Nowadays so much noise around LLM, AI, and so on. Vector databases are kind of a part of it, and already many different realizations for the support in the world outside of IRIS.
Why Vector?
- Similarity Search: Vectors allow for efficient similarity search, such as finding the most similar items or documents in a dataset. Traditional relational databases are designed for exact match searches, which are not suitable for tasks like image or text similarity search.
- Flexibility: Vector representations are versatile and can be derived from various data types, such as text (via embeddings like Word2Vec, BERT), images (via deep learning models), and more.
- Cross-Modal Searches: Vectors enable searching across different data modalities. For instance, given a vector representation of an image, one can search for similar images or related texts in a multimodal database.
And many other reasons.
So, for this pyhon contest, I decided to try to implement this support. And unfortunately I did not manage to finish it in time, below I'll explain why.
 There are a few major things, that have to be done, to make it full
There are a few major things, that have to be done, to make it full
- Accept and store vectorized data, with SQL, simple example, (3 in this example is the amount of dimensions, it's fixed per field, and all vectors in the field have to have exact dimensions)
create table items(embedding vector(3));
insert into items (embedding) values ('[1,2,3]');
insert into items (embedding) values ('[4,5,6]');
- Similarity functions, there are different algorithms for similarity, suitable for a simple search on a small amount of data, without using indexes
select embedding, vector.l2_distance(embedding, '[9,8,7]') distance from items order by distance;
select embedding, vector.cosine_distance(embedding, '[9,8,7]') distance from items order by distance;
select embedding, -vector.inner_product(embedding, '[9,8,7]') distance from items order by distance;
- Custom index, which helps with a faster search on a big amount of data, indexes can use a different algorithm, and use different distance functions from above, and some other options
- HNSW
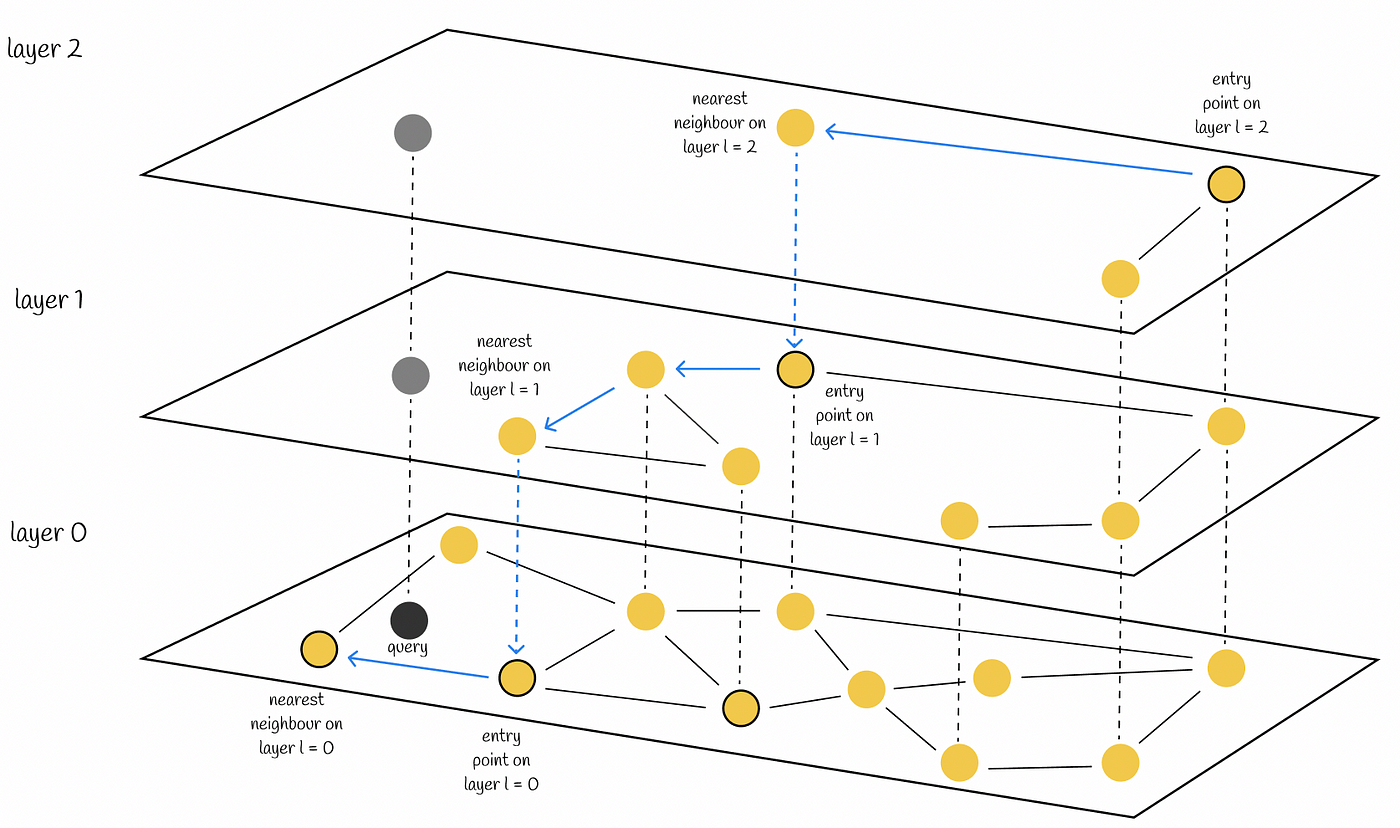
- Inverted file index
.png)
- The search just will use the created index and its algorithm will find the requested information.
Insert vectors
The vector is expected to be an array of numeric values, which could be integers or floats, as well as signed or not. In IRIS we can store it just as $listbuild, it has a good representation, it's already supported, only needed to implement conversion from ODBC to logical.
Then the values can be inserted as plain text using external drivers such as ODBC/JDBC or from just inside IRIS with ObjectScript
- Plain SQL
insert into items (embedding) values ('[1,2,3]');
- From ObjectScript
set rs = ##class(%SQL.Statement).%ExecDirect(, "insert into test.items (embedding) values ('[1,2,3]')")
set rs = ##class(%SQL.Statement).%ExecDirect(, "insert into test.items (embedding) values (?)", $listbuild(2,3,4))
- Or Embedded SQL
&sql(insert into test.items (embedding) values ('[1,2,3]'))
set val = $listbuild(2,3,4)
&sql(insert into test.items (embedding) values (:val))
It will always be stored as $lb(), and returned back in textual format in ODBC
During tests using DBeaver, I found that the first row after connection inserts correctly, but all others go as is, without any validation or conversion.
Then I found, that JDBC uses Fast Inserts by default, in this case, it stores inserted data directly to globals, so I had to switch it off manually
In DBeaver, select optfastSelect in FeatureOption field
.png)
Calculations
Mainly vectors are required to support the calculation of distances between two vectors
For the contest, I needed to use embedded Python, and here comes an issue, how to operate with $lb in Embedded Python. There is a method ToList in %SYS.Class, but Python package iris does not have it builtin, and needs to call it ObjectScript way
ClassMethod l2DistancePy(v1 As dc.vector.type, v2 As dc.vector.type) As %Decimal(SCALE=10) [ Language = python, SqlName = l2_distance_py, SqlProc ]
{
import iris
import math
vector_type = iris.cls('dc.vector.type')
v1 = iris.cls('%SYS.Python').ToList(vector_type.Normalize(v1))
v2 = iris.cls('%SYS.Python').ToList(vector_type.Normalize(v2))
return math.sqrt(sum([(val1 - val2) ** 2 for val1, val2 in zip(v1, v2)]))
}
It does not look right at all. I would prefer that $lb could be interpreted on a fly as list in python, or at list builtin functions to_list and from_list
Another issue is when I tried to test this function using different ways. Using SQL from Embedded Python that uses SQL Function written in Embedded Python, it will crash. So, I had to add ObjectScript's functions as well.
ModuleNotFoundError: No module named 'dc'
SQL Function VECTOR.NORM_PY failed with error: SQLCODE=-400,%msg=ERROR #5002: ObjectScript error: <OBJECT DISPATCH>%0AmBm3l0tudf^%sqlcq.USER.cls37.1 *python object not found
Currently implemented functions to calculate distance, both in Python and ObjectScript
- Euclidean distance
[SQL]_system@localhost:USER> select embedding, vector.l2_distance_py(embedding, '[9,8,7]') distance from items order by distance;
+
| embedding | distance |
+
| [4,5,6] | 5.91607978309961613 |
| [1,2,3] | 10.77032961426900748 |
+
2 rows in set
Time: 0.011s
[SQL]_system@localhost:USER> select embedding, vector.l2_distance(embedding, '[9,8,7]') distance from items order by distance;
+
| embedding | distance |
+
| [4,5,6] | 5.916079783099616045 |
| [1,2,3] | 10.77032961426900807 |
+
2 rows in set
Time: 0.012s
- Cosine similarity
[SQL]_system@localhost:USER> select embedding, vector.cosine_distance(embedding, '[9,8,7]') distance from items order by distance;
+
| embedding | distance |
+
| [4,5,6] | .034536677566264152 |
| [1,2,3] | .11734101007866331 |
+
2 rows in set
Time: 0.034s
[SQL]_system@localhost:USER> select embedding, vector.cosine_distance_py(embedding, '[9,8,7]') distance from items order by distance;
+
| embedding | distance |
+
| [4,5,6] | .03453667756626421781 |
| [1,2,3] | .1173410100786632659 |
+
2 rows in set
Time: 0.025s
- Inner product
[SQL]_system@localhost:USER> select embedding, vector.inner_product_py(embedding, '[9,8,7]') distance from items order by distance;
+
| embedding | distance |
+
| [1,2,3] | 46 |
| [4,5,6] | 118 |
+
2 rows in set
Time: 0.035s
[SQL]_system@localhost:USER> select embedding, vector.inner_product(embedding, '[9,8,7]') distance from items order by distance;
+
| embedding | distance |
+
| [1,2,3] | 46 |
| [4,5,6] | 118 |
+
2 rows in set
Time: 0.032s
Additionally Implemented mathematical functions, add, sub, div, mul. InterSystems support create own aggregate functions. So, it could be possible to sum all vectors or find the avg. But unfortunately, InterSystems does not support using the same name and needs use own name (and schema) for function. But it does not support non-numeric result for aggregate function
Simple vector_add function, which returns a sum of two vectors
.png)
When used as an aggregate, it shows 0, while the expected vector too
.png)
Build an index
Unfortunately, I did not manage to finish this part, due to some obstacles I faced during realization.
- The lack of builtin $lb to python list conversions and back when vector in IRIS stored in $lb, and all the logic with building index is expected to be in Python, it's important to get data from $lb and set it back to globals too
- lack of support for globals
- $Order in IRIS, supports direction, so it can be used in reverse, while order realization in Python Embedded does not have it, so it will require reading all keys and reversing them or storing the end somewhere
- Have doubts due to bad experience with Python's SQL functions, called from Python mentioned above
- During the building index, was expected to store distances in the graph between vectors, but faced a bug with storing float numbers in global
I opened 11 issues with Embedded Python I found during the work, so most of the time to find workarounds to solve issues. With help from @Guillaume Rongier project named iris-dollar-list I managed to solve some issues.
Installation
Anyway it is still available and can be installed with IPM, and used even with limited functionality
zpm "install vector"
Or in development mode with docker-compose
git clone https://github.com/caretdev/iris-vector.git
cd iris-vector
docker-compose up -d
 Open Exchange
Open Exchange.png)