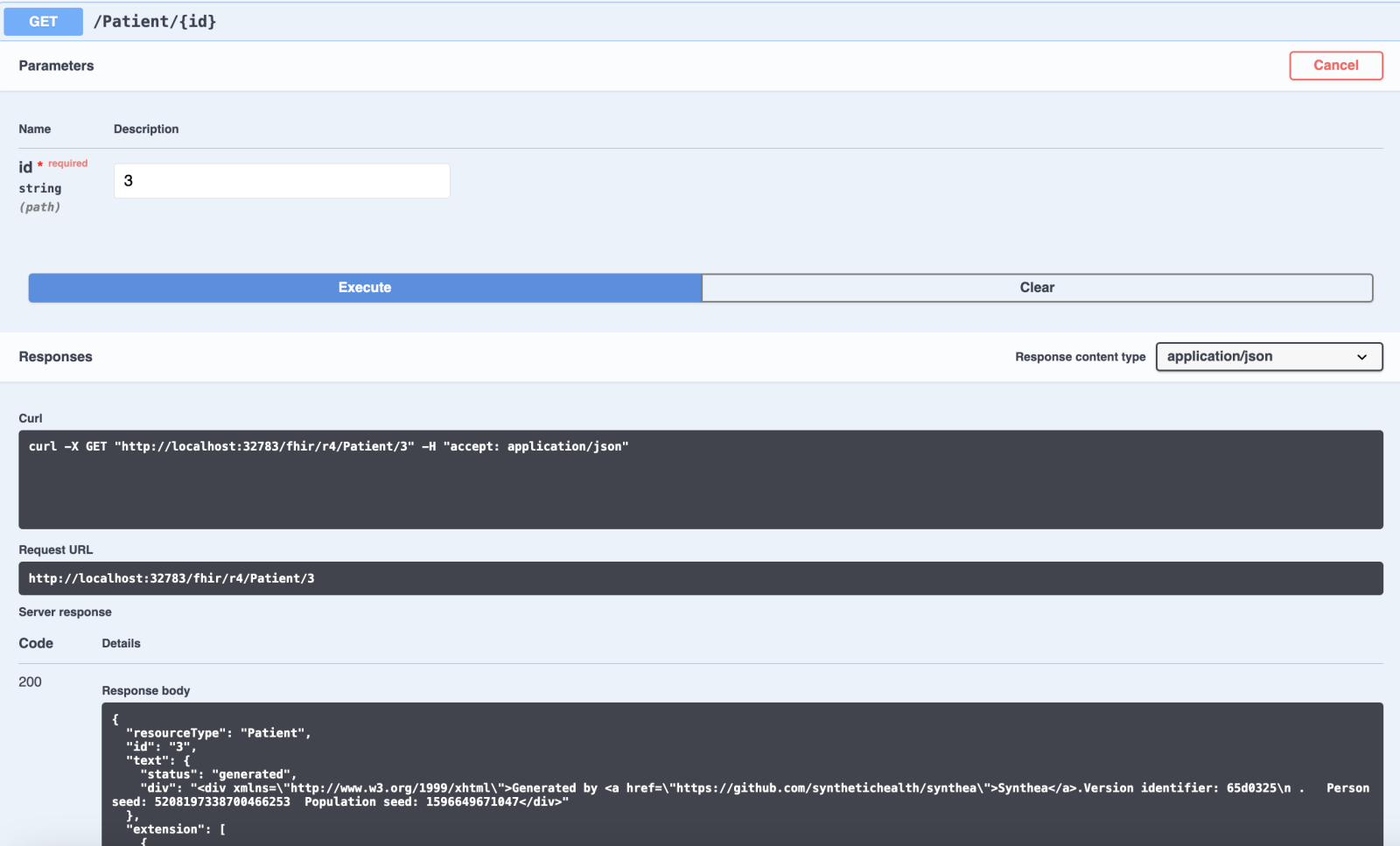
To get it tested for example proceed to Patient entry and request for the patient id=3:
Espero que gostem!
Comentários, feedback e solicitações de pull são muito apreciados!
